式中: ${{a}} = {[{a_1},{a_2},\cdots,{a_{{m}}}]^{\rm{T}}}$ $\,{{b}} = {[{b_1},{b_2},\cdots,{b_{{n}}}]^{\rm{T}}}$ ${ w}_{ij} $ W ${{W}} \in {{\bf{R}}^{{{m}} \times {{n}}}}$
(8) $\begin{aligned} {{X}} &= {[{x_1},\Delta {\bar x_1},{x_2},\Delta {\bar x_2},\cdots,{x_N},\Delta {\bar x_N}]^{\rm T}}{\text{,}}\\ {{Y}} &= {[{y_1},\Delta {\bar y_1},{y_2},\Delta {\bar y_2},\cdots{y_N},\Delta {\bar y_N}]^{\rm T}}. \end{aligned}$
[1]
ERRO D, ALONSO A, SERRANO L Interpretable parametric voice conversion functions based on Gaussian Mixture Models and constrained transformations
[J]. Computer Speech and Language , 2014 , 30 (1 ): 3 - 15
[本文引用: 1]
[2]
DOI H, TODA T, NAKAMURA K, et al Alaryngeal speech enhancement based on one-to-many eigenvoice conversion
[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 2014 , 22 (1 ): 172 - 183
DOI:10.1109/TASLP.2013.2286917
[本文引用: 1]
[3]
TODA T, NAKAGIRI M, SHIKANO K Statistical voice conversion techniques for body-conducted unvoiced speech enhancement
[J]. IEEE Transactions on Audio, Speech, and Language Processing , 2012 , 20 (9 ): 2505 - 2517
DOI:10.1109/TASL.2012.2205241
[本文引用: 1]
[4]
DENG L, ACERO A, JIANG L, et al. High-performance robust speech recognition using stereo training data [C] // IEEE International Conference on Acoustics, Speech, and Signal Processing . Las Vegas: IEEE, 2001: 301-304.
[本文引用: 1]
[5]
KUNIKOSHI A, QIAN L, MINEMATSU N, et al. Speech generation from hand gestures based on space mapping [C] // Tenth Annual Conference of the International Speech Communication Association . England: INTERSPEECH, 2009: 308-311.
[本文引用: 1]
[6]
MIZUNO H, ABE M Voice conversion algorithm based on piecewise linear conversion rules of formant frequency and spectral tilt
[J]. IEEE Transactions on Audio, Speech, and Language Processing , 2013 , 1 (6 ): 469 - 472
[本文引用: 1]
[7]
ABE M, NAKAMURA S, et al. Voice conversion through vector quantization [C] // IEEE International Conference on Acoustics, Speech, and Signal Processing . Las Vegas: IEEE, 1988: 71-76.
[本文引用: 1]
[8]
YAMAGISHI J, KOBAYASHI T, NAKANO Y, et al Analysis of speaker adaptation algorithm
[J]. IEEE Transactions on Audio, Speech, and Language Processing , 2009 , 17 (1 ): 66 - 83
DOI:10.1109/TASL.2008.2006647
[本文引用: 1]
[9]
SARUWATARI T H, SHIKANO K. Voice conversion algorithm based on Gaussian Mixture Model with dynamic frequency warping of STRAIGHT spectrum [C] // Proceedings of IEEE International Conference on Acoust, Speech, Signal Processing . Las Vegas: IEEE, 2001: 841-844.
[本文引用: 1]
[10]
沈惠玲, 万永菁 一种基于预测谱偏移的自适应高斯混合模型在语音转换中的应用
[J]. 华东理工大学学报:工学版 , 2017 , 43 (4 ): 546 - 552
[本文引用: 1]
SHEN Hui-ling, WAN Yong-jing An adaptive Gaussian Mixed Model based on predictive spectral shift and its application in voice conversion
[J]. Journal of East China University of Science and Technology: Engineering Science , 2017 , 43 (4 ): 546 - 552
[本文引用: 1]
[12]
NARENDRANATH M, MURTHY H A, RAJENDRAN S, et al Transformation of formants for voice conversion using artificial neural networks
[J]. Speech Communication , 1995 , 16 (2 ): 207 - 216
[13]
王民, 黄斐, 刘利, 等 采用深度信念网络的语音转换方法
[J]. 计算机工程与应用 , 2016 , 52 (15 ): 168 - 171
DOI:10.3778/j.issn.1002-8331.1409-0383
[本文引用: 1]
WANG Ming, HUANG Fei, LIU Li, et al Voice conversion using deep belief networks
[J]. Computer Engineering and Applications , 2016 , 52 (15 ): 168 - 171
DOI:10.3778/j.issn.1002-8331.1409-0383
[本文引用: 1]
[14]
叶伟, 俞一彪. 超帧特征空间下基于深度置信网络的语音转换[D]. 苏州: 苏州大学, 2016.
[本文引用: 1]
YE Wei, YU Yi-biao. Voice conversion using deep belief network in super frame feature space[D]. Soochow: Soochow University, 2016.
[本文引用: 1]
[15]
宋知用. Matlab在语音信号分析与合成中的应用: 第1版 [M]. 北京: 北京航空航天大学出版社, 2013: 2-16, 62-66, 161-162.
[本文引用: 1]
[16]
吕士楠, 初敏, 许洁萍, 等. 汉语语音合成: 原理和技术[M]. 北京: 科学出版社, 2012.
[本文引用: 1]
[17]
SMOLENSKY P. Information processing in dynamical systems: foundations of harmony theory [D]. Cambridge, MA, USA , 1986, 1(6): 194-281.
[本文引用: 1]
[18]
周志华. 机器学习[M]. 北京: 清华大学出版社, 2013: 111-115.
[本文引用: 1]
[19]
HINTON G Training products of experts by minimizing contrastive divergence
[J]. Neural Computation , 2002 , 12 (14 ): 1711 - 1800
[本文引用: 1]
[20]
NAKASHIKA T, TAKASHIMA R, TAKIGUCH T, et al. Voice conversion in high-order eigen space using deep belief nets [C] // Interspeech . Lyon: INTERSPEECH, 2013: 369-372.
[本文引用: 1]
[21]
GHORBANDOOST M, SAYADIYAN A, AHANGAR M, et al. Voice conversion based on feature combination with limited training data
[J]. Speech Communication 2015 , 67 (3 ): 115 - 117
[本文引用: 2]
[22]
ERRO D, MORENO A, BONAFONTE A Voice conversion based on weighted frequency warping
[J]. IEEE Transactions on Audio, Speech, and Language Processing , 2010 , 18 (5 ): 922 - 931
DOI:10.1109/TASL.2009.2038663
[本文引用: 1]
Interpretable parametric voice conversion functions based on Gaussian Mixture Models and constrained transformations
1
2014
... 语音转换技术旨在保持语义信息不变,修改一个说话人(源说话人)的声音,使其听起来像是由另一个给定说话人(目标说话人)发出的声音[1 ] . 语音转换技术作为语音信号处理领域的一个新兴分支,具有重要的研究价值和应用前景,可应用于语音修复[2 ] 、语音增强[3 ] 、影视配音、保密通信[4 -5 ] 等多个领域. 语音转换包括谱包络转换和基频轨迹转换两部分,由于语音的谱包络中包含大量的内容信息与个性化特征,谱包络转换在语音转换中占主导地位. 因此,本文仅对语音基频轨迹进行简单的单高斯转换[6 ] ,主要研究语音中基于谱包络的转换方法. ...
Alaryngeal speech enhancement based on one-to-many eigenvoice conversion
1
2014
... 语音转换技术旨在保持语义信息不变,修改一个说话人(源说话人)的声音,使其听起来像是由另一个给定说话人(目标说话人)发出的声音[1 ] . 语音转换技术作为语音信号处理领域的一个新兴分支,具有重要的研究价值和应用前景,可应用于语音修复[2 ] 、语音增强[3 ] 、影视配音、保密通信[4 -5 ] 等多个领域. 语音转换包括谱包络转换和基频轨迹转换两部分,由于语音的谱包络中包含大量的内容信息与个性化特征,谱包络转换在语音转换中占主导地位. 因此,本文仅对语音基频轨迹进行简单的单高斯转换[6 ] ,主要研究语音中基于谱包络的转换方法. ...
Statistical voice conversion techniques for body-conducted unvoiced speech enhancement
1
2012
... 语音转换技术旨在保持语义信息不变,修改一个说话人(源说话人)的声音,使其听起来像是由另一个给定说话人(目标说话人)发出的声音[1 ] . 语音转换技术作为语音信号处理领域的一个新兴分支,具有重要的研究价值和应用前景,可应用于语音修复[2 ] 、语音增强[3 ] 、影视配音、保密通信[4 -5 ] 等多个领域. 语音转换包括谱包络转换和基频轨迹转换两部分,由于语音的谱包络中包含大量的内容信息与个性化特征,谱包络转换在语音转换中占主导地位. 因此,本文仅对语音基频轨迹进行简单的单高斯转换[6 ] ,主要研究语音中基于谱包络的转换方法. ...
1
... 语音转换技术旨在保持语义信息不变,修改一个说话人(源说话人)的声音,使其听起来像是由另一个给定说话人(目标说话人)发出的声音[1 ] . 语音转换技术作为语音信号处理领域的一个新兴分支,具有重要的研究价值和应用前景,可应用于语音修复[2 ] 、语音增强[3 ] 、影视配音、保密通信[4 -5 ] 等多个领域. 语音转换包括谱包络转换和基频轨迹转换两部分,由于语音的谱包络中包含大量的内容信息与个性化特征,谱包络转换在语音转换中占主导地位. 因此,本文仅对语音基频轨迹进行简单的单高斯转换[6 ] ,主要研究语音中基于谱包络的转换方法. ...
1
... 语音转换技术旨在保持语义信息不变,修改一个说话人(源说话人)的声音,使其听起来像是由另一个给定说话人(目标说话人)发出的声音[1 ] . 语音转换技术作为语音信号处理领域的一个新兴分支,具有重要的研究价值和应用前景,可应用于语音修复[2 ] 、语音增强[3 ] 、影视配音、保密通信[4 -5 ] 等多个领域. 语音转换包括谱包络转换和基频轨迹转换两部分,由于语音的谱包络中包含大量的内容信息与个性化特征,谱包络转换在语音转换中占主导地位. 因此,本文仅对语音基频轨迹进行简单的单高斯转换[6 ] ,主要研究语音中基于谱包络的转换方法. ...
Voice conversion algorithm based on piecewise linear conversion rules of formant frequency and spectral tilt
1
2013
... 语音转换技术旨在保持语义信息不变,修改一个说话人(源说话人)的声音,使其听起来像是由另一个给定说话人(目标说话人)发出的声音[1 ] . 语音转换技术作为语音信号处理领域的一个新兴分支,具有重要的研究价值和应用前景,可应用于语音修复[2 ] 、语音增强[3 ] 、影视配音、保密通信[4 -5 ] 等多个领域. 语音转换包括谱包络转换和基频轨迹转换两部分,由于语音的谱包络中包含大量的内容信息与个性化特征,谱包络转换在语音转换中占主导地位. 因此,本文仅对语音基频轨迹进行简单的单高斯转换[6 ] ,主要研究语音中基于谱包络的转换方法. ...
1
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
Analysis of speaker adaptation algorithm
1
2009
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
1
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
一种基于预测谱偏移的自适应高斯混合模型在语音转换中的应用
1
2017
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
一种基于预测谱偏移的自适应高斯混合模型在语音转换中的应用
1
2017
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
基于径向基神经网络的声音转换
2
2004
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
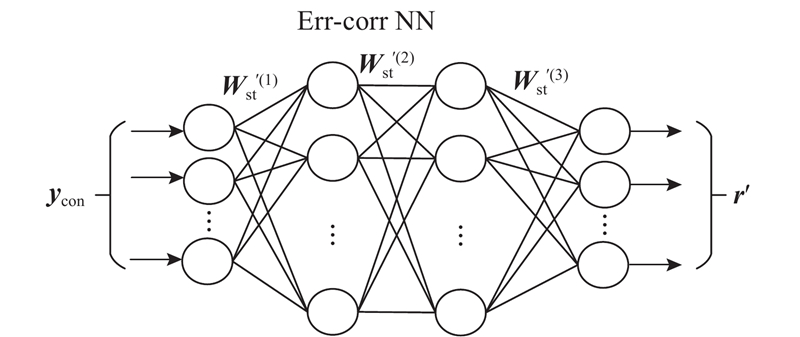
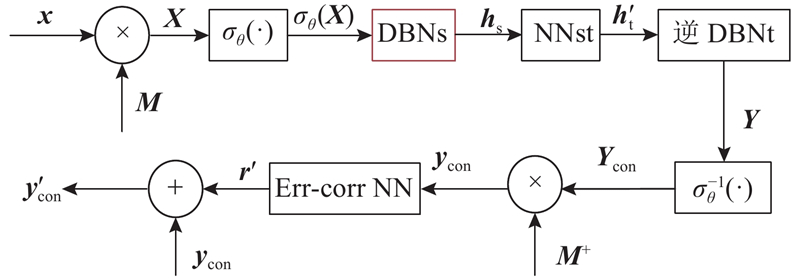
... 本实验采用中国科学院自动化研究所的汉语语料库. 选择两男(M1和M2)、两女(F1和F2),共4个专业说话人的120句相同文本的语音,并对这涵盖400个语音音节的120句语音进行对齐. 本文选用22阶的线谱对参数LSP[11 ] 作为谱特征参数,采用由2个RBM堆叠的深度信念网络架构. 其中,DBNs与DBNt结点数取为[22-66-16],采用CD算法由一步Gibbs采样训练,学习速率为0.05,动量为0.9,迭代次数为50次,训练样本的批次为10. 对于NNst网络而言,则使用2个含有双隐含层的网络架构,NNst网络的结点数分别为[16LL-32NL-32NL-16LL],其中LL代表“线性的”输出函数,NL代表“正切的”输出函数,误差修正网络Err-corr NN同样为双隐含层结构,其结点数分别为[22LL-44NL-44NL-22LL]. ...
基于径向基神经网络的声音转换
2
2004
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
... 本实验采用中国科学院自动化研究所的汉语语料库. 选择两男(M1和M2)、两女(F1和F2),共4个专业说话人的120句相同文本的语音,并对这涵盖400个语音音节的120句语音进行对齐. 本文选用22阶的线谱对参数LSP[11 ] 作为谱特征参数,采用由2个RBM堆叠的深度信念网络架构. 其中,DBNs与DBNt结点数取为[22-66-16],采用CD算法由一步Gibbs采样训练,学习速率为0.05,动量为0.9,迭代次数为50次,训练样本的批次为10. 对于NNst网络而言,则使用2个含有双隐含层的网络架构,NNst网络的结点数分别为[16LL-32NL-32NL-16LL],其中LL代表“线性的”输出函数,NL代表“正切的”输出函数,误差修正网络Err-corr NN同样为双隐含层结构,其结点数分别为[22LL-44NL-44NL-22LL]. ...
Transformation of formants for voice conversion using artificial neural networks
0
1995
采用深度信念网络的语音转换方法
1
2016
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
采用深度信念网络的语音转换方法
1
2016
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
1
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
1
... 基于谱包络的语音转换算法一直是研究热点,在过去几十年中,有许多相关方法已被提出,这些方法大致可分为两类:基于规则的方法和基于统计的方法. 前一种方法基于特定的规则直接修改语音信号的声学信息,该方法尽管保留了大部分信息,但由于不同说话人需要不同的转换规则,不具有通用性. 基于统计的方法估计了源说话人和目标说话人间谱包络的非线性映射函数,建立了比基于规则的方法更精确的复杂转换模型,具有普遍性与适用性. 在基于统计的语音转换算法中,较经典的方法有:矢量量化(vector quantization, VQ)法[7 ] 、隐马尔科夫模型(hidden Markov model, HMM)法[8 ] 、高斯混合模型(Gaussian mixed model, GMM)法[9 ] 、改进的GMM算法[10 ] 以及人工神经网络(artificial neural network, ANN)法[11 -13 ] 等. 近些年来,随着人工智能研究领域的兴起,将各类神经网络应用于语音转换中已成为新的研究热点. 其中,基于传统深度信念网络(deep belief network, DBN)的语音转换算法将原始谱特征抽象到高层空间中,并在高层空间中进行谱特征转换,使得模型即使在训练语音数不多的情况下,也能够转换出使人可接受的语音. 但传统DBN转换模型忽略了转换语音帧间动态变化的信息,即使通过微调网络修正,效果仍然不佳,转换出的语音谱包络有一定的失真与不连续,在听觉上表现为含有一些“喳喳”的噪声. 叶伟等[14 ] 针对此问题,提出对每一帧特征参数,取其前后相邻的7帧,利用扩展后的15帧特征训练DBN. 该算法在一定程度上缓解了各语音帧独立转换时引起的谱包络不连续问题,但不能刻画出语音帧间动态变化的细节信息,因此,谱包络不连续问题仍然存在. 同时,直接扩展相邻多帧的特征,使得扩展后特征维度过大,冗余信息过多,导致网络参数变多,模型训练不稳定,训练时长大幅度增加. ...
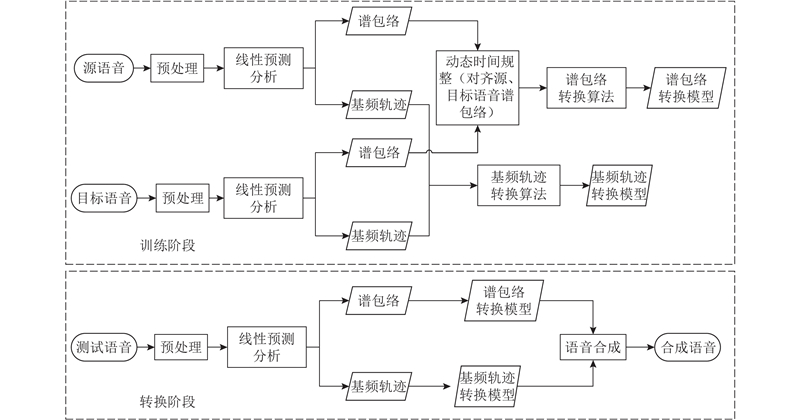
1
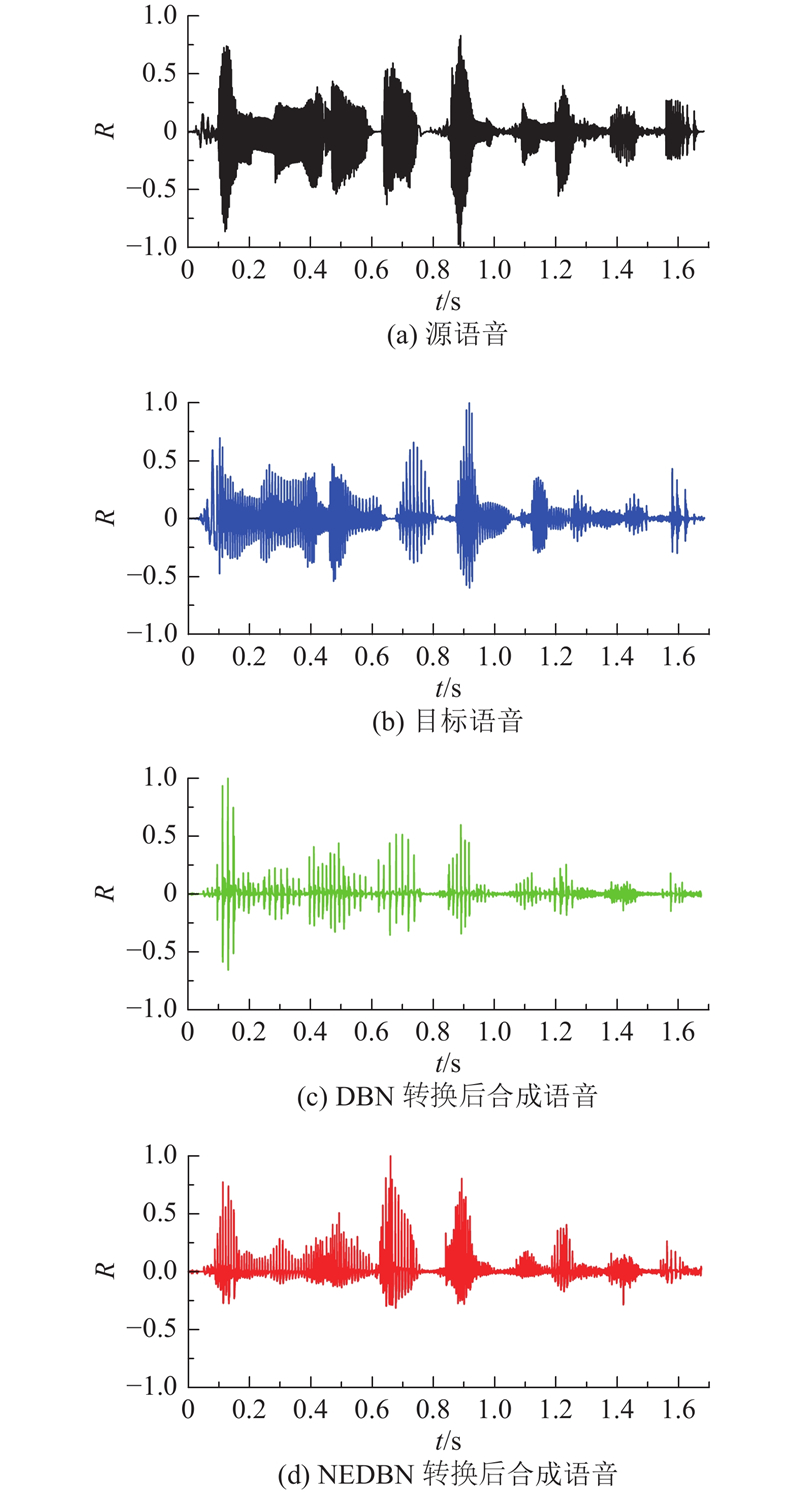
... 语音转换过程分为训练和转换2个阶段,如图1 所示. 在训练阶段,首先对源语音和目标语音进行分帧、加窗、预加重等预处理[15 ] ,通过线性预测分析提取谱包络与基频轨迹;然后分别通过动态时间规整后谱包络和基频轨迹的转换算法,得到相应的转换模型. 在转换阶段,对测试语音进行预处理,同样利用线性预测分析提取谱包络与基频轨迹,采用训练阶段得到的转换模型进行转换,最后基于转换后的谱包络与基音频率,采用参数合成法[16 ] 得到合成语音. ...
1
... 语音转换过程分为训练和转换2个阶段,如图1 所示. 在训练阶段,首先对源语音和目标语音进行分帧、加窗、预加重等预处理[15 ] ,通过线性预测分析提取谱包络与基频轨迹;然后分别通过动态时间规整后谱包络和基频轨迹的转换算法,得到相应的转换模型. 在转换阶段,对测试语音进行预处理,同样利用线性预测分析提取谱包络与基频轨迹,采用训练阶段得到的转换模型进行转换,最后基于转换后的谱包络与基音频率,采用参数合成法[16 ] 得到合成语音. ...
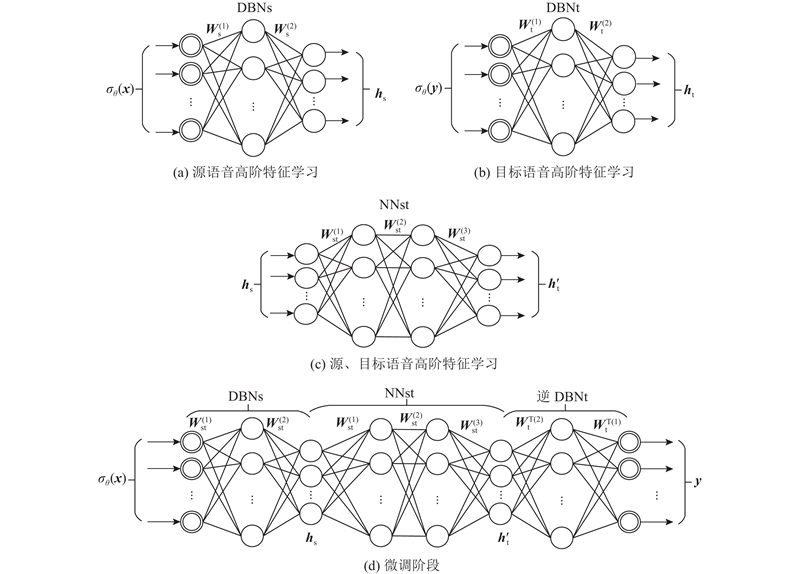
1
... 可将RBM视为一个二分无向图模型[17 ] ,如图2(a) 所示. 该模型有2层结构,其中,双线圈表示显层,单线圈表示隐层. 显层对应显随机变量集 ${{v}} = {[{v_1},{v_{\rm{2}}},\cdots,{v_{{m}}}]^{\rm{T}}}$ ${{h}} = $ $ {[{h_1},{h_{\rm{2}}},\cdots,{h_n}]^{\rm{T}}}$ m 和n 分别为显层和隐层单元数. ...
1
... 深度信念网络(DBN)是一个由多隐含层构成的类似于自编码器的概率生成模型,具有强大的抽象、表征能力,可将原始空间中谱包络特征编码为只含有“0”和“1”的高层空间中的抽象特征[18 ] . 如图2(b) 所示为一个含有2个隐含层的DBN,整个网络由2个RBM堆叠而成. 假设v h (l ) (l ∈{1, 2})均为二值随机变量,对于l =1,在给定显层单元条件下,隐层各神经元开启的概率为 ...
Training products of experts by minimizing contrastive divergence
1
2002
... 给定训练数据集,DBN模型的参数 ${{\theta}} = \{ {{{a}}^{(1)}}, $ ${{{W}}^{(1)}},{{{a}}^{(2)}},{{{b}}^{(2)}},{{{W}}^{(2)}}\} $ [19 ] . ...
1
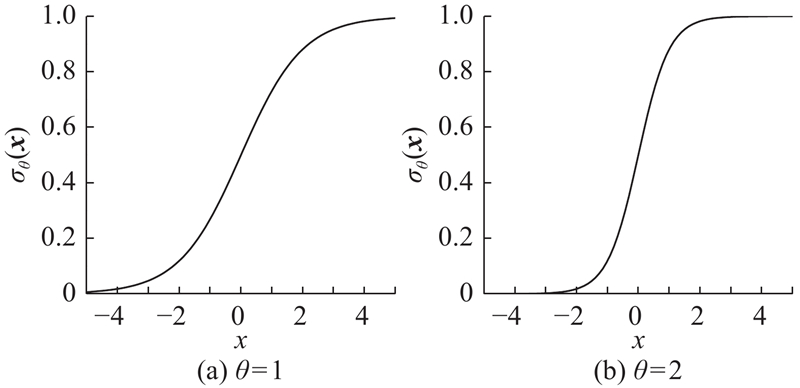
... DBN有多种形式,其中最常见的是基于Bernoulli-Bernoulli形式的DBN[20 ] . 在这种形式中,每一个显层单元是二值的. 由于谱特征参数的连续变化性,很难固定一个阈值对其进行硬二值化,因此,需要将语音的谱特征参数x
Voice conversion based on feature combination with limited training data
2
2015
... 基于谱失真的评价准则是一种被广泛使用的客观评价方法,该方法通过采用IS谱距离来作为谱失真(spectral distance, SD)测度的度量值,其计算方法[21 ] 如下式所示: ...
... MOS(mean opinion score, MOS)[22 ] 和ABX[21 ] 是2种主观评测方法. S 用来对转换语音的音质进行评价,计算方法如下式所示: ...
Voice conversion based on weighted frequency warping
1
2010
... MOS(mean opinion score, MOS)[22 ] 和ABX[21 ] 是2种主观评测方法. S 用来对转换语音的音质进行评价,计算方法如下式所示: ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}