[1]
牛玉磊, 张含望 视觉问答与对话综述
[J]. 计算机科学 , 2021 , 48 (3 ): 10
URL
[本文引用: 1]
NIU Yu-lei, ZHANG Han-wang Visual question answering and dialogue summary
[J]. Computer Science , 2021 , 48 (3 ): 10
URL
[本文引用: 1]
[2]
REN M, KIROS R, ZEMEL R. Exploring models and data for image question answering [C]// Advances in Neural Information Processing Systems . Montreal: [s. n.], 2015: 2953–2961.
[本文引用: 1]
[3]
ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6077-6086.
[本文引用: 1]
[4]
CHEN F, MENG F, XU J, et al. Dmrm: a dual-channel multi-hop reasoning model for visual dialog [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020, 34(5): 7504-7511.
[本文引用: 1]
[5]
YU Z, YU J, CUI Y, et al. Deep modular co-attention networks for visual question answering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 6281-6290.
[本文引用: 1]
[6]
ZHU Z, YU J, WANG Y, et al. Mucko: multi-layer cross-modal knowledge reasoning for fact-based visual question answering [EB/OL]. (2020-11-04)[2021-03-19]. https://arxiv.org/abs/2006.09073.
[本文引用: 1]
[7]
JOHNSON J, HARIHARAN B, VAN DER MAATEN L, et al. Inferring and executing programs for visual reasoning [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2989-2998.
[本文引用: 1]
[8]
邱真娜, 张丽红, 陶云松 基于物体检测及关系推理的视觉问答方法研究
[J]. 测试技术学报 , 2020 , 34 (5 ): 8
URL
[本文引用: 1]
QIU Zhen-na, ZHANG Li-hong, TAO Yun-song Research on visual question answering method based on object detection and relational reasoning
[J]. Journal of Testing Technology , 2020 , 34 (5 ): 8
URL
[本文引用: 1]
[9]
SANTORO A, RAPOSO D, BARRETT D G T, et al. A simple neural network module for relational reasoning [EB/OL]. (2017-06-05)[2021-03-19]. https://arxiv.org/abs/1706.01427.
[本文引用: 1]
[10]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[11]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 39 (6 ): 1137 - 1149
[本文引用: 1]
[12]
TENEY D, ANDERSON P, HE X, et al. Tips and tricks for visual question answering: learnings from the 2017 challenge [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4223-4232.
[本文引用: 3]
[13]
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014: 1532-1543.
[本文引用: 1]
[15]
PIRSIAVASH H, RAMANAN D, FOWLKES C C. Bilinear classifiers for visual recognition [C]// Advances in Neural Information Processing Systems . Denver, USA: Curran Associates, 2009: 3.
[本文引用: 1]
[16]
PEI H, CHEN Q, WANG J, et al. Visual relational reasoning for image caption [C]// 2020 International Joint Conference on Neural Networks. Glasgow, UK: IEEE, 2020: 1-8.
[本文引用: 1]
[17]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// European Conference on Computer Vision. Cham: Springer, 2014: 740-755.
[本文引用: 1]
[18]
ANTOL S, AGRAWAL A, LU J, et al. Vqa: visual question answering [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 2425-2433.
[本文引用: 1]
[19]
MA C, SHEN C, DICK A, et al. Visual question answering with memory-augmented networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6975-6984.
[本文引用: 2]
[20]
NAM H, HA J W, KIM J. Dual attention networks for multimodal reasoning and matching [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 299-307.
[本文引用: 1]
[21]
YU Z, YU J, FAN J, et al. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 1821-1830.
[本文引用: 1]
[22]
YU Z, YU J, XIANG C, et al Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2018 , 29 (12 ): 5947 - 5959
DOI:10.1109/TNNLS.2018.2817340
[本文引用: 1]
[23]
NGUYEN D K, OKATANI T. Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6087-6096.
[本文引用: 4]
[24]
GOYAL Y, KHOT T, SUMMER-STAY D, et al. Making the v in vqa matter: elevating the role of image understanding in visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6904-6913.
[本文引用: 2]
[25]
CADENE R, BEN-YOUNES H, CORD M, et al. Murel: multimodal relational reasoning for visual question answering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1989-1998.
[本文引用: 2]
[26]
GAO P, JIANG Z, YOU H, et al. Dynamic fusion with intra-and inter-modality attention flow for visual question answering[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 6639-6648.
[本文引用: 2]
[27]
YANG X, LIN G, LV G, et al. TRRNet: tiered relation reasoning for compositional visual question answering[C]// The European Conference on Computer Vision. Glasgow: Springer, 2020: 414-430.
[本文引用: 2]
视觉问答与对话综述
1
2021
... 近年来,运用最广泛的注意力机制能够从多模态的输入中提取有效的信息,使其成为视觉问答领域的主流技术之一[1 ] . 视觉问答的相关研究主要基于CNN-RNN技术框架[2 ] ,使用“编码器-解码器(encoder-decoder)”的结构输出预测答案. Anderson等[3 ] 提出结合自上向下与自下向上注意力机制,用于视觉问答领域. 自下向上注意力机制检测视觉区域,以突出显著对象;自上向下注意力机制用于计算所有显著对象的注意映射,对重要的视觉区域分配较大的权重. 这些与问题相关的视觉区域可以得到更多的关注. Chen等[4 ] 提出双通道多跳注意力模型用于视觉对话领域,在模型中多次回溯关注与问题相关的视觉特征,解决了只利用编码端输出多模态信息融合的局限性. Yu等[5 ] 设计深度模块化注意网络,该网络能够将问题的关键词与图像的关键区域相关联,提升对图像及问题的细粒度理解. ...
视觉问答与对话综述
1
2021
... 近年来,运用最广泛的注意力机制能够从多模态的输入中提取有效的信息,使其成为视觉问答领域的主流技术之一[1 ] . 视觉问答的相关研究主要基于CNN-RNN技术框架[2 ] ,使用“编码器-解码器(encoder-decoder)”的结构输出预测答案. Anderson等[3 ] 提出结合自上向下与自下向上注意力机制,用于视觉问答领域. 自下向上注意力机制检测视觉区域,以突出显著对象;自上向下注意力机制用于计算所有显著对象的注意映射,对重要的视觉区域分配较大的权重. 这些与问题相关的视觉区域可以得到更多的关注. Chen等[4 ] 提出双通道多跳注意力模型用于视觉对话领域,在模型中多次回溯关注与问题相关的视觉特征,解决了只利用编码端输出多模态信息融合的局限性. Yu等[5 ] 设计深度模块化注意网络,该网络能够将问题的关键词与图像的关键区域相关联,提升对图像及问题的细粒度理解. ...
1
... 近年来,运用最广泛的注意力机制能够从多模态的输入中提取有效的信息,使其成为视觉问答领域的主流技术之一[1 ] . 视觉问答的相关研究主要基于CNN-RNN技术框架[2 ] ,使用“编码器-解码器(encoder-decoder)”的结构输出预测答案. Anderson等[3 ] 提出结合自上向下与自下向上注意力机制,用于视觉问答领域. 自下向上注意力机制检测视觉区域,以突出显著对象;自上向下注意力机制用于计算所有显著对象的注意映射,对重要的视觉区域分配较大的权重. 这些与问题相关的视觉区域可以得到更多的关注. Chen等[4 ] 提出双通道多跳注意力模型用于视觉对话领域,在模型中多次回溯关注与问题相关的视觉特征,解决了只利用编码端输出多模态信息融合的局限性. Yu等[5 ] 设计深度模块化注意网络,该网络能够将问题的关键词与图像的关键区域相关联,提升对图像及问题的细粒度理解. ...
1
... 近年来,运用最广泛的注意力机制能够从多模态的输入中提取有效的信息,使其成为视觉问答领域的主流技术之一[1 ] . 视觉问答的相关研究主要基于CNN-RNN技术框架[2 ] ,使用“编码器-解码器(encoder-decoder)”的结构输出预测答案. Anderson等[3 ] 提出结合自上向下与自下向上注意力机制,用于视觉问答领域. 自下向上注意力机制检测视觉区域,以突出显著对象;自上向下注意力机制用于计算所有显著对象的注意映射,对重要的视觉区域分配较大的权重. 这些与问题相关的视觉区域可以得到更多的关注. Chen等[4 ] 提出双通道多跳注意力模型用于视觉对话领域,在模型中多次回溯关注与问题相关的视觉特征,解决了只利用编码端输出多模态信息融合的局限性. Yu等[5 ] 设计深度模块化注意网络,该网络能够将问题的关键词与图像的关键区域相关联,提升对图像及问题的细粒度理解. ...
1
... 近年来,运用最广泛的注意力机制能够从多模态的输入中提取有效的信息,使其成为视觉问答领域的主流技术之一[1 ] . 视觉问答的相关研究主要基于CNN-RNN技术框架[2 ] ,使用“编码器-解码器(encoder-decoder)”的结构输出预测答案. Anderson等[3 ] 提出结合自上向下与自下向上注意力机制,用于视觉问答领域. 自下向上注意力机制检测视觉区域,以突出显著对象;自上向下注意力机制用于计算所有显著对象的注意映射,对重要的视觉区域分配较大的权重. 这些与问题相关的视觉区域可以得到更多的关注. Chen等[4 ] 提出双通道多跳注意力模型用于视觉对话领域,在模型中多次回溯关注与问题相关的视觉特征,解决了只利用编码端输出多模态信息融合的局限性. Yu等[5 ] 设计深度模块化注意网络,该网络能够将问题的关键词与图像的关键区域相关联,提升对图像及问题的细粒度理解. ...
1
... 近年来,运用最广泛的注意力机制能够从多模态的输入中提取有效的信息,使其成为视觉问答领域的主流技术之一[1 ] . 视觉问答的相关研究主要基于CNN-RNN技术框架[2 ] ,使用“编码器-解码器(encoder-decoder)”的结构输出预测答案. Anderson等[3 ] 提出结合自上向下与自下向上注意力机制,用于视觉问答领域. 自下向上注意力机制检测视觉区域,以突出显著对象;自上向下注意力机制用于计算所有显著对象的注意映射,对重要的视觉区域分配较大的权重. 这些与问题相关的视觉区域可以得到更多的关注. Chen等[4 ] 提出双通道多跳注意力模型用于视觉对话领域,在模型中多次回溯关注与问题相关的视觉特征,解决了只利用编码端输出多模态信息融合的局限性. Yu等[5 ] 设计深度模块化注意网络,该网络能够将问题的关键词与图像的关键区域相关联,提升对图像及问题的细粒度理解. ...
1
... 研究人员除注意力机制方法外,还探索了众多方法,取得了一定的研究成果. Zhu等[6 ] 通过加入外部知识库帮助模型理解图像内容,但这些工作严重依赖于作为监督信息的知识事实. Johnson等[7 ] 提出将视觉关系推理运用到视觉问答工作中,提出由程序生成器构成的框架,可以显式地表示推理过程. 该方法的不足是需要额外的监督数据,训练时面临着运算量过高和训练时间过长的问题. 邱真娜等[8 ] 提出利用上下游网络分别进行物体检测与特征推理的神经网络模型,利用极快速区域卷积神经网络提取特征在下游网络加以推理. Santoro等[9 ] 提出关系推理网络(RN),该模型的思想是通过约束神经网络的形式来捕捉对象之间的关系. 上述研究针对视觉问答领域,从多个方向进行改进,但均忽略了视觉区域之间的空间信息. ...
1
... 研究人员除注意力机制方法外,还探索了众多方法,取得了一定的研究成果. Zhu等[6 ] 通过加入外部知识库帮助模型理解图像内容,但这些工作严重依赖于作为监督信息的知识事实. Johnson等[7 ] 提出将视觉关系推理运用到视觉问答工作中,提出由程序生成器构成的框架,可以显式地表示推理过程. 该方法的不足是需要额外的监督数据,训练时面临着运算量过高和训练时间过长的问题. 邱真娜等[8 ] 提出利用上下游网络分别进行物体检测与特征推理的神经网络模型,利用极快速区域卷积神经网络提取特征在下游网络加以推理. Santoro等[9 ] 提出关系推理网络(RN),该模型的思想是通过约束神经网络的形式来捕捉对象之间的关系. 上述研究针对视觉问答领域,从多个方向进行改进,但均忽略了视觉区域之间的空间信息. ...
基于物体检测及关系推理的视觉问答方法研究
1
2020
... 研究人员除注意力机制方法外,还探索了众多方法,取得了一定的研究成果. Zhu等[6 ] 通过加入外部知识库帮助模型理解图像内容,但这些工作严重依赖于作为监督信息的知识事实. Johnson等[7 ] 提出将视觉关系推理运用到视觉问答工作中,提出由程序生成器构成的框架,可以显式地表示推理过程. 该方法的不足是需要额外的监督数据,训练时面临着运算量过高和训练时间过长的问题. 邱真娜等[8 ] 提出利用上下游网络分别进行物体检测与特征推理的神经网络模型,利用极快速区域卷积神经网络提取特征在下游网络加以推理. Santoro等[9 ] 提出关系推理网络(RN),该模型的思想是通过约束神经网络的形式来捕捉对象之间的关系. 上述研究针对视觉问答领域,从多个方向进行改进,但均忽略了视觉区域之间的空间信息. ...
基于物体检测及关系推理的视觉问答方法研究
1
2020
... 研究人员除注意力机制方法外,还探索了众多方法,取得了一定的研究成果. Zhu等[6 ] 通过加入外部知识库帮助模型理解图像内容,但这些工作严重依赖于作为监督信息的知识事实. Johnson等[7 ] 提出将视觉关系推理运用到视觉问答工作中,提出由程序生成器构成的框架,可以显式地表示推理过程. 该方法的不足是需要额外的监督数据,训练时面临着运算量过高和训练时间过长的问题. 邱真娜等[8 ] 提出利用上下游网络分别进行物体检测与特征推理的神经网络模型,利用极快速区域卷积神经网络提取特征在下游网络加以推理. Santoro等[9 ] 提出关系推理网络(RN),该模型的思想是通过约束神经网络的形式来捕捉对象之间的关系. 上述研究针对视觉问答领域,从多个方向进行改进,但均忽略了视觉区域之间的空间信息. ...
1
... 研究人员除注意力机制方法外,还探索了众多方法,取得了一定的研究成果. Zhu等[6 ] 通过加入外部知识库帮助模型理解图像内容,但这些工作严重依赖于作为监督信息的知识事实. Johnson等[7 ] 提出将视觉关系推理运用到视觉问答工作中,提出由程序生成器构成的框架,可以显式地表示推理过程. 该方法的不足是需要额外的监督数据,训练时面临着运算量过高和训练时间过长的问题. 邱真娜等[8 ] 提出利用上下游网络分别进行物体检测与特征推理的神经网络模型,利用极快速区域卷积神经网络提取特征在下游网络加以推理. Santoro等[9 ] 提出关系推理网络(RN),该模型的思想是通过约束神经网络的形式来捕捉对象之间的关系. 上述研究针对视觉问答领域,从多个方向进行改进,但均忽略了视觉区域之间的空间信息. ...
1
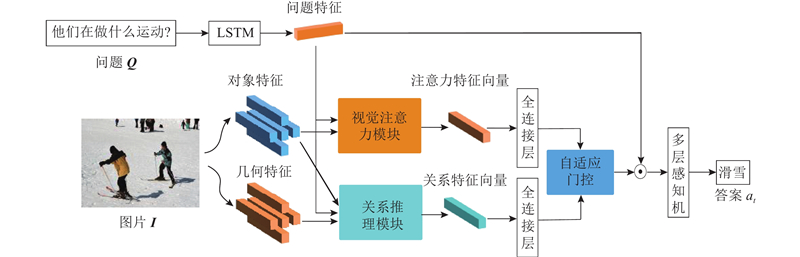
... 将ResNet-101[10 ] 作为基础网络,使用对象检测器(Faster R-CNN[11 ] )检测图像中的物体,以提取输入图像中显著区域的视觉特征. 采用Faster R-CNN以获得对象检测区域,对每个对象区域执行非极大抑制并选择最相关的K 个候选区域(一般为K = 36). 对于每个候选区域i ,v i d v 维的视觉对象向量,则输入的图像表示为V v 1 , v 2 , ···, v K T ,其中 ${\boldsymbol{v}}_{i}\in {\bf{R}}^{{{d}}_{\mathrm{v}}}$ . 此外,会获取到输入图像的视觉几何特征B b 1 ,b 2 ,···,b K T ,其中 ${{\boldsymbol b}}_{i} = [ {{{x}}_{{i}}}/{{w}},{{{y}}_{{i}}}/{{h}}, $ $ {{{w}}_{{i}}}/{{w}},{{{h}}_{{i}}}/{{h}} ]$ x i y i w i h i i 的中心坐标、宽度与高度,w 、h 分别为输入图像的宽度与高度. 上述的视觉对象特征与视觉几何特征将会被输入到视觉注意力模块与关系推理模块. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2016
... 将ResNet-101[10 ] 作为基础网络,使用对象检测器(Faster R-CNN[11 ] )检测图像中的物体,以提取输入图像中显著区域的视觉特征. 采用Faster R-CNN以获得对象检测区域,对每个对象区域执行非极大抑制并选择最相关的K 个候选区域(一般为K = 36). 对于每个候选区域i ,v i d v 维的视觉对象向量,则输入的图像表示为V v 1 , v 2 , ···, v K T ,其中 ${\boldsymbol{v}}_{i}\in {\bf{R}}^{{{d}}_{\mathrm{v}}}$ . 此外,会获取到输入图像的视觉几何特征B b 1 ,b 2 ,···,b K T ,其中 ${{\boldsymbol b}}_{i} = [ {{{x}}_{{i}}}/{{w}},{{{y}}_{{i}}}/{{h}}, $ $ {{{w}}_{{i}}}/{{w}},{{{h}}_{{i}}}/{{h}} ]$ x i y i w i h i i 的中心坐标、宽度与高度,w 、h 分别为输入图像的宽度与高度. 上述的视觉对象特征与视觉几何特征将会被输入到视觉注意力模块与关系推理模块. ...
3
... 对于问题的嵌入,用空格与标点符号将句子分割为单词(数字或基于数字的单词被当作是一个单词). Teney等[12 ] 提出在VQA的数据集中,只有0.25% 的问题长度会超过14个单词,为了提高计算效率,将每个输入问题Q 修剪为最多14个单词,将超过14个单词的额外单词丢弃,不足14个单词的问题用0向量填补. 通过使用预训练的Glove模型[13 ] 进行词向量嵌入,将每个单词转换为300维的向量. 由此产生的单词嵌入序列大小为14×300,将单词嵌入序列依次通过隐藏层为d q 维的长短期记忆(LSTM)[14 ] 网络中,得到问题的特征向量 $\widetilde{\boldsymbol{Q}}\in {\bf{R}}^{{{d}}_{\mathrm{q}}}$ . ...
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 2.0 data set
Tab.3 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 LSTM+CNN[24 ] − − − − 54.22 41.83 35.18 73.46 MCB[24 ] − − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36
由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
... 由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
1
... 对于问题的嵌入,用空格与标点符号将句子分割为单词(数字或基于数字的单词被当作是一个单词). Teney等[12 ] 提出在VQA的数据集中,只有0.25% 的问题长度会超过14个单词,为了提高计算效率,将每个输入问题Q 修剪为最多14个单词,将超过14个单词的额外单词丢弃,不足14个单词的问题用0向量填补. 通过使用预训练的Glove模型[13 ] 进行词向量嵌入,将每个单词转换为300维的向量. 由此产生的单词嵌入序列大小为14×300,将单词嵌入序列依次通过隐藏层为d q 维的长短期记忆(LSTM)[14 ] 网络中,得到问题的特征向量 $\widetilde{\boldsymbol{Q}}\in {\bf{R}}^{{{d}}_{\mathrm{q}}}$ . ...
Long short-term memory
1
1997
... 对于问题的嵌入,用空格与标点符号将句子分割为单词(数字或基于数字的单词被当作是一个单词). Teney等[12 ] 提出在VQA的数据集中,只有0.25% 的问题长度会超过14个单词,为了提高计算效率,将每个输入问题Q 修剪为最多14个单词,将超过14个单词的额外单词丢弃,不足14个单词的问题用0向量填补. 通过使用预训练的Glove模型[13 ] 进行词向量嵌入,将每个单词转换为300维的向量. 由此产生的单词嵌入序列大小为14×300,将单词嵌入序列依次通过隐藏层为d q 维的长短期记忆(LSTM)[14 ] 网络中,得到问题的特征向量 $\widetilde{\boldsymbol{Q}}\in {\bf{R}}^{{{d}}_{\mathrm{q}}}$ . ...
1
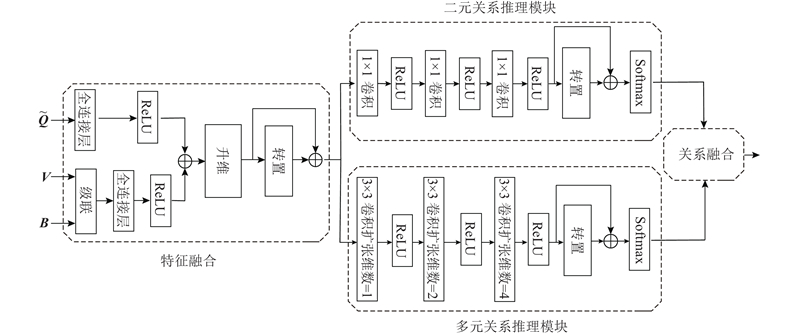
... 该模型采用低秩双线性模型[15 ] 来降低双线性模型参数的数量,通过将W i H i G i T ,降低计算的复杂程度,其中 ${\boldsymbol{H}}_{{i}}\in {\bf{R}}^{{{d}}_{\mathrm{v}}\times {d}}$ ${\boldsymbol{G}}_{{i}}\in {\bf{R}}^{{{d}}_{\mathrm{q}}\times {d}}$
1
... 视觉图像主要包含2种信息:视觉对象的信息及对象间的关系信息. 当对一个问题给出回答时,要求模型能够根据问题的需要检索视觉区域的信息或区域间的关系信息,或同时检索二者. 受门控机制应用[16 ] 的启发,引入自适应门控机制,动态地控制2种信息对预测答案的贡献. 该模块的输入是视觉注意力特征V at 与视觉关系特征V rl ,为了能够自适应地对2种不同特征进行筛选,将2种特征映射到同一空间中,获得自适应选择门控gate c ,如下所示: ...
1
... 在视觉问答领域的2个主流数据集(VQA 1.0与VQA 2.0数据集)上进行实验. 对于这2个数据集,样本均被分为训练集、验证集和测试集. VQA 1.0是基于MSCOCO图像数据集[17 ] 建立的,数据集中的训练集包含248 349个问题与82 783张图片,验证集包含121 512个问题与40 504个图片,测试集包含244 302个问题与81 434个图片. 问题的类型主要包含3种:Yes/No、number及other. VQA 2.0是VQA 1.0 的更新版本,相比于 VQA 1.0增加了更多的问题样本,使语言偏置方面变得更加平衡,问题类型变得更加广泛. 对于视觉问答的测试集,一般被分为4个部分:测试开发集、测试标准集、测试挑战集和测试保留集. 在VQA 2.0验证集上报告消融实验的实验结果;分别在VQA 1.0与VQA 2.0的测试开发集(test-dev)与测试标准集(test-standard)上,报告模型总体性能实验的结果. ...
1
... 对于VQA 1.0和VQA 2.0数据集,选择在训练集中出现超过9次的答案作为候选答案集,所以在VQA 1.0中产生了包含2 185个候选答案的答案集,在VQA 2.0中产生了3 129个候选答案. 本文的VQA模型分别被视为对2 185个标签及3 129个标签进行筛选的分类器. 对于开放式任务,遵循Antol等[18 ] 的工作,使用投票机制对预测答案的准确率进行打分,如下所示: ...
2
... 如表2 所示为提出的模型在VQA 1.0的测试-开发集与测试-标准集上的性能对比. 可以看出,提出的模型在大部分指标上优于目前较先进的方法. 其中,在测试-标准集上相比于DCN[23 ] 的总体精度提升了1.41%,相比于MAN[19 ] 提升了4.44%. 从表2 的第1、2行结果表明,视觉问答系统中基于关系推理与门控机制的效果优于基于文本注意力与记忆机制的效果,后者加强了对图像对象与文本内容的关注,而本文模型在关注图像内容的同时,加入了关系信息是预测精度提升的重要原因. 从表2 的第2~4行可以看出,目前较流行的双线性池化方法及变体虽然能够高效地学习特定阶数的组合特征,但在忽略关系信息的前提下性能尚有明显不足,验证了关系推理与门控机制的重要影响. 提出的方法对于答案预测能力的提升,在测试-标准集上有同样的表现. ...
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 1.0 data set
Tab.2 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 MAN[19 ] 63.80 54.00 39.00 81.50 64.10 54.70 37.60 81.70 DAN[20 ] 64.30 53.90 39.10 83.00 64.20 54.00 38.10 82.80 MFB[21 ] 65.90 56.20 39.80 84.00 65.80 56.30 38.90 83.80 MFH[22 ] 66.80 57.40 39.70 85.00 66.90 57.40 39.50 85.00 DCN[23 ] 66.83 57.44 41.66 84.48 66.66 56.83 41.27 84.61 提出模型 68.24 58.56 42.32 84.65 68.37 58.21 47.44 84.48
如表3 所示为提出的模型在VQA 2.0中的测试-开发集和测试-标准集上的性能. ...
1
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 1.0 data set
Tab.2 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 MAN[19 ] 63.80 54.00 39.00 81.50 64.10 54.70 37.60 81.70 DAN[20 ] 64.30 53.90 39.10 83.00 64.20 54.00 38.10 82.80 MFB[21 ] 65.90 56.20 39.80 84.00 65.80 56.30 38.90 83.80 MFH[22 ] 66.80 57.40 39.70 85.00 66.90 57.40 39.50 85.00 DCN[23 ] 66.83 57.44 41.66 84.48 66.66 56.83 41.27 84.61 提出模型 68.24 58.56 42.32 84.65 68.37 58.21 47.44 84.48
如表3 所示为提出的模型在VQA 2.0中的测试-开发集和测试-标准集上的性能. ...
1
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 1.0 data set
Tab.2 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 MAN[19 ] 63.80 54.00 39.00 81.50 64.10 54.70 37.60 81.70 DAN[20 ] 64.30 53.90 39.10 83.00 64.20 54.00 38.10 82.80 MFB[21 ] 65.90 56.20 39.80 84.00 65.80 56.30 38.90 83.80 MFH[22 ] 66.80 57.40 39.70 85.00 66.90 57.40 39.50 85.00 DCN[23 ] 66.83 57.44 41.66 84.48 66.66 56.83 41.27 84.61 提出模型 68.24 58.56 42.32 84.65 68.37 58.21 47.44 84.48
如表3 所示为提出的模型在VQA 2.0中的测试-开发集和测试-标准集上的性能. ...
Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering
1
2018
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 1.0 data set
Tab.2 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 MAN[19 ] 63.80 54.00 39.00 81.50 64.10 54.70 37.60 81.70 DAN[20 ] 64.30 53.90 39.10 83.00 64.20 54.00 38.10 82.80 MFB[21 ] 65.90 56.20 39.80 84.00 65.80 56.30 38.90 83.80 MFH[22 ] 66.80 57.40 39.70 85.00 66.90 57.40 39.50 85.00 DCN[23 ] 66.83 57.44 41.66 84.48 66.66 56.83 41.27 84.61 提出模型 68.24 58.56 42.32 84.65 68.37 58.21 47.44 84.48
如表3 所示为提出的模型在VQA 2.0中的测试-开发集和测试-标准集上的性能. ...
4
... 如表2 所示为提出的模型在VQA 1.0的测试-开发集与测试-标准集上的性能对比. 可以看出,提出的模型在大部分指标上优于目前较先进的方法. 其中,在测试-标准集上相比于DCN[23 ] 的总体精度提升了1.41%,相比于MAN[19 ] 提升了4.44%. 从表2 的第1、2行结果表明,视觉问答系统中基于关系推理与门控机制的效果优于基于文本注意力与记忆机制的效果,后者加强了对图像对象与文本内容的关注,而本文模型在关注图像内容的同时,加入了关系信息是预测精度提升的重要原因. 从表2 的第2~4行可以看出,目前较流行的双线性池化方法及变体虽然能够高效地学习特定阶数的组合特征,但在忽略关系信息的前提下性能尚有明显不足,验证了关系推理与门控机制的重要影响. 提出的方法对于答案预测能力的提升,在测试-标准集上有同样的表现. ...
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 1.0 data set
Tab.2 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 MAN[19 ] 63.80 54.00 39.00 81.50 64.10 54.70 37.60 81.70 DAN[20 ] 64.30 53.90 39.10 83.00 64.20 54.00 38.10 82.80 MFB[21 ] 65.90 56.20 39.80 84.00 65.80 56.30 38.90 83.80 MFH[22 ] 66.80 57.40 39.70 85.00 66.90 57.40 39.50 85.00 DCN[23 ] 66.83 57.44 41.66 84.48 66.66 56.83 41.27 84.61 提出模型 68.24 58.56 42.32 84.65 68.37 58.21 47.44 84.48
如表3 所示为提出的模型在VQA 2.0中的测试-开发集和测试-标准集上的性能. ...
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 2.0 data set
Tab.3 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 LSTM+CNN[24 ] − − − − 54.22 41.83 35.18 73.46 MCB[24 ] − − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36
由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
... 由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
2
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 2.0 data set
Tab.3 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 LSTM+CNN[24 ] − − − − 54.22 41.83 35.18 73.46 MCB[24 ] − − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36
由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
... [
24 ]
− − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36 由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
2
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 2.0 data set
Tab.3 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 LSTM+CNN[24 ] − − − − 54.22 41.83 35.18 73.46 MCB[24 ] − − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36
由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
... 由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
2
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 2.0 data set
Tab.3 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 LSTM+CNN[24 ] − − − − 54.22 41.83 35.18 73.46 MCB[24 ] − − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36
由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
... 由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
2
... Experimental results of visual question answering model based on relational reasoning and gating mechanism on VQA 2.0 data set
Tab.3 % 模型 测试-开发集 测试-标准集 总体 其他 数字 是/否 总体 其他 数字 是/否 LSTM+CNN[24 ] − − − − 54.22 41.83 35.18 73.46 MCB[24 ] − − − − 62.27 53.36 38.28 78.82 Adelaide[12 ] 65.32 56.05 44.21 81.82 65.67 56.26 43.90 82.20 DCN[23 ] 66.60 56.72 46.60 83.50 67.00 56.90 46.93 83.89 MuRel[25 ] [26 ] 68.03 57.85 49.84 84.77 68.41 − − − 70.22 60.49 53.32 86.09 70.34 − − − TRRNet[27 ] 70.80 61.02 51.89 87.27 71.20 − − − 提出模型 68.16 58.46 47.78 84.00 68.51 58.11 47.36 84.36
由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...
... 由表3 的对比实验可以得出,利用提出的关系推理模块与自适应门控机制能够提高答案预测的准确率. 表3 中的前2种方法均未采用自下向上的注意力机制,本文模型在各类问题的指标上明显高于这2种方法,因此可以认为软注意力机制的运用对模型的整体效果有着重要的影响. Adelaide模型[12 ] 是2017年VQA挑战赛的冠军,模型采用自下向上的注意力机制提取视觉特征. 可以看出,本文模型的性能明显优于Adelaide模型,是由于本文模型中的关系推理模块能够加强模型对视觉区域关系的理解,筛选区域间的关系信息,通过自适应门控机制动态选择与问题相关的特征,这与VQA 1.0数据集上的观察结果一致. DCN[23 ] 模型尽管没有采用自下向上的注意力机制,但通过使用密集双向交互的注意力机制在“数字”与“是/否”的问题上取得不错的成果,本文提出的模型相较于DCN模型具有明显的优势. 相比于MuRel[25 ] 模型,本文模型在测试-开发集总体精度上达到68.16%的准确率,在测试-标准集总体精度上达到68.51%的准确率,均高于采用残差特性学习端到端推理的MuRel模型. DFAF[26 ] 模型设计的模态内与模态间的信息流交互,使该模型在总体准确率上达到70.22%,该方法中核心单元的迭代与本文提出的逐步推理本质类似,不同之处在于该模型相比于本文更加注重文本模态内的内模特征,在结合模态间的信息流后可以更好地捕捉语言和视觉域之间的高层次交互. 本文方法相比于DFAF模型存在一定的优势:DFAF模型缺乏视觉模态内多特征间的交互,在某种程度上忽略了视觉区域间的多重关系;本文将多元关系特征加入视觉特征中,使得模型在多元的角度上更好地理解图像内容. TRRNet[27 ] 与本文均采用推理关系特征的方法加强模型对图像的理解能力. 本文在选取视觉特征时,考虑多个视觉特征对答案输出的影响,采用36个候选区域作为输入; TRRNet中的方法认为一个问题特征中包含的对象不应超过6个. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}