

三维人体模型在人机交互、服装设计、虚拟试衣等领域有着广泛的应用,如何快速、低成本地重建高精度的三维人体模型,一直是计算机图形学领域的重点研究方向.
本文提出由LeNet-5从单张着装图像重建三维人体的方法,以A-pose人体的二值化图像为输入,通过对公开数据集中的虚拟人体进行数据扩增并穿着不同款式、尺寸的服装,构建着装人体数据集;以人体形状参数误差、正/侧面轮廓误差为损失函数,开展模型迭代优化,实现快速、高精度的三维人体重建.
1. 系统概述
图 1
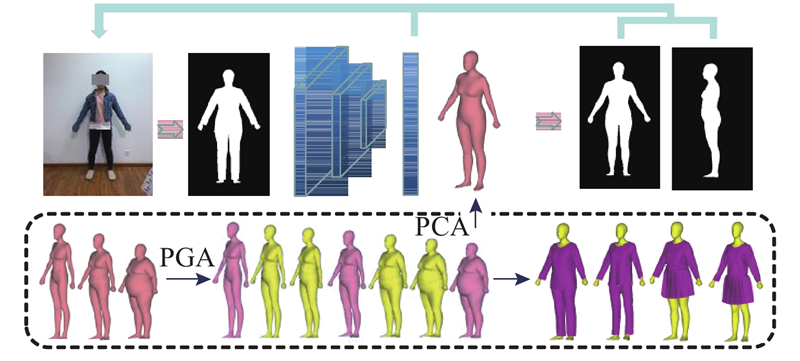
图 1 由单张图像重建三维人体流程
Fig.1 Pipeline of reconstruction of three-dimensional human bodies from single image
对于在流型空间上扩增后的人体数据库,采用PCA进行降维,以低维度的PCA主轴系数向量γ表征高维人体;对于着装人体数据库中的每一个样本人体,通过投影得到正面轮廓图像,从中提取特征. 为了能够更加准确地建立着装人体正面轮廓图像与人体形状空间之间的映射模型,重建结果进行重投影,得到三维人体正、侧面轮廓图像. 以PCA主轴系数向量误差、人体正、侧面轮廓误差为损失函数,迭代优化模型,实现了基于单张着装人体正面图像的三维人体重建.
2. 着装人体数据集构建
2.1. 人体姿态调整
在计算机图形学中,通常使用高维三角网格表征人体表面形状. 为了构建不同形状、不同姿态人体的形变关系,参数化统计模型SCAPE和SMPL近年来被逐渐广泛采用,其中以SMPL更具有代表性. SMPL是基于网格顶点的人体形变模型,用于表征不同姿态下不同人体的表面形状,网格形变参数包括形状参数β及非刚性姿态参数θ. 为了降低人体姿态对重建结果的影响,实现高精度三维人体建模,对于所有着装人体数据,姿态均被调整为A-pose.
式中:
每个虚拟人体以6 890个网格顶点表征,扫描人体姿态均通过SMPL转换为A-pose,βi维度为10,θi维度为72.
2.2. 数据集扩增
样本数据的数量和质量会影响模型的拟合能力,充足的样本数量及合理的样本分布是构建高精度网络模型的必要条件. 现有的扫描人体数据库[20]仅包含约1 500组男性人体、1 500组女性人体,样本数量有限,不足以训练得到稳定的模型,因而需要进行数据集扩增. 男性和女性在人体形态上存在明显差异,例如在腰围与臀围接近的情况下,女性人体的胸围普遍大于男性. 为了能够更加准确地建立统计模型,重建得到更高精度的三维人体,需要对男性与女性人体分别构建数据集,开展独立的三维建模,思路与方法完全相同. 以女性人体为实例,进行详细说明.
常用的人体数据集扩增方法为现有人体数据之间的线性插值,但人体形状空间是一个复杂的高维空间,不同人体加权求和得到的人体不一定有效. 为了能够更加准确地表征人体形状空间,得到更加接近于真实人体的扩增数据集,将现有的人体数据投影至黎曼空间,采用李群(Lie Groups)构造流型结构,用测地线距离定义不同人体之间的差异[22],进行人体数据集扩增.
拓扑结构统一的人体之间的变形可以认为是各三角网格形变的综合. 人体H1和H2中对应三角形T1=[v12−v11, v13−v11]∈R3×2和T2= [v22−v21, v23−v21]∈R3×2之间的形变方程可以表示为T1=QT2,其中[v11, v12, v13]、[v21, v22, v23]分别为三角形T1、T2的顶点;Q∈R3×3为形变矩阵,共包含9个未知数,大于方程数量6. 在欧式空间里,常通过添加额外约束,如正则项来解决这一病态问题,但会不可避免地引入误差;在黎曼几何中,Q可以被分解为
式中:d(·)为测地线距离,
其中
图 2
式中:k1、k2为权重系数,k1+k2=1.
虽然数据库中的所有人体姿态均为A-pose,不同样本之间的姿态信息可能存在细微的差别. 为了更加合理地表征数据库中的三维人体模型,采用PCA对插值后的人体数据库进行降维. 取前95%的特征值对应的特征向量表征三维人体模型,即PCA主轴系数向量γi的维度为15.
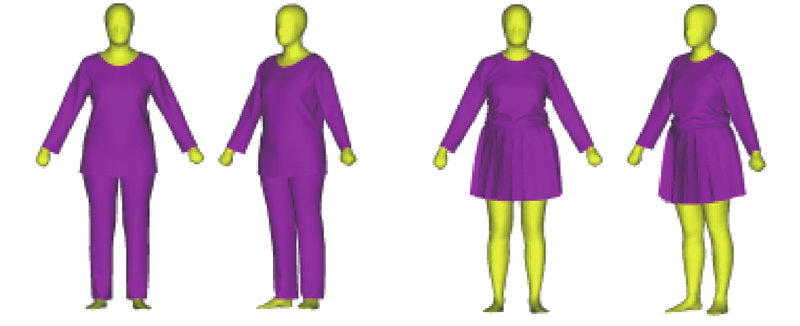
在实际应用场景中,用户通常更倾向于在穿日常服饰的情况下,采用非侵入式且少附加条件的测量方式,需要在虚拟人体表面添加不同款式、尺寸的虚拟服装. 如图3所示,采用Marvelous Designer添加虚拟服装,构建着装人体数据库. 样本数据集中服装款式的增加必然会提升模型的泛化能力,但也会增加数据集构建成本,提升模型训练难度. 综合考虑上述因素,本数据集累计包含1 500组真实人体描述数据、1 500组插值人体、3款不同款式的虚拟服装,总计约9 000组着装人体.
图 3
3. 基于LeNet-5的三维人体重建
为了降低拍摄环境及人体姿态信息对于重建结果的影响,构建人体正面二值化轮廓图像与人体形状空间之间的映射模型. 模型训练数据为着装人体正面轮廓图像及对应的三维人体数据. 为了减小图像平移对于模型训练的影响,将人体中心点与图像中心点对齐后进行投影变换,得到无平移的人体正面轮廓图像. 从图像中提取特征,以人体姿态参数及正、侧面轮廓为约束,迭代优化重建结果.
3.1. 网络结构及训练参数
图 4
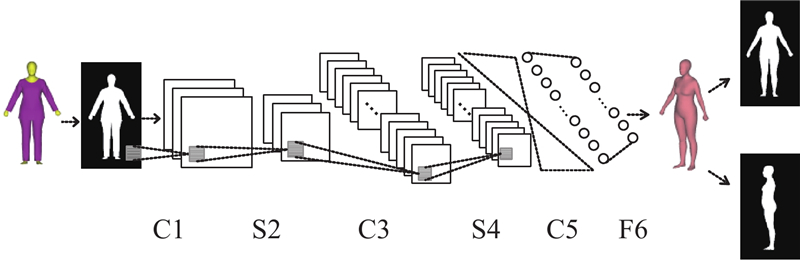
1)输入层:输入图像大小为256×256,每个像素点的物理尺寸为8 mm×8 mm.
2)C1层:卷积层,滤波器大小为5×5,步长为2,共包含16个滤波器.
3)S2层:子采样层/池化层,对每个2×2区块中的值取平均值,得到16组特征映射.
4)C3层:卷积层,滤波器大小为5×5,步长为2,共包含32个滤波器.
5)S4层:子采样层/池化层,对每个2×2区块中的值取平均值,得到32组特征映射.
6)C5层:卷积层,滤波器大小为5×5,步长为2,共包含64个滤波器.
7)F6层:全连接层.
8)输出层:由PCA主轴系数构成的向量γ.
在模型训练的过程中,采用dropout以避免模型过拟合,提升模型的泛化能力[25],将dropout rate设定为0.5;将学习率和batch分别设置为0.01和100,添加批处理规范化,以提升收敛速度. 将着装人体数据集中70%的样本数据作为训练集,剩下的作为测试集和验证集,采用TensorFlow及Python实现网络模型,在服务器上进行训练. 服务器相关硬件为1块Intel Xeon E5 CPU和4块NVIDIA 2080Ti GPU,训练时间大约为36 h.
3.2. 损失函数
单视角数据往往不能全面地反映人体表面形状信息,为了提升模型的性能,使得重建结果在视觉上更加接近于真实人体,以人体模型PCA主轴系数向量及人体正、侧面形状误差为损失函数. 迭代优化模型如下.
1)人体形状参数误差,即
式中:N为训练样本数量,Gi为第i个着装人体的正面轮廓图像,
2)轮廓误差. 根据PCA主轴系数向量γi计算得到三维人体模型M(γi),重投影得到人体正面轮廓图像
式中:f(I1,I2)为图像I1和I2之间的差异,
该模型结合人体形状参数误差及正、侧面轮廓误差,总体损失函数为
式中:
4. 实验结果与分析
为了客观评价该方法的有效性和泛化能力,开展了大量的实验,主要包括:模型对比,即不同损失函数下模型误差比较及与常见深度学习及非深度学习算法比较;从虚拟着装人体图像和真实人体正面图像恢复三维人体模型. 其中虚拟着装人体图像由三维着装人体模型的小孔成像投影获得,在已知三维人体体形的情况下,可以有效地测试该方法的效果;将真人着装图像的重建测试用于验证该方法的实际应用效果.
4.1. 模型对比
表 1 不同损失函数下重建结果误差
Tab.1
| 损失函数 | e /cm | |||||
| 总体误差 | 胸围 | 腰围 | 臀围 | 手长 | 腿长 | |
| | 1.76 | 3.27 | 3.18 | 3.51 | 1.94 | 2.04 |
| | 1.36 | 2.34 | 2.49 | 2.72 | 1.48 | 1.59 |
| | 1.31 | 2.36 | 2.23 | 2.66 | 1.41 | 1.62 |
| Ltotal | 1.15 | 1.97 | 2.08 | 2.32 | 1.21 | 1.45 |
表 2 不同方法重建结果误差
Tab.2
4.2. 虚拟人体三维重建
表 3 不同姿态下人体的误差
Tab.3
| 人体姿态 | e /cm | |||||
| 总体误差 | 胸围 | 腰围 | 臀围 | 手长 | 腿长 | |
| P = 15° | 1.56 | 3.45 | 2.91 | 3.34 | 1.84 | 2.15 |
| P = 25° | 1.26 | 2.06 | 2.24 | 2.29 | 1.41 | 1.53 |
| P = 30° | 1.15 | 1.97 | 2.08 | 2.32 | 1.21 | 1.45 |
| P = 35° | 1.19 | 1.95 | 2.17 | 2.57 | 1.15 | 1.57 |
| P = 45° | 1.69 | 3.16 | 3.05 | 3.40 | 2.02 | 2.01 |
| P = 90° | 2.68 | 4.52 | 5.05 | 5.13 | 3.17 | 3.64 |
| L = 0 | 1.21 | 2.14 | 2.09 | 2.45 | 1.36 | 1.68 |
图 5
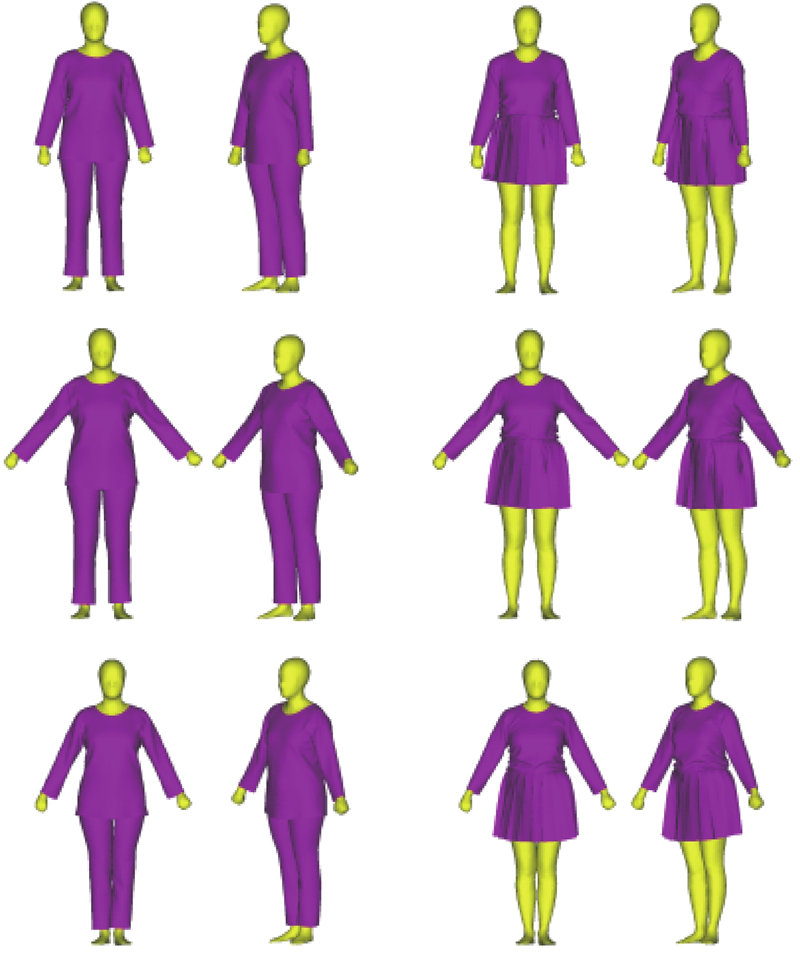
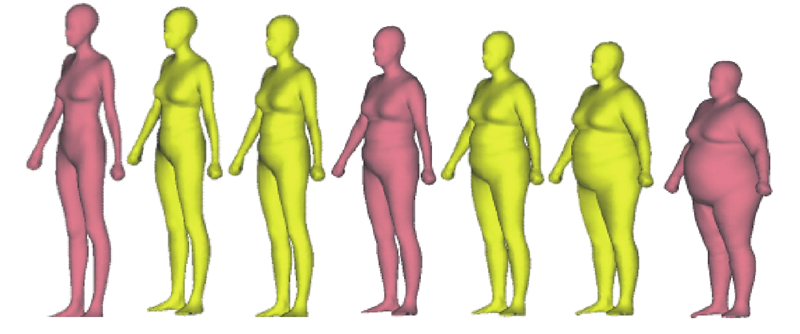
为了直观展示模型在不同体型人体上的性能,手动从数据集中挑选若干具有代表性的人体进行实验. 如图6所示,四肢与头部的误差相对更大,这主要是因为不同人体之间的姿态存在细微差别. 从上述实验可以看出,无论是身材相对标准的人体还是偏胖或者偏瘦的人体,利用提出的模型都能够实现较高精度的三维重建.
图 6
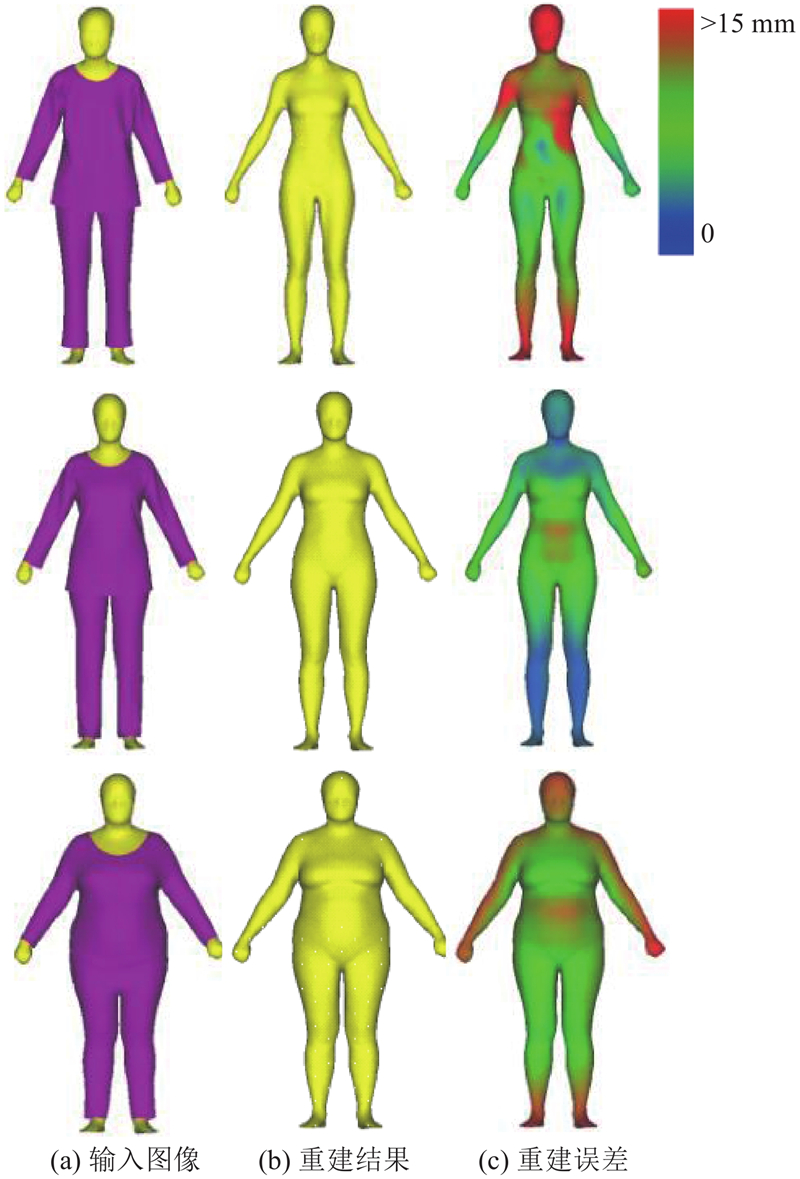
4.3. 真实人体三维重建
三维模型的精度测试数据与样本数据之间的差异性相关. 为了证明本文方法的实际应用价值,在真实人体上开展多次实验,主要可以分为3类,分别评估目标人体本身、目标人体姿态及服装款式对重建结果的影响. 在模型训练的过程中,输入图像为背景纯净的人体正面轮廓图像,且假设相机位置固定不变. 在实际的应用环境下,背景通常多变而复杂,且相机位置难以固定;因此,需要对输入图像进行预处理,保证相机位置与训练图像中的相机位置一致,即从真实人体采集到的图像应与其对应的虚拟人体投影得到的图像相同(假设可以重建得到高精度的三维人体模型). 如图7所示,具体步骤如下.
图 7
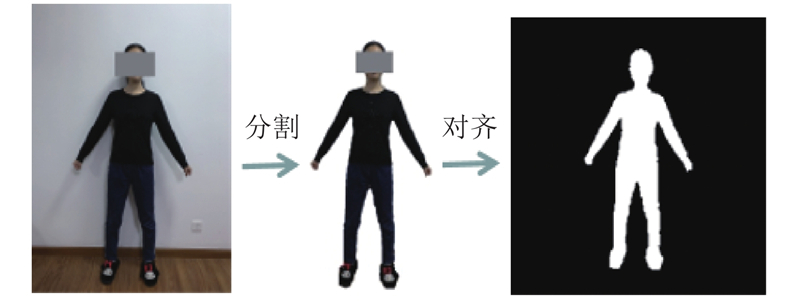
1)背景分割. 去除环境背景,采用Grabcut算法[26]从原始图像中提取人体,并进行二值化. 由于背景分割不是本文研究的重点,数据采集环境均为白色背景,这在实际应用中不难实现.
2)中心点对齐. 以人体平均点为人体中心点,并将图像中心点和人体中心点对齐.
3)人体图像缩放. 结合用户提供的身高信息,计算当前图像中每个像素点的实际物理尺寸;按比例缩放人体轮廓,调整图像中每个像素点的物理尺寸至8 mm×8 mm.
表 4 不同人体的重建误差
Tab.4
| 人体 | 着装 | e /cm | ||||
| 胸围 | 腰围 | 臀围 | 手长 | 腿长 | ||
| 人体1 | 长衣长裤 | 2.35 | 2.08 | 1.14 | 1.96 | 0.91 |
| 人体1 | 短裙 | 3.15 | 2.93 | 3.20 | 1.69 | 1.46 |
| 人体2 | 长衣长裤 | 1.05 | 0.81 | 1.02 | 0.36 | 1.34 |
| 人体2 | 短裙 | 1.47 | 1.61 | 1.84 | 1.37 | 2.11 |
| 人体3 | 长衣长裤 | 1.54 | 1.72 | 3.03 | 2.35 | 1.71 |
| 人体3 | 短裙 | 2.61 | 2.20 | 2.61 | 3.22 | 1.68 |
图 8

图 8 从正面图像恢复三维人体,姿态A,长衣长裤
Fig.8 3D human body reconstruction from images captured in front view, posture A, and long trousers
图 9

图 9 从正面图像恢复三维人体,姿态A,着短裙
Fig.9 3D human body reconstruction from images captured in front view, posture A, and short skirt
表 5 不同姿态人体的重建误差
Tab.5
| 人体姿态 | e /cm | ||||
| 胸围 | 腰围 | 臀围 | 手长 | 腿长 | |
| P = 15° | 1.84 | 0.73 | 1.51 | 1.46 | 1.58 |
| P = 25° | 1.62 | 0.88 | 0.67 | 0.93 | 1.61 |
| P = 30° | 1.05 | 0.81 | 1.02 | 0.73 | 1.34 |
| P = 35° | 0.91 | 1.20 | 1.53 | 0.36 | 0.95 |
| P = 45° | 2.15 | 2.06 | 2.07 | 1.04 | 1.36 |
| P = 90° | 2.16 | 3.84 | 4.21 | 5.13 | 4.38 |
| L = 0 | 1.26 | 1.39 | 0.79 | 0.51 | 1.37 |
图 10

图 10 从不同姿态人体图像恢复三维人体
Fig.10 Reconstruction from images of human bodies in different postures
为了提升用户体验,验证模型的泛化能力,评估服装款式对重建结果的影响. 实验者穿着不同款式的服装,按照要求采集正面图像,如图11所示. 重建结果的围度误差如表6所示. 可以看出,在当前数据集下,当真实人体着装款式与训练集中服装相同或相近时,重建结果较理想;当服装款式发生明显变化时,重建结果精度会受到影响. 这主要是由于数据集中服装款式有限,若适当丰富数据集中的服装款式,则重建精度必然得到提升. 本文旨在从现有数据集中学习着装人体正面图像与人体表面形状之间的统计规律. 在面对某些特殊情形时,如测试人体脸部及四肢相对肥胖,躯干相对瘦小,且身着相对宽松的服装时,正面图像通常无法准确地反映表面形状,重建误差必然相对较大.
表 6 不同服装下人体的重建误差
Tab.6
| 服装款式 | e /cm | ||||
| 胸围 | 腰围 | 臀围 | 手长 | 腿长 | |
| 款式1 | 0.73 | 1.43 | 2.71 | 1.82 | 1.51 |
| 款式2 | 2.65 | 2.81 | 1.97 | 1.60 | 0.82 |
| 款式3 | 4.79 | 4.56 | 1.76 | 3.14 | 1.01 |
图 11

图 11 从同一人体不同着装的图像恢复三维人体
Fig.11 Reconstruction from images of one human body in different garments
5. 结 语
本文提出由LeNet-5从单张着装图像恢复三维人体的方法. 为了降低人体姿态、图像背景及服装款式对重建精度的影响,得到符合虚拟试衣要求的高精度三维人体模型,从公开数据集中获取了约1 500组女性真实人体数据. 采用PGA在流型空间上进行数据扩增,给虚拟人体穿上不同款式、尺寸的虚拟服装,构建着装人体数据集. 从人体正面轮廓图像中提取特征,以PCA主轴系数向量误差、正、侧面轮廓误差为损失函数,预测人体形态. 实验证明,该模型对于不同体型的人体,在不同着装下,通常都能够得到较理想的重建结果. 本文的主要贡献如下:1)将人体侧面轮廓信息作为约束,提高了模型的性能;2)基于不同服装款式及尺寸的着装人体样本数据训练模型,降低了服装款式及尺寸对三维人体重建结果的影响.
参考文献
Scanning 3D full human bodies using kinects
[J].DOI:10.1109/TVCG.2012.56 [本文引用: 1]
Reconstructing 3D human models with a kinect
[J].DOI:10.1002/cav.1632
Optimizing human model reconstruction from RGB-D image based on skin detection
[J].DOI:10.1007/s10055-016-0291-y [本文引用: 1]
Parameterization and parametric design of mannequins
[J].DOI:10.1016/j.cad.2004.05.001 [本文引用: 1]
Parametric human body shape modeling framework for human-centered product design
[J].
Parametric design for human body modeling by wireframe-assisted deep learning
[J].DOI:10.1016/j.cad.2018.10.004 [本文引用: 1]
SCAPE: shape completion and animation of people
[J].DOI:10.1145/1073204.1073207 [本文引用: 1]
SMPL: a skinned multi-person linear model
[J].
Human body shape reconstruction from binary silhouette images
[J].DOI:10.1016/j.cagd.2019.04.019
Human3.6m: large scale datasets and predictive methods for 3d human sensing in natural environments
[J].
Building statistical shape space for 3d human modeling
[J].DOI:10.1016/j.patcog.2017.02.018 [本文引用: 2]
Customizing 3D garments based on volumetric deformation
[J].DOI:10.1016/j.compind.2011.04.002 [本文引用: 1]
Gradient-based learning applied to document recognition
[J].DOI:10.1109/5.726791 [本文引用: 1]
"GrabCut" interactive foreground extraction using iterated graph cuts
[J].DOI:10.1145/1015706.1015720 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}