

在自然条件下,由于遮挡物的存在,光源发出的光线无法全部入射到物体表面,从而产生阴影. 一方面,阴影区域能够提供足够的信息,用于估计环境光亮度、推断遮挡物的几何形状以及确定光源位置等[1]. 另一方面,图像中阴影像素的存在会导致图像内容的不确定性,对目标识别、目标跟踪、视频监控、自动驾驶等任务而言是有害的. 因此,研究全自动阴影检测算法,并将其用作计算机视觉任务的预处理步骤,提前标注出阴影区域的位置,避免其与待处理目标的混淆,可提高计算机视觉算法的鲁棒性.
现有的阴影检测算法可按照自身特点分为4类:基于本征图像(intrinsic image)的方法[2-4]、基于区域的方法[5-8]、基于特征提取的方法[9-13]、基于深度学习的方法[14-18]. Finlayson等[2-4]提出完整的本征图像理论(intrinsic image theory),该理论建立在光照均匀假设的基础上,利用熵值最小化(entropy minimization)方法求取灰度不变图像(greyscale invariant image),进而完成阴影检测与阴影去除. 但是,由于光照均匀假设并非时刻成立,图像质量参差不齐,使用该自动算法对普通网络图片进行处理时鲁棒性不强. 基于区域的方法通常采用聚类(clustering)算法将图像像素分为不同的小块,根据颜色、亮度、纹理等特征将像素块分类为阴影区域或非阴影区域. Hoiem等[5-6]基于支持向量机(support vector machine,SVM)方法分别构建单区域分类器和双区域分类器,使用图割法(graph cut)实现最终预测. Vincente等[7]和Yuan等[8]采用与Hoiem等[5-6]类似的算法流程,但在分类器及分类依据上有所不同. Vincente等[7]为每项不同特征单独训练SVM分类器,最终获得多核SVM分类器. Yuan等[8]使用逻辑回归(logistic regression)和决策树(decision trees)构建单区域分类器. 基于区域的方法包含聚类、多特征提取、分类、随机场优化等算法流程,时间复杂度高,不适用于实时阴影检测. 基于特征提取的方法关注阴影区域与非阴影区域的不同特性. 通常来说,阴影区域亮度和饱和度偏低,色调基本不变. 利用这一特性设定阈值,可获得初步的阴影检测结果. 但考虑到场景、光照条件、物体表面反射率的多样性,仅使用1种特征进行阈值分割是不够的. 一些算法[9-10]关注阴影区域的颜色信息,采用HSI、YCbCr等颜色空间协助检测任务. 另一些算法[10-13]关注物体的几何特征及边缘信息,常使用sobel算子或canny算子,这类算法往往侧重于提取图像的低阶信息,忽略像素块之间的关系及图像中物体的语义信息,对复杂场景的处理效果不佳. 由于深度学习方法的兴起,近年来学者们提出了一系列利用卷积神经网络(convolutional neural network,CNN)模型实现阴影检测的新方法. Khan等[14]首先使用深度学习方法进行阴影检测,训练2个网络分别用于检测阴影区域和阴影边缘,将检测结果输入条件随机场(conditional random field,CRF)得到分类结果,相比传统算法效果提升显著. Vincente等[15]最早使用2个级联网络实现阴影检测,第1个网络用来初步提取阴影标记,并将其作为阴影概率图与原图一起输入到第2个网络,最终得到精细化的阴影标记结果. Hosseinzadeh等[16]根据颜色及纹理特征使用SVM分类器得到阴影先验图(shadow prior map),将其与原图合并后送入训练好的CNN网络,输出阴影检测结果. Nguyen等[17]引入条件生成对抗网络(conditional generative adversarial networks,cGAN),生成器(generator)输出阴影标记,判别器(discriminator)分辨阴影标记真假,两者相互对抗使得生成器具备检测图像阴影区域的能力,该方法相较Vincente[15]的方法有了进一步的效果提升. Le等[18]同样借鉴生成对抗网络的思想,训练生成器生成阴影区域被衰减后的图像,训练判别器输出阴影标记,从图像源层面加强网络分辨阴影区域的能力. 现有的CNN阴影检测方法常使用级联网络[14-16]或生成对抗网络[17-18]的形式,增加了模型训练的难度,同时不利于快速检测算法的实现. 与之相比,单网络结构既可以实现端对端训练,降低模型训练的难度,又可以在一定程度上减少计算量,加快算法的运行速度,优势明显.
本研究以分类网络ResNeXt101[19]作为特征提取模块,借鉴U-Net[20]的设计思想,结合残差注意力机制(residual attention mechanism)[21]、非局部操作(non-local operation)[22],设计全新的单网络结构Attention Res-Unet,重点关注图像中包含的语义信息与像素之间的联系. 所设计的模型结构对不同场景(也包含某些复杂环境)、不同光照条件下获取的阴影图像都有较好的阴影检测效果. 将所提算法在SBU[15]、UCF[23]2个通用阴影检测数据集上进行验证,得到的客观指标及主观目视效果皆优于此前方法. 首次将单网络结构用于阴影检测,并通过深层预训练网络、注意力机制、非局部操作等手段融合语义信息和像素关系,设计模型结构并通过实验验证其有效性,进一步提高了阴影检测结果的可信度.
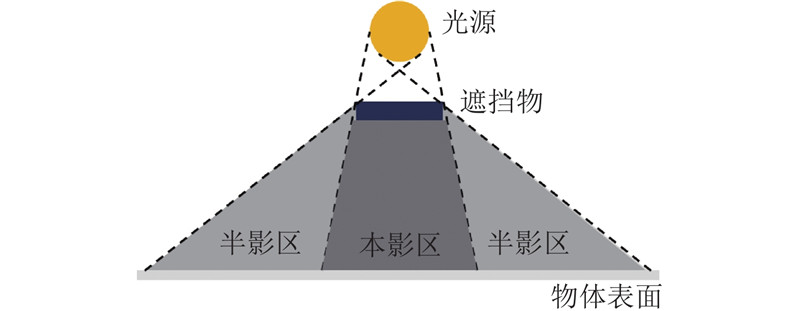
1. 阴影模型分析
图 1
式中:
非学习类算法倾向于根据图像中阴影区域的统计规律分辨阴影像素与非阴影像素. 对于一些容易引起混淆的图像,以上算法的检测效果较差. 如图2所示列举了2种情况,如图2(a)所示为容易将阴影区域错误判定为非阴影区域的典型案例,左图为原图,右图为左图中方框区域的放大图像;如图2(b)所示为容易将非阴影区域错误判定为阴影区域的典型案例. 仅给出右边的2幅图像,即使是人类也难以判断其类别. 但当这2个区域被放回原图,问题变得十分简单,如图2(a)所示为1个人在公路上的影子,影子形状是连续的,那么红框内一定是阴影;图2(b)方框内的黑板没有被遮挡,一定不属于阴影. 这说明,图像中包含的语义信息和像素联系对阴影检测至关重要,它们可以帮助正确判别阴影区域与伪阴影区域,同时保持阴影检测结果的连续性. 本研究以此为导向,设计了效果更好的阴影检测模型.
图 2

2. 阴影模型框架
图像中包含的语义信息和像素联系对阴影检测大有裨益. 为了获得语义信息,使用分类网络ResNeXt101(32×4 d)[19]作为前端的特征提取模块. ResNeXt101结构随深度增加,特征层尺寸逐步减小,可以认为是下采样的过程. 下采样有利于提取高层次信息,但在语义分割任务中常常会导致分类精度的下降. 为适应阴影检测任务的需求,借鉴医学图像分割网络U-Net[20]的设计思想,对已获得的ResNeXt特征层,逐步扩大特征层尺寸,同时减小特征层深度,直至输出图像尺寸恢复到输入大小. 同时,在网络输出前添加非局部操作[22],为每一个像素提供全局信息,建立像素与像素之间的联系. 最后,为进一步提升网络对不同场景、不同光照条件的泛化能力,结合最新的残差注意力机制[21],设计注意力生成模块和注意力融合模块,为输入图像的每一个像素位置分配权重,用于改善网络输出.
2.1. Attention Res-Unet算法
如图3所示为Attention Res-Unet的网络结构和整体流程,为了方便理解,已将所有特征层的尺寸和深度都标示出来. 采样操作过程如下:将调整大小后的RGB三通道图像输入网络前端的ResNeXt101特征提取模块,得到尺寸为8×8、深度为2 048的特征向量;为了满足特征提取的需要,保留ResNeXt101的结构主体,丢弃用于分类结果输出的最后3层;在下采样过程后,依次设置步长为2,卷积核尺寸为2×2的转置卷积层(transposed convolution layer),可逐步增大特征层尺寸,同时减小特征层深度;仿照U-Net的典型结构,采用特征层拼接(concatenate)方法,结合下采样线路和上采样线路中相同尺度的信息;在每一次拼接后,使用3×3卷积层、批归一化层(batch normalization layer)[24]、ReLU激活函数组合融合相同尺度的特征信息. 按规则重复上述上采样操作,将得到128×128×64的特征层. 考虑到卷积层只能初步结合感受野中的图像信息[22],在该特征层后使用非局部操作[22],为每个像素提供精准的全局信息,自动构建像素关系,解决在困难案例图像检测时阴影区域内部大范围识别错误的问题. 非局部操作只会引入全局信息,而不会改变特征层的大小和深度,最后使用1×1卷积层和双线性插值方法得到初步的阴影检测结果.
图 3
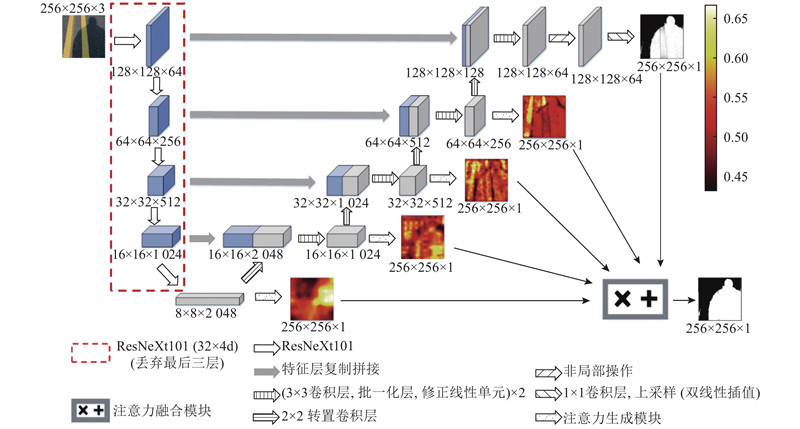
图 3 Attention Res-Unet算法网络结构
Fig.3 Network architecture of Attention Res-Unet algorithm
为了进一步优化检测结果,在Attention Res-Unet主线路前向传播的同时,对上采样线路中不同层次的4个卷积层,分别使用注意力生成模块(attention generation module)生成对应层级的权重图. 然后将已获得的初步阴影检测结果和4张权重图输入注意力融合模块(attention fusion module),获得精细化的阴影检测结果.
2.2. 注意力生成模块
图 4
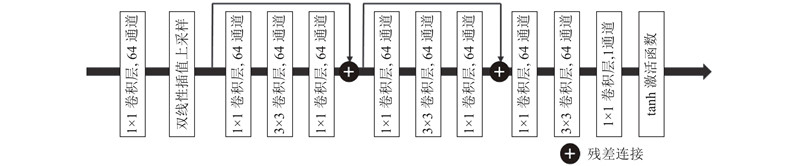
图 4 Attention Res-Unet算法中注意力生成模块流程图
Fig.4 Procedure scheme of attention generation module in Attention Res-Unet algorithm
2.3. 注意力融合模块
经过网络主线路的前向传播,得到了初步的阴影检测结果. 另一方面,将不同尺度的特征层输入注意力生成模块,可以得到4张对应的权重图. 将这4张权重图按照前向传播的先后顺序依次输入注意力融合模块,如图5所示. 阴影掩模(shadow mask)与权重图的尺寸一致,所以将对应元素相乘,相乘后的结果再加上该阴影掩模,得到新的阴影检测结果. 重复这一过程,并在该模块的最终输出前使用sigmoid激活函数将响应值大小映射至(0,1.0). 该过程可表示为
式中:
从注意力融合模块的输入到输出,一共能得到5个阴影掩模,包括1个初步结果,3个中间结果和1个最终结果.
3. 训练及测试细节
3.1. 数据集
3.2. 数据预处理
训练时将原图大小缩放至256×256,并以0.5的概率对调整大小后的图像做水平翻转. 测试时仅缩放至256×256. 最后将结果插值至原图大小.
3.3. 网络预训练
Attention Res-Unet中用于特征提取的前端结构是ResNeXt101,为了结合输入图像中包含的语义信息,使用在ImageNet数据库上训练得到的模型参数初始化特征提取模块.
3.4. 损失函数
二分类任务常采用二进制交叉熵损失函数(binary cross entropy loss,BCE Loss). 为了解决图像中正负例不平衡的问题,即阴影像素数目远少于非阴影像素数目,采用类别均衡的二进制交叉熵损失函数(class-balanced BCE loss),引入平衡因子
式中:
为注意力融合模块相关的每一个阴影掩模计算损失函数,如图5所示. 阴影检测模型的损失值为这5个损失值之和.
图 5
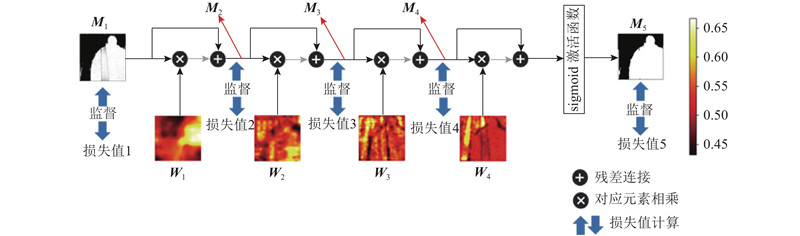
图 5 Attention Res-Unet算法中注意力融合模块流程图
Fig.5 Procedure scheme of attention fusion module in Attention Res-Unet algorithm
3.5. 训练超参数
1)学习率(learning-rate):初始时为0.005,衰减系数为0.9;
2)动量(momentum):0.9;
3)权重衰减系数(weight decay coefficient):0.000 5;
4)批量大小(batch size):8;
5)训练迭代期(iteration):10 000;
6)优化方法:随机梯度下降(stochastic gradient descent,SGD).
4. 实验与结果讨论
4.1. 评价指标
式中:TP、TN、
4.2. 效果对比
如图6所示为所设计的Attention Res-Unet对不同场景图像的阴影检测结果,以及与当前最优算法scGAN[17]、patched-CNN[16]、stacked-CNN[15]进行对比的结果. 从左到右,每一列分别为原图、真实检测结果、所提方法检测结果、scGAN[17]检测结果、patched-CNN[16]检测结果及stacked-CNN[15]检测结果. 相较于其他方法,Attention Res-Unet对阴影的定位更加准确,同时能够分辨真实的阴影区域和外观类似阴影的非阴影区域,错误检测的像素数目更少. 对于容易引起混淆的困难案例,例如图6第1列的第4~6幅图像,scGAN[17]、patched-CNN[16]、stacked-CNN[15]3种方法都出现了大面积的检测错误. 与之相比,所提算法仍然能够准确判断出:斑马线之间的低亮度区域不是阴影,黑色的螺丝钉不是阴影,阴影区域内部出现的高对比度黄色区域属于阴影. 这也证实了语义信息和像素关联对阴影检测的正面作用.
图 6

为了进一步验证所提观点,在SBU、UCF数据集上进行定量评价,结果如表1所示,最优结果用加粗数字标出. 实验结果显示,在SBU数据集上,所提算法的平均检测错误因子BER相对A+D-Net[18]、scGAN[17]、patched-CNN[16]、stacked-CNN[15]所得BER分别降低14.4%、46.3%、56.4%、55.6%;在UCF数据集上,所提算法的BER相对A+D-Net、scGAN、stacked-CNN所得BER的降幅分别为14.9%、26.8%、35.2%. 所提算法的总体检测正确率,在SBU数据集上达到95.53%,在UCF数据集上达到91.72%. 跨数据集验证的成功说明Attention Res-Unet方法的泛化能力很强,能够准确检测不同类型的阴影图像.
表 1 Attention Res-Unet与A+D-Net[18]、scGAN[17]、patched-CNN[16]、stacked-CNN[15]的定量评价结果
Tab.1
4.3. 各模块效果探究
为了研究Attention Res-Unet中各模块的作用,训练了3个不同的网络进行对比. 第1个是基本的U-net结构;第2个是Res-Unet结构,相较于Attention Res-Unet舍弃了注意力机制(注意力生成机制+注意力融合机制)以及非局部操作;第3个是Res-Unet+Attenion,在Res-Unet结构的基础上融入了注意力机制,但依然缺少非局部操作. 以上3个网络结构的复杂程度依次上升,与Attention Res-Unet的相似程度逐渐提高,可分别验证ResNeXt101特征提取模块、注意力机制以及非局部操作的作用. 在不同网络训练时使用相同的损失函数及训练策略,确保对比结果的可信度. 具体的实验结果如表2所示,Attention Res-Unet的3项指标都是最优(用加粗数字标出),说明本研究所提出的网络结构设计的合理性. 4个网络的BER分别为7.69、6.56、5.33、4.88,引入ResNeXt101特征提取模块后,BER降低14.69%;引入注意力模块后,BER降低18.75%;在输出层之前引入非局部操作后,BER降低8.44%. 和最简单的U-net结构相比,Attention Res-Unet的BER指标降幅达到36.54%. 另外,挑选了一些容易引起混淆的图像场景,测试这4个网络的阴影检测效果. 如图7所示,Attention Res-Unet的阴影检测结果与真实结果较接近,其他方法都出现了不同程度的错误分类,以及阴影区域不连续、不平滑,阴影边界粗糙的问题. 相较之下,Attention Res-Unet能够更准确地定位阴影边界,同时在易混淆场景中表现更佳,这与客观评价得到的结论一致.
表 2 Attention Res-Unet各模块作用验证
Tab.2
| 方法 | SBU[15] | ||
| BER | SER | NER | |
| U-net | 7.69 | 10.48 | 4.90 |
| Res-Unet | 6.56 | 7.40 | 5.73 |
| Res-Unet+Attenion | 5.33 | 5.88 | 4.77 |
| Attention Res-Unet | 4.88 | 5.31 | 4.44 |
图 7

图 7 Attention Res-Unet与Res-Unet+Attenion、Res-Unet、U-net检测结果的目视效果对比
Fig.7 Visual effect comparison of test results of Attention Res-Unet with Res-Unet+Attenion, Res-Unet and U-net
4.4. 更多的实验结果
图 8

图 8 Attention Res-Unet的其他实验结果
Fig.8 Other results produced by Attention Res-Unet
如图9所示为Attention Res-Unet在阴影检测时出现的典型失败案例. 如图9(a)所示,所提方法已经能够正确区分网球选手所穿的黑色衣裤与实际的阴影,说明网络在一定程度上结合了图像中的语义信息. 但对于人物主体以外的黑色袜子,类别判断出现了错误,一方面是因为特征提取模块能够提供的语义信息有限,且没有针对性,另一方面是袜子颜色与阴影颜色太过接近,难以区分. 如图9(b)所示的场景内容非常复杂,阴影区域分散程度高、个数多、面积小,难以提炼语义信息. 网络是在256×256的尺度下进行训练和测试的,更不利于检测小面积阴影区域,因此只能实现大致的阴影定位,无法精确绘制阴影轮廓. 一般来说,在更大的图像尺度下进行训练和测试能够减少误差的引入,但对计算机硬件有着更高的要求.
图 9

5. 结 语
针对阴影检测问题,提出全新的网络结构Attention Res-Unet,该网络使用ResNeXt101作为特征提取前端,并结合U-net的设计思想完成特征层的上采样过程,融入注意力机制和非局部操作进一步提升网络效果. 将训练后的网络在SBU、UCF数据集上进行验证,客观指标及主观目视效果皆优于此前方法. 同时,额外设计和训练了3个具有相似结构但缺少相应模块的网络,实验结果显示,使用深层网络进行特征提取,结合注意力机制和非局部操作都对网络性能的提升起到了实质性的作用. 提出的网络结构对大多数不同光照条件、不同投影表面、不同遮挡物体所形成的阴影区域都可以实现精确检测,但在某些严苛条件或复杂场景下表现不佳,下一步将着重研究如何更高效率地结合图像中的语义信息,减少像素的错误分类,以及如何解决小面积阴影区域的精确检测问题.
参考文献
A survey on shadow detection techniques in a single image
[J].
On the removal of shadows from images
[J].
Entropy minimization for shadow removal
[J].
Paired regions for shadow detection and removal
[J].
Single-image shadow detection and removal using local colour constancy computation
[J].
Shadow detection using color and edge information
[J].
Detecting soft shadows in a single outdoor image: from local edge-based models to global constraints
[J].
New spectrum ratio properties and features for shadow detection
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}