

基于深度学习的水下图像增强算法主要利用卷积神经网络自动提取水下图像特征,得到原始水下图像与增强图像之间的映射关系,实现水下图像清晰化. 基于监督学习的方法需要大量成对的样本进行监督训练,但实际中收集足够多成对的水下图像极其困难. Li等[7]将水下图像生成模型嵌入生成对抗网络(generative adversarial network,GAN)结构中,利用清晰的陆地图像生成浑浊的水下图像;然后利用该成对数据集训练水下图像增强网络模型. Chen等[8]通过水下图像成像模型,将浑浊的水下图像转化为清晰的水下图像,然后用该成对的数据集训练条件生成对抗网络实现水下图像增强. 但由于合成图像与真实水下图像的分布存在差异,这类方法在真实图像增强效果方面并不理想. Zhu等[9]提出的循环对抗神经网络(cycle-consistent adversarial networks,CycleGAN)设计了一种双路GAN结构并引入了循环一致性损失,放宽了对成对训练集的需求,但该算法不能完整地恢复原始图像中的内容信息. Li等[10]在CycleGAN的基础上提出了一种弱监督水下图像颜色转换方法,该网络模型设计的多项损失函数在去除水下图像色偏的同时,保留了原始图像中的内容信息,但该方法对图像对比度的增强效果不佳.
针对现有的基于深度学习的水下图像增强算法存在的问题,本文提出一种融入注意力机制的弱监督水下图像增强算法. 由于不同波长的光在水中传播时存在衰减差异,因此将红通道衰减图作为注意力图与水下图像同时输入生成网络,进行融入注意力机制的对抗网络训练。同时采用全局和局部2种判别器约束生成网络模型,提高生成图像清晰度. 实验结果表明,本文算法能有效地提高水下图像对比度,增强细节,校正色偏.
1. 理论基础
1.1. 光在水中的衰减
在水下环境中,不同波长的光具有不同的衰减程度. 一般情况下,红光的波长最长,在水中的穿透力最弱,因此最先消失. 蓝光因为具有最短的波长,在水中的穿透力最强,所以在水中传播距离最远. 这种与波长相关的光传播是导致水下图像颜色偏差的主要原因[11].
根据光在水中传播时的选择性衰减特点,若假设背景光已知,则可以利用红通道与蓝绿通道之间的差异估计介质透射率图[12]. 各通道之间的衰减差异可以通过比较红通道的最大值与蓝绿通道的最大值得到:
式中:
由式(2)可得红通道衰减
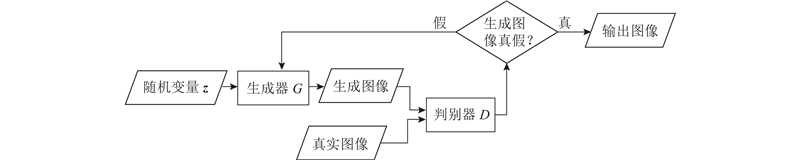
1.2. 生成对抗网络
图 1
式中:
2. 算 法
为了解决监督学习的水下图像增强算法所需成对训练集获得困难的问题,提出一种融入注意力机制的弱监督水下图像增强算法,算法流程如图2所示. 首先原始水下图像通过逐像素值运算得到注意力图像,这里采用红通道的衰减图作为注意力图,再将原始图像和注意力图像同时输入融入注意力机制的生成器中,在注意力图像的引导下生成器输出生成图像. 然后将生成图像与真实图像输入全局判别器,生成图像块与真实图像块输入局部判别器,2个判别器共同判别该生成图像是真是假. 若辨别该生成图像是真实图像就直接输出该生成图像(增强后的水下图像),否则将判别结果反馈给生成器,生成器继续生成图像欺骗2个判别器,直到2个判别器均无法辨别生成图像与真实图像真假为止.
图 2
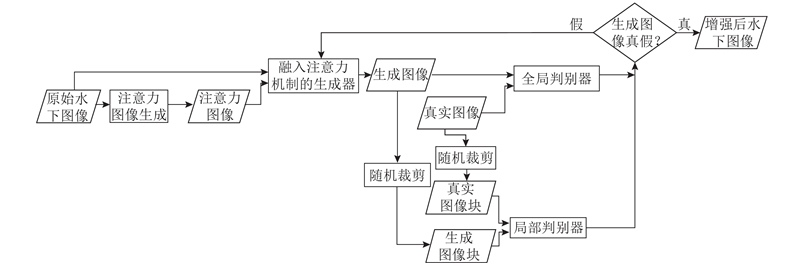
图 2 融入注意力机制的弱监督水下图像增强算法流程
Fig.2 Flowchart of weakly supervised underwater image enhancement algorithm incorporating attention mechanism
2.1. 算法核心网络结构
图 3

图 3 融入注意力机制的弱监督水下图像增强算法核心网络结构
Fig.3 Network architecture of weakly supervised underwater image enhancement algorithm incorporating attention mechanism
2.2. 融入注意力机制的生成器
注意力机制一方面可以减轻计算高维数据的负担,降低数据的维度;另一方面可以帮助网络更专注于学习与任务最相关的信息,从而提高网络的学习能力. 注意力机制模型的最终目的是帮助网络学到更多不同信息之间隐蔽、复杂的映射关系. 这种关系对于弱监督/无监督学习网络尤为有效. 水下图像与陆地图像最大不同是存在色偏问题,根据不同颜色的光在水中传播时的衰减程度不同,估计出介质透射率图. 蓝绿通道的透射率图是由红通道透射率图求出,所以红通道的透射率图就已经包含了蓝绿通道的透射率图的信息. 因此,这里采用处理后的红通道的透射率图(红通道的衰减图)作为注意力图来引导网络进行水下图像颜色修正.
生成器的运算过程是:先通过5次卷积操作实现图像下采样,再通过4次反卷积操作实现图像上采样. 为了避免信息丢失,在下采样阶段,采用卷积替代最大池化,以保留更多的内容信息. 为了减少栅格效应,在上采样阶段,将标准的反卷积层替换为一个双线性上采样层和一个卷积层,以保留更多的纹理信息. 此外,为了保证注意力图像的大小适应每个对应特征图像,将注意力图像与水下图像同时输进网络模型进行下采样. 再将每层下采样的注意力图像与对应的特征图像点乘并与上采样中对应大小的特征图像相连,从而发挥注意力图像的引导作用,来提高生成网络模型增强水下图像的性能.
2.3. 全局-局部判别器
对于全局判别器,Alexia[17]提出相对判别器. 该结构分为2部分:
式中:
对于局部判别器,从每次生成图像和真实图像中分别随机裁剪出6个小块,大小均为32×32. 局部判别器D和生成器G的损失函数为
式中:
全局判别器的运算过程是:先通过5次下采样操作再经过1次激活函数处理来实现图像判别. 每次下采样包括1个卷积层(convolution layer)和1个批量标准化层(batch normalization layer),采用Leaky Relu激活函数,在第5次下采样操作后通过Sigmoid激活函数输出最终结果. 局部判别器的运算过程是:先通过4次下采样操作再经过1次Sigmoid激活函数处理来实现局部图像判别. 其中,每次下采样操作均与全局判别器的下采样操作相同.
2.4. 结构相似性损失
结构相似性[19]从图像组成的角度定义结构信息,反映物体的结构属性. 使用均值估计亮度,标准差估计对比度,协方差估计结构相似程度,结构相似性
式中:
对于局部判别器,从水下图像中随机裁剪出的局部小块
网络模型总体损失函数为
根据训练数据和实验结果,选取权重
3. 实验结果分析
3.1. 主观评价
本文算法与现有的4种经典水下图像增强算法的对比结果如图4所示. 文献[12]算法处理后的图像远景处理效果不够理想,远景色偏仍然存在,有些图像还出现了颜色过饱和问题. 该算法引入过多的参数,导致该算法鲁棒性不高. 文献[9]算法处理后的图像整体偏黄,局部视觉效果不够自然. 文献[10]算法处理后的图像噪声明显,图像整体偏暗,局部清晰度不高. 文献[21]算法处理后的图像有局部色偏没有去除,局部对比度较低. 这4种算法都仅对全局图像进行增强,无法实现局部区域特定增强,导致整体视觉效果不佳. 通过与这4种算法对比,本文算法修正了图像色偏,实现了图像局部区域的特定增强,整体亮度提升,视觉效果更为清晰自然.
图 4

图 4 本文算法与经典算法实验结果对比
Fig.4 Experimental results of proposed algorithm compared with classical algorithms
图 5

图 5 本文算法与经典算法实验图像细节对比
Fig.5 Experimental image details of proposed algorithm compared with classical algorithms
3.2. 客观指标
采用4种水下图像质量评价指标,分别是水下图像质量指标(underwater image quality measure,UIQM)[23]、水下图像对比度度量指标(underwater image contrast measure,UIConM)、水下图像质量评估度量指标(underwater color image quality evaluation,UCIQE)[24]和信息熵(entropy). UIQM和UCIQE是目前较为公认的2种综合性水下图像质量评价指标. UIQM从色彩度量指标(UICM)、清晰度度量指标(UISM)、对比度度量指标(UIConM)3个方面对增强后的图像进行客观评价. UIQM的值越高说明图像的综合质量越好,UIConM的值越高说明图像的对比度越好. UCIQE是从色度、饱和度和对比度3个方面对增强后的水下图像进行综合评价,该值越高,说明增强图像的总体效果越好. 信息熵度量图像所含信息量,该值越高说明图像所含信息量越大,内容越丰富.
表 1 各算法不同客观指标对比结果
Tab.1
综合主观评价和客观指标,本文算法能够有效去除色偏,具有较高的对比度,恢复更多图像细节与内容信息,提高了图像的亮度,具有更加自然清晰的视觉效果. 不管是在主观视觉上还是客观指标上均优于其他算法.
3.3. 消融实验
为了突出融入注意力机制在算法中的重要作用,开展消融实验. 在保证其他实验条件相同的情况下,去除注意力机制进行实验.
3.3.1. 主观评价
采用相同测试集进行未融入注意力机制的消融实验,并给出了由原始水下图像生成的注意力图(红通道衰减图). 主观对比结果如图6所示.
图 6

图6中,未融入注意力机制的增强图像与原始水下图像相比,在一定程度上去除了色偏,提高了图像对比度,具有一定的增强效果,但是仍有色偏存在,图像视觉效果不够清晰. 将融入注意力机制的增强图像和未融入注意力机制的增强图像相比,融入注意力机制后的增强图像修正了色偏,对比度更高,细节更明显,具有更加清晰的视觉效果.
3.3.2. 客观指标
采用相同测试图像进行未融入注意力机制的消融实验并计算处理后图像的客观评价指标,结果取均值精确到0.000 1. 融入注意力机制的增强图像与未融入注意力机制的增强图像的客观评价指标对比如表2所示.
表 2 消融实验不同客观指标对比结果
Tab.2
| 机制 | UIQM | UIConM | UCIQE | UICM | Entropy |
| 融入注意力 | 5.517 7 | 0.926 9 | 0.583 9 | 2.838 2 | 7.608 9 |
| 未融入注意力 | 5.060 9 | 0.847 8 | 0.516 4 | 3.020 9 | 7.271 7 |
融入注意力机制的增强图像在综合度量UIQM、UCIQE以及UIConM和Entropy指标上均高于未融入注意力机制的增强图像,说明本文算法增强后的图像整体效果更好,对比度更高,内容细节更丰富. 因为未融入注意力机制的增强图像仍有部分色偏未能去除,导致未融入注意力机制的增强图像在色彩度量UICM指标上高于融入注意力机制的增强图像.
综合主观评价和客观指标,融入注意力机制的增强算法能够有效去除色偏,提高图像对比度,增强后的图像具有更加清晰自然的视觉效果. 不管是在主观视觉上还是客观指标上均优于未融入注意力机制的增强算法.
4. 结 语
本文算法充分考虑了水下图像与陆地图像的差异,利用卷积神经网络本身的学习能力自动提取特征,采用注意力机制引导网络学习,最终实现水下图像增强. 本文算法解决了监督学习的水下图像增强算法所需成对训练集获得困难,现有无监督学习的水下图像增强算法增强效果欠佳的问题. 对水下图像增强的研究具有重要意义.
本文算法主要考虑水下图像颜色校正和对比度增强,在极度浑浊的水下图像增强方面存在不足. 在未来的研究中,将会提高传输图估计的准确性,增强算法的鲁棒性.
参考文献
Underwater image processing: state of the art of restoration and image enhancement methods
[J].
Research progress of underwater image enhancement methods
[J].
Subcarrier-index modulation aided OFDM—will it work?
[J].DOI:10.1109/ACCESS.2016.2568040 [本文引用: 1]
Enhancement of low exposure images via recursive histogram equalization algorithms
[J].DOI:10.1016/j.ijleo.2015.06.060 [本文引用: 1]
Underwater image enhancement via extended multi-scale Retinex
[J].DOI:10.1016/j.neucom.2017.03.029 [本文引用: 1]
WaterGAN: unsupervised generative network to enable real-time color correction of monocular underwater images
[J].
Towards real-time advancement of underwater visual quality with GAN
[J].DOI:10.1109/TIE.2019.2893840 [本文引用: 1]
Emerging from water: underwater image color correction based on weakly supervised color transfer
[J].DOI:10.1109/LSP.2018.2792050 [本文引用: 5]
Light in the sea
[J].DOI:10.1364/JOSA.53.000214 [本文引用: 1]
Underwater image enhancement by dehazing and color correction
[J].
Loss functions for image restoration with neural networks
[J].
An underwater image enhancement benchmark dataset and beyond
[J].
Fast underwater image enhancement for improved visual perception
[J].
Human-visual-system-inspired underwater image quality measures
[J].
An underwater color image quality evaluation metric
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}