假设候选观测任务集合为 $X = \left\{ {{x_1},{x_2},\cdots,{x_M}} \right\}$ $M$ ${x_i} = \left\{ {{\rm{w}}{{\rm{s}}_i},} \right.$ $\left. {{\rm{po}}{{\rm{s}}_i},{\rm{w}}{{\rm{e}}_i},{d_i},{r_i},{e_i},{m_i}} \right\}$ ${x_i}$ $Y = \left\{ {{y_1},{y_2},\cdots,{y_N}} \right\}$ $N$
将输入任务集合 $X = \left\{ {{x_1},{x_2},\cdots,{x_M}} \right\}$ ${x_i}$ ${s_i}$ $d_i^t$ . 在模型的解码阶段的每个解码时间步骤 $t$ ${s_i}\! = \!\left\{ {{\rm{w}}{{\rm{s}}_i},{\rm{po}}{{\rm{s}}_i},{\rm{w}}{{\rm{e}}_i},{d_i},{r_i},{e_i},{m_i}} \right\}$ $d_i^t = \left\{ {{\rm{win}}_i^t,{\rm{acc}}_i^t,{\rm{mem}}_i^t,{\rm{pow}}_i^t,{\rm{pos}}_i^t} \right\}$ $ {\rm{win}}_{i}^{t}{\text{、}}{\rm{acc}}_{i}^{t}{\text{、}}{\rm{mem}}_{i}^{t}{\text{、}} {\rm{pow}}_{i}^{t}{\text{、}}{\rm{pos}}_{i}^{t}$ $t$ $X = \left\{ {x_i^t = \left( {{s_i},d_i^t} \right),i = 0,1, \cdots ,M} \right\}$ $x_i^t$ ${x_i}$ ${x_i}$ $t$
[1]
刘晓路, 何磊, 陈英武, 等. 面向多颗敏捷卫星协同调度的自适应大邻域搜索算法[C]//第四届高分辨率对地观测学术年会论文集. 武汉: 国防科学技术大学信息系统与管理学院, 2017.
[本文引用: 1]
LIU Xiao-lu, HE Lei, CHEN Ying-wu, et al. An adaptive large neighborhood search algorithm for multiple agile satellites [C]// Proceedings of 4th Annual Conference on High Resolution Earth Observation . Wuhan: School of Information Systems and Management, National University of Defense Technology, 2017.
[本文引用: 1]
[2]
郭浩, 邱涤珊, 伍国华, 等 基于改进蚁群算法的敏捷成像卫星任务调度方法
[J]. 系统工程理论与实践 , 2012 , (11 ): 185 - 191
[本文引用: 1]
GUO Hao, QIU Di-shan, WU Guo-hua, et al Agile imaging satellite task scheduling method based on improved ant colony algorithm
[J]. System Engineering Theory and Practice , 2012 , (11 ): 185 - 191
[本文引用: 1]
[3]
王法瑞. 基于改进遗传算法的微小卫星自主任务规划方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2017.
[本文引用: 1]
WANG Fa-rui. Research on autonomous task planning method of micro satellite based on improved genetic algorithm [D]. Harbin: Harbin Institute of Technology, 2017.
[本文引用: 1]
[4]
贺仁杰, 高鹏, 白保存, 等 成像卫星任务规划模型、算法及其应用
[J]. 系统工程理论与实践 , 2011 , (3 ): 29 - 40
[本文引用: 1]
HE Ren-jie, GAO Peng, BAI Bao-cun, et al Imaging satellite mission planning model, algorithm and application
[J]. System Engineering Theory and Practice , 2011 , (3 ): 29 - 40
[本文引用: 1]
[5]
陈英武, 方炎申, 李菊芳, 等 卫星任务调度问题的约束规划模型
[J]. 国防科技大学学报 , 2006 , (5 ): 126 - 132
DOI:10.3969/j.issn.1001-2486.2006.05.026
[本文引用: 1]
CHEN Ying-wu, FANG Yan-shen, LI Ju-fang, et al Constrained programming model for satellite task scheduling problem
[J]. Journal of National University of Defense Technology , 2006 , (5 ): 126 - 132
DOI:10.3969/j.issn.1001-2486.2006.05.026
[本文引用: 1]
[7]
CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling [J/OL]. [2020-02-29]. https://arxiv.org/abs/1412.3555.
[本文引用: 2]
[8]
BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [J/OL]. [2020-02-29]. https://arxiv.org/abs/1409.0473.
[本文引用: 1]
[9]
VINYALS O, FORTUNATO M, JAITLY N. Pointer networks [C]// International Conference on Neural Information Processing Systems . Montreal: MIT Press, 2015.
[本文引用: 1]
[10]
BELLO I, PHAM H, LE Q V, et al. Neural combinatorial optimization with reinforcement learning [J/OL]. [2020-02-29]. https://arxiv.org/abs/1611.09940.
[本文引用: 2]
[11]
MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning [J/OL]. [2020-02-29]. https://arxiv.org/abs/1602.01783.
[本文引用: 2]
[12]
NAZARI M, OROOJLOOY A, SNYDER L, et al. Reinforcement learning for solving the vehicle routing problem [J/OL]. [2020-02-29]. https://arxiv.org/abs/1802.04240.
[本文引用: 8]
[13]
DAI H, KHALIL E B, ZHANG Y, et al. Learning combinatorial optimization algorithms over graphs [J/OL]. [2020-02-29]. https://arxiv.org/abs/1704.01665.
[本文引用: 1]
[14]
DAI H, DAI B, SONG L. Discriminative embeddings of latent variable models for structured data [J/OL]. [2020-02-29]. https://arxiv.org/abs/1603.05629.
[本文引用: 1]
[15]
KOOL W, HOOF H V, WELLING M. Attention, learn to solve routing problems! [J/OL]. [2020-02-29]. https://arxiv.org/abs/1803.08475.
[本文引用: 1]
[16]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [J/OL]. [2020-02-29]. https://arxiv.org/abs/1706.03762v4.
[本文引用: 2]
[17]
VINYALS O, BENGIO S, KUDLUR M. Order matters: sequence to sequence for sets [J/OL]. [2020-02-29]. https://arxiv.org/abs/1511.06391.
[本文引用: 1]
[18]
KINGMA D, BA J. Adam: a method for stochastic optimization [J/OL]. [2020-02-29]. https://arxiv.org/abs/1412.6980.
[本文引用: 1]
[19]
赵凡宇. 航天器多目标观测任务调度与规划方法研究[D]. 北京: 北京理工大学, 2015.
[本文引用: 1]
ZHAO Fan-yu. Research on scheduling and planning methods of spacecraft multi-object observation mission [D]. Beijing: Beijing Institute of Technology, 2015.
[本文引用: 1]
1
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
1
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
基于改进蚁群算法的敏捷成像卫星任务调度方法
1
2012
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
基于改进蚁群算法的敏捷成像卫星任务调度方法
1
2012
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
1
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
1
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
成像卫星任务规划模型、算法及其应用
1
2011
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
成像卫星任务规划模型、算法及其应用
1
2011
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
卫星任务调度问题的约束规划模型
1
2006
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
卫星任务调度问题的约束规划模型
1
2006
... 卫星观测任务规划问题是在考虑时间窗口和资源约束的条件下,对卫星资源加以分配,制定出合理的任务观测序列,从而使有限的卫星资源得以高效利用. 卫星成本高昂,星上资源有限,所以制定出合理的任务观测序列显得尤为重要. 卫星观测任务规划是提高卫星运行效率和降低成本的基础和关键,成为航空航天、计算机、运筹学的研究热点之一[1 ] . 卫星观测任务规划问题是一类多约束组合优化问题,模型的求解空间大. 目前国内外的研究者对卫星任务观测规划问题进行了研究,并基于智能优化算法对卫星观测任务规划问题进行求解,比如蚁群算法[2 ] 、遗传算法[3 ] 、模拟退火算法[4 ] 和禁忌搜索算法[5 ] . 这些算法虽然合理有效,但是存在着启发式因子设计困难、状态转移复杂和寻优速度较慢的问题. ...
Long short-term memory
1
1997
... 近几年来,出现了一些基于深度强化学习求解组合优化问题的研究. 这些算法的模型整体上采用了序列到序列(sequence to sequence,Seq2Seq)的结构,这种结构通常是由2个循环神经网络(recurrent neural network,RNN),或者其变种如长短期记忆网络[6 ] (long short-term memory,LSTM)和门控循环单元[7 ] (gate recurrent unit,GRU)构成,分别称为编码器和解码器. 这种Seq2Seq结构的问题在于,输入序列无论长短都会被编码为一个固定的向量,在解码时受限于该固定的向量表示,当输入序列较长时会造成信息丢失. 注意力机制[8 ] 在解码阶段构建输出状态和输入序列的连接,以发现输出状态和输入序列各节点之间相关性,解决Seq2Seq结构长距离依赖的问题. ...
2
... 近几年来,出现了一些基于深度强化学习求解组合优化问题的研究. 这些算法的模型整体上采用了序列到序列(sequence to sequence,Seq2Seq)的结构,这种结构通常是由2个循环神经网络(recurrent neural network,RNN),或者其变种如长短期记忆网络[6 ] (long short-term memory,LSTM)和门控循环单元[7 ] (gate recurrent unit,GRU)构成,分别称为编码器和解码器. 这种Seq2Seq结构的问题在于,输入序列无论长短都会被编码为一个固定的向量,在解码时受限于该固定的向量表示,当输入序列较长时会造成信息丢失. 注意力机制[8 ] 在解码阶段构建输出状态和输入序列的连接,以发现输出状态和输入序列各节点之间相关性,解决Seq2Seq结构长距离依赖的问题. ...
... 使用GRU[7 ] 搭建模型的解码器,在模型解码的每个时间步骤 $t$ ${{{h}}^t}$ ${y^{t + 1}}$ . 将节点 ${y^{t + 1}}$ ${\bar {{e}}^{t + 1}}$ $t + 1$
1
... 近几年来,出现了一些基于深度强化学习求解组合优化问题的研究. 这些算法的模型整体上采用了序列到序列(sequence to sequence,Seq2Seq)的结构,这种结构通常是由2个循环神经网络(recurrent neural network,RNN),或者其变种如长短期记忆网络[6 ] (long short-term memory,LSTM)和门控循环单元[7 ] (gate recurrent unit,GRU)构成,分别称为编码器和解码器. 这种Seq2Seq结构的问题在于,输入序列无论长短都会被编码为一个固定的向量,在解码时受限于该固定的向量表示,当输入序列较长时会造成信息丢失. 注意力机制[8 ] 在解码阶段构建输出状态和输入序列的连接,以发现输出状态和输入序列各节点之间相关性,解决Seq2Seq结构长距离依赖的问题. ...
1
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
2
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
... [10 ]所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
2
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
... 使用Actor Critic算法[11 ] 对模型进行训练,其由2个神经网络构成. ...
8
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
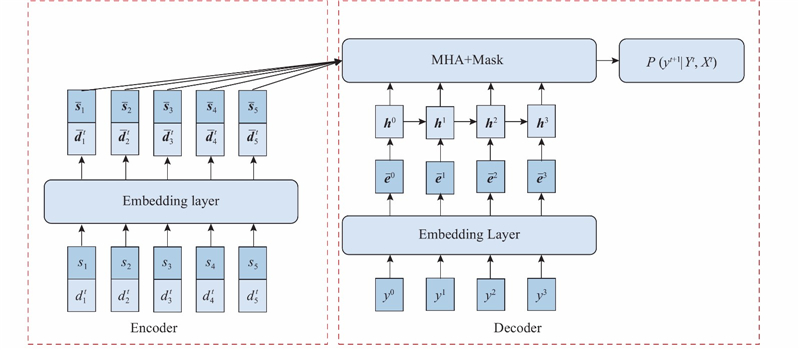
... 本研究对上述基于深度强化学习(deep reinforcement learning,DRL)解决组合优化问题的方法进行研究,并应用在卫星观测任务规划问题的求解上,为解决卫星观测任务规划问题提供了新的思路. 主要工作包含以下几方面:1)根据卫星执行观测任务的特点,综合考虑时间窗口和资源约束,对卫星观测任务规划问题进行建模;2)继承Nazari等[12 ] 所提出的算法结构,基于PN的运行机制建立序列决策模型,并通过Actor Critic强化学习算法对模型进行训练,实现对卫星观测任务规划问题的求解;3)借鉴多头注意力(multi-head attention,MHA)机制[16 ] 的思想,对PN进行改进,提出MHA-PN算法. ...
... 提出MHA-PN算法对卫星观测任务规划问题进行求解,算法的模型结构如图1 所示. MHA-PN算法整体是基于Seq2Seq[12 ] 的结构,分为编码器和解码器两部分. ...
... Pointer Networks机制可以描述为:在每个解码时间步骤 $t$ [17 ] 计算得到的Softmax概率值,指向输入序列中下一个要访问的节点. 具体计算过程[12 ] 如下. ...
... 采用相同的超参数设定,在相同的硬件平台上对Nazari等[12 ] 所使用的PN模型和MHA-PN模型进行训练,模型的收益率 $R$ $T$ 表2 所示. 表中, ${V_{{\rm{rate}}}}$
... 在序列长度为50的数据集上训练好的模型,可以对不同长度的样本序列进行推理. 在实际的卫星任务规划场景中,要求模型对不同长度的样本序列具有较好的泛化能力. 对比不同序列长度下Nazari等[12 ] 所使用的PN算法和MHA-PN算法的表现,为了减小实验的随机性,将每个长度的样本数设置为100. 不同序列长度下收益率 $R$ 图4 所示. ...
... 如图4(a) ~(f) 所示分别对应长度 $n$ $R$ [12 ] 所使用的PN算法. 随着序列长度的增加,MHA-PN算法收益率的优势也越来越明显,说明MHA-PN算法可以更好地泛化在密集对地观测场景下的任务规划求解上. 在不同序列长度下,模型收益率的均值对比如表3 所示. ...
... 对卫星观测任务规划问题进行建模,并基于深度强化学习的方法对卫星观测任务规划问题进行求解. 相比于启发式算法,训练好的模型可以直接对输入序列进行端到端的推理,避免迭代求解的过程,极大提高了求解效率. 在Nazari等[12 ] 所使用的PN算法的基础上,借鉴多头注意力机制的思想,提出MHA-PN算法. 由实验结果可知,MHA-PN算法相比于改进前的PN算法可以获得更高的收益率和更快的训练速度. 对于不同长度的输入序列,MHA-PN算法具有更强的泛化能力,算法在实际卫星观测任务规划应用场景下具有更高的适用性. ...
1
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
1
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
1
... Vinyals等[9 ] 提出指针网络(pointer networks,PN)求解了一些经典的组合优化问题,比如旅行商问题(traveling salesman problem,TSP)和背包问题(knapsack problem,KP),使用注意力机制计算得到Softmax概率分布,作为指针(pointer)指向输入序列中的元素,对输入序列进行组合,最后使用有监督方法对模型进行训练. Bello等[10 ] 使用Actor Critic强化学习算法[11 ] 对PN进行训练,在节点长度为100的TSP问题上获得了近似最优解,解决了有监督训练中训练数据获取困难、精度不足的问题. Nazari等[12 ] 对Bello等[10 ] 所使用算法模型中的Encoder部分进行改进,用一个嵌入层替换PN的RNN编码器部分,使得输入序列中的动态元素发生改变时,可以并行地对Encoder进行更新,减小了计算的复杂度,最后对交通路线规划问题(vehicle routing problem,VRP)进行了求解.Dai等[13 ] 使用Structure2Vector的图嵌入[14 ] (graph embedding,GE)模型依次输出TSP的访问节点,使用DQN算法对模型进行训练. 这种基于图的结构相比于Seq2Seq结构能够更好地反映TSP的结构特征.Kool等[15 ] 使用图注意力网络(graph attention networks,GAT)和自注意力机制建立编码器和解码器,并使用REINFORCE算法对模型进行训练,在训练过程中采用贪婪策略更新基准,该研究在基于深度强化学习解决TSP的算法当中实现了最先进的效果. ...
2
... 本研究对上述基于深度强化学习(deep reinforcement learning,DRL)解决组合优化问题的方法进行研究,并应用在卫星观测任务规划问题的求解上,为解决卫星观测任务规划问题提供了新的思路. 主要工作包含以下几方面:1)根据卫星执行观测任务的特点,综合考虑时间窗口和资源约束,对卫星观测任务规划问题进行建模;2)继承Nazari等[12 ] 所提出的算法结构,基于PN的运行机制建立序列决策模型,并通过Actor Critic强化学习算法对模型进行训练,实现对卫星观测任务规划问题的求解;3)借鉴多头注意力(multi-head attention,MHA)机制[16 ] 的思想,对PN进行改进,提出MHA-PN算法. ...
... 借鉴多头注意力机制[16 ] 的思想,对PN算法进行改进,得到MHA-PN算法. 在解码时间步骤 $t$ ${\bar {{s}}_i}$ $\bar {{d}}_i^t$ ${{{h}}^t}$ $n$ ${\bar {{s}}_i}$ $\bar {{d}}_i^t$ ${{{h}}^t}$ ${d_{{\rm{mod}}}}$ ${d_n}$
1
... Pointer Networks机制可以描述为:在每个解码时间步骤 $t$ [17 ] 计算得到的Softmax概率值,指向输入序列中下一个要访问的节点. 具体计算过程[12 ] 如下. ...
1
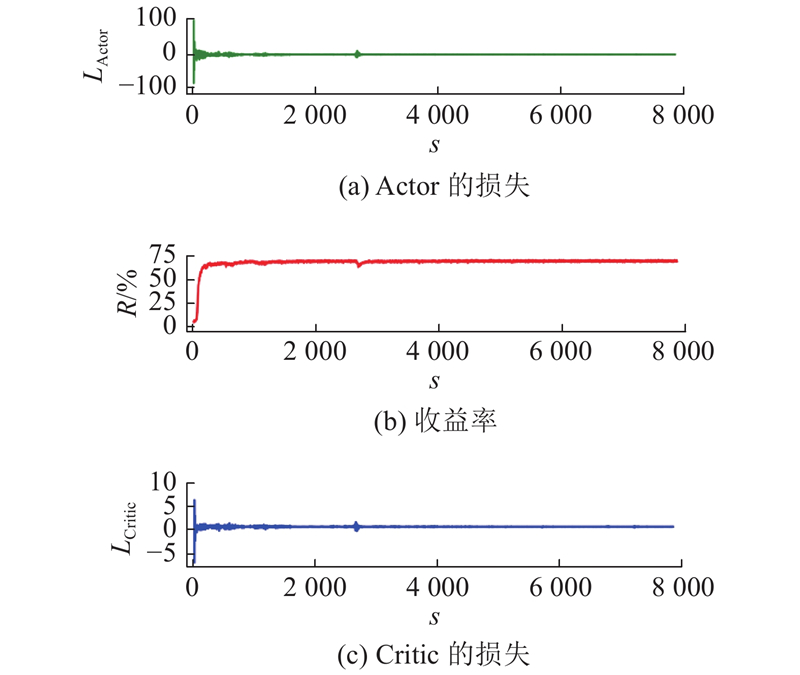
... 实验环境设置如下:操作系统为Ubuntu16.04,CPU为Intel Xeon E5-2620,GPU为RTX2080Ti,在GPU上对模型进行训练,实验代码基于Pytorch深度学习框架编写. 采用MHA-PN模型对卫星观测任务规划问题进行求解,训练的超参数设定如下:批样本数量(batch size)为128,训练轮次(epoch)为1,Actor网络的学习率为 ${\rm{5}} \times {\rm{1}}{{\rm{0}}^{{\rm{ - 4}}}}$ ${\rm{5}} \times {\rm{1}}{{\rm{0}}^{{\rm{ - 4}}}}$ ${\rm{2}}\,{\rm{000}}$ [18 ] . ...
1
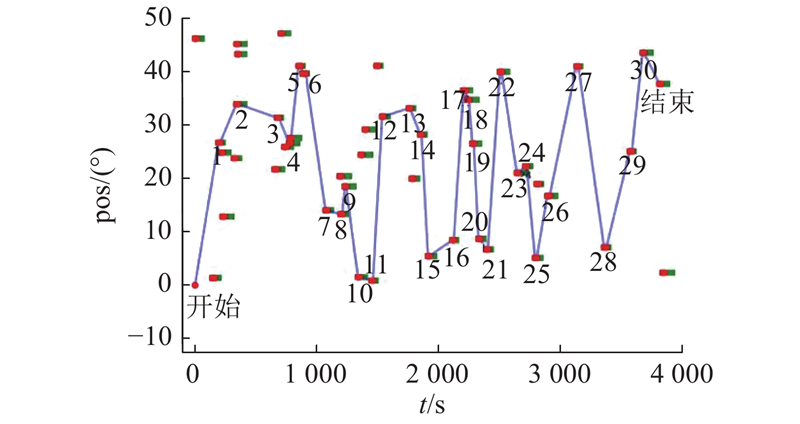
... 针对同样的卫星观测任务规划问题模型,赵凡宇[19 ] 基于蚁群优化(ant colony optimization,ACO)算法对多目标卫星观测任务规划问题进行求解. 将在序列长度为50的数据集上训练所得的MHA-PN算法模型和ACO算法分别对收益率和求解时间 $T'$ 表4 所示. 可以看出,对于不同长度的输入序列,MHA-PN算法获得了更高的收益率和更快的求解速度. ...
1
... 针对同样的卫星观测任务规划问题模型,赵凡宇[19 ] 基于蚁群优化(ant colony optimization,ACO)算法对多目标卫星观测任务规划问题进行求解. 将在序列长度为50的数据集上训练所得的MHA-PN算法模型和ACO算法分别对收益率和求解时间 $T'$ 表4 所示. 可以看出,对于不同长度的输入序列,MHA-PN算法获得了更高的收益率和更快的求解速度. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}