[1]
罗浩, 姜伟, 范星, 等 基于深度学习的行人重识别研究进展
[J]. 自动化学报 , 2019 , 45 (11 ): 2032 - 2049
URL
[本文引用: 4]
LUO Hao, JIANG Wei, FAN Xing, et al A survey on deep learning based person re-identification
[J]. Acta Automatica Sinica , 2019 , 45 (11 ): 2032 - 2049
URL
[本文引用: 4]
[2]
李幼蛟, 卓力, 张菁, 等 行人再识别技术综述
[J]. 自动化学报 , 2018 , 44 (9 ): 1554 - 1568
URL
[本文引用: 1]
LI You-jiao, ZHUO Li, ZHANG Jing, et al A survey of person re-identification
[J]. Acta Automatica Sinica , 2018 , 44 (9 ): 1554 - 1568
URL
[本文引用: 1]
[3]
QIAN X L, WANG W X, ZHANG L, et al. Long-term cloth-changing person re-identification [EB/OL]. [2020-05-26]. https://arxiv.org/abs/2005.12633.
[本文引用: 11]
[4]
JIN X, LAN C, ZENG W, et al. Style normalization and restitution for generalizable person re-identification[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3140-3149.
[本文引用: 2]
[5]
WEI L H, ZHANG S L, GAO W, et al. Person transfer GAN to bridge domain gap for person re-identification [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 79-88.
[本文引用: 3]
[6]
KHATUN A, DENMAN S, SRIDHARAN, S, et al. End-to-end domain adaptive attention network for cross-domain person re-identification [EB/OL]. [2020-05-07]. https://arxiv.org/abs/2005.03222.
[本文引用: 5]
[7]
ZHAI Y P, LU S J. AD-Cluster: augmented discriminative clustering for domain adaptive person re-identification [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9018-9027.
[本文引用: 3]
[8]
SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 815-823.
[本文引用: 7]
[9]
WEN Y D, ZHANG K P, LI Z F. A discriminative feature learning approach for deep face recognition [C]// Proceedings of the 2016 European Conference on Computer Vision . Amsterdam: Springer, 2016: 499-515.
[本文引用: 3]
[10]
ZHANG J, LIU L, XU C, et al. Hierarchical and efficient learning for person re-identification [EB/OL]. [2020-05-18]. https://arxiv.org/abs/2005.08812.
[本文引用: 1]
[11]
SUN Y, ZHENG L, YANG Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline) [C]// Proceedings of the 2016 European Conference on Computer Vision . Munich: Springer, 2018: 3387–3396.
[本文引用: 1]
[12]
LIAO S C, HU Y, ZHU X Y, et al. Person re-identification by local maximal occurrence representation and metric learning [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 2197−2206.
[13]
TAGORE N K, SINGH A, MANCHE S, et al. Deep learning based person re-identification [EB/OL]. [2020-05-07]. https://arxiv.org/abs/2005.03293.
[本文引用: 1]
[14]
HE K M, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 5]
[15]
ULYANOV D, VEDALDI A, LEMPITSKY V. Instance normalization: the missing ingredient for fast stylization [EB/OL]. [2016-06-27]. https://arxiv.org/abs/1607.08022.
[本文引用: 1]
[16]
QIAN X L, FU Y, XIANG T, et al Leader-based multi-scale attention deep architecture for person re-identification
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (2 ): 371 - 385
DOI:10.1109/TPAMI.2019.2928294
[本文引用: 2]
[17]
LI W, ZHU X, GONG S. Harmonious attention network for person re-identification [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2285–2294.
[本文引用: 1]
[18]
CHEN B, DENG W, HU J. Mixed high-order attention network for person re-identification [C]// Proceedings of the 2019 IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 371-381.
[19]
周勇, 王瀚正, 赵佳琦, 等. 基于可解释注意力部件模型的行人重识别方法[EB/OL]. [2020-08-23]. https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CAPJ&dbname=CAPJLAST&filename=MOTO20201105000&uniplatform=NZKPT&v=JCreBvAGjWgg9eTStxOX1MHBH7tyLrog82SWoZ97XdB1Id9qWj877hYBzM9evYAl.
[本文引用: 1]
ZHOU Yong, WANG Han-zheng, ZHAO Jia-qi, et al. Interpretable Attention Part Model for Person Re-identification [EB/OL]. [2020-08-23]. https:/kns.cnki.net/kcms/detail/detail.aspx?dbcode=CAPJ&dbname=CAPJLAST&filename=MOTO20201105000&uniplatform=NZKPT&v=JCreBvAGjWgg9eTStxOX1MHBH7tyLrog82SWoZ97XdB1Id9qWj877hYBzM9evYAl.
[本文引用: 1]
[20]
ZHANG K, ZHANG Z, LI Z, et al Joint face detection and alignment using multitask cascaded convolutional networks
[J]. IEEE Signal Processing Letters , 2016 , 23 : 1499 - 1503
DOI:10.1109/LSP.2016.2603342
[本文引用: 2]
[21]
JIN X., LAN C, ZENG W, et al. Global distance distributions separation for unsupervised person re-identification [EB/OL]. [2020-06-01]. https://arxiv.org/pdf/2006.00752.pdf.
[本文引用: 1]
[22]
LIN Y T, XIE L X. Unsupervised person re-identification via softened similarity learning [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3387-3396.
[本文引用: 1]
[23]
ZHENG L, SHEN L, TIAN L, et al. Scalable person re-identification: a benchmark [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1116–1124.
[本文引用: 3]
[24]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
[本文引用: 1]
基于深度学习的行人重识别研究进展
4
2019
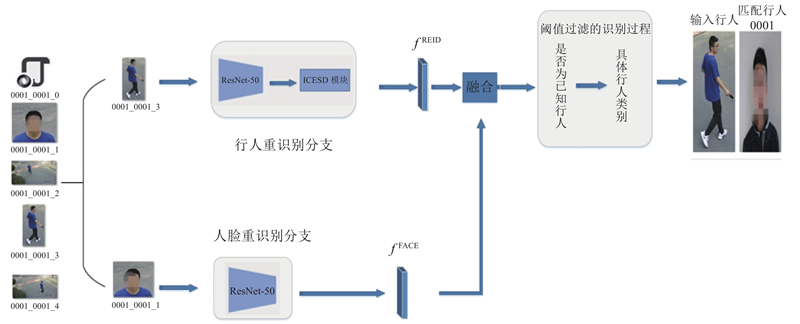
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... [1 ]. 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 随着深度学习的发展,基于深度学习的行人重识别方法相较于人工设计特征的行人重识别方法表现出更高的性能并逐渐占据主流[1 ] . 同时,将人脸识别引入算法之中以提高行人身份识别算法在现实场景中应用的准度. 将人脸识别与行人重识别相结合,人脸识别在检测到人脸数据时提高行人身份识别算法的准确度,行人重识别在人脸识别因未检测到人脸而失效时提供较为可靠的检索结果. ...
... 大多数的行人重识别都是以有监督的方式进行的,有监督行人重识别已经在现有的公开行人重识别数据集上实现了较高的性能[10 -13 ] . 有监督行人重识别在大量身份标注的基础上,通常使用主干网络提取图片的特征,利用基于交叉熵的分类损失和基于三元组的三元组损失[8 ] 监督整个模型的训练. 虽然在当前主流公开数据库中获得了卓越的性能表现,但是有监督行人重识别需要巨大的标注花销,而这在现实场景的行人重识别应用中往往是不现实的[1 ] . ...
基于深度学习的行人重识别研究进展
4
2019
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... [1 ]. 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 随着深度学习的发展,基于深度学习的行人重识别方法相较于人工设计特征的行人重识别方法表现出更高的性能并逐渐占据主流[1 ] . 同时,将人脸识别引入算法之中以提高行人身份识别算法在现实场景中应用的准度. 将人脸识别与行人重识别相结合,人脸识别在检测到人脸数据时提高行人身份识别算法的准确度,行人重识别在人脸识别因未检测到人脸而失效时提供较为可靠的检索结果. ...
... 大多数的行人重识别都是以有监督的方式进行的,有监督行人重识别已经在现有的公开行人重识别数据集上实现了较高的性能[10 -13 ] . 有监督行人重识别在大量身份标注的基础上,通常使用主干网络提取图片的特征,利用基于交叉熵的分类损失和基于三元组的三元组损失[8 ] 监督整个模型的训练. 虽然在当前主流公开数据库中获得了卓越的性能表现,但是有监督行人重识别需要巨大的标注花销,而这在现实场景的行人重识别应用中往往是不现实的[1 ] . ...
行人再识别技术综述
1
2018
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
行人再识别技术综述
1
2018
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
11
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... [3 ]等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 行人的换装问题是行人重识别应用于现实场景的重大挑战之一,当前的主流深度学习方法提取的特征主要关注于包含行人的衣着信息的外观信息[3 ] ,这使得对于同一行人不同穿着场景下的检索变得尤为困难[3 ] . 目前具有衣着标注的公开换装行人重识别数据库还较少,关于换装行人重识别的研究也才刚刚起步. Qian等[3 ] 为学术界引入了换装行人重识别数据库LTCC,并提出身形嵌入(shape embedding,SE)模块和衣着信息消除(cloth-elimination shape-distillation,CESD)模块来利用身形信息消除衣着信息. 在利用现成的姿态估计器获得身体结构信息后,SE模块利用人身体结构信息提取身形信息,CESD模块利用SE模块提取的身形信息和注意力模块分离身份信息和衣着信息,这在一定程度上缓解了行人换装对检索带来的消极影响[3 ] . ...
... [3 ]. 目前具有衣着标注的公开换装行人重识别数据库还较少,关于换装行人重识别的研究也才刚刚起步. Qian等[3 ] 为学术界引入了换装行人重识别数据库LTCC,并提出身形嵌入(shape embedding,SE)模块和衣着信息消除(cloth-elimination shape-distillation,CESD)模块来利用身形信息消除衣着信息. 在利用现成的姿态估计器获得身体结构信息后,SE模块利用人身体结构信息提取身形信息,CESD模块利用SE模块提取的身形信息和注意力模块分离身份信息和衣着信息,这在一定程度上缓解了行人换装对检索带来的消极影响[3 ] . ...
... [3 ]为学术界引入了换装行人重识别数据库LTCC,并提出身形嵌入(shape embedding,SE)模块和衣着信息消除(cloth-elimination shape-distillation,CESD)模块来利用身形信息消除衣着信息. 在利用现成的姿态估计器获得身体结构信息后,SE模块利用人身体结构信息提取身形信息,CESD模块利用SE模块提取的身形信息和注意力模块分离身份信息和衣着信息,这在一定程度上缓解了行人换装对检索带来的消极影响[3 ] . ...
... [3 ]. ...
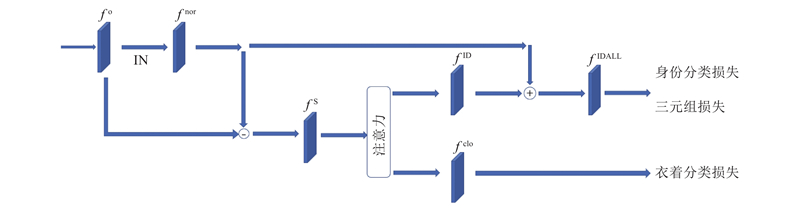
... 目前主流的基于深度学习的行人重识别方法普遍依赖行人衣着这样的外观信息来提取特征,在应用到现实场景时,会由于行人衣着变化而失效,不能正确识别行人[3 ] . 为了解决这个问题,提出改进的衣着信息消除模块(ICESD模块)[3 ] 来消除衣着信息,提取对于衣着变化具有鲁棒性的特征,ICESD模块的具体结构如图3 所示. 图中,f o 、f nor 、f S 、f ID 、f clo 、f IDALL 分别为原始输入的特征、去风格化后的特征、原始输入特征减去去风格化特征后的特征、分离出的身份特征、分离出的衣着特征、最终的身份特征. ...
... [3 ]来消除衣着信息,提取对于衣着变化具有鲁棒性的特征,ICESD模块的具体结构如图3 所示. 图中,f o 、f nor 、f S 、f ID 、f clo 、f IDALL 分别为原始输入的特征、去风格化后的特征、原始输入特征减去去风格化特征后的特征、分离出的身份特征、分离出的衣着特征、最终的身份特征. ...
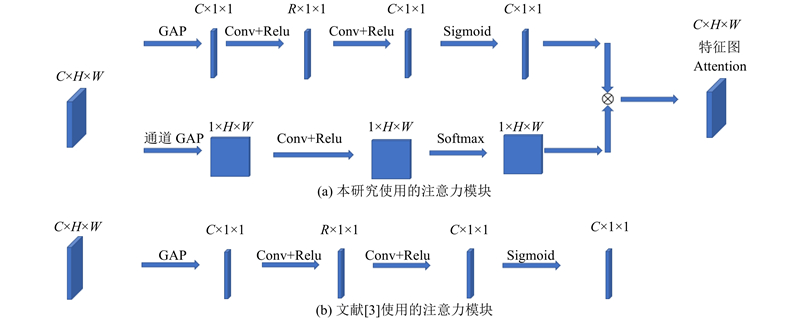
... 文献[3 ]的CESD模块的注意力模块如图4 (b)所示,输入的特征图[C ,H ,W ]经过全局平均池化后,接1×1的卷积层和 $ \mathrm{R}\mathrm{e}\mathrm{l}\mathrm{u} $ C 变为R ),然后再接1×1的卷积层和 $ \mathrm{R}\mathrm{e}\mathrm{l}\mathrm{u} $ C ,经过 $ \mathrm{s}\mathrm{i}\mathrm{g}\mathrm{m}\mathrm{o}\mathrm{i}\mathrm{d} $ C ,1,1]的注意力图. 这一过程可以表示为 ...
... 这样得到的注意图在每一个通道上的值是相同的,未能充分注意到每个通道不同空间位置的不同激活. 相较于文献[3 ],本研究在注意力机制上进行了改进,提出通道方向重校准和空间方向增强的注意力模块,具体结构如图4 (a)所示,分别在通道方向和空间位置上提取注意力图,最后将通道和空间位置整合在一起得到最终的注意力图. ...
... 具体来说,在通道方向重校准与原文献基本一致,采用基本类似的结构,与文献[3 ]除第1个卷积层所用卷积核数不同(L 和R 不同),其余均相同,得到通道方向的注意力图 $ {A}_{\text{c}} $
2
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 为了降低对身份标注的要求,并且充分利用已有的行人重识别的数据集,域适应的方法逐渐被提出来解决这一问题[4 -7 ] . 域适应方法通常利用有身份标注的源域数据以有监督的方式训练模型为模型适应到目标域提供一个好的初始化. 域适应的方法主要可以分为2类. 1)基于生成对抗网络(generative adversarial networks, GAN)的域适应[5 -6 ] . Wei等[5 ] 提出PTGAN将源域数据迁移到目标域使其具有目标域的风格同时保持源域的标签来增强目标域训练数据,使得深度模型对于目标域的适应性更强,能够提取更具辨识性的目标域特征[5 ] . Khatun等[6 ] 将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
3
... 为了降低对身份标注的要求,并且充分利用已有的行人重识别的数据集,域适应的方法逐渐被提出来解决这一问题[4 -7 ] . 域适应方法通常利用有身份标注的源域数据以有监督的方式训练模型为模型适应到目标域提供一个好的初始化. 域适应的方法主要可以分为2类. 1)基于生成对抗网络(generative adversarial networks, GAN)的域适应[5 -6 ] . Wei等[5 ] 提出PTGAN将源域数据迁移到目标域使其具有目标域的风格同时保持源域的标签来增强目标域训练数据,使得深度模型对于目标域的适应性更强,能够提取更具辨识性的目标域特征[5 ] . Khatun等[6 ] 将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
... [5 ]提出PTGAN将源域数据迁移到目标域使其具有目标域的风格同时保持源域的标签来增强目标域训练数据,使得深度模型对于目标域的适应性更强,能够提取更具辨识性的目标域特征[5 ] . Khatun等[6 ] 将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
... [5 ]. Khatun等[6 ] 将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
5
... 为了降低对身份标注的要求,并且充分利用已有的行人重识别的数据集,域适应的方法逐渐被提出来解决这一问题[4 -7 ] . 域适应方法通常利用有身份标注的源域数据以有监督的方式训练模型为模型适应到目标域提供一个好的初始化. 域适应的方法主要可以分为2类. 1)基于生成对抗网络(generative adversarial networks, GAN)的域适应[5 -6 ] . Wei等[5 ] 提出PTGAN将源域数据迁移到目标域使其具有目标域的风格同时保持源域的标签来增强目标域训练数据,使得深度模型对于目标域的适应性更强,能够提取更具辨识性的目标域特征[5 ] . Khatun等[6 ] 将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
... [6 ]将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
... [6 ]. 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
... 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
... [6 ]. 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
3
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 为了降低对身份标注的要求,并且充分利用已有的行人重识别的数据集,域适应的方法逐渐被提出来解决这一问题[4 -7 ] . 域适应方法通常利用有身份标注的源域数据以有监督的方式训练模型为模型适应到目标域提供一个好的初始化. 域适应的方法主要可以分为2类. 1)基于生成对抗网络(generative adversarial networks, GAN)的域适应[5 -6 ] . Wei等[5 ] 提出PTGAN将源域数据迁移到目标域使其具有目标域的风格同时保持源域的标签来增强目标域训练数据,使得深度模型对于目标域的适应性更强,能够提取更具辨识性的目标域特征[5 ] . Khatun等[6 ] 将风格信息分为光照、分辨率、摄像机视角等几个因子分别进行光照迁移、分辨率迁移和摄像机视角迁移,然后通过选择网络学习3个因子的权重信息,将3个因子通过权重合并再通过整合生成对抗网络将源域数据迁移到目标域中,实现性能提升[6 ] . 2)基于聚类的域适应[7 ] . 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
... [7 ]. 这类方法首先使用在源域上预训练的深度模型对目标域的数据提取特征. 然后应用聚类方法对提取的特征进行聚类,依据聚类标签来给目标域数据分配伪标签,利用分配的伪标签监督深度模型训练,上述训练深度模型和提取特征分配伪标签迭代进行,直到深度模型收敛. ...
7
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 随着深度学习的发展,人脸识别已经取得了显著的进展,并且已经成功应用于现实布控的安防系统[8 -9 ] . Schroff等[8 ] 提出的FaceNet引入困难三元组损失来监督模型的训练,取得了较好的精度. Wen等[9 ] 提出的Center Loss使用聚类和分类相结合的方式提取特征信息,使得相同身份的人脸特征在特征空间中有更加紧密的分布,因此实现了性能的提升. ...
... [8 ]提出的FaceNet引入困难三元组损失来监督模型的训练,取得了较好的精度. Wen等[9 ] 提出的Center Loss使用聚类和分类相结合的方式提取特征信息,使得相同身份的人脸特征在特征空间中有更加紧密的分布,因此实现了性能的提升. ...
... 大多数的行人重识别都是以有监督的方式进行的,有监督行人重识别已经在现有的公开行人重识别数据集上实现了较高的性能[10 -13 ] . 有监督行人重识别在大量身份标注的基础上,通常使用主干网络提取图片的特征,利用基于交叉熵的分类损失和基于三元组的三元组损失[8 ] 监督整个模型的训练. 虽然在当前主流公开数据库中获得了卓越的性能表现,但是有监督行人重识别需要巨大的标注花销,而这在现实场景的行人重识别应用中往往是不现实的[1 ] . ...
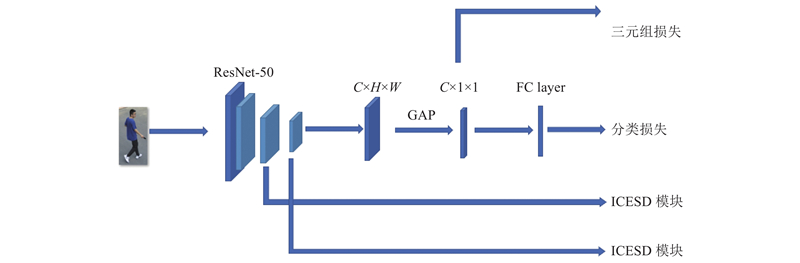
... 行人重识别分支整体结构如图2 所示,采用ResNet-50[14 ] 作为主干网络,并将改进的衣着信息消除模块分别嵌入到layer3、layer4后. 对于前端摄像机检测到的行人图片,将其输入到主干网络中提取特征,提取的特征图尺寸为[C ,H ,W ],C 、H 、W 分别为特征图的通道数、高度、宽度. 提取出的特征经过全局平局池化(global average pooling,GAP)后得到[C ,1,1]的向量,通过三元组损失(triplet loss)[8 ] 和分类损失(classification loss)进行约束训练,分类损失和三元组损失表达式如下: ...
... 将得到的身份信息特征和衣着信息特征分别通过身份分类器和衣着分类器进行分类,对于身份信息特征同时施加三元组损失[8 ] . 分类损失和三元组损失计算如下: ...
... 人脸识别模型的结构如图5 所示,本研究使用ResNet-50[14 ] 作为主干网络提取特征,对于一张检测到的人脸图片,首先使用MTCNN[20 ] 网络来对齐人脸图片,将对齐后的人脸图片输入到主干网络中提取特征,提取的特征图尺寸为[C ,H ,W ]. 提取出的特征经过GAP后得到长度为C 的向量,通过三元组损失[8 ] 和分类损失来监督整个人脸识别模型的训练. ...
3
... 近年来,随着监控设备的广泛应用,行人身份识别相关技术获得越来越广泛的关注,行人身份识别关注于利用拍摄到的行人图片在行人数据库中找寻具有相同身份的行人,以确定拍摄到的行人的身份. 行人身份识别在物联网与大数据环境下具有广阔的应用场景. 目前主要行人重识别技术和人脸识别技术与行人身份识别关系密切,行人重识别最近也获得了广泛关注,在公开数据集上取得了显著的性能提升[1 -2 ] . 但是高昂的行人身份标注费用,在不同域(场景)下所获得行人图片在光照、背景、姿态等方面的巨大差异,给行人重识别在现实场景中的应用带来了巨大的挑战[1 ] . 同一个行人的频繁变装更使得当前的行人重识别技术难以应用于现实场景[3 ] . 为了有效应对这些挑战,越来越多研究者关注行人重识别域适应(domain adaptation, DA)[4 -7 ] 、换装行人重识别(cloth-changing person Re-id)[3 ] 等问题,提出了一些解决方法,并为行人重识别在现实场景中的应用打下基础. 同时,人脸识别随着深度学习的不断发展取得了显著的性能提升,实现了大规模的商用布置[8 -9 ] . 在现实布控的监控网络中,能够检测到人脸图片的行人可以将人脸信息融入到行人身份识别算法设计中,利用成熟的人脸识别算法提高整体行人身份识别准度,并结合改进的衣着信息消除模块来解决行人重识别中的行人换装问题,更多地利用身形姿态信息进行识别,提高行人身份识别算法在现实场景中的适应性. 将人脸识别和换装行人重识别引入到行人身份识别算法整体设计中,并通过先识别是否为已知行人然后识别具体行人类别的阈值过滤识别过程来识别行人身份,使得算法能更好地应用到现实场景. ...
... 随着深度学习的发展,人脸识别已经取得了显著的进展,并且已经成功应用于现实布控的安防系统[8 -9 ] . Schroff等[8 ] 提出的FaceNet引入困难三元组损失来监督模型的训练,取得了较好的精度. Wen等[9 ] 提出的Center Loss使用聚类和分类相结合的方式提取特征信息,使得相同身份的人脸特征在特征空间中有更加紧密的分布,因此实现了性能的提升. ...
... [9 ]提出的Center Loss使用聚类和分类相结合的方式提取特征信息,使得相同身份的人脸特征在特征空间中有更加紧密的分布,因此实现了性能的提升. ...
1
... 大多数的行人重识别都是以有监督的方式进行的,有监督行人重识别已经在现有的公开行人重识别数据集上实现了较高的性能[10 -13 ] . 有监督行人重识别在大量身份标注的基础上,通常使用主干网络提取图片的特征,利用基于交叉熵的分类损失和基于三元组的三元组损失[8 ] 监督整个模型的训练. 虽然在当前主流公开数据库中获得了卓越的性能表现,但是有监督行人重识别需要巨大的标注花销,而这在现实场景的行人重识别应用中往往是不现实的[1 ] . ...
1
... Comparison of person Re-id
Tab.3 模型 mAP Rank-1 ResNet-50[14 ] 10.7 13.3 SENet-50[24 ] 16.5 20.5 HACNN[17 ] 21.6 39.9 MuDeep[16 ] 22.7 40.2 PCB[11 ] 24.3 43.6 本研究所提模型 27.7 47.8
3.2.2. 人脸识别模型 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
1
... 大多数的行人重识别都是以有监督的方式进行的,有监督行人重识别已经在现有的公开行人重识别数据集上实现了较高的性能[10 -13 ] . 有监督行人重识别在大量身份标注的基础上,通常使用主干网络提取图片的特征,利用基于交叉熵的分类损失和基于三元组的三元组损失[8 ] 监督整个模型的训练. 虽然在当前主流公开数据库中获得了卓越的性能表现,但是有监督行人重识别需要巨大的标注花销,而这在现实场景的行人重识别应用中往往是不现实的[1 ] . ...
5
... 行人重识别分支整体结构如图2 所示,采用ResNet-50[14 ] 作为主干网络,并将改进的衣着信息消除模块分别嵌入到layer3、layer4后. 对于前端摄像机检测到的行人图片,将其输入到主干网络中提取特征,提取的特征图尺寸为[C ,H ,W ],C 、H 、W 分别为特征图的通道数、高度、宽度. 提取出的特征经过全局平局池化(global average pooling,GAP)后得到[C ,1,1]的向量,通过三元组损失(triplet loss)[8 ] 和分类损失(classification loss)进行约束训练,分类损失和三元组损失表达式如下: ...
... 人脸识别模型的结构如图5 所示,本研究使用ResNet-50[14 ] 作为主干网络提取特征,对于一张检测到的人脸图片,首先使用MTCNN[20 ] 网络来对齐人脸图片,将对齐后的人脸图片输入到主干网络中提取特征,提取的特征图尺寸为[C ,H ,W ]. 提取出的特征经过GAP后得到长度为C 的向量,通过三元组损失[8 ] 和分类损失来监督整个人脸识别模型的训练. ...
... Comparison of person Re-id
Tab.3 模型 mAP Rank-1 ResNet-50[14 ] 10.7 13.3 SENet-50[24 ] 16.5 20.5 HACNN[17 ] 21.6 39.9 MuDeep[16 ] 22.7 40.2 PCB[11 ] 24.3 43.6 本研究所提模型 27.7 47.8
3.2.2. 人脸识别模型 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
... Params and FLOPs of deep model
Tab.5 模型 P /M FLOPs/G 行人重识别模型 46.6 6.0 ResNet-50[14 ] (行人) 24.0 4.1 人脸识别模型 24.0 1.6 ResNet-50[14 ] (人脸) 24.0 1.6
系统计算耗时同样是行人身份识别系统在现实场景下应用的重要考量. 系统计算耗时如表6 所示. 表中,系统运行整体时间包含导入模型时间和运算时间,前者是指导入训练好的模型和已经构建好的人脸和行人特征库所需的时间,后者是指在读取到质询图片后经深度模型提取特征然后与特征库进行距离度量,最后将识别结果绘制成图形输出所需的时间. 可以看出,一次系统运行的大部分时间花费在模型导入过程中,而模型导入可以在程序运行初始完成,之后每次质询图片识别无须再进行模型导入,所以每次识别运行过程的实际时间消耗为运算时间. 在单张GTX1080ti设备下,包含人脸数据一次识别花费0.79 s,不包含人脸数据的行人识别由于无须人脸模型提取特征,消耗时间相对较少,为0.58 s. 在有更多算力资源的情况下,运行效率会更高. 在本研究所布置的现实场景下,监控网络并不是逐帧返回检测结果,在检测到一段移动行人数据后,才会将一个结构化数据传输给行人身份识别系统进行识别. 本研究系统应用在该现实场景下可以实时返回输出结果,满足布置的需求. ...
... [
14 ](人脸)
24.0 1.6 系统计算耗时同样是行人身份识别系统在现实场景下应用的重要考量. 系统计算耗时如表6 所示. 表中,系统运行整体时间包含导入模型时间和运算时间,前者是指导入训练好的模型和已经构建好的人脸和行人特征库所需的时间,后者是指在读取到质询图片后经深度模型提取特征然后与特征库进行距离度量,最后将识别结果绘制成图形输出所需的时间. 可以看出,一次系统运行的大部分时间花费在模型导入过程中,而模型导入可以在程序运行初始完成,之后每次质询图片识别无须再进行模型导入,所以每次识别运行过程的实际时间消耗为运算时间. 在单张GTX1080ti设备下,包含人脸数据一次识别花费0.79 s,不包含人脸数据的行人识别由于无须人脸模型提取特征,消耗时间相对较少,为0.58 s. 在有更多算力资源的情况下,运行效率会更高. 在本研究所布置的现实场景下,监控网络并不是逐帧返回检测结果,在检测到一段移动行人数据后,才会将一个结构化数据传输给行人身份识别系统进行识别. 本研究系统应用在该现实场景下可以实时返回输出结果,满足布置的需求. ...
1
... 对于ICESD模块的结构,首先将输入的特征图经过实例正则化(instance normalization,IN)[15 ] 去风格化,经过去风格化,可以消除掉与身份无关的衣着信息这些风格信息,保留下需要的身份特定的身份信息. 这个过程可以表示为 ...
Leader-based multi-scale attention deep architecture for person re-identification
2
2020
... 原始输入的特征包含身份信息和风格信息,去风格化后的特征包含大部分身份信息和部分的风格信息. 原始特征减去去风格化后的包含一定身份信息的特征得到包含行人身份信息和衣着信息的特征 $ {f}^{{\rm{S}}} $ 图4 (a)所示. 通过注意力模块[16 -19 ] ,分别关注对身份信息和衣着信息最显著的区域,这个过程可以表示为 ...
... Comparison of person Re-id
Tab.3 模型 mAP Rank-1 ResNet-50[14 ] 10.7 13.3 SENet-50[24 ] 16.5 20.5 HACNN[17 ] 21.6 39.9 MuDeep[16 ] 22.7 40.2 PCB[11 ] 24.3 43.6 本研究所提模型 27.7 47.8
3.2.2. 人脸识别模型 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
1
... Comparison of person Re-id
Tab.3 模型 mAP Rank-1 ResNet-50[14 ] 10.7 13.3 SENet-50[24 ] 16.5 20.5 HACNN[17 ] 21.6 39.9 MuDeep[16 ] 22.7 40.2 PCB[11 ] 24.3 43.6 本研究所提模型 27.7 47.8
3.2.2. 人脸识别模型 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
1
... 原始输入的特征包含身份信息和风格信息,去风格化后的特征包含大部分身份信息和部分的风格信息. 原始特征减去去风格化后的包含一定身份信息的特征得到包含行人身份信息和衣着信息的特征 $ {f}^{{\rm{S}}} $ 图4 (a)所示. 通过注意力模块[16 -19 ] ,分别关注对身份信息和衣着信息最显著的区域,这个过程可以表示为 ...
1
... 原始输入的特征包含身份信息和风格信息,去风格化后的特征包含大部分身份信息和部分的风格信息. 原始特征减去去风格化后的包含一定身份信息的特征得到包含行人身份信息和衣着信息的特征 $ {f}^{{\rm{S}}} $ 图4 (a)所示. 通过注意力模块[16 -19 ] ,分别关注对身份信息和衣着信息最显著的区域,这个过程可以表示为 ...
Joint face detection and alignment using multitask cascaded convolutional networks
2
2016
... 人脸识别模型的结构如图5 所示,本研究使用ResNet-50[14 ] 作为主干网络提取特征,对于一张检测到的人脸图片,首先使用MTCNN[20 ] 网络来对齐人脸图片,将对齐后的人脸图片输入到主干网络中提取特征,提取的特征图尺寸为[C ,H ,W ]. 提取出的特征经过GAP后得到长度为C 的向量,通过三元组损失[8 ] 和分类损失来监督整个人脸识别模型的训练. ...
... 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...
1
... 对数据库中的数据进行统计,平均一个人有5次变装. 对数据集中属于同一个类别的特征进行聚类,用不同聚类中心分别代表一个行人身份的不同穿着(风格). 本研究采用K-means聚类方法,聚类数设定为5,最终选择这5个聚类中心作为该类别的特征,存储在特征库中,这样每个类别有5个特征. 在测试时,若质询图片与任一类别的5个特征的任何一个最为相似,且符合设定的阈值条件,即认为该质询图片属于这一类别[21 -22 ] . 分别对人脸识别和行人重识别提取人脸特征库和行人特征库. ...
1
... 对数据库中的数据进行统计,平均一个人有5次变装. 对数据集中属于同一个类别的特征进行聚类,用不同聚类中心分别代表一个行人身份的不同穿着(风格). 本研究采用K-means聚类方法,聚类数设定为5,最终选择这5个聚类中心作为该类别的特征,存储在特征库中,这样每个类别有5个特征. 在测试时,若质询图片与任一类别的5个特征的任何一个最为相似,且符合设定的阈值条件,即认为该质询图片属于这一类别[21 -22 ] . 分别对人脸识别和行人重识别提取人脸特征库和行人特征库. ...
3
... 针对行人重识别模型,使用域适应的方法,首先在公开数据集Market1501[23 ] 上进行预训练,然后在标记的数据上进行精调,使其适应到数据的域中. 在Market1501[23 ] 源域数据集上的预训练只使用随机水平翻转数据增强,训练用行人图片放缩至256×128大小,然后输入行人重识别模型进行训练,采用SGD优化器,初始学习率为0.001,总共训练500个回合,每100个回合衰减至1/10. 无须在源域数据上进行测试,因此,原Market1501[23 ] 数据集中的训练数据和测试数据均用来训练. 在标记的数据上进行精调时,采用早停策略,即在采集的数据域上,当模型还未在训练数据上完全收敛时,选择在验证集上获得最高准确度时的模型. 本研究的算法在行人数据上的效果如表1 所示. 表中,A 为准度. ...
... [23 ]源域数据集上的预训练只使用随机水平翻转数据增强,训练用行人图片放缩至256×128大小,然后输入行人重识别模型进行训练,采用SGD优化器,初始学习率为0.001,总共训练500个回合,每100个回合衰减至1/10. 无须在源域数据上进行测试,因此,原Market1501[23 ] 数据集中的训练数据和测试数据均用来训练. 在标记的数据上进行精调时,采用早停策略,即在采集的数据域上,当模型还未在训练数据上完全收敛时,选择在验证集上获得最高准确度时的模型. 本研究的算法在行人数据上的效果如表1 所示. 表中,A 为准度. ...
... [23 ]数据集中的训练数据和测试数据均用来训练. 在标记的数据上进行精调时,采用早停策略,即在采集的数据域上,当模型还未在训练数据上完全收敛时,选择在验证集上获得最高准确度时的模型. 本研究的算法在行人数据上的效果如表1 所示. 表中,A 为准度. ...
1
... Comparison of person Re-id
Tab.3 模型 mAP Rank-1 ResNet-50[14 ] 10.7 13.3 SENet-50[24 ] 16.5 20.5 HACNN[17 ] 21.6 39.9 MuDeep[16 ] 22.7 40.2 PCB[11 ] 24.3 43.6 本研究所提模型 27.7 47.8
3.2.2. 人脸识别模型 针对人脸识别模型,同样使用域适应的方法,首先在公开数据集CASIA上进行预训练,然后在所标记的数据上进行精调,以使其适应到数据的域中. 在CASIA源域数据集上的预训练与文献[6 ]一致,训练用人脸图片经MTCNN[20 ] 网络对齐后放缩至224×224大小,然后输入人脸识别模型进行训练[6 ] . 无须在源域数据上进行测试,因此,将原CASIA数据集中的训练数据和测试数据均用于训练. 在所采集的数据上精调时,因为标记数据较少,为了防止过拟合,同样采用早停策略. 本研究算法在人脸数据上实现了卓越的性能表现,在Rank-1、正样本正确划分率、无关样本正确划分率上分别实现100%、97.70%、99.93%的性能表现. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}