假设一个轨迹被描述为 $\left\{ {{P_i}\left| {i = 1,\;2, \cdots ,k} \right.} \right\}$ . Pi 可以由元组 $\left\{ {l{_i},{t_i}} \right\}$ t i l i k 项的马尔可夫链. 由马尔可夫稳定无后效理论可知,P i +1P i $\left\{ {{P_{i + 1}}\left| {{P_i},{P_{i - 1}},{P_{i - 2}},\cdots,{P_1}} \right.} \right\} = \left\{ {{P_{i + \;1}}\left| {{P_i}} \right.} \right\}$ . 通过计算状态转移矩阵来求得P i +1 的最大概率.
[1]
LUO E, BHUIYAN M Z A, WANG G, et al Privacy protector: privacy-protected patient data collection in IoT-based healthcare systems
[J]. IEEE Communications Magazine , 2018 , 56 (2 ): 163 - 168
DOI:10.1109/MCOM.2018.1700364
[本文引用: 1]
[2]
LIU Q, WANG G, LI F, et al Preserving privacy with probabilistic indistinguishability in weighted social networks
[J]. IEEE Transactions on Parallel and Distributed Systems , 2017 , 28 (5 ): 1417 - 1429
DOI:10.1109/TPDS.2016.2615020
[本文引用: 1]
[3]
LI L, LU R, HUANG C EPLQ: efficient privacy-preserving location-based query over outsourced encrypted data
[J]. IEEE Internet of Things Journal , 2016 , 3 (2 ): 206 - 218
DOI:10.1109/JIOT.2015.2469605
[本文引用: 1]
[4]
AMAGATA D, HARA T A general framework for MaxRS and MaxCRS monitoring in spatial data streams
[J]. ACM Transactions on Spatial Algorithms and Systems , 2017 , 3 (1 ): 1 - 34
[本文引用: 1]
[5]
JUNGGAB S, DONGHYUN K, ALAM B M Z, et al Privacy enhanced location sharing for mobile online social networks
[J]. IEEE Transactions on Sustainable Computing , 2018 , 5 (2 ): 279 - 290
[本文引用: 1]
[6]
NIU B, GAO S, LI F, et al. Protection of location privacy in continuous LBSs against adversaries with background information [C]// ICNC . Kauai: IEEE, 2016: 1-6.
[本文引用: 1]
[7]
LIU H, LI X, LI H, et al. Spatiotemporal correlation-aware dummy-based privacy protection scheme for location-based services [C]// INFOCOM . Atlanta: IEEE, 2017: 1-9.
[8]
SCHLEGEL R, CHOW C Y, HUANG Q, et al User-defined privacy grid system for continuous location-based services
[J]. IEEE Transactions on Mobile Computing , 2015 , 14 (10 ): 2158 - 2172
[本文引用: 1]
[9]
ZHU X, CHI H, NIU B, et al. MobiCache: when k-anonymity meets cache [C]// Globecom . Atlanta: IEEE, 2013: 820-825.
[本文引用: 3]
[10]
REZA S, GEORGE T, PANOS P Hiding in the mobile crowd: locationprivacy through collaboration
[J]. IEEE Transactions on Dependable and Secure Computing , 2014 , 11 (3 ): 266 - 279
DOI:10.1109/TDSC.2013.57
[11]
ZHANG S, LIU Q, WANG G. A caching-based privacy-preserving scheme for continuous location-based services [C]//SpaCCS . Zhangjiajie: Springer, 2016: 73-82.
[本文引用: 1]
[12]
PINGLEY A, ZHANG N, FU X, et al. Protection of query privacy for continuous location based services [C]// INFOCOM . Shanghai: IEEE, 2011: 1710-1718.
[本文引用: 1]
[13]
LIAO D, SUN G, LI H, et al The framework and algorithm for preserving user trajectory while using location-based services in IoT-cloud systems
[J]. Cluster Computing , 2017 , 20 (2 ): 1 - 15
[本文引用: 1]
[14]
WANG X, PANDE A, ZHU J, et al STAMP: enabling privacy-preserving location proofs for mobile users
[J]. IEEE/ACM Transactions on Networking , 2016 , 24 (6 ): 3276 - 3289
DOI:10.1109/TNET.2016.2515119
[本文引用: 1]
[16]
HWANG R H, HSUEH Y L, WU J J, et al SocialHide: a generic distributed framework for location privacy protection
[J]. Journal of Network and Computer Applications , 2016 , 76 (9 ): 87 - 100
[本文引用: 1]
[17]
NIU B, ZHU X, LI W, et al. EPcloak: an efficient and privacy-preserving spatial cloaking scheme for LBSs [C]// IEEE International Conference on Mobile Ad Hoc and Sensor Systems . Philadelphia: IEEE, 2014: 398-406.
[本文引用: 1]
[18]
ZHANG S, WANG G, LIU Q, et al. A trajectory privacy-preserving scheme based on dual-K mechanism for continuous location-based services [C]// IEEE ISPA / IUCC . Guangzhou: IEEE, 2017: 406-419.
[本文引用: 1]
[19]
SHUHEI H, DAICHI A, TAKAHIRO H, et al Dummy generation based on user-movement estimation for location privacy protection
[J]. IEEE Access , 2018 , 6 : 22958 - 22969
DOI:10.1109/ACCESS.2018.2829898
[本文引用: 1]
[20]
GONG X, CHEN X, XING K, et al. Personalized location privacy in mobile networks: a social group utility approach [C]// INFOCOM . Hong Kong: IEEE, 2015: 1008-1016.
[本文引用: 1]
[21]
NATESAN G, LIU J. An adaptive learning model for k-anonymity location privacy protection [C]// COMPSAC . Taichung: IEEE, 2015: 10-16.
[本文引用: 1]
[22]
HWANG R H, HSUEH Y L, CHUNG H W A novel time-obfuscated algorithm for trajectory privacy protection
[J]. IEEE Transactions on Services Computing , 2014 , 7 (2 ): 126 - 139
DOI:10.1109/TSC.2013.55
[本文引用: 1]
[23]
ZHANG S, WANG G, LIU Q, et al A trajectory privacy-preserving scheme based on query exchange in mobile social networks
[J]. Soft Computing , 2017 , 22 (18 ): 6121 - 6133
[本文引用: 1]
[24]
JUNG K, JO S, SEOG P. A game theoretic approach for collaborative caching techniques in privacy preserving location-based services [C]// BIGCOMP . Jeju: IEEE, 2015: 59–62.
[本文引用: 1]
[25]
PENG T, LIU Q, MENG D, et al Collaborative trajectory privacy preserving scheme in location-based services
[J]. Information Sciences , 2017 , 387 : 165 - 179
DOI:10.1016/j.ins.2016.08.010
[本文引用: 1]
[26]
ZHANG S, CHOO K K R, LIU Q, et al Enhancing privacy through uniform grid and caching in location-based services
[J]. Future Generation Computer Systems , 2017 , 86 (9 ): 881 - 892
[本文引用: 1]
[27]
NIU B, LI Q, ZHU X, et al. Enhancing privacy through caching in location-based services [C]// INFOCOM . Hong Kong: IEEE, 2015: 1017-1025.
[本文引用: 4]
[28]
李璐璐, 华佳烽, 万盛, 等 基于高效信息缓存的位置隐私保护方案
[J]. 通信学报 , 2017 , 38 (6 ): 148 - 157
[本文引用: 2]
LI Lu-lu, HUA Jia-feng, WAN Sheng, et al Achieving efficient location privacy protection based on cache
[J]. Journal on Communications , 2017 , 38 (6 ): 148 - 157
[本文引用: 2]
[29]
ZHENG Y, XIE X, MA W GeoLife: a collaborative social networking service among user location and trajectory
[J]. IEEE Data Engineering Bulletin , 2010 , 33 (2 ): 32 - 39
[本文引用: 1]
Privacy protector: privacy-protected patient data collection in IoT-based healthcare systems
1
2018
... 近年来,无线通信技术取得了突飞猛进的发展,随之而来的是通讯成本的快速降低,智能手机的广泛普及. 位置服务(location-based services,LBS)使人们的生活更加舒适和方便,基于LBS研发的各类软件已经成为人们生活中的热门应用[1 -2 ] . LBS是依赖于用户位置信息的服务,如路径导航,查找酒店、餐馆或加油站等目的地位置,用户通常使用移动设备获取这类服务[3 -4 ] . 为了享受这些便利,移动用户须向不可信的位置服务提供商(location service provider,LSP)提交查询. 通过收集用户的请求数据,LSP可以推断用户的个人信息,如用户的位置、偏好、家庭背景等[5 ] ,LSP有可能向第三方披露用户的私人信息. 因此,在LBS中保护用户的个人隐私成为人们关注的焦点. ...
Preserving privacy with probabilistic indistinguishability in weighted social networks
1
2017
... 近年来,无线通信技术取得了突飞猛进的发展,随之而来的是通讯成本的快速降低,智能手机的广泛普及. 位置服务(location-based services,LBS)使人们的生活更加舒适和方便,基于LBS研发的各类软件已经成为人们生活中的热门应用[1 -2 ] . LBS是依赖于用户位置信息的服务,如路径导航,查找酒店、餐馆或加油站等目的地位置,用户通常使用移动设备获取这类服务[3 -4 ] . 为了享受这些便利,移动用户须向不可信的位置服务提供商(location service provider,LSP)提交查询. 通过收集用户的请求数据,LSP可以推断用户的个人信息,如用户的位置、偏好、家庭背景等[5 ] ,LSP有可能向第三方披露用户的私人信息. 因此,在LBS中保护用户的个人隐私成为人们关注的焦点. ...
EPLQ: efficient privacy-preserving location-based query over outsourced encrypted data
1
2016
... 近年来,无线通信技术取得了突飞猛进的发展,随之而来的是通讯成本的快速降低,智能手机的广泛普及. 位置服务(location-based services,LBS)使人们的生活更加舒适和方便,基于LBS研发的各类软件已经成为人们生活中的热门应用[1 -2 ] . LBS是依赖于用户位置信息的服务,如路径导航,查找酒店、餐馆或加油站等目的地位置,用户通常使用移动设备获取这类服务[3 -4 ] . 为了享受这些便利,移动用户须向不可信的位置服务提供商(location service provider,LSP)提交查询. 通过收集用户的请求数据,LSP可以推断用户的个人信息,如用户的位置、偏好、家庭背景等[5 ] ,LSP有可能向第三方披露用户的私人信息. 因此,在LBS中保护用户的个人隐私成为人们关注的焦点. ...
A general framework for MaxRS and MaxCRS monitoring in spatial data streams
1
2017
... 近年来,无线通信技术取得了突飞猛进的发展,随之而来的是通讯成本的快速降低,智能手机的广泛普及. 位置服务(location-based services,LBS)使人们的生活更加舒适和方便,基于LBS研发的各类软件已经成为人们生活中的热门应用[1 -2 ] . LBS是依赖于用户位置信息的服务,如路径导航,查找酒店、餐馆或加油站等目的地位置,用户通常使用移动设备获取这类服务[3 -4 ] . 为了享受这些便利,移动用户须向不可信的位置服务提供商(location service provider,LSP)提交查询. 通过收集用户的请求数据,LSP可以推断用户的个人信息,如用户的位置、偏好、家庭背景等[5 ] ,LSP有可能向第三方披露用户的私人信息. 因此,在LBS中保护用户的个人隐私成为人们关注的焦点. ...
Privacy enhanced location sharing for mobile online social networks
1
2018
... 近年来,无线通信技术取得了突飞猛进的发展,随之而来的是通讯成本的快速降低,智能手机的广泛普及. 位置服务(location-based services,LBS)使人们的生活更加舒适和方便,基于LBS研发的各类软件已经成为人们生活中的热门应用[1 -2 ] . LBS是依赖于用户位置信息的服务,如路径导航,查找酒店、餐馆或加油站等目的地位置,用户通常使用移动设备获取这类服务[3 -4 ] . 为了享受这些便利,移动用户须向不可信的位置服务提供商(location service provider,LSP)提交查询. 通过收集用户的请求数据,LSP可以推断用户的个人信息,如用户的位置、偏好、家庭背景等[5 ] ,LSP有可能向第三方披露用户的私人信息. 因此,在LBS中保护用户的个人隐私成为人们关注的焦点. ...
1
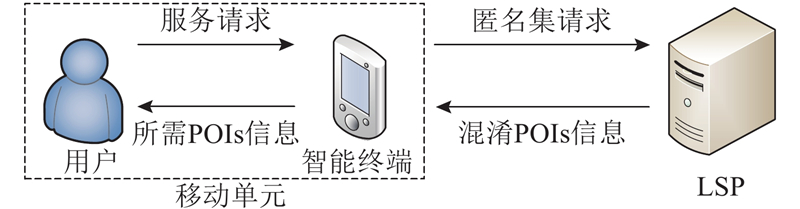
... 如何才能保护LBS中移动用户的个人隐私,有很多研究提出了解决方案. 其中,大多数解决方案依赖于包含可信第三方(trusted third-party,TTP)的架构,TTP的功能是构造匿名区[6 -8 ] . 这些方案的问题是,方案将所有隐私信息都集中到TTP服务器,一旦TTP服务器被对手攻击导致信息泄露,用户的个人隐私将得不到保护. 另一些方案是利用TTP服务器的缓存来记录和查询数据. 虽然用户从缓存中获取所需的服务数据,可以减少与LSP的交互次数[9 -11 ] ,但是这些方案未能充分利用缓存和历史数据来更好地保护用户的个人隐私. 为了提高对用户个人隐私的保护程度,同时提高对缓存数据的利用效率,本研究提出基于本地缓存的位置感知匿名隐私保护方案(location-aware anonymous selection algorithm, LaSA). 在本方案中,用户不依赖于TTP,而是利用移动终端的缓存构造匿名集. 当用户需要LBS查询服务时,用户先在本地移动终端的缓存中查询结果. 如果缓存中的数据能够满足用户需求,则用户无须再向LSP发起请求,用户的隐私信息不会被暴露给LSP. 如果缓存数据不能满足用户需求,方案将在本地移动终端构造一组可以覆盖其真实查询区域的匿名位置集,再把对匿名位置集的查询请求发送给LSP. 生成匿名集的过程是利用基于历史数据所建立的马尔可夫模型预测下一个可能查询的位置. ...
User-defined privacy grid system for continuous location-based services
1
2015
... 如何才能保护LBS中移动用户的个人隐私,有很多研究提出了解决方案. 其中,大多数解决方案依赖于包含可信第三方(trusted third-party,TTP)的架构,TTP的功能是构造匿名区[6 -8 ] . 这些方案的问题是,方案将所有隐私信息都集中到TTP服务器,一旦TTP服务器被对手攻击导致信息泄露,用户的个人隐私将得不到保护. 另一些方案是利用TTP服务器的缓存来记录和查询数据. 虽然用户从缓存中获取所需的服务数据,可以减少与LSP的交互次数[9 -11 ] ,但是这些方案未能充分利用缓存和历史数据来更好地保护用户的个人隐私. 为了提高对用户个人隐私的保护程度,同时提高对缓存数据的利用效率,本研究提出基于本地缓存的位置感知匿名隐私保护方案(location-aware anonymous selection algorithm, LaSA). 在本方案中,用户不依赖于TTP,而是利用移动终端的缓存构造匿名集. 当用户需要LBS查询服务时,用户先在本地移动终端的缓存中查询结果. 如果缓存中的数据能够满足用户需求,则用户无须再向LSP发起请求,用户的隐私信息不会被暴露给LSP. 如果缓存数据不能满足用户需求,方案将在本地移动终端构造一组可以覆盖其真实查询区域的匿名位置集,再把对匿名位置集的查询请求发送给LSP. 生成匿名集的过程是利用基于历史数据所建立的马尔可夫模型预测下一个可能查询的位置. ...
3
... 如何才能保护LBS中移动用户的个人隐私,有很多研究提出了解决方案. 其中,大多数解决方案依赖于包含可信第三方(trusted third-party,TTP)的架构,TTP的功能是构造匿名区[6 -8 ] . 这些方案的问题是,方案将所有隐私信息都集中到TTP服务器,一旦TTP服务器被对手攻击导致信息泄露,用户的个人隐私将得不到保护. 另一些方案是利用TTP服务器的缓存来记录和查询数据. 虽然用户从缓存中获取所需的服务数据,可以减少与LSP的交互次数[9 -11 ] ,但是这些方案未能充分利用缓存和历史数据来更好地保护用户的个人隐私. 为了提高对用户个人隐私的保护程度,同时提高对缓存数据的利用效率,本研究提出基于本地缓存的位置感知匿名隐私保护方案(location-aware anonymous selection algorithm, LaSA). 在本方案中,用户不依赖于TTP,而是利用移动终端的缓存构造匿名集. 当用户需要LBS查询服务时,用户先在本地移动终端的缓存中查询结果. 如果缓存中的数据能够满足用户需求,则用户无须再向LSP发起请求,用户的隐私信息不会被暴露给LSP. 如果缓存数据不能满足用户需求,方案将在本地移动终端构造一组可以覆盖其真实查询区域的匿名位置集,再把对匿名位置集的查询请求发送给LSP. 生成匿名集的过程是利用基于历史数据所建立的马尔可夫模型预测下一个可能查询的位置. ...
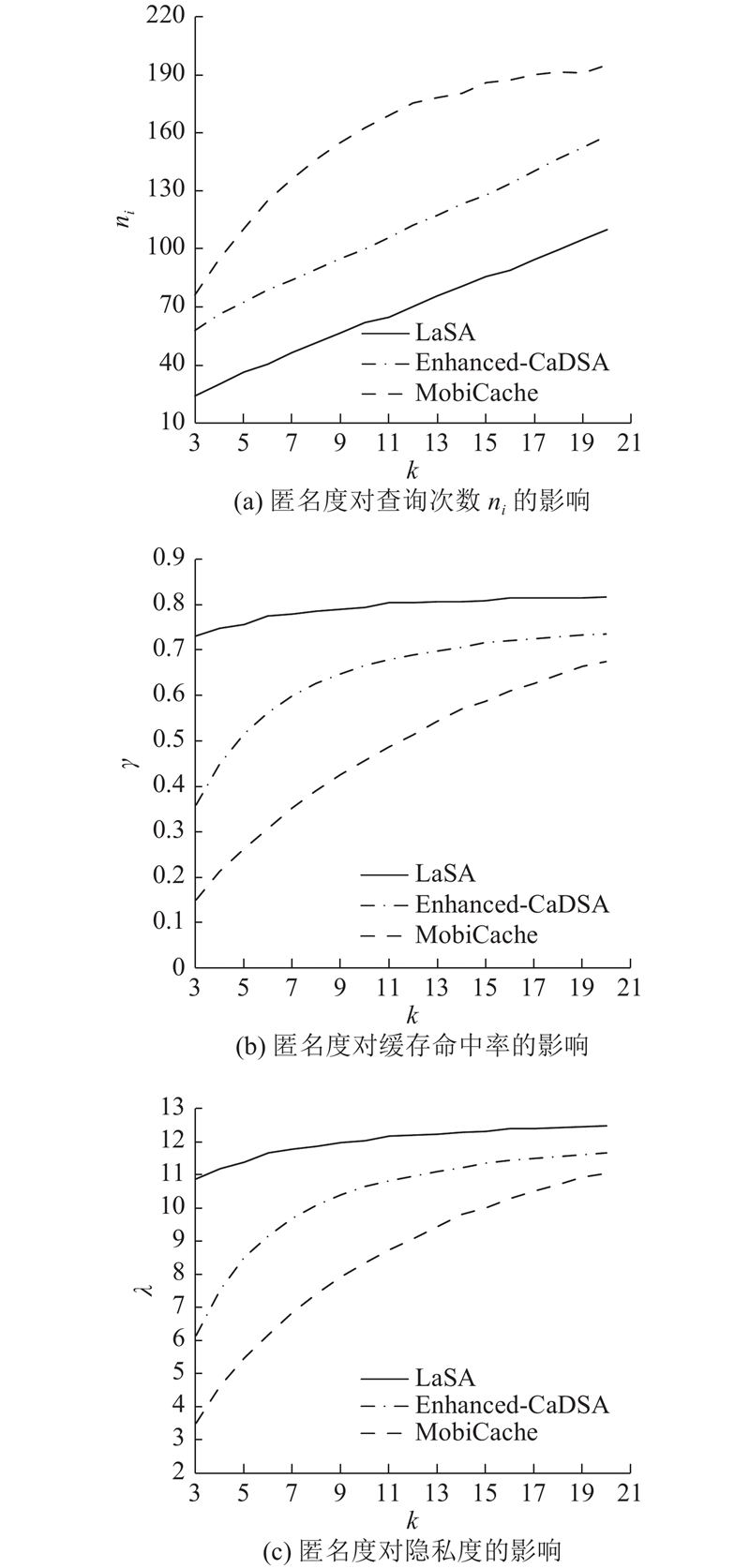
... 实验电脑配置为Intel(R)Core(TM)i7-8550U CPU@1.80 GHz 2.00 GHz和8 GB RAM;所提隐私保护方案的实验环境为Anaconda3和Python3.7. Enhanced-CaDSA[27 ] 和MobiCache[9 ] 方案将作为对照方案与所提方案进行对比. ...
... MobiCache方案[9 ] 是在地图中选择缓存贡献度较高的位置来构成匿名集合,这使它仅在局部时间范围内保证较高的缓存利用率. Enhanced-CaDSA[27 ] 除了考虑缓存贡献度,还考虑归一化距离,于是所选位置接近实际位置,但它没有考虑用户的移动性. 另外,还评估了匿名度对隐私度的影响. LaSA方案具有最高的缓存利用率,因此需要的查询次数更少. 在这种情况下,用户的隐私保护效果是最好的,如图3(c) 所示. 结果表明,所提方案可以更有效地利用来自LSP服务器的查询数据,从而减少移动单元向LSP发送查询的次数,能够增强对用户隐私的保护. ...
Hiding in the mobile crowd: locationprivacy through collaboration
0
2014
1
... 如何才能保护LBS中移动用户的个人隐私,有很多研究提出了解决方案. 其中,大多数解决方案依赖于包含可信第三方(trusted third-party,TTP)的架构,TTP的功能是构造匿名区[6 -8 ] . 这些方案的问题是,方案将所有隐私信息都集中到TTP服务器,一旦TTP服务器被对手攻击导致信息泄露,用户的个人隐私将得不到保护. 另一些方案是利用TTP服务器的缓存来记录和查询数据. 虽然用户从缓存中获取所需的服务数据,可以减少与LSP的交互次数[9 -11 ] ,但是这些方案未能充分利用缓存和历史数据来更好地保护用户的个人隐私. 为了提高对用户个人隐私的保护程度,同时提高对缓存数据的利用效率,本研究提出基于本地缓存的位置感知匿名隐私保护方案(location-aware anonymous selection algorithm, LaSA). 在本方案中,用户不依赖于TTP,而是利用移动终端的缓存构造匿名集. 当用户需要LBS查询服务时,用户先在本地移动终端的缓存中查询结果. 如果缓存中的数据能够满足用户需求,则用户无须再向LSP发起请求,用户的隐私信息不会被暴露给LSP. 如果缓存数据不能满足用户需求,方案将在本地移动终端构造一组可以覆盖其真实查询区域的匿名位置集,再把对匿名位置集的查询请求发送给LSP. 生成匿名集的过程是利用基于历史数据所建立的马尔可夫模型预测下一个可能查询的位置. ...
1
... 在LBS位置隐私保护中,主要有2种常用的架构:依赖TTP的架构[12 ] 和不依赖TTP的架构. ...
The framework and algorithm for preserving user trajectory while using location-based services in IoT-cloud systems
1
2017
... 在依赖TTP的架构中有一个名为匿名器的可信的第三方组件,它位于用户和LSP之间. 匿名器的作用是执行位置匿名,使得LSP无法分辨真实用户和其他用户. 匿名器的引入增强了保护用户隐私的能力[13 -14 ] . 但是,所有提交的查询都必须通过匿名器,使得匿名器成为此类架构的性能瓶颈. 如果恶意第三方攻击该服务器,所有用户的隐私都将受到危害. ...
STAMP: enabling privacy-preserving location proofs for mobile users
1
2016
... 在依赖TTP的架构中有一个名为匿名器的可信的第三方组件,它位于用户和LSP之间. 匿名器的作用是执行位置匿名,使得LSP无法分辨真实用户和其他用户. 匿名器的引入增强了保护用户隐私的能力[13 -14 ] . 但是,所有提交的查询都必须通过匿名器,使得匿名器成为此类架构的性能瓶颈. 如果恶意第三方攻击该服务器,所有用户的隐私都将受到危害. ...
基于Space Twist的k-匿名增量近邻查询位置隐私保护算法
1
2016
... 在不依赖TTP的架构中,用户通过移动终端直接与LSP通信,客户端通过独立[15 ] 或协作[16 -17 ] 的方式构造匿名区域. 该类架构的优点是易于部署. 然而,在这些方案中,独立构建匿名区域的方法虽然能够实现对用户隐私信息的保护,但隐私保护的程度不够. 在用户相互协作的方法中,用户和协作方须拥有2个独立的通信网络,分别用于P2P通信和LBS查询,这严重降低了该类方案的实用性. ...
基于Space Twist的k-匿名增量近邻查询位置隐私保护算法
1
2016
... 在不依赖TTP的架构中,用户通过移动终端直接与LSP通信,客户端通过独立[15 ] 或协作[16 -17 ] 的方式构造匿名区域. 该类架构的优点是易于部署. 然而,在这些方案中,独立构建匿名区域的方法虽然能够实现对用户隐私信息的保护,但隐私保护的程度不够. 在用户相互协作的方法中,用户和协作方须拥有2个独立的通信网络,分别用于P2P通信和LBS查询,这严重降低了该类方案的实用性. ...
SocialHide: a generic distributed framework for location privacy protection
1
2016
... 在不依赖TTP的架构中,用户通过移动终端直接与LSP通信,客户端通过独立[15 ] 或协作[16 -17 ] 的方式构造匿名区域. 该类架构的优点是易于部署. 然而,在这些方案中,独立构建匿名区域的方法虽然能够实现对用户隐私信息的保护,但隐私保护的程度不够. 在用户相互协作的方法中,用户和协作方须拥有2个独立的通信网络,分别用于P2P通信和LBS查询,这严重降低了该类方案的实用性. ...
1
... 在不依赖TTP的架构中,用户通过移动终端直接与LSP通信,客户端通过独立[15 ] 或协作[16 -17 ] 的方式构造匿名区域. 该类架构的优点是易于部署. 然而,在这些方案中,独立构建匿名区域的方法虽然能够实现对用户隐私信息的保护,但隐私保护的程度不够. 在用户相互协作的方法中,用户和协作方须拥有2个独立的通信网络,分别用于P2P通信和LBS查询,这严重降低了该类方案的实用性. ...
1
... 在构建匿名区域的技术中,主要方法包含匿名和混淆. 前者主要通过生成一系列假位置来隐藏用户的真实位置,以降低用户隐私暴露的风险. 例如,Zhang等[18 ] 提出基于实际道路条件构建匿名位置的方法. Shuhei等[19 ] 使用基于估计的虚拟轨迹生成方法,该方法根据给定的访问点来估计用户的移动计划,并生成虚拟轨迹,使得对手无法区分用户和假用户. 身份匿名方法是通过使用附近用户信息来隐藏自身的真实身份,从而防止攻击者锁定目标用户[20 ] . 该方法对用户隐私的保护程度主要取决于用户身份与特定位置用户之间的关联. 因此,在这类方法中,用户须频繁更换自己的假名. ...
Dummy generation based on user-movement estimation for location privacy protection
1
2018
... 在构建匿名区域的技术中,主要方法包含匿名和混淆. 前者主要通过生成一系列假位置来隐藏用户的真实位置,以降低用户隐私暴露的风险. 例如,Zhang等[18 ] 提出基于实际道路条件构建匿名位置的方法. Shuhei等[19 ] 使用基于估计的虚拟轨迹生成方法,该方法根据给定的访问点来估计用户的移动计划,并生成虚拟轨迹,使得对手无法区分用户和假用户. 身份匿名方法是通过使用附近用户信息来隐藏自身的真实身份,从而防止攻击者锁定目标用户[20 ] . 该方法对用户隐私的保护程度主要取决于用户身份与特定位置用户之间的关联. 因此,在这类方法中,用户须频繁更换自己的假名. ...
1
... 在构建匿名区域的技术中,主要方法包含匿名和混淆. 前者主要通过生成一系列假位置来隐藏用户的真实位置,以降低用户隐私暴露的风险. 例如,Zhang等[18 ] 提出基于实际道路条件构建匿名位置的方法. Shuhei等[19 ] 使用基于估计的虚拟轨迹生成方法,该方法根据给定的访问点来估计用户的移动计划,并生成虚拟轨迹,使得对手无法区分用户和假用户. 身份匿名方法是通过使用附近用户信息来隐藏自身的真实身份,从而防止攻击者锁定目标用户[20 ] . 该方法对用户隐私的保护程度主要取决于用户身份与特定位置用户之间的关联. 因此,在这类方法中,用户须频繁更换自己的假名. ...
1
... 混淆技术通常将用户的查询点扩大为一个区域,然后将该区域发送到LSP进行查询;因此,攻击者只知道用户所在的区域[21 ] . Hwang等[22 ] 将S-段范式与R-匿名、K-匿名技术相融合,提出将基于用户隐私的隐藏位置信息与真实环境条件相结合,以避免LSP挖掘用户真实轨迹. Zhang等[23 ] 设计基于偏差的查询交换方案,该方案对不同用户的查询点进行混淆操作,从而阻碍轨迹推断,降低用户隐私暴露的风险. ...
A novel time-obfuscated algorithm for trajectory privacy protection
1
2014
... 混淆技术通常将用户的查询点扩大为一个区域,然后将该区域发送到LSP进行查询;因此,攻击者只知道用户所在的区域[21 ] . Hwang等[22 ] 将S-段范式与R-匿名、K-匿名技术相融合,提出将基于用户隐私的隐藏位置信息与真实环境条件相结合,以避免LSP挖掘用户真实轨迹. Zhang等[23 ] 设计基于偏差的查询交换方案,该方案对不同用户的查询点进行混淆操作,从而阻碍轨迹推断,降低用户隐私暴露的风险. ...
A trajectory privacy-preserving scheme based on query exchange in mobile social networks
1
2017
... 混淆技术通常将用户的查询点扩大为一个区域,然后将该区域发送到LSP进行查询;因此,攻击者只知道用户所在的区域[21 ] . Hwang等[22 ] 将S-段范式与R-匿名、K-匿名技术相融合,提出将基于用户隐私的隐藏位置信息与真实环境条件相结合,以避免LSP挖掘用户真实轨迹. Zhang等[23 ] 设计基于偏差的查询交换方案,该方案对不同用户的查询点进行混淆操作,从而阻碍轨迹推断,降低用户隐私暴露的风险. ...
1
... 缓存方法的基本思想是利用先前查询的缓存数据来应答后续查询. 例如,Kangsoo等[24 ] 设想了使用虚拟专用服务器来保护LBS中位置隐私的保护方案. 在匿名过程中,该方案使用协作缓存来保证系统稳定. Peng等[25 ] 开发了通过协作缓存保护用户轨迹信息的隐私保护方案. 该方案给恶意第三方试图重绘用户轨迹造成较大困难. Zhang等[26 ] 提出将网格和缓存相结合的方案来增强用户隐私保护. 该方案可以防止不同的用户查询相同的区域,但是会增大客户端开销. Niu等[27 -28 ] 提出基于缓存的方案,使用多种基于缓存的匿名位置选择算法,以提高用户的位置隐私.但上述这些方案不适用于连续的LBS服务. ...
Collaborative trajectory privacy preserving scheme in location-based services
1
2017
... 缓存方法的基本思想是利用先前查询的缓存数据来应答后续查询. 例如,Kangsoo等[24 ] 设想了使用虚拟专用服务器来保护LBS中位置隐私的保护方案. 在匿名过程中,该方案使用协作缓存来保证系统稳定. Peng等[25 ] 开发了通过协作缓存保护用户轨迹信息的隐私保护方案. 该方案给恶意第三方试图重绘用户轨迹造成较大困难. Zhang等[26 ] 提出将网格和缓存相结合的方案来增强用户隐私保护. 该方案可以防止不同的用户查询相同的区域,但是会增大客户端开销. Niu等[27 -28 ] 提出基于缓存的方案,使用多种基于缓存的匿名位置选择算法,以提高用户的位置隐私.但上述这些方案不适用于连续的LBS服务. ...
Enhancing privacy through uniform grid and caching in location-based services
1
2017
... 缓存方法的基本思想是利用先前查询的缓存数据来应答后续查询. 例如,Kangsoo等[24 ] 设想了使用虚拟专用服务器来保护LBS中位置隐私的保护方案. 在匿名过程中,该方案使用协作缓存来保证系统稳定. Peng等[25 ] 开发了通过协作缓存保护用户轨迹信息的隐私保护方案. 该方案给恶意第三方试图重绘用户轨迹造成较大困难. Zhang等[26 ] 提出将网格和缓存相结合的方案来增强用户隐私保护. 该方案可以防止不同的用户查询相同的区域,但是会增大客户端开销. Niu等[27 -28 ] 提出基于缓存的方案,使用多种基于缓存的匿名位置选择算法,以提高用户的位置隐私.但上述这些方案不适用于连续的LBS服务. ...
4
... 缓存方法的基本思想是利用先前查询的缓存数据来应答后续查询. 例如,Kangsoo等[24 ] 设想了使用虚拟专用服务器来保护LBS中位置隐私的保护方案. 在匿名过程中,该方案使用协作缓存来保证系统稳定. Peng等[25 ] 开发了通过协作缓存保护用户轨迹信息的隐私保护方案. 该方案给恶意第三方试图重绘用户轨迹造成较大困难. Zhang等[26 ] 提出将网格和缓存相结合的方案来增强用户隐私保护. 该方案可以防止不同的用户查询相同的区域,但是会增大客户端开销. Niu等[27 -28 ] 提出基于缓存的方案,使用多种基于缓存的匿名位置选择算法,以提高用户的位置隐私.但上述这些方案不适用于连续的LBS服务. ...
... 根据文献[27 ]、[28 ],对位置隐私指标定义如下. ...
... 实验电脑配置为Intel(R)Core(TM)i7-8550U CPU@1.80 GHz 2.00 GHz和8 GB RAM;所提隐私保护方案的实验环境为Anaconda3和Python3.7. Enhanced-CaDSA[27 ] 和MobiCache[9 ] 方案将作为对照方案与所提方案进行对比. ...
... MobiCache方案[9 ] 是在地图中选择缓存贡献度较高的位置来构成匿名集合,这使它仅在局部时间范围内保证较高的缓存利用率. Enhanced-CaDSA[27 ] 除了考虑缓存贡献度,还考虑归一化距离,于是所选位置接近实际位置,但它没有考虑用户的移动性. 另外,还评估了匿名度对隐私度的影响. LaSA方案具有最高的缓存利用率,因此需要的查询次数更少. 在这种情况下,用户的隐私保护效果是最好的,如图3(c) 所示. 结果表明,所提方案可以更有效地利用来自LSP服务器的查询数据,从而减少移动单元向LSP发送查询的次数,能够增强对用户隐私的保护. ...
基于高效信息缓存的位置隐私保护方案
2
2017
... 缓存方法的基本思想是利用先前查询的缓存数据来应答后续查询. 例如,Kangsoo等[24 ] 设想了使用虚拟专用服务器来保护LBS中位置隐私的保护方案. 在匿名过程中,该方案使用协作缓存来保证系统稳定. Peng等[25 ] 开发了通过协作缓存保护用户轨迹信息的隐私保护方案. 该方案给恶意第三方试图重绘用户轨迹造成较大困难. Zhang等[26 ] 提出将网格和缓存相结合的方案来增强用户隐私保护. 该方案可以防止不同的用户查询相同的区域,但是会增大客户端开销. Niu等[27 -28 ] 提出基于缓存的方案,使用多种基于缓存的匿名位置选择算法,以提高用户的位置隐私.但上述这些方案不适用于连续的LBS服务. ...
... 根据文献[27 ]、[28 ],对位置隐私指标定义如下. ...
基于高效信息缓存的位置隐私保护方案
2
2017
... 缓存方法的基本思想是利用先前查询的缓存数据来应答后续查询. 例如,Kangsoo等[24 ] 设想了使用虚拟专用服务器来保护LBS中位置隐私的保护方案. 在匿名过程中,该方案使用协作缓存来保证系统稳定. Peng等[25 ] 开发了通过协作缓存保护用户轨迹信息的隐私保护方案. 该方案给恶意第三方试图重绘用户轨迹造成较大困难. Zhang等[26 ] 提出将网格和缓存相结合的方案来增强用户隐私保护. 该方案可以防止不同的用户查询相同的区域,但是会增大客户端开销. Niu等[27 -28 ] 提出基于缓存的方案,使用多种基于缓存的匿名位置选择算法,以提高用户的位置隐私.但上述这些方案不适用于连续的LBS服务. ...
... 根据文献[27 ]、[28 ],对位置隐私指标定义如下. ...
GeoLife: a collaborative social networking service among user location and trajectory
1
2010
... 轨迹数据集来自文献[29 ],包括由23 667 828个点组成的17 621条轨迹. 这个数据集包含5 a多来收集的约1 229 951英里的GPS数据. 这些数据由多种支持GPS的设备收集. 该数据集中的轨迹大部分分布在北京地区. 选取北京市区的12024个轨迹数据作为本实验使用的数据集. 将30 km×26 km的地图划分为200 m×200 m的单元网格. 每个网格的初始查询概率可以从Google Maps API获得. 在实验中,先用90%的轨迹数据建立马尔可夫转移矩阵. 使用剩余10%的轨迹来模拟连续的LBS查询. 设置用户发起连续LBS查询的时间间隔为2 min. 详细的实验参数表如表1 所示. 表中,N t 为轨迹数量,(x 1 , y 1 )、(x 2 , y 2 )分别为起点(左下)、最大(右上)坐标. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}