

理解人脑的工作机制是21世纪最具挑战性的前沿课题. 脑功能连接刻画不同脑区之间神经元活动的动态关联性,为研究人脑的工作机制提供了崭新的视角[1]. 功能磁共振脑成像(functional magnetic resonance imaging,fMRI)具有无创伤、可重复以及高空间分辨率等优点,是当前脑功能连接研究中重要的神经影像技术[2]. 基于机器学习的fMRI脑功能连接分类由于可以提取fMRI数据中带有判别信息的脑功能连接特征,对脑疾病的早期诊断和病理研究具有重要意义,已成为脑疾病分类的研究热点[3-4]. fMRI脑功能连接的高维小样本特性所引发的维灾难问题给脑疾病分类模型的构建提出了巨大挑战[5].如何对fMRI脑功能连接进行特征归约已经成为脑疾病分类研究的重要课题.
目前,研究人员已经提出多种fMRI脑功能连接特征归约方法,这些方法大致可以分为fMRI脑功能连接特征提取和fMRI脑功能连接特征选择2类. 其中,特征提取方法通常利用变换或映射方式,将原始数据从高维特征空间投影到一个低维空间,从而降低特征维数. Mohanty等[6]采用主成分分析方法(principal component analysis,PCA)将高维脑功能连接特征通过正交变换的方式变为低维脑功能连接特征. Shen等[7]利用局部线性嵌入方法(locally linear embedding,LLE)将原始的脑功能连接特征映射到低维空间. 这类方法能够快速完成特征归约任务,但是得到的特征归约结果不易理解,不利于给出神经学的解释. 特征选择方法依据某种度量指标从特征集中挑选出拥有最优评价指标的特征子集,不改变特征的原始表达,因此能够保持原始特征的含义,有利于人们的理解和判断. Hamdi等[8]使用最大相关最小冗余(minimal redundancy maximal relevance,mRMR)的特征选择方法从脑功能连接数据中获得重要的脑功能连接特征,为脑疾病的病理研究提供生物标志物. Cheng等[9]利用双样本T检验方法从感兴趣的功能连接区域中选取差异显著的特征. Kong等[10]使用非模型评价打分方法(F-score)衡量每个特征的分类判别能力,选择评分高的特征输入到深度神经网络进行脑疾病的分类. 利用这些已有的特征选择方法可以快速获得可解释的特征子集,但是它们只根据单个判别标准选择相对重要的脑功能连接特征,没有考虑特征之间的联系,容易影响得到的特征子集的分类判别能力.
粗糙集是Pawlak[11]提出的用于处理不完整、不精确数据的数学工具. 该理论不需要任何先验知识,仅使用数据本身蕴含的信息就能分析特征之间的关系,现已被广泛应用到特征选择、数据挖掘、决策与分析等领域.付志耀等[12]利用粗糙集得到计算机漏洞的强关联特征集. Liu等[13]提出基于群体粗糙集的数据分析方法SRS,该方法通过观察粒子在搜索空间中正域的变化,有效地发现特征组合. Sarkheyli等[14]利用粗糙集自动选择相关特征,实现实时态势识别. 近年来,随着数据环境的变化,已经涌现出不少粗糙集扩展模型,例如模糊粗糙集[15]、决策粗糙集[16]、邻域粗糙集[17]等. 其中,邻域粗糙集(neighborhood rough set,NRS)结合邻域模型和粗糙集理论,根据实数空间中点的邻域来粒化邻域空间,能够处理连续型数据,有效避免离散化数据带来的损失. 作为有效的粗糙集扩展模型,邻域粗糙集目前在图像分割、基因选择、模式识别等众多领域得到了成功应用[18-20].
鉴于脑功能连接是衡量不同脑区间神经元活动在时间上关联性的连续型数据,而邻域粗糙集可以直接处理连续型数据且具有强大的归约能力,可能在脑功能连接特征归约上发挥作用. 潜在的问题是现有的邻域粗糙集方法大多利用贪心算法搜索候选特征子集,这种方式比较容易陷入局部最优,影响得到的特征子集的分类判别能力. 近年来,基于群智能的搜索方法由于具有结构简单、鲁棒性强、易于与领域知识结合等优点,得到研究者的广泛关注. 鱼群算法作为新型群智能算法,采用自上而下的寻优模式,通过鱼群中各个体的局部寻优,使得全局最优解在群体中突现出来,是解决全局优化问题的有效工具[21-23]. 若在利用邻域粗糙集进行脑功能连接特征归约时,使用鱼群算法对候选特征子集进行搜索,有望克服利用贪心算法搜索候选特征子集时易陷入局部最优的不足.
为了提高脑功能连接特征的分类判别能力,探索高效的邻域粗糙集方法,本研究提出基于鱼群算法的脑功能连接邻域粗糙集特征归约方法(feature reduction of neighborhood rough set based on fish swarm algorithm in brain functional connectivity). 该方法使用邻域粗糙集挖掘脑功能连接特征与标签特征之间的依赖度,并依据该信息初始化种群,然后采用综合特征子集依赖度和长度的适应度函数来评价个体的优劣,最后执行觅食、聚集、追尾、交叉和迁徙机制来优化种群的脑功能连接特征.
1. 相关知识
1.1. 邻域粗糙集
在邻域粗糙集中,邻域信息表由五元组
定义1 在
式中:
式中:
定义2 在
定义3 在
定义4 在
邻域下近似集也称为决策正域,记为
定义5 在
式中:
定义6 在
1.2. 鱼群算法
受鱼类觅食行为的启发,李晓磊等[21]提出在空间中寻求全局最优解的鱼群算法(fish swarm algorithm,FSA). 面对具体的优化问题,鱼群算法将每个人工鱼位置表示为求解问题的一个可行解,并定义适应度函数来衡量个体位置的优劣,然后执行觅食、聚集和追尾机制来搜索最优位置. 算法的主要机制如下.
1) 觅食机制. 鱼类在水中自由游动,可以快速地游向食物所在位置. 令Xi、Yi为人工鱼
式中:I为与Xi同维的单位向量.
2) 聚集机制. 鱼类在寻找食物的过程中,会自发地聚集在一起,以避免伤害,保证生存. 对于任意人工鱼
3) 追尾机制.当一条鱼发现某区域的食物丰富且该区域不太拥挤时,附近鱼类会尾随其后,快速到达该区域. 对于任意人工鱼
2. NRSFSA算法
NRSFSA利用邻域粗糙集与鱼群算法实现脑功能连接特征归约. 该算法的主要思路如下:建立脑功能连接数据的邻域决策表;依据功能连接特征与标签特征之间的依赖度初始化种群,并采用综合特征子集依赖度和长度的适应度函数来评价个体的优劣;执行觅食、聚集、追尾、交叉和迁徙5种机制来不断优化个体,直到获得最优或近似最优的脑功能连接特征子集为止. 其中,觅食、聚集和追尾机制是鱼群算法的核心优化机制,交叉和迁徙机制是为了改善鱼群算法搜索后期个体趋同、早熟现象而引入的新机制. 下面对NRSFSA算法涉及的主要步骤和机制进行详细介绍.
2.1. 个体初始化及其评价
2.1.1. 个体初始化
NRSFSA算法中每条人工鱼的位置代表一个候选的脑功能连接特征子集,用长度为m(m为脑功能连接特征总数)的二进制向量来表示,当第k个脑功能连接特征被选择时,该向量第k个分量的值为“1”,否则为“0”.
个体初始化的步骤如下:1)建立脑功能连接数据的邻域决策表
2.1.2. 个体评价
对于脑功能连接特征归约问题,总希望得到分类能力较强且长度较短的特征子集,因此定义如下综合脑功能连接特征子集依赖度和特征子集长度的适应度函数:
式中:
2.2. 觅食机制
觅食机制使种群中每条人工鱼在自身周围随机游动. 该机制的实现过程如下:对于任意人工鱼
2.3. 聚集机制
在聚集机制中,鱼群中心对鱼个体具有一定的吸引力,当鱼群中心位置的适应度较高且不太拥挤时,个体使用差异移动规则向鱼群中心聚集. 在这一过程中,视野范围的确定、个体之间距离的度量、中心位置的定义以及差异移动规则的确定是实现该机制的关键.这4个关键部分的实现方法如下所示.
1)视野范围.为了平衡算法的全局搜索能力与局部搜索能力,使用自适应的线性函数自动调整视野范围,表达式如下:
式中:
2)鱼个体之间的距离.鉴于脑功能连接的稀疏性,使用Jaccard距离来衡量鱼个体之间的距离,具体表达式如下:
式中:E、H分别为个体
3)中心位置.令
式中:
4)差异移动规则. 当人工鱼i向中心位置
聚集机制的实现过程描述如下:对于任意人工鱼i,根据式(14)确定
2.4. 追尾机制
追尾机制是为了使种群中每条人工鱼朝着适应度较高个体所在的方向移动. 该机制的实现过程描述如下:对于任意人工鱼
2.5. 交叉机制
在算法优化后期,种群多样性严重丧失,使得个体容易陷入局部最优. 在算法中执行交叉机制,可以生成新的个体,增加种群的多样性. 该机制的实现过程如下:对于任意人工鱼位置
式中:
2.6. 迁徙机制
在鱼类的觅食活动中,那些找不到足够食物的个体可能会迁徙到其他地方去寻找更多的食物.因此,执行迁徙机制剔除搜索性能较低的个体,提高算法的全局搜索能力.该机制的实现过程如下:将种群个体按照其适应度连续不变的次数降序排列,移除连续
2.7. 算法描述与分析
NRSFSA算法利用邻域粗糙集与鱼群算法实现脑功能连接特征归约.核心思想是首先建立脑功能连接数据的邻域决策表,计算每个特征与标签特征之间的依赖度信息,初始化种群,并综合特征子集的依赖度和特征子集的长度来评价个体,接着执行觅食、聚集、追尾、交叉和迁徙机制不断优化种群. 具体流程如算法1所示.
算法1.NRSFSA算法
输入:脑功能连接
输出:脑功能连接特征子集
1. 参数设置. 设置种群规模
2. 初始化种群. 根据式(8)计算每个特征的依赖度,选出排列在前的特征初始化种群;
3. 优化种群. 根据式(13)计算每条人工鱼个体的适应度;将种群最优个体及其适应度
While
For
对个体尝试:执行觅食、聚集、追尾机制;执行3种机制中最好的机制,更新个体位置;执行交叉机制;
End for
执行迁徙机制,生成新鱼群;计算鱼群中最优个体及其适应度
If
更新公告牌的最优个体及其适应度;
Else
End If
End While
4. 输出公告牌最优解表示的脑功能连接特征子集.
基于算法1的描述,对NRSFSA进行时间复杂度分析:在初始化过程中,计算所有特征依赖度的时间复杂度为
3. 实验与分析
实验在处理器为Intel (R) Core (TM) i3 CPU 3 120M 2.50 GHz、RAM为4.00 G、操作系统为Windows 10的环境下,利用Matlab2017a运行工具编写的Matlab代码完成.
3.1. 实验数据及评价标准
3.1.1. 实验数据
使用如下3种脑疾病的静息态fMRI数据:阿尔茨海默症神经影像学联盟在平台上发布的ADNI数据集(http://www.adni-info.org)、注意力缺陷多动症联盟提供的ADHD数据集(http://fcon_1000.projects.nitrc.org/indi/adhd200)和孤独症脑成像数据交换联盟发布的ABIDE数据集(http://fcon_1000.projects.nitrc.org/indi/abide/). 3种脑疾病静息态fMRI数据的具体信息如表1所示. 其中,ADNI数据集含有阿尔茨海默症(AD)、认知功能障碍症(MCI)和正常被试(NC)3组被试,ABIDE和ADHD数据集均含有2组被试,分别为孤独症(ASD)组和正常(NC)组、注意力缺陷多动症(ADHD)组和正常 (NC)组. 由于将ADNI数据集的3组被试两两对照,本研究对比实验中共有ABIDE、ADHD、NC-AD、NC-MCI和AD-MCI这5组数据.
表 1 静息态fMRI数据集
Tab.1
| 数据集 | 组别 | 人数 | 年龄范围 | ||
| 被试 | 男 | 女 | |||
| ADNI | NC | 53 | 31 | 22 | 65~96 |
| MCI | 61 | 29 | 32 | 63~88 | |
| AD | 66 | 27 | 39 | 56~88 | |
| ADHD | NC | 48 | 27 | 21 | 8~16 |
| ADHD | 32 | 28 | 4 | 8~15 | |
| ABIDE | NC | 52 | 39 | 13 | 8~56 |
| ASD | 48 | 37 | 11 | 8~55 | |
在实验中,首先对3种脑疾病静息态fMRI数据进行预处理,得到fMRI脑功能连接数据. 具体来说,对于每个fMRI数据集下的每组被试,利用AAL(anatomical automatic labeling)模板将大脑划分为90个脑区,然后分别计算2个脑区之间平均时间序列的皮尔森相关系数,得到 90×90的功能连接矩阵,其中每个元素表示相应2个脑区之间的功能连接强度. 因为功能连接矩阵是对称矩阵,所以原始的不同脑功能连接特征数为4 005.
3.1.2. 评价标准
特征归约的评价标准主要有两方面:归约所得脑功能连接特征的数目;特征子集的分类判别能力.利用SVM分类学习算法来检验脑功能连接特征子集的分类判别能力,SVM参数值由libsvm工具箱提供的网格搜索策略自适应确定,并使用如下4种常用的分类评价指标:准确率(accuracy, Acc)、精确率(precision, Pr)、召回率(recall, Re)以及F度量(F-measure, Fm). 定义如下:
式中:TP为将患者预测为病人的数目;TN为将正常人预测为正常人的数目;FP为将正常人预测为病人的数目;FN为将患者预测为正常人的数目. 准确率、精确率、召回率以及F度量4项指标越高,特征子集的分类判别能力越强.
3.2. 参数分析
NRSFSA算法在5组数据上的参数设置如下:
3.2.1. 鱼群算法相关参数分析
在数据上测试视野权重、迁徙阈值、交叉概率、尝试次数及拥挤度对算法的影响. 在测试过程中保持其余参数不变,仅变动待测试参数,结果如图1所示.具体来看,参数W影响算法全局搜索与局部搜索之间的平衡,随着W的增加,Acc、Pr、Re、Fm总体呈现先增后减的趋势,在
图 1
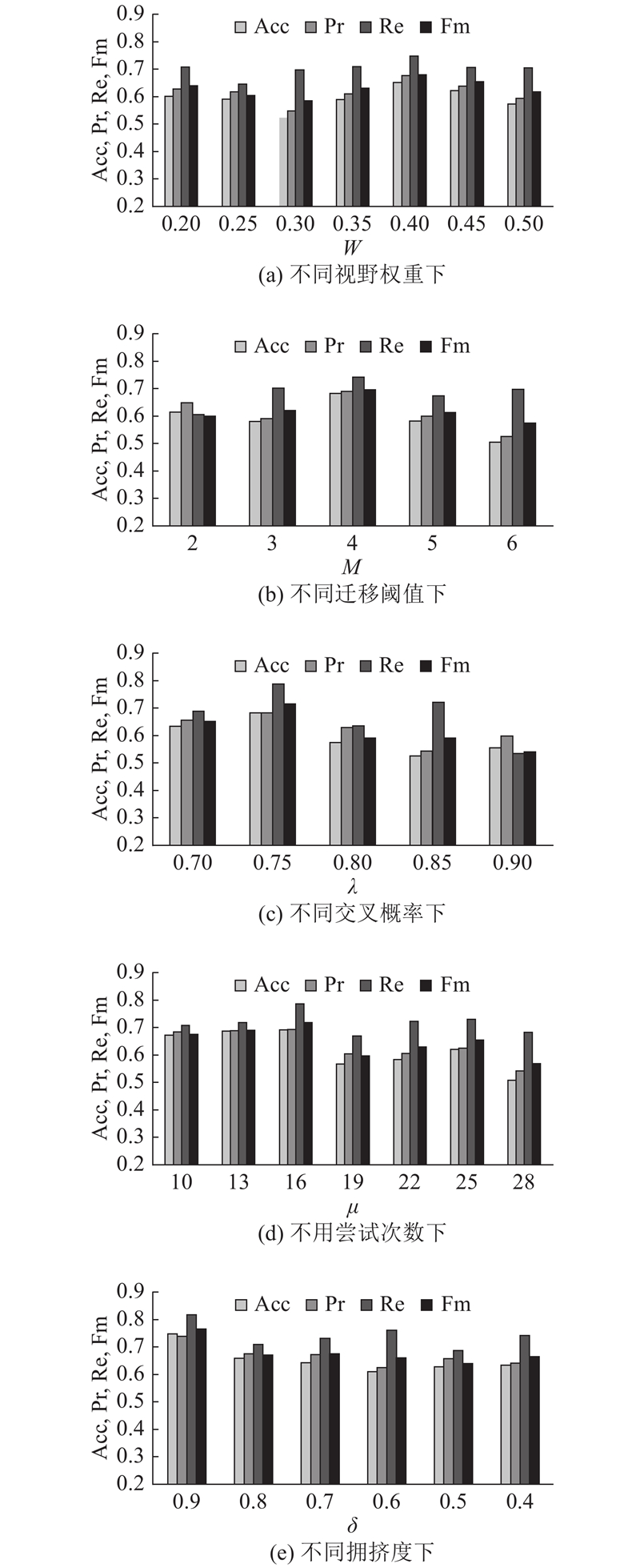
图 1 NRSFSA算法在不同测试参数下的评价指标
Fig.1 Evaluation index of NRSFSA algorithm under different test parameters
3.2.2. 邻域半径参数分析
经过初步实验得到每个数据集上
图 2
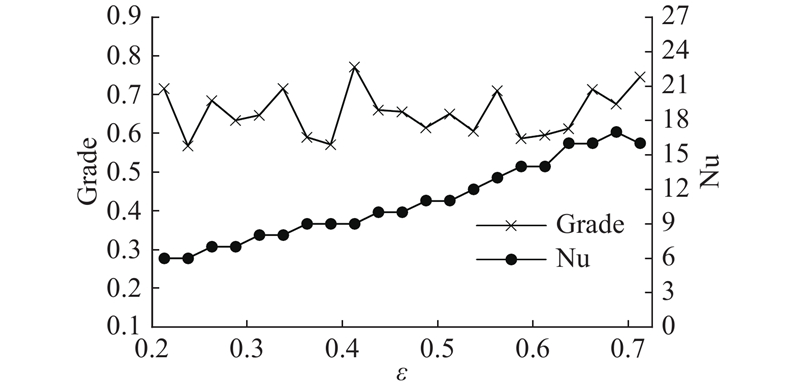
图 2 NRSFSA算法在不同邻域半径下的实验结果
Fig.2 Experimental results of NRSFSA algorithm under different neighborhood radius
3.3. 收敛过程
NRSFSA算法通过鱼群逐步迭代获得最优或最近最优的脑功能连接特征子集. 为了展示算法的收敛特性,提供NRSFSA算法在5组fMRI脑功能连接数据上的迭代过程,如图3所示.可以看出,随着迭代次数的增加,纵坐标的适应度也逐步提高,最后算法收敛于最优值或近似最优值.
图 3
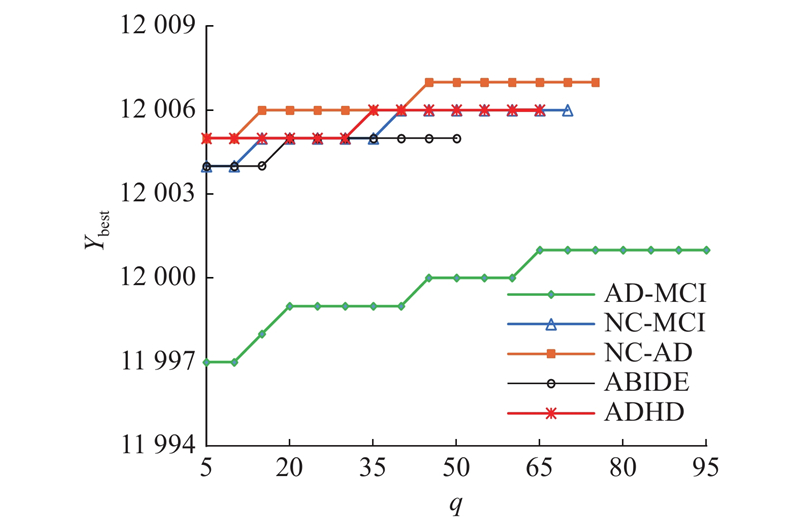
图 3 NRSFSA算法在数据集上的迭代过程
Fig.3 Iterative process of NRSFSA algorithm on datasets
3.4. 实验对比分析
为了验证NRSFSA算法的有效性,将NRSFSA与PCA、LLE、mRMR、NRS、F-score、SRS以及使用邻域粗糙集替代SRS中粗糙集的SNRS共7种方法进行对比.
3.4.1. 特征归约
表 2 8种算法在5组实验数据上的实验结果
Tab.2
| 数据集 | 算法 | Nu | Acc | Pr | Re | Fm |
| ADHD | SRS | 23 | 0.60750 | 0.58638 | 0.48067 | 0.41665 |
| SNRS | 11 | 0.66250 | 0.64095 | 0.48600 | 0.48524 | |
| mRMR | 9 | 0.72500 | 0.75757 | 0.51510 | 0.54380 | |
| NRS | 11 | 0.69750 | 0.68933 | 0.53933 | 0.52734 | |
| LLE | 22 | 0.58250 | 0.63433 | 0.40365 | 0.27369 | |
| PCA | 39 | 0.61750 | 0.68170 | 0.28600 | 0.31450 | |
| F-score | 9 | 0.64750 | 0.62633 | 0.48133 | 0.48689 | |
| NRSFSA | 9 | 0.76500 | 0.79333 | 0.61962 | 0.64165 | |
| ABIDE | SRS | 43 | 0.53400 | 0.70633 | 0.19945 | 0.24923 |
| SNRS | 14 | 0.51200 | 0.52567 | 0.37864 | 0.40008 | |
| mRMR | 10 | 0.56200 | 0.58071 | 0.52614 | 0.50408 | |
| NRS | 6 | 0.65800 | 0.67351 | 0.68288 | 0.63672 | |
| LLE | 36 | 0.57800 | 0.56712 | 0.61083 | 0.55199 | |
| PCA | 66 | 0.53800 | 0.55890 | 0.51870 | 0.49210 | |
| F-score | 10 | 0.72600 | 0.74643 | 0.68048 | 0.68616 | |
| NRSFSA | 10 | 0.69400 | 0.73376 | 0.61683 | 0.61745 | |
| NC-AD | SRS | 15 | 0.59152 | 0.75000 | 0.07386 | 0.10269 |
| SNRS | 14 | 0.70924 | 0.73227 | 0.74110 | 0.71883 | |
| mRMR | 8 | 0.70167 | 0.72543 | 0.78083 | 0.73496 | |
| NRS | 17 | 0.81803 | 0.80314 | 0.89052 | 0.83404 | |
| LLE | 24 | 0.71970 | 0.74294 | 0.78606 | 0.74340 | |
| PCA | 60 | 0.76920 | 0.76320 | 0.82900 | 0.77960 | |
| F-score | 8 | 0.64288 | 0.66526 | 0.74277 | 0.68361 | |
| NRSFSA | 8 | 0.75348 | 0.77167 | 0.81725 | 0.77346 | |
| NC-MCI | SRS | 15 | 0.62379 | 0.65169 | 0.71285 | 0.65813 |
| SNRS | 12 | 0.67530 | 0.69825 | 0.76487 | 0.70573 | |
| mRMR | 9 | 0.69712 | 0.71774 | 0.76529 | 0.71338 | |
| NRS | 15 | 0.72015 | 0.72979 | 0.79019 | 0.73919 | |
| LLE | 24 | 0.73076 | 0.72760 | 0.83533 | 0.76117 | |
| PCA | 60 | 0.76710 | 0.76270 | 0.84500 | 0.78490 | |
| F-score | 9 | 0.81652 | 0.82566 | 0.82013 | 0.80176 | |
| NRSFSA | 9 | 0.75697 | 0.75238 | 0.81108 | 0.76553 | |
| AD-MCI | SRS | 16 | 0.63077 | 0.64118 | 0.71899 | 0.65242 |
| SNRS | 19 | 0.66179 | 0.65876 | 0.77476 | 0.68663 | |
| mRMR | 14 | 0.81859 | 0.79769 | 0.87512 | 0.82196 | |
| NRS | 16 | 0.79244 | 0.80323 | 0.81253 | 0.79404 |
表 2
Tab.2
| 数据集 | 算法 | Nu | Acc | Pr | Re | Fm |
| LLE | 24 | 0.81936 | 0.82191 | 0.81978 | 0.80961 | |
| PCA | 64 | 0.78720 | 0.78090 | 0.82660 | 0.79100 | |
| F-score | 14 | 0.81077 | 0.82612 | 0.80229 | 0.80196 | |
| NRSFSA | 14 | 0.79231 | 0.77573 | 0.86441 | 0.80501 | |
| 平均值 | SRS | 22.4 | 0.59751 | 0.66712 | 0.43716 | 0.41582 |
| SNRS | 14.0 | 0.64417 | 0.65118 | 0.62908 | 0.59930 | |
| mRMR | 10.0 | 0.70088 | 0.71583 | 0.69250 | 0.66364 | |
| NRS | 13.0 | 0.73722 | 0.73980 | 0.74309 | 0.70627 | |
| LLE | 26.0 | 0.68606 | 0.69878 | 0.69113 | 0.62797 | |
| PCA | 57.8 | 0.69580 | 0.70950 | 0.66110 | 0.63240 | |
| F-score | 10.0 | 0.72873 | 0.73796 | 0.70540 | 0.69208 | |
| NRSFSA | 10.0 | 0.75235 | 0.76538 | 0.74584 | 0.72062 | |
由表2可知,在ADHD数据集上,与其他7种算法相比,NRSFSA算法获得的脑功能连接特征数最少,并且在Acc、Pr、Re和Fm指标上的取值最优. 在ABIDE数据集上,NRSFSA算法获得10个脑功能连接特征,在Acc和Pr上均取得第2的成绩,在Re和Fm上均取得第3的成绩;由于在阿尔兹海默症的数据集上出现了多个适应度相同的候选脑功能连接特征子集,NRSFSA算法的输出具有一定的随机性,性能有所下降,不过实验结果相比于其他算法也大多排名前3. 具体来说,在NC-AD数据集上,NRSFSA算法在Pr指标上排名第2,在Acc、Re和Fm指标上均排名第3;在NC-MCI数据集上,NRSFSA算法在Acc、Pr、Fm指标上均排名第3,在Re指标上以较小差距排名第4;在AD-MCI数据集上,NRSFSA算法在Re和Fm上分别取得第2、3的成绩,在Acc和Pr指标上的结果有所下降,分别取得第5、6的成绩. NRSFSA算法在NC-AD、NC-MCI、AD-MCI数据集上获得的特征数均是最少的. 此外,为了更好地展示NRSFSA算法在fMRI脑功能连接特征归约方面的整体性能,在表格最后一部分展示了每个算法在5组数据集上的平均指标值. 从整体平均值来说,与其他7种特征归约算法相比,NRSFSA算法不仅获得的脑功能连接特征数最少,而且在准确率、精确率、召回率和F度量4项指标上均取值最优.
3.4.2. 时间性能
如表3所示为8种算法在每个数据集上运行所消耗的时间. 由于在不同数据集上算法消耗的时间不同,根据平均结果对算法的时间性能进行整体分析.可以看出,相较于PCA、LLE、F-score等特征归约方法,NRSFSA、SRS、SNRS这些迭代类特征归约方法的运行时间较长.在NRSFSA、SRS、SNRS算法中,本研究所提出的算法在时间性能上排名第3. 这是由于算法在迭代时须重新计算鱼个体差异位置的特征重要度,时间复杂度较高. 虽然本研究算法在时间性能上表现一般,但是相比于其他算法,NRSFSA算法的特征归约能力较强,得到的脑功能连接特征子集的分类能力较好. 总体而言,NRSFSA算法在高维的fMRI脑功能连接数据中具有一定的应用价值.
表 3 8种算法在数据集上运行时间的比较
Tab.3
| 数据集 | 算法 | |||||||
| SRS | SNRS | mRMR | NRS | LLE | PCA | F-score | NRSFSA | |
| ADHD | 1605.45 | 2428.04 | 554.124 | 55.551 3 | 45.905 0 | 70.5156 | 31.9536 | 2834.76 |
| ABIDE | 2083.90 | 3180.85 | 571.607 | 60.0268 | 75.5599 | 142.769 0 | 43.7131 | 4814.16 |
| NC-AD | 2836.60 | 3190.06 | 669.555 | 177.550 0 | 95.3279 | 177.166 0 | 62.1608 | 4465.16 |
| NC-MCI | 3014.95 | 4081.99 | 586.957 | 162.096 0 | 82.5792 | 125.213 0 | 53.4089 | 5391.35 |
| AD-MCI | 4006.34 | 4785.98 | 610.880 | 198.639 0 | 93.1654 | 194.548 0 | 73.9587 | 11228.40 |
| 平均值 | 2709.45 | 3533.38 | 598.625 | 130.773 0 | 78.5075 | 142.042 0 | 53.0390 | 5746.77 |
3.4.3. 生物信息
为了探讨NRSFSA算法得到的脑功能连接特征代表的生物意义,首先将其放回原始的功能连接矩阵中,得到已选特征的脑功能连接矩阵;通过对照ALL模板,发现NRSFSA算法获得的脑功能连接特征所涉及的脑区包括后扣带回、背外侧前额叶、角回和海马等. 在大脑的神经活动中,后扣带回是记忆系统的重要组成部分,参与情景记忆的信息加工过程. 位于顶下小叶的角回属于视野语言中枢,具有理解看到的符号和文字的作用. 海马位于大脑丘脑和内侧颞叶之间,属于边缘系统的一部分,主要负责长时记忆和空间定位等功能. 这些脑区均属于大脑默认网络(default mode network, DMN),目前已有研究发现在阿尔兹海默症、注意力缺陷多动症、自闭症等患者的大脑中均存在DMN的异常活动[26-27]. 由上可知,NRSFSA算法可以有效降低脑功能连接数据的维度,获得带有判别信息的脑功能连接特征.
4. 结 语
利用邻域粗糙集的特征归约能力与鱼群算法的全局寻优能力,提出新的脑功能连接特征归约方法NRSFSA. 该方法基于邻域粗糙集的依赖度评价脑功能连接特征子集和标签的相关性,并使用鱼群的觅食、聚集、追尾、交叉和迁徙机制来不断搜索较好的特征子集.在3种脑疾病fMRI数据上的实验表明,所提方法不仅能降低脑功能连接的特征维度,而且能获得分类判别能力较强的脑功能连接特征.该方法的研究,不仅拓展了鱼群算法和邻域粗糙集理论的应用领域,而且对其他高维数据的分析与研究也有一定的借鉴意义.
本研究是邻域粗糙集在脑功能连接特征归约上的新探索.由于脑功能连接数据特征维度较高,又采用种群迭代的方式搜索候选特征子集,新算法的效率不高.如何基于邻域粗糙集定义更好的适应度函数,并融合更多的生物信息来提高鱼群算法搜索特征子集的效率,进而提高脑功能连接特征的分类判别能力是未来工作的主要方向.
参考文献
发展认知神经科学: 人脑毕生发展的功能连接组学时代
[J].DOI:10.1360/N972015-01146 [本文引用: 1]
Developmental cognitive neuroscience: functional connectomics agenda for human brain lifespan development
[J].DOI:10.1360/N972015-01146 [本文引用: 1]
Abnormal regional homogeneity as a potential imaging biomarker for adolescent-onset schizophrenia: aresting-state fMRI study and support vector machine analysis
[J].DOI:10.1016/j.schres.2017.05.038 [本文引用: 1]
Computational approaches to fMRI analysis
[J].
Network neuroscience
[J].
Multivariate classification of major depressive disorder using the effective connectivity and functional connectivity
[J].DOI:10.3389/fnins.2018.00038 [本文引用: 1]
Machine learning classification to identify the stage of brain-computer interface therapy for stroke rehabilitation using functional connectivity
[J].DOI:10.3389/fnins.2018.00353 [本文引用: 1]
Discriminative analysis of resting-state functional connectivity patterns of schizophrenia using low dimensional embedding of fMRI
[J].DOI:10.1016/j.neuroimage.2009.11.011 [本文引用: 1]
Autism: reduced connectivity between cortical areas involved in face expression, theory of mind, and the sense of self
[J].DOI:10.1093/brain/awv051 [本文引用: 1]
Classification of autism spectrum disorder by combining brain connectivity and deep neural network classifier
[J].DOI:10.1016/j.neucom.2018.04.080 [本文引用: 1]
Rough sets
[J].DOI:10.1007/BF01001956 [本文引用: 1]
基于粗糙集的漏洞属性约简及严重性评估
[J].
Vulnerability attribute reduction and severity evaluation based on rough set
[J].
A swarm-based rough set approach for fMRI data analysis
[J].
基于随机抽样的模糊粗糙约简
[J].
Fuzzy rough reduction based on random sampling
[J].
决策粗糙集理论研究现状与展望
[J].
Current situation and prospect of decision rough set theory
[J].
Numerical attribute reduction based on neighborhood granulation and rough approximation
[J].DOI:10.3724/SP.J.1001.2008.00640 [本文引用: 1]
Gene selection using rough set based on neighborhood for the analysis of plant stress response
[J].DOI:10.1016/j.asoc.2014.09.013 [本文引用: 2]
High precision image segmentation algorithm using SLIC and neighborhood rough set
[J].
Neighborhood classifiers
[J].DOI:10.1016/j.eswa.2006.10.043 [本文引用: 2]
一种基于动物自治体的寻优模式: 鱼群算法
[J].
A fish swarm algorithm based on animal autonomy
[J].
A novel fuzzy time series forecasting method based on the improved artificial fish swarm optimization algorithm
[J].
Selective ensemble based on extreme learning machine and improved discrete artificial fish swarm algorithm for haze forecast
[J].DOI:10.1007/s10489-017-1027-8 [本文引用: 1]
Discriminating bipolar disorder from major depression using whole-brain functional connectivity: a feature selection analysis with SVM-FoBa algorithm
[J].DOI:10.1007/s11265-016-1159-9 [本文引用: 1]
Discriminating bipolar disorder from major depression based on SVM-FoBa: efficient feature selection with multimodal brain imaging data
[J].DOI:10.1109/TAMD.2015.2440298 [本文引用: 1]
The brain's default network: anatomy, function, and relevance to disease
[J].DOI:10.1196/annals.1440.011 [本文引用: 1]
Neural network topology in ADHD: evidence for maturational delay and default-mode network alterations
[J].DOI:10.1016/j.clinph.2017.09.004 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}