[1]
LIAN J, ZHANG F, XIE X, et al. Restaurant survival analysis with heterogeneous information [C] // Proceedings of the 26th International Conference on World Wide Web Companion . Perth: IW3C2, 2017: 993-1002.
[本文引用: 2]
[2]
ROIG-TIERNO N, BAVIERA-PUIG A, BUITRAGO-VERA J, et al The retail site location decision process using GIS and the analytical hierarchy process
[J]. Applied Geography , 2013 , 40 : 191 - 198
DOI:10.1016/j.apgeog.2013.03.005
[本文引用: 1]
[3]
XU M, WANG T, WU Z, et al. Demand driven store site selection via multiple spatial-temporal data [C] // Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems . Burlingame: ACM, 2016: 40.
[本文引用: 1]
[4]
KARAMSHUK D, NOULAS A, SCELLATO S, et al. Geo-spotting: mining online location-based services for optimal retail store placement [C] // Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining . Chicago: ACM, 2013: 793-801.
[本文引用: 1]
[5]
CHEN L, ZHANG D, PAN G, et al. Bike sharing station placement leveraging heterogeneous urban open data [C] // Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing . Osaka: ACM, 2015: 571-575.
[本文引用: 1]
[6]
CUO B, LI J, ZHENG V W, et al CityTransfer: Transferring Inter-and Intra-City knowledge for chain store site recommendation based on multi-source urban data
[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies , 2018 , 1 (4 ): 135
[本文引用: 1]
[7]
ZHANG S,YAO L,SUN A X,et al Deep learning based recommender system: a survey and new perspectives
[J]. ACM Computing Surveys (CSUR) , 2019 , 52 (1 ): 5
[本文引用: 2]
[8]
HE X, LIAO L, ZHANG H, et al. Neural collaborative filtering [C] // Proceedings of the 26th International Conference on World Wide Web Companion . Perth: International World Wide Web Conferences Steering Committee, 2017: 173-182.
[本文引用: 8]
[9]
CHIEN Y H, GEORGE E I. A Bayesian model for collaborative filtering [C] // AISTATS . [S.l.]: [s.n.], 1999.
[本文引用: 2]
[10]
BROWNING J, MILLER D J A maximum entropy approach for collaborative filtering
[J]. Journal of VLSI Signal Processing Systems for Signal, Image and Video Technology , 2004 , 37 (2/3 ): 199 - 209
DOI:10.1023/B:VLSI.0000027485.11890.15
[本文引用: 2]
[11]
KOREN Y, BWLL R, VOLINSKY C Matrix factorization techniques for recommender systems
[J]. Computer , 2009 , 42 (8 ): 30 - 37
DOI:10.1109/MC.2009.263
[本文引用: 1]
[12]
TOROSLU Ġ H. A singular value decomposition approach for recommendation systems [D]. Ankara: METU, 2010: 1-67.
[本文引用: 2]
[13]
SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms [C] // Proceedings of the 10th international conference on World Wide Web . Hong Kong: ACM, 2001: 285-295.
[本文引用: 2]
[14]
GETOOR L, SAHAMI M. Using probabilistic relational models for collaborative filtering [C] // Workshop on Web Usage Analysis and User Profiling . [S.l.]: WEBKDD, 1999: 1-6
[本文引用: 1]
[15]
SHI Y, LARSON M, HANJALIC A Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges
[J]. ACM Computing Surveys (CSUR) , 2014 , 47 (1 ): 3
[本文引用: 1]
[16]
KINGMA D P, Ba J. Adam: A method for stochastic optimization [J]. arXiv preprint . arXiv: 1412.6980, 2014.
[本文引用: 2]
[17]
ELKAHKY A M, SONG Y, HE X. A multi-view deep learning approach for cross domain user modeling in recommendation systems [C] // Proceedings of the 24th International Conference on World Wide Web . Florence: IW3C2, 2015: 278-288.
[本文引用: 1]
[18]
WANG H, WANG N, YEUNG D Y. Collaborative deep learning for recommender systems [C] // Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Sydney: ACM, 2015: 1235-1244.
[本文引用: 2]
[19]
MA W J. Deep learning meets recommendation systems [EB/OL]. NYC Data Science Academy. (2017-01-24). [2018-12-17]. https://nycdatascience.com/blog/student-works/deep-learning-meets-recommendation-systems/.
[本文引用: 2]
[20]
XUE H J, DAI X, ZHANG J, et al. Deep matrix factorization models for recommender systems [C] // Proceedings of the 26th International Joint Conference on Artificial Intelligence . Melbourne: AAAI, 2017: 3203-3209.
[本文引用: 2]
[21]
RENDLE S, FREUDENTHALER C, GANTHER Z, et al. BPR: Bayesian personalized ranking from implicit feedback [C] // Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence . Montreal: AUAI, 2009: 452-461.
[本文引用: 1]
2
... 近年来,在城市大数据与人工智能的背景下,智能商业选址一直是一个热门的研究领域. 因为位置不仅影响企业的利润,也影响其未来的发展[1 -2 ] . 一方面,企业的选址影响单个店铺的经济效益、发展方式和该区域居民的生活水平,另一方面,企业的选址对整个城市的布局规划造成影响. 因此,在复杂的城市空间中选取企业的最佳空间位置,以实现商店的客流量和销售利润的最大化,具有非常重要的意义. ...
... 目前已经出现很多基于地理信息服务、POI数据等多元异构信息来选择其最佳位置的研究[1 , 3 -5 ] . 这类研究大多是从多元数据中提取信息来获取各个方面的特征并返回一个数字分数,对应于商店位置的质量评估,使用回归分析的方法为商店找到最佳位置. Karamshuk等[4 ] 依据基于位置的服务信息和人口统计信息得到地理特征(包括密度、邻居熵、竞争性和延森质量)和移动性特征(包括区域流行度、过渡密度、流入流量和过渡质量),使用回归方法为商店找出最优位置. 最近,一些研究将提取的各种特征融入矩阵分解(matrix factorization,MF)技术,进一步提高了商业选址的性能. Guo等[6 ] 将提取的商业特征作为商店项的潜在向量,将地理特征作为地址项的潜在向量,利用矩阵分解模型得到商店的所有地址项的评分,依此选择出最优地址. 然而这些特征需要手工提取,若提取不全面便可能得不到较好的效果;此外,回归和MF方法均是线性模型,若2个特征之间存在某种关联,则此模型就不能很好地表达这些特征. ...
The retail site location decision process using GIS and the analytical hierarchy process
1
2013
... 近年来,在城市大数据与人工智能的背景下,智能商业选址一直是一个热门的研究领域. 因为位置不仅影响企业的利润,也影响其未来的发展[1 -2 ] . 一方面,企业的选址影响单个店铺的经济效益、发展方式和该区域居民的生活水平,另一方面,企业的选址对整个城市的布局规划造成影响. 因此,在复杂的城市空间中选取企业的最佳空间位置,以实现商店的客流量和销售利润的最大化,具有非常重要的意义. ...
1
... 目前已经出现很多基于地理信息服务、POI数据等多元异构信息来选择其最佳位置的研究[1 , 3 -5 ] . 这类研究大多是从多元数据中提取信息来获取各个方面的特征并返回一个数字分数,对应于商店位置的质量评估,使用回归分析的方法为商店找到最佳位置. Karamshuk等[4 ] 依据基于位置的服务信息和人口统计信息得到地理特征(包括密度、邻居熵、竞争性和延森质量)和移动性特征(包括区域流行度、过渡密度、流入流量和过渡质量),使用回归方法为商店找出最优位置. 最近,一些研究将提取的各种特征融入矩阵分解(matrix factorization,MF)技术,进一步提高了商业选址的性能. Guo等[6 ] 将提取的商业特征作为商店项的潜在向量,将地理特征作为地址项的潜在向量,利用矩阵分解模型得到商店的所有地址项的评分,依此选择出最优地址. 然而这些特征需要手工提取,若提取不全面便可能得不到较好的效果;此外,回归和MF方法均是线性模型,若2个特征之间存在某种关联,则此模型就不能很好地表达这些特征. ...
1
... 目前已经出现很多基于地理信息服务、POI数据等多元异构信息来选择其最佳位置的研究[1 , 3 -5 ] . 这类研究大多是从多元数据中提取信息来获取各个方面的特征并返回一个数字分数,对应于商店位置的质量评估,使用回归分析的方法为商店找到最佳位置. Karamshuk等[4 ] 依据基于位置的服务信息和人口统计信息得到地理特征(包括密度、邻居熵、竞争性和延森质量)和移动性特征(包括区域流行度、过渡密度、流入流量和过渡质量),使用回归方法为商店找出最优位置. 最近,一些研究将提取的各种特征融入矩阵分解(matrix factorization,MF)技术,进一步提高了商业选址的性能. Guo等[6 ] 将提取的商业特征作为商店项的潜在向量,将地理特征作为地址项的潜在向量,利用矩阵分解模型得到商店的所有地址项的评分,依此选择出最优地址. 然而这些特征需要手工提取,若提取不全面便可能得不到较好的效果;此外,回归和MF方法均是线性模型,若2个特征之间存在某种关联,则此模型就不能很好地表达这些特征. ...
1
... 目前已经出现很多基于地理信息服务、POI数据等多元异构信息来选择其最佳位置的研究[1 , 3 -5 ] . 这类研究大多是从多元数据中提取信息来获取各个方面的特征并返回一个数字分数,对应于商店位置的质量评估,使用回归分析的方法为商店找到最佳位置. Karamshuk等[4 ] 依据基于位置的服务信息和人口统计信息得到地理特征(包括密度、邻居熵、竞争性和延森质量)和移动性特征(包括区域流行度、过渡密度、流入流量和过渡质量),使用回归方法为商店找出最优位置. 最近,一些研究将提取的各种特征融入矩阵分解(matrix factorization,MF)技术,进一步提高了商业选址的性能. Guo等[6 ] 将提取的商业特征作为商店项的潜在向量,将地理特征作为地址项的潜在向量,利用矩阵分解模型得到商店的所有地址项的评分,依此选择出最优地址. 然而这些特征需要手工提取,若提取不全面便可能得不到较好的效果;此外,回归和MF方法均是线性模型,若2个特征之间存在某种关联,则此模型就不能很好地表达这些特征. ...
CityTransfer: Transferring Inter-and Intra-City knowledge for chain store site recommendation based on multi-source urban data
1
2018
... 目前已经出现很多基于地理信息服务、POI数据等多元异构信息来选择其最佳位置的研究[1 , 3 -5 ] . 这类研究大多是从多元数据中提取信息来获取各个方面的特征并返回一个数字分数,对应于商店位置的质量评估,使用回归分析的方法为商店找到最佳位置. Karamshuk等[4 ] 依据基于位置的服务信息和人口统计信息得到地理特征(包括密度、邻居熵、竞争性和延森质量)和移动性特征(包括区域流行度、过渡密度、流入流量和过渡质量),使用回归方法为商店找出最优位置. 最近,一些研究将提取的各种特征融入矩阵分解(matrix factorization,MF)技术,进一步提高了商业选址的性能. Guo等[6 ] 将提取的商业特征作为商店项的潜在向量,将地理特征作为地址项的潜在向量,利用矩阵分解模型得到商店的所有地址项的评分,依此选择出最优地址. 然而这些特征需要手工提取,若提取不全面便可能得不到较好的效果;此外,回归和MF方法均是线性模型,若2个特征之间存在某种关联,则此模型就不能很好地表达这些特征. ...
Deep learning based recommender system: a survey and new perspectives
2
2019
... 深度学习在图像识别、文本处理、计算机视觉已取得巨大成功,在推荐系统方面也取得了巨大突破[7 ] ,表明深度学习可以从内容中直接提取特征,可以更加准确地学习用户和项目的潜在特征. 因此,本文不直接计算商店特征(密度、环境、口味等)、地址特征(人流量、交通、房价等),而是从深度学习的角度出发,自动提取商店和地址的特征,得到商店对地址的评分以便于为商店推荐出地址列表. ...
... 近年来,深度学习在语音识别、文本处理、计算机视觉等方面已取得巨大成功,可以直接从内容中提取特征;可以很容易地对噪声数据进行处理;可以更加准确地学习用户和项目的特征;可以更容易对数据进行统一处理[7 ] . 因此,一些研究将深度学习与CF相结合[8 , 16 -18 ] ,使得学习的潜在特征更有效,用户或项目的表达能力更强. ...
8
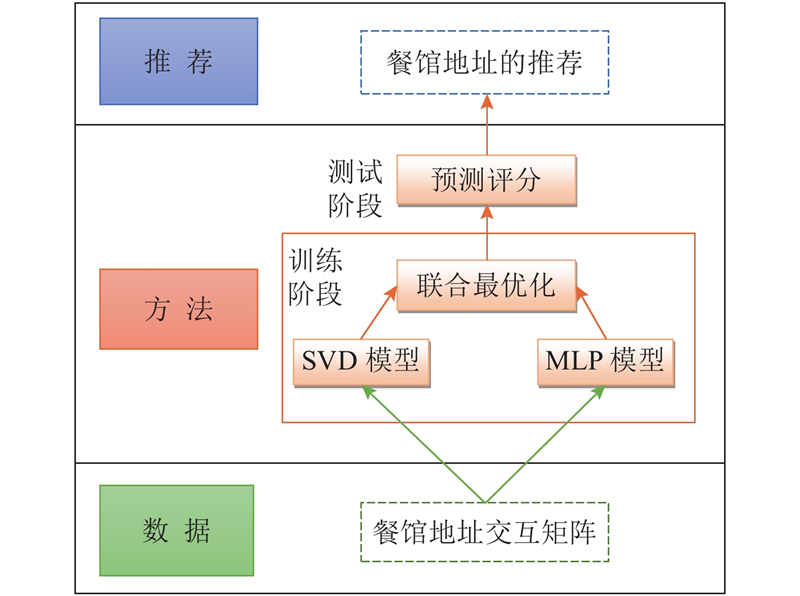
... 本文使用深度学习中的多层感知机(multi-layer perception,MLP)方法非线性地表达餐馆类别对地址的偏好,同时利用MF方法线性刻画餐馆类别对地址的偏好,将2个偏好值相结合从而得到最终的餐馆类别对地址的偏好,为餐馆类别推荐地址列表. 本文的主要工作如下:1)研究He等[8 ] 提出的神经协同过滤(NCF)框架,并将其应用于智能商业选址推荐. 2)在NCF框架基础上,提出新的应用于商业选址的神经协同过滤方法—NeuMF-RS. 使用MF和MLP技术同时表达餐馆对地址的偏好,将2个偏好值相结合得到最终的餐馆对地址的偏好,据此进行地址推荐. 3)使用大众点评的餐馆数据与高德地图的POI数据验证NeuMF-RS对于地址推荐的可行性与有效性. ...
... 近年来,深度学习在语音识别、文本处理、计算机视觉等方面已取得巨大成功,可以直接从内容中提取特征;可以很容易地对噪声数据进行处理;可以更加准确地学习用户和项目的特征;可以更容易对数据进行统一处理[7 ] . 因此,一些研究将深度学习与CF相结合[8 , 16 -18 ] ,使得学习的潜在特征更有效,用户或项目的表达能力更强. ...
... 在推荐系统中一般有几种使用深度学习的方法[19 ] :无监督的学习方法;利用深度学习来预测CF所产生的潜在特征;使用深度学习的方法将学习到的特征作为辅助信息. 例如Ma[19 ] 将深度学习作为一种无监督的学习方法,并通过处理电影海报数据来学习电影之间的相似性. 通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述[18 ] 、跨域行为的用户[17 ] 以及丰富的知识库[8 ] ,然后将深度学习学到的特征与CF的矩阵分解技术相结合. 本文则是利用深度学习来预测CF产生的潜在特征. Xue等[20 ] 提出了一种使用深度神经网络将用户和项目映射到共同低维空间的矩阵分解方法,使用深度学习的方法同时对用户和项目建模,将学习到的用户与项目的潜在向量利用矩阵分解的方式结合得到最终的评分. 与本文直接相关的是He等[8 ] 提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
... [8 ]提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
... 5)NCF[8 ] 提出了一个GMF与MLP的双通道混合模型. 线性和非线性独立的建模、用户与项目独立的嵌入,均使得推荐的模型更加灵活,性能更加稳健、卓越. 详见第2.1节. ...
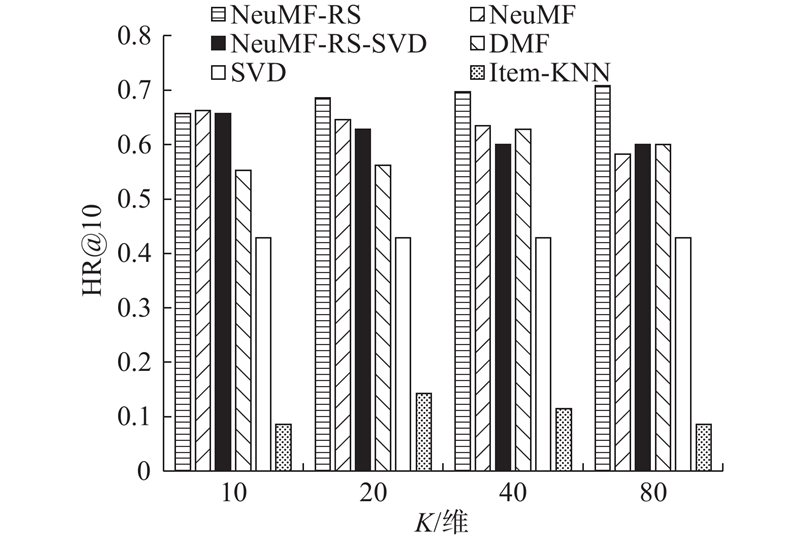
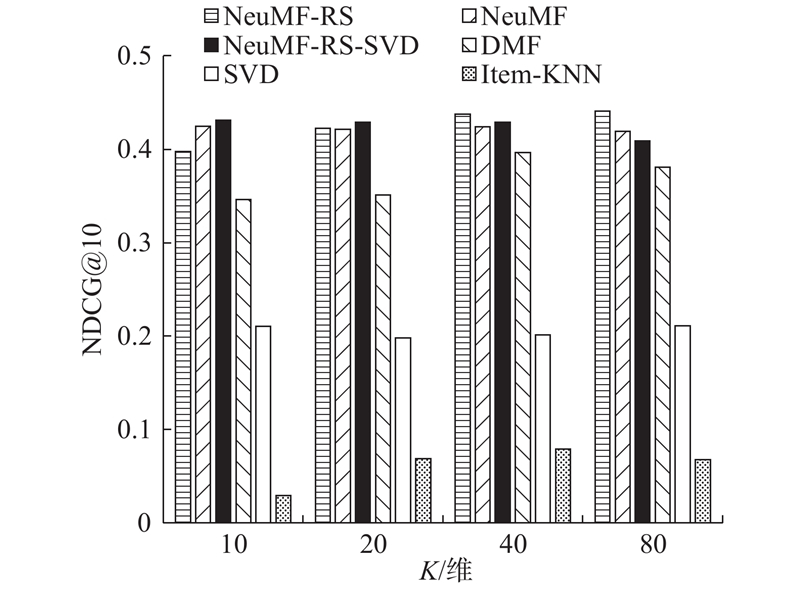
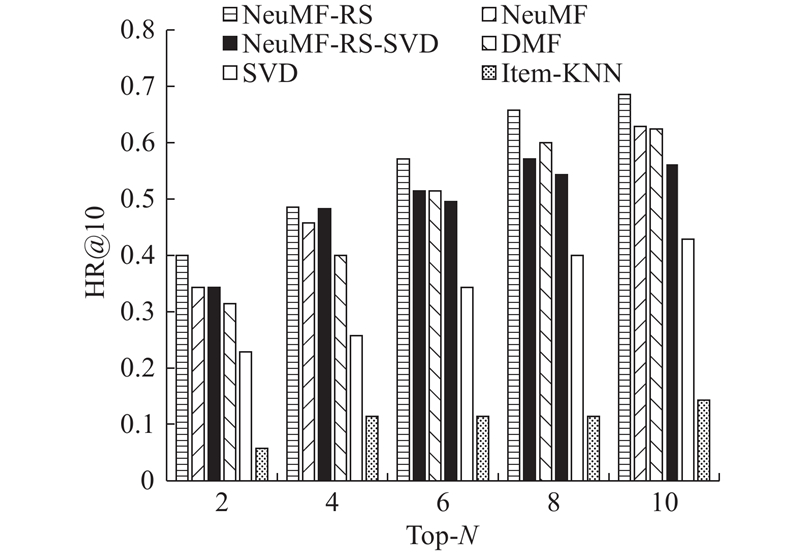
... 为了评估项目推荐的性能,本文采用leave-one-out[8 ] 方法评估,即:对于每一个餐馆类别,随机选择一次交互作为测试集,并将其余的作为训练集. 由于每个餐馆类别的地址选项太多,随机选择100个不与餐馆类别交互的地址,并将要测试的地址排列在这100个地址中. ...
... 排名列表的性能由命中率[8 ] (hitting rate,HR)和归一化折扣累积增益[8 ] (normalized discounted cumulative gain,NDCG)来衡量. HR表示推荐的前N 个项目能够命中用户实际偏好的比例. 而NDGG则表明了推荐列表的排名质量. ...
... [8 ](normalized discounted cumulative gain,NDCG)来衡量. HR表示推荐的前N 个项目能够命中用户实际偏好的比例. 而NDGG则表明了推荐列表的排名质量. ...
2
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
... [9 ]、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
A maximum entropy approach for collaborative filtering
2
2004
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
... [10 ]、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
Matrix factorization techniques for recommender systems
1
2009
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
2
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
... 3)SVD[12 ] 考虑了偏置项的MF,利用均方损失函数来进行优化. ...
2
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
... 1)Item-KNN[13 ] 是基于项目的CF方法,通过不同方法计算项目相似度并获取推荐列表. ...
1
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges
1
2014
... 基于模型的CF方法[9 -10 ] 的主要思想是使用所有收集的评级来学习模型,然后使用该模型进行评分预测. 常用的基于模型的CF方法包括贝叶斯模型[9 ] 、最大熵模型[10 ] 、矩阵分解模型[11 -12 ] 、线性回归模型[13 ] 和概率关系模型[14 ] 等. 其中,矩阵分解模型是应用最广泛的方法[15 ] ,主要通过学习用户与用户、项目与项目之间的关系来自动获得用户、项目的隐属性,相当于把用户-项目评分矩阵分解为用户隐属性矩阵和项目隐属性矩阵,然后通过用户隐属性向量与项目隐属性向量进行点乘来得到该用户对项目的评分,并依此进行推荐. 本文中NeuMF-RS的线性通道便是利用矩阵分解模型完成的. 这样不仅可以学习到餐馆类别和地址的潜在特征,还可以学习到餐馆类别与地址的固有属性. 最重要的是,本文的NeuMF-RS在矩阵分解的基础上融入了深度学习的方法,可以非线性地刻画餐馆类别对地址的偏好,很大程度上提高了推荐的准确性. ...
2
... 近年来,深度学习在语音识别、文本处理、计算机视觉等方面已取得巨大成功,可以直接从内容中提取特征;可以很容易地对噪声数据进行处理;可以更加准确地学习用户和项目的特征;可以更容易对数据进行统一处理[7 ] . 因此,一些研究将深度学习与CF相结合[8 , 16 -18 ] ,使得学习的潜在特征更有效,用户或项目的表达能力更强. ...
... 本文基于keras① 实现了NeuMF-RS,并选用自适应矩估计(Adam)[16 ] 的方法来优化目标函数(式(4)). 模型优化之后,参数确定,可以用训练好的模型预测每个餐馆类别对所有地址的预测评分,据此评分可以为每个餐馆类别推荐地址. ...
1
... 在推荐系统中一般有几种使用深度学习的方法[19 ] :无监督的学习方法;利用深度学习来预测CF所产生的潜在特征;使用深度学习的方法将学习到的特征作为辅助信息. 例如Ma[19 ] 将深度学习作为一种无监督的学习方法,并通过处理电影海报数据来学习电影之间的相似性. 通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述[18 ] 、跨域行为的用户[17 ] 以及丰富的知识库[8 ] ,然后将深度学习学到的特征与CF的矩阵分解技术相结合. 本文则是利用深度学习来预测CF产生的潜在特征. Xue等[20 ] 提出了一种使用深度神经网络将用户和项目映射到共同低维空间的矩阵分解方法,使用深度学习的方法同时对用户和项目建模,将学习到的用户与项目的潜在向量利用矩阵分解的方式结合得到最终的评分. 与本文直接相关的是He等[8 ] 提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
2
... 近年来,深度学习在语音识别、文本处理、计算机视觉等方面已取得巨大成功,可以直接从内容中提取特征;可以很容易地对噪声数据进行处理;可以更加准确地学习用户和项目的特征;可以更容易对数据进行统一处理[7 ] . 因此,一些研究将深度学习与CF相结合[8 , 16 -18 ] ,使得学习的潜在特征更有效,用户或项目的表达能力更强. ...
... 在推荐系统中一般有几种使用深度学习的方法[19 ] :无监督的学习方法;利用深度学习来预测CF所产生的潜在特征;使用深度学习的方法将学习到的特征作为辅助信息. 例如Ma[19 ] 将深度学习作为一种无监督的学习方法,并通过处理电影海报数据来学习电影之间的相似性. 通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述[18 ] 、跨域行为的用户[17 ] 以及丰富的知识库[8 ] ,然后将深度学习学到的特征与CF的矩阵分解技术相结合. 本文则是利用深度学习来预测CF产生的潜在特征. Xue等[20 ] 提出了一种使用深度神经网络将用户和项目映射到共同低维空间的矩阵分解方法,使用深度学习的方法同时对用户和项目建模,将学习到的用户与项目的潜在向量利用矩阵分解的方式结合得到最终的评分. 与本文直接相关的是He等[8 ] 提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
2
... 在推荐系统中一般有几种使用深度学习的方法[19 ] :无监督的学习方法;利用深度学习来预测CF所产生的潜在特征;使用深度学习的方法将学习到的特征作为辅助信息. 例如Ma[19 ] 将深度学习作为一种无监督的学习方法,并通过处理电影海报数据来学习电影之间的相似性. 通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述[18 ] 、跨域行为的用户[17 ] 以及丰富的知识库[8 ] ,然后将深度学习学到的特征与CF的矩阵分解技术相结合. 本文则是利用深度学习来预测CF产生的潜在特征. Xue等[20 ] 提出了一种使用深度神经网络将用户和项目映射到共同低维空间的矩阵分解方法,使用深度学习的方法同时对用户和项目建模,将学习到的用户与项目的潜在向量利用矩阵分解的方式结合得到最终的评分. 与本文直接相关的是He等[8 ] 提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
... [19 ]将深度学习作为一种无监督的学习方法,并通过处理电影海报数据来学习电影之间的相似性. 通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述[18 ] 、跨域行为的用户[17 ] 以及丰富的知识库[8 ] ,然后将深度学习学到的特征与CF的矩阵分解技术相结合. 本文则是利用深度学习来预测CF产生的潜在特征. Xue等[20 ] 提出了一种使用深度神经网络将用户和项目映射到共同低维空间的矩阵分解方法,使用深度学习的方法同时对用户和项目建模,将学习到的用户与项目的潜在向量利用矩阵分解的方式结合得到最终的评分. 与本文直接相关的是He等[8 ] 提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
2
... 在推荐系统中一般有几种使用深度学习的方法[19 ] :无监督的学习方法;利用深度学习来预测CF所产生的潜在特征;使用深度学习的方法将学习到的特征作为辅助信息. 例如Ma[19 ] 将深度学习作为一种无监督的学习方法,并通过处理电影海报数据来学习电影之间的相似性. 通常更多的是利用深度学习来对辅助信息建模,比如项目的文字描述[18 ] 、跨域行为的用户[17 ] 以及丰富的知识库[8 ] ,然后将深度学习学到的特征与CF的矩阵分解技术相结合. 本文则是利用深度学习来预测CF产生的潜在特征. Xue等[20 ] 提出了一种使用深度神经网络将用户和项目映射到共同低维空间的矩阵分解方法,使用深度学习的方法同时对用户和项目建模,将学习到的用户与项目的潜在向量利用矩阵分解的方式结合得到最终的评分. 与本文直接相关的是He等[8 ] 提出的NCF(neural collaborative filtering),该方法使用深度学习对用户-项目交互矩阵直接建模,完全取代了基于矩阵分解,或将矩阵分解作为通用模型特例用于生成用户和项目潜在特征的方法. 本文的NeuMF-RS在NCF的基础上,考虑到餐馆类别与地址的固有属性而添加了偏置项. NeuMF-RS使用深度学习表示用户、项目的潜在向量,可以线性、非线性双通道、独立地刻画用户对项目的偏好,使得整个模型的灵活性好、准确性高. 虽然本文与深度矩阵分解(deep matrix factorization,DMF)均是使用双通道结构和MLP和MF相结合的方法,但是DMF本质上仍是利用MF线性表达用户对项目的偏好,只是使用MLP的方法来描述了用户与项目的潜在表示;而NeuMF-RS则是利用MF和MLP同时描述用户和项目之间的关系,以此刻画用户对项目的偏好. ...
... 4)DMF[20 ] 带有神经网络的深度MF模型,将用户和项目利用深度神经网络分别映射到相同的低维空间,通过计算相似度来进行预测评分. ...
1
... 接下来学习模型参数. 一般来说,对于显性反馈使用均方根误差损失,而对于隐性反馈则使用交叉熵损失[21 ] . 此模型是针对隐性反馈建立的,所以,选择交叉熵损失函数(式(4))来学习模型参数,得到最终的预测评分矩阵,以便于进行推荐: ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}