[1]
LONG J, SHELHAMER E, DARRELL T Fully convolutional networks for semantic segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2014 , 39 (4 ): 640 - 651
[本文引用: 3]
[2]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// European Conference on Computer Vision. Munich: Springer, 2018: 801-818.
[本文引用: 3]
[3]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al Semantic image segmentation with deep convolutional nets and fully connected CRFs
[J]. International Conference on Learning Representations , 2014(4) , 357 - 361
[本文引用: 5]
[4]
LIN G, MILAN A, SHEN C, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 5168-5177.
[本文引用: 3]
[5]
ZHAO H, SHI J, QI X, et al Pyramid scene parsing network
[J]. IEEE Conference on Computer Vision and Pattern Recognition , 2017(1) , 2881 - 2890
[本文引用: 3]
[6]
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 1251-1258.
[本文引用: 1]
[7]
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications [EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704.04861.
[本文引用: 1]
[8]
PIOTR B, VICTOR P. Dense decoder shortcut connections for single-pass semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6596-6605.
[本文引用: 2]
[9]
ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks [C]// European Conference on Computer Vision. Zurich: Springer, 2014: 818–833.
[本文引用: 2]
[10]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2014 , 37 (9 ): 1904 - 1916
[本文引用: 1]
[11]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. [2017-06-17]. https://arxiv.org/abs/1706.05587.
[本文引用: 1]
[12]
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions [EB/OL]. [2015-11-23]. https://arxiv.org/abs/1511.07122.
[本文引用: 2]
[13]
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks. conference [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510-4520.
[本文引用: 1]
[14]
RUSSAKOVSKY O, DENG J, SU H, et al ImageNet large scale visual recognition challenge
[J]. International Journal of Computer Vision , 2015 , 115 (3 ): 211 - 252
DOI:10.1007/s11263-015-0816-y
[本文引用: 1]
[15]
CIRESAN D, GIUSTI A, GAMBARDELLA L M, et al. Deep neural networks segment neuronal membranes in electron microscopy images [C]// Advances in Neural Information Processing Systems. Lake Tahoe: MIT Press, 2012: 2843-2851.
[本文引用: 1]
[16]
FARABET C, COUPRIE C, NAJMAN L, et al Learning hierarchical features for scene labeling
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2013 , 35 (8 ): 1915 - 1929
DOI:10.1109/TPAMI.2012.231
[本文引用: 1]
[17]
EVERINGHAM M, ESLAMI S M A, VAN-GOOI L, et al The pascal visual object classes challenge: a retrospective
[J]. International Journal of Computer Vision , 2015 , 111 (1 ): 98 - 136
DOI:10.1007/s11263-014-0733-5
[本文引用: 1]
[18]
CORDTS M, OMRAN M, RANMOS S. The cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223.
[本文引用: 1]
[19]
PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation [EB/OL]. [2016-06-07]. https://arxiv.org/abs/1606.02147.
[本文引用: 2]
[20]
TREML M, ARJONA-MEDINA J, UNTERTHINER T, et al. Speeding up semantic segmentation for autonomous driving [C]// Neural Information Processing Systems Workshop. Barcelona: MIT Press, 2016.
[本文引用: 1]
[21]
FORREST N L, SONG H, MATTHEW W, et al. SqueezeNet: alexnet-level accuracy with 50x fewer parameters and 1mb model size [EB/OL]. [2016-02-24]. https://arxiv.org/abs/1602.07360.
[本文引用: 1]
[22]
SERCAN T, JANNE H. An efficient solution for semantic segmentation_ShuffleNet V2 with atrous separable convolutions [EB/OL]. [2019-02-20]. https://arxiv.org/abs/1902.07476.
[本文引用: 1]
[23]
ZHAO H, QI X, SHEN X, et al. ICNET for real-time semantic segmentation on high-resolution images [EB/OL]. [2017-04-27]. https://arxiv.org/abs/1704.08545.
[本文引用: 1]
[24]
BADRINARAYANAN V, KENDALL A, CIPOLLA R SegNet: a deep convolutional encoder-decoder architecture for scene segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (12 ): 2481 - 2495
DOI:10.1109/TPAMI.2017.2701373
[本文引用: 1]
[25]
ZHENG S, JAYASUMANA S, ROMERA-PAREDES B, et al. Conditional random fields as recurrent neural networks [C]// IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1529-1537.
[本文引用: 1]
[26]
ROMERA E, ÁLVAREZ J M, BERGASA L M, et al ERFNet: efficient residual factorized convNet for real-time semantic segmentation
[J]. IEEE Transactions on Intelligent Transportation Systems , 2018 , 19 (1 ): 263 - 272
DOI:10.1109/TITS.2017.2750080
[本文引用: 1]
Fully convolutional networks for semantic segmentation
3
2014
... 深度卷积神经网络(deep convolutional neural network,DCNN)在计算机图像理解任务上有较高的准确度,但这些网络准确度的提高通常依靠加深网络深度、扩宽网络维度来实现,普遍具有计算速度较慢、资源开销较大的问题. 这一问题在计算密集型任务—图像语义分割中尤为严重. 语义分割是图像理解的核心任务,是计算机视觉最基础的问题之一. 语义分割任务要求对图像中的每个像素预测标签,可以视作图像的密集分类问题. 当前的语义分割网络大多基于全卷积网络[1 ] (fully convolutional network,FCN)实现,网络性能的提高大多以计算量和参数量的急剧增高为代价. 以当前具有高性能的DeepLabv3+[2 ] 语义分割模型为例,整个网络需要4461万参数量和8677亿次乘加计算量,使其在许多具有实时性要求的语义分割应用场景,如自动驾驶、机器人视觉、增强现实等领域中具有局限性. DeepLab[3 ] 、RefineNet[4 ] 、PSPNet[5 ] 等高性能的语义分割网络对硬件设备也具有较高的要求,并且具有较差的实时性,不适用于存储资源和计算能力有限的可移动式设备. ...
... Comparison of proposed model and other high-performance semantic segmentation methods on PASCAL VOC 2012 test set
Tab.8 方法 P / 106 mIoU / % FCN-8s[1 ] 134.50 67.20 DeepLab[3 ] 44.04 71.60 DeepLabv3+[2 ] 44.61 87.80 本研究算法 6.52 77.13
表 9 Cityscapes测试集上所提算法与高性能语义分割网络性能对比 ...
... Comparison of network performance of proposed model and other high-performance semantic segmentation methods on Cityscapes test set
Tab.9 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % SegNet[24 ] 60 16.70 57.0 CRF-RCNN[25 ] 700 1.43 62.5 DeepLab[3 ] 400 2.50 63.1 FCN-8s[1 ] 500 2.00 65.3 Dilation[12 ] 4000 0.25 67.1 DeepLabv3+[2 ] 350 2.86 82.1 本研究算法 18 55.60 70.6
将本研究算法与当前表现较好的实时语义分割算法进行对比,如表10 所示. 可以看出,本研究算法在具有较好的实时性同时也具有较高的性能. 本研究算法中的特征融合结构,在保证轻量级的同时,融合了深层和浅层的特征,更好地获取了网络中不同深浅层位置的语义信息和位置信息,取得了较好的性能效果. ...
3
... 深度卷积神经网络(deep convolutional neural network,DCNN)在计算机图像理解任务上有较高的准确度,但这些网络准确度的提高通常依靠加深网络深度、扩宽网络维度来实现,普遍具有计算速度较慢、资源开销较大的问题. 这一问题在计算密集型任务—图像语义分割中尤为严重. 语义分割是图像理解的核心任务,是计算机视觉最基础的问题之一. 语义分割任务要求对图像中的每个像素预测标签,可以视作图像的密集分类问题. 当前的语义分割网络大多基于全卷积网络[1 ] (fully convolutional network,FCN)实现,网络性能的提高大多以计算量和参数量的急剧增高为代价. 以当前具有高性能的DeepLabv3+[2 ] 语义分割模型为例,整个网络需要4461万参数量和8677亿次乘加计算量,使其在许多具有实时性要求的语义分割应用场景,如自动驾驶、机器人视觉、增强现实等领域中具有局限性. DeepLab[3 ] 、RefineNet[4 ] 、PSPNet[5 ] 等高性能的语义分割网络对硬件设备也具有较高的要求,并且具有较差的实时性,不适用于存储资源和计算能力有限的可移动式设备. ...
... Comparison of proposed model and other high-performance semantic segmentation methods on PASCAL VOC 2012 test set
Tab.8 方法 P / 106 mIoU / % FCN-8s[1 ] 134.50 67.20 DeepLab[3 ] 44.04 71.60 DeepLabv3+[2 ] 44.61 87.80 本研究算法 6.52 77.13
表 9 Cityscapes测试集上所提算法与高性能语义分割网络性能对比 ...
... Comparison of network performance of proposed model and other high-performance semantic segmentation methods on Cityscapes test set
Tab.9 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % SegNet[24 ] 60 16.70 57.0 CRF-RCNN[25 ] 700 1.43 62.5 DeepLab[3 ] 400 2.50 63.1 FCN-8s[1 ] 500 2.00 65.3 Dilation[12 ] 4000 0.25 67.1 DeepLabv3+[2 ] 350 2.86 82.1 本研究算法 18 55.60 70.6
将本研究算法与当前表现较好的实时语义分割算法进行对比,如表10 所示. 可以看出,本研究算法在具有较好的实时性同时也具有较高的性能. 本研究算法中的特征融合结构,在保证轻量级的同时,融合了深层和浅层的特征,更好地获取了网络中不同深浅层位置的语义信息和位置信息,取得了较好的性能效果. ...
Semantic image segmentation with deep convolutional nets and fully connected CRFs
5
2014(4)
... 深度卷积神经网络(deep convolutional neural network,DCNN)在计算机图像理解任务上有较高的准确度,但这些网络准确度的提高通常依靠加深网络深度、扩宽网络维度来实现,普遍具有计算速度较慢、资源开销较大的问题. 这一问题在计算密集型任务—图像语义分割中尤为严重. 语义分割是图像理解的核心任务,是计算机视觉最基础的问题之一. 语义分割任务要求对图像中的每个像素预测标签,可以视作图像的密集分类问题. 当前的语义分割网络大多基于全卷积网络[1 ] (fully convolutional network,FCN)实现,网络性能的提高大多以计算量和参数量的急剧增高为代价. 以当前具有高性能的DeepLabv3+[2 ] 语义分割模型为例,整个网络需要4461万参数量和8677亿次乘加计算量,使其在许多具有实时性要求的语义分割应用场景,如自动驾驶、机器人视觉、增强现实等领域中具有局限性. DeepLab[3 ] 、RefineNet[4 ] 、PSPNet[5 ] 等高性能的语义分割网络对硬件设备也具有较高的要求,并且具有较差的实时性,不适用于存储资源和计算能力有限的可移动式设备. ...
... 1)空间金字塔系列. He等[10 ] 在目标检测网络R-CNN中提出空间金字塔池化(spatial pyramid pooling,SPP),用不同尺寸的池化层来感受不同规模的语义特征信息. PSPNet[5 ] 、DeepLab[3 ] 方法都引入了SPP来整合多尺度的语义信息,证明了SPP在语义分割领域中的优良性质. 其中,PSPNet在网络的最后加入SPP模块,网络最后的深层特征包含了较全面的语义特征信息,不同感受野大小的池化层能更好地理解该语义特征信息中不同尺寸规模的物体,更有助于对语义信息做出更精准的识别. 在DeepLabv3[11 ] 中提出空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),在SPP的基础上加入不同尺度的空洞卷积,进一步加强该模块对不同规模大小物体的识别,并在实验中取得了较好的性能效果. 本研究所提出的DASPP结构对ASPP进行加深处理,进一步聚合不同尺寸的语义信息. ...
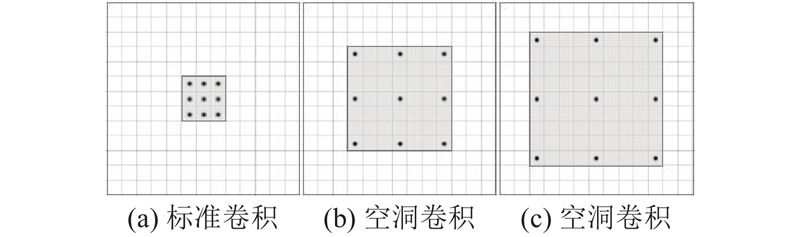
... 2)空洞卷积. 语义分割通过微调分类网络实现,但由于分类网络须不断扩大感受野、聚合语境信息,存在较多池化层使原图像分辨率下降,损失位置和密集语义信息. 空洞卷积可以用来代替部分池化层,在聚合语义信息的同时保留图像分辨率. 另外,空洞卷积还可以用来增大网络的有效感受野. Yu等[12 ] 最早提出空洞卷积,通过在标准卷积核之间进行零插值来增大有效感受野. DeepLab[3 ] 方法对空洞卷积的应用进一步证明空洞卷积的优良性能. 空洞卷积与标准卷积相比具有更大的有效感受野. ...
... Comparison of proposed model and other high-performance semantic segmentation methods on PASCAL VOC 2012 test set
Tab.8 方法 P / 106 mIoU / % FCN-8s[1 ] 134.50 67.20 DeepLab[3 ] 44.04 71.60 DeepLabv3+[2 ] 44.61 87.80 本研究算法 6.52 77.13
表 9 Cityscapes测试集上所提算法与高性能语义分割网络性能对比 ...
... Comparison of network performance of proposed model and other high-performance semantic segmentation methods on Cityscapes test set
Tab.9 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % SegNet[24 ] 60 16.70 57.0 CRF-RCNN[25 ] 700 1.43 62.5 DeepLab[3 ] 400 2.50 63.1 FCN-8s[1 ] 500 2.00 65.3 Dilation[12 ] 4000 0.25 67.1 DeepLabv3+[2 ] 350 2.86 82.1 本研究算法 18 55.60 70.6
将本研究算法与当前表现较好的实时语义分割算法进行对比,如表10 所示. 可以看出,本研究算法在具有较好的实时性同时也具有较高的性能. 本研究算法中的特征融合结构,在保证轻量级的同时,融合了深层和浅层的特征,更好地获取了网络中不同深浅层位置的语义信息和位置信息,取得了较好的性能效果. ...
3
... 深度卷积神经网络(deep convolutional neural network,DCNN)在计算机图像理解任务上有较高的准确度,但这些网络准确度的提高通常依靠加深网络深度、扩宽网络维度来实现,普遍具有计算速度较慢、资源开销较大的问题. 这一问题在计算密集型任务—图像语义分割中尤为严重. 语义分割是图像理解的核心任务,是计算机视觉最基础的问题之一. 语义分割任务要求对图像中的每个像素预测标签,可以视作图像的密集分类问题. 当前的语义分割网络大多基于全卷积网络[1 ] (fully convolutional network,FCN)实现,网络性能的提高大多以计算量和参数量的急剧增高为代价. 以当前具有高性能的DeepLabv3+[2 ] 语义分割模型为例,整个网络需要4461万参数量和8677亿次乘加计算量,使其在许多具有实时性要求的语义分割应用场景,如自动驾驶、机器人视觉、增强现实等领域中具有局限性. DeepLab[3 ] 、RefineNet[4 ] 、PSPNet[5 ] 等高性能的语义分割网络对硬件设备也具有较高的要求,并且具有较差的实时性,不适用于存储资源和计算能力有限的可移动式设备. ...
... Chollet等[6 -7 ] 提出深度可分离卷积,证明其在保持卷积性能的同时能有效减少计算量. 此外,在深度方向上的逐点卷积能在聚合维度信息的同时减少网络的内存占有量和计算量. 在减少网络内存占有量和计算量的同时,如何保证网络的性能也是至关重要的问题. FCN最先实现了端到端的语义分割网络结构,有一定的启发作用,同时也存在须继续思考的问题. 在FCN中,32倍下采样导致原图的语义和位置信息损失过多,预测结果较粗糙. 不过,FCN中引入了跳跃连接结构,指出为了实现更好的性能要注意网络中不同深浅层特征的融合. 通常,网络浅层包含更多的位置信息,网络深层包含更多的语义信息. 在DDSCNet[8 ] 、RefineNet[4 ] 网络中,通过较密集的不同深浅层特征的融合来进一步提高网络的性能,但会使得网络的参数量和计算量增大,并且较密集的特征融合也存在一定程度的特征冗余. ...
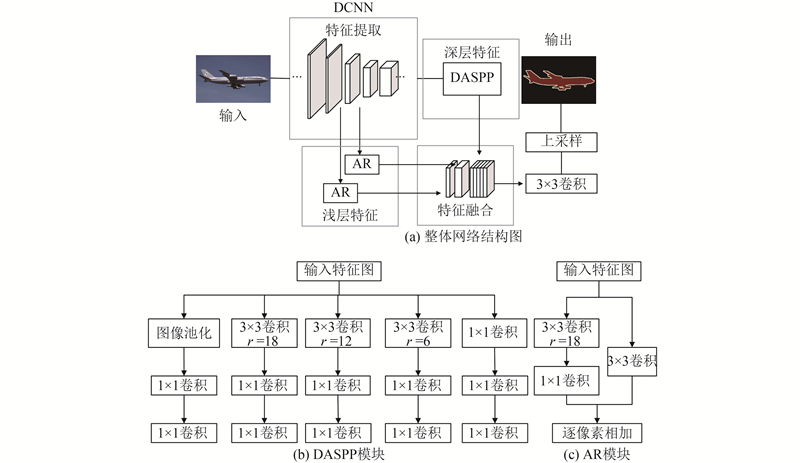
... Zeiler等[9 ] 指出,在深度卷积神经网络中,浅层特征包含低级边缘轮廓信息,深层特征具有丰富的语义信息. DDSCNet[8 ] 、Refinenet[4 ] 网络结构证明具有较好融合性能的特征融合结构都融合了特征提取网络的不同阶段的浅层和深层特征. 本研究算法在考虑网络的参数量和性能后,设计实现了轻量级的特征融合结构,如图2(a) 所示. 通过对比实验选取2个下采样阶段的浅层特征(shallow features)和最终的深层特征(deep features),在融合时浅层特征和深层特征根据特征的深浅设置不同的维度,特征对应的网络深度越深,设置的维度越大,不同特征层的维度逐层递加. 在具有较小参数量的同时更好地保留了各层不同等级的语义和位置信息,能够更好地对图像中不同大小规模的目标物体进行识别和定位. 此外,DASPP和AR模块主要是分别对深层和浅层特征进行处理,有针对性的根据不同层次等级的特征进行处理,更有利于特征融合时保留浅层特征的边缘轮廓信息和深层的丰富的语义信息. ...
Pyramid scene parsing network
3
2017(1)
... 深度卷积神经网络(deep convolutional neural network,DCNN)在计算机图像理解任务上有较高的准确度,但这些网络准确度的提高通常依靠加深网络深度、扩宽网络维度来实现,普遍具有计算速度较慢、资源开销较大的问题. 这一问题在计算密集型任务—图像语义分割中尤为严重. 语义分割是图像理解的核心任务,是计算机视觉最基础的问题之一. 语义分割任务要求对图像中的每个像素预测标签,可以视作图像的密集分类问题. 当前的语义分割网络大多基于全卷积网络[1 ] (fully convolutional network,FCN)实现,网络性能的提高大多以计算量和参数量的急剧增高为代价. 以当前具有高性能的DeepLabv3+[2 ] 语义分割模型为例,整个网络需要4461万参数量和8677亿次乘加计算量,使其在许多具有实时性要求的语义分割应用场景,如自动驾驶、机器人视觉、增强现实等领域中具有局限性. DeepLab[3 ] 、RefineNet[4 ] 、PSPNet[5 ] 等高性能的语义分割网络对硬件设备也具有较高的要求,并且具有较差的实时性,不适用于存储资源和计算能力有限的可移动式设备. ...
... 1)空间金字塔系列. He等[10 ] 在目标检测网络R-CNN中提出空间金字塔池化(spatial pyramid pooling,SPP),用不同尺寸的池化层来感受不同规模的语义特征信息. PSPNet[5 ] 、DeepLab[3 ] 方法都引入了SPP来整合多尺度的语义信息,证明了SPP在语义分割领域中的优良性质. 其中,PSPNet在网络的最后加入SPP模块,网络最后的深层特征包含了较全面的语义特征信息,不同感受野大小的池化层能更好地理解该语义特征信息中不同尺寸规模的物体,更有助于对语义信息做出更精准的识别. 在DeepLabv3[11 ] 中提出空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),在SPP的基础上加入不同尺度的空洞卷积,进一步加强该模块对不同规模大小物体的识别,并在实验中取得了较好的性能效果. 本研究所提出的DASPP结构对ASPP进行加深处理,进一步聚合不同尺寸的语义信息. ...
... Performance and speed comparison with different baseline networks on Cityscapes validation set
Tab.2 方法 基准网络 T 0 / ms mIoU / % ENet[19 ] ENet 261 58.3 SQ[20 ] SqueezeNet[21 ] 781 59.8 ShuffleNetV2[22 ] ShuffleNetv2 45 67.7 ICNet[23 ] PSPNet50[5 ] 176 70.2 本研究算法 mobileNetv2 18 70.6
图 3 网络中的bottleneck结构图 ...
1
... Chollet等[6 -7 ] 提出深度可分离卷积,证明其在保持卷积性能的同时能有效减少计算量. 此外,在深度方向上的逐点卷积能在聚合维度信息的同时减少网络的内存占有量和计算量. 在减少网络内存占有量和计算量的同时,如何保证网络的性能也是至关重要的问题. FCN最先实现了端到端的语义分割网络结构,有一定的启发作用,同时也存在须继续思考的问题. 在FCN中,32倍下采样导致原图的语义和位置信息损失过多,预测结果较粗糙. 不过,FCN中引入了跳跃连接结构,指出为了实现更好的性能要注意网络中不同深浅层特征的融合. 通常,网络浅层包含更多的位置信息,网络深层包含更多的语义信息. 在DDSCNet[8 ] 、RefineNet[4 ] 网络中,通过较密集的不同深浅层特征的融合来进一步提高网络的性能,但会使得网络的参数量和计算量增大,并且较密集的特征融合也存在一定程度的特征冗余. ...
1
... Chollet等[6 -7 ] 提出深度可分离卷积,证明其在保持卷积性能的同时能有效减少计算量. 此外,在深度方向上的逐点卷积能在聚合维度信息的同时减少网络的内存占有量和计算量. 在减少网络内存占有量和计算量的同时,如何保证网络的性能也是至关重要的问题. FCN最先实现了端到端的语义分割网络结构,有一定的启发作用,同时也存在须继续思考的问题. 在FCN中,32倍下采样导致原图的语义和位置信息损失过多,预测结果较粗糙. 不过,FCN中引入了跳跃连接结构,指出为了实现更好的性能要注意网络中不同深浅层特征的融合. 通常,网络浅层包含更多的位置信息,网络深层包含更多的语义信息. 在DDSCNet[8 ] 、RefineNet[4 ] 网络中,通过较密集的不同深浅层特征的融合来进一步提高网络的性能,但会使得网络的参数量和计算量增大,并且较密集的特征融合也存在一定程度的特征冗余. ...
2
... Chollet等[6 -7 ] 提出深度可分离卷积,证明其在保持卷积性能的同时能有效减少计算量. 此外,在深度方向上的逐点卷积能在聚合维度信息的同时减少网络的内存占有量和计算量. 在减少网络内存占有量和计算量的同时,如何保证网络的性能也是至关重要的问题. FCN最先实现了端到端的语义分割网络结构,有一定的启发作用,同时也存在须继续思考的问题. 在FCN中,32倍下采样导致原图的语义和位置信息损失过多,预测结果较粗糙. 不过,FCN中引入了跳跃连接结构,指出为了实现更好的性能要注意网络中不同深浅层特征的融合. 通常,网络浅层包含更多的位置信息,网络深层包含更多的语义信息. 在DDSCNet[8 ] 、RefineNet[4 ] 网络中,通过较密集的不同深浅层特征的融合来进一步提高网络的性能,但会使得网络的参数量和计算量增大,并且较密集的特征融合也存在一定程度的特征冗余. ...
... Zeiler等[9 ] 指出,在深度卷积神经网络中,浅层特征包含低级边缘轮廓信息,深层特征具有丰富的语义信息. DDSCNet[8 ] 、Refinenet[4 ] 网络结构证明具有较好融合性能的特征融合结构都融合了特征提取网络的不同阶段的浅层和深层特征. 本研究算法在考虑网络的参数量和性能后,设计实现了轻量级的特征融合结构,如图2(a) 所示. 通过对比实验选取2个下采样阶段的浅层特征(shallow features)和最终的深层特征(deep features),在融合时浅层特征和深层特征根据特征的深浅设置不同的维度,特征对应的网络深度越深,设置的维度越大,不同特征层的维度逐层递加. 在具有较小参数量的同时更好地保留了各层不同等级的语义和位置信息,能够更好地对图像中不同大小规模的目标物体进行识别和定位. 此外,DASPP和AR模块主要是分别对深层和浅层特征进行处理,有针对性的根据不同层次等级的特征进行处理,更有利于特征融合时保留浅层特征的边缘轮廓信息和深层的丰富的语义信息. ...
2
... 通过对上述问题的综合考虑,本研究提出基于多级特征并联的轻量级图像语义分割网络模型,模型的设计更好的权衡了网络性能和网络的参数量、计算量. 在网络中引入深度可分离卷积和逐点卷积来减少网络的参数和计算量;提出更精简高效的特征融合结构,提出空洞残差增强(atrous residual feature refine,AR)模块和深度空洞空间金字塔池化(deep atrous spatial pyramid pooling,DASPP)模块,加强浅层的全局位置特征和深层的语义特征,使有限的特征图能够表达出更强的特征信息;在特征融合时根据深层网络中不同深浅层特征的可视化规律[9 ] 来设置浅层和深层特征的维度,更好地兼顾网络中不同层次的语义和位置信息. ...
... Zeiler等[9 ] 指出,在深度卷积神经网络中,浅层特征包含低级边缘轮廓信息,深层特征具有丰富的语义信息. DDSCNet[8 ] 、Refinenet[4 ] 网络结构证明具有较好融合性能的特征融合结构都融合了特征提取网络的不同阶段的浅层和深层特征. 本研究算法在考虑网络的参数量和性能后,设计实现了轻量级的特征融合结构,如图2(a) 所示. 通过对比实验选取2个下采样阶段的浅层特征(shallow features)和最终的深层特征(deep features),在融合时浅层特征和深层特征根据特征的深浅设置不同的维度,特征对应的网络深度越深,设置的维度越大,不同特征层的维度逐层递加. 在具有较小参数量的同时更好地保留了各层不同等级的语义和位置信息,能够更好地对图像中不同大小规模的目标物体进行识别和定位. 此外,DASPP和AR模块主要是分别对深层和浅层特征进行处理,有针对性的根据不同层次等级的特征进行处理,更有利于特征融合时保留浅层特征的边缘轮廓信息和深层的丰富的语义信息. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2014
... 1)空间金字塔系列. He等[10 ] 在目标检测网络R-CNN中提出空间金字塔池化(spatial pyramid pooling,SPP),用不同尺寸的池化层来感受不同规模的语义特征信息. PSPNet[5 ] 、DeepLab[3 ] 方法都引入了SPP来整合多尺度的语义信息,证明了SPP在语义分割领域中的优良性质. 其中,PSPNet在网络的最后加入SPP模块,网络最后的深层特征包含了较全面的语义特征信息,不同感受野大小的池化层能更好地理解该语义特征信息中不同尺寸规模的物体,更有助于对语义信息做出更精准的识别. 在DeepLabv3[11 ] 中提出空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),在SPP的基础上加入不同尺度的空洞卷积,进一步加强该模块对不同规模大小物体的识别,并在实验中取得了较好的性能效果. 本研究所提出的DASPP结构对ASPP进行加深处理,进一步聚合不同尺寸的语义信息. ...
1
... 1)空间金字塔系列. He等[10 ] 在目标检测网络R-CNN中提出空间金字塔池化(spatial pyramid pooling,SPP),用不同尺寸的池化层来感受不同规模的语义特征信息. PSPNet[5 ] 、DeepLab[3 ] 方法都引入了SPP来整合多尺度的语义信息,证明了SPP在语义分割领域中的优良性质. 其中,PSPNet在网络的最后加入SPP模块,网络最后的深层特征包含了较全面的语义特征信息,不同感受野大小的池化层能更好地理解该语义特征信息中不同尺寸规模的物体,更有助于对语义信息做出更精准的识别. 在DeepLabv3[11 ] 中提出空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),在SPP的基础上加入不同尺度的空洞卷积,进一步加强该模块对不同规模大小物体的识别,并在实验中取得了较好的性能效果. 本研究所提出的DASPP结构对ASPP进行加深处理,进一步聚合不同尺寸的语义信息. ...
2
... 2)空洞卷积. 语义分割通过微调分类网络实现,但由于分类网络须不断扩大感受野、聚合语境信息,存在较多池化层使原图像分辨率下降,损失位置和密集语义信息. 空洞卷积可以用来代替部分池化层,在聚合语义信息的同时保留图像分辨率. 另外,空洞卷积还可以用来增大网络的有效感受野. Yu等[12 ] 最早提出空洞卷积,通过在标准卷积核之间进行零插值来增大有效感受野. DeepLab[3 ] 方法对空洞卷积的应用进一步证明空洞卷积的优良性能. 空洞卷积与标准卷积相比具有更大的有效感受野. ...
... Comparison of network performance of proposed model and other high-performance semantic segmentation methods on Cityscapes test set
Tab.9 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % SegNet[24 ] 60 16.70 57.0 CRF-RCNN[25 ] 700 1.43 62.5 DeepLab[3 ] 400 2.50 63.1 FCN-8s[1 ] 500 2.00 65.3 Dilation[12 ] 4000 0.25 67.1 DeepLabv3+[2 ] 350 2.86 82.1 本研究算法 18 55.60 70.6
将本研究算法与当前表现较好的实时语义分割算法进行对比,如表10 所示. 可以看出,本研究算法在具有较好的实时性同时也具有较高的性能. 本研究算法中的特征融合结构,在保证轻量级的同时,融合了深层和浅层的特征,更好地获取了网络中不同深浅层位置的语义信息和位置信息,取得了较好的性能效果. ...
1
... 当前较高性能的语义分割网络通常具有较复杂的特征融合结构,在取得较好性能的同时往往以巨大的计算开销为代价. 本研究提出轻量级的基于多级特征并联的语义分割网络. 该网络主要由特征提取和特征融合两部分组成,将轻量级MobileNetv2[13 ] 作为特征提取基准网络,特征融合部分由所提出的DASPP和AR模块组成,这2个模块分别处理来自特征提取基准网络中的深层特征和浅层特征,最后按特定维度比例以并联的方式进行融合. 所提方法在保证较高性能的同时避免复杂特征融合结构所带来的大参数量问题. ...
ImageNet large scale visual recognition challenge
1
2015
... 本研究所提方法通过微调MobileNetv2网络进行特征提取,基于ImageNet-1k[14 ] 上预训练[15 -16 ] 的MobileNetv2网络模型,调整网络结构进行训练,应用TensorFlow深度学习框架实现,实验环境为单块GeForce GTX TITAN X显卡. ...
1
... 本研究所提方法通过微调MobileNetv2网络进行特征提取,基于ImageNet-1k[14 ] 上预训练[15 -16 ] 的MobileNetv2网络模型,调整网络结构进行训练,应用TensorFlow深度学习框架实现,实验环境为单块GeForce GTX TITAN X显卡. ...
Learning hierarchical features for scene labeling
1
2013
... 本研究所提方法通过微调MobileNetv2网络进行特征提取,基于ImageNet-1k[14 ] 上预训练[15 -16 ] 的MobileNetv2网络模型,调整网络结构进行训练,应用TensorFlow深度学习框架实现,实验环境为单块GeForce GTX TITAN X显卡. ...
The pascal visual object classes challenge: a retrospective
1
2015
... 所提方法在语义分割领域通用的数据集PASCAL VOC 2012[17 ] 和Cityscapes[18 ] 上进行训练、验证和测试. PASCAL VOC数据集共包括21个类,其中包括20个目标类和1个背景类,由1 464张训练集图片、1449张验证集图片和1456张测试集图片组成;Cityscapes 为城市街景图,包含2 975张训练集图片、500张验证集图片和1525张测试集图片. 以上数据集的测试集图片的真实标签官方没有公布,须上传预测好的分割图像到服务器对精确度进行测试. 语义分割性能的客观评价指标为平均交并比(mean Intersection over Union,mIoU),mIoU的表达式为 ...
1
... 所提方法在语义分割领域通用的数据集PASCAL VOC 2012[17 ] 和Cityscapes[18 ] 上进行训练、验证和测试. PASCAL VOC数据集共包括21个类,其中包括20个目标类和1个背景类,由1 464张训练集图片、1449张验证集图片和1456张测试集图片组成;Cityscapes 为城市街景图,包含2 975张训练集图片、500张验证集图片和1525张测试集图片. 以上数据集的测试集图片的真实标签官方没有公布,须上传预测好的分割图像到服务器对精确度进行测试. 语义分割性能的客观评价指标为平均交并比(mean Intersection over Union,mIoU),mIoU的表达式为 ...
2
... Performance and speed comparison with different baseline networks on Cityscapes validation set
Tab.2 方法 基准网络 T 0 / ms mIoU / % ENet[19 ] ENet 261 58.3 SQ[20 ] SqueezeNet[21 ] 781 59.8 ShuffleNetV2[22 ] ShuffleNetv2 45 67.7 ICNet[23 ] PSPNet50[5 ] 176 70.2 本研究算法 mobileNetv2 18 70.6
图 3 网络中的bottleneck结构图 ...
... Comparison of proposed model and other real-time semantic segmentation methods on Cityscapes test set
Tab.10 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % ENet[19 ] 13 76.9 58.3 ERFNet[26 ] 89 11.2 69.7 本研究算法 18 55.6 70.6
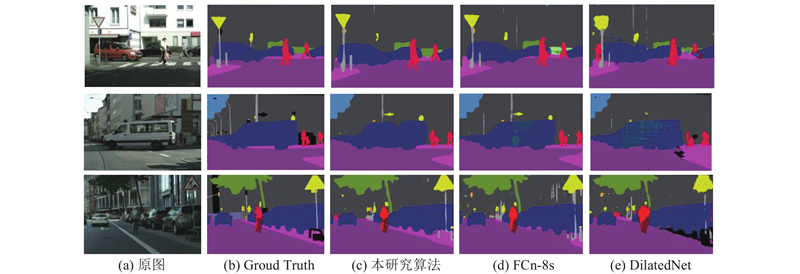
通过如图4 、5 所示的可视化对比,可以看出本研究算法在语义分割常用数据集Cityscapes和PASCAL VOC 2012上能够更好地识别图像的细节和轮廓信息,具有更好的可视化效果. ...
1
... Performance and speed comparison with different baseline networks on Cityscapes validation set
Tab.2 方法 基准网络 T 0 / ms mIoU / % ENet[19 ] ENet 261 58.3 SQ[20 ] SqueezeNet[21 ] 781 59.8 ShuffleNetV2[22 ] ShuffleNetv2 45 67.7 ICNet[23 ] PSPNet50[5 ] 176 70.2 本研究算法 mobileNetv2 18 70.6
图 3 网络中的bottleneck结构图 ...
1
... Performance and speed comparison with different baseline networks on Cityscapes validation set
Tab.2 方法 基准网络 T 0 / ms mIoU / % ENet[19 ] ENet 261 58.3 SQ[20 ] SqueezeNet[21 ] 781 59.8 ShuffleNetV2[22 ] ShuffleNetv2 45 67.7 ICNet[23 ] PSPNet50[5 ] 176 70.2 本研究算法 mobileNetv2 18 70.6
图 3 网络中的bottleneck结构图 ...
1
... Performance and speed comparison with different baseline networks on Cityscapes validation set
Tab.2 方法 基准网络 T 0 / ms mIoU / % ENet[19 ] ENet 261 58.3 SQ[20 ] SqueezeNet[21 ] 781 59.8 ShuffleNetV2[22 ] ShuffleNetv2 45 67.7 ICNet[23 ] PSPNet50[5 ] 176 70.2 本研究算法 mobileNetv2 18 70.6
图 3 网络中的bottleneck结构图 ...
1
... Performance and speed comparison with different baseline networks on Cityscapes validation set
Tab.2 方法 基准网络 T 0 / ms mIoU / % ENet[19 ] ENet 261 58.3 SQ[20 ] SqueezeNet[21 ] 781 59.8 ShuffleNetV2[22 ] ShuffleNetv2 45 67.7 ICNet[23 ] PSPNet50[5 ] 176 70.2 本研究算法 mobileNetv2 18 70.6
图 3 网络中的bottleneck结构图 ...
SegNet: a deep convolutional encoder-decoder architecture for scene segmentation
1
2017
... Comparison of network performance of proposed model and other high-performance semantic segmentation methods on Cityscapes test set
Tab.9 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % SegNet[24 ] 60 16.70 57.0 CRF-RCNN[25 ] 700 1.43 62.5 DeepLab[3 ] 400 2.50 63.1 FCN-8s[1 ] 500 2.00 65.3 Dilation[12 ] 4000 0.25 67.1 DeepLabv3+[2 ] 350 2.86 82.1 本研究算法 18 55.60 70.6
将本研究算法与当前表现较好的实时语义分割算法进行对比,如表10 所示. 可以看出,本研究算法在具有较好的实时性同时也具有较高的性能. 本研究算法中的特征融合结构,在保证轻量级的同时,融合了深层和浅层的特征,更好地获取了网络中不同深浅层位置的语义信息和位置信息,取得了较好的性能效果. ...
1
... Comparison of network performance of proposed model and other high-performance semantic segmentation methods on Cityscapes test set
Tab.9 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % SegNet[24 ] 60 16.70 57.0 CRF-RCNN[25 ] 700 1.43 62.5 DeepLab[3 ] 400 2.50 63.1 FCN-8s[1 ] 500 2.00 65.3 Dilation[12 ] 4000 0.25 67.1 DeepLabv3+[2 ] 350 2.86 82.1 本研究算法 18 55.60 70.6
将本研究算法与当前表现较好的实时语义分割算法进行对比,如表10 所示. 可以看出,本研究算法在具有较好的实时性同时也具有较高的性能. 本研究算法中的特征融合结构,在保证轻量级的同时,融合了深层和浅层的特征,更好地获取了网络中不同深浅层位置的语义信息和位置信息,取得了较好的性能效果. ...
ERFNet: efficient residual factorized convNet for real-time semantic segmentation
1
2018
... Comparison of proposed model and other real-time semantic segmentation methods on Cityscapes test set
Tab.10 方法 T 0 / ms N f / (帧·s−1 ) mIoU / % ENet[19 ] 13 76.9 58.3 ERFNet[26 ] 89 11.2 69.7 本研究算法 18 55.6 70.6
通过如图4 、5 所示的可视化对比,可以看出本研究算法在语义分割常用数据集Cityscapes和PASCAL VOC 2012上能够更好地识别图像的细节和轮廓信息,具有更好的可视化效果. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}