

国家旅游局最新发布的统计信息显示,自2016年以来,全国出行旅游人次已超过150亿,国民旅游需求不断增加,旅游活动持续升温. 然而,互联网上与旅行相关的信息庞杂,手动整理困难,为用户推荐一条满意度高的路线不是一件容易的事情. 随着基于位置社交网络(location-based social network, LBSN)的日益普及,信息的传播和共享越来越便捷,互联网上积累了大量关于人类行为的数据. 用户旅行后,通常会分享自己的经验和评论,形成了大量包括评论、照片、签到数据、旅游游记和 GPS 轨迹等的用户生成内容. 通过对这些生成内容进行分析,可以得到用户喜好和历史行为,为用户推荐个性化旅游路线,更好地满足用户需求[1].
现在已有一些利用用户生成内容、结合用户喜好和相关约束为用户推荐路线的工作[2]. 这些工作一般是通过对比用户的历史轨迹和目标城市中其他用户旅行记录之间的相似性进行推荐. 这些方法的缺点是返回的都是既有路线,无法探索出用户可能喜欢的新路线. 下面用一个例子说明现有的路线推荐工作以及本文要解决的问题.
假设小敏想要在一个新城市找到一条从火车站到酒店,依次经过美术馆、餐厅和书店,且路上行车时间较少、访问人气较高的路线. 数据库中存储着用户的历史路线. 如果历史轨迹中并不存在同时包含这3个类别(美术馆、餐厅、书店)的轨迹,则现有工作无法为用户进行推荐. 然而,历史数据中可能存在2条不同的轨迹,如 “火车站→美术馆→餐厅→公园→书店”和“火车站→餐厅→书店→酒店”,通过执行连接(Join)操作可以获得一条满足用户需求的隐藏路线,即 “火车站→美术馆→餐厅→书店→酒店”. 这条路线可满足用户指定的所有类别和顺序要求.
为解决上述问题,最直观的方法是首先在历史数据的任意2条轨迹中,通过共有感兴趣点枚举所有的连接可能性;然后,在生成的所有新轨迹上根据用户需求进一步求精. 很明显,这种算法的时间代价过高. 当然,也有通过研究历史数据中感兴趣点(points of interested, POI)之间的转移特性,寻找并推荐隐藏路线. 例如,Chen等 [3]提出了一种基于马尔科夫模型的Rank+Markov算法,该工作的缺点是没有考虑用户的类别序列要求,不能满足用户的个性化需求,用户满意度低.
本文根据用户的历史轨迹构建隐马尔科夫模型,把路线推荐问题转化为感兴趣点序列预测问题,在最终的路线推荐中同时考虑众多与用户有关的因素,如:喜好、流行度、起点和终点位置等. 具体来讲,将用户指定的类别文本序列作为观测状态序列,将用户访问的POI作为隐藏状态,在考虑类别序列上下文的基础上,实现将历史数据中常出现但属于不同轨迹的子轨迹进行结合,生成新的隐藏轨迹. 通过结合路线长度、个性化路线分数以及访问点序列的可能性对路线进行综合性评分,并推荐综合性评分较高的TOP-k路线集合.
1. 相关工作
根据路线推荐内容的不同,将现有工作分为3类[3].
1) POI推荐. 根据单个POI的评分为用户推荐,评分中考虑每个POI的地理位置和其他属性信息,如:类别、评论、受欢迎程度等. 例如,Yoon 等[4]通过分析用户的历史轨迹,挖掘流行的地点和频繁的地点访问模式,为用户推荐旅游路线. 与此类工作不同,本研究同时考虑POI分数和类型. POI的推荐工作只是推荐单时刻点(snapshot)的位置,并未考虑用户之前的位置序列.
2)下一个位置点推荐. 根据用户的历史行为信息、单个POI的信息、POI之间的关系等对下一个候选位置进行推荐. 可以将此类工作看作是POI推荐工作的变体. 例如,Qiao等[5]为了预测连续的轨迹点链,提出了一种基于密度的轨迹聚类算法,将轨迹段作为隐藏状态,提出一种基于隐马尔科夫模型的轨迹预测算法(hidden Markov model-based trajectory prediction, HMTP). Braunhofer等[6]提出了一个基于情境感知模型的主动推荐系统,在用户兴趣偏好和情境因素2个维度上为每个POI进行预测评分. 与此类工作不同,本研究根据用户提供的起点和终点,结合地点的类别、地理位置、受欢迎程度以及用户的历史行为轨迹数据,向用户推荐包含起点和终点的完整路线.
2. 问题建模及相关定义
定义1 利用隐马尔科夫模型为现有的轨迹集合进行建模. 隐马尔科夫模型由2个状态集合(观测状态集合O和隐藏状态集合S)和3个概率矩阵λ组成.
1)观测状态集合O是直接观测得到的与隐藏状态相关联的状态集合. 本研究根据用户指定的感兴趣点类别寻找相关路线,将感兴趣点的类别文本域设置为观测状态集合. 观测状态序列是观测状态集合中类别文本的任意组合.
2)隐藏状态集合S是无法直接观测得到、需要通过观测状态推导得到的状态集合. 本研究中用户访问的POI为隐藏状态. 依据观测状态序列,通过计算、推导可获得隐藏状态序列. 与文献[3]的研究类似,本研究假设用户对某一个POI的访问只受前一个POI的影响,因此,隐藏状态(即POI)之间满足马尔科夫链性质.
3) λ ={π, A, B},其中,π为初始隐藏状态(即POI访问)概率矩阵,A为隐藏状态转移概率矩阵(即POI之间的转移矩阵),B为发射矩阵(即观测状态集合O与隐藏状态集合S的转移概率矩阵). 3个概率矩阵的具体计算方法见定义2~4.
如图1所示为所构建的隐马尔科夫抽象模型示例. {类别1,类别2,类别3} 来自观测状态集合;{POI 1, POI 2, POI 3}来自隐藏状态集合,是根据历史访问轨迹数据形成的地点序列,满足马尔科夫性质.
图 1
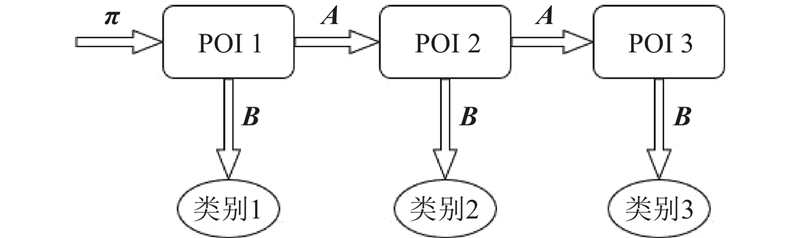
定义2 初始隐藏状态概率矩阵π 即所有POI的初始访问概率,π中的任意值πi表示POI vi被访问的初始概率. 一个POI的访问概率受该点流行度的影响,一个点的流行度需要同时考虑该点的访问次数以及访问人数[9]. 从直观上看,访问次数越多的点越流行,但是为了避免部分POI仅有个别用户多次访问,造成虚假流行的情况,采用访问次数与访问人数的调和平均数计算POI vi的访问概率,即
式中:
定义3 隐藏状态转移概率矩阵A 即POI间的转移概率矩阵,记录各个POI之间的转移概率,其中每一个概率值aij = P( vj|vi),表示在访问了前1个POI vi的前提下,访问当前POI vj的概率.
式中:count(vi,vj)为在所有的历史轨迹中连续访问vi和vj的次数,count(vi)为从点vi发生转移的总次数.
需要说明的是,当POI的数量很大时,采用二维数组表示隐藏状态的转移概率矩阵A非常浪费空间,因为不是任意2个POI之间都有转移概率,转移概率矩阵会比较稀疏. 本研究采用逆邻接表示存储隐藏状态转移概率矩阵. 用一个数组存储所有的隐藏状态(即POI),数组当中的每一项(即每一个隐藏状态vj)由(hj, Lj)组成. 其中,Lj为一个指向单链表的指针,单链表中存储隐藏状态vi及从隐藏状态vi到vj的非零转移概率aij;hj为隐藏状态转移概率非零的个数,即链表长度.
定义4 发射矩阵B 观测状态(即POI的类别)与隐藏状态(即POI)的转移概率矩阵. 令N为POI的数目,M为类别文本的数目,则每一个类别与POI的转移概率bij= P(ci | vj)(1≤i≤M,1≤j≤N) 表示以类别ci访问POI vj的概率,即
式中:W(ci)为点vj所包含的类别文本中类别ci的数量①,W(vj)为点vj所包含的类别总数.
问题定义:用户输入3元组Q = < s, d, Ω>,其中,s为起点位置,d为终点位置,Ω=<c1,c2, ··· ,cm>是用户指定的感兴趣类别文本序列. 潜在轨迹推荐欲为用户返回一个由POI序列组成的路线集合,该路线集合满足:1) 每一条路线上POI的类别文本的并集包含用户要求的类别关键字集合Ω,且同时满足用户指定的类别顺序. 2) 向用户推荐个性化的平衡分数值高的路线,即综合考虑路线的访问概率、个性化路线分数以及路线长度.
3. 潜在个性化路线推荐算法
基于隐马尔科夫模型的推荐算法(path based on hidden Markov model,HMMPath)主要包括2个部分:路线生成和路线排名. 首先,根据用户输入的类别文本序列,基于隐马尔科夫模型寻找与类别文本序列对应的POI序列以及相应的访问概率. 然后,根据个性化路线排名算法,为每一个候选的POI序列计算平衡分数,返回给用户平衡分数高的TOP-k路线集合. HMMPath算法的计算步骤如下.
算法1 HMMPath算法
Input:Ω= < c1, c2, ··· , cm>,π, A, B
Output:个性化路线排名路线集合R*
1. R=φ;
2. R=利用路线生成算法(见算法2)获得候选的POI序列集合;
3. R*=利用个性化路线排名算法(见算法3)为候选集合R中的路线排序,返回TOP-k条路线;
4. return R*.
3.1. 路线生成算法
3.1.1. 算法流程
路线生成算法要解决的问题是根据用户提供的类别文本序列得到一个已存在或潜在的POI序列,这与基于隐马尔科夫模型的预测问题类似;预测问题是在已知一个观测状态序列O= < o1,o2, ··· ,om>和模型参数λ=(π, A, B)的情况下,找到在某种意义上最优的隐藏状态序列,一般使用维特比 (Viterbi algorithm)算法来解决该问题. 维特比算法可以利用模型参数,找到一个与观测状态序列对应的发生概率最大的隐藏状态序列. 路线生成算法在维特比算法的基础上针对路径“回溯”进行修改.
为叙述方便,首先设置一些变量:δt(vi)为第t–1个类别文本(观测状态)对应POI(隐藏状态)到第t个类别文本(观测状态)对应POI(隐藏状态)为vi的最大概率值;ψt(vi)为使第t个类别文本(观测状态)对应的POI(隐藏状态)为vi的概率值最大的第t–1个类别文本对应的POI(隐藏状态). 该算法包含3个主要步骤.
1)初始化.
式中:δ1(vi)为第一个类别文本对应的POI为vi的概率,N为POI的个数.
初始化即计算用户查询中要求的第一个类别文本对应于每一个POI的概率. 因此,δ1(vi)是发射概率b1i与每一个POI的初始概率πi的乘积. 由于第一个类别文本对应的POI没有前一个POI,ψ1(vi)=0.
2)递归.
递归过程就是计算第t个类别文本ct对应于每个POI的概率. ψt(vi)中记录的是POI,该POI对应δt–1(vj)与aji的乘积最大值. 在完成对最后一个类别文本的计算后,递归过程结束.
3)路径回溯.
在递归的最后一步,将获得多条与用户文本序列对应的POI序列以及相应的发生概率值. 路径回溯用以获得每个概率值对应的POI序列. 维特比算法是机器学习中应用非常广泛的动态规划算法. 维特比算法仅返回概率最高的POI序列,然而由于推荐路线也受流行度、用户的喜好等其他因素的影响,这里的路径回溯将对递归过程得到的所有POI进行回溯.
具体来讲,从第m个类别文本(观测状态)所对应的POI(隐藏状态)开始,寻找造成此概率值的第m–1个类别文本(观测状态)对应的POI(隐藏状态),然后依次回溯下去,即
最后得到与类别文本(观测状态)序列对应的完整POI(隐藏状态)序列,即I=(v1,v2, ···, vm).
路线生成算法的具体步骤如算法2所示. 首先初始化,根据用户给定的类别文本序列中的第一个类别文本c1,计算第一个可能访问的POI的概率值(第1~2行). 然后,通过递归依次计算查询类别文本序列中其他类别文本对应的POI的概率值. 每计算完成类别文本ci对应的POI vi的概率值,需要同时记录导致此vi概率值的前一个访问POI vi–1(第3~10行). 当计算完成最后一个类别文本后,进行路径回溯,找到每一个概率值对应的POI并组成序列,将其添加到候选结果集R中(第11~18行). 算法2的时间复杂度为O(mN2).
算法2 路线生成算法
Input:Ω= < c1, c2, ···, cm>,π, A, B
Output:POI序列集合R
1. t=2; R=φ;
2. for 每1个POI点vi in V
3.
4. while t<=m do
5. for 每1个POIvi in V
6. for (int j=1; j<=hi; j++)
7. aji=
8. vj=Li.vj ;
9.
10. 记录得到此最大概率值的前1个POI vj为 ψt(vi);
11. t=t+1;
12. for each 最后1个类别文本对应的概率值δm(vi)
13. if δm(vi)>0
14. h=m−1;
15. while h>0do
16. ih=ψh+1(vh+1);
17. h=h−1;
18. I=(v1, v2,···, vm);
19. 将I添加到POI序列集合R中;
20. return R.
3.1.2. 运行示例
表 1 POI之间的转移概率矩阵
Tab.1
| 前一状态 | 后一状态 | ||
| v1 | v2 | v3 | |
| v1 | 0 | 2/3 | 1/3 |
| v2 | 0 | 0 | 1 |
| v3 | 1/2 | 1/2 | 0 |
表 2 POI与类别文本之间的转移概率矩阵
Tab.2
| 地点 | 类别 | ||||
| c1 | c2 | c3 | c4 | c5 | |
| v1 | 2/5 | 0 | 2/5 | 1/5 | 0 |
| v2 | 1/4 | 1/4 | 0 | 0 | 1/2 |
| v3 | 0 | 1/3 | 1/3 | 0 | 1/3 |
设用户查询的类别序列为Ω={c1,c2,5c3},则执行算法2的步骤如下.
1)初始化.
第1个POI的确定需要同时考虑POI的初始概率和第1个类别c1与每一个POI的转移概率(表2中第1列):
δ1(v1)=1/3×2/5=2/15;δ1(v2)=1/3×1/4=1/12;
δ1(v3)=1/3×0=0;
ψ1(v1)= 0;ψ1(v2)=0;ψ1(v3)=0;
2)递归.
第2个POI的确定需要考虑第2个类别文本c2与前一个POI的转移概率以及前一个POI的概率:
δ2(v1)=max {0×1/2}×0=0;
δ2(v2)=max {2/15×2/3, 0×1/2}×1/4=1/45;
δ2(v3)=max {2/15×1/3, 1/12×1}×1/3=1/36;
ψ2(v1)= 0;ψ2(v2)=v1;ψ2(v3)=v2;
第3个POI的确定与第2个POI的确定过程相同:
δ3(v1)=max {1/36×1/2}×2/5=1/180;
δ3(v2)=max {0×2/3, 1/36×1/2}×0=0;
δ3(v3)=max {0×1/3, 1/45×1}×1/3=1/135;
ψ3(v1)=v3;ψ3(v2)= 0;ψ3(v3)=v2;
3)路径回溯.
在第3个点的概率计算完成之后,进行路径回溯,分别找到形成最后概率的每个类别文本对应的POI. 概率为1/135的POI序列为{v1,v2,v3},概率为1/180的POI序列为{v2,v3,v1}.
3.2. 个性化路线排名算法
路线生成算法生成的POI序列集合只关注了用户连续的访问模式和用户指定的类别序列,并没有考虑用户起点、终点的位置以及用户对不同类别的喜好程度,这可能会造成返回的路线距离用户指定的位置较远及路线的受欢迎度不佳等问题. 为了解决这些问题,综合考虑POI序列的概率值P、个性化路线分数S和路线长度L,为用户返回一个综合性评分较高的路线集合.
定义5 路线长度L 即POI序列中任意2个连续的POI之间的距离、第一个POI与起点的距离以及最后一个POI点与终点的距离的加和,具体计算公式如下:
式中:距离函数dist可以是任意的空间距离函数,如:欧式、路网或曼哈顿距离等.
用户对不同类别的POI的喜好具有个性化特点. 本研究将用户对路线上所包含POI的类别喜好程度相加,作为用户对该路线的个性化喜好分数. 以用户访问某类别的次数表示用户对该类别的喜好度.
定义6 个性化路线喜好分数S即用户对路线上POI所包含的类别文本喜好度的加和,即
式中:
其中,
综合路线长度、个性化路线喜好分数以及序列发生概率因素,定义路线的平衡分数.
定义7 平衡分数G 是将路线的概率P、个性化路线喜好分数S以及路线的长度L进行综合考虑,以平衡三者的关系,具体的计算公式如下:
受文献[9]中牛顿万有引力定律的启发,定义平衡分数与路线的产生概率和喜好分数成正比,与路线长度成反比. 如果将分母中路线长度的μ设定为0,那么基于平衡分数的排名就是路线概率值和路线分数的排名,而不会考虑路线的长度;相反地,如果将μ设置的比较大,则平衡分数将受到路线长度较大的影响.
路线排名算法见算法3. 在个性化路线排名算法中,对R中的每一个POI序列,分别计算其对应的平衡分数,根据平衡分数对POI序列进行排名,返回TOP-k条排名最高的路线进行推荐.
算法3 路线排名算法
Input:POI序列集合R
Output:个性化路线排名路线集合R*
1. for each POI序列 l in R
2. 根据定义5计算路线长度L;
3. 根据定义6计算个性化路线分数S;
4. 根据定义7结合路线长度L、个性化路线分数S以及POI序列概率值P计算路线平衡分数;
5. 对R中所有POI序列按照平衡分数进行排名,返回TOP-k的路线集合R*;
6. return R*.
4. 实验设置与实验结果
4.1. 实验设置
4.1.1. 数据预处理
表 3 数据集的用户、地点和轨迹统计信息
Tab.3
| 城市 | 用户数量 | 地点数量 | 轨迹数量 |
| 洛杉矶 | 8 539 | 11 051 | 18 604 |
| 纽约 | 10 005 | 15 697 | 31 539 |
图 2
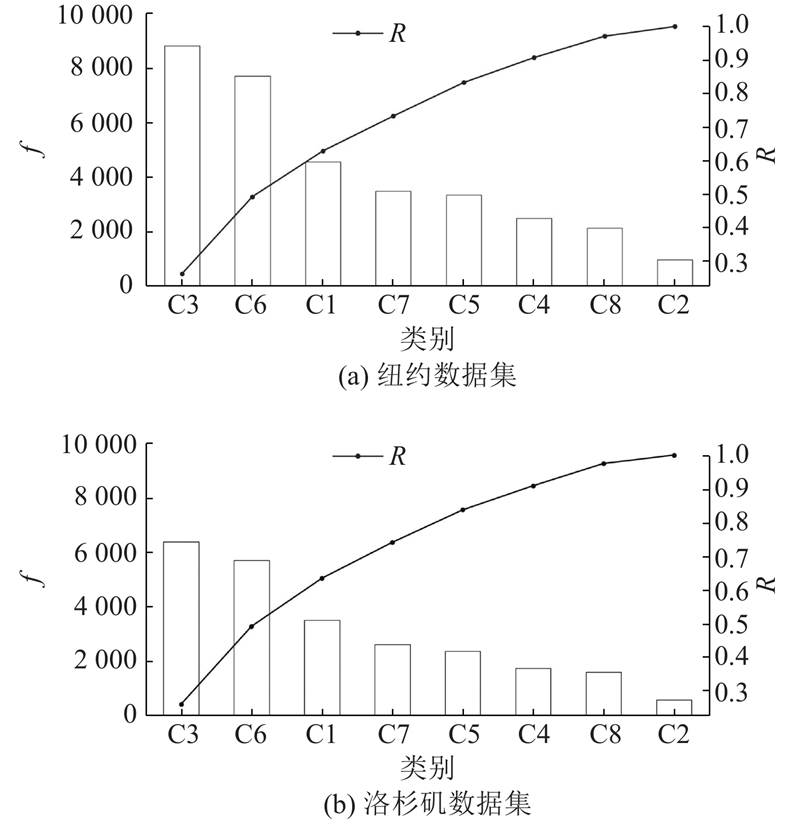
表 4 类别文本及词频
Tab.4
| 类别代号 | 类别文本 | 词频 |
| C1 | Arts&Entertainment | 高 |
| C2 | College&University | 低 |
| C3 | Food | 高 |
| C4 | Great Outdoors | 低 |
| C5 | Home, Work, Other | 中 |
| C6 | Nightlife Spot | 高 |
| C7 | Shop | 中 |
| C8 | Travel Spot | 低 |
4.1.2. 实验设置
马尔科夫模型也可被用于寻找隐藏路线,因此,本实验简化文献[3]中马尔科夫模型的建立过程,以所有POI作为模型的状态集,构建基于马尔科夫模型的路线算法,作为基线对比算法,记作MP算法. 将提出的HMMPath算法和MP算法在洛杉矶和纽约2个数据集上分别进行实验. 为方便描述,下文中用N-MP(N-HMMPath)表示在纽约数据集上使用基线算法(HMMPath算法);用N-HMMPath表示在纽约数据集上使用 HMMPath算法;用L-MP表示在洛杉矶数据集上使用基线算法;用L-HMMPath表示在洛杉矶数据集上使用HMMPath算法.
实验通过改变数据集大小D、查询类别关键字数量m、查询关键字类型和推荐路线数量k,评测算法的准确率和平均运行时间. 在缺省情况下,使用10 000个POI创建模型,提出的查询包含3个查询类别关键字,这3个关键字分别从高频、中频和低频3种类型中随机抽取,最后返回平衡分数排名前3的路线. 实验中的所有算法均使用Java实现,运行于Intel(R) i7 2.30 GHz CPU处理器、4 GB内存的Windows10计算机上.
HMMPath算法既可返回既有路线也可返回隐藏路线,不适宜使用与历史轨迹的一致程度计算准确率. 因此,本研究对传统准确率的定义进行修正,查询返回的推荐路线与原有签到轨迹上POI序列相同的点的个数在推荐路线上所占的比例可以表达如下:
式中:Hi为与签到轨迹中POI相同且顺序也保持一致的POI个数;|Tv|为推荐路线中的POI个数,其作用是将准确率标准化.
4.2. 实验结果与分析
图3(a)展示了2种算法在2个数据集上准确率的变化情况,D为数据集大小. 从实验结果来看,随着数据集的增大,无论在哪一个数据集上,HMMPath算法的准确率均保持在70%以上,MP算法的准确率均保持在30%左右. HMMPath算法比MP算法的准确率更高,这是因为MP算法在计算路线概率时仅依据POI之间的转移概率对POI子序列进行组合,组合时更关注的是2个连续POI的访问频率,忽略了POI所反映的类别序列,导致最后路线中类别序列不符合用户POI的序列要求. 随着数据集的增大,HMMPath算法中应用到的3个概率矩阵能更准确地估计POI流行度以及POI之间的转移概率. 因此,随着数据集的增大,HMMPath算法的准确率上升,在洛杉矶数据集上的上升趋势表现得尤为明显.
图 3

图 3 不同大小的数据集上准确率和运行时间的变化情况
Fig.3 Change of accuracy and running time on different sizes of datasets
如图4所示为当输入不同数量的查询类别关键字m时,HMMPath算法和MP算法的准确率以及平均运行时间. 查询类别的关键字数量从3增加到8. 当查询类别的关键字数量为3和6时,等概率地从高、中、低3种不同频率的类别中选取类别关键字;当查询关键字数量为4、5、7时,从高、中、低3种词频类型中各选择1个,剩下的1或2个类别关键字则从3个词频类型中随机选取.
图 4
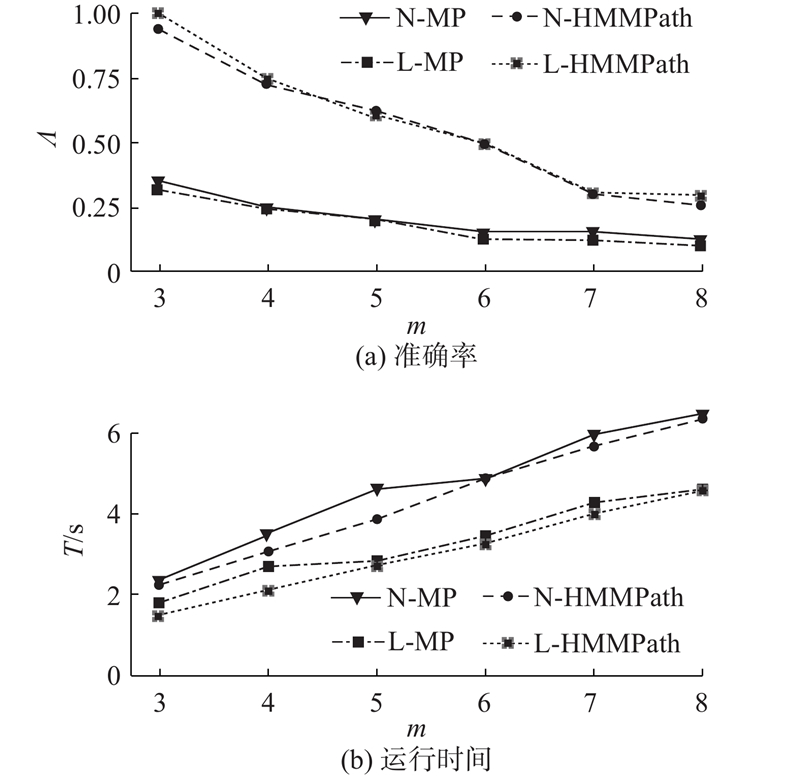
图 4 不同查询关键字数量下准确率和运行时间的变化情况
Fig.4 Change of accuracy and running time with different numbers of query keywords
查询类别关键字的个数反映了返回路线包含的POI个数. 随着查询类别关键字数量的增加,2种算法的准确率都逐渐降低,如图4(a)所示. 这是因为随着输入类别关键字数量的增加,用户签到轨迹中满足此类别序列的轨迹数量减少. 若想要得到满足此类别序列的路线,需要结合多条不同轨迹的子轨迹,生成更多的隐藏路线,因此,准确率下降. 但是,这也正反映了HMMPath算法和MP算法寻找隐藏轨迹的能力. 即使原始轨迹无法满足用户查询类别需求,HMMPath算法和MP算法依然可以执行TOP-k推荐.
从图4(b)中观察到,随着查询类别关键字数量的增加,各算法的运行时间也随之增加. 但是,在查询关键字数量较小时,在2个数据集上,MP算法的运行时间略大于HMMPath算法的运行时间;当查询关键字数量继续增大时,MP运行时间的增长率低于HMMPath运行时间的增长率,HMMPath和MP的运行时间差别不大. 这是因为在查询类别关键字数量较少时,2个模型生成的候选路线(即没有执行算法3排序)较多;而且由于MP没有考虑类别文本序列,所生成的候选路线多于HMMPath,此时MP算法的运行时间略高于HMMPath. 但是,随着查询关键字数量的增加,即随着返回路线包含的POI数量的增多,生成的候选路线数下降,MP算法和HMMPath算法的运行时间的差别变得不明显.
查询关键字的词频从一定程度上反映了感兴趣点类别的流行程度,词频越高说明这种类别越流行;相反地,词频低说明其属于偏冷门的类别. 为了验证查询关键字的词频是否对返回结果有影响,即验证提出算法在查询热门类别文本和冷门类别文本上的性能差别,实验分别将3个高频和3个低频查询关键字作为输入. 由于MP算法没有考虑查询关键字序列,这里仅验证HMMPath算法的准确率和运行时间.
HMMPath算法输入不同类型关键字时在纽约和洛杉矶数据集上的准确率和运行时间的变化情况如表5所示. 可以观察到,在这2个数据集上,虽然低频查询关键字的POI冷门,导致路线生成算法生成较少的POI序列,但是这并不影响查询准确率. 高频和低频具有相同的准确率,相比之下,当查询的是随机类型的关键字时,准确率没有前两者高.
表 5 不同类型关键字的准确率和运行时间
Tab.5
| 数据集 | | T/s | |||||
| 高频 | 低频 | 随机 | 高频 | 低频 | 随机 | ||
| 纽约 | 1.00 | 1.00 | 0.94 | 2.28 | 2.16 | 2.22 | |
| 洛杉矶 | 1.00 | 1.00 | 1.00 | 1.55 | 1.53 | 1.49 | |
在纽约和洛杉矶数据集上,HMMPath算法在高频、低频和随机文本查询关键字作为输入时的平均运行时间如表5所示. 在纽约数据集上,高频的运行时间略高于随机,随机略高于低频. 这很容易理解,因为高频关键字较低频关键字在隐马尔科夫模型中对应更多的POI序列. 在洛杉矶数据集上,高频关键字的运行时间高于低频和随机. 由于纽约数据集上路线生成算法返回的POI序列较多,其平均运行时间普遍高于HMMPath算法在洛杉矶数据集上的运行时间.
图 5

图 5 不同推荐路线数量下的准确率运行时间变化情况
Fig.5 Change of accuracy and running time with different numbers of recommended routes
观察发现,经过平衡分数排名后返回的推荐路线比没有排名的推荐路线的准确率更高. 说明路线排名算法对路线推荐的准确率起到了积极的作用. 对于MP--来讲,随着k的增加(纽约数据集上k从2增加到5;洛杉矶数据集上k从2增加到10)时,其准确率的增长比较明显. 此外,当k=5时,HMMPath算法和MP算法返回路线的准确率分别达到100%和33%,之后k值继续增长,路线准确率基本保持不变,这是因为算法准确率的评价标准使用的是k条路线中的最大准确率值. 因此,随着k的增加,虽然推荐给用户的路线数增多,但是不能提高准确率.
就运行时间来讲,HMMPath算法和MP算法的运行时间均被路线生成算法所控制. 个性化路线排名算法仅对从路线生成算法中得到的POI序列进行评分并返回TOP-k. 因此,算法的运行时间并不受k值变化的影响. 无论k取什么值,MP在纽约数据集的运行时间为2.3 s,MP--在纽约数据集的运行时间为2.0 s;MP在洛杉矶数据集上的运行时间为1.8 s,MP--在洛杉矶数据集上的运行时间为1.6 s. HMMPath在纽约数据集上的运行时间为2.2 s,HMMPath--在纽约数据集上的运行时间为1.9 s;HMMPath在洛杉矶数据集上的运行时间为1.5 s,HMMPath--在洛杉矶数据集上的运行时间为1.1 s.
5. 结 语
本文针对现有路线推荐算法只能推荐历史轨迹中既有路线的问题,提出了一种可以推荐潜在个性化路线的算法. 利用隐马尔科夫模型对路线推荐问题进行建模,提出了基于修改维特比算法的HMMPath算法,结合POI序列的概率、个性化路线分数以及路线长度进行推荐. 推荐的路线可以是历史数据中的既有路线,也可以是历史数据中没有的潜在路线. 实验结果显示,所提出的模型在较短(类别序列长度小于4)的查询类别序列上,可达70%以上的准确率,每一条查询的平均运行时间在3 s,表现出了较好的效果和性能.
未来考虑两方面工作:一方面,将场地限制时间因素加入到路线推荐研究中,为用户推荐更加准确和有效的旅行路线;另一方面,借助多源数据融合技术在国内数据集上进行实验,进一步验证算法的可行性和通用性.
参考文献
多源异构众包数据风景旅行路线规划
[J].
Scenic travel route planning based on multi-sourced and heterogeneous crowd-sourced data
[J].
Social itinerary recommendation from user-generated digital trails
[J].DOI:10.1007/s00779-011-0419-8 [本文引用: 1]
A self-adaptive parameter selection trajectory prediction approach via hidden Markov models
[J].DOI:10.1109/TITS.2014.2331758 [本文引用: 1]
MA-SSR: a memetic algorithm for skyline scenic routes planning leveraging heterogeneous user-generated digital footprints
[J].
TripPlanner: personalized trip planning leveraging heterogeneous crowdsourced digital footprints
[J].DOI:10.1109/TITS.2014.2357835 [本文引用: 3]
Approximate similarity measurements on multi-attributes trajectories data
[J].DOI:10.1109/ACCESS.2018.2889475 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}