

核心网是移动通信系统的重要组成部分. 在传统的EPC(evolved packet core)网络架构中,网元部署在专用的硬件平台上,网络的灵活性和可扩展性差,部署成本高. 随着5G时代的到来,为了应对爆炸式的移动数据流量增长以及海量的设备连接等挑战,移动运营商必须改变传统的EPC网络架构. 网络功能虚拟化(network function virtualization, NFV)作为新的网络范式,彻底变革了传统的网络功能实现方式. 在NFV范式中,网络功能被实现为软件设备,运行在云环境或者通用服务器上,提高了网络的灵活性和可扩展性,节省了部署成本. 因此,NFV技术被引入5G核心网的架构设计[1-2].
核心网虚拟化为移动运营商带来新的挑战:如何根据负载需求,弹性伸缩核心网资源配置,在满足性能要求的前提下,降低运营成本. Alawe等[8]利用循环神经网络和深度神经网络预测5G核心网流量负载,实现5G核心网资源的弹性伸缩. Arteaga等[9]提出基于阈值的vEPC伸缩机制,利用垂直伸缩和水平伸缩应对工作负载变化. Prados-garzon等[10]提出基于开放Jackson网络的vMME(virtualized mobility management entity)性能分析模型,利用该模型计算所需的vMME实例数量. Prados-garzon等[11]建立vEPC资源规划与映射联合优化模型,提出启发式求解方法. Bagaa等[12]提出vEPC切片构建方法,利用混合整数线性规划确定核心网网元虚拟实例的最优数量.
本文采用G/G/m队列的开放排队网络建立核心网控制面性能评估模型,推导出信令流程平均响应时间的近似表达式. 在此基础上,综合考虑处理性能和VNF实例部署成本,建立核心网控制面资源分配多目标优化模型. 为了求解上述资源分配问题,提出改进的多目标遗传算法,改进拥挤距离计算方法.
1. 核心网控制面性能分析建模
LTE(long term evolution)控制面由用户设备(user equipment, UE)、基站、移动管理实体(mobility management entity, MME)、服务和分组数据网关控制面(serving and packet data network gateway control plane, SPGW-C)与归属用户服务器(home subscriber server, HSS)组成. 核心网控制面集中部署在云数据中心,每个网元由多个虚拟实例组成,并且有缓存队列用于缓存待处理信令,所有网元均为单队列多服务台排队系统. LTE控制面信令流程需要经过多个网元处理,分别对每个网元进行性能分析是不合理的,本文采用排队网络对LTE控制面进行建模. M/M/m队列的开放Jackson网络是经典的排队网络,但其受限于强假设:外部到达过程是泊松过程,服务时间服从指数分布[13]. LTE控制面每个网元需要处理多种信令,每种信令的处理时间均为常数,服务时间并不服从指数分布,因此,M/M/m队列的开放Jackson网络并不适用. 采用G/G/m队列的开放排队网络[14]对LTE控制面进行性能分析,将每个网元建模为G/G/m排队系统,并利用到达时间间隔及服务时间的均值和平方变异系数表征. 无线接入网(E-UTRAN)作为整体采用G/G/∞排队系统建模.
令
式中:
式中:
求解式(4),可以得到:
进一步可以求得
基于上述分析,核心网控制面网元
式中:
可以得到平均一次信令流程的响应时间为
2. 核心网控制面资源分配
2.1. 问题模型
为了降低信令流程的平均响应时间,需要增加核心网控制面VNF实例,但是这会导致更高的VNF实例部署成本. 为了确定核心网控制面VNF实例的最优配置数量,综合考虑处理性能和VNF实例部署成本,建立核心网控制面资源分配多目标优化模型.
核心网控制面资源分配多目标优化问题可以描述为
式中:
2.2. 改进的多目标遗传算法
针对核心网控制面资源分配多目标优化问题,采用实数编码的NSGA-II算法求解[15]. 为了提高进化过程中种群的多样性,改进拥挤距离计算方法.
2.2.1. 改进的拥挤距离计算方法
由于处理性能与部署成本具有不同的量纲和取值范围,这里采用Min-Max方法对种群中个体的目标函数值进行归一化处理. 假设种群中个体
式中:
式中:
在生成新的父代种群时,合并当前父代种群和子代种群,对合并后的种群进行快速非支配排序. 对每个个体,从同一非支配等级和更高非支配等级中寻找其
图 1
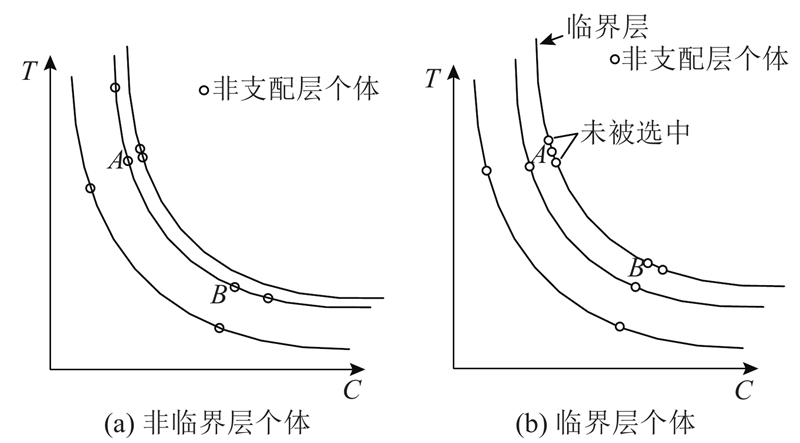
针对上述问题,本文提出改进措施:在生成新的父代种群之后计算个体的调和距离,从新的父代种群中寻找个体的
2.2.2. 算法复杂度分析
分析计算个体调和距离和从临界层选择新的父代个体的复杂度,种群规模为
3. 仿真实验
3.1. 实验设置
通过仿真实验验证本文提出的核心网控制面性能评估模型以及资源分配算法,实验参数设置如下. 考虑3种信令流程:服务请求流程(SR)、S1释放流程(S1R)、切换流程(HO),3种信令流程的产生速率分别为0.004 5、0.004 5、0.001 2次/(UE·s),且服从泊松过程. 3种信令流程的路由路径分别为1)SR: E-UTRAN,MME,E-UTRAN,MME,SPGW-C,MME;2)S1R: E-UTRAN,MME,SPGW-C,MME,E-UTRAN,MME;3)HO: E-UTRAN,MME,SPGW-C,MME,E-UTRAN.基于Amazon EC2的m3.xlarge实例实现MME和SPGW-C,m3.xlarge实例的按需价格为3.471元/h,基于开源的核心网软件OpenAirInterface测试所得,MME和SPGW-C的信令处理时间均设为0.000 1s.
3.2. 实验结果
将本文提出的核心网控制面性能评估模型与Jackson排队网络模型、SimEvents仿真进行比较. 虚拟MME实例的数量和虚拟SPGW-C实例的数量分别为3、1. 如图2所示为不同UE数量下3种性能分析方法的平均响应时间. 由图可知,本文提出的性能评估模型结果与SimEvents仿真结果非常接近,Jackson排队网络模型结果明显高于SimEvents仿真结果,原因是Jackson排队网络模型假设服务时间服从指数分布.
图 2
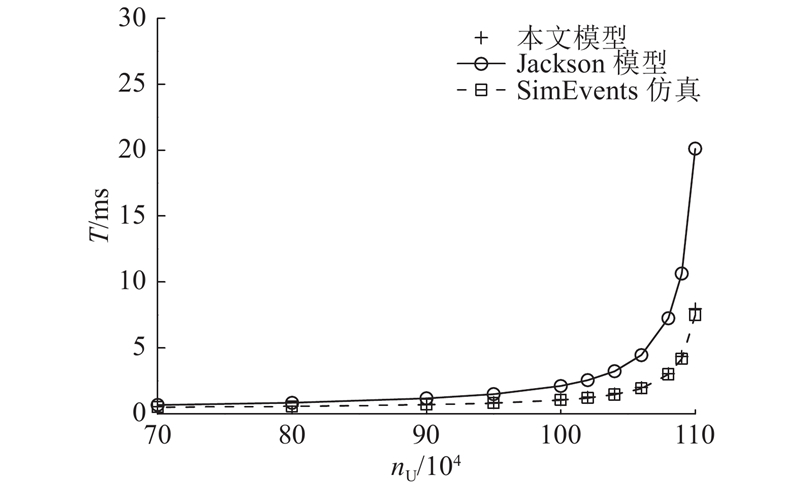
图 2 3种性能分析方法的平均响应时间
Fig.2 Comparison of average response time of three performance analysis methods
图 3
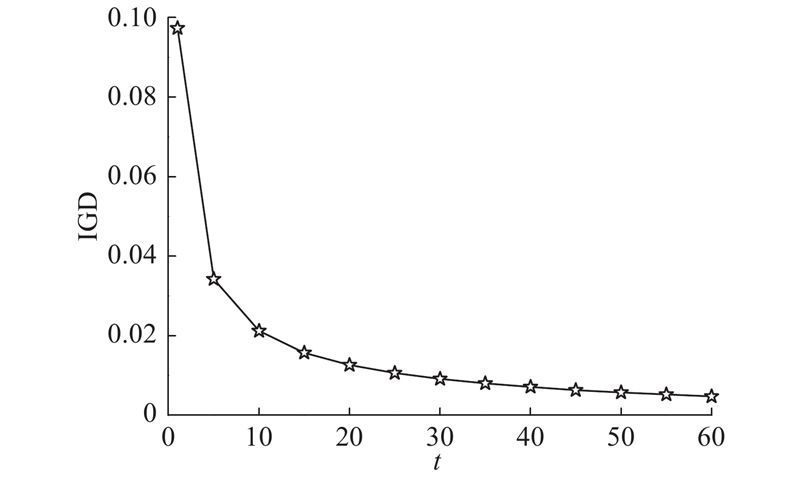
图 3 解集的IGD指标值随进化代数的变化情况
Fig.3 IGD results of Pareto front with evolution generation
将本文算法与NSGA-Ⅱ、HaD-MOEA进行性能比较. 采用IGD和超体积比(hypervolume ratio, HVR)指标[20]评价算法获得的近似Pareto解集的综合性能. HVR指标能够同时反映解集的收敛性和多样性,HVR指标值越大表明解集的综合性能越好. 如表1所示为t=30时3种算法的IGD和HVR指标值. 从表中可以看出,本文算法获得的近似Pareto解集的IGD和HVR指标优于其他2种算法,综合性能最优,原因是本文算法改进了拥挤距离计算方法,丰富了进化过程中种群的多样性. 如图4所示为采用本文算法得到的Pareto前沿. 决策者需要根据偏好从Pareto前沿中选择最优折中解,权衡核心网控制面处理性能与部署成本.
表 1 3种算法的IGD和HVR指标值(t=30)
Tab.1
| 算法 | IGD | HVR |
| 本文算法 | 0.009 1 | 0.847 1 |
| NSGA-II | 0.021 2 | 0.784 6 |
| HaD-MOEA | 0.012 6 | 0.829 5 |
图 4
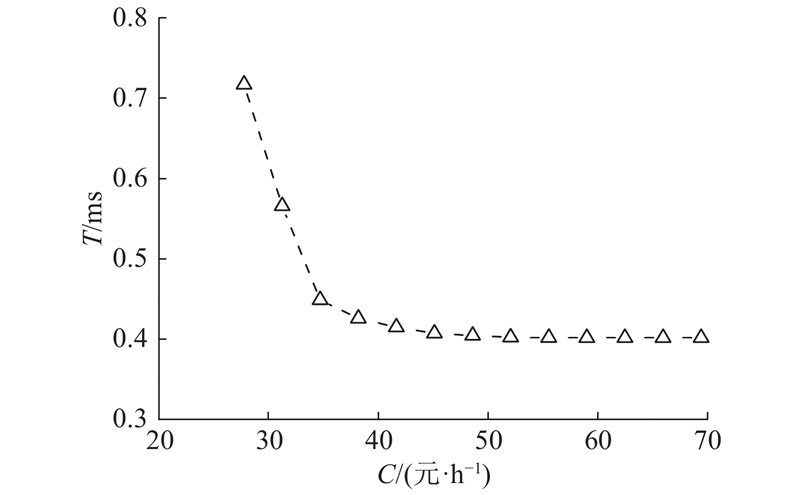
图 4 采用改进多目标遗传算法得到的Pareto前沿
Fig.4 Pareto front obtained by improved multi-objective genetic algorithm
将本文提出的核心网控制面资源分配算法与Prados-Garzon等[11]提出的PES算法及2个单目标遗传算法SGA-T、SGA-C进行比较,其中PES算法中vEPC控制面处理延迟预算设为控制面信令流程服务时间0.000 4 s的1.1倍,即0.000 44 s,这亦与文献[11]一致,SGA-T、SGA-C分别以处理性能和部署成本为优化目标. 如图5所示为不同资源分配算法下核心网控制面的处理性能和部署成本. 由图可知,SGA-T以高昂的部署成本为代价获得最优的处理性能,SGA-C与之相反. PES算法在满足延迟预算的条件下获得最低的部署成本. 相比PES算法,本文算法以较小的性能损失(5.4%)为代价换取显著的成本节省(9.1%).
图 5
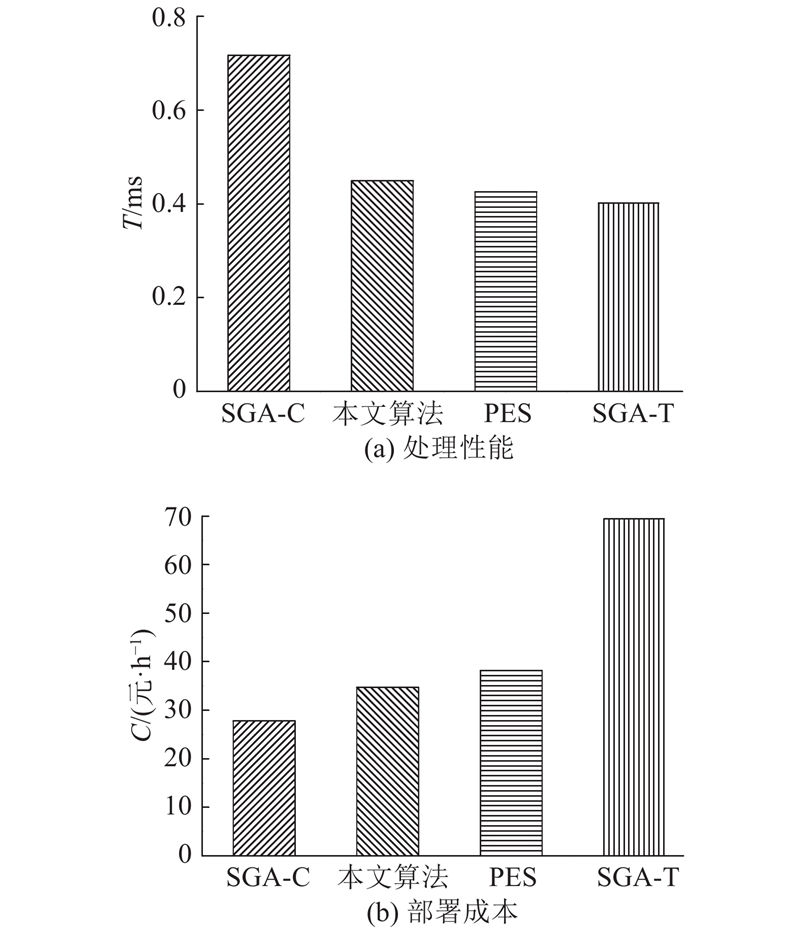
图 5 不同资源分配算法下核心网控制面的处理性能和部署成本
Fig.5 Processing performance and deployment cost of core network control plane under different resource allocation algorithms
4. 结 语
针对NFV环境下核心网控制面资源分配问题,提出性能感知的核心网控制面资源分配算法. 采用排队网络对核心网控制面进行性能分析,能够获得更好的性能评估结果. 所提出的核心网控制面资源分配算法,综合考虑了处理性能和部署成本,与NSGA-II和HaD-MOEA相比,综合性能更好,能够实现核心网控制面处理性能与部署成本的权衡. 后续将进一步针对核心网控制面动态部署中VNF实例初始化产生的能耗、引起的用户QoS的下降进行研究,分析部署决策的延迟影响,并采用强化学习解决核心网控制面动态部署问题.
参考文献
网络功能虚拟化技术研究进展
[J].
Network function virtualization technology: a survey
[J].
SDN/NFV-based mobile packet core network architectures: a survey
[J].DOI:10.1109/COMST.2017.2690823 [本文引用: 1]
EASE: EPC as a service to ease mobile core network deployment over cloud
[J].DOI:10.1109/MNET.2015.7064907 [本文引用: 1]
Effects of C/U plane separation and bearer aggregation in mobile core network
[J].DOI:10.1109/TNSM.2018.2797301 [本文引用: 1]
A survey on low latency towards 5G: RAN, core network and caching solutions
[J].DOI:10.1109/COMST.2018.2841349 [本文引用: 1]
Network function virtualization-aware orchestrator for service function chaining placement in the cloud
[J].DOI:10.1109/JSAC.2019.2895226 [本文引用: 1]
一种5G网络低时延资源调度算法
[J].
A resource scheduling algorithm with low latency for 5G networks based on effective hybrid genetic algorithm and tabu search
[J].
Improving traffic forecasting for 5G core network scalability: a machine learning approach
[J].DOI:10.1109/MNET.2018.1800104 [本文引用: 1]
A scaling mechanism for an evolved packet core based on network functions virtualization
[J].DOI:10.1109/TNSM.2019.2961988 [本文引用: 1]
Modeling and dimensioning of a virtualized MME for 5G mobile networks
[J].DOI:10.1109/TVT.2016.2608942 [本文引用: 1]
A complete LTE mathematical framework for the network slice planning of the EPC
[J].
Coalitional game for the creation of efficient virtual core network slices in 5G mobile systems
[J].DOI:10.1109/JSAC.2018.2815398 [本文引用: 1]
MEC中基于改进遗传模拟退火算法的虚拟网络功能部署策略
[J].DOI:10.11959/j.issn.1000-436x.2020074 [本文引用: 1]
Virtual network function deployment strategy based on improved genetic simulated annealing algorithm in MEC
[J].DOI:10.11959/j.issn.1000-436x.2020074 [本文引用: 1]
The queueing network analyzer
[J].DOI:10.1002/j.1538-7305.1983.tb03204.x [本文引用: 3]
A fast and elitist multiobjective genetic algorithm: NSGA-II
[J].DOI:10.1109/4235.996017 [本文引用: 2]
Multi-objective approaches to optimal testing resource allocation in modular software systems
[J].DOI:10.1109/TR.2010.2057310 [本文引用: 3]
一种基于参考点约束支配的NSGA-Ⅲ算法
[J].
A reference point constrained dominance-based NSGA-Ⅲ algorithm
[J].
一种采用改进交叉熵的多目标优化问题求解方法
[J].
A solution to multi-objective optimization problem with improved cross entropy optimization
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}