

近年来深度神经网络(deep neural network, DNN)深刻改变着人们的生产生活方式. 自2009年ImageNet提出后,各种结构复杂的神经网络相继被提出以提升精度,如AlexNet[1]、ResNet[2],模型规模及计算量爆炸性增长[3]. 这给如何在资源和性能受限的终端平台上有效部署深度学习模型带来了挑战. 1)深度学习模型通常是计算密集型的大规模网络,需要较高的存储、计算和能耗资源,而终端设备的资源通常是有限的. 2)终端设备的计算情境差异性大,而深度学习模型通常是基于特定数据集进行训练的,对复杂计算情境的适应能力差. 3)在设备运行过程中,设备电量、存储空间、网络带宽等都处于动态变化过程中,为深度学习模型的鲁棒运行带来了巨大考验.
面对上述挑战,边缘智能(edge intelligence)应运而生[4],旨在协同终端设备与边缘设备,在靠近数据源头的用户端部署深度学习模型. 边缘智能整合了终端本地化计算无需大量数据传输与边缘端较强计算和存储能力的互补优势,将模型的推断过程由云端下沉至靠近用户的边端,在加强数据隐私的同时,避免不稳定网络状态的影响,提高服务的响应时间. 考虑到边端设备资源和网络状态的动态变化特性,现有工作无法提供动态自适应的边端协同计算模式.
本文提出面向动态变化终端应用情境的自适应边(边缘)端(终端)协同计算模式. 通过主动感知终端情境(待部署平台的资源约束、性能需求等),分别利用自适应的模型压缩和模型分割技术对深度学习模型结构(即模型结构化剪枝)和协同计算模式(即边缘/终端分割点)进行自动调优,实现自适应鲁棒的边缘智能.
1. 相关工作
随着对深度学习网络结构设计的复杂化,高昂的存储、计算资源需求使得难以有效将深度学习模型部署在不同的硬件平台上. 研究人员已从不同角度探索该问题的解决方案,包括边缘智能技术中的模型压缩、模型分割、模型选择及输入过滤等. 其中模型压缩技术及模型分割技术应用最广泛,下面将分别进行介绍.
1.1. 模型压缩技术
模型压缩是在神经网络训练期间或之后,通过修剪权重或其他方式降低模型复杂度,在保持精度的同时缩小原始网络的计算量和存储成本. 目前,国内外已有很多关于模型压缩的相关工作,主要可以分为知识蒸馏、低秩分解、网络剪枝、紧凑网络设计等不同方面. 其中知识蒸馏旨在将预先训练好的复杂教师模型中的输出作为监督信息,训练另一个结构简单的学生模型. Luo等[5]提出利用学习的领域知识,使用神经元选择的方法选择与面部识别最相关的神经元,以实现领域知识的迁移. 网络剪枝旨在剔除权重矩阵中“不重要”的冗余参数,仅保留对网络性能具有较大影响的重要参数,有效地降低了网络参数数量. 按照修剪粒度,可以分为非结构化剪枝和结构化剪枝. 非结构化剪枝是指将网络中的任意权重作为单个参数,进行修剪. Han等[6]将网络剪枝转化为从权重参数中选择最优权重组合的问题,实现对卷积核参数的修剪. 非结构化剪枝虽然可以大幅提高剪枝效率,但会导致网络连接不规整,且需要专业下层硬件和计算库的支持,否则剪枝后的网络性能很难得到提升. 结构化剪枝是粗粒度修剪,主要针对深度学习模型中的过滤器和通道进行修剪. ThiNet[7]以过滤器为单位进行剪枝,通过每层过滤器的输出判断是否修剪该过滤器. 结构化剪枝可以保证权值矩阵的完整性,但模型精度会大幅下降. 目前,网络剪枝的方法是模型压缩领域应用最广泛和简单有效的方法.
目前的研究存在不足. 模型压缩技术的自适应程度较低,大多需要提前设定压缩的比例,无法根据硬件资源的动态变化自动调整压缩比例,且压缩后的模型常常面临资源需求不能满足或精度过低等问题. 考虑将模型压缩与模型分割技术相结合,协同边缘设备计算,在不损失精度的情况下有效降低运行总时延.
1.2. 模型分割技术
模型分割技术旨在根据不同粒度对模型进行分割,根据性能需求和模型资源消耗自动寻找最佳分割点,将深度模型的不同执行部分部署至多台边端设备上进行运行,实现多设备的协同计算. 该方向的研究重点是如何寻找最佳分割点. Kang等[10]提出轻量级的模型分割调度框架——Neuro-surgeon,可以通过最小化时延或能耗,在终端和云端以层为粒度自动对深度学习模型进行分割. JALAD[11]模型将模型分割问题建模为整数线性规划问题,在满足模型精度限制的情况下,通过最小化模型的推理时延寻找最佳分割点. MoDNN[12]模型从计算量入手,考虑将网络中的卷积层和全连接层分割,使得计算量分配至不同移动设备上,通过移动设备间协作实现高效的模型推理. Ko等[13]通过将分割后待传输的数据与有损编码技术结合,实现对传输时延的加速,从而降低整体的模型推断时间.
尽管目前的模型分割技术已经具备对模型运行环境的自适应能力,然而在动态硬件资源和网络通信环境下,深度学习模型的分割点应该是不断变化的,如何快速根据情境变化来重新选择适当的分割点成为一个重要挑战. 本文提出GADS算法,以当前分割状态为导向,优先在相似分割状态中搜索,实现分割点的快速自适应调整.
2. X-ADMM边端融合模型自适应
针对模型压缩后较大体量的模型可能无法部署在资源较受限的终端设备上,同时在受限的设备资源约束下难以在压缩比和精度之间权衡的问题,基于AutoCompress模型[14],提出X-ADMM模型. 结合模型压缩与模型分割,在离线状态下对神经网络模型进行压缩,即根据设定的压缩率进行压缩. 根据网络状况和时延需求,在线寻找合适的模型分割点,将神经网络部署至多台边端设备上.
模型压缩可以实现模型的初步简化,为了更好的模型分割奠基,模型分割可以解决模型压缩后所遇到的无法顺利部署及精度下降等问题,两者相辅相成、紧密结合. 模型分割技术的加入可以在保护用户数据隐私的情况下,协同边缘设备和终端设备,利用了边缘设备强大的计算能力,有效降低总时延,减少模型单台设备上的资源消耗.
2.1. 模型压缩
在模型压缩方面,利用AutoCompress中基于ADMM的权重修剪方案作为核心算法,采用结构化修剪方法,结合ADMM对网络参数进行精细的修剪. 具体的修剪流程如图1所示,包括以下4个步骤:1)动作抽样;2)快速动作评估;3)决定策略;4)实际修剪与结果生成.
图 1
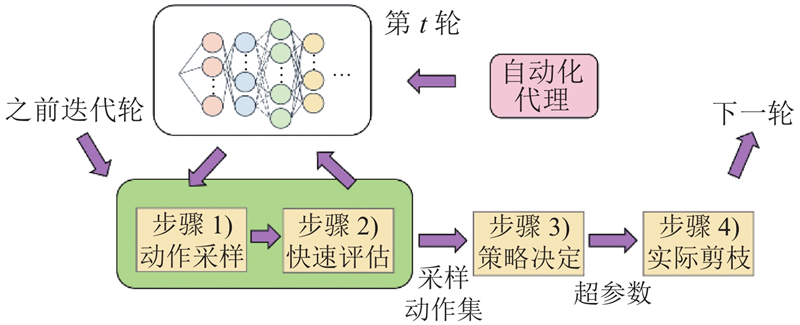
动作抽样对超参数进行一次样本选择,得到一个动作表示. 由于超参数的搜索空间很大,若使用实际测量精度损失的方法会极为耗时,则步骤2)选择简单启发式的方法进行精度快速评估. 步骤3)根据动作样本的集合和精度评估,对超参数值进行决策. 步骤4)利用基于ADMM结构化剪枝的核心算法,进行实际的修剪. 模型运行过程是迭代进行的,步骤1)~5)的运行为一个循环,支持灵活的轮数设置,在给定精度的情况下实现最大程度的权重修剪.
在实际模型的修剪过程中,结构化剪枝中网络每层的修剪率、每层的修剪方式(或修剪方式的组合)均作为超参数待定,确定这些超参数最重要的步骤是ADMM规范化. 将DNN的损失函数定义为
利用增广拉格朗日方法,将该问题转化为可以迭代求解的2个子问题,如式(3)所示.
式中:
图 2
2.2. 模型分割
在模型推理的前向传播过程中,数据经过输入层、隐藏层最终传输到输出层,得到预测结果. 理论上只需保证层间数据传输的准确性,就可将模型的不同层部署至不同设备上运行. 模型分割算法即是基于这一理论实现的. 所以模型分割技术和模型压缩技术是互相独立的,两者互不影响,可以从不同层面降低复杂模型对设备硬件资源的需求. 模型压缩是通过减小模型冗余的方法,使得模型可以顺利部署至资源受限的设备上,但通常会产生模型精度的损失. 若设备资源上限十分受限,算法需要在精度下降和资源消耗之间进行平衡. 模型分割可以在不损失精度的同时,协同多个设备计算模型不同部分,完成整体的推理过程. 基于上述观察,考虑将模型压缩方案与模型分割方案相结合,实现更加高效与快速的模型推理.
在模型压缩完成后,初步实现对模型规模的缩减. 采用以层为粒度[10]的分割方式,即在神经网络层之后进行分割. 预测神经网络各层的推断时延,计算在每层之后进行分割所产生的总推断时延及各设备上的资源消耗. 根据任务的实时性能需求(推断时延、资源上限),选择最佳分割点. 总之,在模型压缩方案之后,采用模型分割技术,根据总时延寻找最佳分割点,将其部署至边端设备上.
每种分割方案总时延的计算参考DADS工作[16],将网络运行的总时延分为计算时延及传输时延. 以2台设备(边缘设备及终端设备)为例,总时延计算为
式中:
以
传输时延为
式中:
3. GADS边端融合模型快速自适应
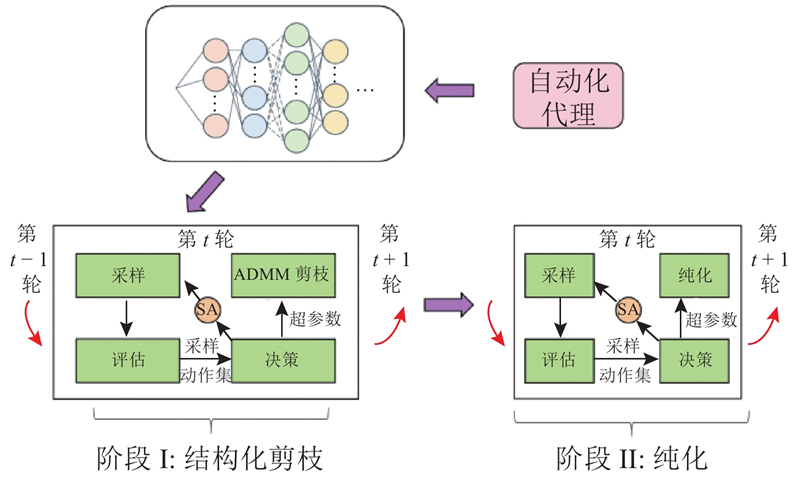
当设备运行情境发生变化、导致设备资源预算变化或实时性能目标(推断时延)发生变化时,X-ADMM算法需要重新运行以调优模型,耗时且耗能,无法在动态情境下提供实时调优方案. 为了满足动态情境下模型快速自适应能力的需求,从模型分割阶段着手,改进X-ADMM方法,提出基于图的自适应DNN手术刀算法(graph based adaptive DNN surgery,GADS). 该方案在模型分割的实现过程中,无需在情境产生变化时重新运行,而是主动捕捉目标部署设备的资源约束. 动态调优模型分割点,产生新的模型计算方案,实现实时自适应的边端协同计算.
介绍模型分割实验中发现的最优分割点周围存在次优分割点的规律,将其命名为最近邻边端模型分割效应. 提出基于图的自适应DNN手术刀算法(graph based adaptive DNN surgery,GADS),为动态情境在局部区域寻找最佳分割点. 目的是在最短时间内寻找最能满足资源约束的分割方案,实现模型的快速自适应调优.
3.1. 最近邻边端模型分割效应及GADS算法的提出
在以层为粒度划分DNN的实验中发现,最优分割点附近总是存在次优分割点,如图3(a)所示. 将其命名为最近邻边端模型分割效应,以指导资源状态动态变化时深度模型最优分割点的快速搜索.
模型的推断总时延由在各设备上的计算时延和传输时延构成,目标是找到使总时延最短的最优分割点,实现模型计算时延和传输时延间的折中,使模型总推断时延较小. 如图3(b)所示(以AlexNet为例),DNN模型中各层的
图 3
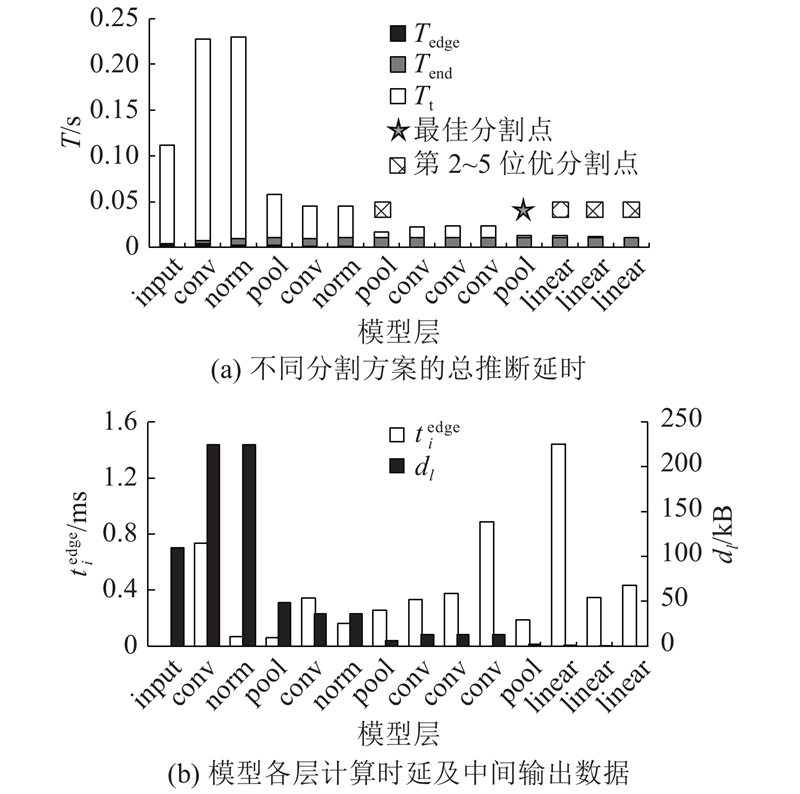
根据对模型各层计算时延及中间输出数据变化趋势的分析,模型分割算法选择不同层进行分割时,倾向于选择后面几层进行分割,从而将前端计算时延较短的层部署在终端,可以选择中间输出数据较小的层,避免大量传输时延. 在计算能力较强的终端或边缘端执行模型后端的部分,利用高计算能力,减少总时延. 这导致了“最近邻边端模型分割效应”的出现. 近邻效应本质上由网络各层的输出数据量、带宽和计算延迟决定,验证在不同带宽和不同模型下最近邻边端模型分割效应的普适性.
基于上述规律,提出基于图的自适应DNN手术刀算法——GADS算法,算法概念图如图4所示. 当模型运行的情境(如设备存储资源、设备电量或网络带宽等)发生变化时,主动感知当前情境,以感知到的设备资源预算作为资源约束条件Target(反映为设备存储资源预算
图 4

3.2. 最优分割点近邻规律验证
针对3.1节阐述的最优分割方式周围存在次优分割方式的规律进行验证及探讨,验证网络带宽发生变化时规律的连续性以及网络结构发生变化时(如ResNet、VGG、GoogleNet等不同网络结构)规律的普适性.
3.2.1. 带宽变化下的规律验证
在以WIFI作为数据传输媒介的情况下,网络带宽设定为0.5~20 MB/s,实验结果如图5所示. 在不同的网络带宽下,模型最优分割点附近分割点的总时延不会出现突变,即最优分割点周围存在次优分割点的规律依然存在.
图 5
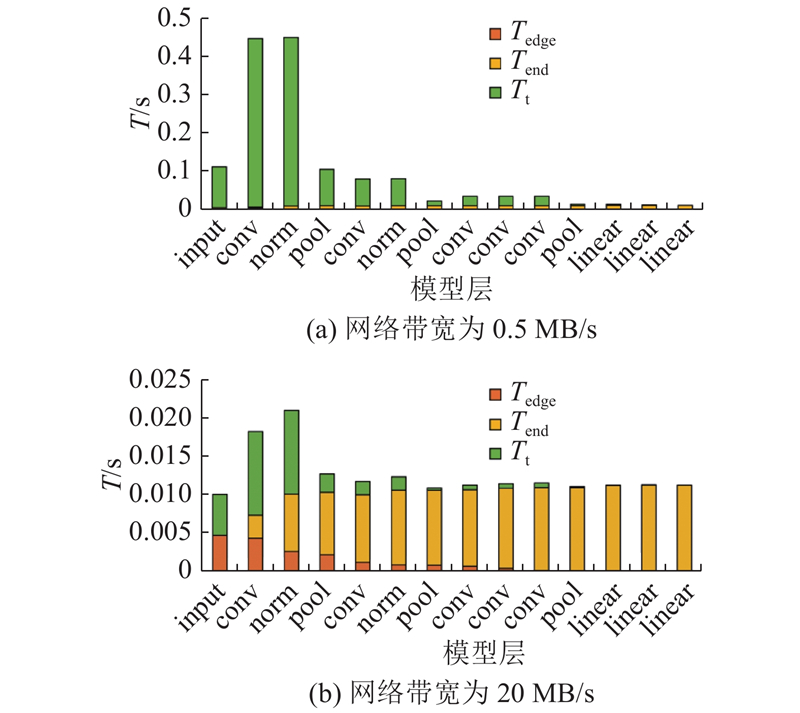
图 5 不同网络带宽下对AlexNet进行划分的总时延
Fig.5 Inference latency for AlexNet with different bandwidths
在相同的网络分割情况下,当网络带宽变小时,边缘计算及终端计算时延保持不变,数据传输时延变长在总时延中的占比变大,如图5(b)所示. 当模型及待部署设备不变,带宽发生变化的情况下,该规律的本质是由神经网络每层输出数据量(待传输数据量)决定的.
如图6所示,AlexNet网络中卷积层每层的输出数据量较大,尤其前3个卷积层使用数百个过滤器提取图片特征,产生大量的输出数据;全连接层的各层输出数据较小. 当网络带宽变化时,模型分割算法在数据输出量较小的层后分割,可以保证模型具有较低的总运行时延,分割点的选择与各层输出数据量密切相关. 最近邻边端模型分割效应在带宽变化下具有连续性.
图 6
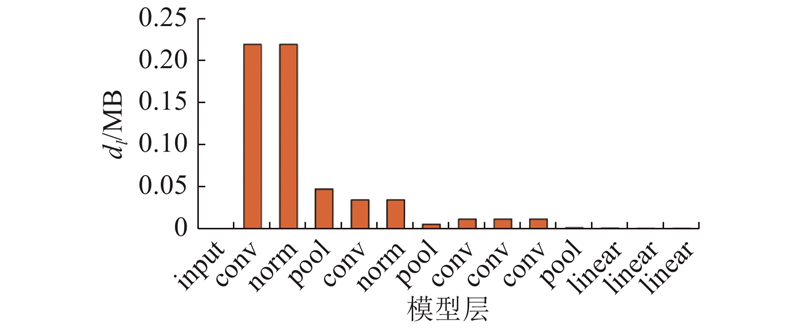
3.2.2. 网络结构变化下的规律验证
最优分割点近邻规律由AlexNet网络每层输出数据量及设备的异构性决定. 以CNN中的几个经典模型:VGG、ResNet-18为例,分析该规律在卷积神经网络中是否具有普适性.
在网络带宽为2 MB/s的情况下,各网络运行总时延如图7所示. 可以看出,不同结构CNN网络在运行总时延变化规律上是类似的,证明最优分割点周围存在次优分割点的规律性不因网络结构的变化而发生改变.
图 7
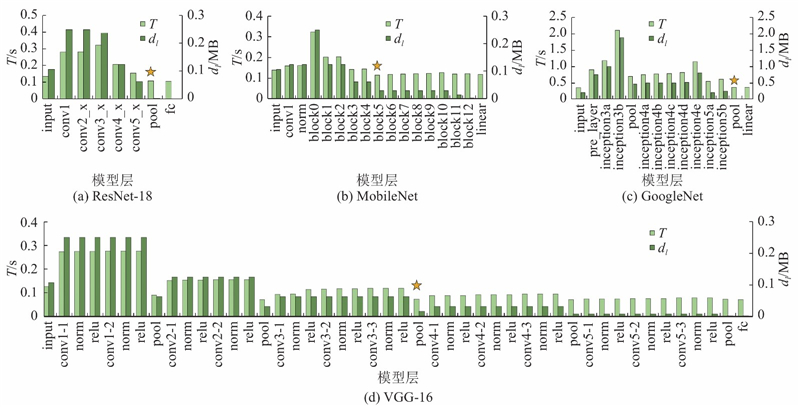
图 7 经典CNN不同分割方案下总时延及输出数据变化图
Fig.7 Inference latency and output data size under different partitions of CNNs
3.3. GADS算法
3.3.1. 模型分割状态结点构建
将DNN网络的分割状态建模为图结构,各结点表示一种网络的分割状态,以结点间的连线体现分割状态之间的相邻关系. 令
图 8
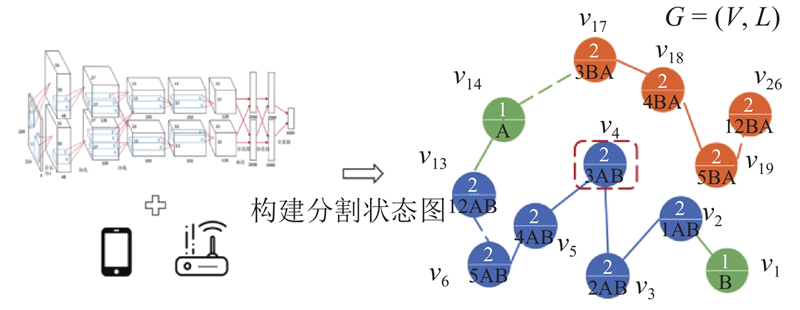
图 8 构建2台设备下的模型分割状态图
Fig.8 Construction of model partition state graph on two devices
以局部分割图为例,如图9所示,每个结点由3个参数组成,框选结点表示当前网络被分割为2个执行部分,分割点选择在第3层之后,将其顺序部署至A、B 2个设备上. 各分割状态结点所代表的实例点以该分割方案在各设备上的资源消耗表示.
图 9
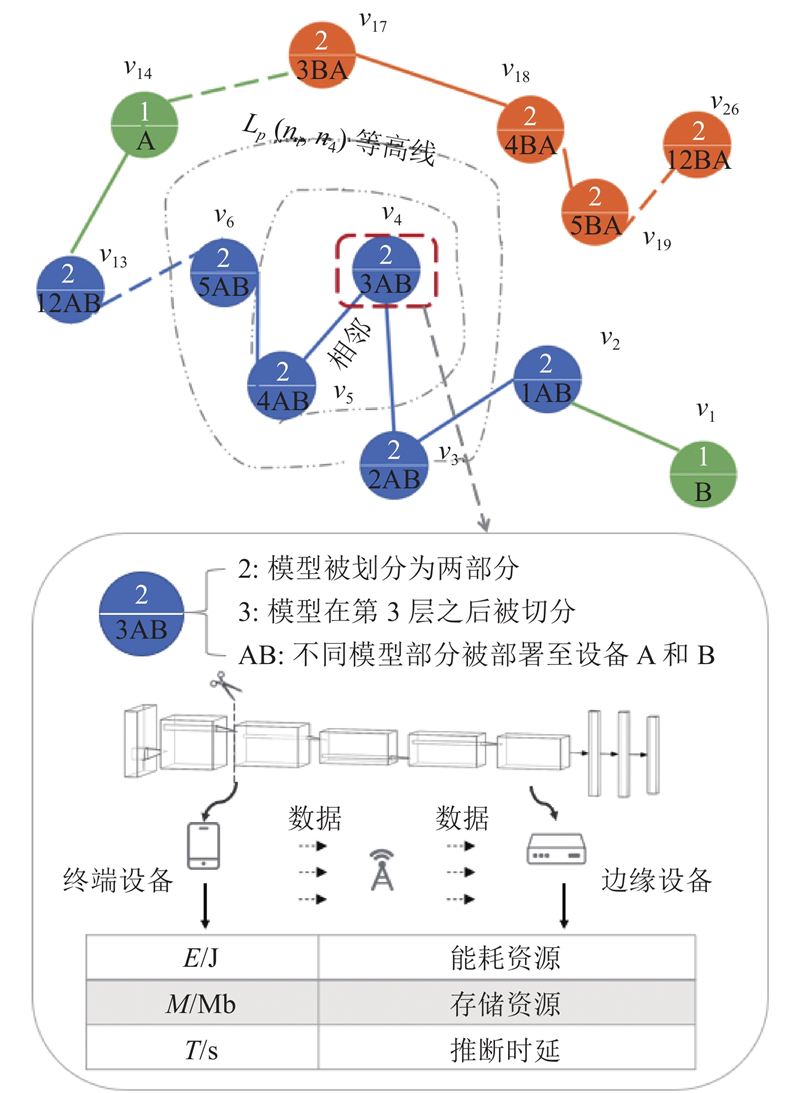
将在模型结构中分割点相邻2个分割方案定义为相邻,将相邻的对应分割状态结点相连,如框选分割状态结点在第3层进行分割,分割点向前向后移动可与其他2个分割状态结点相连. 如图9的
该结构可以体现最近邻边端模型分割效应,以便指导后续的搜索过程. 如图9所示,与
3.3.2. 分割状态量化
1)分割状态情境量化. 程序在设备上运行时需要许多系统资源,例如存储资源和计算资源. 算法要实现根据情境自适应调优模型,须主动捕捉设备中动态变化的资源状态(设备存储资源、设备电量、网络带宽),建模为程序可使用的资源约束,实现对情境的实时感知. 如式(8)所示,根据设备的存储资源,利用函数关系映射到当前程序可使用的存储资源上限上:
式中:
2)分割状态结点量化. 根据3个重要的情境指标,对分割状态结点进行量化,分别为存储、能耗、时延. 使用矩阵表示各设备的指标,如下所示(以2台设备为例):
式中:R是由当前分割状态结点决定的,其中
式中:T ′为用户对模型的实时时延约束.
根据当前分割状态,量化各指标的公式如下.
a)存储M. 参考AdaDeep[8]中对DNN各资源约束的量化规范,网络运行所需的存储资源由网络中偏置量和权值所需的存储位数决定,如下所示:
式中:
某设备上的
b)能耗E. 模型的能耗可以分为计算能耗
式中:以
c)总时延T. 网络运行的总时延可以分为计算时延及传输时延,以2台异构设备(边缘设备、终端设备)为例,总时延的公式为
式中:
具体每项时延的计算可见3.2节. 其中传输时延计算中的带宽可以体现情境中网络状态的动态变化,如式(7)所示.
3.3.3. GADS算法实现
基于对DNN网络的分割状态建模得到的图结构,提出GADS算法. 当终端设备情境发生变化时,以当前分割状态结点为导向,确定相邻分割状态结点为搜索子集;利用最优分割点周围存在次优分割点的规律,快速搜索合适的分割状态并对DNN进行相应分割,部署到多台设备上实现协同运行.
在分割状态结点搜索的过程中,有许多常用的方法,例如KNN最近邻搜索,可以通过比较所有结点与Target之间的距离(体现2个分割状态间的相似程度)寻找全局最近邻,但是不能高效地解决特征数据是高维复杂的问题(如3.3.2节所示,2台异构设备下,指标矩阵是五维的). 考虑使用KD树最近邻搜索算法,搜索次优分割点. KD树最近邻搜索是针对高维特征数据进行存储、以便进行快速查找的数据结构,可以将K维的特征数据切分在不同的空间中,每次选择其中1个维度将数据划分为2部分,直到所有的特征数据被划分完毕. 若有一组二维特征数据,KD树如图10所示.
图 10
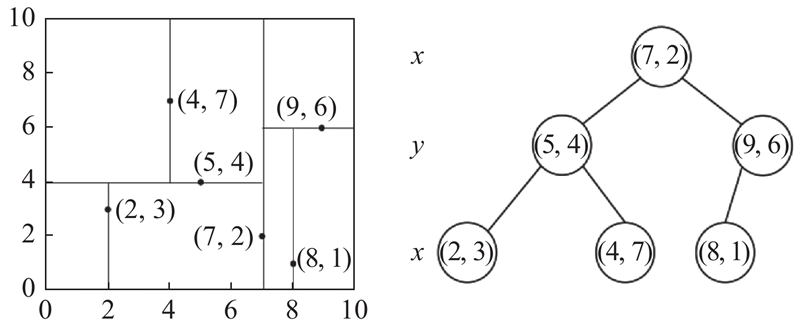
在构建完成KD树后,根据目标点Target寻找最近邻分割状态的步骤如下.
1)在KD树中确定包含Target的叶结点(根据KD树的构建原理可知,各结点会对应一个超平面). 由根结点向下递归访问,若Target坐标值小于切分点坐标值,则移动至左子结点,否则移动至右子结点,直至子结点为叶子结点.
2)以该叶子结点为“当前最近点”.
3)由“当前最近点”递归向上回退,在各结点进行以下判断.
a)若该结点对应的实例点较当前最近点距离Target更近,则将该结点作为“当前最近点”.
b)检查该结点的父结点,查看父结点另一子结点区域,是否有更近的结点. 以Target为圆心、Target和当前最近点的距离为半径,判断另一子结点对应区域是否与该圆相交. 若相交,则该区域可能存在距Target更近的结点;若不相交,则继续向上回退.
4)当搜索过程回退至根结点时,搜索结束,“当前最近点”为KD树中距Target最近的结点.
总之,KD树通过将K维空间中相距较近的特征数据提前划分在一起,在最近邻搜索的过程中,借助KD树中每个结点代表的空间范围,可以提前判断该分支是否可能存在最近邻结点,以减少对大量数据点的检索,实现加速搜索.
将KD树最近邻搜索作为GADS算法的核心搜索算法,定义
式中:
由于各项指标的数值量级不在统一标准下,单位不同,且
式中:
搜索合适分割方式的问题转化为带距离的图结构,参考最近邻搜索解决该问题. GADS算法的具体流程如下.
算法1:GADS算法
输入:设备情境,网络带宽
输出:调优后的分割状态
确定设备指标约束矩阵
构建
If
以任意当前分割状态的近邻分割状态为“当前最近点”
While
由
以
扩大搜索子集
Else
部署
s步选择的意义如下:1)GADS算法并非为了寻找全局最优解;2)加入s步可以加速寻找最近邻.
4. 实验验证
4.1. 数据集选择和实验设置
在X-ADMM实验中,利用树莓派4作为终端设备,戴尔Inspiron 13-7368模拟边缘设备,对X-ADMM模型的有效性进行验证. 神经网络模型分别选择AlexNet、GoogleNet、ResNet-18及VGG-16、MobileNet、ShuffleNet 6个图像处理领域常用的CNN网络进行实验.
在模型压缩实验过程中,利用CIFAR-10数据集进行模型训练,CIFAR-10是普适的彩色图片小型数据集. 模型网络结构代码基于Pytorch实现,网络实现及模型参数设置如下. 在模型压缩阶段,训练过程的批次大小设为64,优化器选择Adam优化器,学习率设置为10−3. 在模型分割阶段,需要根据最佳分割点,将网络不同层部署至不同设备上运行. 在Pytorch框架中,神经网络模型的前向传播函数接收输入后,会一次性执行所有的网络层得到对应的输出,因此对神经网络的前向传播函数进行重构,为前向传播函数的参数增加起始层、中止层及是否是训练阶段3个特殊参数(startLayer、endLayer、isTrain),使得网络模型可以根据分割点所决定的起止层划分网络并部署,避免了对训练过程的影响.
4.2. X-ADMM模型实验结果
模型压缩后的实验结果如图11所示. 图中,kt、ka分别为时延下降比例和精度下降比例. 可以看出,模型压缩技术对4个模型的性能都有不同程度的提升,经过16倍的压缩之后(实验设定的压缩比例),模型推断时间获得了不同的加速效果. 其中AlexNet、GoogleNet、ResNet-18及VGG-16网络分别在精度下降不超过2.5%的情况下,实现了14.1%、3.6%、6.2%、23.5%的加速效果. 基于ADMM的结构化剪枝可以实现在保证精度不产生较大损失的情况下,减少模型参数量和计算量. 经过模型压缩之后,X-ADMM根据总时延、能耗及网络带宽等的要求,自动寻找当前的最佳模型分割点.
图 11
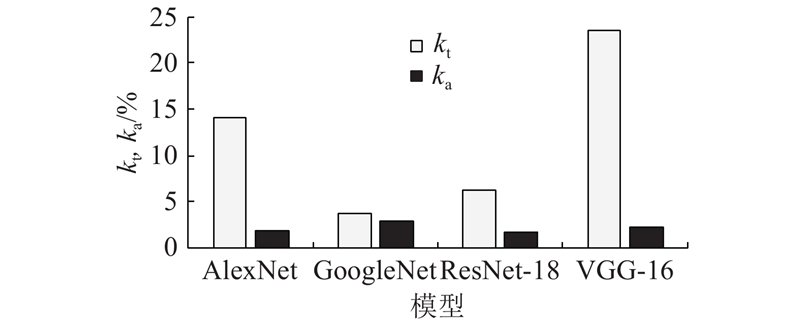
图 11 模型压缩后推断延迟和精度下降比例
Fig.11 Drop ratio of inference latency and accuracy of models after compression
最终X-ADMM的实验结果见表1. 表中,A0、T0为执行X-ADMM算法前的准确率和推断时间,γ为压缩比,TRAP-ADMM、ARAP-ADMM分别为RAP-ADMM推断时间和准确率,TX-ADMM、AX-ADMM分别为X-ADMM推断时间和准确率. 可以看出,经过进一步的模型分割,在6个模型精度基本保持不变的情况下,总推断时间分别下降了22.4%、43.56%、25.2%、56.65%、26.87%、24.36%. 因为由AlexNet至VGG-16模型的复杂度和网络规模逐渐升高,经过模型相同倍数的压缩后,对大体量模型的简化效果更明显. 根据对MobileNet不同倍数的压缩结果发现,随着模型压缩比的增大,模型精度显著下降,甚至在实验过程中8倍压缩后的MobileNet网络无法实现超过15%的精度.
表 1 不同方法下典型深度学习模型的推断时延和精度
Tab.1
| 网络 | A0 /% | T0 /ms | γ | TRAP-ADMM[19] /ms | ARAP-ADMM /% | TX-ADMM /ms | AX-ADMM /% |
| Alexnet | 85.82 | 46.8 | 14.7 | 38.78 | 84.21 | 36.3 | 84.17 |
| GoogleNet | 87.48 | 943.6 | 15.6 | 883.95 | 84.91 | 532.6 | 84.60 |
| Resnet-18 | 91.60 | 285.5 | 15.4 | 267.70 | 90.01 | 213.5 | 89.80 |
| VGG-16 | 91.66 | 203.7 | 16.0 | 186.90 | 89.59 | 88.3 | 89.20 |
| MobileNet | 89.60 | 219.2 | 2.0 | 207.89 | 87.96 | 179.2 | 87.90 |
| MobileNet | 89.60 | 219.2 | 4.0 | 196.69 | 80.60 | 160.3 | 80.83 |
| ShuffleNet | 88.14 | 202.8 | 4.0 | 183.79 | 84.25 | 153.4 | 84.19 |
将X-ADMM与先进模型压缩算法RAP-ADMM[19]进行性能对比. 实验结果表明,在深度学习模型上,X-ADMM在有限精度损失的情况下,性能均优于RAP-ADMM所取得的加速效果. X-ADMM与RAP-ADMM相比,各网络的总推断时延分别节省了6.40%、39.75%、20.25%、52.76%、18.50%、16.54%.
总之,X-ADMM结合模型压缩及模型分割技术,减少了模型计算量,有效降低了总推断时间,同时保持模型精度基本不变.
4.3. GADS算法实验结果
4.3.1. ${L_p}$
针对利用
实验结果如图12所示. 图中,实心五角星表示GADS搜索到的最佳分割点,实心正方形表示GADS搜索到的第2~5位优分割点,空心五角星及正方形对应KNN搜索到的最佳分割点及第2~5位优分割点.
图 12
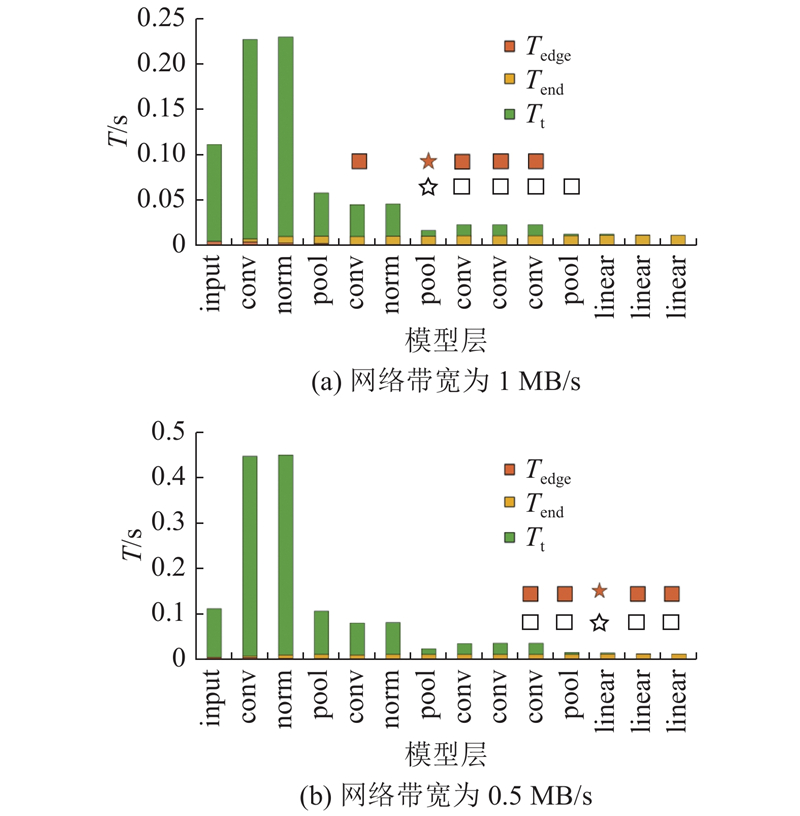
图 12 KNN(K近邻算法)与KD树搜索的效果对比
Fig.12 Comparison of KNN(K-nearest neighbor)and KD trees search approaches
从图12可得如下结论. 1)在相同的指标约束下,利用2种算法搜索到的前3个较优分割方式相同. 2)在相同的指标约束下,利用2种算法搜索到的各较优分割方式相邻,吻合最优分割方式周围存在次优分割方式的规律. 3)在相同的指标约束下,GADS搜索算法由于受到步数的限制,可能与KNN的全局搜索结果不同,如图12(a)所示,选择合适的s可以加快GADS算法的搜索过程,保证搜索到较优的分割方式(CNN中卷积层的前几层主要是为了提取图像特征,s选择非全连接层数的一半较合适). 4)如图12(a)中GADS的搜索结果所示,算法的次优分割点并非推断总时延最小的几个分割点. 因为位于全连接的分割方式虽然推断总时延较小,但会使得终端设备上占用存储资源和运行能耗产生较大的提高,说明了GADS算法以多指标为综合评价标准在选择最优分割点过程中的有效性.
在不同的设备情境,即网络带宽为0.5 MB/S的情况下的搜索效果对比如图12(b)所示. 该情境下更倾向于在模型的全连接层进行划分,因为在网络状态较差的情况下,数据传输时延的高昂代价无法被边缘端的计算优势抵消.
4.3.2. KD树搜索有效性验证
将KD树最近邻搜索为核心的GADS算法与KNN最近邻搜索算法、Neurosurgeon等优秀的模型分割算法进行实验对比,研究并验证KD树搜索在搜索次优分割点过程中的有效性.
在实验中,Neurosurgeon的时延计算采用与本文相同的计算方式(见3.3.2节). 实验结果如表2所示. 表中,
表 2 KD树搜索的有效性
Tab.2
| 算法 | | |
| Neurosurgeon | 0.0822 | 0.4412 |
| GADS-KNN | 0.0452 | 0.9927 |
| GADS-KD树(无s) | 0.0452 | 0.1331 |
| GADS | 0.0581 | 0.0997 |
4.3.3. GADS自适应能力验证
表 3 GADS自适应能力实验结果
Tab.3
| 情境变化 | M1 /MB | M2 /MB | E1 /J | E2 /J | T ′ /s | B /(MB·s−1) | 变化前分割状态集 | 变化后分割状态集 |
| 移动端存储减少 | 230 | 9 | 0.02 | 0.02 | 0.01 | 6 | 8,10,9 | 7,8,10 |
| 移动端存储减少 | 230 | 4.5 | 0.02 | 0.02 | 0.01 | 6 | ||
| 移动端电量降低 | 230 | 9 | 0.02 | 0.02 | 0.01 | 6 | 8,10,9 | 6,7,8 |
| 移动端电量降低 | 230 | 9 | 0.02 | 0.005 | 0.01 | 6 | ||
| 网络带宽降低 | 230 | 9 | 0.02 | 0.02 | 0.01 | 6 | 8,10,9 | 10,8,9 |
| 网络带宽降低 | 230 | 9 | 0.02 | 0.02 | 0.01 | 1 |
若在终端存储资源减少,其他各项指标不变的情况下,即
图 13
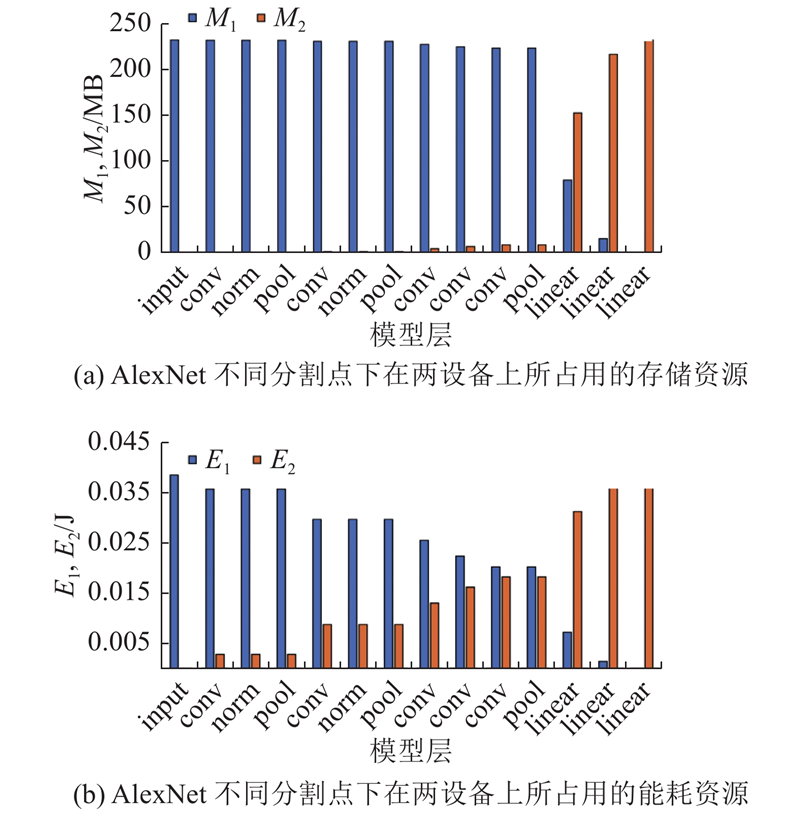
图 13 AlexNet不同分割点下所需的存储量、能耗
Fig.13 Memory and energy consumption required at different partition points on AlexNet
若终端的电量降低,在其他各项指标不变的情况下,
若网络带宽降低,在其他各项指标不变的情况下,分割状态集由情境变化前的(8,10,9)变为(10,8,9). 网络带宽降低导致传输时延增大,使得当前分割状态的各项指标无法满足资源约束. 如图14所示为不同分割方式下待传输中间输出数据量与推断总时延的变化. 可以看出,当网络带宽降低时,算法搜索到的分割点后移,使得部署在终端的层数增多,因为当网络带宽较差时,需要选择待传输中间数据量较小的分割点以降低传输时延.
图 14
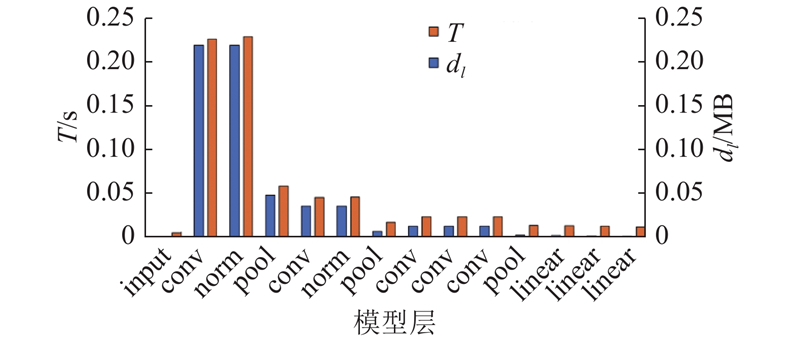
图 14 AlexNet不同分割点下总时延与各层中间输出数据量
Fig.14 Inference latency of different partition points and output data size of each layer on AlexNet
5. 结 语
提出构建边端融合的终端情境自适应的深度感知模型. 通过主动感知终端“情境”(如待部署平台的资源约束和性能需求),利用边缘智能技术,对模型的结构和运算模式进行自动调优,实现模型的顺利部署. 提出X-ADMM模型,结合模型压缩与模型分割技术,对模型进行简化. 根据资源约束寻找合适的分割点,协同边缘设备计算,有效地减少单台设备上的存储、能耗,提高模型的运行效率. 为了使模型具备强自适应能力,提出GADS算法. 在发现的最近邻边端模型分割效应的驱动下,当模型运行的情境发生变化时,以当前分割状态为导向,优先由周围相似分割状态搜索合适的分割状态,以实现模型的快速自适应.
实验结果表明,结合模型压缩和分割技术,可以在保证模型精度的同时,有效降低神经网络模型运行的总时延. 在模型的快速自适应能力方面,GADS算法平均在0.1 ms内实现了模型分割状态的快速自适应调优.
后续工作将会考虑在多个同构或异构设备的算法实现,探索结合层间横向粒度分割的更细粒度、更高效的模型分割,考虑使用更高效的搜索算法进行改进.
参考文献
Imagenet classification with deep convolutional neural networks
[J].
A state-of-the-art survey on deep learning theory and architectures
[J].DOI:10.3390/electronics8030292 [本文引用: 1]
Edge intelligence: paving the last mile of artificial intelligence with edge computing
[J].DOI:10.1109/JPROC.2019.2918951 [本文引用: 1]
DeepThings: distributed adaptive deep learning inference on resource-constrained IoT edge clusters
[J].DOI:10.1109/TCAD.2018.2858384 [本文引用: 1]
Neurosurgeon: collaborative intelligence between the cloud and mobile edge
[J].DOI:10.1145/3093337.3037698 [本文引用: 2]
Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks
[J].DOI:10.1145/3007787.3001177 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}