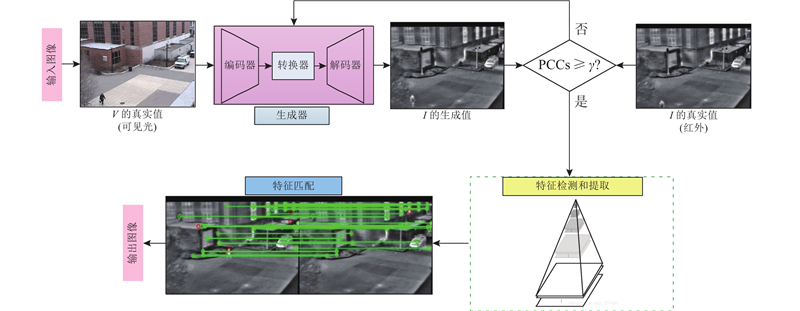
综合上述分析, 本文提出基于生成对抗模型的异源图像匹配方法, 包括以下2个阶段. 1)引入图像转换机制作为匹配预处理阶段, 构建新的损失函数提高可见光-红外图像的转换效果, 消除不同模态图像间的成像差异;2)判断生成图像与真实红外图像的PCCs, 实现匹配任务约束. 设定阈值 $ \gamma $ $ {\text{PCCs}} \geqslant \gamma $
生成式对抗网络是基于深度学习的网络框架, 具有2个相互竞争的神经网络模型, 即1个生成器模型(generative model, $ G $ ) 、1个判别器模型(discriminative model, $ D $ ). 对抗网络的目的是通过反复训练模型来学习输入图像与输出图像二者间的映射关系, 训练好的模型可以生成与给定目标数据集相似的图像,以欺骗判别器. 该网络描述了图像到图像的翻译过程, 如GAN可以实现单模态转多模态数据集, 生成全新图片, 方便后续目标检测、识别和跟踪任务时使用, 以提高数据样本较少时目标检测、识别的准确率. 该应用与本文研究的异源匹配问题高度一致, 即可以看作实现异源(可见光和红外)图像的风格转换问题.
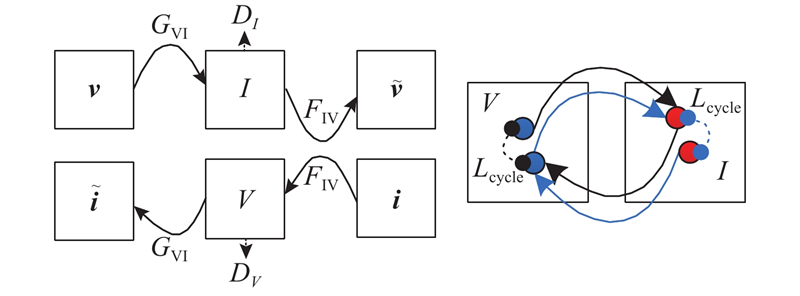
考虑成对的异源图像获取相对困难, 根据GAN网络的核心思想, 利用循环一致性对抗网络(cycle-consistent generative adversarial networks, CycleGAN)[25 ] 不需要成对数据就可以训练、具有较强通用性、性能良好的优势, 完成异源匹配前的图像转换工作. CycleGAN是用2个对称的GAN构成环形网路, 即由2个生成器和2个判别器构成. 以可见光-红外图像的转换问题为例, 将可见光图像和红外图像分别定义为源域 $ V $ $ I $ $ {G_{{\text{VI}}}} $ $ {F_{{\text{IV}}}} $ ${D_{{V}}}$ ${D_{{I}}}$ 图1 所示. 图中,v V 域的图像,i I 域的图像. 通过训练模型的2个映射: $ {G_{{\text{VI}}}} $ $ V \to I $ $ {F_{{\text{IV}}}} $ $ I \to V $ ${G_{{\text{VI}}}}(V)$ $ I $ $ {G_{{\text{VI}}}} $ $ {F_{{\text{IV}}}} $
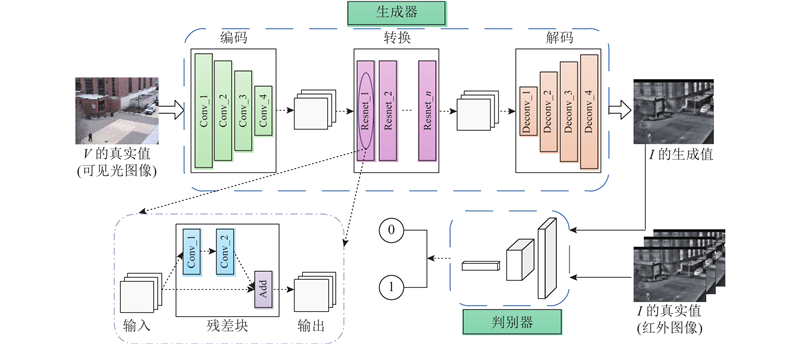
图2 描述了生成对抗网络中生成器和判别器的结构组成. 图中, Conv为卷积层, Resnet为残差层, Deconv为反卷积层. 生成器 $ G $ I . 判别器部分采用Pix2Pix中的PatchGANs结构, 大小为 $ 70 \times 70 $ $ 256 \times 256 $ $ 70 \times 70 $ $ 70 \times 70 $ $ D $
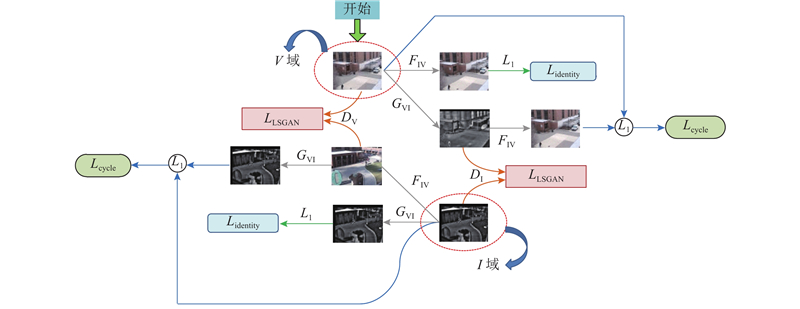
(5) $ \begin{split} & {L_{{\text{loss}}}}\left( {{G_{{\text{VI}}}},{F_{{\text{IV}}}},{D_{{V}}},{D_{{I}}}} \right) = {L_{{\text{LSGAN}}}}\left( {{G_{{\text{VI}}}},{D_{{I}}},V,I} \right) + \\ &\;\;\;\;\;\;\;\;\;\; {L_{{\text{LSGAN}}}}\left( {{F_{{\text{IV}}}},{D_{{V}}},I,V} \right) + \alpha {L_{{\text{cycle}}}}\left( {{G_{{\text{VI}}}},{F_{{\text{IV}}}}} \right){\text{ + }} \\ &\;\;\;\;\;\;\;\;\;\; \beta {L_{{\text{identity}}}}\left( {{G_{{\text{VI}}}},{F_{{\text{IV}}}}} \right). \end{split} $
$ \begin{split} {L_{{\text{loss}}}}({G_{{\text{VI}}}},{F_{{\text{IV}}}},{D_{\text{V}}},{D_{\text{I}}}){\text{ = }}&{L_{{\text{LSGAN}}}}({G_{{\text{VI}}}},{D_{\text{I}}},V,I) + \\ & {L_{{\text{LSGAN}}}}({F_{{\text{IV}}}},{D_{\text{V}}},I,V) + \\ & \alpha {L_{{\text{cycle}}}}({G_{{\text{VI}}}},{F_{{\text{IV}}}}) + \\ & \beta {L_{{\text{identity}}}}({G_{{\text{VI}}}},{F_{{\text{IV}}}}). \\ \end{split} $
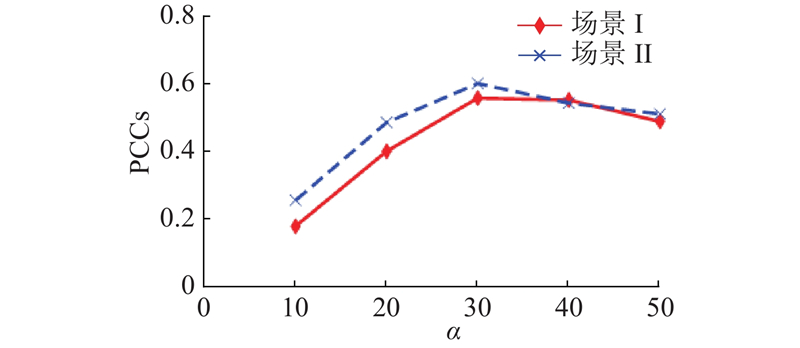
针对模型损失部分, 参考原始CycleGAN模型及相关变体模型, 可以发现,基于该模型下引入的循环一致性损失在总loss中的权值系数大部分位于[10, 40], 该范围在一定程度上保持了风格转换过程中图像的原始特征, 有效实现了原图的循环迁移. 结合生成图像质量评价指标PCCs, 将其作为权重 $ \alpha $ $ \alpha $ $\left( {\alpha {\text{ = }}10、20、30、40、50} \right)$ 图5 所示. 可以看出, 当 $ \alpha = 30 $ $ \alpha $ $ {L_{{\text{identity}}}} $ L identity 权重 $ \;\beta $
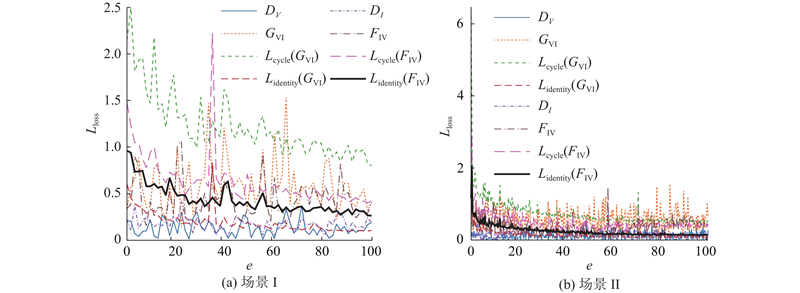
讨论不同场景作用于模型的训练结果, 为了获得最佳转换效果, 对网络模型进行优化处理, 并反复训练模型. 考虑图像转换的多样性问题, 选用网上公开的OTCBVS数据集[26 ] 中Dataset 3: OSUColor and Thermal Database数据库进行实验, 包含2组场景下的可见光图像A和红外图像B, 共计17 089张图像, 大小均为 $ 320 \times 240 $ $ 256 \times 256 $ 图6 所示为随机选取的2组不同场景下可见光、红外图像数据集中的几组样本. 实验模型训练过程的参数设置与3.1节保持一致, 最多迭代100个批次. 如图7 所示为训练模型分别作用于场景1和场景2时对应的损失曲线图.
从表3 可以看出, 随着迭代次数的增加, 生成器越来越能创建更接近真实图像的假样本. 经过30个批次后, 图像的主要特征变得突出. 遍历50个批次后, 几乎能够生成表示真实图像特征的转换图像, 但存在模糊、码率低、波纹明显等问题;通过增加迭代次数尽可能消除上述现象, 经反复验证得出, 数据集被遍历100个批次时视觉效果更好, 图像质量几乎接近真实图像的红外图像, 且 $ {L_{{\text{identity}}}} $ 表4 所示.
从表4 可以看出, 当固定权重 $ \alpha $ $ \alpha $ $ \alpha $ $ \alpha = 30 $ $\; \beta {\text{ = }}0.5 $
为了验证将图像转换机制作为异源匹配预处理方法的可行性, 引入峰值信噪比(peak signal to noise ratio, PSNR)、结构相似性(smart sensors and integrated microsystem, SSIM)、归一化均方根误差(normalization root mean square error, NRMSE)以及信息熵(information entropy, IE) 4种图像质量评价指标, 对模型性能进行客观、全面的分析. 由于测试集3组图像是来自同一采集设备、同一时间的不同场景下的数据, 在温度、光照、视角等方面均相差不大, 且考虑篇幅限制, 仅选取场景1参与数值分析, 其他2组的分析思路与场景1一致. 如表9 所示分别为3种模型(原始图像、CycleGAN转换网络模型及添加L identity 项的CycleGAN)下场景1对应的数值对比结果.
从表9 可知, 原始可见光和红外图像在结构、细节信息方面差异较大, 相似性程度低, 影响最终的匹配效果. 通过CycleGAN模型转换后的生成图像结构更趋于原始红外图像, 且色彩变换和失真程度低, 鲁棒性方面表现良好. 与其他2种模型相比, CycleGAN+ $ {L_{{\text{identity}}}} $ $ {L_{{\text{identity}}}} $
[3]
XIONG Z, ZHANG Y A critical review of image registration methods
[J]. International Journal of Image and Data Fusion , 2010 , 1 (2 ): 137 - 158
DOI:10.1080/19479831003802790
[本文引用: 1]
[4]
SHI W, SU F, WANG R, et al. A visual circle based image registration algorithm for optical and SAR imagery [C]// IEEE International Geoscience and Remote Sensing Symposium . Munich: IEEE, 2012: 2109-2112.
[本文引用: 1]
[5]
SURI S, REINARTZ P Mutual-information-based registration of terraSAR-X and ikonos imagery in urban areas
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2010 , 48 (2 ): 939 - 949
DOI:10.1109/TGRS.2009.2034842
[本文引用: 1]
[6]
HASAN M, PICKERING M R, JIA X Robust automatic registration of multimodal satellite images using CCRE with partial volume interpolation
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2012 , 50 (10 ): 4050 - 4061
DOI:10.1109/TGRS.2012.2187456
[本文引用: 1]
[9]
REN S Q, HE K M, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[10]
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[11]
胡惠雅, 盖绍彦, 达飞鹏 基于生成对抗网络的偏转人脸转正
[J]. 浙江大学学报: 工学版 , 2021 , 55 (1 ): 116 - 123
URL
[本文引用: 1]
HU Hui-ya, GAI Shao-yan, DA Fei-peng Face frontalization based on generative adversarial network
[J]. Journal of Zhejiang University: Engineering Science , 2021 , 55 (1 ): 116 - 123
URL
[本文引用: 1]
[12]
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks
[J]. Communications of the ACM , 2020 , 63 (11 ): 139 - 144
DOI:10.1145/3422622
[本文引用: 1]
[13]
DENTON E L, CHINTALA S, SZLAM A, et al Deep generative image models using a laplacian pyramid of adversarial networks
[J]. Computer Vision and Pattern Recognition , 2015 , 6 (1 ): 1486 - 1494
[本文引用: 1]
[14]
ZHU J Y, PHILIPP K, SHECHTMAN E, et al. Generative visual manipulation on the natural image manifold [C]// European Conference on Computer Vision . Cham: Springer, 2016: 597-613.
[本文引用: 1]
[15]
LI C, WAND M. Precomputed real-time texture synthesis with markovian generative adversarial networks [C]// European Conference on Computer Vision . Cham: Springer, 2016: 702-716.
[本文引用: 1]
[16]
唐贤伦, 杜一铭, 刘雨微, 等 基于条件深度卷积生成对抗网络的图像识别方法
[J]. 自动化学报 , 2018 , 44 (5 ): 855 - 864
URL
[本文引用: 1]
TANG Xian-lun, DU Yi-ming, LIU Yu-wei, et al Image recognition with conditional deep convolutional generative adversarial networks
[J]. Acta Automatica Sinica , 2018 , 44 (5 ): 855 - 864
URL
[本文引用: 1]
[17]
RADFORD A, METZ L, CHINTALA S, et al. Unsupervised representation learning with deep convolutional generative adversarial networks [C]// International Conference of Legal Regulators . Washington: [s. n.], 2016: 1-16.
[本文引用: 1]
[18]
ARJOVSKY M, CHINTALA S, BOTTOU L, et al. Wasserstein generative adversarial networks [C]// International Conference on Machine Learning . Sydney: [s. n. ], 2017: 214-223.
[本文引用: 1]
[19]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223-2232.
[本文引用: 1]
[20]
HUANG X, LIU M Y, BELONGIE S, et al. Multimodal unsupervised image-to-image translation [C]// European Conference on Computer Vision . Cham: Springer, 2018: 172-189.
[本文引用: 1]
[21]
LEE H Y, TSENG H Y, HUANG J B, et al. Diverse image-to-image translation via disentangled representations [C]// European Conference on Computer Vision . Cham: Springer, 2018: 35-51.
[本文引用: 1]
[22]
CHANG H Y, WANG Z, CHUANG Y Y. Domain-specific mappings for generative adversarial style transfer [C]// European Conference on Computer Vision . Cham: Springer, 2020: 573-589.
[本文引用: 1]
[23]
SONG L, ZHANG M, WU X, et al. Adversarial discriminative heterogeneous face recognition [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence . New Orleans: AAAI, 2018: 7355-7362.
[本文引用: 1]
[24]
MERKLE N, AUER S, MULLER R, et al Exploring the potential of conditional adversarial networks for optical and SAR image matching
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2018 , 11 (6 ): 1811 - 1820
DOI:10.1109/JSTARS.2018.2803212
[本文引用: 1]
[26]
DAVIS J W, SHARMA V Background-subtraction using contour-based fusion of thermal and visible imagery
[J]. Computer Vision and Image Understanding , 2007 , 106 (2/3 ): 162 - 182
[本文引用: 1]
A survey of image registration techniques
1
1992
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
Image registration methods: a survey
1
2003
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
A critical review of image registration methods
1
2010
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
1
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
Mutual-information-based registration of terraSAR-X and ikonos imagery in urban areas
1
2010
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
Robust automatic registration of multimodal satellite images using CCRE with partial volume interpolation
1
2012
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
基于图像混合特征的城市绿地遥感图像配准
1
2019
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
基于图像混合特征的城市绿地遥感图像配准
1
2019
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
多摄像机间基于最稳定极值区域的人体跟踪方法
1
2010
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
多摄像机间基于最稳定极值区域的人体跟踪方法
1
2010
... 现有匹配方法分为基于强度和基于特征两大类. 基于强度的方法是利用图像间的相似性度量信息实现匹配, 如归一化互相关(normalized cross correlation, NCC)[1 ] 、互信息(mutual information, MI)[2 ] 或交叉累积剩余熵(cross-cumulative residual entropy, CCRE)[3 ] 等; 基于特征的匹配方法通过提取图像的点[4 ] 、线[5 ] 、面[6 ] 等局部特征实现匹配, 如Harris算法、尺度不变特征变换(scale-invariant feature transform, SIFT)[7 ] 、最大稳定极值区域(maximally stable extremal regions, MSER)[8 ] 等. 以可见光和红外图像为例, 二者存在较大差异,导致匹配难度加大. 一方面是不同成像机理导致图像之间存在差异;另一方面是多模传感器的引入,使得区域图像特征更复杂. 传统的同源图像匹配方法难以直接应用于异源图像. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
基于生成对抗网络的偏转人脸转正
1
2021
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
基于生成对抗网络的偏转人脸转正
1
2021
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
Generative adversarial networks
1
2020
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
Deep generative image models using a laplacian pyramid of adversarial networks
1
2015
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
基于条件深度卷积生成对抗网络的图像识别方法
1
2018
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
基于条件深度卷积生成对抗网络的图像识别方法
1
2018
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
1
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
Exploring the potential of conditional adversarial networks for optical and SAR image matching
1
2018
... 近年来, 大量网络模型应用于图像处理领域[9 -11 ] , Goodfellow等[12 ] 提出生成对抗网络(generative adversarial network, GAN)模型在图像生成[13 ] 、图像编辑[14 ] 、风格转换[15 ] 、照片增强[16 ] 等视觉图像方面发挥重要作用, 大量改进网络不断涌现, 如DCGAN[17 ] 、WGAN[18 ] 、CycleGAN[19 ] 等. 针对模式相差较大的转换任务, 研究者们提出MUNIT[20 ] 、DRIT[21 ] 、DSMAP[22 ] 等多种图像翻译框架. Song等[23 ] 开展近红外-可见光的人脸图像生成与识别工作, 改善了现有方法对于不同模式间差距较大的问题. Merkle等[24 ] 实现了光学与SAR图像的风格转换, 体现了生成对抗网络应用于图像匹配的可行性与实用性. ...
基于生成对抗网络的短波红外-可见光人脸图像翻译
1
2020
... 考虑成对的异源图像获取相对困难, 根据GAN网络的核心思想, 利用循环一致性对抗网络(cycle-consistent generative adversarial networks, CycleGAN)[25 ] 不需要成对数据就可以训练、具有较强通用性、性能良好的优势, 完成异源匹配前的图像转换工作. CycleGAN是用2个对称的GAN构成环形网路, 即由2个生成器和2个判别器构成. 以可见光-红外图像的转换问题为例, 将可见光图像和红外图像分别定义为源域 $ V $ $ I $ $ {G_{{\text{VI}}}} $ $ {F_{{\text{IV}}}} $ ${D_{{V}}}$ ${D_{{I}}}$ 图1 所示. 图中,v V 域的图像,i I 域的图像. 通过训练模型的2个映射: $ {G_{{\text{VI}}}} $ $ V \to I $ $ {F_{{\text{IV}}}} $ $ I \to V $ ${G_{{\text{VI}}}}(V)$ $ I $ $ {G_{{\text{VI}}}} $ $ {F_{{\text{IV}}}} $
基于生成对抗网络的短波红外-可见光人脸图像翻译
1
2020
... 考虑成对的异源图像获取相对困难, 根据GAN网络的核心思想, 利用循环一致性对抗网络(cycle-consistent generative adversarial networks, CycleGAN)[25 ] 不需要成对数据就可以训练、具有较强通用性、性能良好的优势, 完成异源匹配前的图像转换工作. CycleGAN是用2个对称的GAN构成环形网路, 即由2个生成器和2个判别器构成. 以可见光-红外图像的转换问题为例, 将可见光图像和红外图像分别定义为源域 $ V $ $ I $ $ {G_{{\text{VI}}}} $ $ {F_{{\text{IV}}}} $ ${D_{{V}}}$ ${D_{{I}}}$ 图1 所示. 图中,v V 域的图像,i I 域的图像. 通过训练模型的2个映射: $ {G_{{\text{VI}}}} $ $ V \to I $ $ {F_{{\text{IV}}}} $ $ I \to V $ ${G_{{\text{VI}}}}(V)$ $ I $ $ {G_{{\text{VI}}}} $ $ {F_{{\text{IV}}}} $
Background-subtraction using contour-based fusion of thermal and visible imagery
1
2007
... 讨论不同场景作用于模型的训练结果, 为了获得最佳转换效果, 对网络模型进行优化处理, 并反复训练模型. 考虑图像转换的多样性问题, 选用网上公开的OTCBVS数据集[26 ] 中Dataset 3: OSUColor and Thermal Database数据库进行实验, 包含2组场景下的可见光图像A和红外图像B, 共计17 089张图像, 大小均为 $ 320 \times 240 $ $ 256 \times 256 $ 图6 所示为随机选取的2组不同场景下可见光、红外图像数据集中的几组样本. 实验模型训练过程的参数设置与3.1节保持一致, 最多迭代100个批次. 如图7 所示为训练模型分别作用于场景1和场景2时对应的损失曲线图. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}