

近几十年来,越来越多的个性化推荐方法相继被提出,依据模型构建方式可以大致分为3类:基于内容的方法[1]、基于协同过滤的方法[2]和混合推荐方法[3]. 其中,协同过滤推荐算法仅利用评分信息进行推荐,受到工业界与学术界的广泛关注[1]. 依据社交关系理论[4],在社交网络中拥有较强社交关系的用户在某些方面往往具有相似偏好且互相影响,社会化推荐因此引起巨大关注[5-6]. 在社交网络中,用户间是否存在社交关系往往依赖于用户之间是否相互信任,信任关系从某种程度上来说提供了用户的偏好信息. Yang等[7]提出基于信任与被信任关系的社交推荐模型TrustMF. 依据信任关系的有向性,TrustMF将每个用户映射为2个不同的K维特征向量,分别称为信任者特征向量和被信任者特征向量. Jamali等[8]将信任传播的方法引入推荐算法SocialMF,通过约束用户与其好友的平均偏好相似来传播信任关系,从而得到更准确的结果. Ma等[9]提出社交正则化推荐模型,使用社交信息对用户特征向量进行规则化处理,从而利用好友的偏好信息影响用户的最终预测评分. 为了处理评分和信任关系的稀疏问题,Guo等[10]在奇异值分解(singular value decomposition++,SVD++)模型[11]的基础上引入社交信息,提出兼顾评分和信任信息的基于信任的矩阵分解模型TrustSVD,在预测未知项目的评分时考虑评分和信任信息的显性和隐性影响.
在现实生活中,用户对每个好友的信任度并不相同,甚至有可能完全不信任(即有可能仅仅出于礼貌而添加好友关系). 上述前人研究假设每个好友对用户的影响相同. 实际上,用户间的信任关系受多种因素的影响,有的是由于爱好相似,有的是由于相同的社交圈子,有的则仅仅是出于礼貌. 简单的二值信任网络并不能反映用户之间的影响力,也不能充分挖掘社交网络中隐含的用户偏好信息,即须进一步评估用户间的信任度.
为了解决以上问题,本研究提出基于用户信任和影响力的相似度推荐模型(factored similarity model with user trust and influence recommendation,FSTID)进行top-N项目推荐研究. 1)为了解决信任数据稀疏和二值信任关系问题,提出融合用户交互信息、偏好度和信任的新型信任度量模型,发掘社交网络用户间存在的隐含信任关系,构建社会信任网络. 2)将社会信任网络的拓扑结构和用户交互的显式反馈、隐式反馈信息融入结构洞算法,通过改进的结构洞算法来识别网络中的影响力用户,从而更全面地利用信任关系中的隐含信息. 3)综合考虑用户信任和影响力对推荐效果的影响,提出基于用户和项目相似性、信任及社会影响力的新型推荐模型,并针对传统协同过滤算法随机初始化用户及项目特征向量,采用自动编码器对用户行为进行无监督的初始特征优化,提高推荐性能. 4)在FilmTrust、Epinions、Ciao这3个标准数据集上进行大量对比验证以证明所提算法的高效性.
1. 基于信任和影响力推荐算法
1.1. 问题定义
在基于评分的协同过滤算法中,给定
构建社会信任网络有向图
1.2. 特征提取
如图1所示为将用户-项目的评分矩阵输入自动编码器的输入层,经过自动编码器进行用户特征和项目特征提取的过程.
图 1
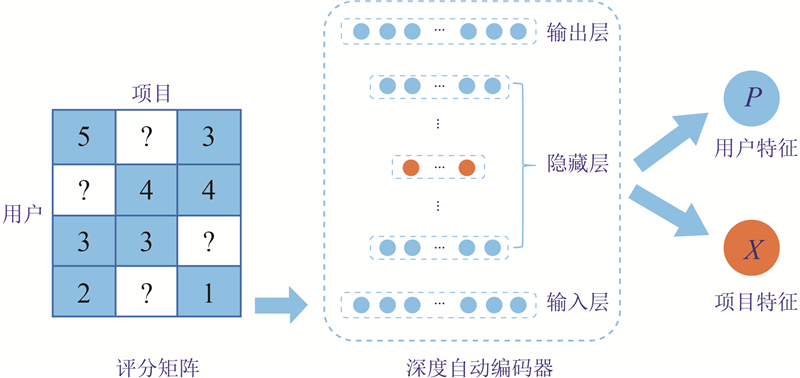
设计基于项目(或用户)的自动编码器,包含编码(输入层到隐含层)与解码(隐含层到输出层)2个部分. 在编码部分,将每个部分观察到的
1)解码. 通过位于输入层与隐含层之间的权值矩阵
式中:h1为隐含层矩阵;
2)编码. 自动编码器通过位于隐含层与输出层之间的权值矩阵
3)优化模型. 通过调整权值矩阵
式中:
在训练过程中,采用反向传播算法训练自动编码器. 利用反向传播算法,从输出层开始反向计算每个节点的残差,并利用这些残差计算代价方程对每个参数的偏导数. 在每个迭代过程中,更新权重矩阵的表达式如下:
式中:
重复以上步骤不断对模型进行优化直至训练结束. 在训练结束后,将得到用户特征向量
1.3. 信任度计算
进行如下假设:如果2个用户对同一项目进行评价,就认为他们之间进行一次交互.
信任来源于主观个体的经验积累,用户
式中:
在现实生活中,人们之间的信任程度受交互经验的影响,彼此的信任度随项目交互结果的变化而逐渐变化. 若用户
式中:ru,i,rv,i分别为用户u、v对项目i的评分,
另外,从大众心理出发,区分用户对项目的兴趣度差异对信任度变化造成的影响,即偏好度. 用户
式中:
采用皮尔逊相关系数计算用户间的相似度:
在成功或失败的交互中,根据用户对项目的偏好度为不同的项目分配不同的权重,得到最终的信任度:
1.4. 影响力用户识别
结构洞[12](structural holes,SH)理论能够较好地度量社会网络的影响力节点,识别影响力用户. 受相关研究的启发,本研究提出改进的结构洞算法(improved structural holes,ISH). ISH在传统的结构洞算法的基础上,融入邻居节点的入度及出度对目标节点的影响,能够有效挖掘有向图中的关键节点. 表达式如下:
式中:
1.5. 个性化推荐
所提模型建立在FST(factored similarity models with social trust)[13]方法的基础上,将用户u对项目i的预测评分分为四部分:1)项目偏置
式中:
根据以上分析,影响力用户对项目
式中:
构建损失函数来优化FSTID模型. 本研究借鉴贝叶斯个性排序[14](Bayesian personalized ranking,BPR)中的损失函数,该函数不拟合具体评分值,而是最大化目标用户已有行为的出现. 损失函数表达式如下:
式中:
采用梯度下降法进行最优化求解,直到损失函数收敛. 最后,返回偏移向量和特征矩阵作为输出.
2. 实验结果和分析
为了避免实验的倾向性,选择3个独立的数据集Filmtrust、Epinions、Ciao进行算法验证. 这3个真实世界的数据集同时包含评分数据和在线社交数据,如表1所示. 可以看出,这些数据集本质上都较稀疏.
表 1 数据集稀疏性分析
Tab.1
| 数据集 | 用户数量 | 项目数量 | 评分记录 | 评分稀疏度/% |
| Epinions | 40 163 | 139 738 | 664 824 | 0.01 |
| Ciao | 7 375 | 99 746 | 139 738 | 0.04 |
| FilmTrust | 1 508 | 2 071 | 40 163 | 1.14 |
采用5-折交叉验证方法,选取5次结果的平均值作为最终实验结果. 和评分预测问题不同的是,采用3种流行的排名指标来评估推荐性能,即精确率(precision)、F1度量(F1 - measure)及归一化折损累积增益(normalized discounted cumulative gain,NDCG). 与大多数推荐系统类似,将备选项目按评分排序,并推荐前N个项目. 对于每个用户,定义
式中:N为推荐的项目数,在本研究中通常设
选择当前最先进的算法进行对比和分析:1)MostPopular:通过受欢迎程度来计算项目的评分分数的基线方法,即该项目被其他用户评分或消费的次数. 2)BPR:经典的基于成对偏好假设的物品排序算法[14],在建模时只使用目标反馈,而没有考虑辅助反馈,通过学习用户对一对产品的偏好关系来预测用户最有可能偏好的产品. 3)GBPR(group Bayesian personalized ranking):Pan等[15]提出的基于BPR的改进方法,结合社交群体对用户偏好的影响来提高项目推荐质量. 4)FISM(factored item similarity model):Kabbur等[16]提出的基于项目相似度的top-N推荐方法,提高项目推荐性能. 5)FST:Guo等[13]提出的基于隐式用户反馈,并融合相似度和社会信任的top-N推荐方法. 6)FSTID、FSTID-:本研究所提出的用于对比的2个方法. 其中,FSTID-不采用自动编码器进行特征优化,其用户特征和项目特征值在(0,0.01)随机产生.
2.1. 节点影响力分析
为了进行节点影响力分析,采用经典的传染病Susceptible Infected(SI)模型进行仿真研究,该模型可以很好地模拟信息、病毒的传播过程. 在SI疾病传播模型中,网络中的节点在任一时刻都有2种可能状态,易感态S和感染态I. 感染态的节点在每个时间段会以
在实验中,以FilmTrust和Ciao的实际社交网络数据为样本,设定
式中:M为对节点i进行重复实验的次数,在本研究中取
图 2
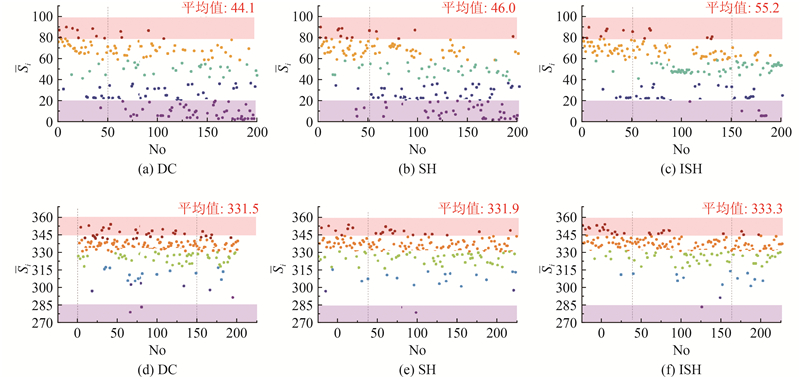
图 2 各算法得出的排名与实际影响力的相关性分析
Fig.2 Correlation analysis between rankings obtained by each algorithm and actual influence
2.2. 模型参数影响分析
2.2.1. 参数 $\alpha $ $\beta $ $z$ $\mu $
为了节省空间,设置
表 2 3个数据集上精确率排名Top-5的参数配置
Tab.2
| 排名 | Epinions | Ciao | FilmTrust | ||||||||||||||
| P@10 | | | | | P@10 | | | | | P@10 | | | | | |||
| 1 | 0.010 486 | 0.5 | 2.0 | 2.0 | 0.5 | 0.023 78 | 0.5 | 2.0 | 2.0 | 2.0 | 0.352 258 | 2.0 | 1.0 | 1.0 | 0.5 | ||
| 2 | 0.010 467 | 1.0 | 2.0 | 0.5 | 0.5 | 0.023 609 | 0.5 | 0.5 | 0.5 | 0.5 | 0.351 964 | 2.0 | 0.5 | 2.0 | 2.0 | ||
| 3 | 0.010 379 | 2.0 | 1.0 | 2.0 | 0.5 | 0.023 411 | 1.0 | 2.0 | 1.0 | 1.0 | 0.351 819 | 0.5 | 1.0 | 0.5 | 1.0 | ||
| 4 | 0.010 243 | 1.0 | 2.0 | 1.0 | 1.0 | 0.023 396 | 0.5 | 2.0 | 1.0 | 0.5 | 0.351 819 | 1.0 | 1.0 | 0.5 | 0.5 | ||
| 5 | 0.010 231 | 0.5 | 2.0 | 0.5 | 2.0 | 0.023 36 | 2.0 | 0.5 | 0.5 | 1.0 | 0.351 775 | 0.5 | 0.5 | 0.5 | 0.5 | ||
2.2.2. 参数 $s$ $\delta $
在实验中,将
图 3

图 3 参数$s$、$\delta $在3个数据集上的精确率结果
Fig.3 Precision results of parameter $s$ and $\delta $ on three datasets
2.2.3. 影响力用户数目的影响
在本研究所提方法中,选取影响力最大的前k%的用户作为全局影响力用户. 在社交网络中仅有少量用户具有明显的影响作用,所以最多选取前10%的用户进行实验. 为了验证参数
图 4
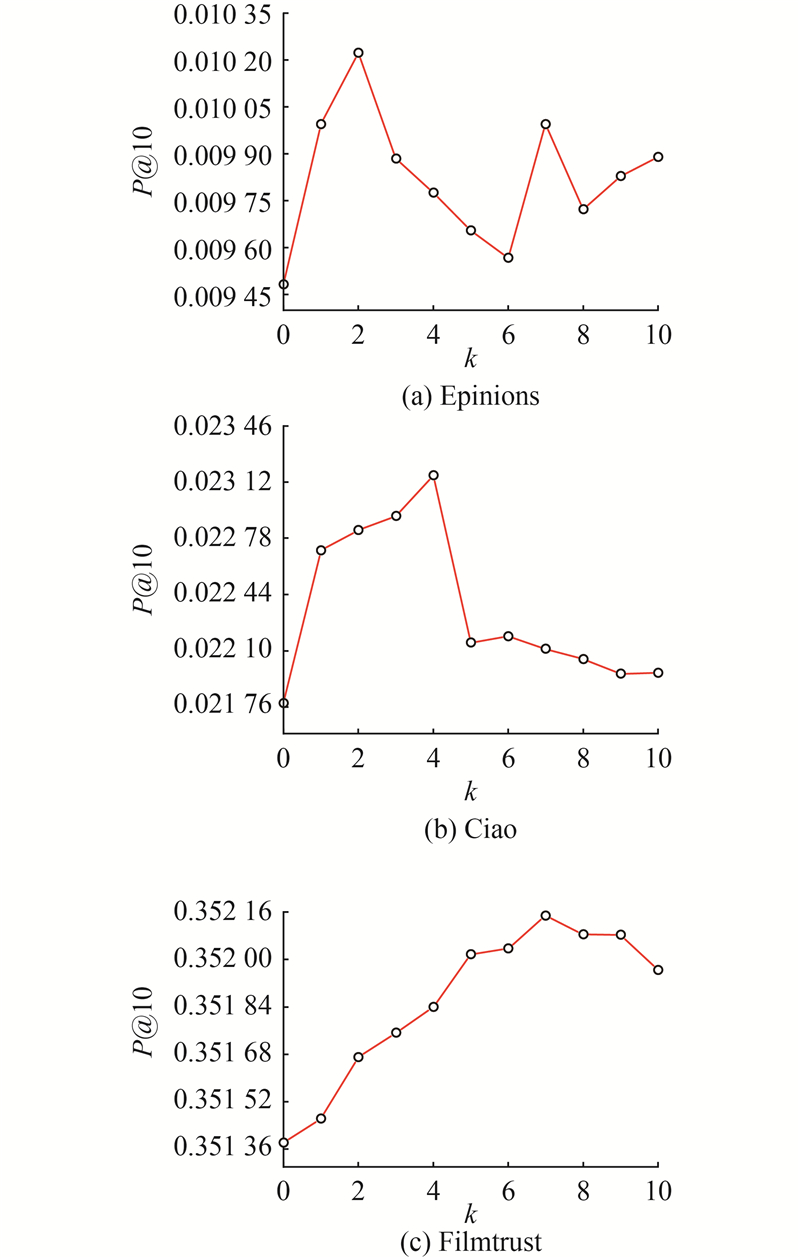
图 4 参数$k$在3个数据集上的精确率结果
Fig.4 Precision results of parameter $k$ on three datasets
2.3. 对比方法实验分析
为了使实验不失偏向性,在Filmtrust、Epinions、Ciao数据集上进行测试,并且验证算法在维度为5、10时的精度. 各种算法在3个数据集中的实验结果和分析如表3所示. 可以看出,1)FST是基于FISM的改进方法,在所有实验中,它都取得除本研究所提方法之外最好的结果,证明隐式反馈并融合社会信任的方法是可行的. 在FSTID-中同时融入社会影响力,并将被信任者用户的影响也纳入推荐中,实验结果表明本研究所提方法FSTID-比FST的效果更好,说明融入影响力用户对提升推荐性能有较大帮助. 2)对比FSTID-与FSTID,可以看出,FSTID的性能总是优于FSTID-,表明相比于随机生成特征,采用自动编码器从原始数据进行特征提取更加有益于算法整体推荐性能的提升.
表 3 Top-N项目推荐对比实验结果
Tab.3
| 数据集 | 方法 | N=5 | N=10 | |||||
| | | | | | | |||
| Epinions | MostPop | 0.011 690 | 0.012 98 | 0.012 334 | 0.009 171 | 0.013 05 | 0.016 238 | |
| GBPR | 0.009 353 | 0.011 03 | 0.012 296 | 0.007 560 | 0.011 11 | 0.016 095 | ||
| FISM | 0.011 470 | 0.013 07 | 0.012 808 | 0.009 020 | 0.013 15 | 0.016 361 | ||
| FST | 0.011 790 | 0.013 30 | 0.013 988 | 0.009 187 | 0.013 28 | 0.016 930 | ||
| FSTID- | 0.012 310 | 0.014 02 | 0.014 355 | 0.010 240 | 0.014 59 | 0.017 588 | ||
| FSTID | 0.012 430 | 0.014 15 | 0.014 470 | 0.010 480 | 0.014 76 | 0.017 832 | ||
| Ciao | MostPop | 0.026 770 | 0.024 36 | 0.025 906 | 0.021 420 | 0.026 62 | 0.033 443 | |
| GBPR | 0.022 280 | 0.020 63 | 0.022 319 | 0.018 270 | 0.021 16 | 0.028 759 | ||
| FISM | 0.027 040 | 0.024 95 | 0.026 185 | 0.021 410 | 0.026 87 | 0.032 510 | ||
| FST | 0.027 410 | 0.025 23 | 0.027 240 | 0.021 740 | 0.027 20 | 0.034 910 | ||
| FSTID- | 0.028 300 | 0.026 44 | 0.027 389 | 0.023 290 | 0.029 14 | 0.035 503 | ||
| FSTID | 0.029 240 | 0.026 82 | 0.027 634 | 0.023 610 | 0.029 50 | 0.035 932 | ||
| FilmTrust | MostPop | 0.417 000 | 0.409 50 | 0.409 529 | 0.350 300 | 0.451 80 | 0.538 924 | |
| GBPR | 0.412 400 | 0.405 10 | 0.372 923 | 0.347 000 | 0.445 80 | 0.500 997 | ||
| FISM | 0.417 100 | 0.408 70 | 0.413 404 | 0.350 300 | 0.451 60 | 0.540 511 | ||
| FST | 0.419 100 | 0.409 90 | 0.419 351 | 0.351 400 | 0.452 10 | 0.545 109 | ||
| FSTID- | 0.419 800 | 0.411 60 | 0.426 273 | 0.353 200 | 0.454 10 | 0.547 688 | ||
| FSTID | 0.420 500 | 0.412 40 | 0.427 569 | 0.353 300 | 0.454 80 | 0.551 260 | ||
2.4. 算法复杂度和运行时间对比分析
所提方法FSTID的时间复杂度分析关键点在于目标函数和最优化求解过程的计算,总计算时间成本为
为了进一步验证算法的效率,展示各算法分别在3个数据集上的运行时间,如表4所示. 考虑FSTID比FSTID-相对增加了读取特征矩阵文件的时间,在实际运行中,该时间差可忽略不计,为此仅展示FSTID运行时间. 由表4可以看出,FSTID方法在保持较高推荐性能的前提下,在Ciao、FilmTrust这2个数据集上的运行时间较短,优于FST的运行时间. 在Epinions数据集上FISM和GBPR花费了最长的运行时间,且FST获得了除MostPop外最好的成绩. 与FST相比,FSTID虽然需要更久的运行时间,但差距并不明显,并且FSTID能有效提升推荐性能.
表 4 各算法在3个数据集上的实际运行时间
Tab.4
| 数据集 | MostPop | GBPR | FISM | FST | FSTID |
| Epinions | 8.98 | 97.20 | 106.20 | 47.00 | 63.60 |
| Ciao | 0.38 | 8.86 | 7.70 | 20.00 | 11.61 |
| FilmTrust | 0.05 | 0.92 | 1.34 | 5.00 | 3.83 |
3. 结 语
基于社会信任和影响力的个性化推荐算法,着重于利用社会网络中高影响力用户的信息传播能力,从而进一步提高推荐精度;同时利用自动编码器初始化用户和项目潜在特征向量,有效提升推荐算法的整体性能. 在FilmTrust、Epinions、Ciao这3个标准数据集上的对比实验结果证明本研究所提方法FSTID的有效性和较高推荐精度,特别是对于稀疏用户,能够取得明显的提高.
此外,在实验中发现仍有一些问题值得进一步研究. 一方面,在识别影响力用户时,没有考虑信任的领域相关性从而导致识别出的影响力用户不是用户所期望领域的影响用户;另一方面,如果仅在信任网络的一个静态快照上识别影响用户而忽略信任网络的动态性,会导致识别出影响力已经消失或变弱的影响用户. 后续将继续引入主题和时间的概念,致力于研究如何根据用户的评分时间来计算用户对项目喜好的动态变化以及信任的动态变化,以便能够更及时地推荐符合用户偏好的项目.
参考文献
Fab: content-based, collaborative recommendation
[J].DOI:10.1145/245108.245124 [本文引用: 1]
Network studies of social influence
[J].DOI:10.1177/0049124193022001006 [本文引用: 1]
Referralweb: combining social networks and collaborative filtering
[J].DOI:10.1145/245108.245123 [本文引用: 1]
Social collaborative filtering by trust
[J].DOI:10.1109/TPAMI.2016.2605085 [本文引用: 1]
A novel recommendation model regularized with user trust and item ratings
[J].DOI:10.1109/TKDE.2016.2528249 [本文引用: 2]
Factored similarity models with social trust for top-N item recommendation
[J].DOI:10.1016/j.knosys.2017.01.027 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}