

随着互联网的迅猛发展和用户获取信息需求的增加,网站作为服务与用户沟通的主要渠道,一直致力于为用户提供更加丰富多元的信息. 然而随着网页代码量及网页中图像、视频、动态代码等资源的增加,网站系统逐渐庞大,导致网站的加载时间变长,网页的浏览速度变慢,影响了用户的上网体验. BBC发现其网站的加载时间每增加1 s,便会多失去 10% 的用户. Google的研究表明,如果页面加载时间超过 3 s,53% 的移动网站访问活动将会遭到用户抛弃[1].因此控制时延无疑是衡量网站设计的重要指标.
在多层多域名的研究中,涉及主域名以及从域名2个概念,主域名是用户访问网站时在浏览器地址栏输入的域名,而从域名是由主域名查询触发查询的相关域名,比如托管在该网站上的页面元素所对应的域名或一些请求关联域名. 显然主域名才能代表网站本身服务的意义,而域名系统(domain name system, DNS)流量中从域名的存在会导致域名监测的不准确。除此之外,从域名的分布、请求顺序、重复查询机制会影响网站的加载速度,因此识别多层多域名结构有助于站点筛选及有效分析网站的访问行为,进而对其进行优化.
1. 问题背景
1.1. 多层多域名方法的应用
图 1
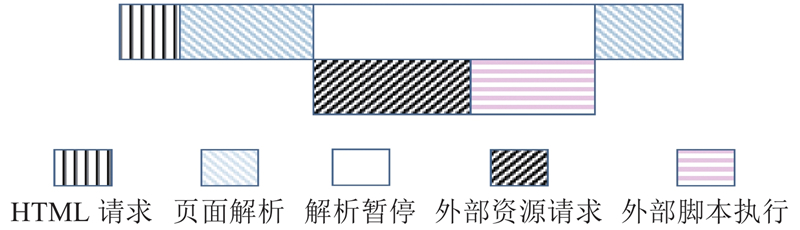
因此在整个网站请求过程中,如果外部资源与网站HTML拥有不同的绝对URI,并未被缓存,就需要多次DNS解析去获得资源所在的服务器IP,进而获得服务器上的资源. 另外为了提升页面的加载速度,外部资源通常是并发请求,并行下载的. 这就是多层多域名应用的一个体现. 因此首先解析主域名,再猝发解析外部资源的域名将作为多层多域名检测的一个重要依据.
1.2. 域名监测及数据来源
DNS是当今互联网中重要的基础核心服务之一,负责提供统一域名地址空间映射服务. 然而,域名系统在提供正常服务的同时,越来越多的网络非法活动也开始滥用域名系统以达到恶意目的. 为了更好地实现内网运行管理,挖掘恶意服务,CERNET主干网华东北地区网络中心对江苏省网与CERNET主干网之间的DNS流量进行了监测.
IP 地址综合信息系统(IP comprehensive information system, IPCIS )是面向CERNET主干网运行管理和安全保障需求而开发的一个标识资源基础信息库,包含IP地址和域名的背景信息. 目前 IPCIS 系统信息库主要由 IP 地址管理归属库、DNS 域名信息库2部分组成. 利用IPCIS系统对江苏省网边界的DNS流量进行实时采集和解析,并将DNS应答报文中的资源记录存储到DNS域名信息库中,为多层多域名研究提供了DNS应答数据. IPCIS域名信息数据库的总体结构如图2所示.
图 2
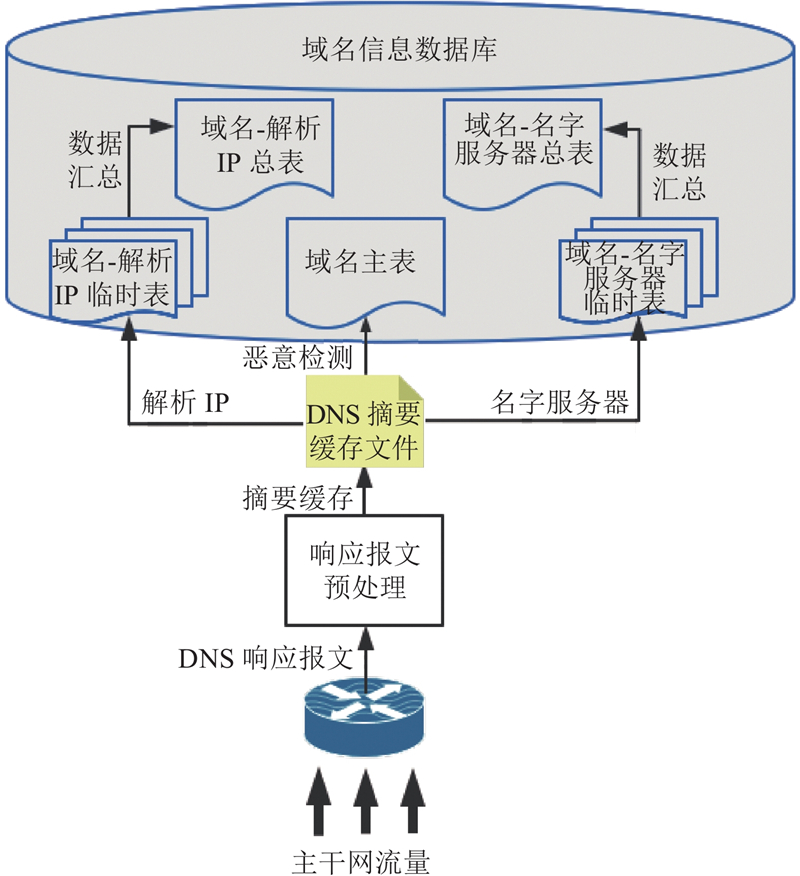
此外还提供DNS服务,包括本地权威域名的维护和向江苏入网用户开放的递归查询服务,以及为部分入网单位提供的权威域名托管服务. DNS查询记录存入数据库时,以5 min为单位时间做了聚合. IPCIS提供的请求和应答数据是本研究的主要数据来源.
1.3. 多层多域名现象对域名监测的影响
域名监测针对的是提供服务的域名,也就是主域名,然而在域名监测的过程中,发现DNS流量中存在着大量的非服务域名,即从域名。多层多域名现象的存在会导致监测的不准确,因此主从域名的识别有助于域名监测.
针对多层多域名检测的研究需要解决2个关键问题:如何获得域名解析列表、如何在一批域名中检测出主域名及其下的资源从域名.
根据主域名和资源从域名的包含关系以及域名请求时的时间序列信息进行多层多域名的测量,通常有2种思路:1)爬取特定网站的HTML获得src中URL包含的域名,这是在已知主域名的情况下,主动探测资源从域名的方法;2)基于DNS流量,利用DNS请求和应答报文的时间序列信息发现其中的多层多域名关系,这是一种被动测量的方式,适用于对用户访问行为未知的情况下,对海量域名中多层多域名现象的测量. 本研究采用的就是第2种方法,使用的是上述在CERNET主干网边界采集到的DNS请求数据和DNS应答数据.
在基于IPCIS进行域名监测的过程中,通过对一些组织的域名和IP的映射关系及IP归属进行研究和统计,发现了多层多域名现象的存在. 例如对于归属在东南大学和江苏广播电视大学内的IP,查找了DNS域名信息库中所有被解析到这些IP的域名. 发现它们的域名数量、IP数量及比例关系如表1所示. 2个案例中域名数量都是多于IP数量的,说明了多层多域名现象的存在. 多层多域名现象的存在使得DNS流量中混杂着大量不提供网站服务的资源域名,影响着域名监测的准确性,因此主从域名的检测有一定的必要性.
表 1 2个单位的域名及IP数量
Tab.1
| 单位 | 域名数量 | IP数量 | 域名数量∶IP |
| 东南大学 | 1 398 | 1 309 | 1.07∶1 |
| 江苏广播电视大学 | 17 061 | 61 | 280∶1 |
2. 多层多域名检测算法
2.1. 研究现状
目前对多层多域名的研究主要集中在域名关联性隐含的安全问题. 彭成维等[14]分析了Web第三方资源加载的隐式信任链,将主从域名抽象成信任链的关系,使用一个Chrome的爬虫工具[15]对Web中的依赖链的安全性进行了研究,但是这种方法属于主动探测,并不适用于被动流量分析. Ikram等[16]提出一种基于域名请求伴随关系的恶意域名检测方法,利用具有伴随关系的域名在DNS请求时间上具有明显分块聚簇的特点,提取DNS流量中具有伴随关系的域名序列,但是采用的是粗粒度的聚类操作,并且没有对主从域名的关系进行进一步的研究. Gao等[17]通过设定一个恶意锚域名,判断时间窗口内的关联域名是否与恶意锚域名是同个恶意域. Yajodia等[18]利用解析成功的域名在时间窗口内与失败域名查询的关联性来检测僵尸网络. Liu等[19]通过分析递归服务器中用户的DNS流记录的相关性来识别可疑域名的重定向问题,从而发现欺诈站点,并引入用于关联分析的衰减因子做置信度判定. 这些都是域名关联性研究在网络管理和网络安全领域的应用. Dell′Amico等[20]通过对依赖关系图进行图论分析量化了网站对特定服务的依赖程度,这也说明了多层多域名的发掘可以为域名影响力的分析提供研究对象. 相对于域名关联性在安全领域的应用,本研究更关注的是多层多域名现象对于域名监测准确度的影响,能够从大量DNS流量中发现主从域名结构,筛选出有服务意义的站点域名.
2.2. 设计思路
基于浏览器请求解析网页的流程,以及资源域名大量猝发式请求的特征,利用DNS流量中提取的请求和应答序列,设计一个基于DNS流量的多层多域名检测算法. 挖掘DNS流量中的多层多域名结构,为域名监测提供有服务意义的研究对象. 算法设计主要基于以下原则。
1)性能黄金法则:只有10%~20%的最终用户响应时间花在下载HTML文档上. 其余的80%~90%时间花在下载页面中所有组件上[13].
2)通常浏览器查找一个给定域名的IP地址要花费20~120 ms,发出主域名和资源从域名解析请求的时间差不超过1 s,获得两者解析结果的时间差也不超过1 s;从属于同一个主域名的资源从域名的请求时间和解析结果返回时间在秒级别相同[14].
3)主域名可以通过URL直接进行访问,返回的HTTP状态码为200,而资源从域名无法通过URL直接访问,会返回错误的HTTP状态码.
4)为了缩短域名解析的时间,增加并行下载的数量,网站的外部资源一般会放到至少2个但不多于4个主机名下,因此一个主域名下的大量资源从域名拥有相同的二级域名.
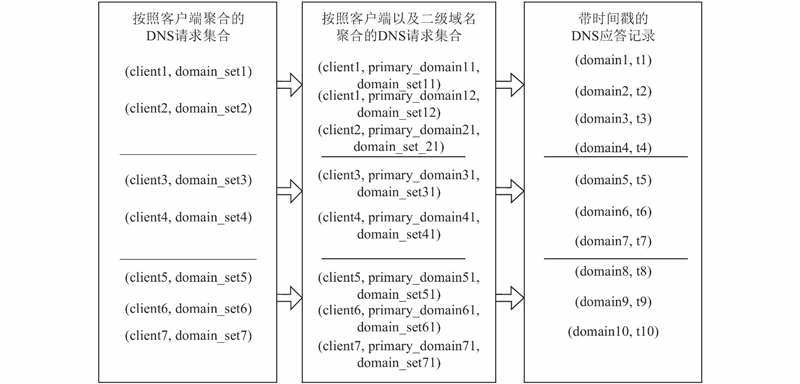
综上,本文设计的算法思路如下所述。首先将DNS服务器监听到的DNS流量数据以5 min为粒度进行划分,再分解为不同终端用户的DNS请求集合,然后将每个DNS请求集合按照二级域名聚合. 在同时间粒度的DNS应答序列中找到二级域名下所有域名的解析时间,判断最早解析的域名能否通过URL直接访问,如果可以,该域名就是主域名,二级域名下其他域名就为从域名;如果该域名不能直接访问,就按照时间倒序的方式找到该域名解析之前第一个能被直接访问的域名作为主域名,二级域名下所有的域名都为从域名. 由于客户端DNS缓存的存在会导致解析服务器无法观测到完整的DNS解析序列,在实验过程中会丢弃无法探测到主域名的该客户端在对应时间粒度下的实验数据和结果,而有主域名,但从域名不完全的数据和结果会被保留. 图3展示了域名聚合映射过程的简单示例图.
图 3
2.3. 核心算法流程
1)将Domain_query中5 min粒度[t, t+5m]内的请求记录先按照客户端(client)聚合,再按照二级域名(SL_domain)聚合,会得到若干域名集合
query_set={query_domain(c, sld)|c=client, sld=SL_domain}
2)获取resolved_ip临时表[t, t+6 m]时间范围内的域名集合resolved_set={resolved_domain(t)|t∈[t, t+6m]},对于domain_set={domain|domain∈query_domain∩resolved_domain, timestamp在秒级别相同},获取domain_set中最早被解析的域名e_domain及其解析时间e_t.
3)判断e_domain能否被直接访问,如果可以,e_domain域名为主域名parent_domain,child_domain_set={child_domain|child_domain∈domain_set-e_domain }为e_domain作为主域名下二级域名为SL_domain的资源从域名;如果e_domain不能被直接访问,将解析时间timestamp∈[e_t-1s, e_t]内能够被直接访问且|timestamp- e_t|最小的域名作为主域名,child_domain_set=domain_set为e_domain作为主域名下二级域名为SL_domain的资源从域名.基本算法如下:
输入:5 min粒度的DNS查询数据query_domain
同时间粒度内的DNS应答数据resolved_ip
输出:主从域名集合(parent_domain,child_domain_set)
query_set<-{query_domain(c, p)|c=client, sld=SL_domain}
//DNS请求数据按照client以及二级域名聚合
resolved_set<-{resolved_domain(t)|t∈[t, t+6m]}
//同时间粒度内的DNS应答数据
domain_set<-{domain|domain∈query_domain∩ resolved_domain}
//获取同client下请求和应答数据的交集
while t∈[t, t+6m] do
for each domain_sete_domain<-the earliest resolved_domain
e_t<-the timestamp of the earliest resolved_domain
if e_domain can be accessed
parent_domain=e_domain
break
else
while t∈[e_t-1s,e_t] do
find the earliest resolved_domain can be accessed
parent_domain=the earliest resolved_domain
end while
child_domain_set={child_domain|child_domain∈domain_ set-e_domain}
output(parent_domain,child_domain_set)
end while
return
2.4. 滑动窗口验证机制和可信度的引入
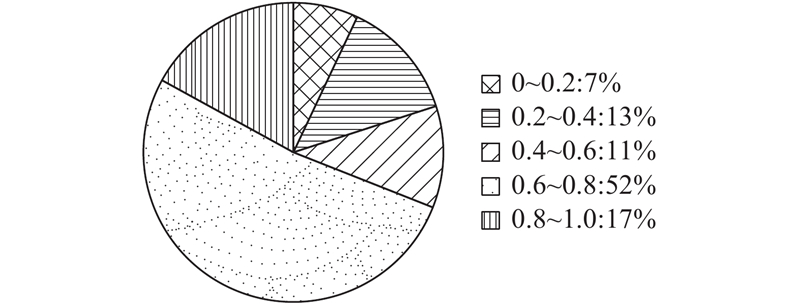
考虑到时间精度问题及数据随机性问题会造成实验结果的误差,引入滑动窗口验证机制对已经测量出的主从域名结果进行可靠性验证. 对于每组主从域名测量结果(parent_domain,child_domain_set),使用其后一天的DNS应答数据,以5 min为滑动窗口,重复多层多域名检测算法中的2)、3)步骤进行200次测量,验证以child_domain_set作为domain_set时,利用5 min时间窗口内的数据作为元数据所得到的主域名是否与parent_domain相同。这里需要说明的是,如果domain_set中的域名有一半以上无法在窗口数据内找到,则放弃该次验证,视为parent_domain在本次验证测量中未出现. 最终统计在200次验证测量中parent_domain出现的频率,并将出现频率分为(0,0.2]、(0.2,0.4]、(0.4,0.6]、(0.6,0.8]、(0.8,1]共5个区间,标识着测量结果的可信度,可信度验证在5个区间内的分布如图4所示.
由图4可见,虽然单次测量结果有一定的误报,但是结果可信度主要分布在0.6~0.8,且可信度在0.6以上的测量结果占测量结果总量的70%. 因此滑动窗口验证机制在一定程度上说明了多层多域名检测算法的可行性,并为提升算法检测结果的准确度提供了一种优化方法. 比如可以在原算法的基础上叠加置信度算法,使用时间滑动窗口验证机制进行周期性检测,为每次的测量结果赋予一个可信度,并随时间窗口累计,直到可信度到达某个阈值再停止验证检测,形成一个流式的多层多域名检测验证算法.
图 4
3. 数据采集
表 2 源数据统计分析
Tab.2
| 数量 | 不重复 域名数量 | 不重复二级 域名数量 | 请求客户 端数量 | 请求/应 答总量 |
| DNS请求 | 4378 064 | 737 575 | 113 427 | 273 744 822 |
| DNS应答 | 2071 320 | 465 652 | − | 414 397 058 |
图 5
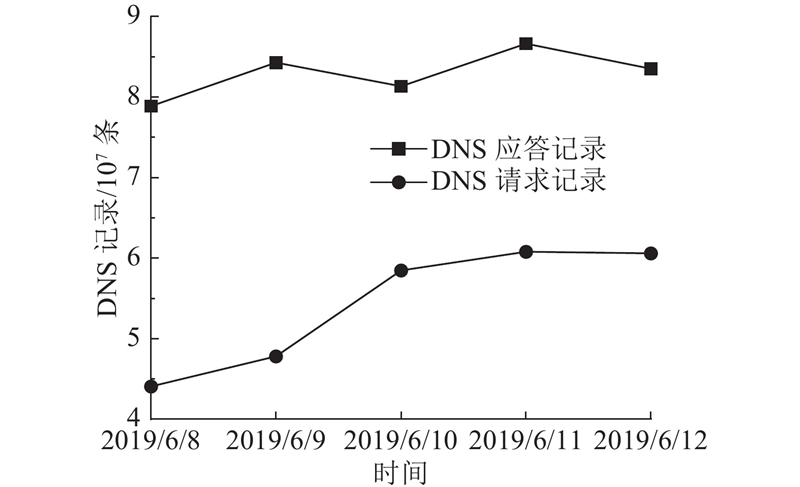
须说明的是,DNS请求记录与DNS解析记录中的域名并非完全吻合,所以只有部分数据可以作为多层多域名检测的数据集,即在同一时间范围内同一域名的DNS请求记录和DNS解析记录都存在的域名相关信息才能够作为多层多域名检测算法的源数据.
4. 结果分析
通过采用多层多域名检测算法对以上数据进行测量并合并以后,共得到819 173个主从域名集合,即819 173个具有多层多域名结构的网站. 其中包括主域名819 173个,不重复从域名5 346 120个,平均一个主域名下包含从域名37个,共覆盖不重复解析IP地址4 799 615个,平均每个解析IP地址对应1.28个域名. 需要说明的是,测量过程未考虑从域名个数在2个以下的情况.
表 3 拥有不同数量从域名的网站数量分布
Tab.3
| 从域名数量范围 | 网站数量分布/% |
| [3, 10] | 44.4 |
| [11, 20] | 18.0 |
| [21, 30] | 9.0 |
| >30 | 28.6 |
表 4 被不同数量网站引用的从域名数量分布
Tab.4
| 被网站引用数量 | 从域名数量分布/% |
| [1, 10] | 65.6 |
| [11, 20] | 24.0 |
| [21, 30] | 5.0 |
| >30 | 5.4 |
图 6
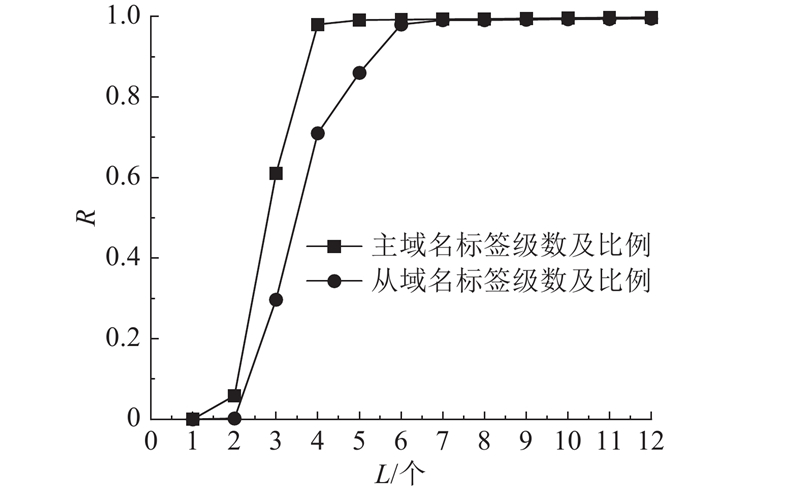
图 6 主从域名标签级数及比例(CDF)
Fig.6 Ratio of number of tags of parent-child domain (CDF)
图 7
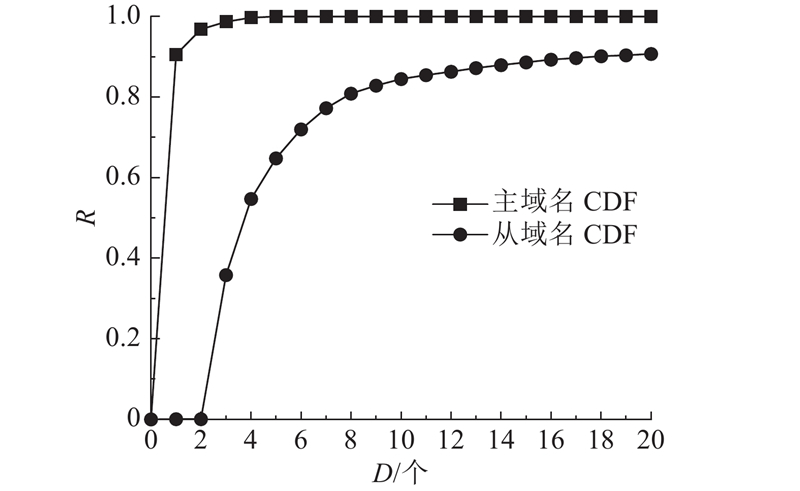
图 7 含有相同二级域名的域名数量及比例(CDF)
Fig.7 Ratio of number of domain with the same second level domain (CDF)
另外,主域名中以“www”开头的域名比例高达30.00%;而从域名中仅有2.25%. 由此可见,网站的域名多以“www”开头.
资源从域名的二级域名通常对应着一些公共资源服务器群。表5列举了部分被从域名使用最多的二级域名及它们的供应商,这些二级域名下的资源从域名对应着不同类型的CDN公共库,供网站调用以达到静态加速的目的.
表 5 top 二级域名及其运营商
Tab.5
| 二级域名 | 运营商 | 二级域名 | 运营商 | |
| akamai.net | Akamai | cdn20.com | 网宿科技 | |
| wsglb0.com | ||||
| wsglb0.com | ||||
| aliyuncs.com | 阿里云 | qq.com | 腾讯云 | |
| alibabadns.com | ||||
| alikunlun.com |
据前文所述,与资源从域名关联的通常是各式各样的静态图片、gif动图、JavaScript脚本、CSS文件等。表6列举了实验结果中2个存在多层多域名的典型网站案例,并且通过使用Chrome开发者工具查看这2个网站,对实验所得到的资源从域名对应的资源类型进行查找统计.
表 6 典型多层多域名网站主从域名示例
Tab.6
| 主域名 | 网站类型 | 资源从域名 | 资源类型 |
| www.cctv.com | 新闻 门户 | p1.img.cctvpic.com | JS,图片,CSS |
| js.player.cntv.cn | JS | ||
| time.tv.cctv.com | PHP | ||
| api.cntv.cn | 接口 | ||
| p.data.cctv.com | JS,gif | ||
| www.iqiyi.com | 视频 网站 | stc.iqiyipic.com | JS,图片,CSS |
| static.iqiyi.com | JS,字体 | ||
| hm.baidu.com | JS,gif |
5. 结 语
本文给出了多层多域名概念的定义,通过分析网站并行加载资源的行为和多层多域名的特点,设计了基于DNS流量的多层多域名检测算法。在使用该算法对CERNET主干网的DNS流量进行检测的实验中,对识别到的主从域名集合的规模、相交现象以及主从域名的特点和差异进行了分析。滑动窗口验证机制证明70%以上的测量结果置信度大于0.6,验证了多层多域名现象的存在以及检测算法的可行性和有效性。基于DNS流量的多层多域名结构的识别和主域名的筛选,为域名监测和对有服务意义的站点域名的影响力分析提供了更为准确的研究对象;利用主从域名的域名关联性挖掘恶意请求链和发现恶意域名组,为解决域名安全问题提供了新的思路。如何提升多层多域名检测的准确率,以及更深层地挖掘主从域名集合之间的关联关系是下一步的研究重点。
参考文献
Web-Page complexity and optimization mechanism to reduce Web-Page load time
[J].
Effects of Web page contents on load time over the Internet
[J].
一种基于域名请求伴随关系的恶意域名检测方法
[J].DOI:10.7544/issn1000-1239.2019.20180481 [本文引用: 2]
Detecting malicious domains using co-occurrence relation between DNS query
[J].DOI:10.7544/issn1000-1239.2019.20180481 [本文引用: 2]
An empirical reexamination of global DNS behavior
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}