

在传统的冯·诺依曼处理器架构中,数据需要在处理单元与存储单元之间频繁地移动. 访存所需的时间远大于对该部分数据进行计算所需的时间,使得内存访问很容易成为应用性能的瓶颈. 同时,从能耗的角度来看,数据移动的能量,即处理单元与片外存储之间数据移动所消耗的能量,比浮点操作高出2个数量级[4]. 实验数据显示,对于MapReduce这类大数据应用,超过45%的系统能量消耗与数据移动相关,表明处理单元与存储单元之间的数据移动已经成为影响系统性能和能耗表现的关键因素之一.
消除处理单元与存储单元之间的数据移动的一种有效方式是采用近数据处理(near-data processing,NDP)[5],即将数据处理移动到数据存储的本地进行. 随着3D集成技术的日益成熟,3D存储为近数据处理带来了可行的解决方案. 在3D存储器中,多层存储芯片被堆叠在一层逻辑芯片上,这层逻辑芯片用于实现存储单元的控制逻辑和物理链接协议. 目前,在工业界已有HBM[6]和HMC[7]2种商用存储采用了这种架构. 3D存储的逻辑层芯片可以集成定制的计算逻辑,一些研究基于3D存储提出了针对键值对存储[8]、图计算[9-11]、神经网络[12]等应用的近数据处理方案. 针对MapReduce应用,现有研究[13]在3D存储的控制逻辑中集成处理核心,支持Map任务的近数据处理. 但该方案不能消除Reduce任务的数据移动开销,且未对MapReduce应用运行环境提供支持,难以充分利用近数据处理对MapReduce应用中的数据移动进行优化.
为了大幅度减少MapReduce应用中主处理单元与存储单元之间的数据移动,以提升系统性能和能效,结合MapReduce应用任务间高度并行、处理逻辑相同的特点,本文提出一种基于动态任务迁移的近数据处理方法. 基于3D存储结构构建近数据处理模块,采用动态任务迁移机制,对MapReduce流程解耦,将Map任务和Reduce任务迁移到近数据处理单元中进行处理.
1. 相关工作
1.1. MapReduce原理
“分而治之”是MapReduce模型的基本原理. 数据处理过程被分成若干任务,以高度并行的方式运行. 一个MapReduce应用包含Map和Reduce 2个阶段. 在Map阶段,多个Map任务同时对输入数据进行处理,每个任务负责独立的数据分片;在Reduce阶段,多个Reduce任务同时对Map任务产生的中间数据进行处理,每个任务负责的数据之间也相互独立. 此外,完整的MapReduce计算过程还包括数据划分、流程控制、线程管理等与数据处理逻辑无关的过程,这些过程由MapReduce框架完成,对用户透明. 目前,最有代表性的MapReduce框架是Hadoop[14]. 但Hadoop平台较为庞大,且运行依赖较多,难以被应用到近数据处理环境中. 为了支持MapReduce应用的近数据处理,同时便于验证和评估,本文基于MapReduce模型原理,实现一个轻量级MapReduce框架.
1.2. 近数据处理
近年来,3D存储技术发展,为近数据处理带来了新机遇. Ahn等[9]在3D存储中集成了简单的处理器核、预取器和消息队列,并设计了专用的内存网络,实现了不同内存模块间的数据传输,利用近数据处理对大规模图处理进行加速. Gao等[19]在3D存储的逻辑层中集成了多个处理核心,并对缓存一致性和通信模型进行了研究. Azarkhish等[10]针对图遍历应用,对标准的HMC结构进行了扩展,在其逻辑层中集成了一个近数据处理单元. Nai等[11]利用3D存储的原子操作对图计算进行了优化. 还有研究基于3D存储提出了针对神经网络的加速方案[12]. 与本文工作最相关的是Pugsley等[13]其提出的一种适用于MapReduce应用的近数据处理架构NDC. 在NDC架构中,每个控制器中集成的近数据处理核心分别与3D存储中的特定存储空间对应. 因此,该方案对Map任务的数据分布有特定的要求,且不支持Reduce任务的近数据处理,未提供可行的MapReduce应用运行环境.
2. 近数据处理系统
2.1. 近数据处理模块
基于3D存储的结构特点和MapReduce模型的并行特性,本文构建的近数据处理模块的结构如图1所示. 3D存储中,多块DRAM芯片堆叠在一起作为NDP系统的存储单元,各层之间通过硅通孔连接. 垂直对齐的多个内存分区构成一个Vault. 每个Vault都有一个相应的控制器集成在逻辑层中,负责该Vault内的数据读写操作. Vault间通过互连网络进行连接. 互连网络通过高速串行链路与主处理器端通信. 为了支持MapReduce应用的近数据处理,本文在逻辑层中集成了多个NDP单元,负责处理MapReduce框架交付的计算任务. 每一个NDP单元中包含一个近数据处理器,一个便签式存储器(scratchpad memory,SPM),一个直接存储访问(direct memory access,DMA)引擎,以及一个转换查找表缓存(translation lookaside buffer,TLB).
图 1
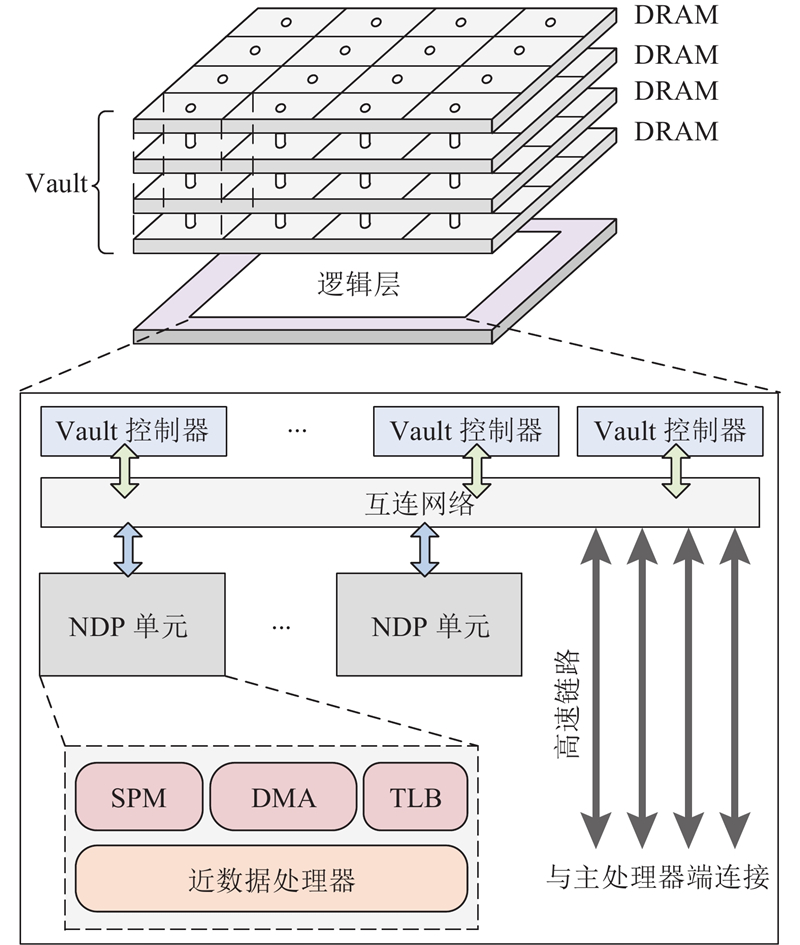
SPM中存储了NDP单元需要运行的代码,并为近数据处理器中运行的程序提供栈空间. 为了避免应用和NDP单元间的数据拷贝开销,构建的NDP系统允许NDP单元直接访问主处理器端应用程序的虚拟地址空间. 为此,近数据处理器需要通过TLB完成虚拟地址到物理地址的转换. 当计算任务被迁移到NDP单元中时,会在主处理器端的内核空间中创建包含当前计算任务地址转换规则的规则表,以供NDP单元发生TLB缺失时查询. 基于这种地址转换机制,主处理器端的应用程序和NDP单元之间可以通过指针进行数据传递. 此外,近数据处理器可以通过DMA引擎实现存储单元和NDP单元SPM之间的批量数据传输.
2.2. 动态任务迁移
2.2.1. MapReduce框架与任务解耦
为了支持NDP系统中MapReduce应用的运行,同时便于验证和评估,本文基于多线程技术,提出一个轻量级的适用于近数据处理的MapReduce框架. 实现原则与Hadoop一致,即用户只须关注Map任务和Reduce任务的具体功能实现,其余的数据分割、流程控制、线程管理等则由MapReduce框架负责.
MapReduce框架将Map任务和Reduce任务从MapReduce应用中解耦,并将其迁移到NDP单元中执行. NDP系统中MapReduce应用的工作流程可以分为4个阶段,如图2所示,包括数据分片阶段、Map阶段、数据混排阶段,以及Reduce阶段. 在数据分片阶段,MapReduce框架负责根据用户提供的输入数据指针和数据大小将数据读取到输入缓冲区中,对数据进行分割,并向各个Map任务返回对应的数据地址和数据大小. 为了减少主处理器与存储单元之间的数据移动,同时充分发挥Map任务和Reduce任务的并行特性,在Map阶段和Reduce阶段,MapReduce框架负责将Map任务和Reduce任务调度到NDP单元中执行. 数据混排通常用于为Reduce任务准备数据. 在Hadoop中,数据混排过程与Reduce任务紧密耦合在一起,包含大量的数据排序、合并、传输等操作,控制流程和处理逻辑较为复杂,且会造成主处理器与存储单元之间大量的数据移动操作. 为了避免这种问题,本文实现的MapReduce框架在混排时主要负责为Reduce任务分配数据地址. 运行时,Map任务根据Reduce任务的个数将输出数据写入相应的缓冲区中,每个缓冲区对应一个Reduce任务. MapReduce框架会记录这些缓冲区地址并分配给Reduce任务. 每个Reduce任务启动时根据分配到的数据地址列表,主动从Map任务的输出缓冲区中读取数据. 数据混排涉及的排序、合并等操作交由相应的Reduce任务处理. 需要指出的是,上述分配过程只涉及对缓存区的地址进行操作,可以通过指针操作实现,不涉及具体的数据传输.
图 2
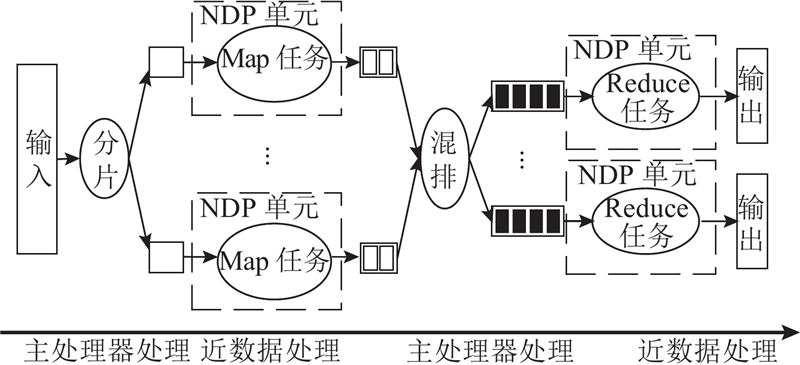
为了降低管理和调度的复杂度,同时减小线程创建与终止的开销,MapReduce框架不会为每一个Map任务或Reduce任务单独创建一个线程,而是为每一个NDP单元创建一个管理线程. 管理线程负责将Map任务或Reduce任务迁移到NDP单元中,并监控其运行状态. 当任务数量超过NDP单元的数量时,管理线程负责将任务分批迁移到NDP单元中进行处理.
2.2.2. 编程接口
为了便于用户使用,本文提供了一套应用程序编程接口(application program interface,API),主要的函数及其功能描述如表1所示. 这套API可以分为2个部分. 第一部分是面向MapReduce应用开发的高层API. 高层API为用户隐藏NDP系统的底层实现,除Map方法和Reduce方法外,其余方法均提供默认实现,用户也可以根据需要对这些方法进行重写. 以split方法为例,默认以固定分片大小对输入数据进行切分,根据需要,用户可以定义采用固定分片数量的方式对输入数据进行切分. 第二部分则是用于对NDP单元进行控制的底层API. 底层API提供的功能包括:1)将计算任务迁移到NDP单元中;2)启动NDP单元中的计算任务;3)监控NDP单元的运行状态;4)与NDP单元进行通信. 对于MapReduce应用开发,用户一般只须关注高层API,但若须对MapReduce框架中NDP单元的管理和调度方式进行修改,则须使用底层API.
表 1 MapReduce框架的应用程序编程接口(API)
Tab.1
| 函数 | 功能描述 | |
| 高层API | split | 对输入数据进行分片 |
| shuffle | 将Map任务的输出数据地址传递给Reduce任务 | |
| map | 用户定义的Map方法 | |
| reduce | 用户定义的Reduce方法 | |
| map_worker | 调用NDP单元,执行用户定义的Map方法 | |
| reduce_worker | 调用NDP单元,执行用户定义的Reduce方法 | |
| 底层API | offload_kernel | 将计算核写入NDP单元 |
| offload_data | 将数据传递给NDP单元 | |
| start_computation | 启动计算任务 | |
| wait_for_completion | 等待计算任务完成 | |
| write_reg | 向NDP单元的寄存器写入数据 | |
| read_reg | 从NDP单元的寄存器读取数据 | |
2.2.3. 任务迁移机制
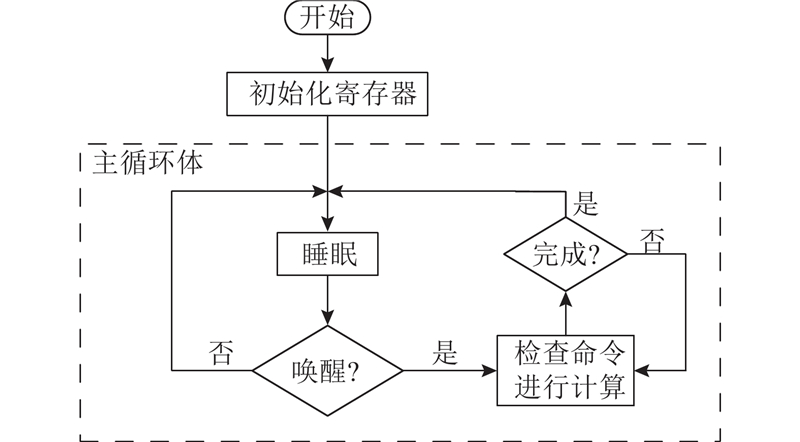
NDP单元需要响应主处理器中发送的控制命令,如启动计算任务、报告运行状态等,因此在近数据处理器中运行有常驻程序. NDP单元启动后通过引导程序进行引导,跳转至常驻程序运行. 常驻程序的运行流程如图3所示,开始运行后,首先对NDP单元的寄存器进行初始化,然后进入主循环体. 在主循环体中,常驻程序调用汇编指令WFI(wait for interrupt)使近数据处理器进入睡眠状态,以降低功耗. 当主处理器端的应用程序通过写中断寄存器的方式唤醒NDP单元时,常驻程序检查命令并跳转到相应计算任务所在代码段,开始执行计算任务. 计算任务执行结束后,常驻程序再次使近数据处理器进入睡眠状态.
图 3
运行在主处理器端操作系统中的应用程序将计算任务交付给NDP单元执行的过程称为任务迁移. 为了降低MapReduce框架进行任务迁移的开销,将任务迁移解耦为两步操作,即计算核迁移和计算数据迁移. 用户定义的Map任务和Reduce任务的处理逻辑被编译为单独的计算核. 出于通用性方面的考虑,这些计算核应该由MapReduce框架根据计算需要动态分发给各个NDP单元. 对于计算数据迁移,得益于地址转换机制,MapReduce框架只须将数据的指针传递给NDP单元. 以Map任务的迁移过程为例,基于提供的底层API,MapReduce框架首先调用offload_kernel将Map任务的计算核写入到NDP单元中;然后根据任务列表,新建Map任务并封装对应数据,再调用offload_data 将任务的数据信息发送给NDP单元;最后,调用start_computation唤醒NDP单元进行数据处理. Reduce任务的迁移过程与Map任务类似. 稍有不同的是,Reduce任务中会添加多个Map任务对应的输出缓冲区信息.
2.2.4. 计算核提取和迁移
在动态任务迁移的过程中,最为关键的是计算核的迁移,其目的是将计算任务的代码写入到NDP单元中,以供NDP单元运行时调用. 为此,首先需要将Map任务和Reduce任务的代码分别编译为目标文件. 生成的目标文件符合标准的可执行与可链接格式(executable and linking format,ELF). ELF文件的结构如图4中所示,其中与任务执行代码相关数据主要保存在text段和rodata段. text段保存了代码编译后的运行指令,rodata段保存了常量数据. 通过提取对应ELF文件的text段和rodata段即可获得Map任务和Reduce任务的计算核.
图 4
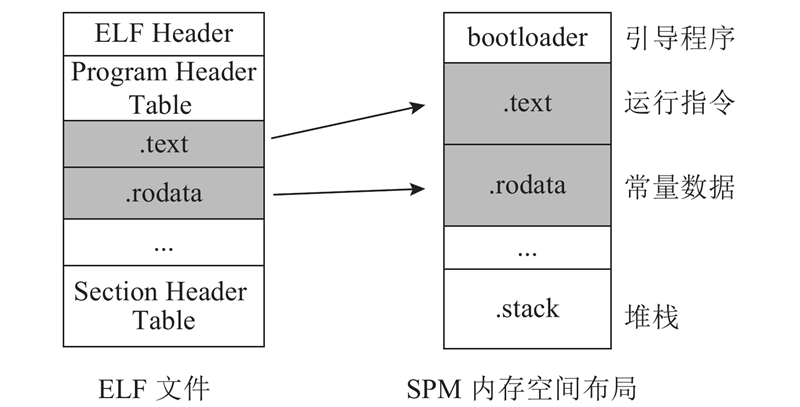
NDP单元包含一块SPM,用于存储NDP单元运行的代码. 当需要进行计算核迁移时,MapReduce框架将ELF文件中提取的text段和rodata段数据写入到相应NDP单元SPM的对应位置. 这正是MapReduce框架调用offload_kernel实现计算核迁移功能的主要过程. 对于处理逻辑相同的计算任务,MapReduce框架只须为NDP单元进行一次计算核迁移,随后可以通过多轮的计算数据迁移实现任务的分批处理. 因此,计算核迁移的开销可以被多轮计算任务分摊.
2.3. 原子操作
3D存储的抽象内存接口允许在Vault控制器中集成一些基本读写操作之外的计算命令[7]. 这些计算命令被称为原子操作. 因此,通过增加原子操作,可以使Vault控制器具备一定的计算能力,以供外部模块调用. 原子操作高度适用于以下计算模式的操作:从存储单元中读取数据,对读取的数据进行逻辑或算术操作,将结果写回存储单元. 正常情况下,数据需要从存储单元中被读取到相应的处理单元中进行处理,处理完成后再被写回到存储单元中,总共需要进出存储单元2次. 原子操作可以在3D堆叠存储的Vault控制器内部实现2次访问,有效减少外围电路和处理单元的活动,降低访问延迟和能量消耗.
针对MapReduce应用的需求,本文主要实现了Increment,AddImmediate,Compare,以及MemCopy等4种原子操作. Increment和AddImmediate分别实现数据自增,加立即数的功能,常用于对变量的操作. Compare用于比较2个数据的大小,支持多种数据类型. MemCopy主要实现数据复制功能,可用于结果数据写回. 这些原子操作可以被用户程序显示调用,并返回一个响应信号,以指示该原子操作是否成功完成.
3. 实验方法
本文的NDP系统基于gem5模拟器[20]实现,支持3D存储以及多个NDP单元的仿真. 模拟器以全系统模式运行,操作系统为Linux,内核版本为3.16. 主处理器为ARM Cortex-A15双核处理器,工作频率为2 GHz,存储单元为3D存储. 为了方便与传统架构进行对比,存储单元的逻辑层中集成了2个NDP单元,每个NDP单元包含一个与主处理器类似的ARM Cortex-A15单核处理器. NDP系统的关键配置参数如表2所示. 其中,3D存储单元包括4层DRAM芯片,共16个Vault,大小为512 MB,时序参数tRP 、tRCD 、tCL、tWR、tRAS、tCK、ttCCD、tBURST分别为3D存储单元的行预充电时间、行寻址到列寻址延迟、列地址选通延迟、写入恢复时间、行地址选通时间、时钟周期时间、列选通到列选通延迟、突发读时间.
表 2 近数据处理(NDP)系统的配置
Tab.2
| 模块 | 配置 |
| 主处理器 | 2x ARM Cortex-A15 core 32 KB L1 I Cache, 64 KB L1 D Cache 2 MB L2 Cache |
| 近数据处理单元 | 1x ARM Cortex-A15 core 1MB SPM, 16-Entry TLB DMA: Burst size 256 Bytes |
| 3D存储单元 | 4 layers, 16 Vaults, 512 MB Timing(ns):tRP = 13.75, tRCD = 13.75, tCL = 13.75, tWR = 15, tRAS = 27.5, tCK = 0.8, ttCCD = 5, tBURST = 3.2 |
采用C语言实现5种典型的MapReduce应用作为评测程序,包括WordCount,InvertedIndex,AdjList,PageRank,以及Sort. WordCount用于统计文档中的单词数量;InvertedIndex以一个文档或者一组文档为输入,用于生成单词和该单词在文档中位置之间的映射;AdjList用于生成图中节点之间的邻接及反向邻接列表;PageRank是一种用于评估网页重要性的算法;Sort对输入数据进行排序.
为了评估近数据处理方法的性能,实验中比较不同的处理系统,分别为Host系统、NDC系统,以及NMR(near-data MapReduce)系统. Host系统作为基准系统,采用传统架构,无NDP单元,所有计算任务在主处理器端运行;NDC系统参考文献[13]的方案,只将Map任务迁移到NDP单元中运行,由于原方案未提供运行环境支持,实验中将其迁移到本文提供的MapReduce框架中运行;NMR系统为本文构建的NDP系统,所有计算任务均迁移到NDP单元中处理,同时采用原子操作进行性能优化.
实验中采用加速比S作为评估指标,定义如下:
式中:Tbase为MapReduce应用程序在作为基准的系统上的运行时间,Ttarget为MapReduce应用程序在待评估的目标系统上的运行时间.
采用能量时延积(energy delay product)P作为系统能效指标,能量时延积越小则能效越高,其定义如下:
式中:E为运行一个指定的MapReduce应用时系统消耗的能量,TD为该MapReduce应用的运行时间.
4. 实验结果分析
4.1. 数据移动
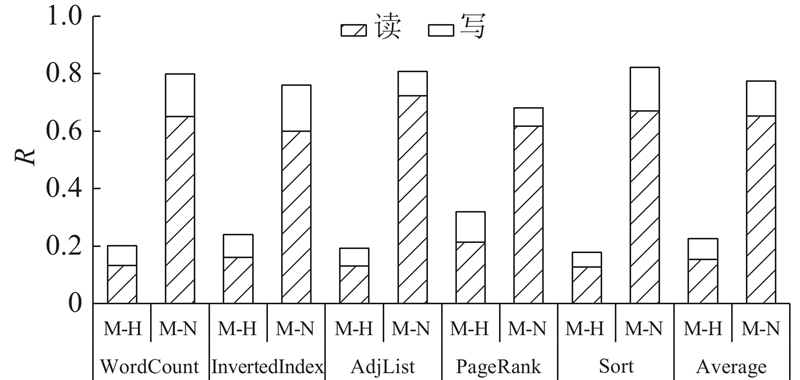
本文NDP系统中数据移动的分布如图5所示. 纵轴的数值代表存储单元与特定处理单元之间传输数据量的比例,用R表示. 横轴的“M-H”代表存储单元与主处理器之间的数据移动,“M-N”代表存储单元与NDP单元之间的数据移动. 可以看到,采用近数据处理后平均75%以上的数据移动位于NDP单元和存储单元之间. 表明对于MapReduce应用,本文提出的近数据处理方法可以有效减少主处理器和存储单元之间的数据移动. 另一个现象是,NDP单元与存储单元之间的数据移动主要来源于NDP单元对存储单元的数据读取. 原因主要有两方面:一方面,NDP单元对主存的部分数据写入操作可以通过原子操作优化,有效减小写入的数据量;另一方面,在Reduce阶段,Reduce任务会对键相同的键/值对数据进行归并操作,最终输出一个“reduced”的结果,是一种天然的“读多写少”的处理模式.
图 5
4.2. 系统能耗
当计算任务迁移到NDP单元中运行之后,系统的能量消耗情况会发生明显的变化. 图6展示了Host系统和NMR系统运行相同MapReduce应用时的能量消耗情况. 数据以Host系统运行WordCount程序的情况进行归一化. 可以看到,相比于Host系统,NMR系统的总能耗明显更低. 对于WordCount,InvertedIndex,AdjList,PageRank和Sort程序,NMR系统的能耗分别只占Host系统的36%,15%,24%,13%和23%. 原因有两点:一是当计算任务被迁移到NDP单元中运行后,主处理器端比较空闲,因而主处理器和其高速缓存的能耗可以被降低;二是当NDP单元进行数据处理时,主处理器和存储单元之间数据传输需求小,通过门控技术[27]关闭部分高速链路,降低了高速链路能耗. 同时,可以观察到,在Host系统中,超过45%的系统能量消耗与数据移动相关(存储单元和高速链路部分),表明对于MapReduce应用,数据移动确实是影响系统能耗表现的重要因素.
图 6
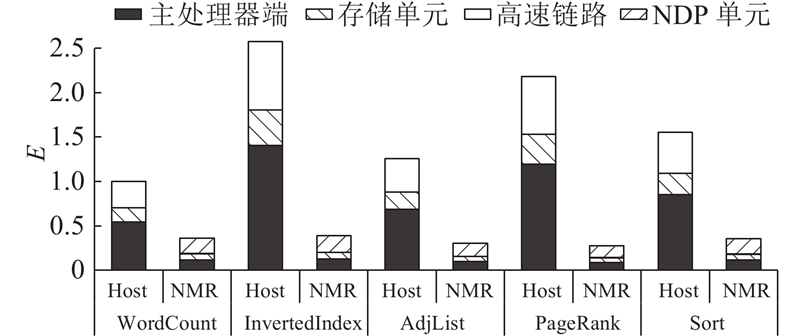
图 6 Host和NMR系统中各个模块的能量消耗
Fig.6 Energy consumption of each module in Host and NMR systems
4.3. 性能提升
首先评估近数据处理分别对Map任务和Reduce任务的性能影响. 图7为NMR系统执行Map任务和Reduce任务相比Host系统的加速比. 可见,近数据处理对Map任务的性能提升较大,平均加速比为4.5倍;而对Reduce任务的性能提升相对较小,平均加速比为2.6倍. 原因在于,相比于Reduce任务,Map任务的处理逻辑和数据访问模式一般更加简单,利用近数据处理进行数据移动优化效果较好.
图 7

图 7 NMR系统中Map任务和Reduce任务的加速比
Fig.7 Speedup of Map task and Reduce task in NMR system
为了评估近数据处理方法的整体性能,对比MapReduce应用在不同处理系统的运行. 加速比以Host系统上的性能作为基准进行归一化,Host、NDC和NMR系统的性能对比如图8所示. 可以看到,对于MapReduce应用,采用近数据处理可以有效提升性能,相比于Host系统,NMR系统的平均加速比为4.4倍,最高可达6.8倍.
图 8
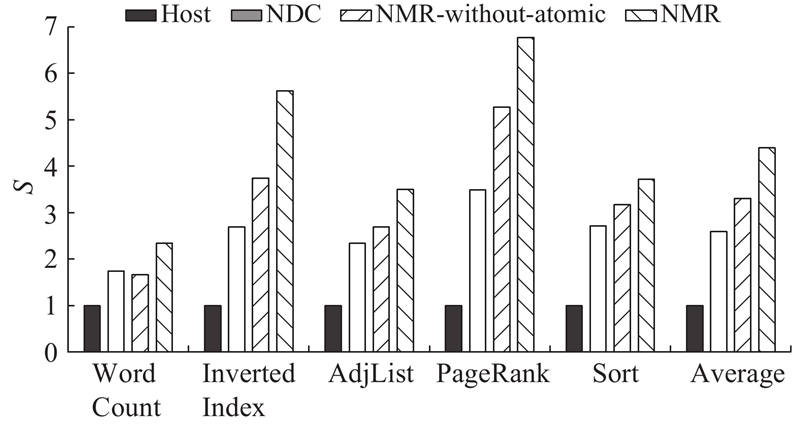
图 8 Host、NDC和NMR系统的性能对比
Fig.8 Performance comparison of Host, NDC and NMR systems
相比于Host系统,NDC系统的平均加速比为2.6倍. 而未采用原子操作优化的NMR系统(图中NMR-without-atomic)的加速比为3.3倍,相比NDC系统提升了27%. 这部分性能提升主要来源于NMR系统对Reduce任务迁移的支持. 一方面,在NDC系统中,Reduce任务只能在主处理器端执行,在数据混排和Reduce阶段中主处理器与存储单元之间的数据移动开销较大. 另一方面,NMR系统采用原子操作对数据访问延迟进行优化,其性能相比未使用原子操作提升了33%. 在这2种因素共同作用下,最终NMR系统的性能相比NDC系统平均提升了70%. 需要指出的是,NDC系统需要预先进行数据分布,这部分开销未计算在其运行时间内.
此外,采用能量时延积对不同系统的能效表现进行评估. 结果表明,NMR系统的能量时延积相当于NDC系统的56%. 可见,相比NDC系统,提出的NMR系统的能效提升了44%.
4.4. 扩展性
通过增加NDP单元的数量,提出的NDP系统的性能变化如图9所示. 数据以Host系统处理时的性能进行归一化. 可以看到,随着NDP单元数量的增加,NDP系统可以同时处理更多的计算任务,系统性能也相应获得了提升. 系统实际获得的加速比低于理想情况下获得的加速比. 理想加速比的推导依据如下:在计算任务数不变的情况下,NDP单元数量增加1倍,相应NDP单元的运行时间减少50%. 实际加速比与理想加速比之间的差异主要来源于两方面. 一方面,不同计算任务处理的数据不同,所需运行时间存在差异,造成各个NDP单元运行时间不一致,与理想情况存在差异;另一方面,当NDP单元数量增加时,需要主处理器的管理调度操作会变得更加复杂,进而影响系统性能,这一点在NDP单元增加到16个时较为明显.
图 9
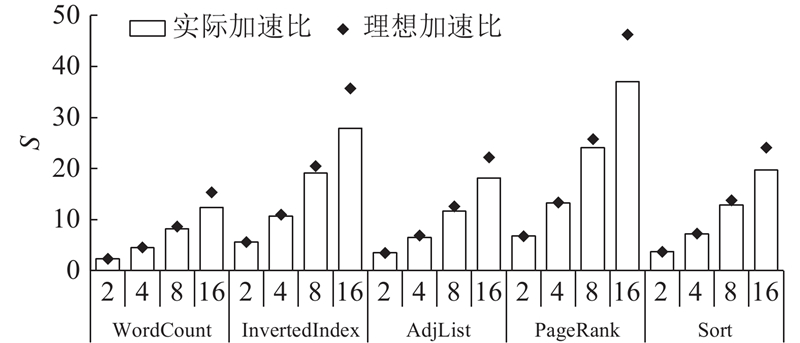
总的来看,当NDP单元的数量扩展到4、8和16个时,系统的平均性能分别提升了8.4、15.2和23.0倍. 相比于理想情况,实际系统运行的性能损失分别为2%、6%和19%. 可见,对于目前的系统配置(单个3D存储单元),NDP单元数量扩展到8个时较为合适.
5. 结 语
本文提出了一种基于动态任务迁移的近数据处理方法. 针对MapReduce应用,基于3D存储构建了近数据处理架构,采用动态任务迁移机制将计算任务迁移到NDP单元中运行,同时利用原子操作优化数据访问. 实验结果表明,在提出的NDP系统中,75%的数据移动发生在存储单元内部,有效减少了主处理单元与存储单元之间的数据移动;相比现有工作,提出的近数据处理方法使系统性能提升了70%,使系统能效提升了44%.
此外,当NDP单元的数量分别扩展到4、8和16个时,NDP系统的性能提升分别可以达到Host系统的8.4、15.2和23.0倍。需要指出的是,在大规模系统中,多个3D存储单元可以通过高速链路连接在一起,使系统具备上千个NDP单元。对于这种情况,得益于MapReduce应用良好的并发特性,本文提出的近数据处理方法同样适用。但此时,系统的主要扩展瓶颈在于上千个NDP单元的管理、调度与通信问题。同时,如何对MapReduce应用的数据流进行优化以提高3D存储单元之间高速链路的利用率,降低3D存储单元之间的数据传输开销,也是系统扩展的难点所在,这些都是未来研究的重要方向.
致谢 感谢美国罗切斯特大学Michael C. Huang老师在NDP系统结构上的指导和帮助.
参考文献
MapReduce: simplified data processing on large clusters
[J].DOI:10.1145/1327452.1327492 [本文引用: 1]
GPUs and the future of parallel computing
[J].DOI:10.1109/MM.2011.89 [本文引用: 1]
Near-data processing: insights from a micro-46 workshop
[J].DOI:10.1109/MM.2014.55 [本文引用: 1]
A scalable processing-in-memory accelerator for parallel graph processing
[J].
Neurostream: Scalable and energy efficient deep learning with smart memory cubes
[J].DOI:10.1109/TPDS.2017.2752706 [本文引用: 2]
A case for intelligent DRAM: IRAM
[J].
The gem5 simulator
[J].DOI:10.1145/2024716.2024718 [本文引用: 1]
Low-power hybrid memory cubes with link power management and two-level prefetching
[J].DOI:10.1109/TVLSI.2015.2420315 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}