

园区网是一个由有限的地理区域内互相连接的局域网所组成的网络和传媒体. 大学的校园网是一种非常典型的园区网[1]. 本研究以校园网为例,研究园区网风险账号的评估方法. 通常情况下,学校师生在利用校园网访问网络资源时,需要登录自己的入网账号. 然而,校园网的账号安全保护机制较为薄弱,存在初始密码简单、易被破解,登录过程未加密导致用户账号密码容易泄露等问题. 同时,校园网账号往往与流量、计费等系统挂钩,一旦账号密码泄露,用户的流量就会被盗用,造成经济损失. 因此,研究校园网风险账号评估方法、及时发现风险账号、减少账号被盗用给用户带来的损失具有现实意义.
现有的对于账号保护的研究主要基于二次验证、登录日志分析等. Wang等[2]提出了改进的双因素(two-factory)验证方法,但是现有的校园网内大多数账号的登录环节并没有配置双因素验证系统,用户的账号依然存在被盗用的风险. Mills等[3-5]通过登录日志频率、时间、登录结果等提取用户行为特征,从而判断用户账号是否具有风险,但是这些特征在校园网内不适用,比如:用户有可能使用自己的设备在其不常登录的时间段登录,传统算法会将其判断为风险账号,但实际上这种情况下用户的账号仍是低风险的. Freeman等[6]通过对用户的登录日志进行IP处理,分析国别、运营商等信息,检测登录地点差异过大的账号并将其视为风险账号. 但是这种方法在校园网内并不适用,由于校园网内登录的IP都是内网IP,IP地址范围有限,单纯通过互联网服务提供商(internet service provider,ISP)、IP国别等信息无法有效判断用户账号是否存在风险. 章思宇等[7-8]从统一身份认证系统的日志中提取了登录次数、用户代理信息、登录IP等特征对用户登录相关系统的账号进行风险评估. 然而,由于很多校园网的入网系统并没有接入统一身份认证,统一身份认证系统里缺失入网登录日志,无法用于有效地评估风险账号.
上述方法主要着眼于用户账号的登录阶段,利用登录阶段的日志信息对风险账号进行评估. 在校园网环境下,由于IP地址范围小、登录次数少等原因,上述方法提取的特征无法很好地刻画校园网账号的使用情况. 本研究根据校园网账号的使用特点,从用户设备的访问是否出现异常行为的角度出发,基于用户账号的URL访问日志,提取一段时间内的设备出现次数离散度、设备多账号风险度等访问行为特征,利用高斯混合模型对特征数据进行聚类,得出设备有异常访问行为的概率,并结合修正余弦相似度算法计算设备访问URL的相似度,综合高斯混合模型和修正余弦相似度算法的结果得出风险账号的评估结果.
1. 基于URL访问日志的风险账号评估方法
园区网的入网账号如果被盗用,就会在他人的设备上登录,本研究称这种设备为风险设备. 因此,对账号作出风险评估的关键在于找出风险设备. 下文将详细介绍定位风险设备的步骤,包括日志特征提取、特征向量聚类分析和同账号下同类设备URL的访问相似度计算.
1.1. 特征提取
以一段时间内设备访问的统一资源定位符(uniform resource locator,URL)为分析单位,从中提取出设备出现次数离散度
1.1.1. 设备出现次数离散度
当一个设备是风险设备时,该设备上登录的账号的URL访问日志通常会表现出如下特征:在一段时间内访问URL的数量突然增多,超出正常用户的平均水平. 如果将时间窗口扩大到7或10 d,可以发现风险设备的访问主要集中于某几个时间段,而在风险设备出现的前几天里,正常用户的设备在一段时间内访问URL的次数总体趋于稳定. 因此,可以通过计算设备出现的离散程度量化这种特征.
设备出现离散度
当设备访问规律时,设备出现次数的离散程度较小,即
1.1.2. 设备多账号风险度
通常情况下校园网用户的设备只会登录自己的账号,而盗号者的设备可能会登录多个账号(自己的以及被盗者的)以获取更多的流量. 本研究引入设备多账号风险度
当设备使用的账号数越多时,
1.1.3. 收费网络占比
校园网通常分为免费网络和收费网络. 其中免费网络只能访问特定的网站,而收费网络可以访问其他网站,但需要按访问流量计费. 调研发现,风险设备大概率访问的是收费网络,因此,普通用户账号被盗取后,收费流量占所有上网流量的比例将会升高. 本研究通过统计设备访问URL记录中收费网络的占比标识这种风险.
设该设备访问URL的总次数为
设备访问的收费网络次数越多,
1.1.4. 对立位置风险度
可以通过设备访问的IP地址获取用户的地理位置信息[9]. 分析用户设备的访问日志发现,风险设备会在与被盗账号常用IP地址所在地理位置不同的场所登录,本研究称之为对立位置. 比如:某用户经常在A楼登录使用其账号,而盗号者却在B楼登录了该账号,此时盗号者设备所在的位置为对立位置. 本研究认为设备出现在对立位置时具有风险性.
根据设备访问URL的IP地址可以得出用户访问的地理位置信息. 设该账号一段时间内出现过的地理位置列表为
对立位置风险度为
当访问URL时,处于对立位置的次数越多,风险越大.
1.2. 聚类分析
将上文得到的特征向量
本研究使用的聚类模型为高斯混合模型(Gaussian mixed model,GMM)[10],其对符合高斯分布的特征数据有较好的分类效果. 本研究中正常账号的的样本较多,风险账号的样本较少,根据中心极限定理,当实验数据足够多时,数据的随机性足够大,实验结果的二项分布收敛于正态分布,符合高斯混合模型的使用条件. 高斯混合模型聚类的结果是样本属于每个簇的概率,其定义为
式中:K为模型的个数(即簇的个数),本研究中K=2;
高斯混合模型聚类的过程是通过参数估计,推导出每一种混合成分的参数:均值向量
式中:m为输入的样本个数.
继而求出模型参数
1.3. 设备访问URL的相似度计算
通过分析被盗账号下所有设备的URL访问记录发现,账号被盗取前、后,URL访问喜好通常有较大的差异. 为了使账号的风险评估更加全面,引入设备访问URL的相似度计算. 若一段时间内某一个账号下同类设备(如:PC设备)的URL访问相似度很低,则说明偏离了用户平时的访问习惯,该账号下存在风险设备,账号风险度升高.
由于用户可能有多种设备,不同设备的访问习惯不同,分别统计不同类型设备的访问情况. 为了简化计算并提高算法的运行速度,本研究将用户的设备类型分为2类,包括PC设备与移动设备(非PC设备). 下面以PC设备为例对算法进行介绍.
设一个账号下的PC设备列表为
式中:
经过修正余弦相似度计算后得到一个
式中,
为了方便计算,当
根据聚类分析的结果可以得出设备有异常访问行为的概率,根据URL相似度计算结果可以得出设备与同类型其他设备访问URL的相似度,综合两者更好地对风险账号进行评估,至此可以得出园区网风险账号评估公式:
式中:
2. 实验与分析
2.1. 实验环境与数据
本实验所用的主机配置为Intel® Core™ i7-4790K CPU @ 4.00 GHz,16 GB内存的64位Windows10操作系统. 所使用的开发环境主要有Node.js v10.15.3 以及 Anaconda 4.6.14.
表 1 用户URL访问日志数据集的存储字段
Tab.1
| 字段 | 含义 |
| TIME | 访问时间 |
| LABEL | 访问标签 |
| MAC | 设备MAC地址 |
| URL | 访问URL地址 |
| DEVICE | 设备类型 |
| POS | 设备访问地理位置信息 |
| USER | 用户账号 |
| IP | 设备访问的IP地址 |
| SSID | 设备访问的服务集标识 |
本研究通过日志分析和前期调研发现4个真实被盗账号,并在其余时间段里发现6个真实被盗账号,通过脚本将这6个被盗账号的访问日志的日期映射到4月1日—10日;而后通过脚本随机混合不同账号的设备访问记录,生成10个风险账号样本,真实样本与模拟样本比例为1∶1.
综上,本研究共采集1 000个账号的访问日志数据,其中包括980个正常账号和20个风险账号,按7∶3将数据源分成训练集与测试集. 实验总共采集日志数据达5 414万条,大小为13.7 GB.
2.2. 实验结果与分析
从1 000个账号的访问日志中提取特征向量,构成98 475条输入样本,其中包括13 781条风险设备输入样本. 利用高斯混合模型对输入样本进行聚类,同时计算这些账号下的设备URL访问相似度. 将聚类的真实结果与实验结果通过二值分类表[19]进行展示,如表2所示. 其中,T/F表示分类结果是否正确,正确为T,错误为F;P/N表示实验结果是否有风险,P表示有风险,N表示无风险. 从中可得聚类分析后的准确度为86.2%. 利用聚类分析和设备访问URL相似度的结果,根据式(13)计算R值. 由训练集可得,当R的阈值为0.437时,能较好地区分风险账号和正常账号;阈值过大将导致检出率降低,过小将导致误报率升高. 测试时,对于每一个输入账号计算其R值,当
表 2 高斯混合模型(GMM)聚类结果
Tab.2
| 真实结果/聚类结果 | 有风险 | 无风险 |
| 有风险 | TP=11 737 | FN=2 044 |
| 无风险 | FP=11 573 | TN=73 121 |
从实验结果里随机抽取1 000条正常输入样本与1 000条风险输入样本,分别对样本中的设备出现次数离散度、设备多账号风险度、收费网络占比、对立位置风险度和设备访问URL相似度5个特征进行可视化分析,如图1所示. 其中,N为样本的编号,编号范围为1~1000. 正常设备的出现次数离散度大部分低于550,而风险设备大部分高于1 000,说明风险设备的出现次数更不规律.
图 1
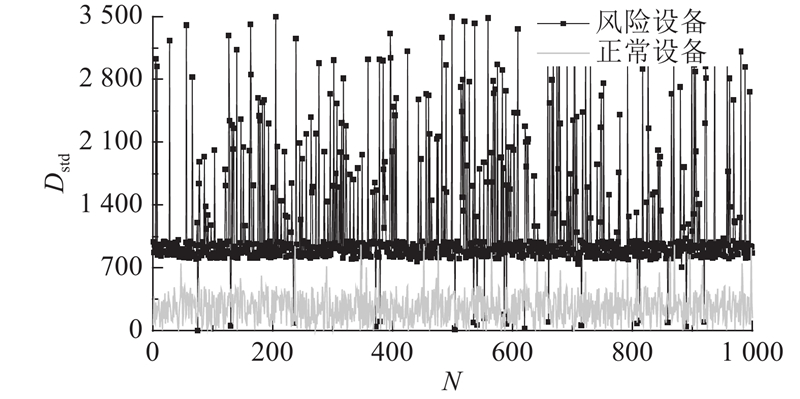
图 1 随机抽取的2 000个样本在设备出现次数离散度上的取值情况
Fig.1 Values of 2,000 samples randomly selected on dispersion of device occurrences
如图2所示,正常设备的多账号风险度大部分为0,而风险设备多数大于0.3,说明风险设备更容易出现多个账号登录的情况.
图 2
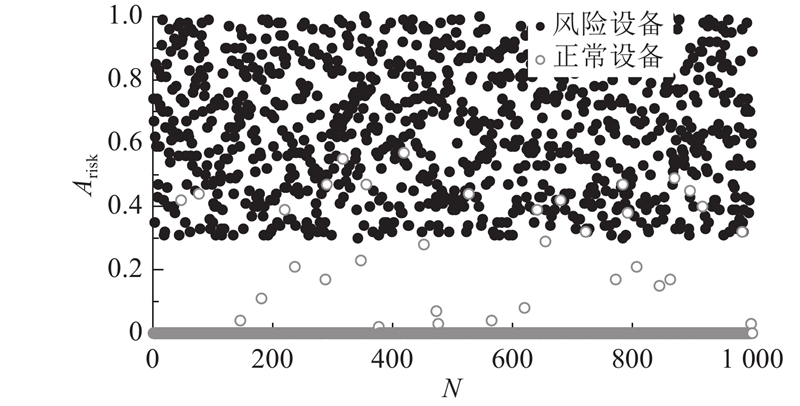
图 2 随机抽取的2 000个样本在设备多账号风险度上的取值情况
Fig.2 Values of 2,000 samples randomly selected on device multi-account risk level
如图3所示,正常设备的收费网络占比大部分低于0.7,而风险设备高于0.9,并且绝大部分为1,说明风险设备访问收费网络的占比更大.
图 3

图 3 随机抽取的2 000个样本在收费网络占比上的取值情况
Fig.3 Values of 2,000 samples randomly selected on percentage of charged network
如图4所示,正常设备的访问多数处于非对立位置,与预期相符;而风险设备只有57.9%的访问处于对立位置,与预期的结果有所差距. 主要原因是部分风险设备的访问位置难以判断为对立位置(如:与正常设备处于同一栋楼),导致聚类效果不理想.
图 4
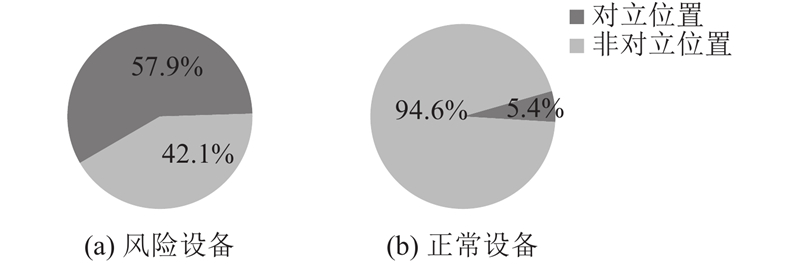
图 4 随机抽取的2 000个样本在对立位置风险度上的占比情况
Fig.4 Proportion of 2,000 samples randomly selected on opposing position risk levels
如图5所示,正常设备的URL访问相似度大部分高于0.4,而风险设备大部分低于0.2. 说明风险设备访问的URL与被盗账号其余设备访问的URL有较大的差异.
图 5

图 5 随机抽取的2 000个样本在设备访问URL相似度上的取值情况
Fig.5 Values of 2,000 samples randomly selected on similarity of device access URLs
针对上述特征进行主成分分析[20],分析各个特征对于最终结果的贡献率,得到特征
综上所述,对立位置风险度分类效果较不明显,因为难以判断部分风险设备与正常设备所在的位置是否为对立位置. 风险设备访问次数离散度、多账号风险度、收费网络占比、设备访问URL的修正余弦相似度均与正常设备有明显区分度,与预期的表现一致,其中设备多账号风险度的效果最好,在低误报率的情况下能够检测出85%的风险账号,检出率较高.
3. 结 语
基于账号登录后的URL访问日志,本研究提出了一种园区网风险账号的评估方法. 本研究以校园网为研究对象,提出了风险设备的概念,并通过检测风险设备定位风险账号. 实验结果表明,所提方法能够在误报率低于5%的同时达到85%的检出率,能有效地评估风险账号. 并且当日志信息欠缺时,仅使用设备多账号风险度也能取得较为良好的评估效果,说明同一设备登录多个账号是较为明显的风险行为. 该方法同样适用于特征类似的园区网,例如:在运营商部署收费WIFI的园区网环境下,可以利用访问点(access point,AP)位置信息替代本研究方法使用的IP位置信息,将AP位置信息用于量化对立位置特征,从而实现风险账号的评估. 未来的工作可以着眼于在更短的日志周期内、更小的日志量中挖掘风险账号的特征,从而提升评估方法的性能和效率.
参考文献
高校园区网的规划与构建
[J].DOI:10.3969/j.issn.1006-8724.2010.01.043 [本文引用: 1]
Planning and construction of university campus network
[J].DOI:10.3969/j.issn.1006-8724.2010.01.043 [本文引用: 1]
Two birds with one stone: two-factor authentication with security beyond conventional bound
[J].
Predict insider threats using human behaviors
[J].DOI:10.1109/EMR.2017.2667218 [本文引用: 1]
Proguard: detecting malicious accounts in social-network-based online promotions
[J].DOI:10.1109/ACCESS.2017.2654272 [本文引用: 1]
统一身份认证日志集中管理与账号风险检测
[J].
Unified identity authentication log centralized management and account risk detection
[J].
高校统一身份认证中的账号安全研究
[J].DOI:10.3969/j.issn.1008-3421.2017.04.019 [本文引用: 1]
Research on account security in university unified identity authentication
[J].DOI:10.3969/j.issn.1008-3421.2017.04.019 [本文引用: 1]
IP地址地理位置映射技术
[J].DOI:10.3969/j.issn.1000-3428.2008.15.036 [本文引用: 1]
IP address geolocation mapping technology
[J].DOI:10.3969/j.issn.1000-3428.2008.15.036 [本文引用: 1]
高斯混合模型聚类中EM算法及初始化的研究
[J].DOI:10.3969/j.issn.1008-0570.2006.33.086 [本文引用: 1]
Research on EM algorithm and initialization in Gaussian mixture model clustering
[J].DOI:10.3969/j.issn.1008-0570.2006.33.086 [本文引用: 1]
基于高斯混合模型的EM学习算法
[J].
EM learning algorithm based on Gaussian mixture model
[J].
基于 DPI 的流量识别系统的研究
[J].DOI:10.3969/j.issn.1671-1122.2014.10.008 [本文引用: 1]
Research on DPI-based traffic identification system
[J].DOI:10.3969/j.issn.1671-1122.2014.10.008 [本文引用: 1]
协同过滤推荐算法综述
[J].
A survey of collaborative filtering recommendation algorithms
[J].
适应用户兴趣变化的协同过滤推荐算法
[J].DOI:10.1360/crad20070216 [本文引用: 1]
Collaborative filtering recommendation algorithm adapted to changes in user interest
[J].DOI:10.1360/crad20070216 [本文引用: 1]
基于用户兴趣模型的协同过滤推荐算法
[J].DOI:10.3969/j.issn.1000-386x.2014.11.066 [本文引用: 1]
Collaborative filtering recommendation algorithm based on user interest model
[J].DOI:10.3969/j.issn.1000-386x.2014.11.066 [本文引用: 1]
Score normalization in multimodal biometric systems
[J].DOI:10.1016/j.patcog.2005.01.012 [本文引用: 1]
支持向量机分类与回归方法研究
[J].
Research on support vector machine classification and regression method
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}