[1]
TAO C, ZHANG J, WANG P. Smoke detection based on deep convolutional neural networks [C]// 2016 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration . Wuhan: IEEE, 2016: 150-153.
[本文引用: 1]
[2]
SHRIVASTAVA M, MATLANI P. A smoke detection algorithm based on K-means segmentation [C]// 2016 International Conference on Audio, Language and Image Processing . Shanghai: IEEE, 2016: 301-305.
[本文引用: 1]
[3]
FILONENKO A, HERNÁNDEZ D C, JO K H Fast smoke detection for video surveillance using CUDA
[J]. IEEE Transactions on Industrial Informatics , 2017 , 14 (2 ): 725 - 733
URL
[本文引用: 1]
[4]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431-3440.
[本文引用: 2]
[7]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[8]
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5693-5703.
[本文引用: 8]
[9]
HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. [2020-11-16]. https://arxiv.org/pdf/1704.04861.pdf.
[本文引用: 1]
[10]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881-2890.
[本文引用: 2]
[11]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. [2020-12-10]. https://arxiv.org/pdf/1706.05587.pdf.
[本文引用: 2]
[12]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 40 (4 ): 834 - 848
DOI:10.1109/TPAMI.2017.2699184
[本文引用: 1]
[13]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1904 - 1916
DOI:10.1109/TPAMI.2015.2389824
[本文引用: 1]
[14]
YUAN Y, CHEN X, WANG J, et. Object-contextual representations for semantic segmentation[C]// Computer Vision-ECCV 2020 . [S.l.]: Springer, 2020: 173-190.
[本文引用: 1]
[15]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3-19.
[本文引用: 1]
[16]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
[17]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 801-818.
[本文引用: 1]
[18]
BESBES O, BENAZZA-BENYAHIA A. A Novel video-based smoke detection method based on color invariants [C]// 2016 IEEE International Conference on Acoustics , Speech and Signal Processing . Shanghai: IEEE, 2016: 1911-1915.
[本文引用: 3]
[19]
赵敏, 张为, 王鑫, 等 时空背景模型下结合多种纹理特征的烟雾检测
[J]. 西安交通大学学报 , 2018 , 52 (8 ): 67 - 73
URL
[本文引用: 2]
ZHAO Min, ZHANG Wei, Wang Xin, et al A smoke detection algorithm with multi-texture feature exploration under a spatio-temporal background model
[J]. Journal of Xi’an Jiaotong University , 2018 , 52 (8 ): 67 - 73
URL
[本文引用: 2]
[20]
汪梓艺, 苏育挺, 刘艳艳, 等 一种改进DeeplabV3网络的烟雾分割算法
[J]. 西安电子科技大学学报 , 2019 , 46 (6 ): 52 - 59
URL
[本文引用: 4]
WANG Zi-yi, SU Yu-ting, LIU Yan-yan, et al Algorithm for segmentation of smoke using the improved DeeplabV3 network
[J]. Journal of Xidian University , 2019 , 46 (6 ): 52 - 59
URL
[本文引用: 4]
1
... 目标检测一般用边界框标记目标区域,由于烟雾形状不规则,用矩形框标记容易将烟雾与背景混淆,不利于提取烟雾的特征信息,影响检测结果. 利用语义分割的方法对烟雾图像进行逐像素分类预测可以更准确地分离烟雾区域与背景,得到烟雾区域的详细边界和位置信息. 基于手工设计规则的烟雾分割算法,大多数依赖烟雾区域的颜色信息以及纹理特征[1 ] . Shrivastava等[2 ] 利用烟雾的颜色特征,用k 均值分割算法分类像素点. Filonenko等[3 ] 通过背景减除法检测场景变化,利用颜色信息预测烟雾区域,用边界粗糙度确认烟雾区域的存在,该算法利用Nvidia计算统一设备架构内核(compute unified device architecture, CUDA)提升处理速度. 这些基于手工设计规则的方法只能提取浅层特征的信息,很少利用抽象和高阶的语义信息,因此分割效果较差. 自从全卷积网络(fully convolutional networks, FCN)[4 ] 应用于语义分割后,基于深度学习的语义分割算法极大提升了分割准确率. Yuan等[5 ] 提出的分割网络分为粗略路径和精细路径,粗略路径用来提取全局上下文信息,精细路径用来提取细节信息,将2条路径融合进行烟雾分割. Xu等[6 ] 提出端到端的深度显著性网络,该方法将像素级和对象级显著卷积网络结合,以提取信息丰富的烟雾显著性图,将深度特征图与显著性图结合起来预测图像中的烟雾像素点. ...
1
... 目标检测一般用边界框标记目标区域,由于烟雾形状不规则,用矩形框标记容易将烟雾与背景混淆,不利于提取烟雾的特征信息,影响检测结果. 利用语义分割的方法对烟雾图像进行逐像素分类预测可以更准确地分离烟雾区域与背景,得到烟雾区域的详细边界和位置信息. 基于手工设计规则的烟雾分割算法,大多数依赖烟雾区域的颜色信息以及纹理特征[1 ] . Shrivastava等[2 ] 利用烟雾的颜色特征,用k 均值分割算法分类像素点. Filonenko等[3 ] 通过背景减除法检测场景变化,利用颜色信息预测烟雾区域,用边界粗糙度确认烟雾区域的存在,该算法利用Nvidia计算统一设备架构内核(compute unified device architecture, CUDA)提升处理速度. 这些基于手工设计规则的方法只能提取浅层特征的信息,很少利用抽象和高阶的语义信息,因此分割效果较差. 自从全卷积网络(fully convolutional networks, FCN)[4 ] 应用于语义分割后,基于深度学习的语义分割算法极大提升了分割准确率. Yuan等[5 ] 提出的分割网络分为粗略路径和精细路径,粗略路径用来提取全局上下文信息,精细路径用来提取细节信息,将2条路径融合进行烟雾分割. Xu等[6 ] 提出端到端的深度显著性网络,该方法将像素级和对象级显著卷积网络结合,以提取信息丰富的烟雾显著性图,将深度特征图与显著性图结合起来预测图像中的烟雾像素点. ...
Fast smoke detection for video surveillance using CUDA
1
2017
... 目标检测一般用边界框标记目标区域,由于烟雾形状不规则,用矩形框标记容易将烟雾与背景混淆,不利于提取烟雾的特征信息,影响检测结果. 利用语义分割的方法对烟雾图像进行逐像素分类预测可以更准确地分离烟雾区域与背景,得到烟雾区域的详细边界和位置信息. 基于手工设计规则的烟雾分割算法,大多数依赖烟雾区域的颜色信息以及纹理特征[1 ] . Shrivastava等[2 ] 利用烟雾的颜色特征,用k 均值分割算法分类像素点. Filonenko等[3 ] 通过背景减除法检测场景变化,利用颜色信息预测烟雾区域,用边界粗糙度确认烟雾区域的存在,该算法利用Nvidia计算统一设备架构内核(compute unified device architecture, CUDA)提升处理速度. 这些基于手工设计规则的方法只能提取浅层特征的信息,很少利用抽象和高阶的语义信息,因此分割效果较差. 自从全卷积网络(fully convolutional networks, FCN)[4 ] 应用于语义分割后,基于深度学习的语义分割算法极大提升了分割准确率. Yuan等[5 ] 提出的分割网络分为粗略路径和精细路径,粗略路径用来提取全局上下文信息,精细路径用来提取细节信息,将2条路径融合进行烟雾分割. Xu等[6 ] 提出端到端的深度显著性网络,该方法将像素级和对象级显著卷积网络结合,以提取信息丰富的烟雾显著性图,将深度特征图与显著性图结合起来预测图像中的烟雾像素点. ...
2
... 目标检测一般用边界框标记目标区域,由于烟雾形状不规则,用矩形框标记容易将烟雾与背景混淆,不利于提取烟雾的特征信息,影响检测结果. 利用语义分割的方法对烟雾图像进行逐像素分类预测可以更准确地分离烟雾区域与背景,得到烟雾区域的详细边界和位置信息. 基于手工设计规则的烟雾分割算法,大多数依赖烟雾区域的颜色信息以及纹理特征[1 ] . Shrivastava等[2 ] 利用烟雾的颜色特征,用k 均值分割算法分类像素点. Filonenko等[3 ] 通过背景减除法检测场景变化,利用颜色信息预测烟雾区域,用边界粗糙度确认烟雾区域的存在,该算法利用Nvidia计算统一设备架构内核(compute unified device architecture, CUDA)提升处理速度. 这些基于手工设计规则的方法只能提取浅层特征的信息,很少利用抽象和高阶的语义信息,因此分割效果较差. 自从全卷积网络(fully convolutional networks, FCN)[4 ] 应用于语义分割后,基于深度学习的语义分割算法极大提升了分割准确率. Yuan等[5 ] 提出的分割网络分为粗略路径和精细路径,粗略路径用来提取全局上下文信息,精细路径用来提取细节信息,将2条路径融合进行烟雾分割. Xu等[6 ] 提出端到端的深度显著性网络,该方法将像素级和对象级显著卷积网络结合,以提取信息丰富的烟雾显著性图,将深度特征图与显著性图结合起来预测图像中的烟雾像素点. ...
... 为了验证本研究算法的有效性,将其与经典语义分割网络FCN[4 ] ,PSPNet[10 ] ,DeepLabV3[11 ] ,DeepLabV3+[17 ] 在本研究数据集上进行对比实验,所有算法均采用相同的训练设置. ...
Deep smoke segmentation
1
2019
... 目标检测一般用边界框标记目标区域,由于烟雾形状不规则,用矩形框标记容易将烟雾与背景混淆,不利于提取烟雾的特征信息,影响检测结果. 利用语义分割的方法对烟雾图像进行逐像素分类预测可以更准确地分离烟雾区域与背景,得到烟雾区域的详细边界和位置信息. 基于手工设计规则的烟雾分割算法,大多数依赖烟雾区域的颜色信息以及纹理特征[1 ] . Shrivastava等[2 ] 利用烟雾的颜色特征,用k 均值分割算法分类像素点. Filonenko等[3 ] 通过背景减除法检测场景变化,利用颜色信息预测烟雾区域,用边界粗糙度确认烟雾区域的存在,该算法利用Nvidia计算统一设备架构内核(compute unified device architecture, CUDA)提升处理速度. 这些基于手工设计规则的方法只能提取浅层特征的信息,很少利用抽象和高阶的语义信息,因此分割效果较差. 自从全卷积网络(fully convolutional networks, FCN)[4 ] 应用于语义分割后,基于深度学习的语义分割算法极大提升了分割准确率. Yuan等[5 ] 提出的分割网络分为粗略路径和精细路径,粗略路径用来提取全局上下文信息,精细路径用来提取细节信息,将2条路径融合进行烟雾分割. Xu等[6 ] 提出端到端的深度显著性网络,该方法将像素级和对象级显著卷积网络结合,以提取信息丰富的烟雾显著性图,将深度特征图与显著性图结合起来预测图像中的烟雾像素点. ...
Video smoke detection based on deep saliency network
1
2019
... 目标检测一般用边界框标记目标区域,由于烟雾形状不规则,用矩形框标记容易将烟雾与背景混淆,不利于提取烟雾的特征信息,影响检测结果. 利用语义分割的方法对烟雾图像进行逐像素分类预测可以更准确地分离烟雾区域与背景,得到烟雾区域的详细边界和位置信息. 基于手工设计规则的烟雾分割算法,大多数依赖烟雾区域的颜色信息以及纹理特征[1 ] . Shrivastava等[2 ] 利用烟雾的颜色特征,用k 均值分割算法分类像素点. Filonenko等[3 ] 通过背景减除法检测场景变化,利用颜色信息预测烟雾区域,用边界粗糙度确认烟雾区域的存在,该算法利用Nvidia计算统一设备架构内核(compute unified device architecture, CUDA)提升处理速度. 这些基于手工设计规则的方法只能提取浅层特征的信息,很少利用抽象和高阶的语义信息,因此分割效果较差. 自从全卷积网络(fully convolutional networks, FCN)[4 ] 应用于语义分割后,基于深度学习的语义分割算法极大提升了分割准确率. Yuan等[5 ] 提出的分割网络分为粗略路径和精细路径,粗略路径用来提取全局上下文信息,精细路径用来提取细节信息,将2条路径融合进行烟雾分割. Xu等[6 ] 提出端到端的深度显著性网络,该方法将像素级和对象级显著卷积网络结合,以提取信息丰富的烟雾显著性图,将深度特征图与显著性图结合起来预测图像中的烟雾像素点. ...
1
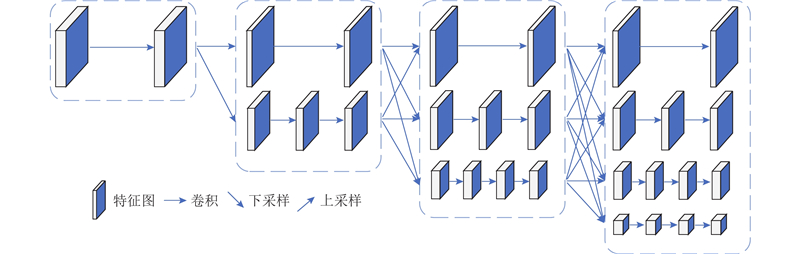
... 由于烟雾形状无规则,不同场景尺度差异大,主干网络只在同一尺度上提取烟雾特征难以取得精确的分割结果. 经典主干网络如残差网络(residual network, ResNet)[7 ] 采用串行方式提取多尺度语义信息,通常用下采样提取更深层的语义信息,同时将特征图尺寸减半. 高分辨率网络1(high-resoultion net1, HRNetv1)[8 ] 从高分辨率子网络开始,并将其作为第1阶段,再逐步添加从高到低各个分辨率子网络,将其并行连接形成新的阶段,同时在并行子网络中引入信息融合单元,使得每个子网络可以接收其他子网络的信息进行多尺度融合. 受文献[8 ]的启发,本研究提出相似的多分支网络,并行级联卷积单元,同时在并行卷积模块中进行多尺度融合.融合多分辨率表征的主干网络架构如图1 所示. 主干网络共有4个阶段,每个阶段由若干个多分辨率模块级联而成,每个多分辨率模块由若干个并行的卷积单元组成,具体网络参数如表1 所示. ...
8
... 由于烟雾形状无规则,不同场景尺度差异大,主干网络只在同一尺度上提取烟雾特征难以取得精确的分割结果. 经典主干网络如残差网络(residual network, ResNet)[7 ] 采用串行方式提取多尺度语义信息,通常用下采样提取更深层的语义信息,同时将特征图尺寸减半. 高分辨率网络1(high-resoultion net1, HRNetv1)[8 ] 从高分辨率子网络开始,并将其作为第1阶段,再逐步添加从高到低各个分辨率子网络,将其并行连接形成新的阶段,同时在并行子网络中引入信息融合单元,使得每个子网络可以接收其他子网络的信息进行多尺度融合. 受文献[8 ]的启发,本研究提出相似的多分支网络,并行级联卷积单元,同时在并行卷积模块中进行多尺度融合.融合多分辨率表征的主干网络架构如图1 所示. 主干网络共有4个阶段,每个阶段由若干个多分辨率模块级联而成,每个多分辨率模块由若干个并行的卷积单元组成,具体网络参数如表1 所示. ...
... 从高分辨率子网络开始,并将其作为第1阶段,再逐步添加从高到低各个分辨率子网络,将其并行连接形成新的阶段,同时在并行子网络中引入信息融合单元,使得每个子网络可以接收其他子网络的信息进行多尺度融合. 受文献[8 ]的启发,本研究提出相似的多分支网络,并行级联卷积单元,同时在并行卷积模块中进行多尺度融合.融合多分辨率表征的主干网络架构如图1 所示. 主干网络共有4个阶段,每个阶段由若干个多分辨率模块级联而成,每个多分辨率模块由若干个并行的卷积单元组成,具体网络参数如表1 所示. ...
... 第1阶段的模块只有1个高分辨率分支,其后每个阶段的模块以并行的方式从高到低逐渐增加多分辨率分支,提取不同尺度的语义信息. 文献[8 ]每个模块分支的卷积单元数均为4,本研究不同分支的卷积单元数并不相同,高分辨率特征图所在的分支设置的卷积单元较少,即构建浅层的神经网络,在有效提取细节信息的同时进一步减少计算量;低分辨率特征图所在的分支设置的卷积单元较多,即构建深层的神经网络,能够有效提取全局语义信息.每个阶段之后融合不同分辨率的特征图,得到更丰富的语义信息. 融合过程包含上采样、下采样以及分辨率保持,低分辨率特征图通过双线性插值提高分辨率与高分辨率特征图进行融合,高分辨率特征图通过池化操作降低分辨率与低分辨率特征图进行融合,同一尺度的特征图通过卷积运算保持分辨率不变. 文献[8 ]采用标准卷积作为基本卷积单元,本研究网络采用深度可分离卷积[9 ] 作为基本卷积单元,在保证准确率的同时提高检测速度. 对于标准卷积单元,输入尺寸为 $h \times w \times {d_i}$ ${\boldsymbol{K}} \in {{\bf{R}}^{k \times k \times {d_i} \times {d_j}}}$ $h \times w \times {d_j}$ $h w {d_i} {d_j} k k$ h 、w 分别为特征图的宽和高,d i d j k 为卷积核尺寸. 对于深度可分离卷积单元,同样尺寸的特征图所需计算量为 $h w {d_i}({k^2} + {d_j})$ . 当卷积核 $k = 3$ $1/9$
... ]每个模块分支的卷积单元数均为4,本研究不同分支的卷积单元数并不相同,高分辨率特征图所在的分支设置的卷积单元较少,即构建浅层的神经网络,在有效提取细节信息的同时进一步减少计算量;低分辨率特征图所在的分支设置的卷积单元较多,即构建深层的神经网络,能够有效提取全局语义信息.每个阶段之后融合不同分辨率的特征图,得到更丰富的语义信息. 融合过程包含上采样、下采样以及分辨率保持,低分辨率特征图通过双线性插值提高分辨率与高分辨率特征图进行融合,高分辨率特征图通过池化操作降低分辨率与低分辨率特征图进行融合,同一尺度的特征图通过卷积运算保持分辨率不变. 文献[8 ]采用标准卷积作为基本卷积单元,本研究网络采用深度可分离卷积[9 ] 作为基本卷积单元,在保证准确率的同时提高检测速度. 对于标准卷积单元,输入尺寸为 $h \times w \times {d_i}$ ${\boldsymbol{K}} \in {{\bf{R}}^{k \times k \times {d_i} \times {d_j}}}$ $h \times w \times {d_j}$ $h w {d_i} {d_j} k k$ h 、w 分别为特征图的宽和高,d i d j k 为卷积核尺寸. 对于深度可分离卷积单元,同样尺寸的特征图所需计算量为 $h w {d_i}({k^2} + {d_j})$ . 当卷积核 $k = 3$ $1/9$
... Ablation experiment results
Tab.5 算法 烟雾前景增强模块 残差注意力模块 mIoU/% T /ms P /MB 文献[8 ] √ √ 91.84 47.63 93.24 Ours1 − − 89.45 34.80 60.00 Ours2 √ − 90.83 38.52 73.24 本研究 √ √ 91.27 39.06 74.66
设计与文献[8 ]的对比实验,以验证主干网络对检测性能的提升.公平起见,在文献[8 ]的网络中加入本研究的烟雾前景增强模块和残差注意力模块. 从表5 的对比结果可见,本研究算法在保证分割准确率的前提下,提高检测速度同时网络更加轻量化,相比于文献[8 ]综合性能更好. ...
... 设计与文献[8 ]的对比实验,以验证主干网络对检测性能的提升.公平起见,在文献[8 ]的网络中加入本研究的烟雾前景增强模块和残差注意力模块. 从表5 的对比结果可见,本研究算法在保证分割准确率的前提下,提高检测速度同时网络更加轻量化,相比于文献[8 ]综合性能更好. ...
... ]的对比实验,以验证主干网络对检测性能的提升.公平起见,在文献[8 ]的网络中加入本研究的烟雾前景增强模块和残差注意力模块. 从表5 的对比结果可见,本研究算法在保证分割准确率的前提下,提高检测速度同时网络更加轻量化,相比于文献[8 ]综合性能更好. ...
... 的对比结果可见,本研究算法在保证分割准确率的前提下,提高检测速度同时网络更加轻量化,相比于文献[8 ]综合性能更好. ...
1
... 第1阶段的模块只有1个高分辨率分支,其后每个阶段的模块以并行的方式从高到低逐渐增加多分辨率分支,提取不同尺度的语义信息. 文献[8 ]每个模块分支的卷积单元数均为4,本研究不同分支的卷积单元数并不相同,高分辨率特征图所在的分支设置的卷积单元较少,即构建浅层的神经网络,在有效提取细节信息的同时进一步减少计算量;低分辨率特征图所在的分支设置的卷积单元较多,即构建深层的神经网络,能够有效提取全局语义信息.每个阶段之后融合不同分辨率的特征图,得到更丰富的语义信息. 融合过程包含上采样、下采样以及分辨率保持,低分辨率特征图通过双线性插值提高分辨率与高分辨率特征图进行融合,高分辨率特征图通过池化操作降低分辨率与低分辨率特征图进行融合,同一尺度的特征图通过卷积运算保持分辨率不变. 文献[8 ]采用标准卷积作为基本卷积单元,本研究网络采用深度可分离卷积[9 ] 作为基本卷积单元,在保证准确率的同时提高检测速度. 对于标准卷积单元,输入尺寸为 $h \times w \times {d_i}$ ${\boldsymbol{K}} \in {{\bf{R}}^{k \times k \times {d_i} \times {d_j}}}$ $h \times w \times {d_j}$ $h w {d_i} {d_j} k k$ h 、w 分别为特征图的宽和高,d i d j k 为卷积核尺寸. 对于深度可分离卷积单元,同样尺寸的特征图所需计算量为 $h w {d_i}({k^2} + {d_j})$ . 当卷积核 $k = 3$ $1/9$
2
... 语义分割是像素级别的细粒度分类任务,为了提升分割精度,分割网络应充分提取图像的语义信息并进行特征融合,具有代表性的工作有金字塔场景解析网络(pyramid scene parsing network, PSPNet)[10 ] 和DeepLabv3[11 ] . PSPNet对网络提取的特征做了4种不同尺度的池化操作后再上采样回原来尺度,最终对不同尺度的信息进行融合,但是池化过程中会损失一定的语义信息且难以恢复. DeepLabv3中空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)模块[12 ] 通过不同采样率的空洞卷积并行提取多尺度目标特征并进行融合[13 ] ,空洞卷积能够避免损失语义信息,但是采样间隔较大时容易引入背景信息,对目标特征造成干扰. ...
... 为了验证本研究算法的有效性,将其与经典语义分割网络FCN[4 ] ,PSPNet[10 ] ,DeepLabV3[11 ] ,DeepLabV3+[17 ] 在本研究数据集上进行对比实验,所有算法均采用相同的训练设置. ...
2
... 语义分割是像素级别的细粒度分类任务,为了提升分割精度,分割网络应充分提取图像的语义信息并进行特征融合,具有代表性的工作有金字塔场景解析网络(pyramid scene parsing network, PSPNet)[10 ] 和DeepLabv3[11 ] . PSPNet对网络提取的特征做了4种不同尺度的池化操作后再上采样回原来尺度,最终对不同尺度的信息进行融合,但是池化过程中会损失一定的语义信息且难以恢复. DeepLabv3中空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)模块[12 ] 通过不同采样率的空洞卷积并行提取多尺度目标特征并进行融合[13 ] ,空洞卷积能够避免损失语义信息,但是采样间隔较大时容易引入背景信息,对目标特征造成干扰. ...
... 为了验证本研究算法的有效性,将其与经典语义分割网络FCN[4 ] ,PSPNet[10 ] ,DeepLabV3[11 ] ,DeepLabV3+[17 ] 在本研究数据集上进行对比实验,所有算法均采用相同的训练设置. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
1
2018
... 语义分割是像素级别的细粒度分类任务,为了提升分割精度,分割网络应充分提取图像的语义信息并进行特征融合,具有代表性的工作有金字塔场景解析网络(pyramid scene parsing network, PSPNet)[10 ] 和DeepLabv3[11 ] . PSPNet对网络提取的特征做了4种不同尺度的池化操作后再上采样回原来尺度,最终对不同尺度的信息进行融合,但是池化过程中会损失一定的语义信息且难以恢复. DeepLabv3中空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)模块[12 ] 通过不同采样率的空洞卷积并行提取多尺度目标特征并进行融合[13 ] ,空洞卷积能够避免损失语义信息,但是采样间隔较大时容易引入背景信息,对目标特征造成干扰. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2015
... 语义分割是像素级别的细粒度分类任务,为了提升分割精度,分割网络应充分提取图像的语义信息并进行特征融合,具有代表性的工作有金字塔场景解析网络(pyramid scene parsing network, PSPNet)[10 ] 和DeepLabv3[11 ] . PSPNet对网络提取的特征做了4种不同尺度的池化操作后再上采样回原来尺度,最终对不同尺度的信息进行融合,但是池化过程中会损失一定的语义信息且难以恢复. DeepLabv3中空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)模块[12 ] 通过不同采样率的空洞卷积并行提取多尺度目标特征并进行融合[13 ] ,空洞卷积能够避免损失语义信息,但是采样间隔较大时容易引入背景信息,对目标特征造成干扰. ...
1
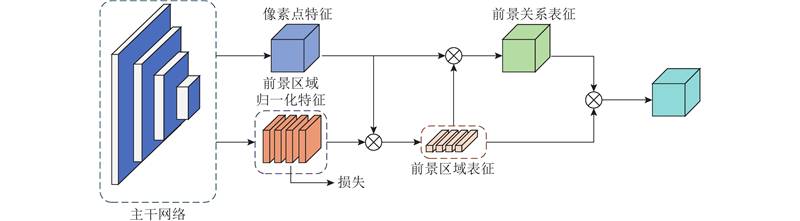
... 烟雾具有半透明的特征,在光照干扰下,容易与地面、墙壁、天空等背景融在一起,使分割准确率降低. 受对象上下文表示(object-contextual representations, OCR)[14 ] 的启发,本研究针对烟雾与背景难以区分的问题提出烟雾前景增强模块(smoke foreground enhancement module, SFEM). 1个像素与其所在的目标区域同属于1个类别,通过分析1个位置的像素点特征和目标区域特征的联系,可以建立起相应的关系表征,关系表征可以衡量像素点与目标区域的相似程度. 单个像素点特征信息不够充分,利用烟雾前景特征与前景关系表征可以得到前景增强表征,前景增强表征包含与像素点相关联的前景特征信息,将其与像素点特征级联起来能够增强单个像素点的特征表达,使对应的像素点融合更丰富的语义信息,提高该像素点的分类准确率. 对于1个烟雾像素点,利用与其对应的烟雾前景增强表征能使烟雾像素点特征融合更丰富的前景信息,避免背景信息的干扰,特征增强后的烟雾像素点与背景更容易区分开,使分割准确率提高. ...
1
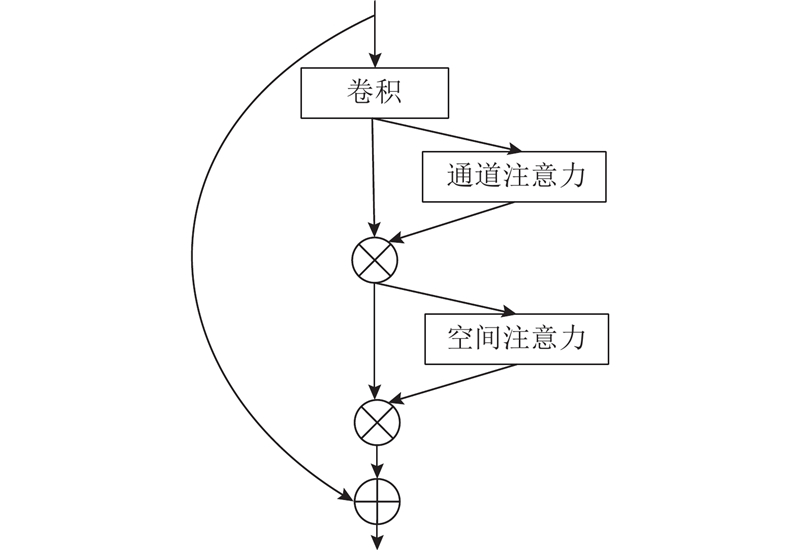
... 在神经网络中,卷积运算能够融合通道和空间这2个维度提取信息特征. 随着卷积层的叠加,提取到的语义信息越来越丰富,然而这些信息与最终优化目标的关联程度不尽相同,因此本研究在网络中加入残差注意力模块(residual attention module, RAM),在通道和空间这2个维度上分析特征内部之间的关系得到注意力特征图[15 ] ,用来增强有意义的特征信息,同时抑制无效的特征信息. ...
1
... 特征图的每个通道包含目标某一方面的特征[16 ] . 为了计算通道注意力,本研究在空间维度上浓缩特征图,将每个通道的特征图通过最大池化操作和平均池化操作进行浓缩,用 ${\boldsymbol{F}}_{{\rm{max}}}^{\rm{c}}$ ${\boldsymbol{F}}_{{\rm{avg}}}^{\rm{c}}$
1
... 为了验证本研究算法的有效性,将其与经典语义分割网络FCN[4 ] ,PSPNet[10 ] ,DeepLabV3[11 ] ,DeepLabV3+[17 ] 在本研究数据集上进行对比实验,所有算法均采用相同的训练设置. ...
3
... 将本文算法与文献[18 ]~[20 ]的3种烟雾检测算法进行对比,评价指标采用真正率TPR (true positive rate)和真负率TNR (true negative rate),结果如表4 所示. ...
... Comparison of detection results between existing smoke detection algorithms and proposed algorithm
% Tab.4 视频名称 本研究算法 文献[20 ] 文献[19 ] 文献[18 ] R TPR R TNR R TPR R TNR R TPR R TNR R TPR R TNR sBehindtheFence 98.64 100.00 98.26 94.60 97.20 96.27 94.72 100.00 sBtFence 98.81 100.00 98.20 100.00 98.17 100.00 99.08 100.00 sMoky 98.27 100.00 98.85 100.00 99.68 100.00 86.23 100.00 sWasteBasket 99.50 96.84 99.41 100.00 97.18 98.36 99.89 92.60 sWindow 98.46 97.87 98.40 100.00 98.10 100.00 94.30 100.00
根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... 根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
时空背景模型下结合多种纹理特征的烟雾检测
2
2018
... Comparison of detection results between existing smoke detection algorithms and proposed algorithm
% Tab.4 视频名称 本研究算法 文献[20 ] 文献[19 ] 文献[18 ] R TPR R TNR R TPR R TNR R TPR R TNR R TPR R TNR sBehindtheFence 98.64 100.00 98.26 94.60 97.20 96.27 94.72 100.00 sBtFence 98.81 100.00 98.20 100.00 98.17 100.00 99.08 100.00 sMoky 98.27 100.00 98.85 100.00 99.68 100.00 86.23 100.00 sWasteBasket 99.50 96.84 99.41 100.00 97.18 98.36 99.89 92.60 sWindow 98.46 97.87 98.40 100.00 98.10 100.00 94.30 100.00
根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... 根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
时空背景模型下结合多种纹理特征的烟雾检测
2
2018
... Comparison of detection results between existing smoke detection algorithms and proposed algorithm
% Tab.4 视频名称 本研究算法 文献[20 ] 文献[19 ] 文献[18 ] R TPR R TNR R TPR R TNR R TPR R TNR R TPR R TNR sBehindtheFence 98.64 100.00 98.26 94.60 97.20 96.27 94.72 100.00 sBtFence 98.81 100.00 98.20 100.00 98.17 100.00 99.08 100.00 sMoky 98.27 100.00 98.85 100.00 99.68 100.00 86.23 100.00 sWasteBasket 99.50 96.84 99.41 100.00 97.18 98.36 99.89 92.60 sWindow 98.46 97.87 98.40 100.00 98.10 100.00 94.30 100.00
根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... 根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
一种改进DeeplabV3网络的烟雾分割算法
4
2019
... 将本文算法与文献[18 ]~[20 ]的3种烟雾检测算法进行对比,评价指标采用真正率TPR (true positive rate)和真负率TNR (true negative rate),结果如表4 所示. ...
... Comparison of detection results between existing smoke detection algorithms and proposed algorithm
% Tab.4 视频名称 本研究算法 文献[20 ] 文献[19 ] 文献[18 ] R TPR R TNR R TPR R TNR R TPR R TNR R TPR R TNR sBehindtheFence 98.64 100.00 98.26 94.60 97.20 96.27 94.72 100.00 sBtFence 98.81 100.00 98.20 100.00 98.17 100.00 99.08 100.00 sMoky 98.27 100.00 98.85 100.00 99.68 100.00 86.23 100.00 sWasteBasket 99.50 96.84 99.41 100.00 97.18 98.36 99.89 92.60 sWindow 98.46 97.87 98.40 100.00 98.10 100.00 94.30 100.00
根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... 根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
一种改进DeeplabV3网络的烟雾分割算法
4
2019
... 将本文算法与文献[18 ]~[20 ]的3种烟雾检测算法进行对比,评价指标采用真正率TPR (true positive rate)和真负率TNR (true negative rate),结果如表4 所示. ...
... Comparison of detection results between existing smoke detection algorithms and proposed algorithm
% Tab.4 视频名称 本研究算法 文献[20 ] 文献[19 ] 文献[18 ] R TPR R TNR R TPR R TNR R TPR R TNR R TPR R TNR sBehindtheFence 98.64 100.00 98.26 94.60 97.20 96.27 94.72 100.00 sBtFence 98.81 100.00 98.20 100.00 98.17 100.00 99.08 100.00 sMoky 98.27 100.00 98.85 100.00 99.68 100.00 86.23 100.00 sWasteBasket 99.50 96.84 99.41 100.00 97.18 98.36 99.89 92.60 sWindow 98.46 97.87 98.40 100.00 98.10 100.00 94.30 100.00
根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... 根据实验结果可知,本研究算法在公开视频数据集上取得了最高的平均真正率百分比R TPR 、真负率百分比R TNR . 文献[18 ]利用颜色特征进行烟雾检测,虽然在多个视频上取得了最高的R TPR ,但是在sMoky视频中检测结果很差,说明该算法容易受到外部环境(如光照)的影响,不具备很强的鲁棒性. 文献[19 ]利用烟雾的纹理特征进行检测,虽然不易受到外界光照的干扰,但是难以充分提取烟雾的深层特征,因此整体性能不如基于神经网络的深度学习算法. 文献[20 ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...
... ]改进DeepLabV3进行烟雾检测,与文献[20 ]相比,本研究算法避免引入背景干扰信息,因此检测效果和鲁棒性更好. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}