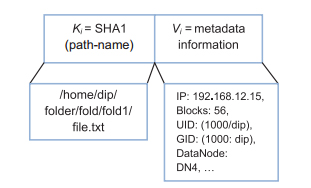
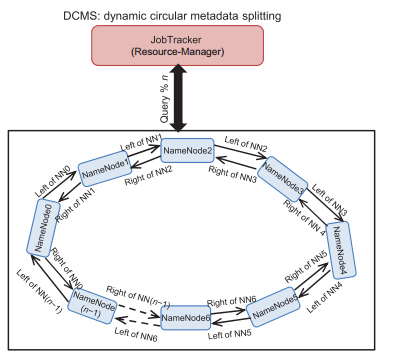
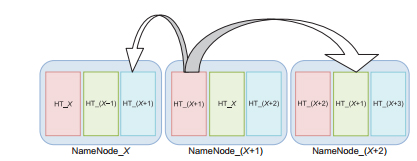
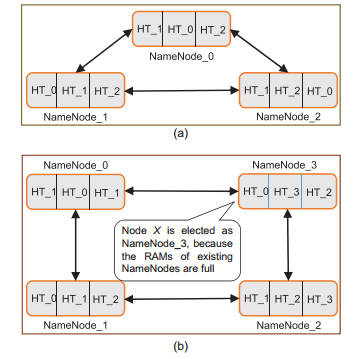
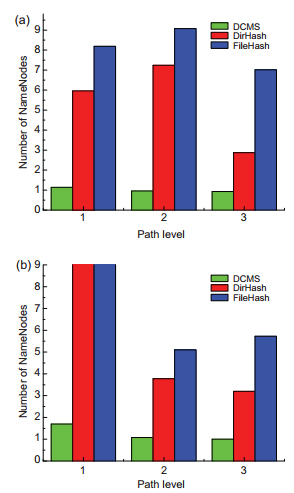
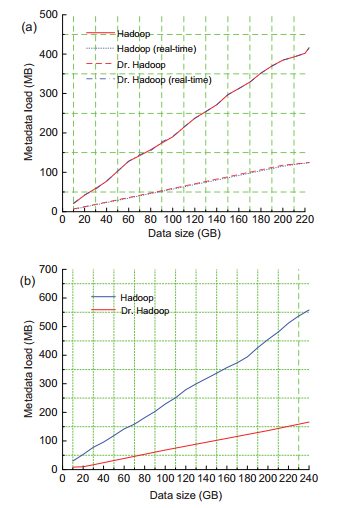
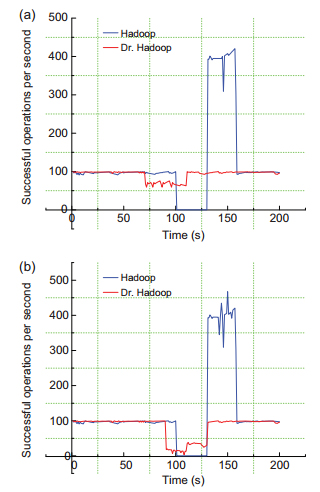
|
|
|
| Dr. Hadoop: an infinite scalable metadata management for Hadoop—How the baby elephant becomes immortal |
| Department of Computer Science and Engineering, NIT Silchar, India |
|
| Dr. Hadoop: an infinite scalable metadata management for Hadoop—How the baby elephant becomes immortal |
Dipayan DEV( ),Ripon PATGIRI() ),Ripon PATGIRI() |
| Department of Computer Science and Engineering, NIT Silchar, India |
| 1 |
Aguilera MK , Chen W , Toueg S . et al. . Heartbeat: a timeoutfree failure detector for quiescent reliable communication. 1997 Proc. 11th Int. Workshop on Distributed Algorithms: 126 - 140 doi: 10.1007/BFb0030680
doi: 10.1007/BFb0030680
|
| 2 |
Apache Software Foundation, Hot Standby for NameNode, 2012, Available from: http://issues.apache.org/jira/browse/HDFS-976
|
| 3 |
Beaver D , Kumar S , Li HC . et al. . Finding aneedle in haystack: Facebook??s photo storage. OSDI, 2010: 47-60
|
| 4 |
Biplob D , Sengupta S , Li J . et al. . FlashStore: high throughput persistent key-value store. 2010, Proc. VLDB Endowment: 1414 - 1425
|
| 5 |
Bisciglia C, Hadoop HA Configuration, 2009, Available from: http://www.cloudera.com/blog/2009/07/22/hadoop-haconfiguration/
|
| 6 |
Braam RZPJ . Lustre: a Scalable, High Performance File System, 2007, Inc, Cluster File Systems
|
| 7 |
Brandt SA , Miller EL , Long DDE . et al. . Efficient metadata management in large distributed storage systems. IEEE Symp. on Mass Storage Systems. 2003: 290 - 298
|
| 8 |
Cao Y , Chen C , Guo F . et al. . Es2: a cloud data storage system for supporting both OLTP and OLAP. 2011, Proc. IEEE ICDE: 291 - 302
|
| 9 |
Corbett PF , Feitelson DG . The Vesta parallel file system. ACM Trans. Comput. Syst, 1996, 14(3): 225 - 264 doi: 10.1145/233557.233558
doi: 10.1145/233557.233558
|
| 10 |
DeCandia G , Hastorun D , Jampani M . et al. . Dynamo: Amazon’s highly available key-value store. ACM SIGOPS Oper. Syst. Rev. 2007, 41(6): 205 - 220
|
| 11 |
Dev D , Patgiri R . Performance evaluation of HDFS in big data management. Int. Conf. on High Performance Computing and Applications. 2014: 1 - 7
|
| 12 |
Dev D , Patgiri R . HAR+: archive and metadata distribution! Why not both?. 2015, ICCCI (in press)
|
| 13 |
Escriva R , Wong B , Sirer EG . et al. . HyperDex: a distributed, searchable key-value store. ACM SIGCOMM Comput. Commun. Rev 2012, 42(4): 25 - 36 doi: 10.1145/2377677.2377681
doi: 10.1145/2377677.2377681
|
| 14 |
Fred H , McNab R . SimJava: a discrete event simulation library for Java . Simul. Ser. 1998, 30: 51 - 56
|
| 15 |
Ghemawat S , Gobioff H , Leung ST . et al. . The Google file system. 2003 Proc. 19th ACM Symp. on Operating Systems Principles: 29 - 43
|
| 16 |
Haddad IF . Pvfs: a parallel virtual file system for Linux clusters. Linux J. 2000: 5
|
| 17 |
Wiki, NameNode Failover, on Wiki Apache Hadoop.2012.Available from:http://wiki.apache.org/hadoop/NameNodeFailover
|
| 18 |
HDFS,Hadoop AvatarNode High Availability. 2010, Available from:http://hadoopblog.blogspot.com/2010/02/hadoop-namenode-high-availability.html
|
| 19 |
Karger D , Lehman E , Leighton F . et al. . Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. 1997, Proc. 29th Annual ACM Symp. on Theory of Computing: 654 - 663
|
| 20 |
Kavalanekar S , Worthington BL , Zhang Q . et al. . Characterization of storage workload traces from production Windows Servers. 2008, Proc. IEEE IISWC: 119 - 128
|
| 21 |
Lewin D . Consistent hashing and random trees: algorithms for caching in distributed networks. Master Thesis, Department of EECS, MIT. 1998
|
| 22 |
Lim H , Fan B , Andersen DG . et al. . SILT: a memory-efficient, high-performance key-value store. 2011, Proc. 23rd ACM Symp. on Operating Systems Principles.
|
| 23 |
McKusick MK , Quinlan S . GFS: evolution on fastforward. ACM Queue, 2009, 7(7): 10 - 20 doi: 10.1145/1594204.1594206
doi: 10.1145/1594204.1594206
|
| 24 |
Miller EL , Katz RH . Rama: an easy-to-use, highperformance parallel file system. Parall. Comput. 1997. 23(4-5): 419 - 446 doi: 10.1016/S0167-8191(97)00008-2
doi: 10.1016/S0167-8191(97)00008-2
|
| 25 |
Miller E.L., Greenan K., Leung A. Reliable and efficient metadata storage and indexing using nvram.. 2008, Available from: dcslab.hanyang.ac.kr/nvramos08/EthanMiller.pdf.
|
| 26 |
Nagle D , Serenyi D , Matthews A . The Panasas activescale storage cluster-delivering scalable high bandwidth storage.. 2004, Proc. ACM/IEEE SC : 1 - 10
|
| 27 |
Okorafor E , Patrick MK . Availability of Jobtracker machine in hadoop/mapreduce zookeeper coordinated clusters. Adv. Comput, 2012, 3(3): 19 - 30 doi: 10.5121/acij.2012.3302
doi: 10.5121/acij.2012.3302
|
| 28 |
Ousterhout JK , Costa HD , Harrison D . et al. . A trace-driven analysis of the Unix 4.2 BSD file system. 1985, SOSP: 15 - 24
|
| 29 |
Raicu I , Foste IT , Beckman P . Making a case for distributed file systems at exascale. 2011, Proc. 3rd Int. Workshop on Large-Scale System and Application Performance: 11 - 18 doi: 10.1145/1996029.1996034
doi: 10.1145/1996029.1996034
|
| 30 |
Rodeh O , Teperman A . ZFS—a scalable distributed file system using object disks. 2003, IEEE Symp. on Mass Storage Systems : 207 - 218
|
| 31 |
Satyanarayanan M , Kistler JJ , Kumar P . et al. . Coda: a highly available file system for a distributed workstation environment. IEEE Trans. Comput, 1990, 39(4): 447 - 459 doi: 10.1109/12.54838
doi: 10.1109/12.54838
|
| 32 |
Shvachko K , Kuang HR , Radia S . et al.. The Hadoop Distributed File System. 2010, IEEE 26th Symp. on Mass Storage Systems and Technologies: 1 - 10
|
| 33 |
Torodanhan, Best Practice: DB2 High Availability Disaster Recovery2009, Available from:http://www.ibm.com/developerworks/wikis/display/data/Best+Practice+-+DB2+High+Availability+Disaster+Recovery.
|
| 34 |
U.S Department of Commerce/NIST, 1995, VA FIPS 180-1. Secure Hash Standard. National Technical Information Service, Springfield
|
| 35 |
Wang F , Qiu J , Yang J . Hadoop high availability through metadata replication. 2009, Proc. 1st Int. Workshop on Cloud Data Management: 37 - 44 doi: 10.1145/1651263.1651271
doi: 10.1145/1651263.1651271
|
| 36 |
Weil SA , Pollack KT , Brandt SA . et al. . Dynamic metadata management for petabyte-scale file systems. 2004, SC: 47
|
| 37 |
Weil SA , Brandt SA , Miller EL . et al. . CEPH: a scalable, high-performance distributed file system. 2006, OSDI: 307 - 320
|
| 38 |
White T . Hadoop: the Definitive Guide. 2009, O’Reilly Media, Inc.
|
| 39 |
White BS , Walker M , Humphrey M . et al. . Legionfs: a secure and scalable file system supporting cross-domain highperformance applications. 2001, Proc. ACM/IEEE Conf. on Supercomputing: 59
|
| 40 |
Yadava H . The Berkeley DB Book. 2007, (Apress)
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|