

基于模型定义[1-3](model-based definition,MBD)的数字化设计与制造技术已经被很多制造企业采用. 在MBD技术的基础上,数字线(digital thread)和数字孪生(digital twin,DT)成为制造信息化发展的趋势. 数字孪生[4-5]作为赛博物理系统的关键技术,能够对物理世界进行数字化描述并有效管控产品全生命周期的数据. 数字孪生的产生和应用是对MBD技术的进一步发展,为全三维研制模式下产品研发、生产提供了新的思路. 在“基于模型驱动”的产品研制环节,根据MBD技术构建零件工艺信息模型,并利用工艺信息模型和工序参数快速构建工序模型,满足工艺规划过程对信息处理速度的要求[6-8];在产品检验环节,利用工艺/工序模型开发三维数字化检测工艺系统,构建检测工艺模型,解决传统二维检测方法速度慢、效率低、准确率低的问题[9-10].
上述模型都是利用底层采集所得的数据构建的,如何深度利用这些模型承载的工艺和检测数据逐渐成为当前数字孪生应用研究的焦点. 近年来,已有学者利用制造过程中采集的工艺信息和检测信息进行数据挖掘分析,并将分析结果用于零件质量的预估和工艺参数的优化.
基于数字孪生思想和已有研究的启发,本研究提出机加零件的质量预测与工艺参数优化方法. 以集成工艺信息和检测信息的MBD模型为唯一数据源,采用CATIA组件应用架构(component application architecture,CAA)二次开发技术,完成工艺信息和检测信息的自动提取并存入数据库;利用逻辑回归(logistic regression,LR)、支持向量机(support vector machine,SVM)、极端梯度提升(extreme gradient boosting,XGBoost)等多种分类器构建预测模型并完成数据训练,实现基于工艺参数的零件质量预测;利用梯度提升树(gradient boost decision tree,GBDT)算法构建特征,提升分类模型预测的准确率;基于零件的工艺参数和质量分类标签,结合信息增益算法对影响零件质量的工艺参数进行优先级的排序;最后,通过GBDT回归模型的训练优化零件的工艺参数.
1. 机加零件质量预测方法
根据工业工程相关理论,影响机加零件质量的主要因素可归纳为加工方法、设备、材料、环境和工艺参数等5个方面. 本研究将在前4个方面因素确定的情况下,从工艺参数对零件质量的影响入手,使用机器学习算法构建零件质量预测模型,通过机加过程中选用的工艺参数预测零件质量.
在实际工业场景中,工艺参数取值对零件质量的影响存在各种不确定性和随机性. 因此,本研究给出通用的工艺信息与检测信息的结构化数据格式、工艺参数优先级排序接口、零件质量模型准确率验证接口以及零件质量预测接口. 基于结构化数据格式对所有工艺参数进行优先级排序,辅助工艺人员进行有效工艺参数选取;针对所选工艺参数,提供多种零件质量预测模型的准确率验证接口,展示模型对工艺参数的拟合情况;选取拟合情况较好的模型作为零件质量预测模型,辅助工艺人员预测零件质量.
1.1. 用于零件质量预测的结构化数据格式
设训练数据集为D,
用于零件质量预测的结构化数据格式如表1所示. 表中,
表 1 零件质量预测的结构化数据格式
Tab.1
| i | 工艺参数1 | 工艺参数2 | | 工艺参数 | 零件质量标签 |
| 0 | | | | | |
| 1 | | | | | |
| | | | | | |
| m | | | | | |
1.2. 影响零件质量工艺参数优先级排序
给定训练数据集
1)计算数据集
2)计算给定
3)计算信息增益:
通过计算机加零件所有工艺参数的信息增益,可以判断不同工艺参数对零件质量的影响程度,信息增益最大的工艺参数对零件质量的影响程度最大.
1.3. 零件质量预测模型构建
GBDT属于Boosting算法,前面的树结构能够构建对多数样本具有区分度的特征,后面的树结构拟合少数样本,因此采用GBDT可以构建具有区分度的特征. 在工艺参数较少的特殊情况下,为了提高零件质量预测模型的准确率,须构建有效特征以弥补人工经验的不足,可以利用GBDT结合LR作为此类情况下的零件质量预测模型.
1.3.1. 逻辑回归模型
使用逻辑回归算法构建的零件质量预测模型的输入为零件的工艺参数,输出为零件质量是否合格. 对于样本编号为i的样本,模型的输入为当前编号零件的工艺参数
可以看出,
1.3.2. GBDT模型
在应用GBDT拟合原始数据集并构建新特征时,须将新特征和原始数据集特征进行拼接后,再对零件质量进行预测. 对于样本编号i,将
首先设定初始
通过经验风险极小化对每一棵决策树的初始化参数
式中:
应用GBDT对训练数据进行拟合,保存训练后的分类器. 通过分类器重新读入全部数据并构建新特征,对于编号为
1.3.3. 十折交叉验证
在机器学习研究中,为了验证模型的准确率,一般情况下会把原始数据分为训练集和测试集. 在样本量不充足的情况下,为了更加充分地利用现有数据测试算法效果,采用随机生成索引的方式将数据集分为10份,一共进行10次试验,每次取其中1份数据作为测试数据,用剩余9份数据作为训练数据进行试验,这种方法称为十折交叉验证(10 fold cross-validation)[20].
1.3.4. 零件质量预测流程
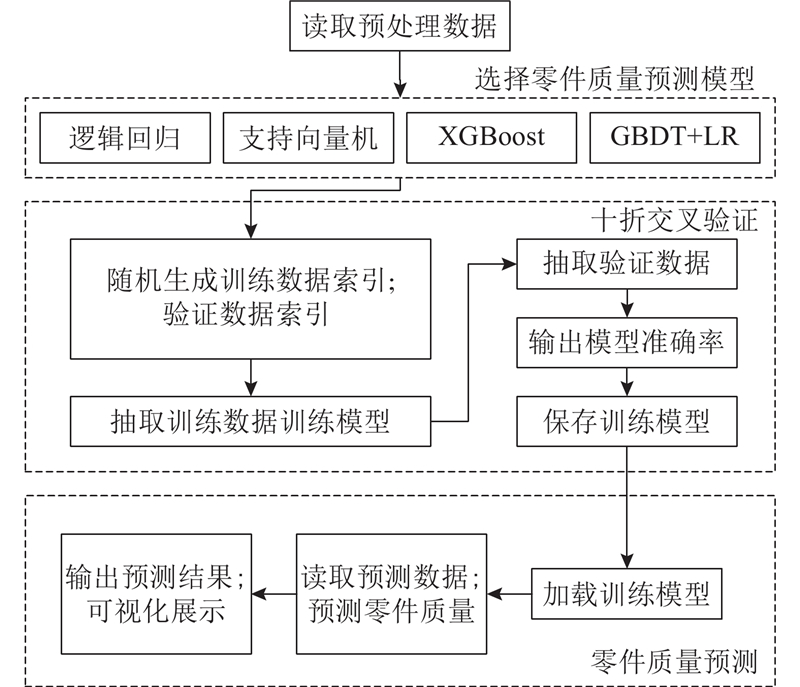
如图1所示为零件质量预测模型的构建流程,共分4个步骤. 1)读取预处理后的数据,分离工艺参数与零件质量标签为2个变量;2)用户选择模型,生成模型训练相应句柄;3)十折交叉验证训练模型,输出对应准确率并保存训练模型;4)加载预训练零件质量预测模型,读取预测数据,输出模型预测结果.
图 1
2. 机加零件工艺参数优化方法
工艺参数优化模型的原理,是利用机器学习算法结合工艺参数和零件质量标签,实现对某一维工艺参数的优化. 具体而言,该模型是在零件试制阶段,计算所有工艺参数的信息增益并排序,在其余参数不变的情况下,使用工艺参数优化模型对信息增益最高者(即对零件质量影响最大的工艺参数)进行预测,实现单点优化.
结合1.1节给出的结构化数据格式,工艺参数优化模型的构建须选定待优化工艺参数,利用机器学习算法构建回归模型;再通过其余工艺参数和零件质量标签对待优化工艺参数进行拟合;最后选取一组待优化工艺参数,并更改零件质量标签为设计设计最优值,将两者输入到模型中,得到优化结果.
2.1. 用于工艺参数优化的结构化数据格式
用于机器学习的工艺参数优化数据格式如表2所示. 新增列
表 2 工艺参数优化的结构化数据格式
Tab.2
| i | 工艺参数1 | | 工艺参数 | 零件质量标签 | 工艺参数 |
| 0 | | | | | |
| 1 | | | | | |
| | | | | | |
| m | | | | | |
2.2. 工艺参数优化模型构建
工艺参数优化模型针对的是某一条生产线的某个问题,具有一定的针对性,因此不要求模型的泛化能力,可以直接选用GBDT模型进行构建:对于样本编号
3. 实例验证
为了确认前述零件质量预测模型和工艺参数优化模型的有效性,采用某航空企业提供的铣削实验数据进行验证.该实验采用控制变量法,分别在不同的轴向切深、径向切深参数下,采用变转速的方式对铝合金材料表面进行铣削,通过测量并记录表面粗糙度,研究机床主轴转速、轴向切深和径向切深3个变量对铣削加工表面粗糙度的影响. 该实验的材料为7050-T7415航空铝合金,选用V1-2000-2T五坐标数控龙门铣床和
3.1. 系统框架
系统整体框架如图2所示,系统的开发以CAA为工具,Microsoft Visual Studio 2005为开发环境,对CATIA V5 R18平台进行二次开发,实现集成工艺信息和检测信息的MBD模型参数自动提取;以Python为工具,Jupyter Notebook为开发环境,实现影响零件质量工艺参数优先级排序、构建零件质量预测模型和优化工艺参数的功能.
图 2
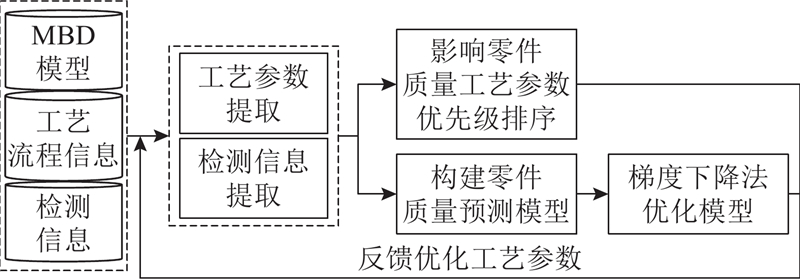
图 2 机加零件质量预测与工艺参数优化系统框架
Fig.2 Systematic framework for quality prediction and process parameter optimization of machining parts
实验选择径向切深(0.5~5 mm)、轴向切深(0.5~18 mm)、主轴转速(4000~13000 rpm)3个参数进行实际加工,得到实验数据共380条,结果设定表面粗糙度阈值为3.2 μm,高于阈值视为不合格并记为0,反之合格并记为1.
表 3 信息增益计算结果
Tab.3
| 工艺参数 | 信息增益 |
| 径向切深 | 0.022 702 294 |
| 轴向切深 | 0.141 402 794 |
| 主轴转速 | 0.240 937 382 |
3.2. MBD模型参数自动提取
针对制造过程中采集的工艺和检测数据,MBD模型统一采用结构树的形式进行组织与存储. 其中,检测信息采用以特征为单位节点的形式进行表达和存储,节点下包含检验特征名称、理论值、公差值、实际值以及检验结果等内容,其结构化数据格式如图3所示:
工艺信息的表达和存储与检测信息相同,节点下包含该特征类型、几何尺寸、工艺要求和加工方案等信息. 其中,几何尺寸和工艺要求是指该特征的设计要求;加工方案包含设计特征在实际加工过程中的所有工序信息和工序采用的工艺参数,其结构化数据格式如图4所示.
图 3

图 4

工艺信息中同一特征的工艺参数,按照工步分别添加在对应工步的子节点下. 在添加检验特征时,根据理论值和公差值自动生成零件是否合格的节点. 工艺信息和检测信息在MBD模型中的集成结果如图5所示.
图 5
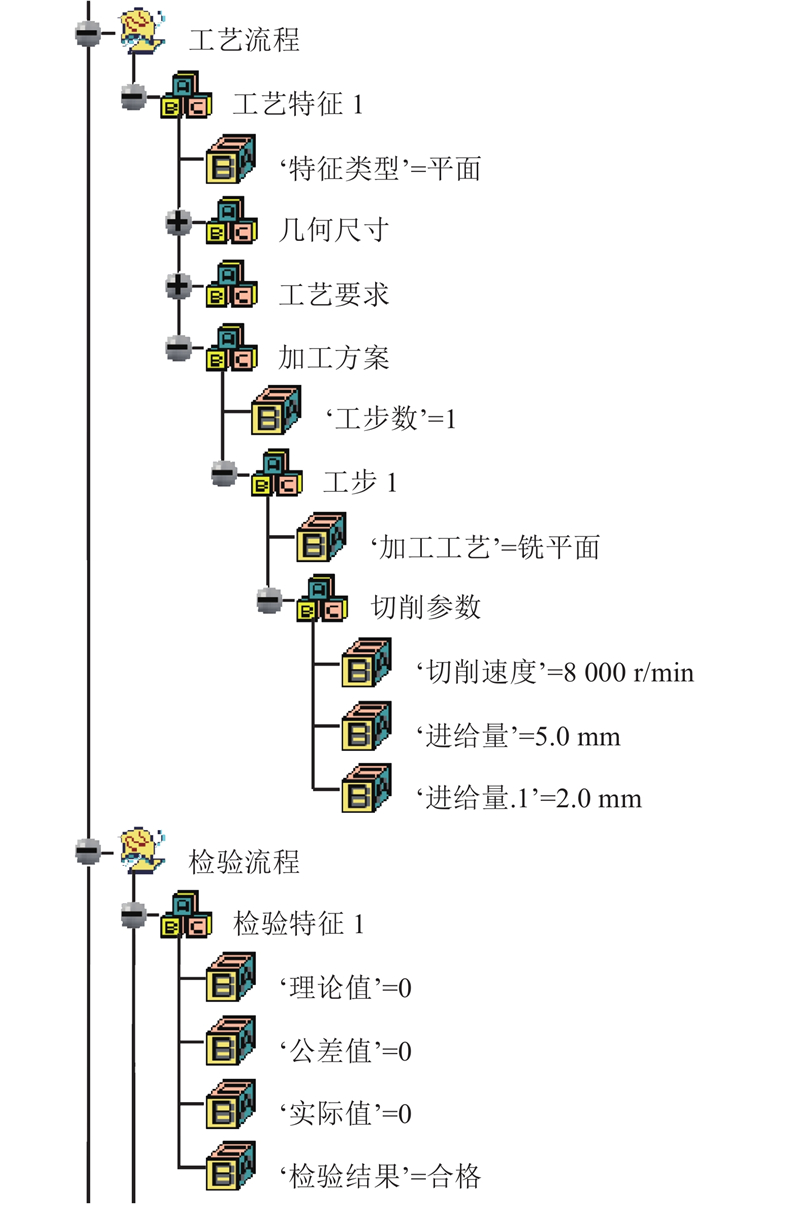
图 5 集成工艺信息和检测信息的MBD模型
Fig.5 MBD model integrated with processing and inspection information
工艺信息和检测信息的提取流程如图6所示,共分为3个步骤. 1)获取MBD模型并遍历工艺流程和检测流程链表;2)分别提取MBD模型指定特征的切削参数和检测结果;3)将所得MBD模型的工艺信息和检测信息结构化表达,为后续机器学习提供数据依据。
图 6
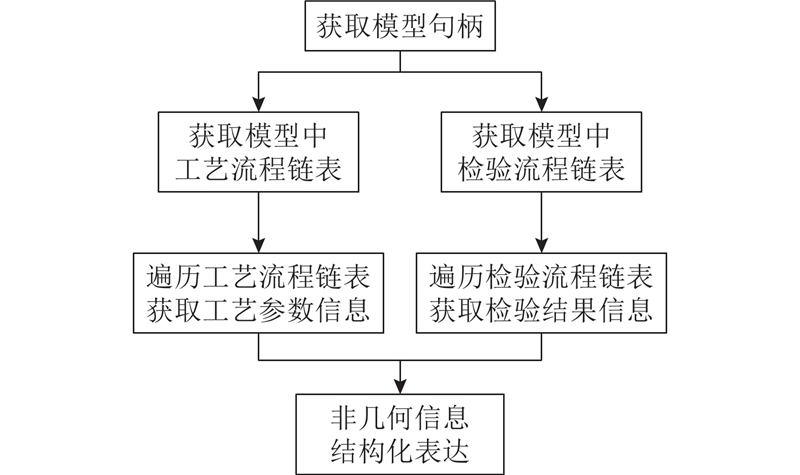
图 6 工艺信息与检测信息提取流程
Fig.6 Extraction process of processing and inspection information
3.3. 机加件质量预测
为了验证所提出的方法,利用Python开发零件质量预测与工艺参数优化工具集用户界面,如图7所示. 利用信息增益算法对所有工艺参数进行信息增益计算,由结果可知主轴转速的信息增益最大,即主轴转速对零件质量的影响程度最大,具体结果如表3所示. 采用选取的500条实验数据,通过十折交叉验证分别训练LR、SVM、XGBoost 3种分类器,从而实现对零件质量的二分类,并记录各个分类器的平均准确率. 接着,为了进一步提升模型预测的准确率,使用GBDT对原始数据进行拟合后构造新特征,并与原始工艺参数拼接后输入LR分类器. 最终所有模型的平均准确率如表4所示. 由表中数据分析可知,相对简单的LR分类器在特征数量较少的情况下预测准确率较低,而SVM和XGBoost 2种复杂分类器的准确率提升较大;GBDT结合LR分类器的准确率为86.31%,比XGBoost还提升了3.43%,表现出最佳的预测准确率.
图 7

图 7 零件质量预测与工艺参数优化工具集用户界面
Fig.7 User interface of toolset for quality prediction and process parameter optimization of parts
表 4 四类分类器的准确率
Tab.4
| 模型名称 | 十折交叉验证平均准确率 |
| LR | 0.658 0 |
| SVM | 0.813 2 |
| XGBoost | 0.828 8 |
| GBDT+LR | 0.863 1 |
在验证完毕分类器准确率的基础上,为了进一步验证模型的可靠性,随机抽取加工数据中的5条原始数据输入到准确率最高的GBDT+LR中进行预测,结果如表5所示. 由表中数据分析可知,对于径向切深和轴向切深确定的情况下转速依次提升的数据,GBDT+LR模型具有较好的拟合效果,验证了预测模型的可靠性.
表 5 零件质量预测结果
Tab.5
| 数据 编号 | 径向 切深 | 轴向 切深 | 主轴 转速 | 表面粗 糙度 | 原始质量 标签 | 预测零件 质量 |
| 0 | 4.2 | 2.2 | 13500 | 3.62 | 0 | 0 |
| 1 | 4.2 | 2.2 | 14000 | 3.23 | 0 | 0 |
| 2 | 4.2 | 2.2 | 14500 | 3.14 | 1 | 1 |
| 3 | 4.2 | 2.2 | 15000 | 2.95 | 1 | 1 |
| 4 | 4.2 | 2.2 | 15500 | 3.01 | 1 | 1 |
3.4. 机加件工艺参数优化
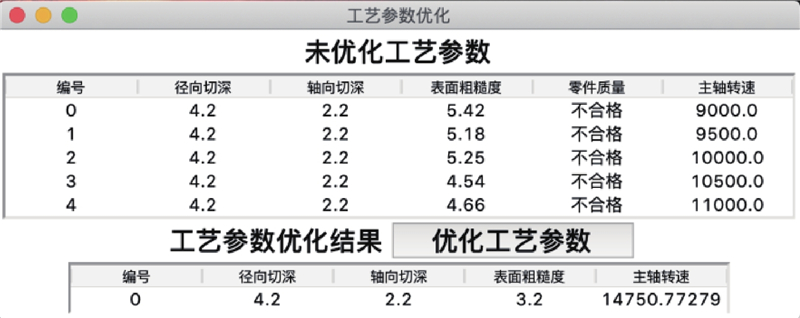
为了验证工艺参数优化方法的有效性,从500条实验数据中随机抽样450条数据,把径向切深、轴向切深和原始采集粗糙度作为特征,主轴转速作为标签,使用GBDT对其进行拟合并保存拟合后的模型;从剩余50条数据中随机抽样5条数据,在预测前把表面粗糙度取值改为理想取值,输出优化后的主轴转速,如图8所示. 优化所得的主轴转速为14750,通过对比原始加工数据可知,GBDT模型对于工艺参数和表面粗糙度数据的拟合效果较好.
图 8
4. 结 语
本研究结合“基于模型驱动”的产品研制模式和数据挖掘相关理论,探讨将机器学习算法应用于机加零件质量预测与工艺参数优化的方法. 应用信息增益算法进行工艺参数优先级排序,为零件加工工艺优化提供重要依据;筛选出了对零件质量影响最大的工艺参数;基于工艺参数优先级排序的零件定量预测,实现不确定工艺参数对零件质量的质量评估;利用实测加工数据和信息增益算法进行工艺参数优化,有效降低了其对工艺人员经验的依赖性,提升了工艺优化工作的智能化水平.
实例表明,本研究所提出的方法和开发的对应工具集,在实际应用中能够有效并可靠地实现机加零件的质量预测和工艺参数优化,为MBD技术和数字孪生思想的深入应用和推广落地提供了坚实的技术基础。本研究构建的零件质量预测和工艺参数优化模型,只适用于解决单点工艺参数的问题。下一步研究工作的重点,将针对同一道工序中多个参数耦合影响零件质量的问题,前一道工序的工艺参数和零件质量影响后一道工序的问题,以及其他实际加工过程中的复杂场景,开展零件质量预测和工艺参数优化。
参考文献
Will model-based definition replace engineering drawings throughout the product lifecycle? A global perspective from aerospace industry
[J].DOI:10.1016/j.compind.2010.01.005 [本文引用: 1]
Model-based definition design in the product lifecycle management scenario
[J].
Testing the digital thread in support of model-based manufacturing and inspection
[J].
数字孪生模型在产品构型管理中应用探讨
[J].
Study on application of digital twin model in product configuration management
[J].
数字孪生在工艺设计中的应用探讨
[J].
Study on application of digital twin in process planning
[J].
基于MBD模型的工序模型构建方法
[J].
In-process model construction method based on model-based definition model
[J].
基于模型定义的工艺信息建模及应用
[J].
Model-based definition process information modeling and application
[J].
基于MBD的产品信息全三维标注方法
[J].
Full 3D annotation of product information based on MBD
[J].
基于MBD的工艺模型集成化建模与表达
[J].
Integrated modeling and expression of the process model definition based on MBD
[J].
基于工业大数据的晶圆制造系统加工周期预测方法
[J].
Cycle time prediction method of wafer fabrication system based on industrial big data
[J].
基于数据挖掘的晶圆制造交货期预测方法
[J].DOI:10.3969/j.issn.1004-132X.2016.01.017 [本文引用: 1]
Data mining for orders' LT forecasting in wafer fabrication
[J].DOI:10.3969/j.issn.1004-132X.2016.01.017 [本文引用: 1]
A mathematical theory of communication
[J].DOI:10.1002/j.1538-7305.1948.tb01338.x [本文引用: 1]
Greedy function approximation: a gradient boosting machine
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}