[1]
RAYNER K Eye movements in reading and information processing: 20 years of research
[J]. Psychological Bulletin , 1998 , 124 (3 ): 372 - 422
DOI:10.1037/0033-2909.124.3.372
[本文引用: 1]
[2]
范琳, 刘振前 阅读理解过程的眼动研究
[J]. 外语与外语教学 , 2007 , (4 ): 38 - 43
[本文引用: 1]
FAN Lin, LIU Zhen-qian A study on eye movement in reading comprehension
[J]. Foreign Languages and Their Teaching , 2007 , (4 ): 38 - 43
[本文引用: 1]
[3]
RIGAS I, FRIEDMAN L, KOMOGORTSEV O. A study on the extraction and analysis of a large set of eye movement features during reading [J]. arXiv Preprint : 1703.09167, 2017.
[本文引用: 1]
[4]
NILSSON M, NIVRE J. Learning where to look: modeling eye movements in reading [C] // Thirteenth Conference on Computational Natural Language Learning (CoNLL) , Boulder: Association for Computational Linguistics, 2009: 93-101.
[本文引用: 1]
[5]
HARA T, MOCHIHASHI D, KANO Y, et al. Predicting word fixations in text with a crf model for capturing general reading strategies among readers [C] // Proceedings of the First Workshop on Eye-Tracking and Natural Language Processing . Stroudsburg: ACL, 2012: 55-70.
[本文引用: 1]
[6]
KUNZE K, IWAMURA M, KISE K, et al Activity recognition for the mind: toward a cognitive "Quantified Self"
[J]. Computer , 2013 , 46 (10 ): 105 - 108
DOI:10.1109/MC.2013.339
[本文引用: 1]
[7]
KUNZE K, UTSUMI Y, SHIGA Y, et al. I know what you are reading: recognition of document types using mobile eye tracking [C] // Proceedings of the 2013 International Symposium on Wearable Computers (ISWC) . New York: ACM, 2013: 113-116.
[本文引用: 1]
[8]
BERZAK Y, KATZ B, LEVY R. Assessing language proficiency from eye movements in reading [J]. arXiv Preprint : 1804.07329, 2018.
[本文引用: 1]
[9]
WALLACE R, MCMILLAN C. EyeDoc: documentation navigation with eye tracking [J]. arXiv Preprint : 1903.00040, 2019.
[本文引用: 1]
[10]
DUSSIAS P E Uses of eye-tracking data in second language sentence processing research
[J]. Annual Review of Applied Linguistics , 2010 , 30 : 149 - 166
DOI:10.1017/S026719051000005X
[本文引用: 1]
[11]
CHEN Z, SHI B E Using variable dwell time to accelerate gaze-based web browsing with two-step selection
[J]. International Journal of Human Computer Interaction , 2019 , 35 (3 ): 240 - 255
DOI:10.1080/10447318.2018.1452351
[本文引用: 1]
[12]
CHIRCOP L, RADHAKRISHNAN J, SELENER L, et al. Markitup: crowdsourced collaborative reading [C] // CHI'13 Extended Abstracts on Human Factors in Computing Systems . New York: ACM, 2013: 2567-2572.
[本文引用: 1]
[13]
TASHMAN C S, EDWARDS W K. Active reading and its discontents: the situations, problems and ideas of readers [C] // Proceedings of the SIG-CHI Conference on Human Factors in Computing Systems . New York: ACM, 2011: 2927-2936.
[本文引用: 1]
[14]
BIEDERT R, BUSCHER G, SCHWARZ S, et al. The text 2.0 framework: writing web-based gaze-controlled realtime applications quickly and easily [C] // Proceedings of the 2010 workshop on Eye Gaze in Intelligent Human Machine Interaction . New York: ACM, 2010: 114-117.
[本文引用: 1]
[15]
BUSCHER G, DENGEL A, VAN ELST L, et al. Generating and using gaze-based document annotations [C] // CHI'08 extended abstracts on Human factors in computing systems . New York: ACM, 2008: 3045-3050.
[本文引用: 1]
[17]
KAR A, CORCORAN P A review and analysis of eye-gaze estimation systems, algorithms and performance evaluation methods in consumer platforms
[J]. IEEE Access , 2017 , 5 : 16495 - 16519
DOI:10.1109/ACCESS.2017.2735633
[本文引用: 1]
[18]
ZHANG C, CHI J N, ZHANG Z H, et al Gaze estimation in a gaze tracking system
[J]. Science China Information Sciences , 2011 , 54 (11 ): 2295 - 2306
DOI:10.1007/s11432-011-4243-6
[19]
周小龙, 汤帆扬, 管秋, 等 基于3D人眼模型的视线跟踪技术综述
[J]. 计算机辅助设计与图形学学报 , 2017 , 29 (9 ): 1579 - 1589
DOI:10.3969/j.issn.1003-9775.2017.09.001
[本文引用: 1]
ZHOU Xiao-long, TANG Fan-yang, GUAN Qiu, et al A survey of 3D eye model based gaze tracking
[J]. Journal of Computer-Aided Design and Computer Graphics , 2017 , 29 (9 ): 1579 - 1589
DOI:10.3969/j.issn.1003-9775.2017.09.001
[本文引用: 1]
[20]
金纯, 李娅萍 视线追踪系统中注视点估计方法研究
[J]. 自动化仪表 , 2016 , 37 (5 ): 32 - 35
JIN Chun, LI Ya-ping Estimation method of the fixation point in gaze tracking system
[J]. Process Automation Instrumentation , 2016 , 37 (5 ): 32 - 35
[21]
张昀, 赵荣椿, 赵歆波, 等. 视线跟踪技术的2D和3D方法综述[C] // 第十三届全国信号处理学术年会(CCSP-2007)论文集. 济南: [s. n.], 2007: 223-229.
[本文引用: 2]
ZHANG Yun, ZHAO Rong-chun, ZHAO Xin-bo, et al. A review of 2d and 3d eye gaze tracking techniques [C] // 13rd Signal Processing (CCSP-2007) . Jinan: [s. n.], 2007: 223-229.
[本文引用: 2]
[22]
ZHANG X. Appearance-based gaze estimation in the wild [C] // Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) . Washington: IEEE CS, 2015: 4511-4520.
[本文引用: 1]
[23]
ZHANG X, SUGANO Y, FRITZ M, et al Mpiigaze: real-world dataset and deep appearance-based gaze estimation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 41 (1 ): 162 - 175
[24]
SELA M, XU P, HE J, et al. Gazegan-unpaired adversarial image generation for gaze estimation [J]. arXiv Preprint : 1711.09767, 2017.
[25]
PALMERO C, SELVA J, BAGHERI M A, et al. Recurrent cnn for 3D gaze estimation using appearance and shape cues [J]. arXiv Preprint : 1805.03064, 2018.
[26]
ZHAO T, YAN Y, PENG J, et al Guiding intelligent surveillance system by learning-by-synthesis gaze estimation
[J]. Pattern Recognition Letters , 2019 , 125 : 556 - 562
DOI:10.1016/j.patrec.2019.02.008
[本文引用: 1]
[27]
程时伟, 孙志强 用于移动设备人机交互的眼动跟踪方法
[J]. 计算机辅助设计与图形学学报 , 2014 , (8 ): 1354 - 1361
[本文引用: 1]
CHENG Shi-wei, SUN Zhi-qiang An approach to eye tracking for mobile device based interaction
[J]. Journal of Computer-Aided Design and Computer Graphics , 2014 , (8 ): 1354 - 1361
[本文引用: 1]
[28]
VILLANUEVA A, CABEZA R A novel gaze estimation system with one calibration point
[J]. IEEE Transactions on Systems, Man and Cybernetics, Part B (Cybernetics) , 2008 , 38 (4 ): 1123 - 1138
DOI:10.1109/TSMCB.2008.926606
[本文引用: 1]
[29]
JI Q, ZHU Z, et al Eye and gaze tracking for interactive graphic display
[J]. Machine Vision and Applications , 2004 , 15 (3 ): 139 - 148
[本文引用: 1]
[30]
GUESTRIN E D, EIZENMAN M General theory of remote gaze estimation using the pupil center and corneal reflections
[J]. IEEE transactions on bio-medical engineering , 2006 , 53 (6 ): 1124 - 1133
DOI:10.1109/TBME.2005.863952
[31]
WANG J, YUAN X, LIU Z An extraction method of pupil and corneal reflection centers based on image processing technology
[J]. CAAI Transactions on Intelligent Systems , 2012 , 5
[32]
MORIMOTO C H, MIMICA M R M Eye gaze tracking techniques for interactive applications
[J]. Computer Vision and Image Understanding , 2005 , 98 (1 ): 4 - 24
DOI:10.1016/j.cviu.2004.07.010
[本文引用: 1]
[33]
FISCHLER M A, BOLLES R C Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography
[J]. Communications of the ACM , 1981 , 24 (6 ): 381 - 395
DOI:10.1145/358669.358692
[本文引用: 1]
[34]
王润民, 桑农, 丁丁, 等 自然场景图像中的文本检测综述
[J]. 自动化学报 , 2018 , 44 (12 ): 3 - 31
[本文引用: 1]
WANG Run-Min, SANG Nong, DING Ding, et al Text detection in natural scene image: a survey
[J]. Journal of Automatica Sinica , 2018 , 44 (12 ): 3 - 31
[本文引用: 1]
[35]
LIAO M H, SHI B G, BAI X, et al. Textboxes: a fast text detector with a single deep neural network [C] // Proceedings of the 31st AAAI Conference on Artificial Intelligence . Menlo Park AAAI, 2017: 4161-4167.
[本文引用: 1]
[36]
ZHANG Z, ZHANG C Q, SHEN W, et al. Multi-oriented text detection with fully convolutional network [C] // Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Washington: IEEE CS, 2016: 4159-4167.
[37]
LIU Y L, JIN L W. Deep matching prior network: toward tighter multi-oriented text detection [C] // Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Washington: IEEE CS, 2017: 3454-3461.
[38]
SHI B, BAI X, BELONGIE S. Detecting oriented text in natural images by linking segments [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Washington: IEEE CS, 2017: 2550-2558.
[39]
ZHOU X Y, YAO C, WEN H, et al. EAST: an efficient and accurate scene text detector [C] // Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Washington: IEEE CS, 2017: 2642-2651.
[本文引用: 1]
[40]
OSTU N A threshold selection method from gray-histogram
[J]. IEEE Transactions on Systems, Man, and Cybernetics , 1979 , 9 (1 ): 62 - 66
DOI:10.1109/TSMC.1979.4310076
[本文引用: 1]
[41]
DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C] // IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) . Washington: IEEE CS, 2005, 1: 886-893.
[本文引用: 1]
[42]
DE C, T E, BABU B R, et al Character recognition in natural images
[J]. Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP) , 2009 , 7 : 273 - 280
[本文引用: 1]
[43]
ESTER M, KRIEGEL H P, XU X. A density-based algorithm for discovering clusters in large spatial databases with noise [C] // International Conference on Knowledge Discovery and Data Mining (KDD) . New York: ACM, 1996, 96(34): 226-231.
[本文引用: 1]
[44]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [J]. arXiv Preprint : 1810.04805, 2018.
[本文引用: 1]
[45]
CHOPRA S, AULI M, Rush A M. Abstractive sentence summarization with attentive recurrent neural networks [C] // Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) . San Diego: NAACL, 2016: 93-98.
[本文引用: 1]
[46]
LIN C Y. Rouge: a package for automatic evaluation of summaries [C] // Text Summarization Branches Out . Barcelona: ACL, 2004: 74-81.
[本文引用: 1]
Eye movements in reading and information processing: 20 years of research
1
1998
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
阅读理解过程的眼动研究
1
2007
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
阅读理解过程的眼动研究
1
2007
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
Activity recognition for the mind: toward a cognitive "Quantified Self"
1
2013
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
Uses of eye-tracking data in second language sentence processing research
1
2010
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
Using variable dwell time to accelerate gaze-based web browsing with two-step selection
1
2019
... 眼动行为是视觉过程的直接反应,眼动跟踪作为研究眼动行为的一种重要手段被广泛应用于阅读研究[1 ] . 眼动模式主要包括3种:注视、眼跳和回视,是用户在阅读过程中形成的特定眼动特征[2 ] . 研究人员对眼动特征的提取与分析进行了深入探讨[3 ] . 例如,通过训练模型对阅读过程中的注视点进行预测[4 ] ;通过条件随机场(conditional random field, CRF)的方法预测文章中哪些词将被读者注视[5 ] ;根据读者眼动数据预测阅读的文章字数和文档类型[6 -7 ] 以及评估读者的语言能力[8 ] ;基于眼动数据开发阅读辅助工具,进行文档导航[9 ] ;通过控制眼跳幅度和避免不必要的回视,使读者的注视点处于恰当的位置来提高阅读效率[10 ] ,以及通过眼动方法加快用户对网页的浏览速度[11 ] . ...
1
... 批注能帮助人们标记关键的、难以理解的内容,提高阅读理解程度[12 -13 ] . 例如,Text2.0系统基于眼动行为为相关文本内容创建实时批注[14 ] 或显示阅读时间[15 ] ;利用专家读者的眼动数据可视化批注来提高新手读者的阅读能力[16 ] . 然而这些批注方法和工具在应用场景上存在一些局限性,例如,多适用于电子阅读,不适用于纸质书籍或文档的阅读,便捷性和实用性不足;没有对用户的实际需求进行判定,影响用户体验. ...
1
... 批注能帮助人们标记关键的、难以理解的内容,提高阅读理解程度[12 -13 ] . 例如,Text2.0系统基于眼动行为为相关文本内容创建实时批注[14 ] 或显示阅读时间[15 ] ;利用专家读者的眼动数据可视化批注来提高新手读者的阅读能力[16 ] . 然而这些批注方法和工具在应用场景上存在一些局限性,例如,多适用于电子阅读,不适用于纸质书籍或文档的阅读,便捷性和实用性不足;没有对用户的实际需求进行判定,影响用户体验. ...
1
... 批注能帮助人们标记关键的、难以理解的内容,提高阅读理解程度[12 -13 ] . 例如,Text2.0系统基于眼动行为为相关文本内容创建实时批注[14 ] 或显示阅读时间[15 ] ;利用专家读者的眼动数据可视化批注来提高新手读者的阅读能力[16 ] . 然而这些批注方法和工具在应用场景上存在一些局限性,例如,多适用于电子阅读,不适用于纸质书籍或文档的阅读,便捷性和实用性不足;没有对用户的实际需求进行判定,影响用户体验. ...
1
... 批注能帮助人们标记关键的、难以理解的内容,提高阅读理解程度[12 -13 ] . 例如,Text2.0系统基于眼动行为为相关文本内容创建实时批注[14 ] 或显示阅读时间[15 ] ;利用专家读者的眼动数据可视化批注来提高新手读者的阅读能力[16 ] . 然而这些批注方法和工具在应用场景上存在一些局限性,例如,多适用于电子阅读,不适用于纸质书籍或文档的阅读,便捷性和实用性不足;没有对用户的实际需求进行判定,影响用户体验. ...
面向阅读教学的眼动数据可视化批注方法
1
2017
... 批注能帮助人们标记关键的、难以理解的内容,提高阅读理解程度[12 -13 ] . 例如,Text2.0系统基于眼动行为为相关文本内容创建实时批注[14 ] 或显示阅读时间[15 ] ;利用专家读者的眼动数据可视化批注来提高新手读者的阅读能力[16 ] . 然而这些批注方法和工具在应用场景上存在一些局限性,例如,多适用于电子阅读,不适用于纸质书籍或文档的阅读,便捷性和实用性不足;没有对用户的实际需求进行判定,影响用户体验. ...
面向阅读教学的眼动数据可视化批注方法
1
2017
... 批注能帮助人们标记关键的、难以理解的内容,提高阅读理解程度[12 -13 ] . 例如,Text2.0系统基于眼动行为为相关文本内容创建实时批注[14 ] 或显示阅读时间[15 ] ;利用专家读者的眼动数据可视化批注来提高新手读者的阅读能力[16 ] . 然而这些批注方法和工具在应用场景上存在一些局限性,例如,多适用于电子阅读,不适用于纸质书籍或文档的阅读,便捷性和实用性不足;没有对用户的实际需求进行判定,影响用户体验. ...
A review and analysis of eye-gaze estimation systems, algorithms and performance evaluation methods in consumer platforms
1
2017
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
Gaze estimation in a gaze tracking system
0
2011
基于3D人眼模型的视线跟踪技术综述
1
2017
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
基于3D人眼模型的视线跟踪技术综述
1
2017
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
2
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
... [21 ];2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
2
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
... [21 ];2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
1
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
Mpiigaze: real-world dataset and deep appearance-based gaze estimation
0
2017
Guiding intelligent surveillance system by learning-by-synthesis gaze estimation
1
2019
... 通过眼动跟踪系统进行眼动数据的获取与计算,例如注视点坐标等. 目前研究学者已经提出了多种眼动跟踪方法和计算模型[17 -21 ] :1)从采集的图像中提取人眼特征参数,并结合采集图像时用户眼睛的注视方向或注视点来建立映射模型[21 ] ;2)对眼球建立3D几何模型来估计视轴方向[19 ] ;3)采集大量的眼球外观图像,同时对图像进行标注,然后通过训练深度神经网络模型对用户的视线方向进行估算[22 -26 ] . ...
用于移动设备人机交互的眼动跟踪方法
1
2014
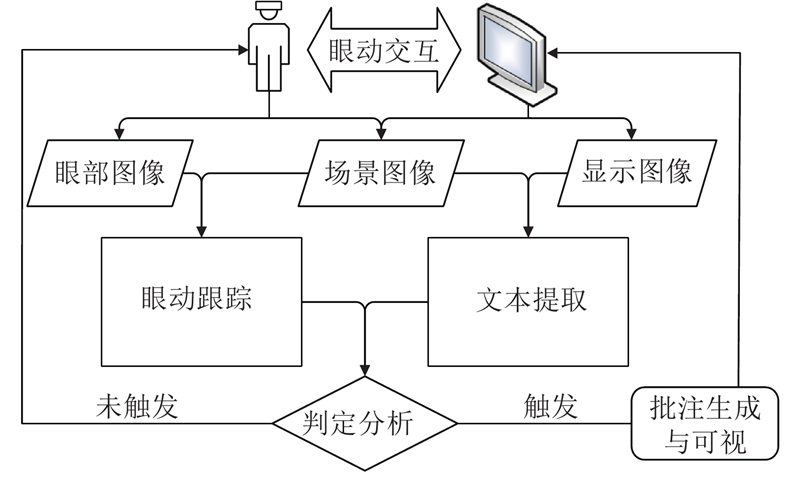
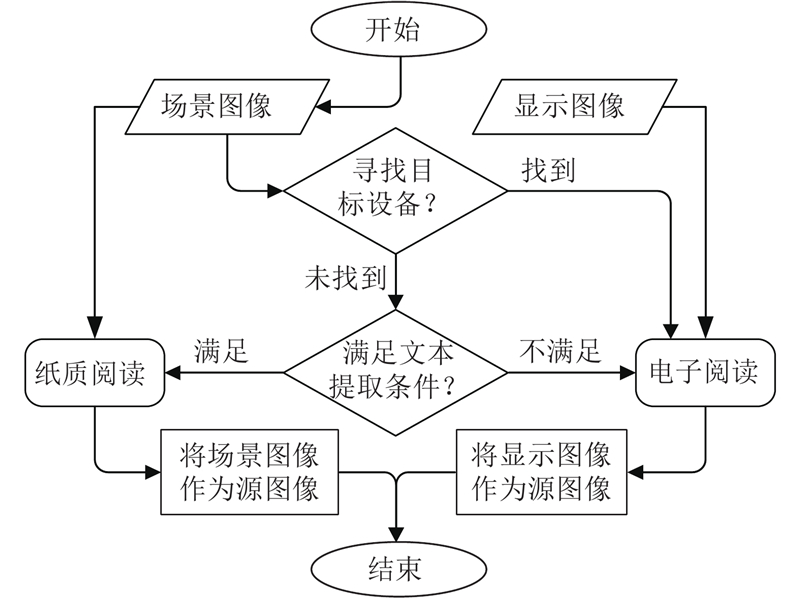
... 为了兼顾眼动跟踪的实时性和精确性,本文采用人眼图像特征映射的方法,在现有眼动跟踪方法的基础上进行优化[27 ] . 具体地,利用瞳孔-普尔钦斑向量(pupil center cornea reflection, PCCR)计算映射模型[28 ] . 在特征提取过程中,一方面对眼部图像提取PCCR向量,通过轮廓形态阈值和椭圆拟合方法获取瞳孔的中心点坐标 $p\;({x_{{p}}},{y_{{p}}})$ $s\;({x_{{s}}},{y_{{s}}})$ ${ v}\;({v_x},{v_y})$ ${{ v}_{{x}}} = {x_{{s}}} - {x_{{p}}}{\text{和}}{{ v}_{{y}}} = {y_{{s}}} - {y_{{p}}}$ . 另一方面寻找场景图像中的屏幕区域,通过Canny算子检测图像边缘信息,由于纸质文档或显示屏幕轮廓类似矩形,通过内、外接矩形面积比和D-P多边形逼近算法即可得到轮廓角点的精确位置. ...
用于移动设备人机交互的眼动跟踪方法
1
2014
... 为了兼顾眼动跟踪的实时性和精确性,本文采用人眼图像特征映射的方法,在现有眼动跟踪方法的基础上进行优化[27 ] . 具体地,利用瞳孔-普尔钦斑向量(pupil center cornea reflection, PCCR)计算映射模型[28 ] . 在特征提取过程中,一方面对眼部图像提取PCCR向量,通过轮廓形态阈值和椭圆拟合方法获取瞳孔的中心点坐标 $p\;({x_{{p}}},{y_{{p}}})$ $s\;({x_{{s}}},{y_{{s}}})$ ${ v}\;({v_x},{v_y})$ ${{ v}_{{x}}} = {x_{{s}}} - {x_{{p}}}{\text{和}}{{ v}_{{y}}} = {y_{{s}}} - {y_{{p}}}$ . 另一方面寻找场景图像中的屏幕区域,通过Canny算子检测图像边缘信息,由于纸质文档或显示屏幕轮廓类似矩形,通过内、外接矩形面积比和D-P多边形逼近算法即可得到轮廓角点的精确位置. ...
A novel gaze estimation system with one calibration point
1
2008
... 为了兼顾眼动跟踪的实时性和精确性,本文采用人眼图像特征映射的方法,在现有眼动跟踪方法的基础上进行优化[27 ] . 具体地,利用瞳孔-普尔钦斑向量(pupil center cornea reflection, PCCR)计算映射模型[28 ] . 在特征提取过程中,一方面对眼部图像提取PCCR向量,通过轮廓形态阈值和椭圆拟合方法获取瞳孔的中心点坐标 $p\;({x_{{p}}},{y_{{p}}})$ $s\;({x_{{s}}},{y_{{s}}})$ ${ v}\;({v_x},{v_y})$ ${{ v}_{{x}}} = {x_{{s}}} - {x_{{p}}}{\text{和}}{{ v}_{{y}}} = {y_{{s}}} - {y_{{p}}}$ . 另一方面寻找场景图像中的屏幕区域,通过Canny算子检测图像边缘信息,由于纸质文档或显示屏幕轮廓类似矩形,通过内、外接矩形面积比和D-P多边形逼近算法即可得到轮廓角点的精确位置. ...
Eye and gaze tracking for interactive graphic display
1
2004
... 面向PCCR的多项式回归是目前最常用的注视点映射模型[29 -32 ] ,其通过最小二乘法求解模型参数的目标函数表达式: ...
General theory of remote gaze estimation using the pupil center and corneal reflections
0
2006
An extraction method of pupil and corneal reflection centers based on image processing technology
0
2012
Eye gaze tracking techniques for interactive applications
1
2005
... 面向PCCR的多项式回归是目前最常用的注视点映射模型[29 -32 ] ,其通过最小二乘法求解模型参数的目标函数表达式: ...
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography
1
1981
... 式中:a 、b 为映射模型参数,m 为样本数, $({p_{{x}}},{p_{{y}}})$ [33 ] 排除噪声数据后再进行拟合计算. 测试结果表明,在采样率为28帧/s、视距为45 cm的情况下,眼动跟踪的平均精度为0.8°(视角). ...
自然场景图像中的文本检测综述
1
2018
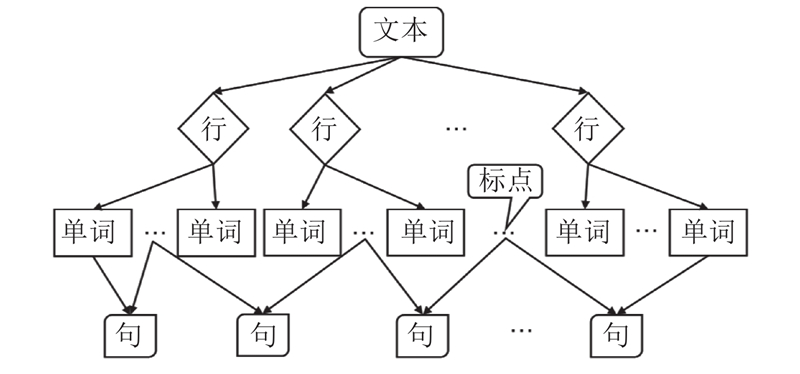
... 文本提取可分为文本检测和文本识别2个步骤. 文本检测主要包括传统文本检测方法和基于深度学习的文本检测方法[34 ] . 近年来,虽然基于深度学习的文本检测方法的性能得到了大幅提升,但仍然存在一些不足,在实时性和精确性上难以满足本文的需求[35 -39 ] . 为此,本文对传统的文本检测方法进行改进,完成文本识别任务,同时结合位置信息构建结构化文本对象树模型,从而快速实现文本的精确提取. 图4 是该方法的流程图,具体说明如下. ...
自然场景图像中的文本检测综述
1
2018
... 文本提取可分为文本检测和文本识别2个步骤. 文本检测主要包括传统文本检测方法和基于深度学习的文本检测方法[34 ] . 近年来,虽然基于深度学习的文本检测方法的性能得到了大幅提升,但仍然存在一些不足,在实时性和精确性上难以满足本文的需求[35 -39 ] . 为此,本文对传统的文本检测方法进行改进,完成文本识别任务,同时结合位置信息构建结构化文本对象树模型,从而快速实现文本的精确提取. 图4 是该方法的流程图,具体说明如下. ...
1
... 文本提取可分为文本检测和文本识别2个步骤. 文本检测主要包括传统文本检测方法和基于深度学习的文本检测方法[34 ] . 近年来,虽然基于深度学习的文本检测方法的性能得到了大幅提升,但仍然存在一些不足,在实时性和精确性上难以满足本文的需求[35 -39 ] . 为此,本文对传统的文本检测方法进行改进,完成文本识别任务,同时结合位置信息构建结构化文本对象树模型,从而快速实现文本的精确提取. 图4 是该方法的流程图,具体说明如下. ...
1
... 文本提取可分为文本检测和文本识别2个步骤. 文本检测主要包括传统文本检测方法和基于深度学习的文本检测方法[34 ] . 近年来,虽然基于深度学习的文本检测方法的性能得到了大幅提升,但仍然存在一些不足,在实时性和精确性上难以满足本文的需求[35 -39 ] . 为此,本文对传统的文本检测方法进行改进,完成文本识别任务,同时结合位置信息构建结构化文本对象树模型,从而快速实现文本的精确提取. 图4 是该方法的流程图,具体说明如下. ...
A threshold selection method from gray-histogram
1
1979
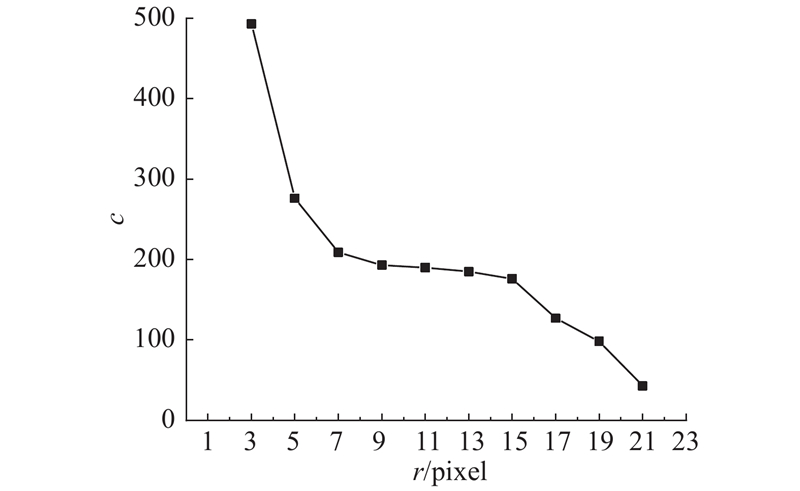
... 为了去除图像噪声,首先对获取的RGB图像进行灰度化处理与3×3的高斯滤波,再采用最大类间方差法和最佳阈值检测法[40 ] 进行前、后景分离. 进一步地为了定位所有单词区域,通过形态学“开”操作和轮廓检测来实现像素级分词. 为使“开”操作将整个单词的轮廓恰好连通,而将不属于一个单词的字符轮廓分离,定义“开”操作的算子大小为n ×n . 如图5 是采用7×7的开算子在3种字符尺度下的测试示例,可以看出,只有图5(b)的示例具有较好的单词连通效果. ...
1
... 对于字符图像分类,本文采用图像特征提取和分类器模型来实现. 具体地,利用梯度方向直方图(histogram of oriented gradient, HOG)提取特征,HOG特征是一种常用的物体检测特征描述子[41 ] ,通过计算和统计图像局部区域的梯度方向直方图来构成特征,其算法流程如下. ...
Character recognition in natural images
1
2009
... 分类器采用支持向量机(supported vector machine, SVM),分类器模型的训练采用Chars74K数据集,Chars74K是一个经典的面向自然图像字符识别的开放数据集[42 ] . 英文手写字符数据集中包含62个类别:52个字符类别(A~Z, a~z)和10个数字类别(0~9),其中有62 992个样本为计算机合成的字体图像,7 705个样本为自然图像. ...
1
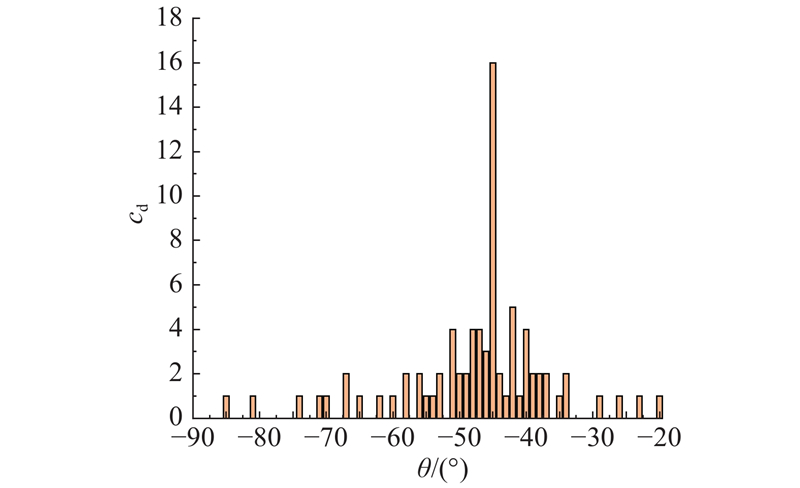
... 进一步地,基于文本方向检测中的中心点与偏移角度集实现像素级分行. 具体地, 将所有单词框的最小包围矩集合看作一个样本空间,每个样本包含3种特征(中心点横坐标x ,中心点纵坐标y ,单词框偏移角度d ),同一行的单词框大多都位于同一偏移轴线上,若单纯以欧氏距离无法正确地区分行,则还需要结合行的偏移方向. 因此,提出一种基于密度空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[43 ] 的行聚类算法. 与采用DBSCAN算法计算欧氏距离不同,提出的行聚类方法定义的距离计算公式为 ...
1
... 本文采用的自动摘要技术最大支持50个单词长度的句子输入,其中word embedding采用BERT预训练模型[44 ] ,摘要生成网络基于biLSTM-Seq2seq-Attention架构[45 ] ,模型训练采用针对文本摘要的DUC2003、DUC2004② ③ [46 ] . 评估结果如表2 所示,其中,R 2 为生成摘要的Rouge-2分数. 从表中可以看出,采用BERT预训练模型作长难句自动摘要的效果比Word2vec与Glove更好. ...
1
... 本文采用的自动摘要技术最大支持50个单词长度的句子输入,其中word embedding采用BERT预训练模型[44 ] ,摘要生成网络基于biLSTM-Seq2seq-Attention架构[45 ] ,模型训练采用针对文本摘要的DUC2003、DUC2004② ③ [46 ] . 评估结果如表2 所示,其中,R 2 为生成摘要的Rouge-2分数. 从表中可以看出,采用BERT预训练模型作长难句自动摘要的效果比Word2vec与Glove更好. ...
1
... 本文采用的自动摘要技术最大支持50个单词长度的句子输入,其中word embedding采用BERT预训练模型[44 ] ,摘要生成网络基于biLSTM-Seq2seq-Attention架构[45 ] ,模型训练采用针对文本摘要的DUC2003、DUC2004② ③ [46 ] . 评估结果如表2 所示,其中,R 2 为生成摘要的Rouge-2分数. 从表中可以看出,采用BERT预训练模型作长难句自动摘要的效果比Word2vec与Glove更好. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}