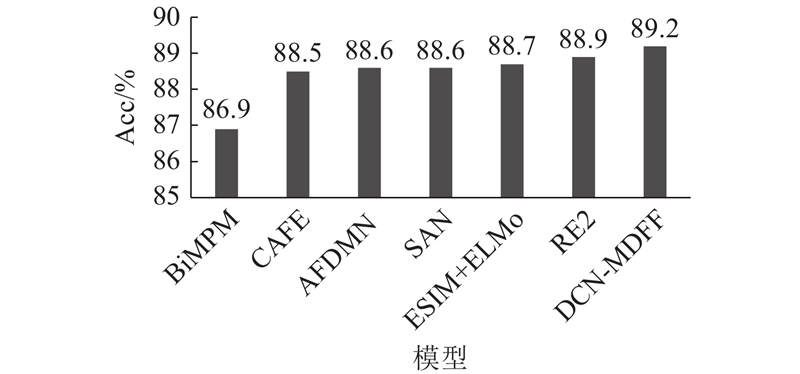
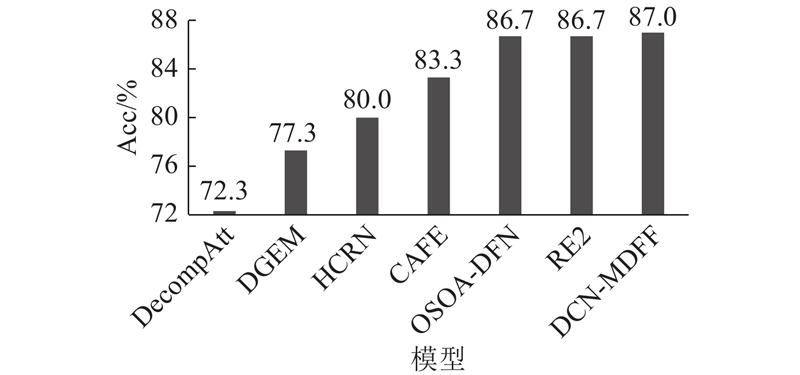
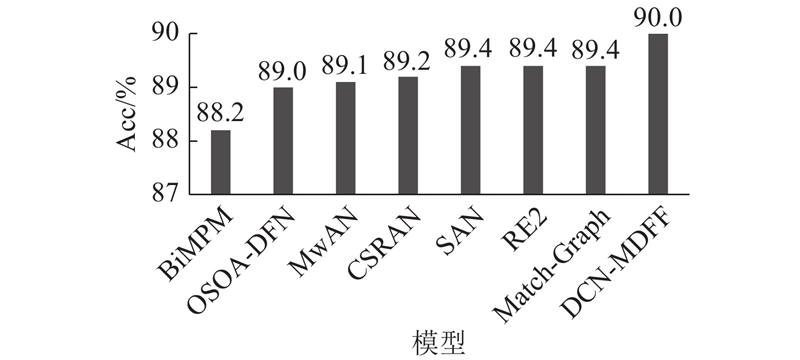
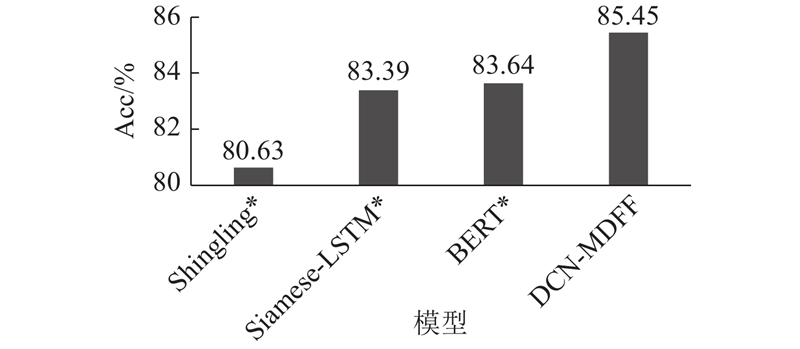
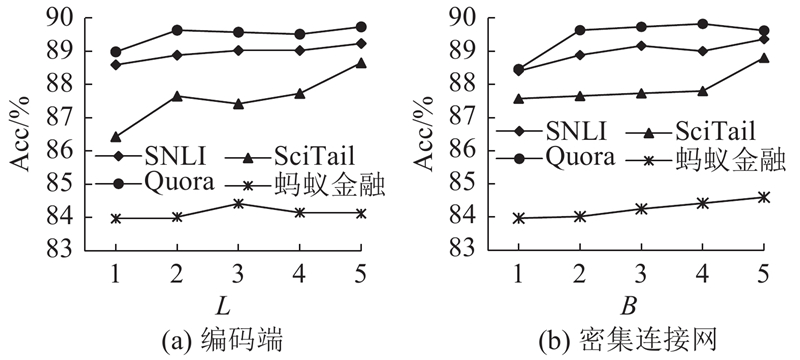
A text matching method was proposed based on the dense connection network and the multi-dimensional feature fusion, aiming at the problems of the semantic loss and insufficient information on the interaction for sentence pairs in the text matching process. The BiLSTM network was used to encode the sentence in order to obtain the semantic features of the sentence in the encoding end of the model. The word embedding feature at the bottom and the dense module feature at the top were connected by the dense connection network, and the semantic features of sentences were enriched. The similarity features, the difference features and the key features of sentence pairs were fused with multi-dimensional features based on the information interaction of word-level for attention mechanism, and large amounts of the semantic relationships between sentence pairs were captured by the model. The model evaluation was performed on four benchmark datasets. Compared with other strong benchmark models, the text matching accuracy of the proposed model was significantly improved by 0.3%, 0.3%, 0.6% and 1.81%, respectively. The validity verification experiment on the Quora dataset of paraphrase recognition showed that the proposed method had an accurate matching effect on the semantic similarity of sentences.
Keywords:semantic loss
;
information interaction
;
BiLSTM network
;
dense connection network
;
attention mechanism
;
multi-dimensional feature fusion
CHEN Yue-lin, TIAN Wen-jing, CAI Xiao-dong, ZHENG Shu-ting. Text matching model based on dense connection networkand multi-dimensional feature fusion. Journal of Zhejiang University(Engineering Science)[J], 2021, 55(12): 2352-2358 doi:10.3785/j.issn.1008-973X.2021.12.015
为了解决特征损失和句子对间交互不充分的问题,本研究提出基于密集连接网络和多维特征融合的文本匹配模型(text matching model based on dense connection network and multi-dimensional feature fusion, DCN-MDFF). 受DenseNet卷积网络的启发[15],提出密集连接网络,将多个密集网络模块特征输出和原始特征(词嵌入特征)融合,使最底层到最高层的特征紧密连接,丰富句子的语义特征. 采用基于注意力机制的多维特征融合方式,丰富句子对间的信息交互,使模型能捕获更多句子对间的语义关系.
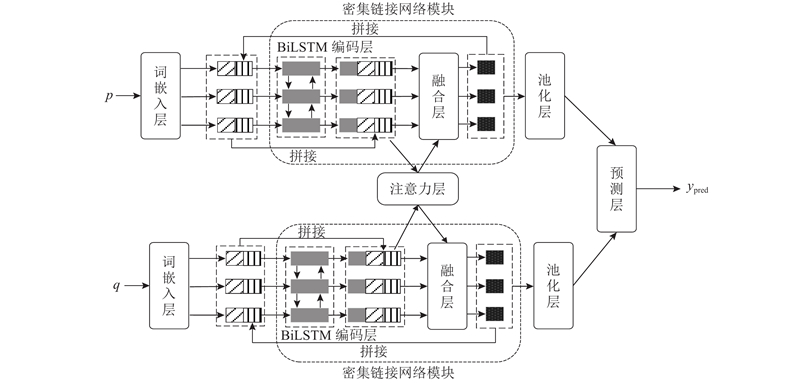
1. DCN-MDFF
如图1所示为DCN-MDFF的框架结构. 图中,p、q为文本输入序列,BiLSTM为双向的长短期记忆网络(Bi-directional long-short term memory)[16], $ {y}_{{\rm{pred}}} $为最终的预测输出. 2个文本序列在预测层之前会被以相同方式处理,该框架为孪生网络结构.
BOWMAN S R, ANGEL G, POTTS C, et al. A large annotated corpus for learning natural language inference [C]// 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: EMNLP, 2015: 632–642.
KHOT T, SABHARWAL A, CLARK P. SCITAIL: a textual entailment dataset from science question answering [C]// The Thirty-Second AAAI Conference on Artificial Intelligence. New Orleans: AAAI, 2018: 5189-5197.
WANG S, JING J. A compare-aggregate model for matching text sequences [C]// 5th International Conference on Learning Representations. Toulon: ICLR, 2017: 1-11.
YANG Y , YIH W T, MEEK C. WikiQA: a challenge dataset for open-domain question answering [C]// 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: EMNLP, 2015: 2013–2018.
RAO J, YANG W, ZHANG Y, et al. Multi-perspective relevance matching with hierarchical ConvNets for social media search [C]// . The 33rd AAAI Conference on Artificial Intelligence. Hawaii: AAAI, 2019: 232-240.
DUAN C Q, CUI L, CHEN X C, et al. Attention-fused deep matching network for natural language inference [C]// 2018 27th International Joint Conference on Artificial Intelligence. Stockholm: IJCAI, 2018: 4033–4040.
WANG Z G, HAMZA W, FLORIAN R. Bilateral multi-perspective matching for natural language sentences [C]// 2017 26th International Joint Conference on Artificial Intelligence. Melbourne: IJCAI, 2017: 4144-4150.
CONNEAU A, KIELA D, SCHWENK H, et al. Supervised learning of universal sentence representations from natural language inference data [C]// 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: EMNLP, 2017: 670-680.
NIE Y, BANSAL M. Shortcut-stacked sentence encoders for multi-domain inference [C]// 2017 2nd Workshop on Evaluating Vector Space Representations for NLP. Copenhagen: EMNLP, 2017: 41-45.
TAO S, ZHOU T, LONG G, et al. Reinforced self-attention network: a hybrid of hard and soft attention for sequence modeling [C]// 2018 27th International Joint Conference on Artificial Intelligence. Stockholm: IJCAI, 2018: 4345-4352.
WANG B, LIU K, ZHAO J. Inner attention based recurrent neural networks for answer selection [C]// 2016 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACL, 2016: 1288-1297.
TAY Y, LUU A, HUI S C. Hermitian co-attention networks for text matching in asymmetrical domains [C]// 2018 27th International Joint Conference on Artificial Intelligence. Stockholm: IJCAI, 2018: 4425–4431.
YANG R, ZHANG J, GAO X, et al. Simple and effective text matching with richer alignment features [C]// 2019 57th Conference of the Association for Computational Linguistics. Florence: ACL, 2019: 4699-4709.
HUANG G, LIU Z, MAATEN L V D, et al. Densely connected convolutional networks [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2261-2269.
PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation [C]// 2014 Conference on Empirical Methods in Natural Language Processing. Doha: EMNLP, 2014: 1532-1543.
PARIKH A P, TÄCKSTRÖM O, DAS D, et al. A decomposable attention model for natural language inference [C]// In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin: EMNLP, 2016: 2249–2255.
GAO Y, CHANG H J, DEMIRIS Y. Iterative path optimisation for personalised dressing assistance using vision and force information [C]// 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems. Daejeon: IEEE, 2016: 4398-4403.
PETERS M, NEUMANN M, IYYER M, et al. Deep contextualized word representations [C]// 2018 Conference of the North American Chapter of the Association for Computational Linguistics. [S.l.]: NAACL-HLT, 2018: 2227-2237.
YI T, LUU A T, HUI S C. Compare, compress and propagate: enhancing neural architectures with alignment factorization for natural language inference [C]// 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: EMNLP, 2018: 1565-1575.
LIU M , ZHANG Y , XU J , et al. Original semantics-oriented attention and deep fusion network for sentence matching [C]// 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: EMNLP-IJCNLP, 2019: 2652-2661.
TAY Y , TUAN L A , HUI S C. Co-stack residual affinity networks with multi-level attention refinement for matching text sequences [C]// 2018 Conference on Empirical Methods in Natural Language Processing, Brussels : EMMLP, 2018: 4492–4502.
CUI P , HU L , LIU Y . Inducing alignment structure with gated graph attention networks for sentence matching [EB/OL]. [2021-03-13]. https://arxiv.org/abs/2010.07668.
... 为了解决特征损失和句子对间交互不充分的问题,本研究提出基于密集连接网络和多维特征融合的文本匹配模型(text matching model based on dense connection network and multi-dimensional feature fusion, DCN-MDFF). 受DenseNet卷积网络的启发[15],提出密集连接网络,将多个密集网络模块特征输出和原始特征(词嵌入特征)融合,使最底层到最高层的特征紧密连接,丰富句子的语义特征. 采用基于注意力机制的多维特征融合方式,丰富句子对间的信息交互,使模型能捕获更多句子对间的语义关系. ...
LSTM recurrent networks learn simple context-free and context-sensitive languages



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}