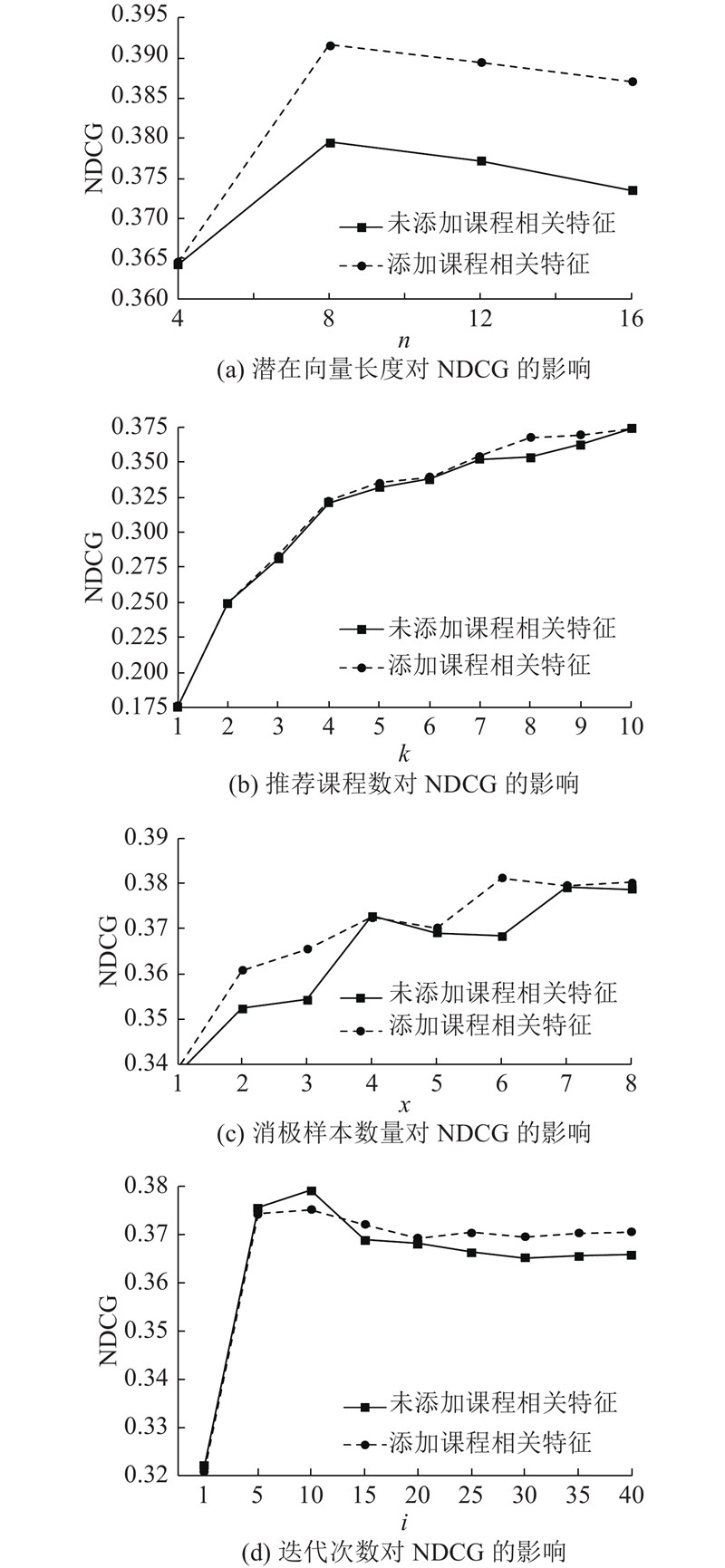
Deep learning was introduced into course recommendation and a neural network model based on assistant information, item and user information (IUNeu) was proposed, aiming at the problem of sparse data and poor recommendation effect at online course recommendation. Based on the existing neural matrix factorization (NeuMF) model with integrated user and course information, the interaction between them was considered to improve the model accuracy of users and courses. Experiments were conducted by crawling the learning data on massive open online course (MOOC) online learning platform. Results showed that with the increase of vector length and the number of recommended courses, the performance of the IUNeu model increased faster than that of the NeuMF model. Different sampling quantities had a great impact on both two models. The models’ performance increased with the increasing sampling quantities, and when the sampling quantity reached a specific threshold, the performance became stable. The convergence rate of the IUNeu model was higher than that of the NeuMF model. The experimental results show that the recommendation quality can be further improved by adding more course feature information to the IUNeu model.
LI Xiao-jun, LIU Hong, SHI Han-xiao, ZHU Liu-qing, ZHANG Ya-hui. Deep learning based course recommendation model. Journal of Zhejiang University(Engineering Science)[J], 2019, 53(11): 2139-2145 doi:10.3785/j.issn.1008-973X.2019.11.011
随着Web2.0和云计算等技术的成熟,出现了以慕课(massive open online course,MOOC)平台为代表的为全球用户提供知识教育服务的网络学习社区. 与单纯的视频公开课相比,慕课这种教学模式既具有正规课程的效能,能保证教学质量,又具有资源免费、课程丰富、以及自由度大等优势,能在很大程度上满足不同群体对知识的需求. 这种理念和实践得到国内外越来越多大学的认同,他们在慕课平台上免费开放自己的课程,方便人们进行在线学习,形成网络学习社区,以此实现知识传播的目的. 当大量学习资源和学习活动同时呈现于网络上时,学习者难免会对过载的信息资源感到困惑,较难快速找到适合自己的学习资源. 因此,如何让知识得到更有效的传播,将合适的知识传播给有需要的人,避免知识的重复生产,促进知识的广泛应用,成为目前在线学习推荐领域重要的研究问题.
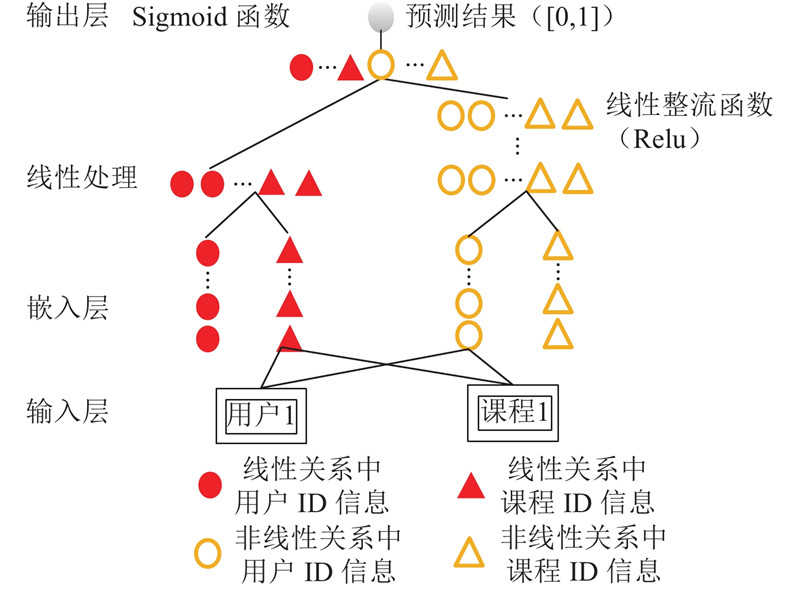
NeuMF模型的具体训练过程如下:1)输入层:提取训练集中用户和课程的ID信息,采用one-hot进行编码. 2)嵌入层:以输入层作为输入,模型中使用了独立的嵌入层,模型左侧为GMF模型,右侧为MLP模型,每层都选用线性整流函数(rectified linear unit,Relu)作为激活函数,输出1×n维矩阵. 3)输出层:将GMF和MLP模型的输出进行首尾相连,通过Sigmoid激活函数将结果映射到[0,1.0],获得预测结果 $\hat y$.
1.2. 实验分析
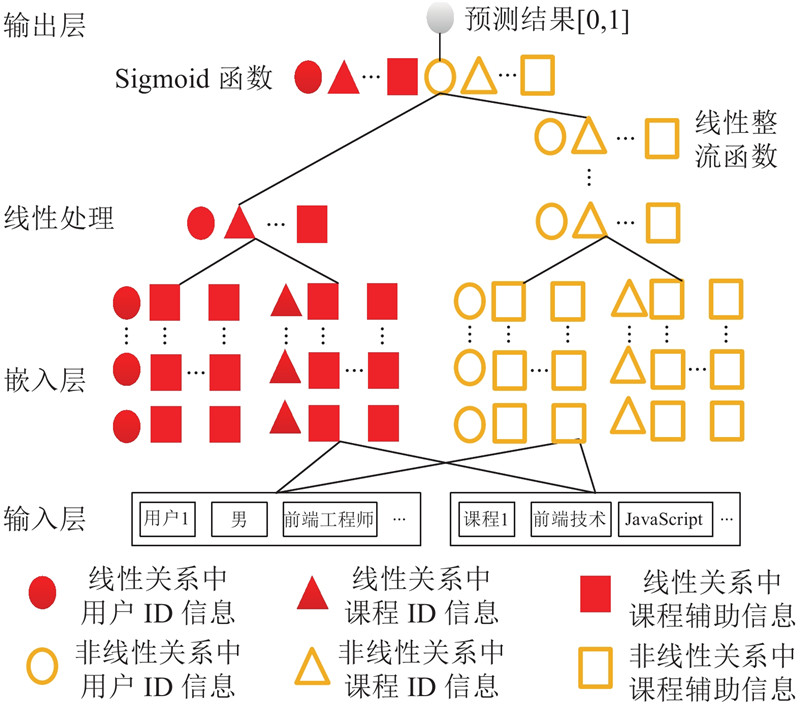
将NeuMF模型应用于分析慕课网的数据,和传统的基于用户的k最近邻算法(user k-nearest neighbor,UserKNN)算法,以及MFALS(matrix factorization-alternating least squares)算法进行比较,在实验中采用留一法(leave one out)方法,以命中率(hit ratio,HR)作为性能评估的指标. 结果发现UserKNN算法由于不涉及潜在特征向量长度n,其命中率为0.075;MFALS涉及到用户矩阵和项目矩阵的构建,其命中率随n的增加而变化,最后稳定在约0.110;NeuMF模型的命中率高于UserKNN算法和MFALS算法,其命中率大于0.500. 究其原因,UserKNN算法用目标用户和k个邻居的相类似的历史行为数据来预测用户未来可能喜欢的课程资源,而MFALS算法根据项目历史评分的高低给用户推荐课程资源,这2个算法均无法较好地满足在线课程资源推荐的实际需求,因此本研究考虑改进NeuMF模型,将推荐问题转化为分类问题. 提出效率更高的基于辅助信息(项目和用户信息)的神经网络模型(neural network model based on assistant information(item and user information),IUNeu). 通过分析用户的历史学习记录来构建模型,并实现以用户和课程为最小单元的分类功能,正类表示用户喜欢,负类表示用户不喜欢,在模型中改进上述UserKNN和MFALS算法在课程推荐上存在的问题,从而提高推荐效果.
CHEN T, HONG L J, SHI Y, et al. Joint text embedding for personalized content-based recommendation [EB/OL]. (2017-06-23). http://arxiv.org/abs/1706.01084.
ALMALIS N D, TSIHRINTZIS G A, KARAGIANNIS N, et al. FoDRA: a new content-based job recommendation algorithm for job seeking and recruiting [C]// 2015 6th International Conference on Information, Intelligence, Systems and Applications. Corfu: IEEE, 2015: 1-7.
ZHOU X, PARANDEHGHEIBI M, FEI X, et al. Content-based recommendation for podcast audio-items using natural language processing techniques [C]// 2016 IEEE International Conference on Big Data. Washington DC: IEEE, 2016: 2378-2383.
OLVERA E P, GODOY D
Evaluating term weighting schemes for content-based tag recommendation in social tagging systems
[J]. IEEE Latin America Transactions, 2012, 10 (4): 1973- 1980
WANG P F, GUO J F, LAN Y Y, et al. Learning hierarchical representation model for nextbasket recommendation [C]// Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2015: 403-412.
SINGH A P, GORDON G J. Relational learning via collective matrix factorization [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas: ACM, 2008: 650-658.
SEDHAIN S, MENON A K, SANNER S, et al. Autorec: autoencoders meet collaborative filtering [C]// Proceedings of the 24th International Conference on World Wide Web. Florence: ACM, 2015: 111-112.
COVINGTON P, ADAMS J, SARGIN E. Deep neural networks for youtube recommendations [C]// Proceedings of the 10th ACM Conference on Recommender Systems. Boston: ACM, 2016: 191-198.
SALAKHUTDINOV R, MNIH A. Bayesian probabilistic matrix factorization using markov chain monte carlo [C]// Proceedings of the 25th International Conference on Machine Learning. Helsinki: ACM, 2008: 880-887.
MA H, YANG H X, LYU M R, et al. Sorec: social recommendation using probabilistic matrix factorization [C]// Proceedings of the 17th ACM Conference on Information and Knowledge Management. Napa Valley: ACM, 2008: 931-940.
DEVOOGHT R, BERSINI H. Collaborative filtering with recurrent neural networks [EB/OL]. (2017-01-03). http://arxiv.org/abs/1608.07400.
WANG C, BLEI D M. Collaborative topic modeling for recommending scientific articles [C]// Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego: ACM, 2011: 448-456.
WANG H, WANG N Y, YEUNG D Y. Collaborative deep learning for recommender systems [C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 1235-1244.
HE X N, LIAO L Z, ZHANG H W, et al. Neural collaborative filtering [C]// Proceedings of the 26th International Conference on World Wide Web. Perth: International World Wide Web Conferences Steering Committee, 2017: 173-182.
ELKAHKY A, SONG Y, HE X D. A multi-view deep learning approach for cross domain user modeling in recommendation systems [C]// Proceedings of the 24th International Conference on World Wide Web. Florence: ACM, 2015: 278-288.
ZHENG L, NOROOZI V, YU P S. Joint deep modeling of users and items using reviews for recommendation [C]// Proceeding of the 10th ACM International Conference on Web Search and Data Mining. Cambridge: ACM, 2017: 425-434.
XU Z H, CHEN C, LUKASIEWICZ T, et al. Tag-aware personalized recommendation using a deep-semantic similarity model with negative sampling [C]// Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. Indianapolis: ACM, 2016: 1921-1924.
OKURA S, TAGAMI Y, ONO S, et al. Embedding-based news recommendation for millions of users [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax: ACM, 2017: 1933-1942.
BANSAL T, BELANGER D, MCCALLUM A. Ask the GRU: multi-task learning for deep text recommendations [C]// Proceedings of the 10th ACM Conference on Recommender Systems. Boston: ACM, 2016: 107-114.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}