

线上购物的兴起带动了快递服务行业的发展,快递数据量近几年来呈现出井喷式的增长变化. 据统计,在2016年6月至2017年6月一年的时间里,从西安寄往其他城市的快递量为460多万条,用户数量达170余万;从其他城市寄往西安的快递量有630多万条,用户数量高达320余万. 与此同时,大数据技术的不断进步也使得通过快递数据来研究用户收寄件行为、分析快递网络并解决城市规划、公共安全等相关问题成为可能.
快递数据具有将虚拟网络与现实社会进行关联的独特优势. 快递一般来讲是指快递公司收取寄件人的快件,在规定的时间内运送至指定的收件地点并由收件人签收的过程,具有很强的时效性[1]. 为便于描述,本文对这种同时包含收件与寄件行为的动作定义为寄递,对应的收寄件快递信息即寄递数据. 其中,快递数据中所包含的时间、收发件地址、物品等信息,是对城市进行数据分析的宝贵资源. 深入研究典型城市区域以及不同类型社会群体在收寄件行为上的共性特征和差异行为,不仅有利于企业政府更有针对性地提供公共服务,还能够更好地对市政规划提供数据支撑.
本文提出一种基于寄递大数据的城市画像系统框架,通过数据分析建立城市画像,为城市发展规划、精准营销及公共服务等提供可视化的大数据决策支撑. 首先提出针对不同快递公司的数据预处理方法,将分散在多家快递公司的数据进行整合、清洗、补全、去噪并进行相关转换处理,使之有序化,方便分析利用. 其次,从寄递频次、寄递时间、寄递地址、寄递物品4个维度对城市中不同社会群体与区域的数据进行分析. 最后利用分析结果进行城市画像. 在此基础上,通过西安市2016—2017年的快递数据进行真实场景数据分析并以可视化平台的方式呈现.
1. 相关工作
利用寄递数据进行异常检测最为普遍的是采用基于统计的方法,在此基础上逐渐发展出一系列基于数据挖掘的方法,包括聚类分析、关联分析以及分类分析. 其中,关联分析是从大量数据中挖掘出特征属性之间隐藏的规则或关联知识,从而发现其中的频繁模式,将新的模式与正常模式进行比较,其中偏差较大的即视为异常模式. 郝晟[2]主要将快递数据与侦查业务需求结合,采用OLAP以及数据挖掘算法,分析犯罪嫌疑人的隐藏寄递特征,进一步通过关系网分析寻找同犯. 文杰锋[3]主要研究快递在配送过程中所出现的异常,分别对普通货物和特殊货物进行定义并利用配送的距离以及路径的不同进行异常检测分析. 李万彪等[8]提出的建立关系数据模型生成犯罪网络的方法为本文寄递关系网的建立提供了思路.
从大量真实杂乱的数据中挖掘出人们感兴趣的知识并实际应用,需要数据挖掘技术和理论进行指导. 刘二超[5]主要研究了利用快递数据以及ArcGIS道路信息,将问题模型分为基于点需求的多选址以及基于面的多目标选址问题,最后利用NSGA-II、MNSGA-II和TOPSIS算法构建模型,实现推荐最优化. 范文兵等[9]为了解决快递行业效率低下、管理不善等问题,利用SaaS模型进行数据集中处理. Guo等[10-11]通过人群的签到数据对社会群体进行分析; 采用CityTransfer利用迁移学习将获取到的连锁店信息推荐到其他城市. Kooti等[12]采用基于统计的方法分析Uber中不同用户特征以及影响用户状态转化的因素.
对城市区域的研究主要集中在城市的POI与人群流动性[13]等数据,通过建立模型对城市的区域进行新的划分以及定义. 目前基于快递行业数据的工作大多集中在某一点,而对城市区域刻画的研究相对较少. 受到以上研究工作的启发,本文提出一种基于寄递大数据的城市画像系统框架,从多个维度对寄递数据进行分析,利用数据分析结果反映城市中社群与区域的寄递特征.
2. 城市画像系统框架
寄递大数据城市画像系统的总体架构如图1所示. 该架构主要包含4个部分:1)数据预处理:对不同快递公司的历史数据进行清洗、补全去噪和数据转换等预处理工作并导入数据仓库;2)数据分析:从寄递频次、寄递时间、寄递物品、寄递地址4个维度对数据进行分析;3)城市画像:从城市区域和社会群体2个方面对城市进行刻画;4)可视化平台:通过可视化平台系统展示数据分析和城市画像结果.
图 1

图 1 寄递大数据城市画像的可视化分析框架
Fig.1 Visualization analysis framework of urban profilingusing express big data
3. 数据预处理
数据预处理作为数据分析的前期工作,在整个可视化分析框架中具有至关重要的作用,预处理得到的结果将作为后续分析工作的数据基础支撑,预处理结果的准确性与可用性直接影响到分析结果的可信程度. 本文提出一种针对多家快递公司通用的寄递数据预处理方法,以下小节对其中关键技术点进行介绍.
3.1. 数据补全
由于不同公司在数据备份时没有统一标准,使得大部分快递公司的数据完整性不理想,存在较多冗余字段与缺失信息字段. 针对此问题,提出一种数据清洗补全算法,具体流程见算法一.
算法一:数据清洗补全算法
输入:历史寄递数据集合
输出:质量达标数据
① 从集合D中选择数据质量达到C标准的数据加入O,
② 以号码
③ 选择剩余未达标数据E进行遍历;
④ 将E与P进行数据指纹相似度对比;
⑤ 如果相似度>ε,进行数据补全;
⑥ 选择E中数据质量达到C标准的数据加入O;
⑦ 循环执行②~⑦;
⑧ 直至E变化趋于稳定;
⑨ 输出O;
⑩ 结束.
从原始数据中选定数据分析所必须的23个字段,对数据质量符合标准的数据进行入库,同时以号码为唯一标识建立个人信息库. 对于缺失信息的数据,通过与个人信息库中数据进行相似度比对实现缺失数据的补全去噪.
3.2. 地址转换
原始数据中的地理位置信息主要包括收件人与发件人的省市区、详细地址等信息,由于个人填单喜好与公司录入数据规范不同,相同地理位置可能存在不同的地址名称,不便于直接利用和分析. 为解决此问题,对地址信息进行预处理,将对寄递地址的分析转化为对经纬度的分析. 一条原始快递数据包含收、发件信息中的2组地址信息,需要分组提取并对其中的省市区与详细地址进行数据融合生成补全地址. 随后,本文借助百度API将实际地理位置与经纬度信息进行映射,最终每一个地点用解析得到的经纬度作为该地的唯一标识.
3.3. 物品分类
考虑到汉语灵活的表述方式,寄递数据中物品名称的记录方式多样,无法直接对其进行分析,需要进行自然语言处理获取物品名称所对应的物品类型. 由于每条寄递物品信息的文本都比较短,物品名称的分词数量不固定且上下文无关联. 查阅现有资料无法找到满足本文需求的物品名词库和分词工具,因此本文自行构建商品类目与名词库,对现有分词工具进行改造[17],提出一种针对寄递物品类型的提取算法,通过预处理将物品名称转化为所属物品类型的编号,具体流程见算法二.
算法二:物品类型提取算法
输入:商品类目C,物品名词库D,物品名称S.
输出:物品类型序列编号O.
① 去除物品名称S中无用字符;
② 对S进行分词得到分词结果
③ 遍历R与物品名词库D进行比对,保留结果
④ 遍历
⑤ 如果N中不同编号频次相同,执行⑦;
⑥ 选择N中最高的编号,赋值O,执行⑧;
⑦ 选择N1的编号,赋值O;
⑧ 输出O;
⑨ 结束.
通过对物品类型获取结果的抽样检验以确保该算法结果的准确性. 实验随机选取1 000条物品名称处理结果分成10组人工进行检验,结果如表1所示. 其中,
表 1 快递数据中物品类型提取算法实验结果
Tab.1
| 实验组号 | Sr | Sc | Rc/% | Ra/% |
| 1 | 87 | 81 | 87 | 93.1 |
| 2 | 92 | 83 | 92 | 90.2 |
| 3 | 85 | 82 | 85 | 96.5 |
| 4 | 86 | 81 | 86 | 94.2 |
| 5 | 90 | 88 | 90 | 98.7 |
| 6 | 94 | 88 | 94 | 93.6 |
| 7 | 90 | 82 | 90 | 91.1 |
| 8 | 87 | 81 | 87 | 93.1 |
| 9 | 92 | 86 | 92 | 93.4 |
| 10 | 96 | 90 | 96 | 93.7 |
3.4. 数据格式转换
对于连续型数据,如每单快递时间、一条快递所对应个人信息等,需要通过分箱操作对数据进行划分,以便后续的分析工作. 例如,对于时间信息“2016-09-19 07:57:13”,分别按照月份和周数划分,结果为2016年9月与2016年第39周. 对于同一公司、学校或同一住宅区的快递数据,也可以进行整合,通过对群体数据的分析,减小个体信息中噪声对结果的影响.
4. 数据分析
考虑到快递数据的信息特性,本文从4个维度对数据进行分析:
1)寄递频次。对快递所反映出一个区域的基本寄递频次信息进行统计分析. 在一定时间窗口T内,R1、R2区域的所有快递数据集合为
2)寄递时间。收寄件频数受不同区域(社群)的影响,在时间序列上可能呈现出不同的分布特征. 通过统计一定时间窗口T内的收寄件频数X,建立时间分布折线图,直观分析数据集的时间分布特征. 进一步形式化定义,在时间序列
3)寄递地址。结合地址经纬度信息对一个社群或区域内所有收、发件关系建立寄递关系网络,从而分析寄递网络的结构特征. 将寄递关系网定义为一个无向带权图,收、发件地址经纬度作为无向图的结点,将用户号码作为标识,用户之间的关系用结点间的边来表示,权重为用户寄递关系的频数.
符号定义:
4)寄递物品。对寄递数据中物品所属一级类目进行统计分析. 受到年龄、工作性质、居住环境等因素的影响,不同类型区域(社群)的数据在寄递物品的类型上存在差异. 结合寄递时间挖掘出不同类型区域(社群)寄递物品的喜好及其随时间的变化趋势.
5. 城市画像
数据分析侧重于数据本身所反映出的规律和特征的发现,而城市画像更侧重于待分析数据对象本身的选取以及数据分析结果与现实社会的联系,通过画像的手段对城市的抽象特征进行概括和描述. 本文分别从城市区域和社会群体2个方面对城市进行画像.
5.1. 数据集
采用西安市60余家快递物流公司在2016年6月至2017年6月期间真实快递记录作为数据集,数据覆盖从西安(包括咸阳)寄出和寄往西安的所有快递数据. 数据量约为2 000万条,经过数据预处理剩余可用数据为5 881 166条. 其中,原始数据字段共130个,可用字段23个,经过数据预处理后保留字段14个. 为了保护数据集中用户隐私信息,所有用户真实信息均经过处理,号码经过MD5加密转化为定长无序字符串,仅用于标识一个虚拟用户而不具体到任何真实用户. 经过数据预处理后快递数据主要包含快递信息、收/寄件人信息、物品信息和关联信息等几个部分,如表2所示为数据预处理后的快递数据样例.
表 2 数据预处理后的快递数据样例
Tab.2
| 信息类别 | 数据子项 | 样例 |
| 快递信息 | 运单号 | 602670843721 |
| 寄件时间 | 2016 09|2016 38 | |
| 快递公司 | 顺丰速运 | |
| 寄件人信息 | 寄件人电话 | 9852e4d457j3s... |
| 地址经纬度 | 117.316453 31.855327 | |
| 收件人信息 | 收件人电话 | 15i42d35098d1... |
| 地址经纬度 | 108.989858 34.252365 | |
| 物品信息 | 物品类型 | 鞋类箱包 |
| 学校信息 | 学校名称 | XXX大学 |
| 学校类型 | 本科院校 | |
| 学校属性 | 理工 |
5.2. 社群分析
城市中存在不同类型社会群体,如:学生、公司职员、退休工人等,通过分析社群收寄快递行为中时间、物品、地址的规律,结合其社会属性,进一步发现不同社群的寄递特征并对特征作出合理解释,进而为公共安全、精准营销等提供例证支撑. 对于西安市最主要的社会群体——高校人群,可以从级别和类型2个方面划分. 其中,学校级别包括985/211院校、普通本科院校、专科院校、陕西独立高校和陕西民办高校. 学校类型也可细分为理工、综合、师范、语言、医科、政法、财经、艺术、体育等. 选取西安市64所不同级别和类型的高校,从4个维度对每1个群体的寄递指标进行分析,并与西安市大型IT公司、研究所的寄递指标进行对比。
对每所高校1 a内的寄递频次进行统计. 以西安6所知名院校为例,结合表3可以看出,相同人口数量级别的高校在寄递频次和用户量上也比较相近,用户量与学校人数呈正相关.
表 3 高校寄递信息统计
Tab.3
| 高校 | 寄递频次 | 寄递用户量 | 学校人数 |
| 西安交通大学 | 19 728 | 11 430 | 38 000 |
| 西北工业大学 | 17 627 | 10 097 | 28 000 |
| 长安大学 | 18 128 | 11 096 | 33 000 |
| 西安电子科技大学 | 17 023 | 10 579 | 30 000 |
| 陕西师范大学 | 12 643 | 8 159 | 25 900 |
| 西北大学 | 13 352 | 8 337 | 25 000 |
对一个社群寄递地址特性的分析,最直观的方式便是建立寄递关系网并将其投影在地图上进行展示. 通过此种方式能够立刻获得与该高校进行频繁交互的地理位置信息,有助于分析决策. 如图2所示为对西安某所高校1 a内收、寄件地址进行处理所建立的寄递关系网,可以看出该高校与沿海城市寄递交互更为密切,网络覆盖较为广泛.
图 2
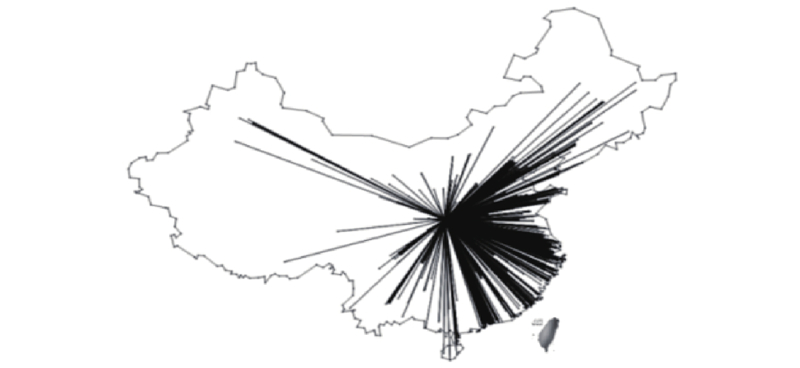
图 3

图 4
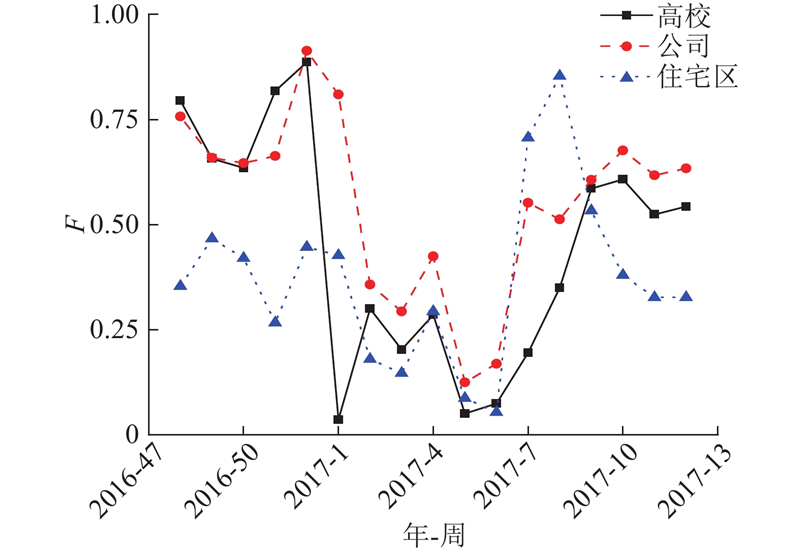
图 4 高校与公司寄递行为的时间分布对比图
Fig.4 Comparison of delivery time distribution betweenuniversities and companies
寄递物品方面,高校与公司物品类型的比重存在一定差异. 如图5所示,公司的办公用品更多,物品类型相对更加单一. 此外,服装、美食、手机数码产品等在高校物品类型中占有较大比例.
图 5
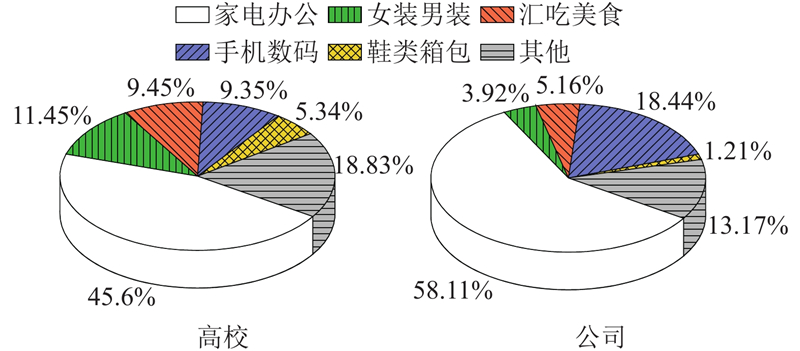
图 5 高校与公司寄递物品类型对比
Fig.5 Comparison of the types of items delivered by universities and companies
如图6所示为不同级别高校1 a内各类物品寄递的分布折线图(R表示物品频数统计结果进行归一化处理后所对应数值). 可以看出,不同级别高校在购买物品的类型方面有着一定的偏好:专科类院校在手机数码类产品的购买比重明显高于其他院校,而对服装产品的购买需求低于均值;本科院校在手机数码、鞋类箱包和护肤彩妆物品上的比重则低于其他院校.
图 6
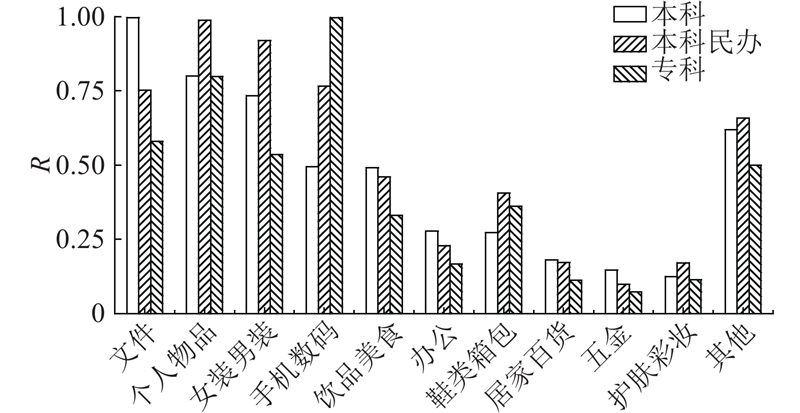
图 7
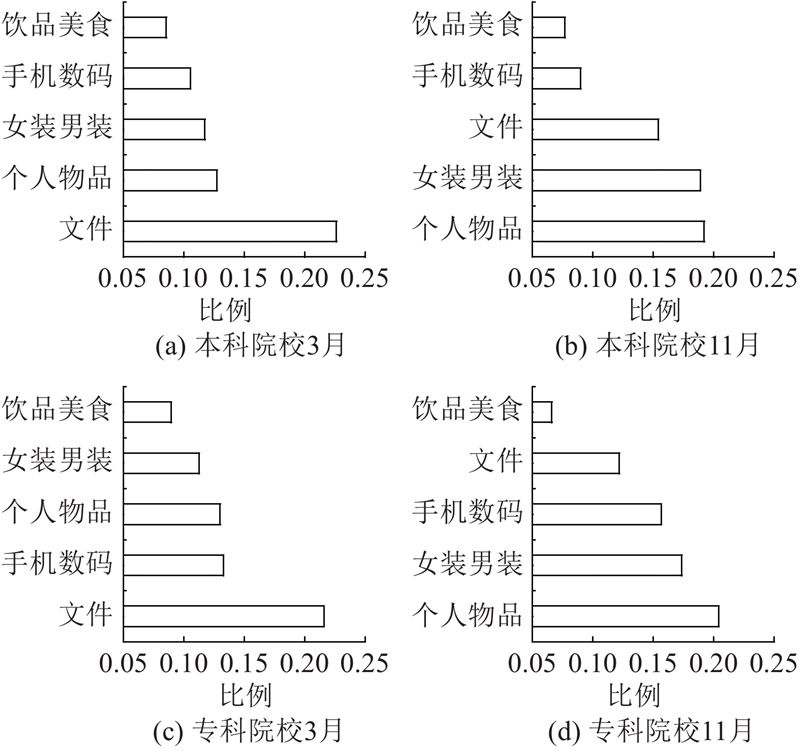
图 7 本科与专科院校3月、11月购买物品类型Top5
Fig.7 Top5 items purchased in March and November by universities of different levels
5.3. 区域分析
城市的区域划分有多种方法,例如基于路网数据划分、基于功能区的划分等. 本文以小区经纬度坐标为圆心,以固定距离为半径覆盖的范围作为划分的区域,分析寄递地址经纬度在区域范围内的数据. 经过试验,当半径为300 m时,区域划分效果最好,结果如图8所示.
图 8

通过爬取安居客网站中不同住宅区二手房屋价格信息将小区等级划分为高档小区、中档小区、普通小区以及独立于普通住宅区域的城中村. 小区等级划分的标准如下:高档小区房价高于12 000元/m2,中档小区房价高于7 000元/m2且低于12 000元/m2,普通小区房价低于7 000元/m2. 随机选取6个高档小区、6个中档小区、6个普通小区以及10个城中村为研究对象,通过对比多个类型区域的寄递行为模式进行分析,发现区域之间的频繁寄递行为与差异.
同类型区域间的寄递情况研究主要是针对各类型小区的收件量随时间的变化情况以及各类型小区购买物品的情况进行分析. 如图9所示为同类型区域间寄递行为随时间的变化情况. 从整体上可以看出,相同类型区域间寄递情况随时间变化存在轻微的差异,总体具有一致性.
图 9
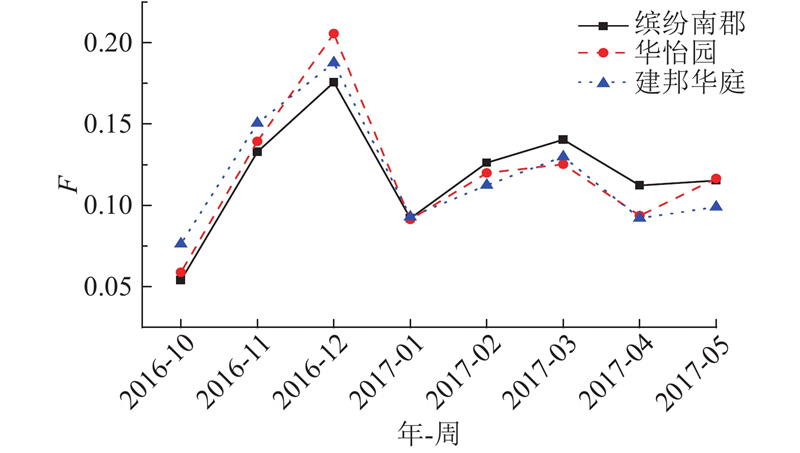
图 9 高档小区寄递量随时间分布图
Fig.9 Distribution of delivery time in high-end residential areas
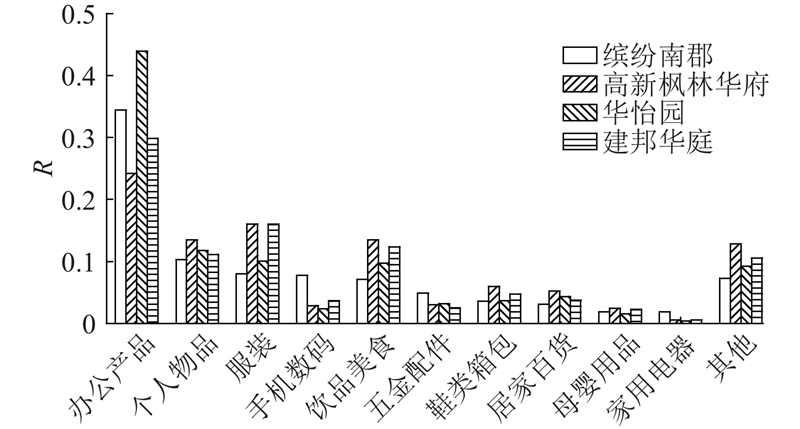
图10反映了相同类型区域用户在购买物品上存在偏好一致性,例如高档小区用户均喜欢购买服装、饮品美食、数码产品等类型的物品.
图 10
不同类型区域间的寄递行为差异主要体现在区域间收件量随时间变化的差异性以及寄递物品比重的差异性. 其中,商业住宅区与城中村区域的收件时间分布情况如图11所示,其相互之间存在明显差异. 从整体上来看,城中村的快递量比其他区域的快递量大. 通过对房价、居住群体等进一步分析可以发现,城中村房价相较于小区的房价更便宜,刚毕业参加工作的人群多选择在此租住,同时该类群体倾向于使用线上购物的方式来满足平日繁忙的生活需求,因此快递量较其他区域更大.
图 11
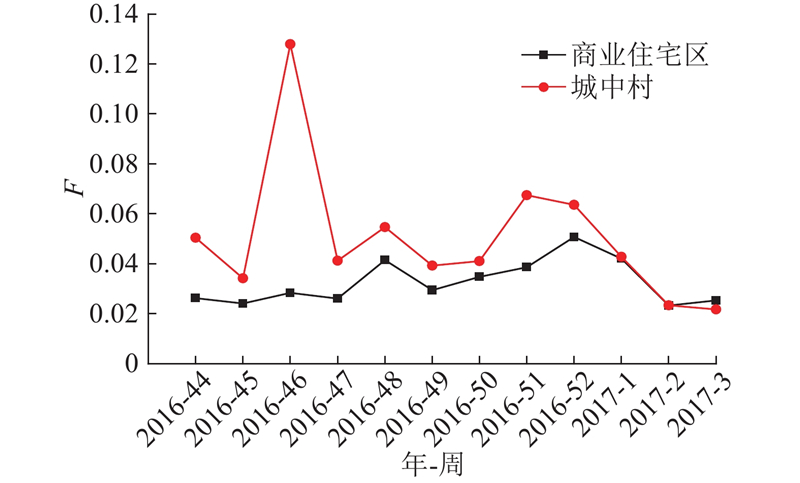
图 11 不同类型区域间收件量随时间分布图
Fig.11 Receipt time distribution between different types of regions
图 12
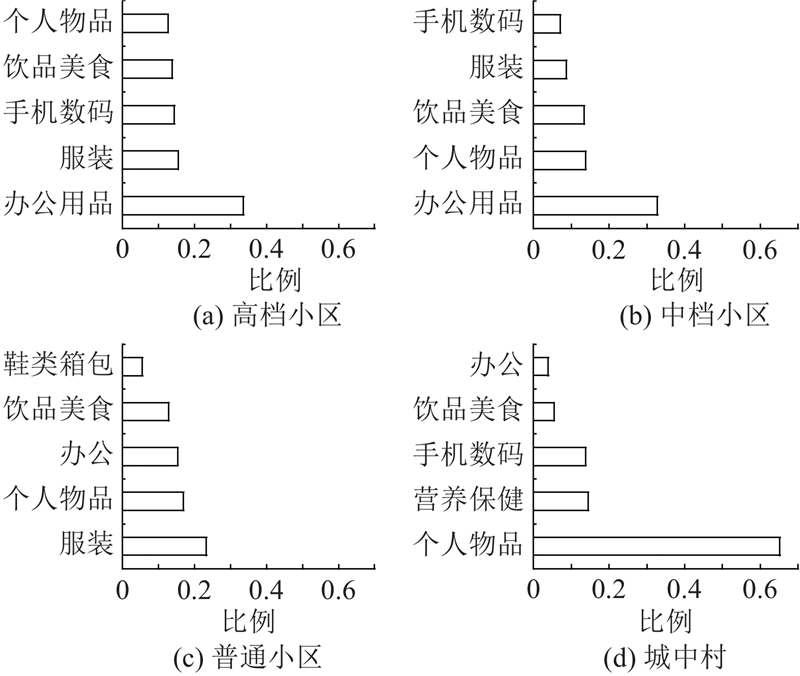
图 12 不同类型区域用户购买物品类型Top5
Fig.12 Top5 item types purchased by users in different regions
此外,区别于其他区域购买的物品,城中村的用户更喜欢购买营养保健产品和手机数码产品. 经分析,城中村属于一种混合型的住宅区,居住的用户群体也是各种各样,妇女、老年人比较多,对于营养保健产品的需求高于其他区域;同时,由于聚集了很多刚毕业的大学生,城中村在电子产品类物品上的购买需求更为强烈.
5.4. 可视化平台
可视化平台主要分为2个部分:前端可视化系统和后台数据处理系统(以下简称“前端”与“后台”),系统界面见图13. 后台的数据存储层存储历史寄递数据,数据处理层负责数据预处理和数据分析任务,依靠数据通信层将分析结果推送至前端. 前端负责分析结果的集成与可视化演示,通信层通过Rest API接收后台请求回调,接收分析结果并在数据存储层缓存,预设的可视化窗口组件用于图表和关键数据的展示.
图 13

图 13 递大数据城市画像系统界面可视化系统界面
Fig.13 Visualization system interface Interface of express big data urban profiling system
6. 结 语
本文主要研究了利用快递数据对城市进行分析的方法,包含4个部分:对不同快递公司的历史数据进行数据预处理;从4个维度对寄递数据进行分析;从城市区域和社会群体2个方面对城市进行刻画;通过可视化平台系统展示数据分析和城市画像结果. 利用西安市2016—2017年的快递数据进行真实场景数据分析,在对西安高校和不同类型小区的分析过程中发现,不同社会群体和区域之间存在的寄递行为规律和异常.
本文存在的不足以及未来改进工作主要如下:一是使用2017—2018年相同月份的寄递数据进行分析,观察文中数据集所发现的寄递行为规律是否依然存在,减小因数据集自身信息缺失所带来的影响;二是对区域划分方法进行优化,使其根据人口密集程度、小区大小等对区域大小实现自适应调整;三是充分利用POI数据与社交媒体数据,考虑区域周边设施和网络中热点事件等因素对快递的影响.
参考文献
Evidential reasoning-based airline network design for long-haul transportation in express delivery
[J].
Based on the theory of grey system to forecast China's business volume of express services
[J].DOI:10.4236/me.2015.62025 [本文引用: 1]
A data-driven fuzzy information granulation approach for freight volume forecasting
[J].DOI:10.1109/TIE.2016.2613974 [本文引用: 1]
基于关系数据模型的犯罪网络挖掘研究
[J].
Criminal network mining based on relational data model
[J].
Extracting social and community intelligence from digital footprints
[J].
CityTransfer: transferring inter-and Intra-City knowledge for chain store site recommendation based on multi-Source urban data
[J].
Fast and accurate neural word segmentation for chinese
[J].
Adversarial multi-criteria learning for Chinese word segmentation
[J].
Network-based predictions of retail store commercial categories and optimal locations
[J].
λ-active learning based microblog-oriented Chinese word segmentation
[J].
Event studies in economics and finance
[J].
Shop-type recommendation leveraging the data from social media and location-based services
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}