

目前关于PAD情感维度的研究主要是根据情感量表人工标注得到PAD[6],标注耗时长、主观性大等因素限制了情感维度领域的发展,所以要对情感维度P、A、D客观预测. 最小二乘支持向量机(least squares support vector machine,LSSVM)[7]在小样本、非线性识别案例表现出许多优势,主要应用于PM2.5浓度预测[8]、滑坡位移预测[9]等方面,尚未应用于情感维度预测. 在构建回归模型时,输入变量冗余或者变量间的相关性都会影响预测精度. 灰色关联分析(grey relational analysis,GRA)[10]和主成分分析(principal component analysis,PCA)[11]为该问题的解决提供了思路,GRA根据特征与情感维度的几何形状相似程度选择影响较大的主要情感特征,同时采用PCA提取主要情感特征的主成分作为LSSVM的输入,既避免了主观选择的不确定性,又可以减弱特征之间的相关性对预测效果的影响.
本文提出基于GRA-PCA-LSSVM模型预测情感维度P、A、D,利用预测得到的PAD识别情感. 选用TYUT2.0和柏林语音库的情感语句,提取韵律特征、共振峰、MFCC和非线性特征,融合得到FPFMN(fusion feature of prosodic feature,formant,MFCC and nonlinear feature,FPFMN);采用GRA从FPFMN中选取主要情感特征,通过PCA提取主要情感特征的主成分,将主成分作为LSSVM的输入,预测P、A、D;设计情感识别对比实验,验证PAD维度的识别性能. 实验表明,GRA-PCA-LSSVM回归模型对P、A、D维度的预测更精确,而且预测值可以对语音情感有效识别.
1. PAD三维情感模型
人类的情感微妙且复杂,例如悲喜交加、喜极而泣和百感交集等情感不完全属于某一基本情感类别,这对智能化的人机交互提出新挑战,情感的连续空间论[12]为解决该问题提供了解决思路. 该理论提出人类的情感由空间维度组成,该空间几乎可以涵盖所有的情感类型,不同情感之间可以连续、平稳地转变. 连续情感模型中较典型的是PAD三维情感模型[5],该模型将情感分为3个维度,分别如下:P表示愉悦度(pleasure-displeasure,表示个体情感状态的正负特性);A表示激活(arousal-nonarousal,表示个体的神经生理激活程度);D表示优势度(dominance - submissiveness,表示个体对情境和他人的控制状态). PAD三维情感模型如图1所示,任意情感都对应于三维空间的一点.
图 1

2. 理论基础
2.1. 灰色关联分析
GRA[10]根据各影响因素与研究对象之间的几何形状相似程度,判定影响因素对研究对象的贡献程度. 计算步骤如下.
1)确定影响因素和研究对象. 设研究对象
2)原始数据的无量纲化. 为了保证研究对象与影响因素的可比性,采用初值化法处理原始数据. 对
3)计算关联系数. 对研究对象
式中:
4)计算关联度. 将关联系数集求平均,可得关联度:
式中:
2.2. 主成分分析
PCA[11]将具有相关性的变量重新组合为相互无关的变量,PCA的主要步骤如下.
1)对原始数据进行标准化处理:
式中:
2)计算数据经标准化处理后的相关系数矩阵.
式中:n>1;
3)计算矩阵
4)根据情感特征对情感维度的累积贡献,选择前
前
2.3. 最小二乘支持向量机理论
设样本集
式中:
式中:
最终的映射关系如式(9)所示. 在本文研究中,
3. GRA-PCA-LSSVM回归模型构建
将GRA、PCA与LSSVM相结合,构建GRA-PCA-LSSVM回归模型,并用于情感维度的预测. 如图2所示为GRA-PCA-LSSVM模型预测P、A、D维度流程图.
图 2
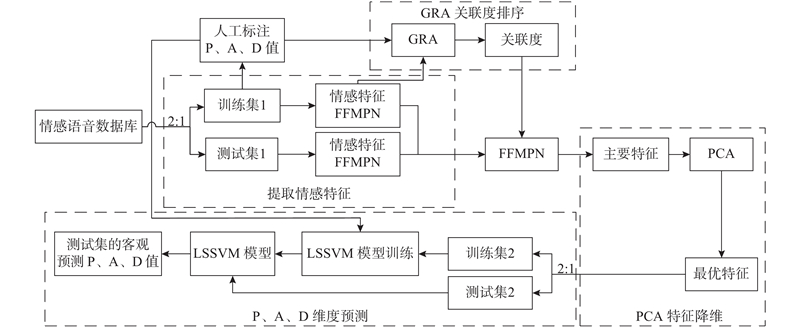
图 2 GRA-PCA-LSSVM模型预测P、A、D流程图
Fig.2 Flow chart of GRA-PCA-LSSVM model to predict P,A,D
具体过程如下.
1)提取情感特征. 将情感语音库中的语音按照训练集1与测试集1的样本数比例为2∶1的比例分类,对语音提取情感特征FPFMN.
2)GRA关联度排序. 由于P、A、D维度相互独立,对P、A、D维度的影响因素会有一定的差别,将训练集的人工标注P、A、D值分别和FPFMN特征进行GRA分析,得到特征与维度的关联度,根据关联度大小将特征进行排序.
3)PCA特征降维. 根据关联度分别筛选出对情感维度P、A、D影响大的主要特征,对主要特征采用PCA降维,消除特征间的相关性,得到最优特征.
4)P、A、D维度预测. 首先将最优特征依照首次对数据库训练集和测试集的分类原则区分,即训练集2与测试集2的样本数比例为2∶1,训练集2的特征是训练集1的FPFMN特征经GRA及PCA优化后的最优特征,测试集2的特征是测试集1的FPFMN特征经GRA及PCA优化后的最优特征;其次由人工标注的P、A、D值(即训练集1的维度)分别与训练集2中各维度对应的最优特征对LSSVM进行训练,得到训练好的LSSVM模型;最后将测试集2(即待测语音各维度对应的最优特征)输入训练好的LSSVM模型,得到待测语音的P、A、D预测值.
4. 实验分析
4.1. 实验数据库
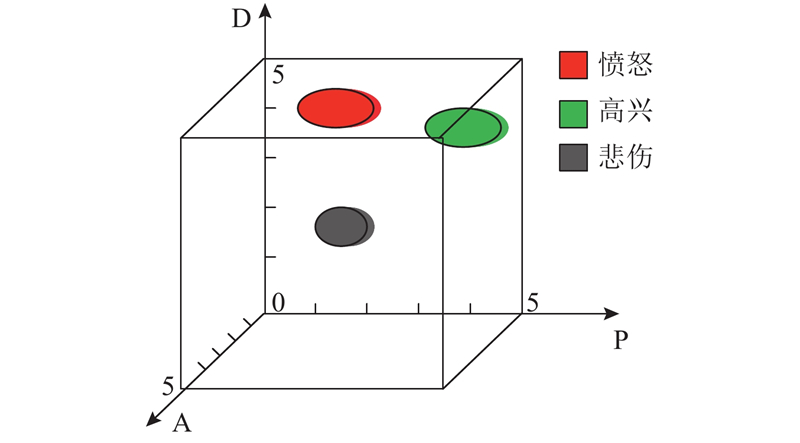
TYUT2.0公开数据库是通过截取广播剧的方式获得的一种摘引型情感数据库,根据改进的PAD情感量表对语音进行维度标注. 在标注试验中,招募100名在校学生(44位男生、56位女生,年龄为21~28岁,身体健康),对TYUT2.0数据库的3类情感共161个语音样本,按照范围为1~5的PAD量表进行PAD维度标注,得到161×100维的数据样本. 每个语音样本的P、A、D维度取这100名学生对该语音维度标注值的平均值. 标注结果的分布如图3所示.
图 3
柏林语音库是由10位演员(5男5女)对7种情感(中性 、生气 、害怕 、高兴 、悲伤 、厌恶 、无聊)进行模拟得到的. 该数据库的语音录制要求演员通过回忆自身经历来完成情绪的表达,使得语音情感真实度高、使用度较广、代表性较强.
4.2. 情感语音特征
为了较完整地表征语音情感进行并更精确地预测PAD维度,提取的具体的语音情感特征类别如表1所示.
表 1 情感语音特征
Tab.1
| 特征 | 特征名称 |
| 韵律特征 | 语速;平均过零率;能量及其1阶差分最大值、最小值、均值;基频及其1阶差分最大值、最小值、均值 |
| 共振峰 | 第1、第2、第3共振峰及其1阶差分最大值、最小值、均值、方差 |
| MFCC | MFCC前12阶的偏度、峰度、均值、方差、中值 |
| 非线性特征 | Hurst指数最大值、最小值、均值、中值、方差;最小延迟时间最大值、最小值、均值、中值、方差;关联维数最大值、最小值、均值、中值、方差;Kolmogorov熵最大值、最小值、均值、中值、方差;最大Lyapunov指数均值、中值、方差 |
4.3. 情感维度影响因素的GRA和PCA分析
设情感维度P(
图 4
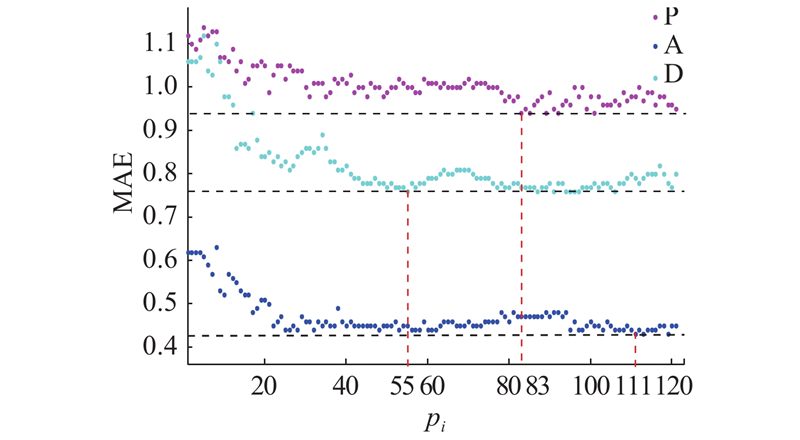
图 4 基于不同特征维数的PAD预测MAE误差趋势图
Fig.4 MAE error chart of PAD prediction based on different feature dimensions
由图4可知,从预测误差整体来看,对维度A的预测误差最小,说明所选特征对A维度的贡献度高于P、D维度. 由于P、A、D维度相互独立,3个维度的主要影响特征不同,基于确定最佳关联特征维数原则,对维度P的预测,取关联度>0.663的83维特征维数作为P维度的主要影响特征;对维度A的预测,取关联度>0.565的111维特征作为A维度的主要影响特征;对维度D的预测,取关联度>0.744的55维特征作为D维度的主要影响特征.
PCA分析时,通常当累积贡献率达到85%以上时,认为所包含的影响因素已包含数据的原始信息,而且累积贡献率越大,包含原始数据的信息越多. 为了尽可能完整地保留信息,选用累积贡献率为99%,此时包含的特征为最优特征,特征维数如表2所示.
表 2 GRA-PCA特征维数
Tab.2
| 维度 | GRA处理后特征维数 | GRA-PCA处理后特征维数 |
| P | 83 | 57 |
| A | 111 | 69 |
| D | 55 | 43 |
根据GRA-PCA处理结果可知,当利用GRA-PCA-LSSVM回归模型预测P、A、D维度时,分别以57维、69维、43维主成分作为LSSVM的输入,以
4.4. 实验方案与结果分析
4.4.1. PAD维度预测
为了验证GRA-PCA-LSSVM模型的预测效果,将GRA-PCA-LSSVM(模型1)的预测结果与GRA-LSSVM(模型2)、2~4的建立如PCA-LSSVM(模型3)、LSSVM(模型4)比较. 模型如下.
模型2:先对训练集的121维特征进行GRA排序,再将由确定最佳关联特征维数原则选择出的主要特征作为LSSVM的输入,P、A、D维度分别作为输出构建模型2.
模型3:先对训练集121维特征进行PCA降维,再将由降维后的特征作为LSSVM的输入,P、A、D维度分别作为输出构建模型3.
模型4:将训练集的121维特征作为LSSVM的输入,P、A、D维度分别作为输出构建模型4.
选取Pearson相关系数r、模型决定系数R2和平均绝对误差(MAE)作为模型预测效果的评价指标,Pearson相关系数和模型决定系数越靠近1越好,MAE越小越好. 以4类回归模型对TYUT2.0数据库和柏林数据库的PAD维度预测结果评价指标如表3所示.
表 3 4类回归模型在2类数据库的预测结果比较
Tab.3
| 维度 | 模型 | TYUT2.0 | EMO-DB | |||||
| r | R2 | MAE | r | R2 | MAE | |||
| P | 模型1 | 0.53 | 0.28 | 0.89 | 0.59 | 0.33 | 0.87 | |
| P | 模型2 | 0.48 | 0.22 | 0.94 | 0.46 | 0.18 | 0.91 | |
| P | 模型3 | 0.48 | 0.23 | 0.92 | 0.46 | 0.19 | 0.94 | |
| P | 模型4 | 0.44 | 0.20 | 0.95 | 0.45 | 0.16 | 0.93 | |
| A | 模型1 | 0.73 | 0.53 | 0.40 | 0.74 | 0.52 | 0.34 | |
| A | 模型2 | 0.70 | 0.49 | 0.43 | 0.68 | 0.38 | 0.40 | |
| A | 模型3 | 0.69 | 0.45 | 0.43 | 0.69 | 0.41 | 0.38 | |
| A | 模型4 | 0.68 | 0.44 | 0.45 | 0.67 | 0.33 | 0.41 | |
| D | 模型1 | 0.69 | 0.46 | 0.74 | 0.96 | 0.92 | 0.27 | |
| D | 模型2 | 0.63 | 0.40 | 0.76 | 0.96 | 0.92 | 0.28 | |
| D | 模型3 | 0.59 | 0.35 | 0.78 | 0.96 | 0.90 | 0.31 | |
| D | 模型4 | 0.59 | 0.34 | 0.80 | 0.96 | 0.91 | 0.29 | |
综合表3,对2类数据库P、A、D维度的预测效果可得如下结论.
1)模型1的Person相关系数最大,说明该模型预测值与标注值的变化趋势最相似;模型1的模型决定系数最大,说明该模型对数据的拟合程度最优;模型1的MAE最小,说明该模型对情感维度P、A、D的预测精度最高.
4.4.2. PAD维度识别情感
方案1:使用FPFMN特征进行语音情感识别.
方案2:使用由GRA-PCA-LSSVM回归模型,预测得到的PAD维度识别情感.
方案3:将FPFMN和由GRA-PCA-LSSVM回归模型预测得到的PAD维度进行融合识别情感.
该实验的评价指标选用识别率,即测试集经SVM得到正确分类的语音样本数与语音样本总数的比值. 识别结果如表4所示.
表 4 PAD维度与FPFMN特征的识别率对比
Tab.4
| % | |||||||
| 情感分类 | TYUT2.0 | EMO-DB | |||||
| 方案1 | 方案2 | 方案3 | 方案1 | 方案2 | 方案3 | ||
| 悲伤 | 52.94 | 52.94 | 76.47 | 100 | 100 | 100 | |
| 愤怒 | 73.68 | 100 | 84.21 | 68.42 | 84.21 | 73.68 | |
| 高兴 | 47.06 | 47.06 | 58.82 | 52.94 | 52.94 | 64.71 | |
| 平均 | 58.49 | 67.92 | 73.58 | 73.58 | 79.25 | 79.25 | |
从表4可以得出以下结论.
1)针对TYUT2.0数据库的语音情感识别,从整体的平均识别结果来看,方案2和方案1在该数据库中的平均识别率依次为58.49%和67.92%,PAD维度的平均识别率高出FPFMN特征9.43%;方案2对“愤怒”情感的识别结果最理想,识别率达到100%;方案3对“愤怒”情感的识别率虽然低于方案2,但高于方案1,此外方案3对“悲伤”和“高兴”情感的识别性能均优于方案1、方案2,且平均识别率高于方案1、方案2,说明PAD与FPFMN特征在语音情感识别方面具有相互促进作用.
2)针对柏林语音库的语音情感识别,方案2不仅维持了方案1在“悲伤”情感上100%的识别率,而且从平均识别结果来看,方案2的识别率高出方案1的识别率5.67%;方案2对“愤怒”情感的识别能力明显增强,比方案1高15.79%;方案3对“愤怒”情感的识别率虽然低于方案2,但高于方案1,而且方案3对“高兴”情感的识别率高于方案1和方案2,说明PAD对FPFMN特征识别情感有一定的补充作用.
3)针对TYUT2.0数据库和柏林语音库的语音情感识别可以发现,PAD维度的平均识别性能优于FPFMN特征,并且PAD维度特征对“愤怒”情感的普适性最优、识别能力最强,达到80%以上;FPFMN与PAD的融合特征对语音情感的识别性能总体优于FPFMN与PAD单独识别,说明PAD维度在语音情感识别中对FPFMN具有补充作用,且在自然度更高的TYUT2.0数据库中补充作用更明显.
综上所述,GRA-PCA-LSSVM模型比LSSVM、GRA-LSSVM、PCA-LSSVM模型对情感维度P、A、D有更精确的预测效果;针对PAD维度在TYUT2.0数据库以及柏林语音库中的情感识别结果可以发现,PAD维度特征较FPFMN特征有更好的识别性能,普适性更强,而且PAD对FPFMN在语音情感识别方面具有一定的补充作用,证明采用的GRA-PCA-LSSVM模型对情感维度PAD预测的有效性.
5. 结 语
为了对情感从更直观的角度进行分析,本文提出基于GRA-PCA-LSSVM回归模型预测情感维度PAD,将预测结果作为特征识别语音情感. 从预测结果来看,通过GRA对情感特征的有效选择以及PCA对特征间相关性的消除作用,降低了LSSVM回归模型的复杂度,提高了对情感维度P、A、D的预测精度. 语音情感识别实验表明,PAD维度与情感特征相比可以有效提高情感识别率,对情感特征的语音情感识别性能具有一定的补充作用. PAD维度是基于情感特征客观预测的结果,情感特征的选择对PAD维度的预测效果有影响作用,在今后的研究中,寻找对情感维度贡献大的最优情感特征集是主要的研究方向.
参考文献
基于PCA和SVM的普通话语音情感识别
[J].
Speech emotion recognition in mandarin based on PCA and SVM
[J].
相空间重构的情感语音特征提取及优化
[J].
Emotional speech feature extraction and optimization of phase space reconstruction
[J].
Pleasure-arousal-dominance: a general framework for describing and measuring individual differences in temperament
[J].DOI:10.1007/BF02686918 [本文引用: 2]
Affect representation and recognition in 3D continuous valence–arousal–dominance space
[J].
Least squares support machine classifiers
[J].DOI:10.1023/A:1018628609742 [本文引用: 2]
Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm
[J].
Prediction of landslide displacement based on GA-LSSVM with multiple factors
[J].DOI:10.1007/s10064-015-0804-z [本文引用: 1]
基于GRA与SVM-mixed的货运量预测方法
[J].DOI:10.3969/j.issn.1009-6744.2016.06.015 [本文引用: 2]
A prediction method of railway freight volumes using GRA and SVM-mixed
[J].DOI:10.3969/j.issn.1009-6744.2016.06.015 [本文引用: 2]
应用PCA和多元非线性回归快速预测储层敏感性
[J].
Application of PCA and multiple nonlinear regression to rapid prediction of reservoir sensitivity
[J].
LSSVM的特征选择算法在烧结过程的应用
[J].DOI:10.3969/j.issn.1001-3997.2018.03.023 [本文引用: 1]
Application in sintering process modeling using the feature selection algorithm of least squares support vector machine
[J].DOI:10.3969/j.issn.1001-3997.2018.03.023 [本文引用: 1]
情感语音数据库优化及PAD情感模型量化标注
[J].
Emotional speech database optimization and quantitative annotation based on PAD emotion model
[J].
情感语音的非线性动力学特征
[J].DOI:10.3969/j.issn.1001-2400.2016.05.029 [本文引用: 1]
Research on nonlinear dynamics features of emotional speech
[J].DOI:10.3969/j.issn.1001-2400.2016.05.029 [本文引用: 1]
基于高斯核函数支持向量机的脑电信号时频特征情感多类识别
[J].DOI:10.11936/bjutxb2017040018 [本文引用: 1]
Human emotion multi-classification recognition based on the EEG time and frequency features by using a Gaussian kernel function SVM
[J].DOI:10.11936/bjutxb2017040018 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}