在多标签新闻分类中,特征矩阵 ${{X}} = \left[ {{{x}}_1}, {{{x}}_2},\cdots,\right.$ $\left.{{{{x}}_N}} \right] \in {{\bf{R}}^{p \times N}}$ ${{Y}} = \left[ {{{{y}}_1},{{{y}}_2},\cdots,{{{y}}_N}} \right] \in {\{ 0,1\} ^{q \times N}}$ . 其中, $N$ $p$ $q$ $i$ ${{{x}}_i} = $ ${\left[ {x_i^1,x_i^2,\cdots,x_i^{p }} \right]^{\rm{T}}} \in {{\bf{R}}^{p\times 1}}$ ${{{y}}_i} = \left[ {y_i^1}, \right.$ $\left. {y_i^2\cdots,y_i^q} \right]^{\rm T} \in {{\bf{R}}^{q \times 1}}$ .
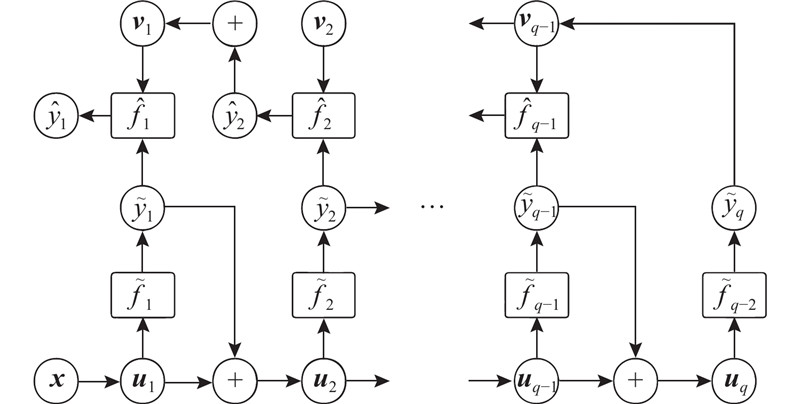
(4) $\!\!\!\!\!\left. \begin{array}{l} \qquad\qquad\qquad\qquad{{\tilde y}^j} = {{\tilde f}_j}\left( {{{{u}}_j}} \right),\\ {{{u}}_j} = \left\{ \begin{array}{c} \left[ {{x^1},{x^2},\cdots,{x^p},{y^1},{y^2},\cdots,{y^{j - 1}}} \right],{\text{训练阶段}};\\ \left[ {{x^1},{x^2},\cdots,{x^p},{{\tilde y}^1},{{\tilde y}^2},\cdots,{{\tilde y}^{j - 1}}} \right],{\text{测试阶段}}. \end{array} \right. \end{array} \right\}\!\!\!\!\!$
(5) $\left. \begin{array}{l} \qquad\qquad\qquad{{\hat y}^j} = {{\hat f}_j}\left( {{{{v}}_j}} \right),\\ {{{v}}_j} = \left\{ \begin{array}{l} \left[ {{{\tilde y}^j},{y^{j + 1}},{y^{j + 2}},\cdots,{y^q}} \right],{\text{训练阶段}};\\ \left[ {{{\tilde y}^j},{{\hat y}^{j + 1}},{{\hat y}^{j + 2}},\cdots,{{\hat y}^q}} \right],{\text{测试阶段}}. \end{array} \right. \end{array} \right\}$
[1]
MCCALLUM A, NIGAM K. A comparison of event models for naive Bayes text classification [C]// AAAI-98 Workshop on Learning for Text Categorization . Madison: AAAI, 1998, 752(1): 41-48.
[本文引用: 1]
[2]
DILRUKSHI I, DE Z K, CALDERA A. Twitter news classification using SVM [C]// International Conference on Computer Science and Education . Colombo: IEEE, 2013: 287-291.
[本文引用: 1]
[3]
KUMAR R B, KUMAR B S, PRASAD C S S Financial news classification using SVM
[J]. International Journal of Scientific and Research Publications , 2012 , 2 (3 ): 1 - 6
[本文引用: 1]
[4]
SELAMAT A, OMATU S Web page feature selection and classification using neural networks
[J]. Information Sciences , 2004 , 158 : 69 - 88
DOI:10.1016/j.ins.2003.03.003
[本文引用: 1]
[5]
KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: ACL, 2014: 1746-1751.
[6]
KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 1725-1732.
[7]
WERMTER S Neural network agents for learning semantic text classification
[J]. Information Retrieval , 2000 , 3 (2 ): 87 - 103
DOI:10.1023/A:1009942513170
[本文引用: 1]
[8]
BLEI D M, NG A Y, JORDAN M I Latent Dirichlet allocation
[J]. Journal of Machine Learning Research , 2003 , 3 : 993 - 1022
[本文引用: 1]
[9]
涂鼎, 陈岭, 陈根才, 等 基于在线层次化非负矩阵分解的文本流主题检测
[J]. 浙江大学学报: 工学版 , 2016 , 50 (8 ): 1618 - 1626
TU Ding, CHEN Ling, CHEN Gen-cai, et al Hierarchical online NMF for detecting and tracking topic
[J]. Journal of Zhejiang University: Engineering Science , 2016 , 50 (8 ): 1618 - 1626
[10]
林萌, 罗森林, 贾丛飞, 等 融合句义结构模型的微博话题摘要算法
[J]. 浙江大学学报: 工学版 , 2015 , 49 (12 ): 2316 - 2325
[本文引用: 1]
LIN Meng, LUO Sen-lin, JIA Cong-fei, et al Microblog topics summarization algorithm merging sentential structure model
[J]. Journal of Zhejiang University: Engineering Science , 2015 , 49 (12 ): 2316 - 2325
[本文引用: 1]
[11]
HARRIS Z S Distributional structure
[J]. Word , 1954 , 10 (2/3 ): 146 - 162
[本文引用: 1]
[12]
SALTON G, YU C T. On the construction of effective vocabularies for information retrieval [C]// ACM SIGIR Forum . Gaithersburg: ACM, 1973: 48-60.
[本文引用: 1]
[13]
BI W, KWOK J T. Multi-label classification on tree-and dag-structured hierarchies [C]// Proceedings of the 28th International Conference on Machine Learning . Bellevue: IMLS, 2011: 17-24.
[本文引用: 1]
[15]
BRINKER K, HÜLLERMEIER E. Case-based multilabel ranking [C]// IJCAI . Hyderabad: IJCAI, 2007: 702-707.
[本文引用: 1]
[16]
TSOUMAKAS G, KATAKIS I, VLAHAVAS I. Mining multi-label data [M]// Data Mining and Knowledge Discovery Handbook . Boston: Springer, 2009: 667-685.
[本文引用: 2]
[17]
HSU D J, KAKADE S M, LANGFORD J, et al. Multi-label prediction via compressed sensing [C]// Advances in Neural Information Processing Systems . Vancouver: NIPS, 2009: 772-780.
[本文引用: 1]
[18]
YEH C K, WU W C, KO W J, et al. Learning deep latent space for multi-label classification [C]// AAAI . San Francisco: AAAI, 2017: 2838-2844.
[本文引用: 5]
[19]
READ J, PFAHRINGER B, HOLMES G, et al Classifier chains for multi-label classification
[J]. Machine Learning , 2011 , 85 (3 ): 333
DOI:10.1007/s10994-011-5256-5
[本文引用: 3]
[20]
王少博, 李宇峰 用于多标记学习的分类器圈方法
[J]. 软件学报 , 2015 , 26 (11 ): 2811 - 2819
[本文引用: 2]
WANG Shao-bo, LI Yu-feng Classifier circle method for multi-label learning
[J]. Journal of Software , 2015 , 26 (11 ): 2811 - 2819
[本文引用: 2]
[21]
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks [C]// Advances in Neural Information Processing Systems . Lake Tahoe: NIPS, 2012: 1097-1105.
[本文引用: 2]
[22]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 2]
[23]
MCCULLOCH W S, PITTS W A logical calculus of the ideas immanent in nervous activity
[J]. The Bulletin of Mathematical Biophysics , 1943 , 5 (4 ): 115 - 133
DOI:10.1007/BF02478259
[本文引用: 2]
[24]
ROSENBLATT F The perceptron: a probabilistic model for information storage and organization in the brain
[J]. Psychological Review , 1958 , 65 (6 ): 386
DOI:10.1037/h0042519
[本文引用: 1]
[25]
LECUN Y, BOTTOU L, BENGIO Y, et al Gradient-based learning applied to document recognition
[J]. Proceedings of the IEEE , 1998 , 86 (11 ): 2278 - 2324
DOI:10.1109/5.726791
[本文引用: 1]
[26]
MIKOLOV T, KARAFIÁT M, BURGET L, et al. Recurrent neural network based language model [C]// 11th Annual Conference of the International Speech Communication Association . Florence: ISCA, 2011: 2877-2880.
[本文引用: 1]
[27]
LEWIS D D, YANG Y, ROSE T G, et al Rcv1: a new benchmark collection for text categorization research
[J]. Journal of Machine Learning Research , 2004 , 5 : 361 - 397
[本文引用: 2]
[28]
ABADI M, BARHAM P, CHEN J, et al. Tensorflow: a system for large-scale machine learning [C]// OSDI . Savannah: USENIX, 2016, 16: 265-283.
[本文引用: 1]
[29]
NAM J, MENCIA E L, KIM H J, et al. Maximizing subset accuracy with recurrent neural networks in multi-label classification [C]// Advances in Neural Information Processing Systems . Long Beach: NIPS, 2017: 5413-5423.
[本文引用: 1]
1
... 随着互联网时代的到来,大众传播媒介迅速发展,信息的巨量生产和高速传播成为常态. 在海量信息前,用户的注意力成为稀缺资源. 如何使受众能够有效寻找、感知、确认以及标签化社会事件和信息,对新闻进行准确分类成为人们日益关注的话题. 早期,人们使用一些传统的机器学习方法,如朴素贝叶斯[1 ] 和支持向量机(support vector machine,SVM)[2 -3 ] 对新闻进行分类. 此外,也有一些研究[4 -7 ] 将神经网络模型引入新闻分类领域. 现有算法多使用单个标签对新闻进行分类,忽视了现实中一条新闻可以被标记上多个标签和主题. 比如关于阿里巴巴财务状况的新闻,既是科技新闻,也是财经新闻;美国军演事件可以同时被纳入军事和国际栏目;“无人驾驶”一直是汽车新闻和科技新闻里的热门话题. ...
1
... 随着互联网时代的到来,大众传播媒介迅速发展,信息的巨量生产和高速传播成为常态. 在海量信息前,用户的注意力成为稀缺资源. 如何使受众能够有效寻找、感知、确认以及标签化社会事件和信息,对新闻进行准确分类成为人们日益关注的话题. 早期,人们使用一些传统的机器学习方法,如朴素贝叶斯[1 ] 和支持向量机(support vector machine,SVM)[2 -3 ] 对新闻进行分类. 此外,也有一些研究[4 -7 ] 将神经网络模型引入新闻分类领域. 现有算法多使用单个标签对新闻进行分类,忽视了现实中一条新闻可以被标记上多个标签和主题. 比如关于阿里巴巴财务状况的新闻,既是科技新闻,也是财经新闻;美国军演事件可以同时被纳入军事和国际栏目;“无人驾驶”一直是汽车新闻和科技新闻里的热门话题. ...
Financial news classification using SVM
1
2012
... 随着互联网时代的到来,大众传播媒介迅速发展,信息的巨量生产和高速传播成为常态. 在海量信息前,用户的注意力成为稀缺资源. 如何使受众能够有效寻找、感知、确认以及标签化社会事件和信息,对新闻进行准确分类成为人们日益关注的话题. 早期,人们使用一些传统的机器学习方法,如朴素贝叶斯[1 ] 和支持向量机(support vector machine,SVM)[2 -3 ] 对新闻进行分类. 此外,也有一些研究[4 -7 ] 将神经网络模型引入新闻分类领域. 现有算法多使用单个标签对新闻进行分类,忽视了现实中一条新闻可以被标记上多个标签和主题. 比如关于阿里巴巴财务状况的新闻,既是科技新闻,也是财经新闻;美国军演事件可以同时被纳入军事和国际栏目;“无人驾驶”一直是汽车新闻和科技新闻里的热门话题. ...
Web page feature selection and classification using neural networks
1
2004
... 随着互联网时代的到来,大众传播媒介迅速发展,信息的巨量生产和高速传播成为常态. 在海量信息前,用户的注意力成为稀缺资源. 如何使受众能够有效寻找、感知、确认以及标签化社会事件和信息,对新闻进行准确分类成为人们日益关注的话题. 早期,人们使用一些传统的机器学习方法,如朴素贝叶斯[1 ] 和支持向量机(support vector machine,SVM)[2 -3 ] 对新闻进行分类. 此外,也有一些研究[4 -7 ] 将神经网络模型引入新闻分类领域. 现有算法多使用单个标签对新闻进行分类,忽视了现实中一条新闻可以被标记上多个标签和主题. 比如关于阿里巴巴财务状况的新闻,既是科技新闻,也是财经新闻;美国军演事件可以同时被纳入军事和国际栏目;“无人驾驶”一直是汽车新闻和科技新闻里的热门话题. ...
Neural network agents for learning semantic text classification
1
2000
... 随着互联网时代的到来,大众传播媒介迅速发展,信息的巨量生产和高速传播成为常态. 在海量信息前,用户的注意力成为稀缺资源. 如何使受众能够有效寻找、感知、确认以及标签化社会事件和信息,对新闻进行准确分类成为人们日益关注的话题. 早期,人们使用一些传统的机器学习方法,如朴素贝叶斯[1 ] 和支持向量机(support vector machine,SVM)[2 -3 ] 对新闻进行分类. 此外,也有一些研究[4 -7 ] 将神经网络模型引入新闻分类领域. 现有算法多使用单个标签对新闻进行分类,忽视了现实中一条新闻可以被标记上多个标签和主题. 比如关于阿里巴巴财务状况的新闻,既是科技新闻,也是财经新闻;美国军演事件可以同时被纳入军事和国际栏目;“无人驾驶”一直是汽车新闻和科技新闻里的热门话题. ...
Latent Dirichlet allocation
1
2003
... 为了解决上述问题,有2种方法:一类是利用特征工程,即利用文本相似性进行分类[8 -10 ] ;另一类是直接应用分类技术,利用词袋模型(bag of words,BOW)[11 ] 、词频-逆向文档频率模型(term frequency- inverse document frequency,TF-IDF)[12 ] 等算法,在将文本数据数值化之后,直接进行有监督多标签分类. 本研究主要探索多标签分类算法在新闻分类领域的应用. ...
基于在线层次化非负矩阵分解的文本流主题检测
0
2016
基于在线层次化非负矩阵分解的文本流主题检测
0
2016
融合句义结构模型的微博话题摘要算法
1
2015
... 为了解决上述问题,有2种方法:一类是利用特征工程,即利用文本相似性进行分类[8 -10 ] ;另一类是直接应用分类技术,利用词袋模型(bag of words,BOW)[11 ] 、词频-逆向文档频率模型(term frequency- inverse document frequency,TF-IDF)[12 ] 等算法,在将文本数据数值化之后,直接进行有监督多标签分类. 本研究主要探索多标签分类算法在新闻分类领域的应用. ...
融合句义结构模型的微博话题摘要算法
1
2015
... 为了解决上述问题,有2种方法:一类是利用特征工程,即利用文本相似性进行分类[8 -10 ] ;另一类是直接应用分类技术,利用词袋模型(bag of words,BOW)[11 ] 、词频-逆向文档频率模型(term frequency- inverse document frequency,TF-IDF)[12 ] 等算法,在将文本数据数值化之后,直接进行有监督多标签分类. 本研究主要探索多标签分类算法在新闻分类领域的应用. ...
Distributional structure
1
1954
... 为了解决上述问题,有2种方法:一类是利用特征工程,即利用文本相似性进行分类[8 -10 ] ;另一类是直接应用分类技术,利用词袋模型(bag of words,BOW)[11 ] 、词频-逆向文档频率模型(term frequency- inverse document frequency,TF-IDF)[12 ] 等算法,在将文本数据数值化之后,直接进行有监督多标签分类. 本研究主要探索多标签分类算法在新闻分类领域的应用. ...
1
... 为了解决上述问题,有2种方法:一类是利用特征工程,即利用文本相似性进行分类[8 -10 ] ;另一类是直接应用分类技术,利用词袋模型(bag of words,BOW)[11 ] 、词频-逆向文档频率模型(term frequency- inverse document frequency,TF-IDF)[12 ] 等算法,在将文本数据数值化之后,直接进行有监督多标签分类. 本研究主要探索多标签分类算法在新闻分类领域的应用. ...
1
... 相比于单标签分类问题,多标签分类有两大难点:1)多个标签之间可能存在着互斥、共生的关系,即标签相关性或标签依赖性. 例如,假设一个男人购买了尿布,他也可能购买啤酒. 当分类算法中“尿布”标签的置信度较高时,“啤酒”标签的输出概率也应当增大. 在某些问题中,标签关系结构是已知的,例如数据中存在的有向无环图结构标签关系、树状结构标签关系[13 ] 等. 但是,在大部分应用场景中,标签结构关系是未知的. 2)在单标签分类中,可能存在维数灾难的问题,即特征空间的维度过高,导致分类性能下降、无法应用于大数据集或过拟合问题等. 在多标签分类中,特征空间和标签空间都可能是高维的,会加剧上述问题. ...
ML-KNN: a lazy learning approach to multi-label learning
1
2007
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
1
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
2
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
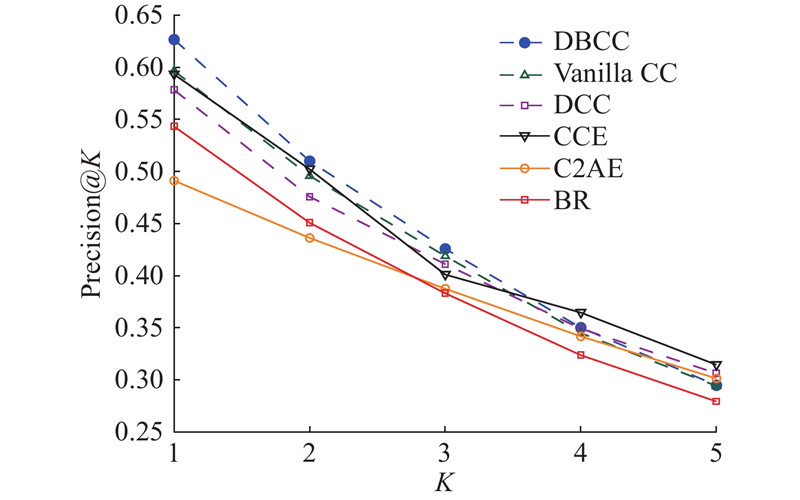
... 用于对比的方法为2个先进的分类器链算法和2个其他多标签算法. 1)CC算法[19 ] . 选择2个不同的分类器链算法:使用SVM作为基分类器的原始分类器链(Vanilla CC)算法和使用深度神经网络作为基分类器(deep classifier chains,DCC)的分类器链算法. 2)CCE算法[20 ] . CCE使用圈结构来避免分类器链,使用多轮迭代求得较为精确的标签值. 3)C2AE算法[18 ] . 作为首个基于深度神经网络的多标签投影算法,C2AE结合深度典型相关分析算法(deep canonical correlation analysis, DCCA)和自动编码器来提取标签依赖.4)BR算法[16 ] . BR算法将多标签问题转化为多个独立的单标签问题进行求解. BR的基分类器同样被设置为深度神经网络. ...
1
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
5
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
... 为了解决上述问题,本研究提出深度双向分类器链(deep bi-directional classifier chains,DBCC)模型,无须考虑标签顺序就能够提取每个标签和剩余标签的依赖关系,并且使用神经网络作为基分类器来提高预测准确率. 近年来随着深度学习的发展,神经网络在分类任务中的表现越来越优异[21 -22 ] ,也有许多标签分类算法引入了神经网络结构,例如C2AE[18 ] . 由于在CC中基分类器执行单标签分类任务,神经网络基分类器分类性能更优. DBCC模型使用传统的分类器链作为正向链,提取第 $j$
... 随着大数据和芯片技术的飞速发展,深度神经网络在单标签分类任务中已经展现出优越的性能[21 -22 ] . 将一些多标签算法[18 ] 引入神经网络结构,极大地提升了其特征提取能力. 但是,现有的分类器链算法的基分类器大多为简单的支持向量机或朴素贝叶斯等分类器,分类效果较差,无法处理大规模数据集. 因此,本研究重点探究如何采用深度神经网络作为基分类器,提升分类器链算法性能. ...
... 用于对比的方法为2个先进的分类器链算法和2个其他多标签算法. 1)CC算法[19 ] . 选择2个不同的分类器链算法:使用SVM作为基分类器的原始分类器链(Vanilla CC)算法和使用深度神经网络作为基分类器(deep classifier chains,DCC)的分类器链算法. 2)CCE算法[20 ] . CCE使用圈结构来避免分类器链,使用多轮迭代求得较为精确的标签值. 3)C2AE算法[18 ] . 作为首个基于深度神经网络的多标签投影算法,C2AE结合深度典型相关分析算法(deep canonical correlation analysis, DCCA)和自动编码器来提取标签依赖.4)BR算法[16 ] . BR算法将多标签问题转化为多个独立的单标签问题进行求解. BR的基分类器同样被设置为深度神经网络. ...
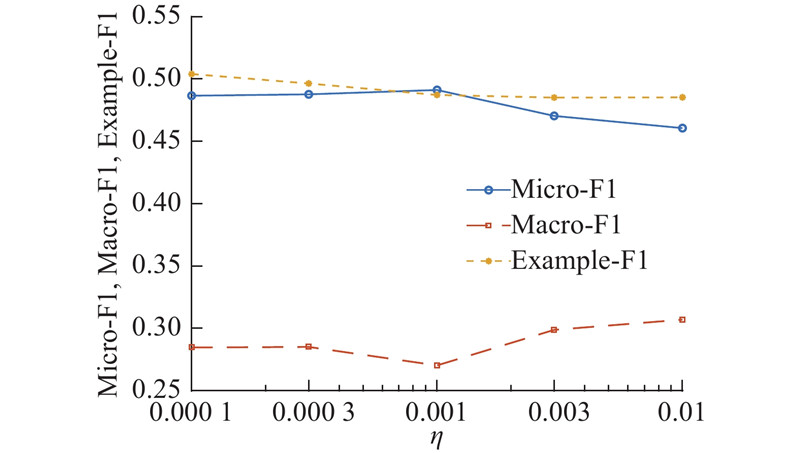
... 使用TensorFlow[28 ] 实现DBCC算法. 设置随机梯度下降算法的学习率默认值 $\eta = 0.001$ $\lambda = 1$ $\tau {\rm{ = 0}}{\rm{.01}}$ . 每个基分类器均为3 层神经网络,维度为 $\left[ {64,8,1} \right]$ . 神经网络的参数由一个标准高斯分布初始化. 在对比实验方面,VanillaCC和CCE算法的基分类器为使用RBF核函数的SVM分类器. 设置CCE算法的迭代次数为5次,BR、DCC算法的学习率 $\eta $ $\left[ {64,8,1} \right]$ 18 ]中的默认参数. 此外,本研究还探究了算法对参数的敏感性,学习率 $\eta $ $\left\{ {10^{ - 4}},3 \times{10^{ - 4}}, {10^{ - 3}},\; \right.$ $3\times{10^{ - 3}} ,{10^{ - 2}}{\rm{\} }}$ . ...
Classifier chains for multi-label classification
3
2011
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
... Read等[19 ] 假设标签之间存在马尔科夫关系,并提出使用分类器链算法进行多标签分类. 分类器链模型由 $q$ $j$ ${{x}}$ ${{x}}$ $j - 1$ ${f_j}$
... 用于对比的方法为2个先进的分类器链算法和2个其他多标签算法. 1)CC算法[19 ] . 选择2个不同的分类器链算法:使用SVM作为基分类器的原始分类器链(Vanilla CC)算法和使用深度神经网络作为基分类器(deep classifier chains,DCC)的分类器链算法. 2)CCE算法[20 ] . CCE使用圈结构来避免分类器链,使用多轮迭代求得较为精确的标签值. 3)C2AE算法[18 ] . 作为首个基于深度神经网络的多标签投影算法,C2AE结合深度典型相关分析算法(deep canonical correlation analysis, DCCA)和自动编码器来提取标签依赖.4)BR算法[16 ] . BR算法将多标签问题转化为多个独立的单标签问题进行求解. BR的基分类器同样被设置为深度神经网络. ...
用于多标记学习的分类器圈方法
2
2015
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
... 用于对比的方法为2个先进的分类器链算法和2个其他多标签算法. 1)CC算法[19 ] . 选择2个不同的分类器链算法:使用SVM作为基分类器的原始分类器链(Vanilla CC)算法和使用深度神经网络作为基分类器(deep classifier chains,DCC)的分类器链算法. 2)CCE算法[20 ] . CCE使用圈结构来避免分类器链,使用多轮迭代求得较为精确的标签值. 3)C2AE算法[18 ] . 作为首个基于深度神经网络的多标签投影算法,C2AE结合深度典型相关分析算法(deep canonical correlation analysis, DCCA)和自动编码器来提取标签依赖.4)BR算法[16 ] . BR算法将多标签问题转化为多个独立的单标签问题进行求解. BR的基分类器同样被设置为深度神经网络. ...
用于多标记学习的分类器圈方法
2
2015
... 现有的多标签分类方法主要有2个类别:算法适应(algorithm adaption,AA)和问题转换(problem transformation,PT). AA将现有单标签分类算法进行转换来解决多标签分类问题. 例如,Zhang等[14 ] 提出的基于k近邻(k nearest neighbor,kNN)的多标签算法,Brinker等[15 ] 提出的基于案例的多标签排名算法等. PT尝试将多标签分类任务转换成其他学习问题. 其中最简单的算法是二值相关(binary relevance,BR)算法[16 ] ,它将多标签问题转化为多个单独的单标签问题. 尽管该算法实现简单,计算速度较快,但它没有考虑标签相关性,因此性能较差. 为了解决这个问题,Hsu等[17 ] 提出基于压缩感知(compressed sensing,CS)的多标签预测算法,将多标签分类算法转换成标签降维问题. 该算法使用随机投影,将原有的高维标签映射到低维标签空间. Yeh等[18 ] 首次集成标签投影技术和深度神经网络,提出典型相关自动编码器(canonical correlated autoencoder,C2AE),进一步增强了投影算法的特征提取能力. Read等[19 ] 提出分类器链(classifier chains,CC)算法,将标签作为输入进行特征增强,有效提取了标签相关性. 但是,由于CC算法要求标签之间具有马尔科夫链性质,对标签顺序较为敏感. 针对此问题,被广泛采用的解决方案是随机生成多个标签序列,然后用集成分类器链(ensemble classifier chains,ECC)算法训练多个分类器链进行预测. 此外,王少博等[20 ] 提出使用分类器圈(classifier circle,CCE)算法构造一个圈结构,避免标签顺序的影响. 但是CCE需要多轮迭代,和ECC一样存在算法规模较大的问题. ...
... 用于对比的方法为2个先进的分类器链算法和2个其他多标签算法. 1)CC算法[19 ] . 选择2个不同的分类器链算法:使用SVM作为基分类器的原始分类器链(Vanilla CC)算法和使用深度神经网络作为基分类器(deep classifier chains,DCC)的分类器链算法. 2)CCE算法[20 ] . CCE使用圈结构来避免分类器链,使用多轮迭代求得较为精确的标签值. 3)C2AE算法[18 ] . 作为首个基于深度神经网络的多标签投影算法,C2AE结合深度典型相关分析算法(deep canonical correlation analysis, DCCA)和自动编码器来提取标签依赖.4)BR算法[16 ] . BR算法将多标签问题转化为多个独立的单标签问题进行求解. BR的基分类器同样被设置为深度神经网络. ...
2
... 为了解决上述问题,本研究提出深度双向分类器链(deep bi-directional classifier chains,DBCC)模型,无须考虑标签顺序就能够提取每个标签和剩余标签的依赖关系,并且使用神经网络作为基分类器来提高预测准确率. 近年来随着深度学习的发展,神经网络在分类任务中的表现越来越优异[21 -22 ] ,也有许多标签分类算法引入了神经网络结构,例如C2AE[18 ] . 由于在CC中基分类器执行单标签分类任务,神经网络基分类器分类性能更优. DBCC模型使用传统的分类器链作为正向链,提取第 $j$
... 随着大数据和芯片技术的飞速发展,深度神经网络在单标签分类任务中已经展现出优越的性能[21 -22 ] . 将一些多标签算法[18 ] 引入神经网络结构,极大地提升了其特征提取能力. 但是,现有的分类器链算法的基分类器大多为简单的支持向量机或朴素贝叶斯等分类器,分类效果较差,无法处理大规模数据集. 因此,本研究重点探究如何采用深度神经网络作为基分类器,提升分类器链算法性能. ...
2
... 为了解决上述问题,本研究提出深度双向分类器链(deep bi-directional classifier chains,DBCC)模型,无须考虑标签顺序就能够提取每个标签和剩余标签的依赖关系,并且使用神经网络作为基分类器来提高预测准确率. 近年来随着深度学习的发展,神经网络在分类任务中的表现越来越优异[21 -22 ] ,也有许多标签分类算法引入了神经网络结构,例如C2AE[18 ] . 由于在CC中基分类器执行单标签分类任务,神经网络基分类器分类性能更优. DBCC模型使用传统的分类器链作为正向链,提取第 $j$
... 随着大数据和芯片技术的飞速发展,深度神经网络在单标签分类任务中已经展现出优越的性能[21 -22 ] . 将一些多标签算法[18 ] 引入神经网络结构,极大地提升了其特征提取能力. 但是,现有的分类器链算法的基分类器大多为简单的支持向量机或朴素贝叶斯等分类器,分类效果较差,无法处理大规模数据集. 因此,本研究重点探究如何采用深度神经网络作为基分类器,提升分类器链算法性能. ...
A logical calculus of the ideas immanent in nervous activity
2
1943
... 深度神经网络的历史可以追溯到20世纪40年代. Mcculloch等[23 ] 提出M-P神经网络模型. Rosenblatt[24 ] 在Mcculloch等[23 ] 工作的基础上,提出感知器(perceptron)模型. 感知器模型与现在的深度神经网络模型较相似. 发展到如今,深度神经网络众所周知,人们发明了上百种不同神经网络结构,将其应用在各种各样的领域,比如Lecun等[25 ] 提出卷积神经网络(convolutional neural network,CNN)并将其应用在计算机视觉领域,Mikolov等[26 ] 提出循环神经网络(recurrent neural network,RNN),在自然语言处理、机器翻译和问答系统等领域有极为成功的应用. ...
... [23 ]工作的基础上,提出感知器(perceptron)模型. 感知器模型与现在的深度神经网络模型较相似. 发展到如今,深度神经网络众所周知,人们发明了上百种不同神经网络结构,将其应用在各种各样的领域,比如Lecun等[25 ] 提出卷积神经网络(convolutional neural network,CNN)并将其应用在计算机视觉领域,Mikolov等[26 ] 提出循环神经网络(recurrent neural network,RNN),在自然语言处理、机器翻译和问答系统等领域有极为成功的应用. ...
The perceptron: a probabilistic model for information storage and organization in the brain
1
1958
... 深度神经网络的历史可以追溯到20世纪40年代. Mcculloch等[23 ] 提出M-P神经网络模型. Rosenblatt[24 ] 在Mcculloch等[23 ] 工作的基础上,提出感知器(perceptron)模型. 感知器模型与现在的深度神经网络模型较相似. 发展到如今,深度神经网络众所周知,人们发明了上百种不同神经网络结构,将其应用在各种各样的领域,比如Lecun等[25 ] 提出卷积神经网络(convolutional neural network,CNN)并将其应用在计算机视觉领域,Mikolov等[26 ] 提出循环神经网络(recurrent neural network,RNN),在自然语言处理、机器翻译和问答系统等领域有极为成功的应用. ...
Gradient-based learning applied to document recognition
1
1998
... 深度神经网络的历史可以追溯到20世纪40年代. Mcculloch等[23 ] 提出M-P神经网络模型. Rosenblatt[24 ] 在Mcculloch等[23 ] 工作的基础上,提出感知器(perceptron)模型. 感知器模型与现在的深度神经网络模型较相似. 发展到如今,深度神经网络众所周知,人们发明了上百种不同神经网络结构,将其应用在各种各样的领域,比如Lecun等[25 ] 提出卷积神经网络(convolutional neural network,CNN)并将其应用在计算机视觉领域,Mikolov等[26 ] 提出循环神经网络(recurrent neural network,RNN),在自然语言处理、机器翻译和问答系统等领域有极为成功的应用. ...
1
... 深度神经网络的历史可以追溯到20世纪40年代. Mcculloch等[23 ] 提出M-P神经网络模型. Rosenblatt[24 ] 在Mcculloch等[23 ] 工作的基础上,提出感知器(perceptron)模型. 感知器模型与现在的深度神经网络模型较相似. 发展到如今,深度神经网络众所周知,人们发明了上百种不同神经网络结构,将其应用在各种各样的领域,比如Lecun等[25 ] 提出卷积神经网络(convolutional neural network,CNN)并将其应用在计算机视觉领域,Mikolov等[26 ] 提出循环神经网络(recurrent neural network,RNN),在自然语言处理、机器翻译和问答系统等领域有极为成功的应用. ...
Rcv1: a new benchmark collection for text categorization research
2
2004
... 使用RCV1-v2数据集来验证所提出算法的有效性. RCV1-v2数据集是Lewis等[27 ] 从新闻网站路透社(Reuters)上收集的新闻稿件集合. 该社每天生产用23种语言写成的11 000 篇新闻稿件,但是这些稿件太过杂乱,也有不少错误. Lewis等[27 ] 收集了部分新闻稿件,并加以整理和修改,最后发布了RCV1-v2数据集. 该数据集包含30 000条新闻稿件,每个新闻稿件具有47 236个特征,对应着101个标签. 为了提高算法运行速度,本研究使用主成分分析算法将特征进行降维,提取前500个特征向量. 同时,在实验时随机选择80%的数据用来训练,剩余20%的数据用作测试. 每个实验均运行5次,并报告平均值和标准差. ...
... [27 ]收集了部分新闻稿件,并加以整理和修改,最后发布了RCV1-v2数据集. 该数据集包含30 000条新闻稿件,每个新闻稿件具有47 236个特征,对应着101个标签. 为了提高算法运行速度,本研究使用主成分分析算法将特征进行降维,提取前500个特征向量. 同时,在实验时随机选择80%的数据用来训练,剩余20%的数据用作测试. 每个实验均运行5次,并报告平均值和标准差. ...
1
... 使用TensorFlow[28 ] 实现DBCC算法. 设置随机梯度下降算法的学习率默认值 $\eta = 0.001$ $\lambda = 1$ $\tau {\rm{ = 0}}{\rm{.01}}$ . 每个基分类器均为3 层神经网络,维度为 $\left[ {64,8,1} \right]$ . 神经网络的参数由一个标准高斯分布初始化. 在对比实验方面,VanillaCC和CCE算法的基分类器为使用RBF核函数的SVM分类器. 设置CCE算法的迭代次数为5次,BR、DCC算法的学习率 $\eta $ $\left[ {64,8,1} \right]$ 18 ]中的默认参数. 此外,本研究还探究了算法对参数的敏感性,学习率 $\eta $ $\left\{ {10^{ - 4}},3 \times{10^{ - 4}}, {10^{ - 3}},\; \right.$ $3\times{10^{ - 3}} ,{10^{ - 2}}{\rm{\} }}$ . ...
1
... Nam等[29 ] 提出基于LSTM的分类器链变种算法. 注意到DBCC算法在结构上与双向循环神经网络模型较相似,因此后续工作将致力于结合双向分类器链算法与RNN、LSTM等神经网络模型. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}