

在信息化系统中,访问控制根据预先定义好的访问控制策略,限定主体可以对资源执行何种操作[1],是保证主体能够对客体进行授权访问、保护客体免于遭受未授权访问的关键技术之一[2]. 随着云计算、大数据技术的发展,信息化系统中的实体数量呈现爆炸式增长,传统的面向封闭环境的访问控制模型如自主访问控制(discretionary access control,DAC)、强制访问控制(mandatory access control,MAC)、基于角色的访问控制(role-based access control,RBAC)等难以直接适用于新型计算环境. 基于属性的访问控制(attribute-based access control,ABAC)使用主体和客体的属性作为权限基本判决依据,可以实现多对多的访问控制,能够较好地将策略管理和权限判定分离,具有更高的灵活性,可以更好地支持大规模信息化系统的细粒度访问控制,环境属性的引入使得ABAC支持动态的访问控制[2-4]. 相较于RBAC,ABAC无须预先进行复杂的角色设计,可以有效避免RBAC中的角色爆炸(role explosion)问题[5]. 但是,由于ABAC的灵活性,在主客体数量、主客体属性数量较多的情况下,人工制定ABAC策略的难度较大,导致实际应用ABAC较困难[4]. 因此,研究自动化的ABAC策略集构建技术,对ABAC模型的推广应用意义巨大.
已有的构建ABAC策略集的方法主要分为自顶向下和自底向上2种[4]. 自顶向下方法的基本思想是结合安全需求,将业务拆解成一个个独立的功能单元,从功能单元细化到具体的访问,然后再从这些访问构造策略,通常的方法是召集专家人工分析,或利用自然语言处理技术从安全需求说明文档中分析得到ABAC策略集;自底向上的方法也被称为策略挖掘,基本思路是结合主客体属性数据,从主体权限关系中挖掘ABAC策略. 主体权限关系有2个来源,一是旧有的访问控制系统,二是访问日志. 相比较而言,旧有的访问控制系统中蕴含更完整的主体权限关系,更容易从中获得与原系统等价的策略集,但它仅仅蕴含纯粹的主体权限关系,反映的主体行为信息较为简单,一般只能从中挖掘静态策略,较难通过数据中的主体行为对策略进行优化;日志中蕴含的主体权限关系不完整,但记录了系统中主体的访问行为,蕴含着主体的行为模式[6],从中可以发现契合主体行为模式的策略,改进原有策略的错误配置[7-8].
基于日志的策略挖掘方法不仅能够构建策略集,还支持策略集的维护、审计和优化. 在将策略集用于策略构建、维护、审计、优化之前,须提高其易阅读性,挖掘得到富语义ABAC策略,使得安全管理员能准确理解其涵义,将其与具体业务关联起来.
因此本研究针对富语义ABAC策略挖掘问题,提出策略语义质量度量标准,并基于频繁模式挖掘算法和语义质量度量标准,实现基于日志的富语义ABAC策略挖掘(log-based rich-semantic ABAC policy mining,LRSAPM)算法,从访问日志和属性数据中挖掘富语义策略,使得所得策略集易于被安全管理员理解,为策略构建、维护和优化提供有力支撑.
1. 相关工作
作为应用ABAC的首要难题,ABAC策略集的构建备受研究者关注. 自顶向下方法从顶层安全需求出发,通过分解业务为独立的功能、对应到访问从而构造策略,通常须召集权威专家团队进行分析,费时费力且难以保证策略集的完备性. 为了自动化该过程,降低人力依赖,Narouei等[9]提出自顶向下的ABAC策略工程框架,利用深度递归神经网络从受限的自然语言文档中自动化地构建ABAC策略集,但这种方法需要有足够的、可靠的安全需求说明文档,制定这些文档同样须耗费大量人力.
Xu等[13]提出基于访问日志和属性数据的ABAC策略挖掘方法,该方法将访问日志转换成用户权限关系,运用贪心算法,在用户权限关系包含的<用户、动作、资源>元组集合中进行迭代,选择一条元组作为种子,根据其属性组合构建规则;删去属性约束、或以用户资源属性之间的约束替换对应2个属性的约束对策略进行泛化,直至其无法覆盖更多元组;选择未被覆盖的元组进入下一次迭代,直至覆盖用户权限关系中的所有元组;通过合并和简化操作对策略进行优化. 在日志包含足够用户权限关系的情况下,通过该方法可以得到与原有系统的授权管理系统等价的策略集. 该方法对于稀疏日志表现不佳;该方法仅仅利用了日志中蕴含的主体权限关系,未对日志信息充分利用;所定义的授权规则支持主体属性与客体属性之间的约束,具备更强的表达力,但所得策略易读性不高.
Mocanu等[14]提出基于神经网络的ABAC策略挖掘方法,将属性数据代入访问日志,转换为二进制向量,作为受限波兹曼机的输入来训练模型,计算所有日志条目在所得模型中的重构误差,取最大值作为阈值;生成所有可能的规则组合,计算其在所得模型中的重构误差,将重构误差小于阈值的规则添加到候选规则. 通过该方法可以发现数据的隐式分布,该方法抗噪声能力较强,但缺乏对规则集的进一步分析与优化,规则集整体质量较差.
Cotrini等[15]提出基于APRIORI算法的ABAC策略挖掘方法,将属性数据代入访问日志,挖掘具有频繁共现属性表达式的组合作为候选规则,提出T可靠度来评价规则,对规则进行筛选合并,使得规则在具备较强泛化能力的同时,保持较低的过度授权的风险,得到具有较高正确率、较好泛化性能的规则集. 但是,该算法支持的规则表达较为简单,只有单个属性的约束,不支持主客体属性之间的约束,因此实际挖掘的规则表达能力较差,该算法仅仅根据T可靠度和规则长度进行策略筛选,未考虑策略的易读性.
为了挖掘同时支持允许和禁止的访问控制策略,Iyer等[16]提出启发式方法,每次从日志中挑选被允许概率最高的属性值约束或属性对约束,作为策略的一个表达式;重复上述过程,直至策略只覆盖允许项,或剩余的拒绝项能被一条拒绝策略覆盖;然后进入下一次迭代,重新选取属性构造策略;最后对拒绝策略进行泛化与合并,得到较高质量的策略集. 该方法仍未能有效利用日志中蕴含的行为信息,且挖掘出来的策略易读性差.
为了挖掘支持环境属性的策略,Das等[17]提出基于基尼不纯度的策略挖掘方法,利用构建决策树的方法进行策略构建,该方法仍然没有充分利用日志的信息,未考虑策略的易读性.
针对以上方法对日志信息利用不够、所得策略表达力不强、不易于人工阅读等问题,本研究提出策略语义质量度量标准,并以此为指导,实现基于频繁模式挖掘技术的ABAC策略挖掘算法,从访问日志中挖掘强表达力、契合主体行为模式、易于人工阅读的ABAC策略.
2. ABAC策略挖掘问题描述
2.1. ABAC策略语言
定义1 ABAC策略. ABAC策略
对于
授权规则
式中:
式中:
式(5)对文献[13]的策略语言进行了简化,
以大学场景为例,学生的试卷,只有相应科目的老师或助教可以批阅,写成规则即为
在访问控制系统中,基本权限以
2.2. 基于日志的ABAC策略挖掘问题
访问日志条目形如
定义2 基于日志的ABAC策略挖掘. 给定访问日志集
3. 基于日志的富语义ABAC策略挖掘算法
图 1
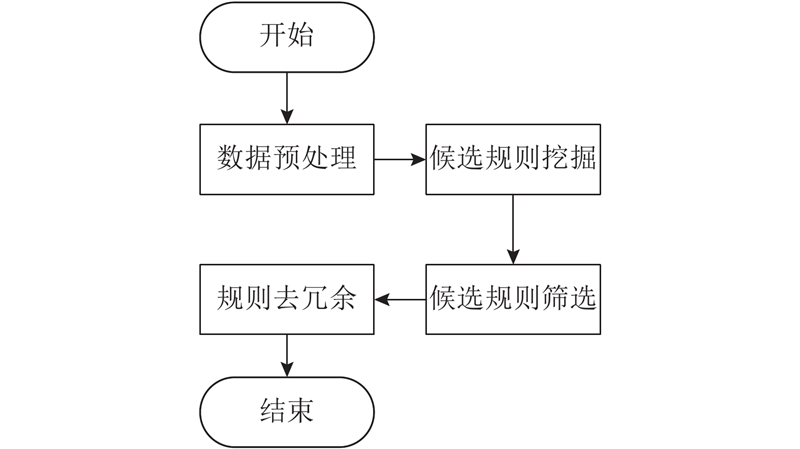
在得到候选规则之后,须进行2步操作:1)依据规则准确度质量度量标准进行候选规则筛选,剔除掉准确度低、过度授权的规则;2)根据规则语义质量度量标准进行规则去冗余,将冗余规则进行化简合并得到最终的规则集.
3.1. 规则准确度质量度量标准
定义3 规则的改进. 对于规则
定义4 规则的置信度. 表达式如下:
式中:
定义5 过度授权. 如果某条规则存在一条置信度较低的改进,那么这条规则就是过度授权的.
定义6 规则的
式中:
为了在挖掘时保留主体访问行为特征,对定义6进行修改,在进行置信度计算时,直接在日志中进行计算,而不是在主体权限关系中计算,记访问日志集
定义7 基于日志的规则的T可靠度. 表达式如下:
其中,
在进行频繁模式挖掘时,能够给予频繁的访问更大的权重,从而保证所得策略尽可能地覆盖常用访问.
3.2. 规则语义质量度量标准
日志记录着主体的访问行为,基于日志挖掘的ABAC策略,可以为管理员进行策略制定、维护、审计和优化提供参考,前提是这些规则容易被管理员理解,但目前已有的方法挖掘得到的授权规则都仅考虑规则的准确性,所挖规则都以简短为先,省略了较多有用信息,不易于人工阅读理解.比如在大学场景中,所教课程是教师独有的属性,学生没有,但是两者都有类型这个属性(教师的类型为教师,学生的类型为学生),在已有的方法中,为了降低策略复杂度,在规则使用所教课程构建属性约束时,会删去类型这个属性,在人工阅读时须知道“所教课程是教师独有的属性”这个先验知识,否则就会产生困惑. 因此,本研究针对规则的易阅读性展开研究,提出规则语义质量度量标准,以获得易于人工理解、能够高效地用于策略创建、维护、审计和优化的规则集.
规则由属性约束组成,因此规则的语义信息由各属性约束的语义信息综合而成. 属性的语义质量分为2个方面,一是属性能够描述的实体数量,二是属性值的分布. 一般来说,属性能够描述的实体越多,选用该属性制定策略时就能区别出更多的实体,更具有普适性. 如在上述大学场景中,类型相比所教课程覆盖更多的实体,因此将该属性引入授权规则可以帮助管理员更快确定实体的一般性质. 属性值的分布也影响属性的语义,如属性只有一个值,对于管理员理解策略帮助就较小.
信息熵在信息学中被用来衡量变量所具有的信息量,引入信息熵来度量属性的语义质量. 为了统一属性两方面的语义质量,将不具备某属性的实体的属性值标记为UNK,给出定义8.
定义8 属性语义质量度量. 表达式如下:
式中:
属性约束的语义信息也分为2个方面,一方面是所使用属性的语义信息,一方面是约束的语义信息. 主客体属性之间的约束的语义信息比单个属性的约束的语义信息丰富,虽然单个属性能够帮助管理员对实体进行精准定位,但属性之间的关系可以反映主客体之间存在的关系,帮助管理员理解主客体权限关系,因此在计算授权规则的语义质量时应给予更高的权重.
定义9 授权规则语义质量度量. 表达式如下:
式中:w1、w2、w3为权重,Attrs (·) 为用到的属性.
4. LRSAPM算法实现
4.1. 候选规则挖掘
候选规则挖掘算法如下所示.
算法1 候选规则挖掘
输入:L,AAR,ACT,T
输出:candi_rules
1 permited_L=get_permited_log (L)
2 ACT=get_acts(permited_L)
3 attr_exps=calc_attr_exps(AAR,ACT)
4 input_X=to_bool_matrix(L,AAR,attr_exps)
5 freq_itemsets=FPGrowth(input_X,T)
6 candi_rules=to_rules(freq_itemsets,attr_exps)
7 return candi_rules
该算法以访问日志集
4.2. 候选规则筛选
候选规则筛选算法如下所示.
算法2 候选规则筛选
输入:candi_rules,K
输出:filtered_rules
1 candi_rules=sort_by_length(candi_rules)
2 filtered_rules=[]
3 while len(candi_rules)>0:
4 rule=candi_rules.pop()
5 if calc_conf(rule)
6 filtered_rules.append(rule)
7 else:
8 del_refined(rule,candi_rules)
9 return filtered_rules
该算法以候选规则集candi_rules和最小
4.3. 候选规则化简
候选规则化简算法如下所示.
算法3 候选规则化简
输入:filtered_rules
输出:rules
1 bad_rules=[]
2 for rule1,rule2 in filtered_rules×filtered_rules:
3 if rule1 equals rule2:
4 continue
5 if better_than(rule1,rule2):
6 bad_rules.append(rule2)
7 filtered_rules.delete(bad_rules)
8 rules=get_minimum(filtered_rules)
该算法以筛选后的规则集filtered_rules为输入,输出最终的规则集rules.将filtered_rules中的规则两两比较,并删去质量较差的规则,better_than函数用于比较2个规则的质量,对于覆盖相同主体权限关系的规则,根据式(6)、(7)计算语义质量,保留语义质量较高的;对于权限关系有真包含关系的,保留覆盖较大权限关系的规则. 最后通过get_minimum函数获取与经过第2~7行筛选过的filtered_rules等价的最小规则集. 该函数从规则集中选择覆盖主体权限关系最多的规则加入新规则集,在原规则集覆盖的主体权限关系集中删去对应主体权限关系,循环往复,直至原规则集中所有的主体权限关系都转移到新规则集下.
5. 实验验证
5.1. 实验环境与数据集
实验环境如下:Intel Core i7-8750H CPU,16 GB内存,Ubuntu 18.04操作系统;基于Python3.7进行开发,开发平台为PyCharm,实现了基于日志的富语义ABAC策略挖掘算法;修改了Cotrini等[15]提出的Rhapsody算法以运行本研究的测试样例.
如表1所示为数据集的基本信息,AmazonEmployee数据集中的主客体数量较多,但日志条目较少,日志集较稀疏,且客体属性只有一个;HealthCare数据集主客体属性数量较多,日志条目相比于主客体数量而言较多.
表 1 AmazonEmployee和HealthCare的数据集信息
Tab.1
| 数据集信息 | 日志条目数量 | 主体数量 | 主体属性数量 | 客体数量 | 客体属性数量 |
| Amazon-Employee | 32769 | 4244 | 8 | 7519 | 1 |
| HealthCare | 2724 | 21 | 6 | 18 | 7 |
5.2. 实验方法与结果
采用交叉验证的方法与文献[15]中的Rhapsody算法在真阳性率(true positive rate,TPR)、假阳性率(false positive rate,FPR)、精确率(precision)、召回率(recall)和F1得分方面进行对比.
挖掘到的策略集在数据集上的预测结果可以分为4类:1)真阳性项:应该被允许,所得策略允许;2)假阳性项:应该被禁止,所得策略允许;3)真阴性项:应该被禁止,所得策略禁止;4)假阴性项:应该被允许,所得策略禁止.
TPR、FPR、Precision、Recall和F1-socre的表达式如下:
式中:策略集在数据集上的真阳性项、假阳性项、真阴性项、假阴性项数目分别为
首先,须选择算法的计算
图 2
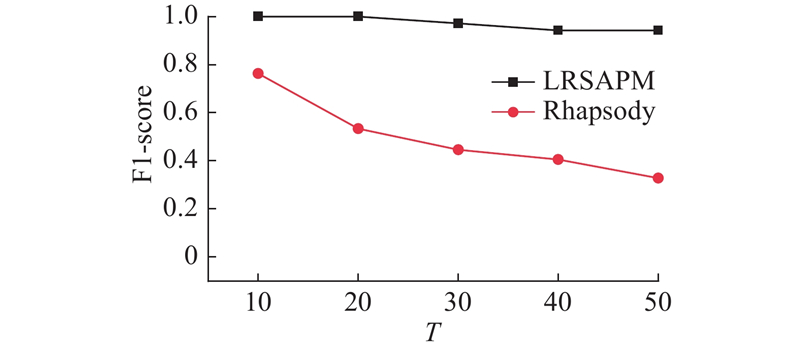
图 2 参数T对2种算法F1得分的影响
Fig.2 Influence of parameter T on F1-score of two algorithms
图 3
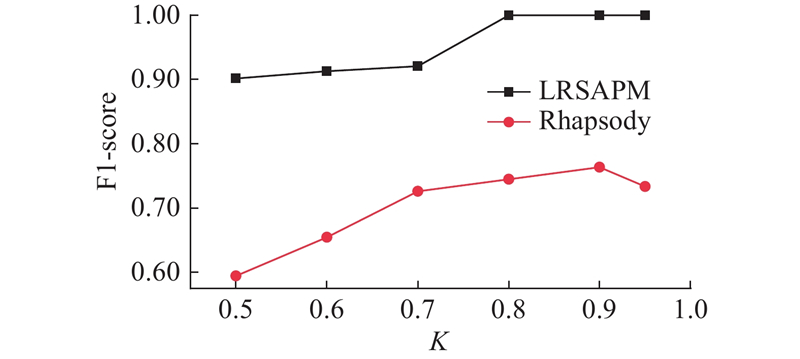
图 3
参数
Fig.3
Influence of parameter
如图4~7所示为2种算法在HealthCare数据集上的TPR/Recall、FPR、Precision和F1-score随训练集所占比例增大的变化情况. 图中,tr为训练集比例. 可以看出,在HealthCare数据集上,随着训练集的增大,2种算法整体趋势均逐渐变好,但Rhapsody算法在FPR和Precision这2个指标上呈现出较大的波动. 相对而言,LRSAPM算法具有更高的TPR/Recall、Precision、F1-score和更低的FPR,且各项指标随着训练集增大具有更规律的变化趋势,即使在训练集较小的情况下,LRSAPM算法也能取得较好的结果. LRSAPM算法在各项指标上具有显著的优势,主要是由于LRSAPM算法在支持Rhapsody算法定义的约束之外,额外支持主客体属性之间的约束,表达能力更强,更加贴合实际的访问控制需求.
图 4
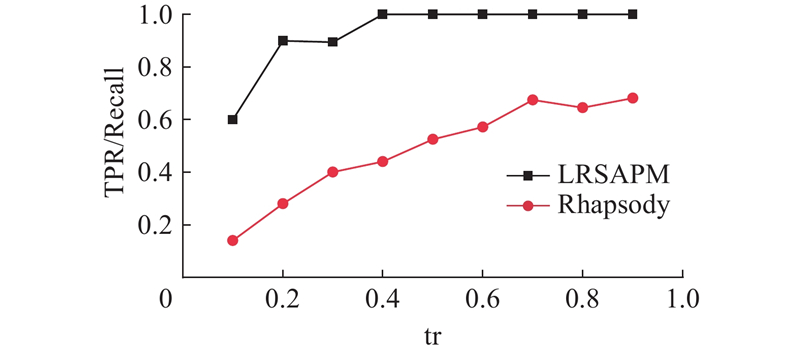
图 4 训练集比例对2种算法TPR/Recall的影响
Fig.4 Influence of train set ratio on TPR/Recall of two algorithms
图 5

图 5 训练集比例对2种算法FPR的影响
Fig.5 Influence of train set ratio on FPR of two algorithms
图 6
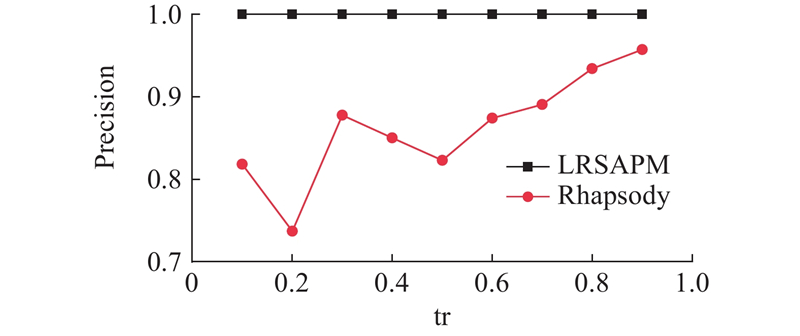
图 6 训练集比例对2种算法Precision的影响
Fig.6 Influence of train set ratio on Precision of two algorithms
图 7
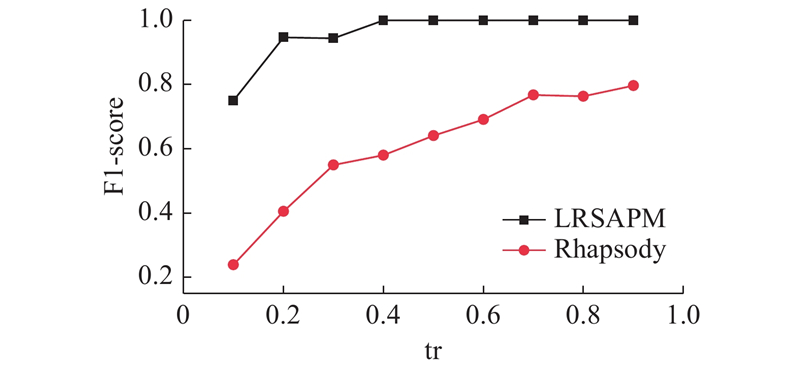
图 7 训练集比例对2种算法F1得分的影响
Fig.7 Influence of train set ratio on F1-score of two algorithms
AmazonEmployee数据集数据量较大,文献[15]在其上进行实验时仅挖掘单个客体的访问控制策略,本实验为验证算法对于较大规模稀疏日志的实际支持度,直接挖掘整个数据集. 当取较小的
采用80%训练集、20%验证集,3次拆分数据集并运行挖掘算法,各指标分别取平均值,如表2所示. 在AmazonEmployee数据集上参数
表 2 2种算法在2个数据集上的F1得分对比
Tab.2
| 数据集 | 算法 | TPR/Recall | FPR | Precision | F1-score |
| Amazon-Employee | LRSAPM | 0.9522 | 0.6200 | 0.7475 | 0.8375 |
| Rhapsody | 0.9906 | 0.0018 | 0.0114 | 0.0226 | |
| Health-Care | LPSAPM | 1 | 0 | 0.8858 | 0.9394 |
| Rhapsody | 0.9092 | 0.0186 | 0.6892 | 0.7833 |
5.3. 策略语义质量分析
为了验证所挖掘策略在语义质量的提升,将挖掘Healthcare数据集得到的策略与原策略进行对比. Rhapsody由于支持的授权规则较简单,所得的授权规则数量较多,且不便于阅读. LRSAPM算法获得的结果基本与原数据集的手写授权规则一一对应,在语义质量上相比原规则更高,比如原规则集中的规则
由于只有医生具有teams属性,原规则省略了position属性的限定,造成阅读不便. 本研究得到的对应规则为
Rhapsody由于不支持主客体属性之间的约束,所得规则数量较多,可读性差,而且可能无法覆盖该规则覆盖的所有访问. 相比较而言,LRSAPM算法挖掘到的规则集语义质量比Rhapsody更高,接近人工制定的规则集,且在易读性上有提升.
6. 结 语
提出基于日志的富语义ABAC策略挖掘算法,从访问日志和属性数据中挖掘高准确度质量、高语义质量的ABAC策略. 实验证明所提算法相对于已有算法,在TPR、Precision、Accuracy和F1-score等标准上有较大的提升,而且可以更好地支持小训练集;挖掘得到的授权规则与人工制定的规则较为接近,且具备更丰富的语义信息,更易被安全管理员理解,更容易应用于实际的访问控制策略制定与维护.
算法对于稀疏日志和低频访问的处理能力有待进一步提高;提出的策略语义质量标准对属性集质量要求较高. 下一步将研究大规模环境下属性集的预处理技术,研究属性集的去冗余、属性值的优化;研究策略的可视化技术,为安全管理员更加直观地展示策略与主客体的综合关系、策略与权限的对应关系,为ABAC策略集的维护提供进一步支撑.
参考文献
Access control: principle and practice
[J].DOI:10.1109/35.312842 [本文引用: 1]
基于属性的访问控制研究进展
[J].
Research progress on attribute-based access control
[J].
基于属性的访问控制关键技术研究综述
[J].DOI:10.11897/SP.J.1016.2017.01680
A survey of key technologies in attribute-based access control scheme
[J].DOI:10.11897/SP.J.1016.2017.01680
Detecting and resolving policy misconfigurations in access-control systems
[J].
Mining attribute-based access control policies
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}