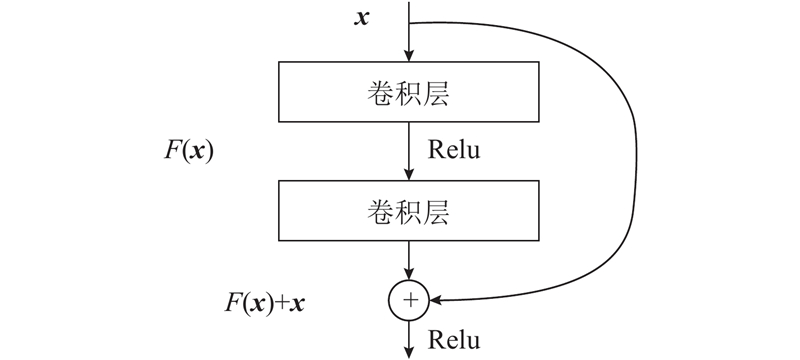
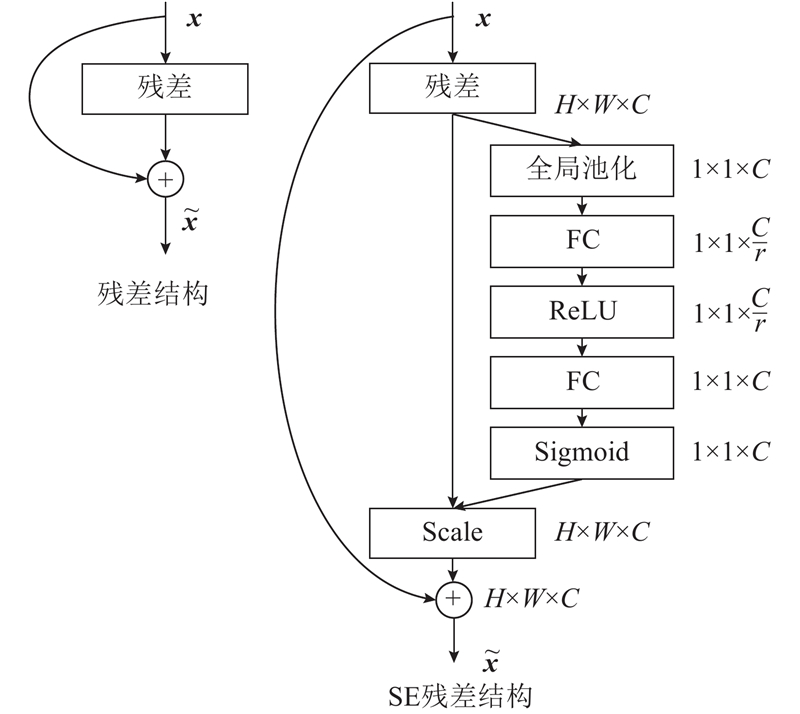
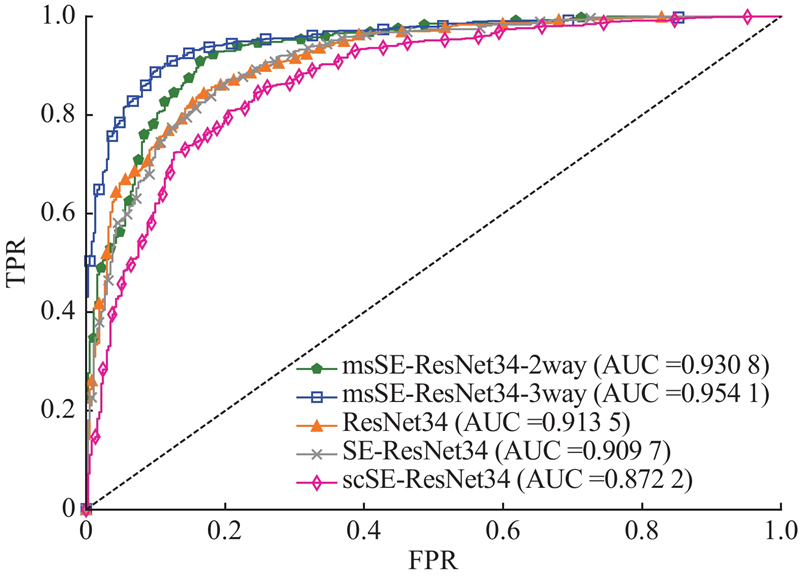
A deep learning-based classification algorithm was proposed aiming at the problem of automatic classification algorithms focusing on breast cancer histopathological images. Channel squeeze-and-excitation (SE) model is an attention model applied to the feature channels. Useless features can be suppressed with learned channel weights so as to recalibrate the feature channels for better classification accuracy. A multi-scale channel SE model was proposed, and a convolutional neural network named msSE-ResNet was designed in order to make the result of channel recalibration more accurate. Multi-scale features were obtained by max-pooling layers and served as inputs to subsequent channel SE models, and the result of channel recalibration was improved by merging channel weights learned under different feature scales. Experiments were conducted on public dataset BreaKHis. Results show that the network can reach an accuracy of 88.87% on the task of classifying benign/malignant breast histopathological images, and can remain good robustness to histopathological images acquired under different magnifications.
Keywords:breast cancer histopathological image classification
;
deep learning
;
residual network
;
multi-scale feature
;
channel squeeze-and-excitation model
MING Tao, WANG Dan, GUO Ji-chang, LI Qiang. Breast cancer histopathological image classification using multi-scale channel squeeze-and-excitation model. Journal of Zhejiang University(Engineering Science)[J], 2020, 54(7): 1289-1297 doi:10.3785/j.issn.1008-973X.2020.07.006
GUPTA V, BHAVSAR A. Breast cancer histopathological image classification: is magnification important? [C] // Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu, USA: IEEE, 2017: 769-776.
CIRESAN D C, GIUSTI A, GAMBARDELLA L M, et al. Mitosis detection in breast cancer histology images with deep neural networks [C] // Proceedings of Medical Image Computing and Computer-Assisted Intervention. Berlin, German: Springer, 2013: 411-418.
SPANHOL F A, OLIVEIRA L S, PETITJEAN C, et al. Breast cancer histopathological image classification using convolutional neural networks [C] // Proceedings of International Joint Conference on Neural Networks. Vancouver, Canada: IEEE, 2016: 2560-2567.
BAYRAMOGLU N, KANNALA J, HEIKKILÄ J. Deep learning for magnification independent breast cancer histopathology image classification [C] // Proceedings of International Conference on Pattern Recognition. Cancun, Mexico: IEEE, 2016: 2441-2446.
SONG Y, ZOU J J, CHANG H, et al. Adapting Fisher vectors for histopathology image classification [C] // Proceedings of the IEEE 14th International Symposium on Biomedical Imaging. Melbourne: IEEE, 2017: 600-603.
HU J, SHEN L, SUN G. Squeeze-and-Excitation network [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141.
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 770-778.
BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. [2019–03–01]. https://arxiv.org/abs/1409.0473.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of Neural Information Processing Systems. Long Beach, USA: Curran Associates, Inc., 2017: 5998-6008.
WANG F, JIANG M, QIAN C, et al. Residual attention network for image classification [C] // Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 6450-6458.
ZHU Y Y, WANG J, XIE L X, et al. Attention-based pyramid aggregation network for visual place recognition [C] // Proceedings of International Conference on Multimedia. Seoul, Korea: ACM, 2018: 99-107.
SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C] // Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 1-9.
NAIR V, HINTON G E. rectified linear units improve restricted Boltzmann machine [C] // International Conference on International Conference on Machine Learning. Haifa, Israel: Omnipress, 2010: 807-814.
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C] // Proceedings of European Conference on Computer Vision. Amsterdam: Springer, 2016: 21-37.
LIN T, DOLLAR P, GIRSHICK R. Feature pyramid networks for object detection [C] // Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2117-2125.
ZHAO H, SHI J, QI X, et el. Pyramid scene parsing network [C] // Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6230-6239.
ZHAO H, QI X, SHEN X, et al. ICNet for real-time semantic segmentation on high-resolution images [C] // Proceedings of European Conference on Computer Vision. Munich, Germany: Springer, 2018: 418-434.
KAMNITASA K, LEDIG C, NEWCOMBE V F, et al
Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation
PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performing deep learning library [C] // Proceedings of Neural Information Processing Systems. Vancouver: Curran Associates, Inc., 2019: 8024-8035.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}