

运动目标检测是计算机视觉领域的重要研究方向之一,在公共安全、道路交通、视频监控、军事侦察、精确制导等军用、民用领域均有着重要的作用[1-3]. 近年来,基于深度学习的目标检测算法取得了重大进展,在准确度和实时性方面不断改进,如Girshick等[4-5]提出的R-CNN和Fast R-CNN算法、Ren等[6]提出的Faster R-CNN算法、Redmon等[7]提出的YOLO算法以及Liu等[8]提出的多类别单阶检测器(single-shot-multibox-detector,SSD)算法. 然而,运动目标检测仍有许多问题亟待解决,如:目标遮挡问题、目标小尺度问题、目标重叠问题等[9-12].
小目标包含的像素少,特征提取困难,经过多次卷积操作以及池化操作后会丢失大量的特征信息,严重影响网络检测的精度. 针对复杂环境下的小目标检测问题,国内外学者作了大量研究. 朱明明等[13]通过特征融合和软判决非极大值抑制的方式加强了Faster-RCNN对小目标的检测性能,从而实现了对小目标的检测,但是该算法实时性较差. 辛鹏等[14]将浅层和深层的特征进行融合,解决了深层特征图对小目标表达不足的问题,但受限于两阶段网络的结构,该算法的实时性并不好. 朱敏超等[15]去掉了多类别单阶检测器(single-shot-multibox-detector,SSD)网络数据预处理层的随机剪裁步骤,并参考特征融合多类别单阶检测器(feature fusion single shot multibox detector,FSSD)算法将低层特征图和高层特征图进行融合,利用具有高分辨率的低层特征图对小目标进行预测,但是该模型引入了多层底层特征图,导致算法的实时性不高.
本文针对复杂环境(包括目标模糊、目标重叠、目标遮挡)下小目标检测精度较差的问题,提出一种改进的SSD算法,在满足实时性的前提下,提升算法对于小目标的检测精度,改进思路如下:1)增加Conv3-3层的特征图用于检测小目标,借鉴特征金字塔网络(feature pyramid networks,FPN)[16]算法,把Conv3-3层、Conv4-3层、Conv7层的不同像素特征采样到相同像素并进行特征融合,将融合特征图每个位置对应的默认框的数量设置为6个;2)在网络上增加裁剪-权重分配网络(squeeze-and-excitation Networks,SENet),提升有效的特征权重,抑制无效或效果小的特征权重,重新分配特征通道权重.
1. 多类别单阶检测器
1.1. 多类别单阶检测器算法网络结构
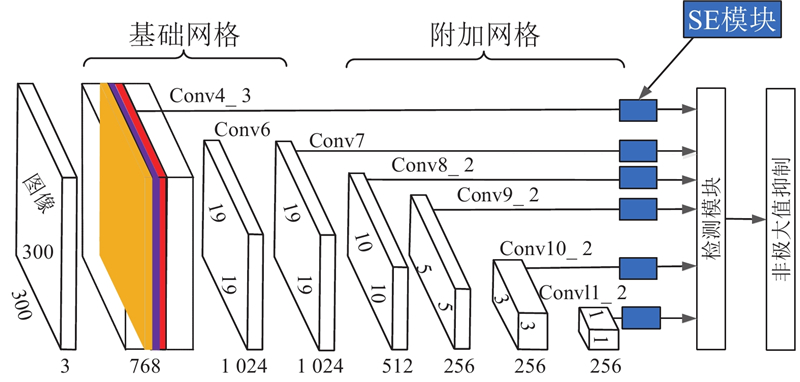
SSD是一种实时、高精度的目标检测算法,该算法最主要的特点是利用具有不同尺度的特征图进行目标的检测和识别,其网络结构如图1所示. 网络框架分为基础网络(base feature layers)和附加网络(extra feature layers)两部分[17]. 基础网络使用改进的VGG网络进行特征提取,附加网络新增了4层级联卷积层,网络的输入为3通道RGB图像,图像从左至右通过网络后会生成一系列特征图(feature map),特征图共有6层:Conv4-3、Conv7、Conv8-2、Conv9-2、Conv10-2、Conv11-2,尺寸分别为38×38、19×19、10×10、5×5、3×3、1×1,通道数分别为512、1024、512、256、256、256. 最后将每个特征图对应的检测结果进行综合,使用非极大值抑制(non-maximum suppression,NMS)算法得出最终检测结果.
图 1

图 1 多类别单阶检测器(SSD)网络模型示意图
Fig.1 Diagram of single-shot-multibox-detector(SSD)network model
图 2

图 2 SSD网络不同层的特征图输出比较
Fig.2 Comparison for feature map output of different layers in SSD network
对于神经网络来说,每层特征的不同通道包含的信息有所不同. 以Conv4-3层为例,该层特征共有512个通道,每个通道对于网络决策的重要程度有所差别. 如图3所示为Conv4-3层不同通道特征的热力图,不同颜色代表原图中像素信息对于网络决策的不同重要程度,暖色像素对网络决策更为重要. Conv4-3_80表示Conv4-3卷积层输出的第80个通道的特征图,其他同理. 由图3可知,Conv4-3层第120通道的特征图已经丢失了小目标的信息,而Conv4-3层第80通道的特征图包含的信息比较丰富,检测到了小目标. 可见,Conv4-3层不同通道的特征图对网络决策的影响不同,因此可以通过增强有效通道的特征、抑制无效通道的特征来增强SSD算法对小目标的检测效果.
图 3

图 3 SSD网络不同通道的特征热力图
Fig.3 Characteristic thermal maps of different channels in SSD network
1.2. 损失函数
SSD损失函数分为2个部分:位置损失(
式中:
式中:
置信损失函数的定义为
式中:
2. 改进的多类别单阶检测器网络
2.1. 特征融合
通过上述分析可知,浅层卷积层中的小目标即使经过少许的卷积和池化操作,也会丢失掉大量的特征信息,以致于影响识别效果,降低检测精度. 本研究通过将浅层特征与深层特征进行融合来增加小目标检测的精度,但是浅层特征图尺寸较大,过多的引入浅层特征会对算法的实时性造成较大影响. 综合考虑实时性与精度,对网络结构进行如下改进,如图4所示. 将Conv3-3层的特征图下采样到38×38的大小,特征图通道数不变;将Conv4-3层的特征图通道数由512个降至256个,特征图大小不变;将Conv7层的特征图上采样到38×38的大小,并将特征通道数由1 024个降至256个;将Conv3-3层、Conv4-3层、Conv7层的特征图进行拼接,拼接后特征图的通道数为768个;并把特征图每个位置对应的默认框数量由4个变为6个.
图 4
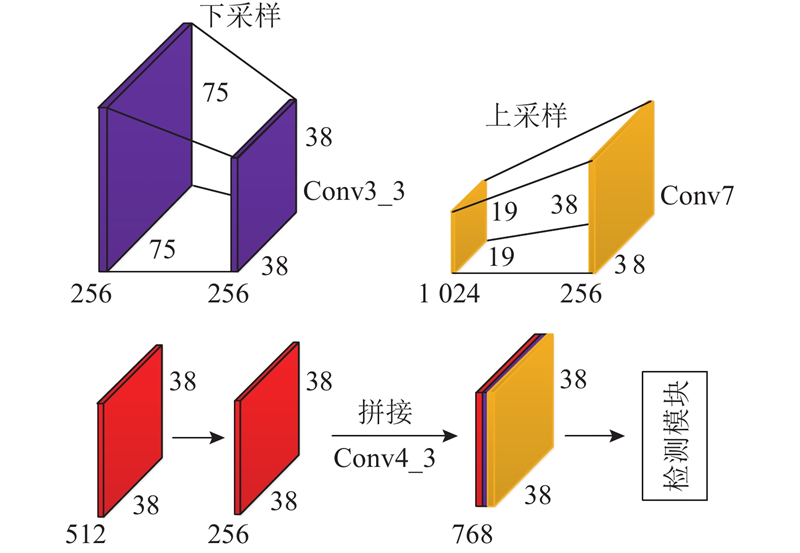
Conv3-3层位于网络的浅层,特征图尺寸较大,拥有较多的表观特征信息,在融合之前需要通过下采样减小特征图的尺寸. 为了不损失特征图的信息,扩大特征图的感受野,采用步长为2的空洞卷积对特征图进行下采样. 空洞卷积[20]的输入与输出特征图的大小关系为
式中:p为填充像素的大小,
Conv4-3层和Conv7层的特征通道数较多,为了减少网络的训练参数量,增加算法的实时性,在将特征拼接起来之前,需要先对其进行降维处理. 对Conv7层进行降维处理后,对降维后特征进行上采样操作. 常用的上采样操作有2种,分别为反卷积[21]和双线性插值,由于反卷积在网络中引入了新的训练参数,会对算法的实时性造成影响,本研究选用运行速度快且操作简单的双线性插值法完成上采样操作.
2.2. 特征通道权重再分配
SENet[22]是由胡杰团队提出的新的网络结构,该团队利用SENet取得了最后一届ImageNet2017竞赛Image Classification任务的冠军. SE模块通过学习的方式自动获取每个特征通道的重要程度,根据重要程度提升有用的特征并抑制对当前任务用处不大的特征,使得有效的特征图权重大,无效或效果小的特征图权重小,使网络达到更好的复杂背景下的小目标检测结果. SE模块的示意图如图5所示. 图中,
图 5
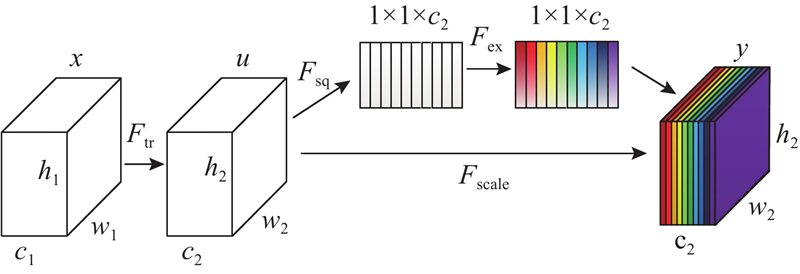
图 5 SE网络结构示意图
Fig.5 Diagram of squeeze-and-excitation network(SENet) structure
式中:
完成压缩操作后进行激活(excitation)操作,为每个通道生成权重,激活操作可表示为
式中:
式中:
由于SE模块本身增加的参数主要来自2个全连接层,对算法的实时性影响较小,本研究在Conv4-3层、Conv7层、Conv8-2层、Conv9-2层、Conv10-2层、Conv11-2层后面分别加入SENet,改进后的网络结构如图6所示. 其中,右边、中间、左边部分分别代表Conv7层、Conv3-3层、Conv4-3层的融合特征,箭头标注部分为SENet.
图 6
3. 实验结果与分析
3.1. 实验平台与数据
本文测试平台配置如下:Intel(R)Core(TM)i7-7700@3.60 GHz,16 G内存,Ubuntu16.04操作系统,显卡型号为GTX1080Ti. 程序运行环境如下:Python版本为3.6,torch版本为0.3.1,CUDA版本为9.0. 选用数据集为VOC以及COCO.
为了提高模型的泛化能力,避免过拟合,在数据量有限的情况下,对原始数据依次采取如下几种数据增强方法,对数据进行扩增,以增加训练样本的多样性. 1)旋转:将图像按顺时针或逆时针方向随机旋转一定角度;2)缩放:将图像随机缩小或放大一定比例;3)随机裁剪:从图像中随机裁剪一定大小的区域;4)色彩变换:将图像变为HSV颜色空间,并对图像的饱和度(S)、明度(V)和色调(H)进行微调;5)加噪声:在图像中随机加入高斯噪声和椒盐噪声.
3.2. 实验结果分析
采用P-R曲线和平均精度均值(mean average precision, mAP)对模型的性能进行测评,P-R曲线是以准确率(precision)为纵轴、召回率(recall)为横轴的二维曲线.
准确率Rpre的定义如下:实际是正类且被预测为正类的样本占所有预测为正类样本的比例. Rpre更关注将负样本错分为正样本的情况:
式中:TP(true positives)指原本为正类且被划分为正类的样本;FP(false positives)指原本为负类但被划分为正类的样本.
召回率Rre的定义如下:实际是正类且被预测为正类的样本占所有实际为正类样本的比例. Rre更关注将正样本分类为负样本的情况:
式中:FN(false negative)指原本为正类但被划分为负类的样本. P-R曲线下的阴影面积为平均精度(average precision,AP)值,记为
如图7所示为不同算法在实验平台以及VOC数据集(右)和COCO数据集(左)的P-R曲线图. 其中,SSD代表改进前的SSD算法,F_SSD代表加入特征融合的SSD算法,F_SE_SSD代表加入特征融合以及SE模块的SSD算法,即提出的算法. F_SE_SSD在VOC数据集上对“bottle”类别的检测效果改善较大,当Rre=0.5时,F_SE_SSD算法的Rpre=0.79,SSD算法的Rpre=0.64,改进后算法的Rpre提高了15%. 对于“car”、“person”和“bird”类别,3种算法的P-R曲线差别较小,F_SE_SSD的性能仍然最好.
图 7
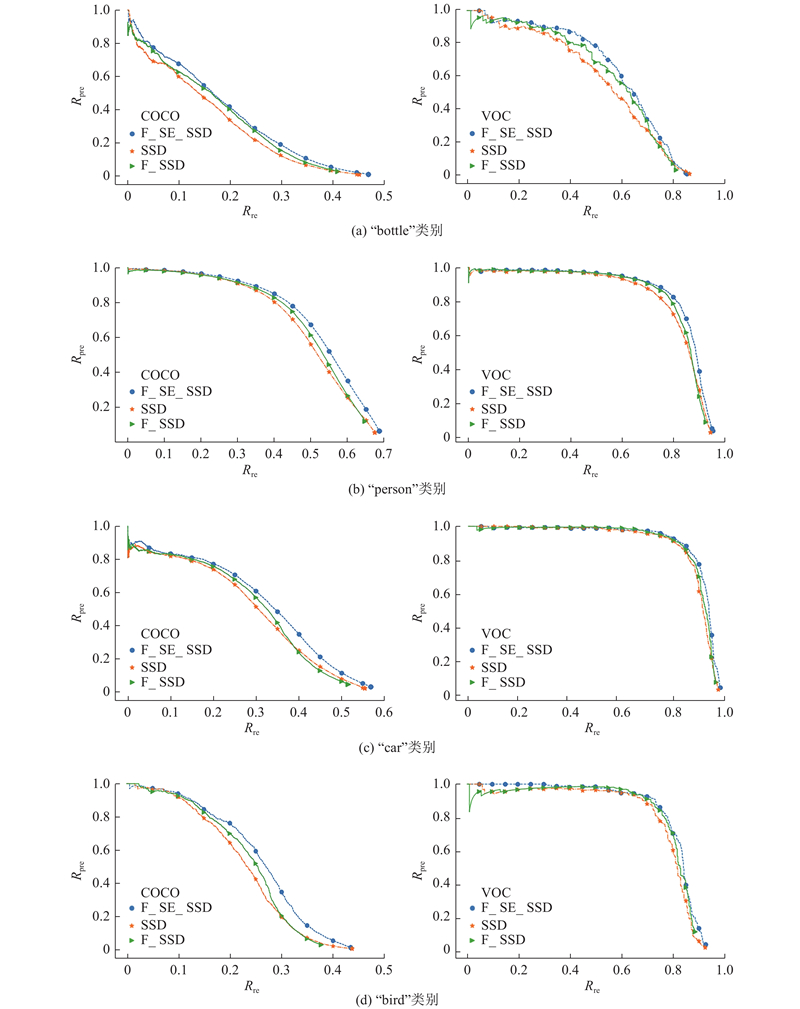
图 7 3种算法在不同数据集、不同类别上(瓶子、人、汽车、鸟)的准确率-召回率曲线对比
Fig.7 Comparison of precision-recall curves of three algorithms on different datasets and different categories (bottle, person, car, bird)
与VOC数据集相比,COCO数据集包含了自然图片以及生活中常见的目标图片,背景比较复杂,目标数量多、尺寸小,因此模型在COCO数据集上的检测精度较低;但总体来看,相比其他算法,F_SE_SSD在COCO数据集上的检测效果依然最好,以COCO数据集上的“bottle”、“person”、“car”、“bird”类别为例,如图7所示,改进后算法在上述类别下的P-R曲线包络面积更大,检测效果更好,当Rre=0.3时,F_SE_SSD对“bird”类别的Rpre=0.37,较SSD算法(Rpre=0.2)提高了17%.
对于多分类问题,将所有类别的AP值作平均值,即可得到mAP. 改进后算法在VOC数据集上对于“bottle”类别的AP值为58.9%,相比改进前算法增加了4.8%;对于“person”类别的AP值为81.7%,相比改进前算法增加了2.7%;在“car”类别上的AP值为87.5%,相比改进前算法增加了1.7%;对于“bird”类别的AP值为79.1%,相比改进前算法增加了3.0%. 改进后算法在VOC数据集上的mAP=80.4%,较SSD算法(mAP=77.7%)提高了2.7%;在COCO数据集上的mAP=42.5%,较SSD算法(mAP=40.2%)提高了2.3%. 本文所提改进算法在实验平台上的处理速度为65 帧/s,与SSD算法[23]相比降低了20帧/s.
相较于SSD算法,F_SE_SSD算法不仅可以准确检测到小目标,而且对遮挡目标的识别率也较高,如图8所示. 目标检测实验以车辆为例,参考COCO数据集的小目标定义,本研究将小目标定义为32×32及其以下像素块构成的目标. 在图8第一行的2幅图中,左图中目标大小为32×32像素,被部分遮挡,未遮挡像素占目标大小的65%,SSD算法漏检了该目标,而本文算法准确检测到了遮挡目标;由于右图中目标较小,像素数仅为16×14,SSD算法没有检测到该目标,而本文算法顺利检测到了目标. 在图8第二行的2幅图中,右图中2辆汽车发生重叠,目标被部分遮挡,未遮挡部分像素为23×31,占目标大小的64%,SSD算法将其误检为1辆,而本文算法没有误检,同时SSD算法漏检了2个大小分别为24×20、19×16像素的小目标,而本文算法将漏检目标精准地检测出来. 在图8第三行的2幅图中,对于密集的车流,本文算法的检测效果比SSD算法更好;右图中,SSD算法漏检了6个小目标,其中尺寸最大为25×20像素,最小为17×13像素,本文算法准确检测出了这6个小目标. 由此可见,改进后算法较SSD算法检测精度更高,对小目标、遮挡目标的检测效果更好.
图 8

图 8 F_SE_SSD与SSD算法在VOC数据集上的检测结果对比
Fig.8 Comparison of detection results of F_SE_SSD and SSD algorithm on VOC dataset
为了验证改进后算法在复杂背景下的检测效果,在目标模糊、目标重叠、目标遮挡情况下对算法进行验证,结果如图9所示,其中第一行为算法在目标模糊情况下对小目标的检测结果,第二行为算法在目标重叠情况下对小目标的检测结果,第三行为算法在目标遮挡情况下对小目标的检测结果. 结果显示,改进后算法具有较强的鲁棒性,能够适应复杂背景下的目标检测任务.
图 9

图 9 改进后算法(F_SE_SSD)在复杂背景下的检测效果
Fig.9 Performance of improved algorithm(F_SE_SSD)under complex background
为了对改进后算法的性能进行量化,选取OTB100数据集上的Car1、Car2、Car4、Car24视频进行测试;这些视频场景都是公路,主要目标为汽车,其中,Car1共1 019帧,Car2共913帧,Car4共659帧,Car24共3 059帧,视频中小目标以及遮挡目标较多. 如图10(a)所示,摄像头逐渐靠近目标车辆B,在第392帧时车辆B首次被检测到,此时车辆B的大小为15×15像素,图10(b)中车辆D首次被检测到时的大小为19×14像素. 在置信度阈值为0.5的情况下,统计视频Car1、Car2、Car4、Car24中所有小目标首次被检测到时的像素值,最终得到改进后算法能够检测的平均最小目标为16×16像素.
图 10

图 10 改进后算法(F_SE_SSD)检测小目标的效果
Fig.10 Performance of improved algorithm(F_SE_SSD)in detecting small targets
4. 结 语
本文针对复杂背景下的小目标检测问题,设计了一种基于SSD的改进算法:F_SE_SSD. 将算法在VOC和COCO数据集上进行测试,实验结果表明:改进后的方法检测效果得到了很大的改善,在VOC2007数据集上的mAP提高了2.7%;在COCO数据集上的mAP提高了2.3%,并且能够检测到遮挡、模糊、重叠情况下的小目标. 通过特征融合以及特征通道权重分配的方法,可以有效提高网络的检测准确精度.
参考文献
Object tracking: a survey
[J].
基于卷积神经网络的目标检测研究综述
[J].DOI:10.3969/j.issn.1001-3695.2017.10.001
Review of object detection based on convolutional neural networks
[J].DOI:10.3969/j.issn.1001-3695.2017.10.001
基于深度学习的目标检测算法综述
[J].DOI:10.3969/j.issn.1002-7300.2017.11.020 [本文引用: 1]
Review of object detection based on deep learning
[J].DOI:10.3969/j.issn.1002-7300.2017.11.020 [本文引用: 1]
Faster R-CNN: towards real-time object detection with region proposal networks
[J].
基于外观模型学习的视频目标跟踪方法综述
[J].DOI:10.7544/issn1000-1239.2015.20130995 [本文引用: 1]
Video object tracking based on appearance models learning
[J].DOI:10.7544/issn1000-1239.2015.20130995 [本文引用: 1]
基于视觉的目标检测与跟踪综述
[J].
Vision-based object detection and tracking: a review
[J].
视觉目标跟踪方法研究综述
[J].
Review of visual object tracking technology
[J].
目标检测算法研究综述
[J].DOI:10.3778/j.issn.1002-8331.1804-0167 [本文引用: 1]
Research overview of object detection methods
[J].DOI:10.3778/j.issn.1002-8331.1804-0167 [本文引用: 1]
基于特征融合与软判决的遥感图像飞机检测
[J].
Airplane detection based on feature fusion and soft decision in remote sensing images
[J].
全卷积网络多层特征融合的飞机快速检测
[J].
Fast airplane detection based on multi-layer feature fusion of fully convolutional networks
[J].
基于FD-SSD的遥感图像多目标检测方法
[J].DOI:10.3969/j.issn.1000-386x.2019.01.042 [本文引用: 1]
Remote sensing image multi-target detection method based on FD-SSD
[J].DOI:10.3969/j.issn.1000-386x.2019.01.042 [本文引用: 1]
多尺度卷积特征融合的SSD目标检测算法
[J].
SSD object detection algorithm with multi-scale convolution feature fusion
[J].
改进的SSD算法及其对遥感影像小目标检测性能的分析
[J].
Improved SSD algorithm and its performance analysis of small target detection in remote sensing images
[J].
构建带空洞卷积的深度神经网络重建高分辨率图像
[J].
Building deep neural networks with dilated convolutions to reconstruct high-resolution image
[J].
Fully convolutional networks for semantic segmentation
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}