[1]
MOROZOV A Development of a method for intelligent video monitoring of abnormal behavior of people based on parallel object-oriented logic programming
[J]. Pattern Recognition and Image Analysis , 2015 , 25 (3 ): 481 - 492
DOI:10.1134/S1054661815030153
[本文引用: 1]
[2]
CHEN D, BHARUCHA A J, WACTLAR H D. Intelligent video monitoring to improve safety of older persons [C]// Proceedings of the 29th Annual International Conference of the IEEE-Engineering-in-Medicine-and-Biology-Society . Lyon: IEEE, 2007: 3814-3817.
[本文引用: 1]
[3]
CHANG C-K, SIAGIAN C, ITTI L. Mobile robot vision navigation and localization using gist and saliency [C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems . Taipei: IEEE, 2010: 4147-4154.
[本文引用: 1]
[7]
HENRIQUES J F, CASEIRO R, MARTINS P, et al High-speed tracking with kernelized correlation filters
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (3 ): 583 - 596
DOI:10.1109/TPAMI.2014.2345390
[本文引用: 1]
[8]
YANG L, ZHU J. A scale adaptive kernel correlation filter tracker with feature integration [C]// Proceedings of the 13th European Conference on Computer Vision. Zurich: Springer, 2014: 254-265.
[本文引用: 1]
[9]
BERTINETTO L, VALMADRE J, GOLODETZ S, et al. Staple: complementary learners for real-time tracking [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2016: 1401-1409.
[本文引用: 3]
[10]
DANELLJAN M, HAGER G, SHAHBAZ KHAN F, et al. Convolutional features for correlation filter based visual tracking [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 58-66.
[本文引用: 1]
[11]
MA C, HUANG J B, YANG X, et al. Hierarchical convolutional features for visual tracking[C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2016.
[本文引用: 2]
[12]
CHOI J, KWON J, LEE K M. Deep meta learning for real-time target-aware visual tracking [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 911-920.
[本文引用: 1]
[13]
XU T, FENG Z, WU X, et al. Joint group feature selection and discriminative filter learning for robust visual object tracking [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 7949-7959.
[本文引用: 1]
[14]
TANG M, FENG J. Multi-kernel correlation filter for visual tracking [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2016: 3038-3046.
[本文引用: 1]
[15]
BHAT G, DANELLJAN M, VAN GOOL L, et al. Learning discriminative model prediction for tracking [C]// proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 6181-6190.
[本文引用: 1]
[16]
LI P, CHEN B, OUYANG W, et al. GradNet: gradient-guided network for visual object tracking [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 6161-6170.
[本文引用: 1]
[17]
GALOOGAHI H K, FAGG A, LUCEY S. Learning background-aware correlation filters for visual tracking [C]// Proceedings of the 16th IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 1144-1152.
[本文引用: 3]
[18]
GALOOGAHI H K, SIM T, LUCEY S. Correlation filters with limited boundaries [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 4630-4638.
[本文引用: 1]
[19]
DANELLJAN M, HÄGER G, KHAN F S, et al. Learning spatially regularized correlation filters for visual tracking [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 4310-4318.
[本文引用: 3]
[20]
MUELLER M, SMITH N, GHANEM B. Context-aware correlation filter tracking [C]// Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1387-1395.
[本文引用: 2]
[21]
LUKEI A, VOJÍ T, EHOVINZAJC L, et al. Discriminative correlation filter with channel and spatial reliability [C]// Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2018: 4847-4856.
[本文引用: 3]
[22]
HUANG Z, FU C, LI Y, et al. Learning aberrance repressed correlation filters for real-time UAV tracking [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 2891-2900.
[本文引用: 3]
[23]
LI Y, ZHU J. A scale adaptive kernel correlation filter tracker with feature integration [C]// Proceedings of the 13th European Conference on Computer Vision. Zurich: Springer, 2014: 254-265.
[本文引用: 3]
[24]
DANELLJAN M, HÄGER G, KHAN F S, et al. Accurate scale estimation for robust visual tracking [C]// Proceedings of the British Machine Vision Conference . Nottingham: [s.n.], 2014: 1-5.
[本文引用: 1]
[25]
DANELLJAN M, HAGER G, KHAN F S, et al Discriminative scale space tracking
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (8 ): 1561 - 1575
DOI:10.1109/TPAMI.2016.2609928
[本文引用: 3]
[26]
WANG X, HOU Z, YU W, et al Robust occlusion-aware part-based visual tracking with object scale adaptation
[J]. Pattern Recognition , 2018 , 81 : 456 - 470
DOI:10.1016/j.patcog.2018.04.011
[本文引用: 1]
[27]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
[本文引用: 1]
[28]
QI Y, ZHANG S, QIN L, et al. Hedged deep tracking [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2016: 4303-4311.
[本文引用: 2]
[29]
VALMADRE J, BERTINETTO L, HENRIQUES J, et al. End-to-end representation learning for correlation filter based tracking [C]// Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 5000-5008.
[本文引用: 2]
[30]
BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional siamese networks for object tracking [C]// Proceedings of the 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 850-865.
[本文引用: 2]
[31]
DANELLJAN M, ROBINSON A, KHAN F S, et al. Beyond correlation filters: learning continuous convolution operators for visual tracking [C]// Proceedings of the 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 472-488.
[本文引用: 1]
[32]
HUANG L, ZHAO X, HUANG K, et al. Bridging the gap between detection and tracking: a unified approach [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3998-4008.
[本文引用: 1]
[33]
WU Y, LIM J, YANG M-H, et al. Online object tracking: a benchmark [C]// Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition. Portland: IEEE, 2013: 2411-2418.
[本文引用: 1]
[34]
WU Y, LIM J, YANG M-H Object tracking benchmark
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1834 - 1848
DOI:10.1109/TPAMI.2014.2388226
[本文引用: 1]
[35]
LIANG P, BLASCH E, LING H Encoding color information for visual tracking: algorithms and benchmark
[J]. IEEE Transactions on Image Processing , 2015 , 24 (12 ): 5630 - 5644
DOI:10.1109/TIP.2015.2482905
[本文引用: 1]
[36]
WANG M, LIU Y, HUANG Z, et al. Large margin object tracking with circulant feature maps [C]// Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 4800-4808.
[本文引用: 1]
[37]
MA C, YANG X, ZHANG C, et al. Long-term correlation tracking [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 5388-5396.
[本文引用: 2]
[38]
ZHANG J, MA S, SCLAROFF S. MEEM: robust tracking via multiple experts using entropy minimization [C]// Proceedings of the 13th European Conference on Computer Vision. Zurich: Springer, 2014: 188-203.
[本文引用: 2]
[39]
WANG Q, GAO J, XING J, et al. DCFNet: discriminant correlation filters network for visual tracking [EB/OL]. [2017-04-13]. http://arxiv.org/abs/1704.04057.
[本文引用: 1]
[40]
CHOI J, CHANG H J, YUN S, et al. Attentional correlation filter network for adaptive visual tracking [C]// Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 4828-4837.
[本文引用: 1]
[41]
LI D, PORIKLI F, WEN G, et al When correlation filters meet siamese networks for real-time complementary tracking
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2020 , 30 (2 ): 509 - 519
DOI:10.1109/TCSVT.2019.2892759
[本文引用: 1]
[42]
HAN R, FENG W, WANG S Fast learning of spatially regularized and content aware correlation filter for visual tracking
[J]. IEEE Transactions on Image Processing , 2020 , 29 : 7128 - 7140
DOI:10.1109/TIP.2020.2998978
[本文引用: 1]
[43]
ZHOU Y, LI J, DU B, et al A target response adaptive correlation filter tracker with spatial attention
[J]. Multimedia Tools And Applications , 2020 , 79 (29/30 ): 20521 - 20543
URL
[本文引用: 1]
[44]
WANG H, WANG Z, FANG B, et al Temporal–spatial consistency of self-adaptive target response for long-term correlation filter tracking
[J]. Signal, Image and Video Processing , 2020 , 14 (4 ): 639 - 644
DOI:10.1007/s11760-019-01594-2
[本文引用: 1]
[45]
CHEN G, PAN G, ZHOU Y, et al Correlation filter tracking via distractor-aware learning and multi-anchor detection
[J]. IEEE Transactions on Circuits And Systems for Video Technology , 2020 , 30 (12 ): 4810 - 4822
DOI:10.1109/TCSVT.2019.2961999
[本文引用: 1]
[46]
BOURAFFA T, YAN L, FENG Z, et al Context-aware correlation filter learning toward peak strength for visual tracking
[J]. IEEE Transactions on Cybernetics , 2019 , 99 : 1 - 11
URL
[本文引用: 1]
Development of a method for intelligent video monitoring of abnormal behavior of people based on parallel object-oriented logic programming
1
2015
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
1
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
1
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
一种改进的医学图像目标轮廓跟踪算法
1
2012
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
一种改进的医学图像目标轮廓跟踪算法
1
2012
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
基于颜色和方向梯度特征融合的粒子滤波跟踪算法
1
2014
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
基于颜色和方向梯度特征融合的粒子滤波跟踪算法
1
2014
... 目标跟踪是机器视觉主流的研究方向之一,它广泛应用于智能视频监控[1 -2 ] 、机器人视觉导航[3 ] 、医学诊断[4 ] 等领域. 目标跟踪过程容易受到复杂背景干扰,从而导致跟踪漂移甚至目标丢失;因此,如何研究出鲁棒性强、实时性好及跟踪精度高的模型成为目标跟踪研究的重点之一[5 ] . ...
基于局部直方图的多区域目标跟踪算法
1
2018
... 复杂背景干扰主要包括相似背景干扰、光照变化及遮挡等[6 ] 情况. 为了解决这些问题,国内外学者都开展了许多研究. 其中相关滤波算法受到了广泛的应用,这得益于简洁的原理和高效的计算速度. 在面对背景干扰的问题上,相关滤波面临很大的挑战. ...
基于局部直方图的多区域目标跟踪算法
1
2018
... 复杂背景干扰主要包括相似背景干扰、光照变化及遮挡等[6 ] 情况. 为了解决这些问题,国内外学者都开展了许多研究. 其中相关滤波算法受到了广泛的应用,这得益于简洁的原理和高效的计算速度. 在面对背景干扰的问题上,相关滤波面临很大的挑战. ...
High-speed tracking with kernelized correlation filters
1
2015
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
3
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
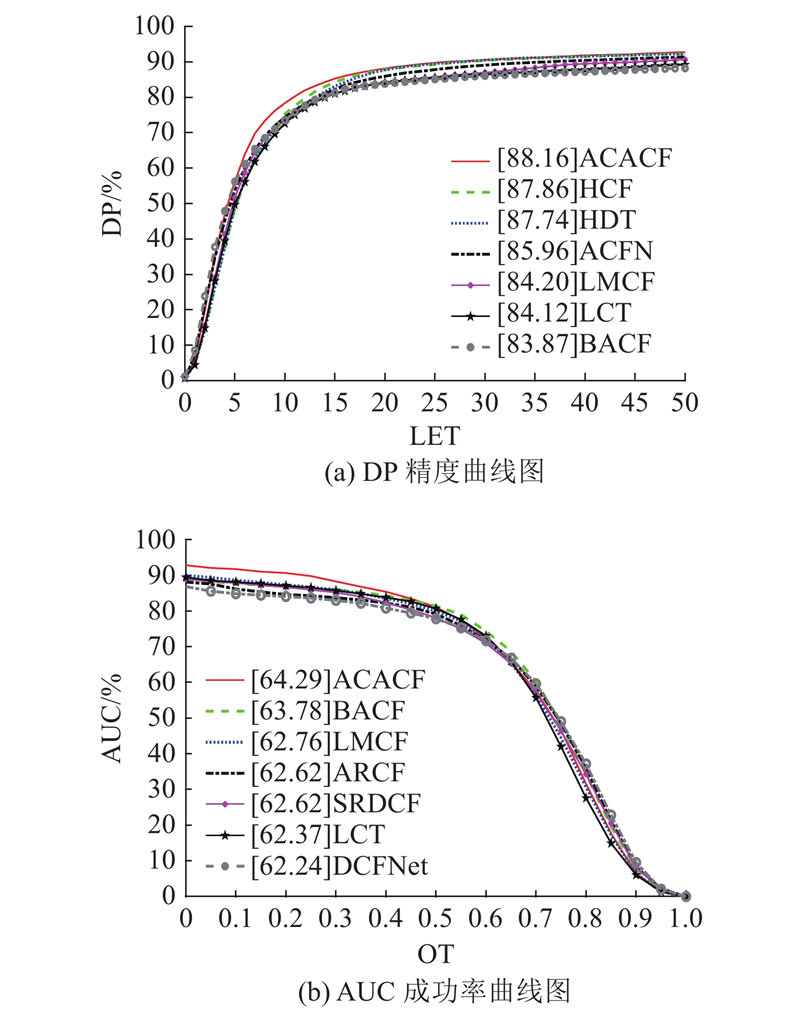
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
2
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
1
... 针对背景干扰的问题,一些学者对目标区域的特征进行改进. Henriques等[7 ] 采用方向梯度直方图(histogram of oriented gradient,HOG)特征的同时引入脊回归,在增强跟踪性能的同时保证了滤波器的鲁棒性. Yang等[8 ] 结合HOG特征和颜色特征(color name,CN),使得模型能够适应更广泛的场景. Bertinetto等[9 ] 融合HOG特征和CN特征,综合跟踪得分信息与统计得分信息,提高了跟踪算法的准确度. Danelljan等[10 ] 将深度特征引入目标跟踪中,该算法用深度学习网络提取目标特征,使得特征具有更好的抵抗复杂背景和噪声干扰的能力. Ma等[11 ] 采用多层卷积的特征,对目标进行更深层次的表达. Choi等[12 ] 融合meta-learner网络提取的特征与Siamese网络提取的特征,得到自适应的目标特征. Xu[13 ] 等在空间层面和通道层面对提取的特征进行选择,减少多通道特征的冗余性. 除了对特征进行改进,Tang等[14 ] 引入多核方法,能够更有效地将目标从搜索区域中分离出来. Bhat等[15 ] 建立端到端学习,考虑背景信息,能够更好地区分目标. Li等[16 ] 利用梯度信息对模板进行更新,提高了跟踪精度. 这些方法通过改善目标区域的特征和模型学习能力,从而抵抗复杂的背景干扰,提高模型的跟踪性能. ...
3
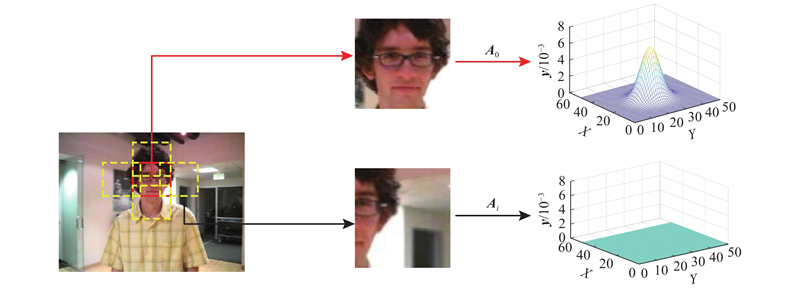
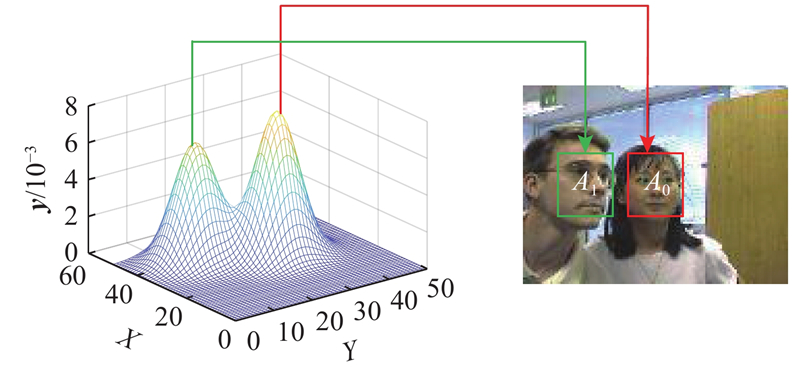
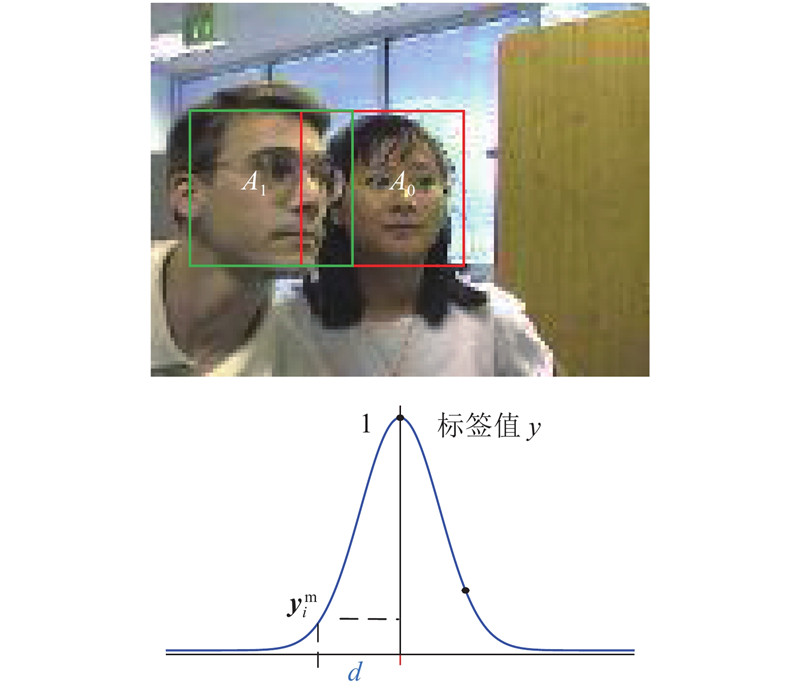
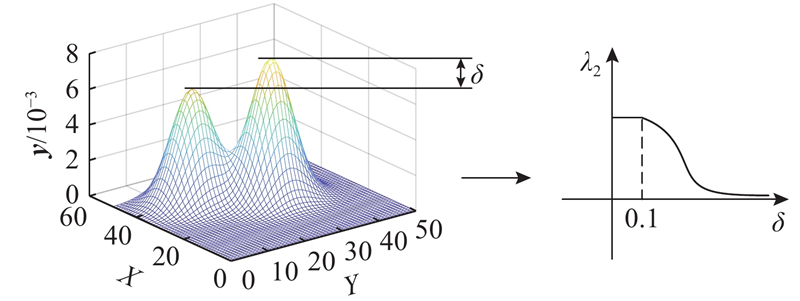
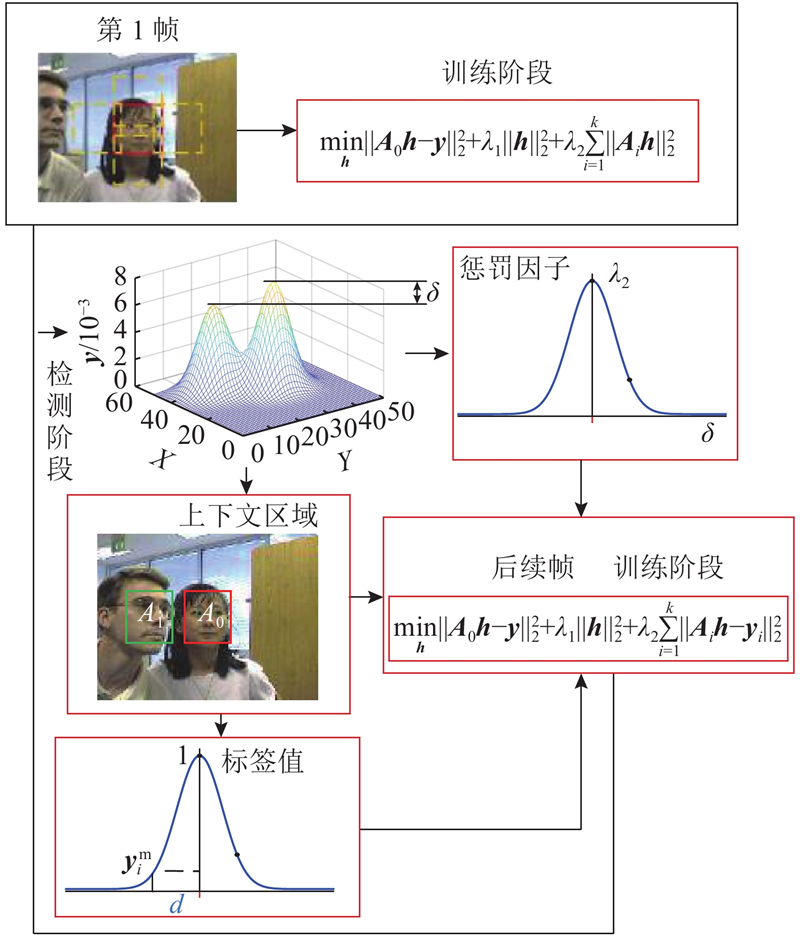
... 目前,目标跟踪算法分为相关滤波和深度学习2个主流方向. 相关滤波类算法的性能受背景干扰的影响,也受限于边界效应和尺度问题. 为了减缓边界效应,Galoogahi等[17 ] 采用更大的搜索域,利用裁剪矩阵以获得循环位移后真实的负样本. Galoogahi等[18 ] 采用较大的检测图像块并引入空间约束,保持样本的真实性. Danelljan等[19 ] 对滤波器增加正则化的惩罚系数,减少边界部分的背景响应. 上下文感知方法[20 ] (context-aware correlation filter tracking,CACF)通过引入上下文区域作为负样本,对上下文区域的响应进行抑制,从而解决背景干扰及边界效应. Lukei等[21 ] 融合空间可靠性和通道可靠性,让滤波器更专注于对目标区域的建模. Huang等[22 ] 通过对检测阶段生成的响应图变化速率进行限制,从而抑制边界效应. 这些方法能够抑制由循环位移带来的边界效应影响,但是对于较复杂的背景干扰,存在一定的局限性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
1
... 目前,目标跟踪算法分为相关滤波和深度学习2个主流方向. 相关滤波类算法的性能受背景干扰的影响,也受限于边界效应和尺度问题. 为了减缓边界效应,Galoogahi等[17 ] 采用更大的搜索域,利用裁剪矩阵以获得循环位移后真实的负样本. Galoogahi等[18 ] 采用较大的检测图像块并引入空间约束,保持样本的真实性. Danelljan等[19 ] 对滤波器增加正则化的惩罚系数,减少边界部分的背景响应. 上下文感知方法[20 ] (context-aware correlation filter tracking,CACF)通过引入上下文区域作为负样本,对上下文区域的响应进行抑制,从而解决背景干扰及边界效应. Lukei等[21 ] 融合空间可靠性和通道可靠性,让滤波器更专注于对目标区域的建模. Huang等[22 ] 通过对检测阶段生成的响应图变化速率进行限制,从而抑制边界效应. 这些方法能够抑制由循环位移带来的边界效应影响,但是对于较复杂的背景干扰,存在一定的局限性. ...
3
... 目前,目标跟踪算法分为相关滤波和深度学习2个主流方向. 相关滤波类算法的性能受背景干扰的影响,也受限于边界效应和尺度问题. 为了减缓边界效应,Galoogahi等[17 ] 采用更大的搜索域,利用裁剪矩阵以获得循环位移后真实的负样本. Galoogahi等[18 ] 采用较大的检测图像块并引入空间约束,保持样本的真实性. Danelljan等[19 ] 对滤波器增加正则化的惩罚系数,减少边界部分的背景响应. 上下文感知方法[20 ] (context-aware correlation filter tracking,CACF)通过引入上下文区域作为负样本,对上下文区域的响应进行抑制,从而解决背景干扰及边界效应. Lukei等[21 ] 融合空间可靠性和通道可靠性,让滤波器更专注于对目标区域的建模. Huang等[22 ] 通过对检测阶段生成的响应图变化速率进行限制,从而抑制边界效应. 这些方法能够抑制由循环位移带来的边界效应影响,但是对于较复杂的背景干扰,存在一定的局限性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
2
... 目前,目标跟踪算法分为相关滤波和深度学习2个主流方向. 相关滤波类算法的性能受背景干扰的影响,也受限于边界效应和尺度问题. 为了减缓边界效应,Galoogahi等[17 ] 采用更大的搜索域,利用裁剪矩阵以获得循环位移后真实的负样本. Galoogahi等[18 ] 采用较大的检测图像块并引入空间约束,保持样本的真实性. Danelljan等[19 ] 对滤波器增加正则化的惩罚系数,减少边界部分的背景响应. 上下文感知方法[20 ] (context-aware correlation filter tracking,CACF)通过引入上下文区域作为负样本,对上下文区域的响应进行抑制,从而解决背景干扰及边界效应. Lukei等[21 ] 融合空间可靠性和通道可靠性,让滤波器更专注于对目标区域的建模. Huang等[22 ] 通过对检测阶段生成的响应图变化速率进行限制,从而抑制边界效应. 这些方法能够抑制由循环位移带来的边界效应影响,但是对于较复杂的背景干扰,存在一定的局限性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
3
... 目前,目标跟踪算法分为相关滤波和深度学习2个主流方向. 相关滤波类算法的性能受背景干扰的影响,也受限于边界效应和尺度问题. 为了减缓边界效应,Galoogahi等[17 ] 采用更大的搜索域,利用裁剪矩阵以获得循环位移后真实的负样本. Galoogahi等[18 ] 采用较大的检测图像块并引入空间约束,保持样本的真实性. Danelljan等[19 ] 对滤波器增加正则化的惩罚系数,减少边界部分的背景响应. 上下文感知方法[20 ] (context-aware correlation filter tracking,CACF)通过引入上下文区域作为负样本,对上下文区域的响应进行抑制,从而解决背景干扰及边界效应. Lukei等[21 ] 融合空间可靠性和通道可靠性,让滤波器更专注于对目标区域的建模. Huang等[22 ] 通过对检测阶段生成的响应图变化速率进行限制,从而抑制边界效应. 这些方法能够抑制由循环位移带来的边界效应影响,但是对于较复杂的背景干扰,存在一定的局限性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
3
... 目前,目标跟踪算法分为相关滤波和深度学习2个主流方向. 相关滤波类算法的性能受背景干扰的影响,也受限于边界效应和尺度问题. 为了减缓边界效应,Galoogahi等[17 ] 采用更大的搜索域,利用裁剪矩阵以获得循环位移后真实的负样本. Galoogahi等[18 ] 采用较大的检测图像块并引入空间约束,保持样本的真实性. Danelljan等[19 ] 对滤波器增加正则化的惩罚系数,减少边界部分的背景响应. 上下文感知方法[20 ] (context-aware correlation filter tracking,CACF)通过引入上下文区域作为负样本,对上下文区域的响应进行抑制,从而解决背景干扰及边界效应. Lukei等[21 ] 融合空间可靠性和通道可靠性,让滤波器更专注于对目标区域的建模. Huang等[22 ] 通过对检测阶段生成的响应图变化速率进行限制,从而抑制边界效应. 这些方法能够抑制由循环位移带来的边界效应影响,但是对于较复杂的背景干扰,存在一定的局限性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
3
... 尺度估计方法通过对目标建立合适的尺度模型,最大程度地学习到目标模型,减少无用的背景信息. Li等[23 ] 将单一特征扩展为多个特征,建立不同的尺度池来实现对目标尺度的自适应. 该方法需要设置尺度步长,步长设置不合理会出现偏移过大的情况. Danelljan等[24 ] 训练2个不同的滤波器,分别用来跟踪及尺度估计,目标变化大则尺度估计不准. Danelljan在原有的基础上引入特征降维和插值方法[25 ] ,使得算法在精度和速度上都有提升. Wang等[26 ] 结合深度特征提出单独的平移和尺度估计,完成目标的精确定位. Girshick等[27 ] 提出基于深度学习的方法进行目标的尺度估计,能够更好地建立目标的尺度模型. 这类方法没有很好的更新策略,容易受到目标周围复杂背景的干扰. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
1
... 尺度估计方法通过对目标建立合适的尺度模型,最大程度地学习到目标模型,减少无用的背景信息. Li等[23 ] 将单一特征扩展为多个特征,建立不同的尺度池来实现对目标尺度的自适应. 该方法需要设置尺度步长,步长设置不合理会出现偏移过大的情况. Danelljan等[24 ] 训练2个不同的滤波器,分别用来跟踪及尺度估计,目标变化大则尺度估计不准. Danelljan在原有的基础上引入特征降维和插值方法[25 ] ,使得算法在精度和速度上都有提升. Wang等[26 ] 结合深度特征提出单独的平移和尺度估计,完成目标的精确定位. Girshick等[27 ] 提出基于深度学习的方法进行目标的尺度估计,能够更好地建立目标的尺度模型. 这类方法没有很好的更新策略,容易受到目标周围复杂背景的干扰. ...
Discriminative scale space tracking
3
2017
... 尺度估计方法通过对目标建立合适的尺度模型,最大程度地学习到目标模型,减少无用的背景信息. Li等[23 ] 将单一特征扩展为多个特征,建立不同的尺度池来实现对目标尺度的自适应. 该方法需要设置尺度步长,步长设置不合理会出现偏移过大的情况. Danelljan等[24 ] 训练2个不同的滤波器,分别用来跟踪及尺度估计,目标变化大则尺度估计不准. Danelljan在原有的基础上引入特征降维和插值方法[25 ] ,使得算法在精度和速度上都有提升. Wang等[26 ] 结合深度特征提出单独的平移和尺度估计,完成目标的精确定位. Girshick等[27 ] 提出基于深度学习的方法进行目标的尺度估计,能够更好地建立目标的尺度模型. 这类方法没有很好的更新策略,容易受到目标周围复杂背景的干扰. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
Robust occlusion-aware part-based visual tracking with object scale adaptation
1
2018
... 尺度估计方法通过对目标建立合适的尺度模型,最大程度地学习到目标模型,减少无用的背景信息. Li等[23 ] 将单一特征扩展为多个特征,建立不同的尺度池来实现对目标尺度的自适应. 该方法需要设置尺度步长,步长设置不合理会出现偏移过大的情况. Danelljan等[24 ] 训练2个不同的滤波器,分别用来跟踪及尺度估计,目标变化大则尺度估计不准. Danelljan在原有的基础上引入特征降维和插值方法[25 ] ,使得算法在精度和速度上都有提升. Wang等[26 ] 结合深度特征提出单独的平移和尺度估计,完成目标的精确定位. Girshick等[27 ] 提出基于深度学习的方法进行目标的尺度估计,能够更好地建立目标的尺度模型. 这类方法没有很好的更新策略,容易受到目标周围复杂背景的干扰. ...
1
... 尺度估计方法通过对目标建立合适的尺度模型,最大程度地学习到目标模型,减少无用的背景信息. Li等[23 ] 将单一特征扩展为多个特征,建立不同的尺度池来实现对目标尺度的自适应. 该方法需要设置尺度步长,步长设置不合理会出现偏移过大的情况. Danelljan等[24 ] 训练2个不同的滤波器,分别用来跟踪及尺度估计,目标变化大则尺度估计不准. Danelljan在原有的基础上引入特征降维和插值方法[25 ] ,使得算法在精度和速度上都有提升. Wang等[26 ] 结合深度特征提出单独的平移和尺度估计,完成目标的精确定位. Girshick等[27 ] 提出基于深度学习的方法进行目标的尺度估计,能够更好地建立目标的尺度模型. 这类方法没有很好的更新策略,容易受到目标周围复杂背景的干扰. ...
2
... 除了相关的滤波类跟踪算法外,深度学习类跟踪算法在目标跟踪算法中有很广泛的应用. Qi等[28 ] 通过对不同卷积层的特征分别进行处理,组合得到更强力的滤波器. Valmadre等[29 ] 引入相关滤波到SiamFC[30 ] 结构,开展端到端的网络训练,减少了卷积的层数. Danelljan等[31 ] 在连续的空间域中学习一个判别算子,在融合多分辨率特征的同时实现了亚像素的定位. Huang等[32 ] 将检测引入跟踪,通过2个网络分别选取相似样本,区分分类目标. 深度学习能够对目标进行更精确的表征,但是由于计算速度较慢,对硬件的要求较高,难以在CPU上满足实时性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
2
... 除了相关的滤波类跟踪算法外,深度学习类跟踪算法在目标跟踪算法中有很广泛的应用. Qi等[28 ] 通过对不同卷积层的特征分别进行处理,组合得到更强力的滤波器. Valmadre等[29 ] 引入相关滤波到SiamFC[30 ] 结构,开展端到端的网络训练,减少了卷积的层数. Danelljan等[31 ] 在连续的空间域中学习一个判别算子,在融合多分辨率特征的同时实现了亚像素的定位. Huang等[32 ] 将检测引入跟踪,通过2个网络分别选取相似样本,区分分类目标. 深度学习能够对目标进行更精确的表征,但是由于计算速度较慢,对硬件的要求较高,难以在CPU上满足实时性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
2
... 除了相关的滤波类跟踪算法外,深度学习类跟踪算法在目标跟踪算法中有很广泛的应用. Qi等[28 ] 通过对不同卷积层的特征分别进行处理,组合得到更强力的滤波器. Valmadre等[29 ] 引入相关滤波到SiamFC[30 ] 结构,开展端到端的网络训练,减少了卷积的层数. Danelljan等[31 ] 在连续的空间域中学习一个判别算子,在融合多分辨率特征的同时实现了亚像素的定位. Huang等[32 ] 将检测引入跟踪,通过2个网络分别选取相似样本,区分分类目标. 深度学习能够对目标进行更精确的表征,但是由于计算速度较慢,对硬件的要求较高,难以在CPU上满足实时性. ...
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
1
... 除了相关的滤波类跟踪算法外,深度学习类跟踪算法在目标跟踪算法中有很广泛的应用. Qi等[28 ] 通过对不同卷积层的特征分别进行处理,组合得到更强力的滤波器. Valmadre等[29 ] 引入相关滤波到SiamFC[30 ] 结构,开展端到端的网络训练,减少了卷积的层数. Danelljan等[31 ] 在连续的空间域中学习一个判别算子,在融合多分辨率特征的同时实现了亚像素的定位. Huang等[32 ] 将检测引入跟踪,通过2个网络分别选取相似样本,区分分类目标. 深度学习能够对目标进行更精确的表征,但是由于计算速度较慢,对硬件的要求较高,难以在CPU上满足实时性. ...
1
... 除了相关的滤波类跟踪算法外,深度学习类跟踪算法在目标跟踪算法中有很广泛的应用. Qi等[28 ] 通过对不同卷积层的特征分别进行处理,组合得到更强力的滤波器. Valmadre等[29 ] 引入相关滤波到SiamFC[30 ] 结构,开展端到端的网络训练,减少了卷积的层数. Danelljan等[31 ] 在连续的空间域中学习一个判别算子,在融合多分辨率特征的同时实现了亚像素的定位. Huang等[32 ] 将检测引入跟踪,通过2个网络分别选取相似样本,区分分类目标. 深度学习能够对目标进行更精确的表征,但是由于计算速度较慢,对硬件的要求较高,难以在CPU上满足实时性. ...
1
... 该算法在Intel core(TM)i7-4700MQ、CPU@2.40 GHz、8 GB内存的PC机上用Matlab R2017b编程实现的. 实验选取OTB2013[33 ] 、OTB2015[34 ] 和Temple-Color128[35 ] 所有视频序列,验证提出的算法在快速移动、背景混杂、目标变形及遮挡情况下所表现的性能. ...
Object tracking benchmark
1
2015
... 该算法在Intel core(TM)i7-4700MQ、CPU@2.40 GHz、8 GB内存的PC机上用Matlab R2017b编程实现的. 实验选取OTB2013[33 ] 、OTB2015[34 ] 和Temple-Color128[35 ] 所有视频序列,验证提出的算法在快速移动、背景混杂、目标变形及遮挡情况下所表现的性能. ...
Encoding color information for visual tracking: algorithms and benchmark
1
2015
... 该算法在Intel core(TM)i7-4700MQ、CPU@2.40 GHz、8 GB内存的PC机上用Matlab R2017b编程实现的. 实验选取OTB2013[33 ] 、OTB2015[34 ] 和Temple-Color128[35 ] 所有视频序列,验证提出的算法在快速移动、背景混杂、目标变形及遮挡情况下所表现的性能. ...
1
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
2
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
2
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
1
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
1
... 对比算法. 本文算法(ACACF)基于相关滤波框架,对比传统CACF[20 ] 算法与K =1,2,3,4时的性能. 将本文算法与现有的优秀算法进行对比,其中包括相关滤波类跟踪算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LMCF[36 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),也包括基于深度特征和深度学习类跟踪算法(CFNet[29 ] 、SiamFC[30 ] 、DCFNet[39 ] 、ACFN[40 ] 、HDT[28 ] 、HCF[11 ] ). 对比算法中最优秀的7种算法. ...
When correlation filters meet siamese networks for real-time complementary tracking
1
2020
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
Fast learning of spatially regularized and content aware correlation filter for visual tracking
1
2020
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
A target response adaptive correlation filter tracker with spatial attention
1
2020
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
Temporal–spatial consistency of self-adaptive target response for long-term correlation filter tracking
1
2020
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
Correlation filter tracking via distractor-aware learning and multi-anchor detection
1
2020
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...
Context-aware correlation filter learning toward peak strength for visual tracking
1
2019
... 为了测试本文算法在更具挑战性的数据集上的跟踪效果,选取Temple-Color128(TC128)作为新的测试集来验证算法的性能. 对比更多优秀的跟踪算法,包括在OTB2015中表现较好的算法(BACF[17 ] 、ARCF[22 ] 、Staple[9 ] 、SRDCF[19 ] 、CSRDCF[21 ] 、LCT[37 ] 、SAMF[23 ] 、fDSST[25 ] 、MEEM[38 ] ),还有近年优秀的跟踪算法(RCT[41 ] 、WSCF[42 ] 、TRACF[43 ] 、TSC[44 ] 、DAMA[45 ] 、PSCA[46 ] ). Temple-Color128一共包含128个彩色视频序列,包含了更多的颜色信息,因此更具有挑战性. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}