[1]
STANKIEWICZ P, TAN Y T, KOBILAROV M Adaptive s-ampling with an autonomous underwater vehicle in static marine environments
[J]. Journal of Field Robotics , 2021 , 38 (4 ): 572 - 597
DOI:10.1002/rob.22005
[本文引用: 1]
[2]
RUMSON A. Development of autonomous subsea pipeline inspection capabilities[C]// Global Oceans 2020: Singapore–US Gulf Coast . Biloxi: IEEE, 2020: 1-6.
[本文引用: 1]
[3]
CEJKA J, BRUNO F, SKARLATOS D, et al Detecting square markers in underwater environments
[J]. Remote Sensing , 2019 , 11 (4 ): 23
[本文引用: 1]
[4]
ANCUTI C, ANCUTI C O, HABER T, et al. Enhancing underwater images and videos by fusion[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 81-88.
[本文引用: 1]
[5]
HUANG D, WANG Y, SONG W, et al. Shallow-water image enhancement using relative global histogram stretching based on adaptive parameter acquisition[C]// International Conference on Multimedia Modeling . Bangkok: Springer, 2018: 453-465.
[本文引用: 2]
[6]
DREWS P, NASCIMENTO E, MORAES F, et al. Transmission estimation in underwater single images[C]// Proceedings of the IEEE International Conference on Computer Vision Workshops . Sydney: IEEE, 2013: 825-830.
[本文引用: 2]
[7]
PENG Y, COSMAN P C Underwater image restoration based on image blurriness and light absorption
[J]. IEEE Transactions on Image Processing , 2017 , 26 (4 ): 1579 - 1594
DOI:10.1109/TIP.2017.2663846
[本文引用: 2]
[8]
SONG W, WANG Y, HUANG D, et al. A rapid scene depth estimation model based on underwater light attenuation prior for underwater image restoration[C]// Pacific Rim Conference on Multimedia . Hefei: Springer, 2018: 678-688.
[本文引用: 2]
[9]
LI J, SKINNER K A, EUSTICE R M, et al WaterGAN: uns-upervised generative network to enable real-time color correction of monocular underwater images
[J]. IEEE Robotics and Automation Letters , 2018 , 3 (1 ): 387 - 394
[本文引用: 1]
[10]
LI C Y, GUO J C, GUO C L Emerging from water: underwater image color correction based on weakly supervised color transfer
[J]. IEEE Signal Processing Letters , 2018 , 25 (3 ): 323 - 327
DOI:10.1109/LSP.2018.2792050
[本文引用: 1]
[11]
FABBRI C, ISLAM M J, SATTAR J. Enhancing underwater imagery using generative adversarial networks[C]// 2018 IEEE International Conference on Robotics and Automation . Brisbane: IEEE, 2018: 7159-7165.
[本文引用: 2]
[12]
WANG N, ZHOU Y, HAN F, et al. UWGAN: underwater GAN for real-world underwater color restoration and dehazing [EB/OL]. (2019-12-21). https://arxiv.org/ftp/arxiv/papers/1912/1912.10269.pdf.
[本文引用: 4]
[13]
LIU P, ZHANG H, ZHANG K, et al. Multi-level wavelet-CNN for image restoration[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops . Salt Lake City: IEEE, 2018: 773-782.
[本文引用: 2]
[14]
JAFFE J S Computer modeling and the design of optimal underwater imaging systems
[J]. IEEE Journal of Oceanic Engineering , 1990 , 15 (2 ): 101 - 111
DOI:10.1109/48.50695
[本文引用: 1]
[15]
AKKAYNAK D, TREIBITZ T. A revised underwater image formation model[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6723-6732.
[本文引用: 4]
[16]
AKKAYNAK D, TREIBITZ T, SHLESINGER T, et al. What is the space of attenuation coefficients in underwater computer vision?[C]// Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition . Honolulu: IEEE, 2017: 4931-4940.
[本文引用: 3]
[17]
GALDRAN A, PARDO D, PICON A, et al Automatic red channel underwater image restoration
[J]. Journal of Visual Communication and Image Representation , 2015 , 26 : 132 - 145
DOI:10.1016/j.jvcir.2014.11.006
[本文引用: 1]
[18]
ZHAO X W, JIN T, QU S Deriving inherent optical properties from background color and underwater image enhancement
[J]. Ocean Engineering , 2015 , 94 : 163 - 172
DOI:10.1016/j.oceaneng.2014.11.036
[本文引用: 1]
[19]
AKKAYNAK D, TREIBITZ T. Sea-thru: a method for removing water from underwater images[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Reco-gnition . Long Beach: IEEE, 2019: 1682-1691.
[本文引用: 2]
[20]
GODARD C, MAC AODHA O, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3828-3838.
[本文引用: 2]
[21]
WEI K, FU Y, YANG J, et al. A physics-based noise formation model for extreme low-light raw denoising [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2758-2767.
[本文引用: 1]
[22]
RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. (2015-11-19). https://arxiv.org/pdf/1511.06434.pdf.
[本文引用: 1]
[23]
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-assisted Intervention. Munich: Springer, 2015: 234-241.
[本文引用: 1]
[24]
ODENA A, DUMOULIN V, OLAH C. Deconvolution and checkerboard artifacts [EB/OL]. [2021-03-01]. https://distill.pub/2016/deconv-checkerboard/.
[本文引用: 1]
[25]
GATYS L A, ECKER A S, BETHGE M. A neural algorithm of artistic style [EB/OL]. (2015-08-26). https://arxiv.org/pdf/1508.06576.pdf.
[本文引用: 1]
[26]
ISLAM M J, XIA Y, SATTAR J Fast underwater image enh-ancement for improved visual perception
[J]. IEEE Robotics and Automation Letters , 2020 , 5 (2 ): 3227 - 3234
DOI:10.1109/LRA.2020.2974710
[本文引用: 2]
[27]
SILBERMAN N, FERGUS R. Indoor scene segmentation using a structured light sensor[C]// 2011 IEEE International Conference on Computer Vision Workshops . Barcelona: IEEE, 2011: 601-608.
[本文引用: 1]
[28]
SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segme-ntation and support inference from rgbd images[C]// European Conference on Computer Vision . Florence: Springer, 2012: 746-760.
[本文引用: 1]
[29]
URPC竞赛项目: 水下目标检测 [DS/OL]. [2019-8-8]. http://www.cnurpc.org/a/xwjrz/2019/0808/129.html.
[本文引用: 1]
[30]
YANG M, SOWMYA A An underwater color image quality evaluation metric
[J]. IEEE Transactions on Image Processing , 2015 , 24 (12 ): 6062 - 6071
DOI:10.1109/TIP.2015.2491020
[本文引用: 1]
[31]
PANETTA K, GAO C, AGAIAN S Human-visual-system-inspired underwater image quality measures
[J]. IEEE Journal of Oceanic Engineering , 2015 , 41 (3 ): 541 - 551
[本文引用: 1]
[32]
MITTAL A, SOUNDARARAJAN R, BOVIK A C Making a “completely blind” image quality analyzer
[J]. IEEE Signal Processing Letters , 2013 , 20 (3 ): 209 - 212
DOI:10.1109/LSP.2012.2227726
[本文引用: 1]
[33]
HORE A, ZIOU D. Image quality metrics: PSNR vs. SSIM [C]// 2010 20th International Conference on Pattern Recognition. Istanbul: IEEE, 2010: 2366-2369.
[本文引用: 2]
Adaptive s-ampling with an autonomous underwater vehicle in static marine environments
1
2021
... 自主水下机器人(autonomous underwater vehicle ,AUV)和遥控无人潜水器(remote operated vehicle,ROV)技术的逐渐成熟使海洋资源的开发和探索进入了新的阶段. 在海洋的勘探活动之中,视觉传感器因具备高信息密度和高直观性,成为水下机器人装备的优选,能够辅助水下机器人完成海洋环境检测[1 ] 、水下电缆检修[2 ] 、水下目标检测[3 ] 等任务. ...
1
... 自主水下机器人(autonomous underwater vehicle ,AUV)和遥控无人潜水器(remote operated vehicle,ROV)技术的逐渐成熟使海洋资源的开发和探索进入了新的阶段. 在海洋的勘探活动之中,视觉传感器因具备高信息密度和高直观性,成为水下机器人装备的优选,能够辅助水下机器人完成海洋环境检测[1 ] 、水下电缆检修[2 ] 、水下目标检测[3 ] 等任务. ...
Detecting square markers in underwater environments
1
2019
... 自主水下机器人(autonomous underwater vehicle ,AUV)和遥控无人潜水器(remote operated vehicle,ROV)技术的逐渐成熟使海洋资源的开发和探索进入了新的阶段. 在海洋的勘探活动之中,视觉传感器因具备高信息密度和高直观性,成为水下机器人装备的优选,能够辅助水下机器人完成海洋环境检测[1 ] 、水下电缆检修[2 ] 、水下目标检测[3 ] 等任务. ...
1
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
2
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
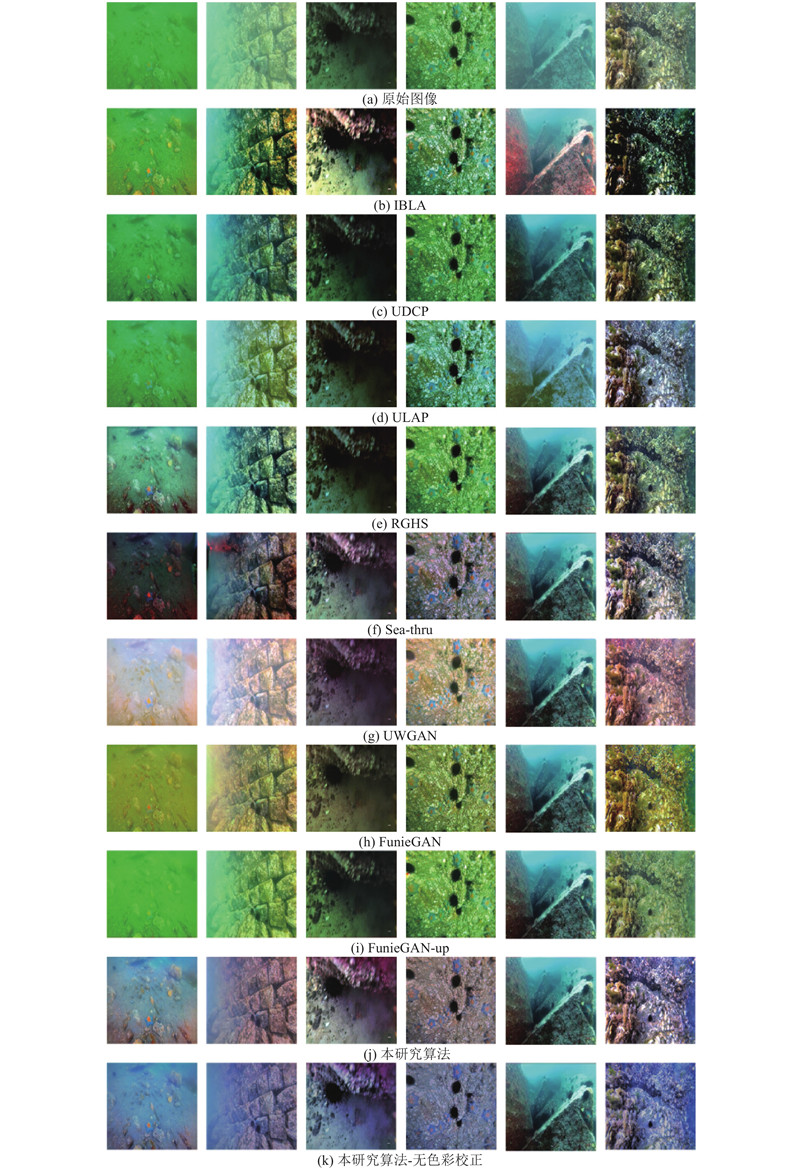
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
2
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
Underwater image restoration based on image blurriness and light absorption
2
2017
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
2
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
WaterGAN: uns-upervised generative network to enable real-time color correction of monocular underwater images
1
2018
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
Emerging from water: underwater image color correction based on weakly supervised color transfer
1
2018
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
2
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
... 1)合成水下数据集. 该数据集由第2节的水下图像生成模型合成,包含3733张室内场景RGB图像和对应的合成水下图像,合成图像风格接近URPC2019数据集的水下图像;2)EUVP数据集. 由文献[26 ]提供的水下图像数据集,其中真实水下图像由7种不同的摄像机于不同地点、不同能见度条件下的海洋环境中采集. 该数据集由Fabbri等[11 ] 所提出的方法制作−利用现有的增强算法对真实水下图像进行增强,人工挑选出具有优良视觉的部分(真值),与原始水下图像配对(若增强图像来自CycleGAN弱监督方法,则采用对应模型的方法对增强图像进行退化,构成配对图像),共有3类共11435组配对水下图像. ...
4
... 由于水下环境的特殊性,水下图像往往须经过预处理才能更好地进行分析处理,所以水下图像增强算法是图像处理领域的热点之一. 针对水下图像的增强算法相继出现,例如,融合算法[4 ] 通过多种增强方法从单张图像中获得多个子增强图像,再按融合权重将子增强图像融合,获得最终的增强图像;相对全局直方图拉伸算法(relative global histogram stretching,RGHS)[5 ] 通过采集自适应参数来对水下图像直方图进行拉伸,以改善水下图像的视觉质量. 另一方面,针对水下环境的成像模型的研究逐渐增多,对应的水下图像复原算法也相继出现. 例如,暗通道优先算法(underwater dark channel prior,UDCP)[6 ] 基于暗通道的先验信息来估计水下场景的光传输图和场景深度图,从而对水下图像进行复原; Peng 等[7 ] 通过建立图像模糊和光吸收(image blurriness and light absorption,IBLA)的模型复原水下图像;Song 等[8 ] 则利用水下光衰减的先验信息(underwater light attenuation prior,ULAP)来估计场景深度图,进而复原水下图像. 随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)在图像检测领域获得了诸多突破性的成果,将CNN引入水下图像增强领域也成为一种趋势. Li 等[9 ] 创新性地利用生成式对抗网络(generative adversarial networks,GAN),以大气中的图像和其深度图以及噪声矢量作为输入,并建立相机模型来生成水下图像,然后将合成的水下图像、大气图像以及对应的深度图像作为输入,对CNN模型进行训练,实现了水下图像增强. Li等[10 ] 从大量水下图像中选取质量最高的一部分,并利用循环式生成对抗网络(cycle generative adversarial networks,Cycle-GAN)[11 ] 学习高质量到低质量水下图像的映射,然后根据该映射对高质量水下图像进行人工退化,获得成对的增强前-增强后数据集,利用该数据集对Cycle-GAN模型进行逆向训练(学习低质量到高质量水下图像的映射),对水下图像进行增强;此外,该文献还提出了一种基于弱监督的方法,不使用配对的水下数据集,而直接将不同质量的水下图像混合作为训练集用于水下图像增强模型,但该方法的增强效果差于使用配对式数据集的方法. Wang等[12 ] 提出了UWGAN,其对水下成像模型进行了改进,同样通过GAN来合成水下图像,并设计了一种U型结构(U-Net)的端到端CNN模型,利用合成水下图像与对应的大气图像作为训练集,实现水下图像增强. 上述算法将深度学习应用到水下图像增强领域,提升了算法的整体性能. ...
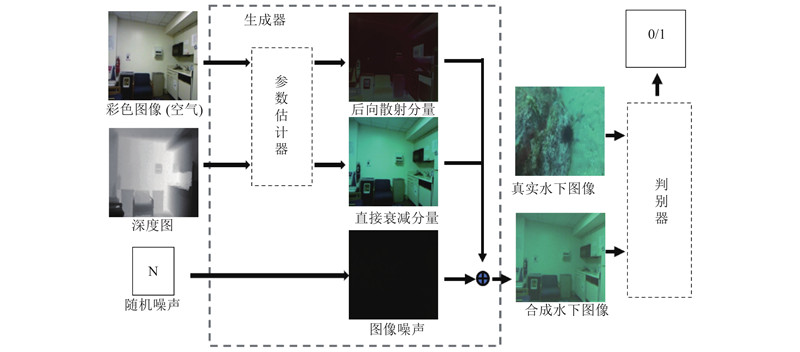
... GAN模型的自由度很高,为了达到纳什均衡,在设计生成器时须尽可能地利用先验知识,对生成模型进行合理的约束. Wang等[12 ] 对雾天成像模型进行改进,将雾天成像模型Ic =Jc tc +A (1−tc )改为Ic =Jc tc +A tc (1−tc ' ),其中,A 为将当前环境置于空气中的环境光,tc 为场景的传递图,tc ' 为考虑了散射系数的传递图. 假设tc 和tc ' 为常数,Akkaynak等[16 ] 的研究表明,这2个是关于波长、水体散射系数和光波衰减系数等物理系数的函数. 本研究提出的GAN模型的生成器以文献[15 ]所提出的修正水下成像模型为基础构建,其对参数tc 和tc ' 进行了更细致的扩展(式(2)). 由式(2)~(6)可知,想要得到理想的增强图像Jc ,须测量或者估计以下参数:1)用于测量水体光学性质的物理散射系数b 和光波衰减系数β ;2)用于计算环境光的光谱E (d , λ )的水深d ;3)物体与相机的距离z ;4)场景中每个物体的反射比ρ 和相机的光谱响应Sc . 实际上,要精确地测量这些参数,就须使用相同的设备在水下场景中进行大量的采样和计算. 在实际应用时希望仅通过单张的图像而不需要任何其他额外信息就可以改善它的视觉效果. Akkaynak等[19 ] 使用非线性最小二乘法从单目图像中拟合B c ∞ 、β c B 和β c D ,并使用Godard等提出的单目相机景深估计方法[20 ] 来估算z . 对于真实的水下环境,假设即使有一个函数可以表示单张图像到这些参数的映射,它的复杂度也应远超过非线性最小二乘法所能拟合出的函数空间. 且Godard等[20 ] 提出的模型是为了应用于空气中场景深度估计,对水下环境会产生较大的误差. 本研究使用拟合空间更大的CNN从图像中估计z 以外参数的值. 单目图像景深值z 的估算是一个复杂的问题,但在合成水下图像的方法中可以回避这个难题−使用已有精确景深标注的RGB-D图像来合成对应的水下图像. ...
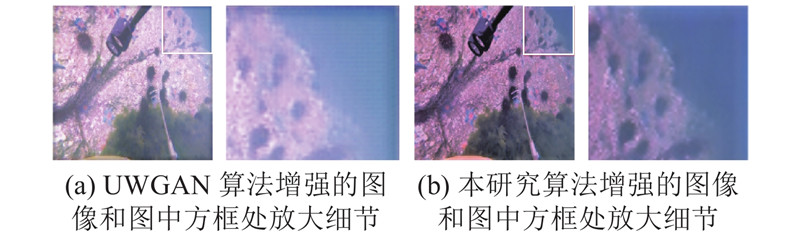
... 获得水下图像到良性视觉图像之间的映射是水下图像增强算法的核心.受采集环境的影响,水下图像通常带有2个严重影响图像分析的退化——雾效应和色彩失真. CNN方法在图像去雾、去模糊任务上取得了较优秀的成果,其中,编码器-解码器式的图像增强网络能在保有良好的图像增强效果的同时大量减少训练参数. U-Net[23 ] 是一种典型的编码器-解码器式网络,其U型结构的网络,在下采样过程中捕捉图像的语义信息,而在与之对应的上采样过程中进行精确的定位,利用少量的图像完成端到端的训练. UWGAN[12 ] 采用U-Net作为水下图像增强网络,取得了一定的效果,但实验发现,U-Net网络处理后的图像可能出现棋盘格效应,且其在图像的色彩调整性能方面有所欠缺. 为了进一步提高水下图像增强网络的性能,针对U-Net增强网络的不足,本研究将水下图像增强任务分为2个部分−去雾和色彩校正,采用MWCNN取代U-Net,克服棋盘格效应并提高网络的细节提取能力,并提出一个新颖的色彩校正方案. ...
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
2
... 本研究进一步探索设计更符合人类视觉的水下图像增强算法,主要进行了以下工作:1)将直接衰减分量和后向散射分量的传输图区分开来,设计了一个用于合成水下图像的GAN;2)基于多级小波包卷积神经网络(multi-level wavelet CNN,MWCNN)[13 ] 设计端到端的图像增强模型,采用离散小波变换取代池化操作,提升模型对图像细节内容的增强作用;3)结合风格代价函数和L2范数损失函数,设计一个同时监控多层特征的损失函数,在不损失细节精度的基础上增强模型色彩校正性能. ...
... MWCNN[13 ] 将小波包变换(wavelet packet transform,WPT)和CNN进行结合,对输入图像进行小波分解,并在每层分解后将所有子带图像作为一个CNN模块的输入,学习紧凑特征表示作为下一层小波分解的输入,利用机器学习的方法替代传统的手工卷积核,以获得更强的鲁棒性和精确性. 经过多层的WPT+CNN结构,CNN可以覆盖多个尺度下的图像分量,进一步加强网络对水下图像特征的学习能力. 与U-Net不同,MWCNN采用离散小波变换(discrete wavelet transform,DWT)和小波逆变换(inverse wavelet transform,IWT)替代下采样和反卷积,由于WPT的双正交特性,MWCNN可以在不丢失信息的条件下进行子采样操作. 与传统的CNN相比,DWT的频率和位置特征也更利于图像细节纹理的保存. 此外,使用IWT替代反卷积可以有效地避免因不均匀重叠[24 ] 而造成的棋盘格效应. 在U型结构网络中引入的跃层连接,可以充分利用编码器中的结构信息,达到更好的去混迭及重建效果. 本研究在MWCNN的基础上提出了改进型的水下图像增强模型,如图4 所示,相比MWCNN,其结构更为简单. 在编码器部分,以256×256像素的RGB图像作为输入,利用DWT不断对原始图像进行逐层分解,并通过3×3卷积对所有层次的子带图像学习紧凑特征表示,其中特征通道数及尺寸的变化已在图中标出. 在每次连续卷积操作后,接入ReLU作为激活层. 在每次DWT操作后特征通道数增加为原来的4倍,除了第1层之外均不使用CNN对特征向量通道进行扩张;在解码器部分,使用IWT按照从高维到低维的顺序使潜在向量返回到原始的输入尺寸. 该模型同样采用了跃层连接,不同于MWCNN,其在每次进行IWT操作后,将输出的张量与编码器侧相同尺度的张量进行拼接而非相加,对拼接后的张量同样采用与编码器部分相同的连续卷积+ReLU操作. ...
Computer modeling and the design of optimal underwater imaging systems
1
1990
... 根据Jaffe的成像模型[14 ] ,水下图像在相机中的成像可以看作3个分量的叠加,分别为直接衰减分量、后向散射分量以及前向散射分量,直接衰减分量为被物体反射回来且在传播过程中未散射到达成像设备的光线;后向散射分量用于描述背景光线被水体中的悬浮微粒折射(散射)后到达成像设备的部分;前向散射分量则是被物体反射的光在传播过程中发生了散射后到达成像设备的部分. 由于水下拍摄可见度较低,水下拍摄时场景与相机之间的距离一般不大,物体反射光线传播过程的散射较弱,故前向散射部分可以忽略. 综上所述,自然光照下的水下图像成像模型可以表示为 ...
4
... Akkaynak等[15 -16 ] 通过实验发现,在水下成像模型中, $ {D}_{c} $ $ {B}_{c} $ $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $ [15 ] : ...
... [15 ]: ...
... 在过去的研究[17 -18 ] 中,通常假设 $ {\;\beta }_{c}^{\mathrm{D}}={\;\beta }_{c}^{\mathrm{B}} $ [15 -16 ] 证明了他们不等且为非常数,并进一步解释了 $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $
... GAN模型的自由度很高,为了达到纳什均衡,在设计生成器时须尽可能地利用先验知识,对生成模型进行合理的约束. Wang等[12 ] 对雾天成像模型进行改进,将雾天成像模型Ic =Jc tc +A (1−tc )改为Ic =Jc tc +A tc (1−tc ' ),其中,A 为将当前环境置于空气中的环境光,tc 为场景的传递图,tc ' 为考虑了散射系数的传递图. 假设tc 和tc ' 为常数,Akkaynak等[16 ] 的研究表明,这2个是关于波长、水体散射系数和光波衰减系数等物理系数的函数. 本研究提出的GAN模型的生成器以文献[15 ]所提出的修正水下成像模型为基础构建,其对参数tc 和tc ' 进行了更细致的扩展(式(2)). 由式(2)~(6)可知,想要得到理想的增强图像Jc ,须测量或者估计以下参数:1)用于测量水体光学性质的物理散射系数b 和光波衰减系数β ;2)用于计算环境光的光谱E (d , λ )的水深d ;3)物体与相机的距离z ;4)场景中每个物体的反射比ρ 和相机的光谱响应Sc . 实际上,要精确地测量这些参数,就须使用相同的设备在水下场景中进行大量的采样和计算. 在实际应用时希望仅通过单张的图像而不需要任何其他额外信息就可以改善它的视觉效果. Akkaynak等[19 ] 使用非线性最小二乘法从单目图像中拟合B c ∞ 、β c B 和β c D ,并使用Godard等提出的单目相机景深估计方法[20 ] 来估算z . 对于真实的水下环境,假设即使有一个函数可以表示单张图像到这些参数的映射,它的复杂度也应远超过非线性最小二乘法所能拟合出的函数空间. 且Godard等[20 ] 提出的模型是为了应用于空气中场景深度估计,对水下环境会产生较大的误差. 本研究使用拟合空间更大的CNN从图像中估计z 以外参数的值. 单目图像景深值z 的估算是一个复杂的问题,但在合成水下图像的方法中可以回避这个难题−使用已有精确景深标注的RGB-D图像来合成对应的水下图像. ...
3
... Akkaynak等[15 -16 ] 通过实验发现,在水下成像模型中, $ {D}_{c} $ $ {B}_{c} $ $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $ [15 ] : ...
... 在过去的研究[17 -18 ] 中,通常假设 $ {\;\beta }_{c}^{\mathrm{D}}={\;\beta }_{c}^{\mathrm{B}} $ [15 -16 ] 证明了他们不等且为非常数,并进一步解释了 $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $
... GAN模型的自由度很高,为了达到纳什均衡,在设计生成器时须尽可能地利用先验知识,对生成模型进行合理的约束. Wang等[12 ] 对雾天成像模型进行改进,将雾天成像模型Ic =Jc tc +A (1−tc )改为Ic =Jc tc +A tc (1−tc ' ),其中,A 为将当前环境置于空气中的环境光,tc 为场景的传递图,tc ' 为考虑了散射系数的传递图. 假设tc 和tc ' 为常数,Akkaynak等[16 ] 的研究表明,这2个是关于波长、水体散射系数和光波衰减系数等物理系数的函数. 本研究提出的GAN模型的生成器以文献[15 ]所提出的修正水下成像模型为基础构建,其对参数tc 和tc ' 进行了更细致的扩展(式(2)). 由式(2)~(6)可知,想要得到理想的增强图像Jc ,须测量或者估计以下参数:1)用于测量水体光学性质的物理散射系数b 和光波衰减系数β ;2)用于计算环境光的光谱E (d , λ )的水深d ;3)物体与相机的距离z ;4)场景中每个物体的反射比ρ 和相机的光谱响应Sc . 实际上,要精确地测量这些参数,就须使用相同的设备在水下场景中进行大量的采样和计算. 在实际应用时希望仅通过单张的图像而不需要任何其他额外信息就可以改善它的视觉效果. Akkaynak等[19 ] 使用非线性最小二乘法从单目图像中拟合B c ∞ 、β c B 和β c D ,并使用Godard等提出的单目相机景深估计方法[20 ] 来估算z . 对于真实的水下环境,假设即使有一个函数可以表示单张图像到这些参数的映射,它的复杂度也应远超过非线性最小二乘法所能拟合出的函数空间. 且Godard等[20 ] 提出的模型是为了应用于空气中场景深度估计,对水下环境会产生较大的误差. 本研究使用拟合空间更大的CNN从图像中估计z 以外参数的值. 单目图像景深值z 的估算是一个复杂的问题,但在合成水下图像的方法中可以回避这个难题−使用已有精确景深标注的RGB-D图像来合成对应的水下图像. ...
Automatic red channel underwater image restoration
1
2015
... 在过去的研究[17 -18 ] 中,通常假设 $ {\;\beta }_{c}^{\mathrm{D}}={\;\beta }_{c}^{\mathrm{B}} $ [15 -16 ] 证明了他们不等且为非常数,并进一步解释了 $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $
Deriving inherent optical properties from background color and underwater image enhancement
1
2015
... 在过去的研究[17 -18 ] 中,通常假设 $ {\;\beta }_{c}^{\mathrm{D}}={\;\beta }_{c}^{\mathrm{B}} $ [15 -16 ] 证明了他们不等且为非常数,并进一步解释了 $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $
2
... GAN模型的自由度很高,为了达到纳什均衡,在设计生成器时须尽可能地利用先验知识,对生成模型进行合理的约束. Wang等[12 ] 对雾天成像模型进行改进,将雾天成像模型Ic =Jc tc +A (1−tc )改为Ic =Jc tc +A tc (1−tc ' ),其中,A 为将当前环境置于空气中的环境光,tc 为场景的传递图,tc ' 为考虑了散射系数的传递图. 假设tc 和tc ' 为常数,Akkaynak等[16 ] 的研究表明,这2个是关于波长、水体散射系数和光波衰减系数等物理系数的函数. 本研究提出的GAN模型的生成器以文献[15 ]所提出的修正水下成像模型为基础构建,其对参数tc 和tc ' 进行了更细致的扩展(式(2)). 由式(2)~(6)可知,想要得到理想的增强图像Jc ,须测量或者估计以下参数:1)用于测量水体光学性质的物理散射系数b 和光波衰减系数β ;2)用于计算环境光的光谱E (d , λ )的水深d ;3)物体与相机的距离z ;4)场景中每个物体的反射比ρ 和相机的光谱响应Sc . 实际上,要精确地测量这些参数,就须使用相同的设备在水下场景中进行大量的采样和计算. 在实际应用时希望仅通过单张的图像而不需要任何其他额外信息就可以改善它的视觉效果. Akkaynak等[19 ] 使用非线性最小二乘法从单目图像中拟合B c ∞ 、β c B 和β c D ,并使用Godard等提出的单目相机景深估计方法[20 ] 来估算z . 对于真实的水下环境,假设即使有一个函数可以表示单张图像到这些参数的映射,它的复杂度也应远超过非线性最小二乘法所能拟合出的函数空间. 且Godard等[20 ] 提出的模型是为了应用于空气中场景深度估计,对水下环境会产生较大的误差. 本研究使用拟合空间更大的CNN从图像中估计z 以外参数的值. 单目图像景深值z 的估算是一个复杂的问题,但在合成水下图像的方法中可以回避这个难题−使用已有精确景深标注的RGB-D图像来合成对应的水下图像. ...
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
2
... GAN模型的自由度很高,为了达到纳什均衡,在设计生成器时须尽可能地利用先验知识,对生成模型进行合理的约束. Wang等[12 ] 对雾天成像模型进行改进,将雾天成像模型Ic =Jc tc +A (1−tc )改为Ic =Jc tc +A tc (1−tc ' ),其中,A 为将当前环境置于空气中的环境光,tc 为场景的传递图,tc ' 为考虑了散射系数的传递图. 假设tc 和tc ' 为常数,Akkaynak等[16 ] 的研究表明,这2个是关于波长、水体散射系数和光波衰减系数等物理系数的函数. 本研究提出的GAN模型的生成器以文献[15 ]所提出的修正水下成像模型为基础构建,其对参数tc 和tc ' 进行了更细致的扩展(式(2)). 由式(2)~(6)可知,想要得到理想的增强图像Jc ,须测量或者估计以下参数:1)用于测量水体光学性质的物理散射系数b 和光波衰减系数β ;2)用于计算环境光的光谱E (d , λ )的水深d ;3)物体与相机的距离z ;4)场景中每个物体的反射比ρ 和相机的光谱响应Sc . 实际上,要精确地测量这些参数,就须使用相同的设备在水下场景中进行大量的采样和计算. 在实际应用时希望仅通过单张的图像而不需要任何其他额外信息就可以改善它的视觉效果. Akkaynak等[19 ] 使用非线性最小二乘法从单目图像中拟合B c ∞ 、β c B 和β c D ,并使用Godard等提出的单目相机景深估计方法[20 ] 来估算z . 对于真实的水下环境,假设即使有一个函数可以表示单张图像到这些参数的映射,它的复杂度也应远超过非线性最小二乘法所能拟合出的函数空间. 且Godard等[20 ] 提出的模型是为了应用于空气中场景深度估计,对水下环境会产生较大的误差. 本研究使用拟合空间更大的CNN从图像中估计z 以外参数的值. 单目图像景深值z 的估算是一个复杂的问题,但在合成水下图像的方法中可以回避这个难题−使用已有精确景深标注的RGB-D图像来合成对应的水下图像. ...
... [20 ]提出的模型是为了应用于空气中场景深度估计,对水下环境会产生较大的误差. 本研究使用拟合空间更大的CNN从图像中估计z 以外参数的值. 单目图像景深值z 的估算是一个复杂的问题,但在合成水下图像的方法中可以回避这个难题−使用已有精确景深标注的RGB-D图像来合成对应的水下图像. ...
1
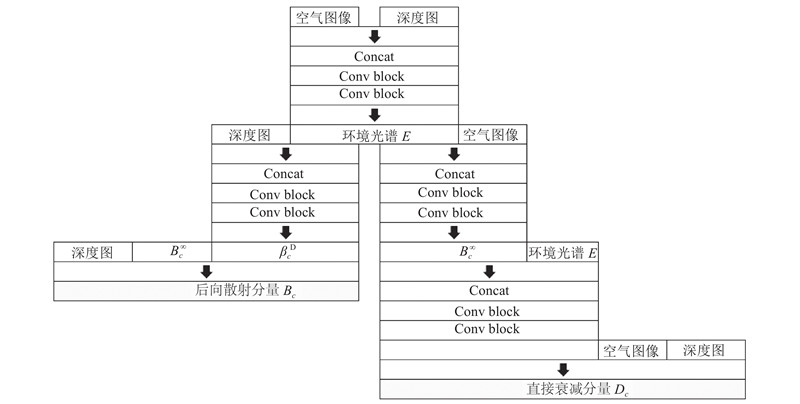
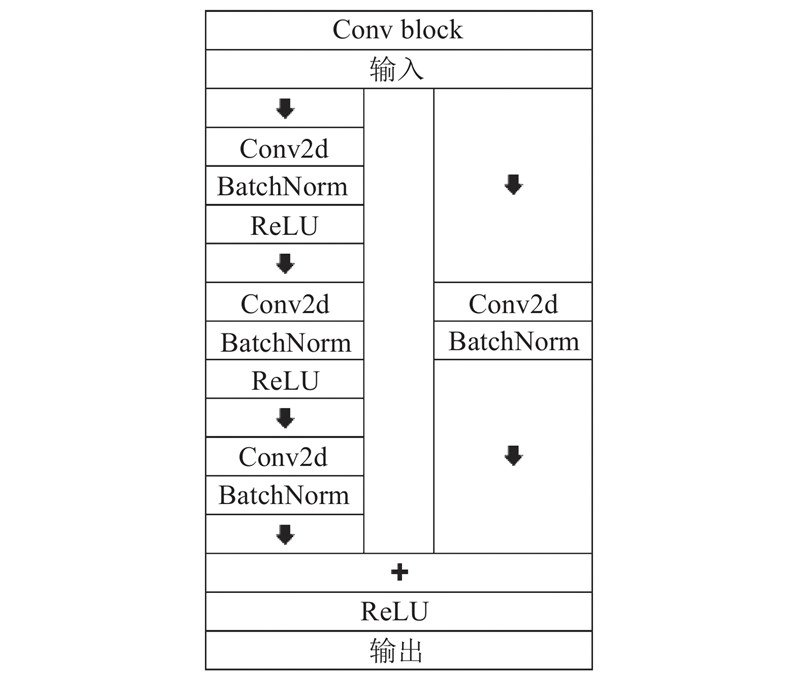
... 由式(6)、(7)可以看出, $ {\;\beta }_{c}^{\mathrm{B}} $ $ {B}_{c}^{\infty } $ $ E $ 图2 所示. 其主要由卷积模块(Conv Block)和连接操作(Concat)组成,Conv Block是一种简单的残差结构,由3层卷积、批标准化、线性整流函数(rectified linear unit,ReLU)和一个残差边组成,如图3 所示,它可以进行特征层串联. 首先,为了估计环境光的光谱 $ E $ $ E $ . 然后,将 $ E $ $ {\;\beta }_{c}^{\mathrm{D}} $ $ {B}_{c}^{\infty } $ $ {B}_{c}^{\infty } $ $ E $ $ {\beta }_{c}^{\mathrm{B}} $ $ {\;\beta }_{c}^{\mathrm{D}} $ $ {\;\beta }_{c}^{\mathrm{B}} $ $ {B}_{c}^{\infty } $ [21 ] 提出的低照度噪声模型,加入了一个人工噪声模块. ...
1
... 所提出的GAN模型判别器采用了Radford等[22 ] 提出的CNN结构,以256×256×3像素的真实或者合成水下图像作为输入,通过4个卷积核大小为5×5、步长为2的卷积层,每个卷积层使得输入图像的尺寸减小为1/2且通道数增加一倍,在每个卷积层后接入leak率为0.2的带泄露修正线性单元(leaky rectified linear unit,LReLU)激活函数.最后一层为线性层,并接入Sigmoid激活函数,最终返回分类标签0(表示合成图像)或1(表示真实图像). ...
1
... 获得水下图像到良性视觉图像之间的映射是水下图像增强算法的核心.受采集环境的影响,水下图像通常带有2个严重影响图像分析的退化——雾效应和色彩失真. CNN方法在图像去雾、去模糊任务上取得了较优秀的成果,其中,编码器-解码器式的图像增强网络能在保有良好的图像增强效果的同时大量减少训练参数. U-Net[23 ] 是一种典型的编码器-解码器式网络,其U型结构的网络,在下采样过程中捕捉图像的语义信息,而在与之对应的上采样过程中进行精确的定位,利用少量的图像完成端到端的训练. UWGAN[12 ] 采用U-Net作为水下图像增强网络,取得了一定的效果,但实验发现,U-Net网络处理后的图像可能出现棋盘格效应,且其在图像的色彩调整性能方面有所欠缺. 为了进一步提高水下图像增强网络的性能,针对U-Net增强网络的不足,本研究将水下图像增强任务分为2个部分−去雾和色彩校正,采用MWCNN取代U-Net,克服棋盘格效应并提高网络的细节提取能力,并提出一个新颖的色彩校正方案. ...
1
... MWCNN[13 ] 将小波包变换(wavelet packet transform,WPT)和CNN进行结合,对输入图像进行小波分解,并在每层分解后将所有子带图像作为一个CNN模块的输入,学习紧凑特征表示作为下一层小波分解的输入,利用机器学习的方法替代传统的手工卷积核,以获得更强的鲁棒性和精确性. 经过多层的WPT+CNN结构,CNN可以覆盖多个尺度下的图像分量,进一步加强网络对水下图像特征的学习能力. 与U-Net不同,MWCNN采用离散小波变换(discrete wavelet transform,DWT)和小波逆变换(inverse wavelet transform,IWT)替代下采样和反卷积,由于WPT的双正交特性,MWCNN可以在不丢失信息的条件下进行子采样操作. 与传统的CNN相比,DWT的频率和位置特征也更利于图像细节纹理的保存. 此外,使用IWT替代反卷积可以有效地避免因不均匀重叠[24 ] 而造成的棋盘格效应. 在U型结构网络中引入的跃层连接,可以充分利用编码器中的结构信息,达到更好的去混迭及重建效果. 本研究在MWCNN的基础上提出了改进型的水下图像增强模型,如图4 所示,相比MWCNN,其结构更为简单. 在编码器部分,以256×256像素的RGB图像作为输入,利用DWT不断对原始图像进行逐层分解,并通过3×3卷积对所有层次的子带图像学习紧凑特征表示,其中特征通道数及尺寸的变化已在图中标出. 在每次连续卷积操作后,接入ReLU作为激活层. 在每次DWT操作后特征通道数增加为原来的4倍,除了第1层之外均不使用CNN对特征向量通道进行扩张;在解码器部分,使用IWT按照从高维到低维的顺序使潜在向量返回到原始的输入尺寸. 该模型同样采用了跃层连接,不同于MWCNN,其在每次进行IWT操作后,将输出的张量与编码器侧相同尺度的张量进行拼接而非相加,对拼接后的张量同样采用与编码器部分相同的连续卷积+ReLU操作. ...
1
... Gatys等[25 ] 使用风格代价模型来实现图像风格转换任务,所提出的Gram矩阵概念将图像各个通道之间的相关性以矩阵的形式表现出来. Gram矩阵的定义如下: ...
Fast underwater image enh-ancement for improved visual perception
2
2020
... 将提出的增强模型同几种具有代表性的水下图像增强算法进行对比实验,包括5种传统增强算法RGHS[5 ] 、UDCP[6 ] 、IBLA[7 ] 、ULAP[8 ] 、Sea-thru[19 ] 及2种深度学习算法FunieGAN、FunieGAN-up(FunieGAN和FunieGAN-up为相同算法[26 ] ,前者基于配对图像训练,后者基于非配对图像训练)和UWGAN[12 ] . 此外,为了验证本研究算法提出的色彩校正方法的性能,对本研究所提出的算法进行消融实验,加入不使用风格代价函数的模型进行对比实验. 实验测试集为URPC数据集上随机选取的500张图像以及EUVP数据集上随机选取的400张图像,从定性和定量的角度来分析实验结果. ...
... 1)合成水下数据集. 该数据集由第2节的水下图像生成模型合成,包含3733张室内场景RGB图像和对应的合成水下图像,合成图像风格接近URPC2019数据集的水下图像;2)EUVP数据集. 由文献[26 ]提供的水下图像数据集,其中真实水下图像由7种不同的摄像机于不同地点、不同能见度条件下的海洋环境中采集. 该数据集由Fabbri等[11 ] 所提出的方法制作−利用现有的增强算法对真实水下图像进行增强,人工挑选出具有优良视觉的部分(真值),与原始水下图像配对(若增强图像来自CycleGAN弱监督方法,则采用对应模型的方法对增强图像进行退化,构成配对图像),共有3类共11435组配对水下图像. ...
1
... 1)NYU Depth数据集[27 -28 ] . 该数据集由纽约大学创建,由Microsoft Kinect的RGB和深度摄像机对各种室内场景采集而成,包含一系列的室内场景RGB图像和对应的深度图. 实验选取了该数据集V1和V2部分的3733张图像和对应的深度图像作为生成模型生成器的输入. 2)URPC2019数据集[29 ] . 该数据集为2019年全国水下机器人大赛提供的目标检测数据集,包含6000余张真实水下图像及物体位置标签,实验将其作为生成模型判别器的输入. ...
1
... 1)NYU Depth数据集[27 -28 ] . 该数据集由纽约大学创建,由Microsoft Kinect的RGB和深度摄像机对各种室内场景采集而成,包含一系列的室内场景RGB图像和对应的深度图. 实验选取了该数据集V1和V2部分的3733张图像和对应的深度图像作为生成模型生成器的输入. 2)URPC2019数据集[29 ] . 该数据集为2019年全国水下机器人大赛提供的目标检测数据集,包含6000余张真实水下图像及物体位置标签,实验将其作为生成模型判别器的输入. ...
1
... 1)NYU Depth数据集[27 -28 ] . 该数据集由纽约大学创建,由Microsoft Kinect的RGB和深度摄像机对各种室内场景采集而成,包含一系列的室内场景RGB图像和对应的深度图. 实验选取了该数据集V1和V2部分的3733张图像和对应的深度图像作为生成模型生成器的输入. 2)URPC2019数据集[29 ] . 该数据集为2019年全国水下机器人大赛提供的目标检测数据集,包含6000余张真实水下图像及物体位置标签,实验将其作为生成模型判别器的输入. ...
An underwater color image quality evaluation metric
1
2015
... 实验使用3种非参考性度量指标−水下图像质量评估度量指标(underwater color image quality evaluation,UCIQE)[30 ] 、水下图像质量指标(underwater image quality measure,UIQM)[31 ] 和图像质量评价(natural image quality evaluator, NIQE)[32 ] 和2种参考性度量指标−峰值信噪比(peak signal-to-noise ratio,PSNR)[33 ] 和结构相似性(structural similarity,SSIM)[33 ] 来评估算法. UCIQE和UIQM是目前认可度较高的2种水下图像非参考性度量指标,UCIQE利用图像色彩浓度、饱和度及对比度的线性组合来量化水下图像的模糊、非均匀色差和对比度. UCIQE越高,说明增强图像总体质量越高. UIQM将色彩度量(UICM)、清晰度度量(UISM)和对比度度量(UIConM)作为评价水下图像质量的基础,UIQM越高,说明增强图像综合质量越高. NIQE是一种基于多元高斯模型的非参考度量指标模型,其在原始图像库中提取图像特征,再利用多元高斯模型进行建模,在评价过程中利用待评价图像的特征模型参数与预先建立的模型参数之间的距离来确定图像质量,NIQE越低说明增强图像质量越好. PSNR将增强图像与真值图像作为输入,可以表征增强图像相对真值图像的失真程度,PSNR越大,失真程度越小. SSIM从亮度、对比度和结构共3个方面来综合评估增强图像与真值图像的相似度,其值越大,两者越相似. ...
Human-visual-system-inspired underwater image quality measures
1
2015
... 实验使用3种非参考性度量指标−水下图像质量评估度量指标(underwater color image quality evaluation,UCIQE)[30 ] 、水下图像质量指标(underwater image quality measure,UIQM)[31 ] 和图像质量评价(natural image quality evaluator, NIQE)[32 ] 和2种参考性度量指标−峰值信噪比(peak signal-to-noise ratio,PSNR)[33 ] 和结构相似性(structural similarity,SSIM)[33 ] 来评估算法. UCIQE和UIQM是目前认可度较高的2种水下图像非参考性度量指标,UCIQE利用图像色彩浓度、饱和度及对比度的线性组合来量化水下图像的模糊、非均匀色差和对比度. UCIQE越高,说明增强图像总体质量越高. UIQM将色彩度量(UICM)、清晰度度量(UISM)和对比度度量(UIConM)作为评价水下图像质量的基础,UIQM越高,说明增强图像综合质量越高. NIQE是一种基于多元高斯模型的非参考度量指标模型,其在原始图像库中提取图像特征,再利用多元高斯模型进行建模,在评价过程中利用待评价图像的特征模型参数与预先建立的模型参数之间的距离来确定图像质量,NIQE越低说明增强图像质量越好. PSNR将增强图像与真值图像作为输入,可以表征增强图像相对真值图像的失真程度,PSNR越大,失真程度越小. SSIM从亮度、对比度和结构共3个方面来综合评估增强图像与真值图像的相似度,其值越大,两者越相似. ...
Making a “completely blind” image quality analyzer
1
2013
... 实验使用3种非参考性度量指标−水下图像质量评估度量指标(underwater color image quality evaluation,UCIQE)[30 ] 、水下图像质量指标(underwater image quality measure,UIQM)[31 ] 和图像质量评价(natural image quality evaluator, NIQE)[32 ] 和2种参考性度量指标−峰值信噪比(peak signal-to-noise ratio,PSNR)[33 ] 和结构相似性(structural similarity,SSIM)[33 ] 来评估算法. UCIQE和UIQM是目前认可度较高的2种水下图像非参考性度量指标,UCIQE利用图像色彩浓度、饱和度及对比度的线性组合来量化水下图像的模糊、非均匀色差和对比度. UCIQE越高,说明增强图像总体质量越高. UIQM将色彩度量(UICM)、清晰度度量(UISM)和对比度度量(UIConM)作为评价水下图像质量的基础,UIQM越高,说明增强图像综合质量越高. NIQE是一种基于多元高斯模型的非参考度量指标模型,其在原始图像库中提取图像特征,再利用多元高斯模型进行建模,在评价过程中利用待评价图像的特征模型参数与预先建立的模型参数之间的距离来确定图像质量,NIQE越低说明增强图像质量越好. PSNR将增强图像与真值图像作为输入,可以表征增强图像相对真值图像的失真程度,PSNR越大,失真程度越小. SSIM从亮度、对比度和结构共3个方面来综合评估增强图像与真值图像的相似度,其值越大,两者越相似. ...
2
... 实验使用3种非参考性度量指标−水下图像质量评估度量指标(underwater color image quality evaluation,UCIQE)[30 ] 、水下图像质量指标(underwater image quality measure,UIQM)[31 ] 和图像质量评价(natural image quality evaluator, NIQE)[32 ] 和2种参考性度量指标−峰值信噪比(peak signal-to-noise ratio,PSNR)[33 ] 和结构相似性(structural similarity,SSIM)[33 ] 来评估算法. UCIQE和UIQM是目前认可度较高的2种水下图像非参考性度量指标,UCIQE利用图像色彩浓度、饱和度及对比度的线性组合来量化水下图像的模糊、非均匀色差和对比度. UCIQE越高,说明增强图像总体质量越高. UIQM将色彩度量(UICM)、清晰度度量(UISM)和对比度度量(UIConM)作为评价水下图像质量的基础,UIQM越高,说明增强图像综合质量越高. NIQE是一种基于多元高斯模型的非参考度量指标模型,其在原始图像库中提取图像特征,再利用多元高斯模型进行建模,在评价过程中利用待评价图像的特征模型参数与预先建立的模型参数之间的距离来确定图像质量,NIQE越低说明增强图像质量越好. PSNR将增强图像与真值图像作为输入,可以表征增强图像相对真值图像的失真程度,PSNR越大,失真程度越小. SSIM从亮度、对比度和结构共3个方面来综合评估增强图像与真值图像的相似度,其值越大,两者越相似. ...
... [33 ]来评估算法. UCIQE和UIQM是目前认可度较高的2种水下图像非参考性度量指标,UCIQE利用图像色彩浓度、饱和度及对比度的线性组合来量化水下图像的模糊、非均匀色差和对比度. UCIQE越高,说明增强图像总体质量越高. UIQM将色彩度量(UICM)、清晰度度量(UISM)和对比度度量(UIConM)作为评价水下图像质量的基础,UIQM越高,说明增强图像综合质量越高. NIQE是一种基于多元高斯模型的非参考度量指标模型,其在原始图像库中提取图像特征,再利用多元高斯模型进行建模,在评价过程中利用待评价图像的特征模型参数与预先建立的模型参数之间的距离来确定图像质量,NIQE越低说明增强图像质量越好. PSNR将增强图像与真值图像作为输入,可以表征增强图像相对真值图像的失真程度,PSNR越大,失真程度越小. SSIM从亮度、对比度和结构共3个方面来综合评估增强图像与真值图像的相似度,其值越大,两者越相似. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}