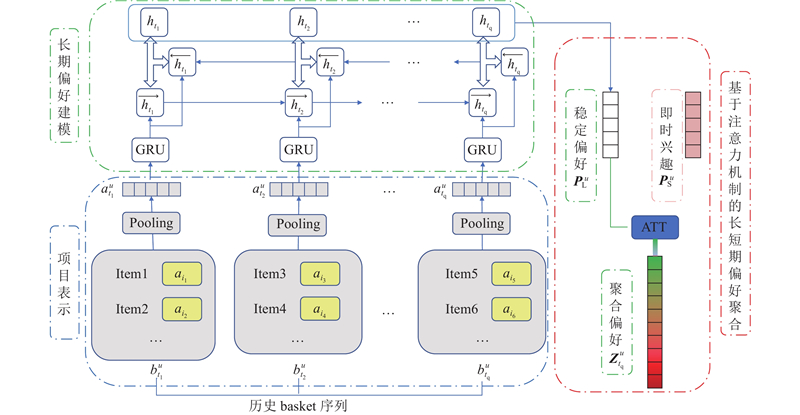
The user’s stable long-term preferences and dynamic instant interests were obtained by modeling on the user’s historical behavior records, and the user preferences were aggregated for personalized recommendation. Firstly, the users’ reviews on the items were extracted to represent the characteristics of the items. Secondly, users’ historical behavior records were used to represent their stable long-term preferences, and query data was used to model their instant interests. Third, the user’s final preferences were aggregated by assigning different weights to the long-term preferences and instant interests through the attention mechanism. Experiments on real data sets of Amazon were conducted to evaluate the performance of SeqRec model, and results show that it is superior to the current state-of-the-art sequential recommendation methods more than 10% in recall rate and percision ratio. Meanwhile, SeqRec model proves that the long-term preferences and instant interests of different users have different influences on their next purchases.
KARATZOGLOU A, BALTRUNAS L, SHI Y. Learning to rank for recommender systems [C] // Proceedings of the 7th ACM Conference on Recommender Systems. Hong Kong: ACM, 2013: 493-494.
KOREN Y. Collaborative filtering with temporal dynamics [C] // Proceedings of the 15th ACM SIGKDD international Conference on Knowledge Discovery and Data Mining. Pairs: ACM, 2009: 447-456.
LIU Q, ZENG X Y, ZHU H S, et al. Mining indecisiveness in customer behaviors [C] // 2015 IEEE International Conference on Data Mining. Atlantic City: IEEE, 2015: 281-290.
ZHANG F Z, YUAN N J, Lian D F, et al. Collaborative knowledge base embedding for recommender systems [C] // Proceedings of the 22nd ACM SIGKDD international Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 353-362.
YAP G E, LI X L, PHILIP S Y. Effective next-items recommendation via personalized sequential pattern mining [C] // International Conference on Database Systems for advanced applications. Berlin: Springer, 2012: 48-64.
GRBOVIC M, RADOSAVLJEVIC V, DJURIC N, et al. E-commerce in your inbox: product recommendations at scale [C] // Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 1809-1818.
DONG D S, ZHENG X L, ZHANG R X, et al. Recurrent collaborative filtering for unifying general and sequential recommender [C] // International Joint Conferences on Artificial Intelligence. Stockholm: IJCAI, 2018: 3350–3356.
NIU S Z, ZHANG R Z. Collaborative sequence prediction for sequential recommender [C] // Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. Singapore: ACM, 2017: 2239-2242.
YU F, LIU Q, WU S, et al. A dynamic recurrent model for next basket recommendation [C] // Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval. Pisa: ACM, 2016: 729-732.
ZHANG Y Y, DAI H J, XU C, et al. Sequential click prediction for sponsored search with recurrent neural networks [C] // Twenty-Eighth AAAI Conference on Artificial Intelligence. Québec: AAAI, 2014.
MNIH A, SALAKHUTDINOV R R. Probabilistic matrix factorization [C] // In Advances in Neural Information Processing Systems. Vancouver: NIPS, 2008, 1257–1264.
BELL R M, KOREN Y. Scalable collaborative filtering with jointly derived neighborhood interpolation weights [C] // Seventh IEEE International Conference on Data Mining. Omaha: IEEE, 2007: 43-52.
WANG J, TANG Q. A probabilistic view of neighborhood-based recommendation methods [C] // 2016 IEEE 16th International Conference on Data Mining Workshops. Barcelona: IEEE, 2016: 14-20.
ZHAO H K, LIU Q, GE Y, et al. Group preference aggregation: a nash equilibrium approach [C] // 2016 IEEE 16th International Conference on Data Mining. Barcelona: IEEE, 2016: 679-688.
TANG J X, WANG K. Personalized top-n sequential recommendation via convolutional sequence embedding [C] // Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. Los Angeles: ACM, 2018: 565-573.
HE X N, LIAO L Z, ZHANG H W, et al. Neural collaborative filtering [C] // Proceedings of the 26th International Conference on World Wide Web. Switzerland: ACM, 2017: 173-182.
RENDLE S, FREUDENTHALER C, SCHMDITHIEME L. Factorizing personalized Markov chains for next-basket recommendation [C] // In Proceedings of the 19th international conference on World Wide Web. Raleigh: ACM, 811–820.
WANG P F, GUO J F, LAN Y Y, et al. Learning hierarchical representation model for next basket recommendation [C] // Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2015: 403-412.
LI J, REN P J, CHEN Z M, et al. Neural attentive session-based recommendation [C] // Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. Singapore: ACM, 2017: 1419-1428.
HE R N, MCAULEY J. Ups and downs: modeling the visual evolution of fashion trends with one-class collaborative filtering [C] // Proceedings of the 25th international Conference on World Wide Web. Montreal: ACM, 2016: 507-517.




{kind=link}
{kind=link}
{kind=link}
{kind=link}