| Computer Technology |
|


|
|
|
| Heterogeneous information network representation learning based on transition probability matrix (HINtpm) |
Ting-ting ZHAO( ),zhe WANG*(),Yi-nan LU ),zhe WANG*(),Yi-nan LU |
| College of Computer Science and Technology, Key Laboratory of Symbolic Computation and Knowledge Engineering, Ministry of Education, Jilin University, Changchun 130012, China |
|
|
|
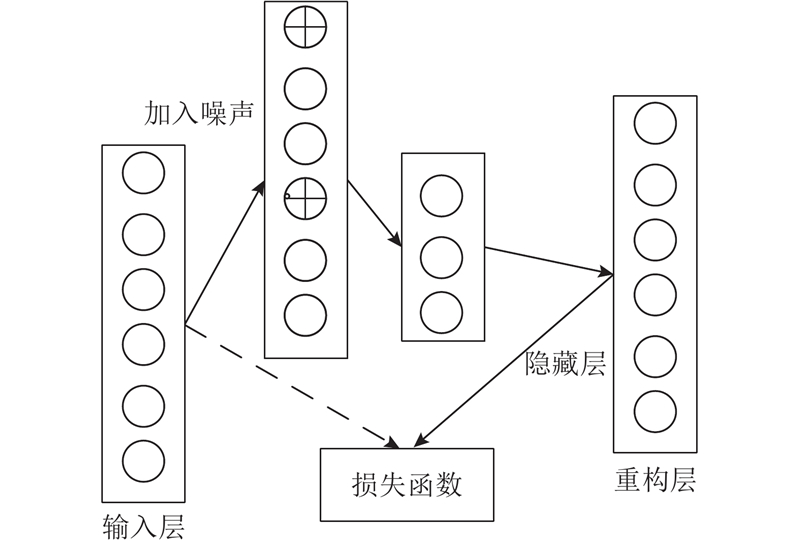
Abstract First, the final probability transition matrix was obtained by combining the first-order and second-order similarity of the nodes, according to the meta-path and the commuting matrix. Then, a Denoisin Auto-encoder was used to reduce the dimension of probability transition matrix for getting the node representation in heterogeneous information network. Finally, the node representation in heterogeneous information network was classified by gradient boosting decision tree (GBDT) and the classification accuracy under different percentage training set was obtained. Use the clustering index normalized mutual information (NMI) to evaluate the clustering effect and use T-SNE to show the visual effect. Experiments were performed on data sets DBLP and AMiner. The proposed heterogeneous information network representation learning based on transition probability matrix (HINtpm) was compared with DeepWalk, node2vec and metapath2vec methods. As results, compared with DeepWalk method, HINtpm improved the classification accuracy by 24% the maximum on the application task-node classify and increased the clustering index NMI by 13% the maximum.
|
|
Received: 05 February 2018
Published: 04 March 2019
|
|
|
|
Corresponding Authors:
zhe WANG
E-mail: zhaott16@mails.jlu.edu.cn;wz2000@jlu.edu.cn
|
基于传播概率矩阵的异构信息网络表示学习
根据元路径和可交换矩阵,结合节点一阶和二阶相似性得到最后的传播概率矩阵;利用降噪自动编码器对传播概率矩阵进行降维得到异构信息网络的节点表示;将异构信息网络的节点表示用梯度提升树(GBDT)分类,得到不同百分比训练集下的分类准确率,用聚类指标标准化互信息(NMI)评价聚类效果,用T-SNE展现可视化效果. 在数据集DBLP和AMiner上分别进行实验,相比DeepWalk、node2vec和metapath2vec方法,在应用任务节点分类上,所提出的基于传播概率矩阵的异构信息网络表示学习(HINtpm)的准确率与DeepWalk相比最高提升了24%,聚类指标NMI与DeepWalk相比最高提升了13%.
关键词:
网络表示学习,
异构信息网络(HIN),
传播概率矩阵,
元路径,
节点相似性,
自动编码器
|
|
| [1] |
涂存超, 杨成, 刘知远, 等 网络表示学习综述[J]. 中国科学: 信息科学, 2017, 47 (8): 980- 996
TU Cun-Chao, YANG Cheng, LIU Zhi-Yuan, at el Network representation learning: an overview[J]. SCIENTIA SINICA: Informations, 2017, 47 (8): 980- 996
|
|
|
| [2] |
ROWEIS S T, SAUL L K Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290 (5500): 2323- 2326
doi: 10.1126/science.290.5500.2323
|
|
|
| [3] |
COX T F, COX M A A. Multidimensional scaling [M]. Boca Raton: CRC Press, 2000: 123–141.
|
|
|
| [4] |
BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering [C] // Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic. Cambridge: MIT Press, 2001: 585–591.
|
|
|
| [5] |
CHEN M, YANG Q, TANG X O. Directed graph embedding [C] // Proceedings of the 20th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc, 2007: 2707–2712.
|
|
|
| [6] |
NALLAPATI R, COHEN W W. Link-PLSA-LDA: a new unsupervised model for topics and influence of blogs [C] // Proceedings of the 2nd International Conference on Weblogs and Social Media. Seattle: AAAI, 2008: 84–92.
|
|
|
| [7] |
CHANG J, BLEI D M. Relational topic models for document networks [C] // Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Cambridge: JMLR, 2009: 81–88.
|
|
|
| [8] |
LE T M V, LAUW H W. Probabilistic latent document network embedding [C] // Proceedings of the 2014 International Conference on Data Mining. Washington: IEEE Computer Society, 2014: 270–279.
|
|
|
| [9] |
WARD C K Word2Vec[J]. Natural Language Engineering, 2016, 23 (1): 155- 162
doi: 10.1017/S1351324916000334
|
|
|
| [10] |
TANG J, QU M, WANG M, et al. Line: large-scale information network embedding [C] // Proceedings of the 24th International Conference on World Wide Web. Florence: WWW, 2015: 1067–1077
|
|
|
| [11] |
WANG D, CUI P, ZHU W. Structural deep network embedding [C] // Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 1225–1234
|
|
|
| [12] |
TANG J, QU M, MEI Q. PTE: predictive text embedding through large-scale heterogeneous text networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 1165–1174.
|
|
|
| [13] |
CAO S S, LU W, XU Q K. GraRep: learning graph representations with global structural information [C] // ACM International on Conference on Information and Knowledge Management. Melbourne: ACM, 2015: 891–900.
|
|
|
| [14] |
YANG J, LESKOVEC J. Overlapping community detection at scale: a nonnegative matrix factorization approach [C] // Proceedings of the 6th ACM International Conference on Web Search and Data Mining. Rome: ACM, 2013: 587–596
|
|
|
| [15] |
LEY M. The DBLP Computer science bibliography: evolution, research issues, perspectives [C] // String Processing and Information Retrieval, International Symposium. Portugal: SPIRE, 2002: 1–10.
|
|
|
| [16] |
TANG J, ZHANG J, YAO L M, et al. ArnetMiner: extraction and mining of academic social networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas: SIGKDD, 2008: 990–998.
|
|
|
| [17] |
CHANG S Y, HAN W, TANG J L, et al. Heterogeneous network embedding via deep architectures [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 119–128.
|
|
|
| [18] |
JI M, HAN J W, DANILEVSKY M. Ranking-based classification of heterogeneous information networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego: ACM, 2011: 1298–1306.
|
|
|
| [19] |
DONG Y, CHAWLA N V, SWAMI A. Metapath2vec: Scalable representation learning for heterogeneous networks [C] // Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Nova Scotia: ACM, 2017: 135–144.
|
|
|
| [20] |
PEROZZI B, ALRFOU R, SKIENA S. DeepWalk: online learning of social representations [C]// ACM Sigkdd International Conference on Knowledge Discovery & Data Mining. New York: SIGKDD, 2014: 701-710.
|
|
|
| [21] |
GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: SIGKDD, 2016: 855–864.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|