[1]
姚聪. 自然图像中文字检测与识别研究[D]. 武汉: 华中科技大学, 2014.
[本文引用: 1]
YAO Cong. Research on text detection and recognition in natural images [D]. Wuhan: Huazhong University of Science and Technology, 2014.
[本文引用: 1]
[2]
杨飞 自然场景图像中的文字检测综述
[J]. 电子设计工程 , 2016 , 24 (24 ): 165 - 168
[本文引用: 1]
YANG Fei Detecting text in natural scene images were reviewed
[J]. Electronic Design Engineering , 2016 , 24 (24 ): 165 - 168
[本文引用: 1]
[3]
DONOSER M, BISCHOF H. Efficient maximally stable extremal region (MSER) tracking [C]// Computer Vision and Pattern Recognition . New York: IEEE, 2006: 553-560.
[本文引用: 1]
[4]
EPSHTEIN B, OFEK E, WEXLER Y. Detecting text in natural scenes with stroke width transform [C]// Computer Vision and Pattern Recognition . San Francisco: IEEE, 2010: 2963-2970.
[本文引用: 1]
[5]
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// International Conference on Neural Information Processing Systems . Lake Tahoe: ACM, 2012: 1097-1105.
[本文引用: 1]
[7]
TIAN Z, HUANG W, HE T, et al. Detecting text in natural image with connectionist text proposal network [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 56-72.
[本文引用: 3]
[8]
YIN X C, YIN X, HUANG K, et al Robust text detection in natural scene images
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2014 , 36 (5 ): 970 - 983
DOI:10.1109/TPAMI.2013.182
[本文引用: 1]
[9]
NEUMANN L, MATAS J Real-time lexicon-free scene text localization and recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 38 (9 ): 1872 - 1885
DOI:10.1109/TPAMI.2015.2496234
[本文引用: 2]
[10]
BUTA M, NEUMANN L, MATAS J. Fastext: efficient unconstrained scene text detector [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1206-1214.
[本文引用: 1]
[11]
MA J, SHAO W, YE H, et al. Arbitrary-oriented scene text detection via rotation proposals [J]. IEEE Transactions on Multimedia , 2018, 20(11): 3111-3122.
[本文引用: 3]
[12]
ZHOU X, YAO C, WEN H, et al. EAST: an efficient and accurate scene text detector [C]// Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2642-2651.
[本文引用: 2]
[13]
LIAO M, SHI B, BAI X, et al. TextBoxes: a fast text detector with a single deep neural network [C]// Thirty-First AAAI Conference on Artificial Intelligence . San Francisco: AAAI, 2017: 4161-4167.
[14]
HONG S, ROH B, KIM K H, et al. PVANet: lightweight deep neural networks for real-time object detection [C]// Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016. arXiv: 1611.08588.
[15]
DENG D, LIU H, LI X, et al. PixelLink: detecting scene text via instance segmentation [C]// Thirty-Second AAAI Conference on Artificial Intelligence . San Francisco: AAAI, 2018: 6773-6780.
[本文引用: 1]
[16]
SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training region-based object detectors with online hard example mining [C]// Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 761-769.
[本文引用: 1]
[17]
ANTHIMOPOULOS M, GATOS B, PRATIKAKIS I A two-stage scheme for text detection in video images
[J]. Image and Vision Computing , 2010 , 28 (9 ): 1413 - 1426
DOI:10.1016/j.imavis.2010.03.004
[本文引用: 1]
[18]
LIN T Y, GOYAL P, GIRSHICK R, et al Focal loss for dense object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , PP (99 ): 2999 - 3007
[本文引用: 1]
[19]
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 936-944.
[本文引用: 1]
[20]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Computer Vision and Pattern Recognition . Amsterdam: IEEE, 2016: 770-778.
[本文引用: 1]
[21]
LIN G, MILAN A, SHEN C, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017, 1925-1934.
[本文引用: 2]
[22]
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C]// Advances in Neural Information Processing Systems . Montreal: ACM, 2015: 91-99.
[本文引用: 1]
[23]
UIJLINGS J R R, VAN DE SANDE K E A, GEVERS T, et al Selective search for object recognition
[J]. International Journal of Computer Vision , 2013 , 104 (2 ): 154 - 171
DOI:10.1007/s11263-013-0620-5
[本文引用: 1]
[24]
ZITNICK C L, DOLLAR P. Edge boxes: locating object proposals from edges [C]// European Conference on Computer Vision . Zurich: Springer, 2014: 391-405.
[本文引用: 1]
[25]
VEIT A, MATERA T, NEUMANN L, et al. Coco-text: dataset and benchmark for text detection and recognition in natural images [C]// Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016. arXiv: 1601.07140.
[本文引用: 1]
[26]
KARATZAS D, SHAFAIT F, UCHIDA S, et al. Robust reading competition [C]// 12th International Conference on Document Analysis and Recognition . Washington: IEEE, 2013: 1484-1493.
[本文引用: 1]
[27]
KARATZAS D, GOMEZ-BIGORDA L, NICOLAOU A, et al. Competition on robust reading [C]// 13th International Conference on Document Analysis and Recognition . Nancy: IEEE, 2015: 1156-1160.
[本文引用: 1]
[28]
WOLF C, JOLION J M Object count/area graphs for the evaluation of object detection and segmentation algorithms
[J]. International Journal of Document Analysis and Recognition , 2006 , 8 (4 ): 280 - 296
DOI:10.1007/s10032-006-0014-0
[本文引用: 1]
[29]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 21-37.
[本文引用: 1]
[30]
LIAO M, ZHU Z, SHI B, et al. Rotation-sensitive regression for oriented scene text detection [C]// Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 5909-5918.
[本文引用: 3]
1
... 自然场景图像文字提取技术被广泛应用于图像内容检索、盲人导航、外语翻译等领域[1 ] . 文字提取过程包括文字检测和文字识别,在自然场景图像中通过文字检测定位出文字区域位置,通过文字识别技术将获得的文字区域转换成可输出的自然语言. 文字检测是文字识别的重要前提,可以有效提高识别效率和准确率. 文字颜色、大小、字体、排布方向的多样性[2 ] 和自然场景图像背景的复杂性,加上天气、光照强度等客观因素或者拍摄抖动等人为因素,导致自然场景图像中的文字检测难度较大. ...
1
... 自然场景图像文字提取技术被广泛应用于图像内容检索、盲人导航、外语翻译等领域[1 ] . 文字提取过程包括文字检测和文字识别,在自然场景图像中通过文字检测定位出文字区域位置,通过文字识别技术将获得的文字区域转换成可输出的自然语言. 文字检测是文字识别的重要前提,可以有效提高识别效率和准确率. 文字颜色、大小、字体、排布方向的多样性[2 ] 和自然场景图像背景的复杂性,加上天气、光照强度等客观因素或者拍摄抖动等人为因素,导致自然场景图像中的文字检测难度较大. ...
自然场景图像中的文字检测综述
1
2016
... 自然场景图像文字提取技术被广泛应用于图像内容检索、盲人导航、外语翻译等领域[1 ] . 文字提取过程包括文字检测和文字识别,在自然场景图像中通过文字检测定位出文字区域位置,通过文字识别技术将获得的文字区域转换成可输出的自然语言. 文字检测是文字识别的重要前提,可以有效提高识别效率和准确率. 文字颜色、大小、字体、排布方向的多样性[2 ] 和自然场景图像背景的复杂性,加上天气、光照强度等客观因素或者拍摄抖动等人为因素,导致自然场景图像中的文字检测难度较大. ...
自然场景图像中的文字检测综述
1
2016
... 自然场景图像文字提取技术被广泛应用于图像内容检索、盲人导航、外语翻译等领域[1 ] . 文字提取过程包括文字检测和文字识别,在自然场景图像中通过文字检测定位出文字区域位置,通过文字识别技术将获得的文字区域转换成可输出的自然语言. 文字检测是文字识别的重要前提,可以有效提高识别效率和准确率. 文字颜色、大小、字体、排布方向的多样性[2 ] 和自然场景图像背景的复杂性,加上天气、光照强度等客观因素或者拍摄抖动等人为因素,导致自然场景图像中的文字检测难度较大. ...
1
... 传统的自然场景图像文字检测方法如最稳定极值区域算法[3 ] (maximally stable extremal regions,MSER)、笔画宽度算法[4 ] (stroke width transform,SWT)等处理流程复杂,对复杂背景图像的鲁棒性较差. 近年来,基于深度学习的方法取得了突破性进展,主要思路是将自然场景文字检测视为特殊的目标检测,检测过程包括特征提取和候选区域定位. 特征提取是目标检测与文字检测中必要且通用的部分;由于背景中可能存在大量形似文字的物体且文字呈现形式多样,文字候选区域定位比一般目标区域定位更加复杂. ...
1
... 传统的自然场景图像文字检测方法如最稳定极值区域算法[3 ] (maximally stable extremal regions,MSER)、笔画宽度算法[4 ] (stroke width transform,SWT)等处理流程复杂,对复杂背景图像的鲁棒性较差. 近年来,基于深度学习的方法取得了突破性进展,主要思路是将自然场景文字检测视为特殊的目标检测,检测过程包括特征提取和候选区域定位. 特征提取是目标检测与文字检测中必要且通用的部分;由于背景中可能存在大量形似文字的物体且文字呈现形式多样,文字候选区域定位比一般目标区域定位更加复杂. ...
1
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
卷积神经网络研究综述
1
2017
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
卷积神经网络研究综述
1
2017
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
3
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2013
Tab.2 方法 R P F RTD[8 ] 0.66 0.88 0.76 RTLF[9 ] 0.72 0.82 0.77 FASText[10 ] 0.69 0.84 0.77 CTPN[7 ] 0.83 0.93 0.88 RRD[30 ] 0.86 0.92 0.89 RRPN[11 ] 0.88 0.95 0.91 RefineScale-RPN 0.88 0.90 0.89
表 3 不同文字检测方法在ICDAR2015上的常用评价指标对比 ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2015
Tab.3 方法 R P F CTPN[7 ] 0.52 0.74 0.61 RTLF[9 ] 0.82 0.72 0.77 RRPN[11 ] 0.77 0.84 0.80 EAST[12 ] 0.78 0.83 0.81 RRD[30 ] 0.80 0.88 0.84 RefineScale-RPN 0.85 0.81 0.83
从ICDAR2013数据集的实验结果来看,本研究所提方法的召回率为0.88,准确率为0.90,相比于同类先进方法,召回率有明显提升,同时准确率也保持在较高水平;从ICDAR2015数据集的实验结果来看,本研究所提方法的召回率为0.85,准确率为0.81,召回率优于同类先进方法. 召回率明显提升的原因有以下2点:1)在精细化特征融合分层预测模型的基础上实施区分尺度的策略,提高了模型对多种尺度文字的召回率;2)增加难分类样本和难回归样本的学习,使得模型对关键难样本的特征学习更加充分,保证了模型学习的准确率. ...
Robust text detection in natural scene images
1
2014
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2013
Tab.2 方法 R P F RTD[8 ] 0.66 0.88 0.76 RTLF[9 ] 0.72 0.82 0.77 FASText[10 ] 0.69 0.84 0.77 CTPN[7 ] 0.83 0.93 0.88 RRD[30 ] 0.86 0.92 0.89 RRPN[11 ] 0.88 0.95 0.91 RefineScale-RPN 0.88 0.90 0.89
表 3 不同文字检测方法在ICDAR2015上的常用评价指标对比 ...
Real-time lexicon-free scene text localization and recognition
2
2016
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2013
Tab.2 方法 R P F RTD[8 ] 0.66 0.88 0.76 RTLF[9 ] 0.72 0.82 0.77 FASText[10 ] 0.69 0.84 0.77 CTPN[7 ] 0.83 0.93 0.88 RRD[30 ] 0.86 0.92 0.89 RRPN[11 ] 0.88 0.95 0.91 RefineScale-RPN 0.88 0.90 0.89
表 3 不同文字检测方法在ICDAR2015上的常用评价指标对比 ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2015
Tab.3 方法 R P F CTPN[7 ] 0.52 0.74 0.61 RTLF[9 ] 0.82 0.72 0.77 RRPN[11 ] 0.77 0.84 0.80 EAST[12 ] 0.78 0.83 0.81 RRD[30 ] 0.80 0.88 0.84 RefineScale-RPN 0.85 0.81 0.83
从ICDAR2013数据集的实验结果来看,本研究所提方法的召回率为0.88,准确率为0.90,相比于同类先进方法,召回率有明显提升,同时准确率也保持在较高水平;从ICDAR2015数据集的实验结果来看,本研究所提方法的召回率为0.85,准确率为0.81,召回率优于同类先进方法. 召回率明显提升的原因有以下2点:1)在精细化特征融合分层预测模型的基础上实施区分尺度的策略,提高了模型对多种尺度文字的召回率;2)增加难分类样本和难回归样本的学习,使得模型对关键难样本的特征学习更加充分,保证了模型学习的准确率. ...
1
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2013
Tab.2 方法 R P F RTD[8 ] 0.66 0.88 0.76 RTLF[9 ] 0.72 0.82 0.77 FASText[10 ] 0.69 0.84 0.77 CTPN[7 ] 0.83 0.93 0.88 RRD[30 ] 0.86 0.92 0.89 RRPN[11 ] 0.88 0.95 0.91 RefineScale-RPN 0.88 0.90 0.89
表 3 不同文字检测方法在ICDAR2015上的常用评价指标对比 ...
3
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2013
Tab.2 方法 R P F RTD[8 ] 0.66 0.88 0.76 RTLF[9 ] 0.72 0.82 0.77 FASText[10 ] 0.69 0.84 0.77 CTPN[7 ] 0.83 0.93 0.88 RRD[30 ] 0.86 0.92 0.89 RRPN[11 ] 0.88 0.95 0.91 RefineScale-RPN 0.88 0.90 0.89
表 3 不同文字检测方法在ICDAR2015上的常用评价指标对比 ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2015
Tab.3 方法 R P F CTPN[7 ] 0.52 0.74 0.61 RTLF[9 ] 0.82 0.72 0.77 RRPN[11 ] 0.77 0.84 0.80 EAST[12 ] 0.78 0.83 0.81 RRD[30 ] 0.80 0.88 0.84 RefineScale-RPN 0.85 0.81 0.83
从ICDAR2013数据集的实验结果来看,本研究所提方法的召回率为0.88,准确率为0.90,相比于同类先进方法,召回率有明显提升,同时准确率也保持在较高水平;从ICDAR2015数据集的实验结果来看,本研究所提方法的召回率为0.85,准确率为0.81,召回率优于同类先进方法. 召回率明显提升的原因有以下2点:1)在精细化特征融合分层预测模型的基础上实施区分尺度的策略,提高了模型对多种尺度文字的召回率;2)增加难分类样本和难回归样本的学习,使得模型对关键难样本的特征学习更加充分,保证了模型学习的准确率. ...
2
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2015
Tab.3 方法 R P F CTPN[7 ] 0.52 0.74 0.61 RTLF[9 ] 0.82 0.72 0.77 RRPN[11 ] 0.77 0.84 0.80 EAST[12 ] 0.78 0.83 0.81 RRD[30 ] 0.80 0.88 0.84 RefineScale-RPN 0.85 0.81 0.83
从ICDAR2013数据集的实验结果来看,本研究所提方法的召回率为0.88,准确率为0.90,相比于同类先进方法,召回率有明显提升,同时准确率也保持在较高水平;从ICDAR2015数据集的实验结果来看,本研究所提方法的召回率为0.85,准确率为0.81,召回率优于同类先进方法. 召回率明显提升的原因有以下2点:1)在精细化特征融合分层预测模型的基础上实施区分尺度的策略,提高了模型对多种尺度文字的召回率;2)增加难分类样本和难回归样本的学习,使得模型对关键难样本的特征学习更加充分,保证了模型学习的准确率. ...
1
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
1
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
A two-stage scheme for text detection in video images
1
2010
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
Focal loss for dense object detection
1
2017
... 基于深度学习的文字检测方法通常采用自底向上(down-top)的卷积神经网络[5 -6 ] (convolutional neural network,CNN)进行特征提取,CNN通过逐层卷积和池化操作实现降维和局部特征的提取. Tian等[7 -11 ] 均采用down-top结构进行特征提取,并选取最顶层的特征图进行文字候选区域定位. 然而,随着卷积和池化的逐层传播,特征图的分辨率逐层下降,逐渐丢失底层边角等细节信息,导致这些采用单层特征图进行文字候选区域定位的检测方法的精度难以提高. Zhou等[12 -15 ] 针对down-top结构进行改进,采用在down-top基础上增加自顶向下(top-down)反向融合特征图的方式,构建具有更高分辨率的特征图,有效提高文字检测的精度. 然而,在自然场景图像中文字尺度变化范围较大,这些方法使用单一的特征融合层对文字进行不区分尺度的检测,没有充分利用中间层特征,不能较好地解决文字的多尺度问题. Shrivastava等[16 ] 针对两阶段目标检测[17 ] 随机选取正负样本导致样本学习不充分的问题,提出在线难样本挖掘算法(online hard example mining,OHEM)以实现自适应样本学习. Lin等[18 ] 针对单阶段目标检测中正负样本不均衡和难样本问题,提出聚焦损失的思想,增大正样本和难分类样本在损失函数中的权重,取得了较好的实验效果. 不过,目前对难样本的研究主要局限于目标检测领域,大部分文字检测方法没有考虑难样本问题. ...
1
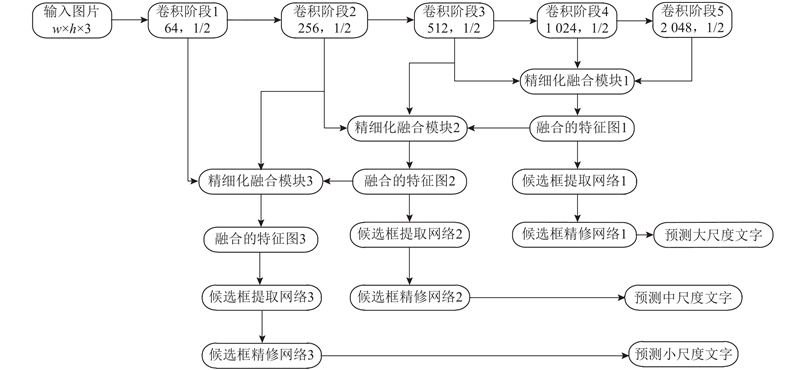
... 针对上述卷积特征层信息利用不充分以及不区分尺度和难易样本学习所导致的文字检测精度不高的问题,提出优化的自然场景图像文字检测方法,旨在实现更符合实际的多尺度多方向的文字检测,提高文字检测精度. 主要研究内容如下. 1)提出基于多路精细化特征融合的模型. 基本模型为特征金字塔网络[19 ] (feature pyramid networks,FPN),down-top基础特征提取采用残差网络(residual network,ResNet)[20 ] ,top-down抽取3种尺度的特征图作为特征融合模块的输入,横向连接引入精细化融合网络(refined fusion network,RefineNet)[21 ] ,充分利用各中间层特征,最终得到3种尺度的高分辨率特征图. 2)提出区分文字尺度的检测策略. 根据不同文字对特征图的尺度敏感度不同,将文字标注框按照其较长边划分为3种尺度范围,将不同尺度范围的标注框分散到3个候选框提取网络(region proposal network,RPN)中进行训练,提高多尺度文字的检测精度. 3)设计聚焦难样本的损失函数. 将难样本问题扩展为难分类和难回归2个问题,分别设计聚焦难分类和难回归样本的损失函数,重点学习难样本特征以提高模型的表达能力,进一步提高文字检测的精度. ...
1
... 针对上述卷积特征层信息利用不充分以及不区分尺度和难易样本学习所导致的文字检测精度不高的问题,提出优化的自然场景图像文字检测方法,旨在实现更符合实际的多尺度多方向的文字检测,提高文字检测精度. 主要研究内容如下. 1)提出基于多路精细化特征融合的模型. 基本模型为特征金字塔网络[19 ] (feature pyramid networks,FPN),down-top基础特征提取采用残差网络(residual network,ResNet)[20 ] ,top-down抽取3种尺度的特征图作为特征融合模块的输入,横向连接引入精细化融合网络(refined fusion network,RefineNet)[21 ] ,充分利用各中间层特征,最终得到3种尺度的高分辨率特征图. 2)提出区分文字尺度的检测策略. 根据不同文字对特征图的尺度敏感度不同,将文字标注框按照其较长边划分为3种尺度范围,将不同尺度范围的标注框分散到3个候选框提取网络(region proposal network,RPN)中进行训练,提高多尺度文字的检测精度. 3)设计聚焦难样本的损失函数. 将难样本问题扩展为难分类和难回归2个问题,分别设计聚焦难分类和难回归样本的损失函数,重点学习难样本特征以提高模型的表达能力,进一步提高文字检测的精度. ...
2
... 针对上述卷积特征层信息利用不充分以及不区分尺度和难易样本学习所导致的文字检测精度不高的问题,提出优化的自然场景图像文字检测方法,旨在实现更符合实际的多尺度多方向的文字检测,提高文字检测精度. 主要研究内容如下. 1)提出基于多路精细化特征融合的模型. 基本模型为特征金字塔网络[19 ] (feature pyramid networks,FPN),down-top基础特征提取采用残差网络(residual network,ResNet)[20 ] ,top-down抽取3种尺度的特征图作为特征融合模块的输入,横向连接引入精细化融合网络(refined fusion network,RefineNet)[21 ] ,充分利用各中间层特征,最终得到3种尺度的高分辨率特征图. 2)提出区分文字尺度的检测策略. 根据不同文字对特征图的尺度敏感度不同,将文字标注框按照其较长边划分为3种尺度范围,将不同尺度范围的标注框分散到3个候选框提取网络(region proposal network,RPN)中进行训练,提高多尺度文字的检测精度. 3)设计聚焦难样本的损失函数. 将难样本问题扩展为难分类和难回归2个问题,分别设计聚焦难分类和难回归样本的损失函数,重点学习难样本特征以提高模型的表达能力,进一步提高文字检测的精度. ...
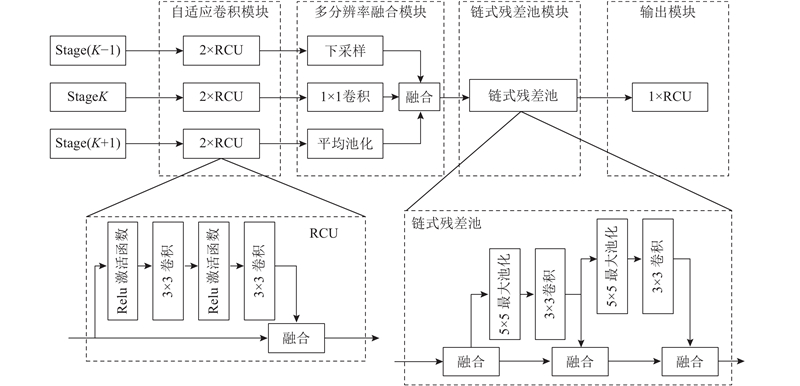
... 在CNN中间特征层中,低层往往携带着对文字检测较有利的边角信息,高层经过多次卷积池化因而语义信息丰富. Lin等[21 ] 在图像分割任务中提出精细化的特征融合网络RefineNet,构建高分辨率的特征图能有效提高图像分割的精度. 为了充分利用低特征层的细节信息和高特征层的语义信息,本研究引入RefineNet精细化特征融合模块,如图1 所示. 自适应卷积模块由成对的残差卷积单元(residual convolution unit,RCU)组成,主要作用是对ResNet中间特征层的权重进行微调;多分辨率融合模块对不同阶段的特征图进行尺度和数量处理以保证不同分辨率的特征融合,即对尺度较大的特征图做1×1卷积以保证特征图数量一致,对尺度较小的特征图进行上采样从而得到相同的尺度,然后采用两路求和的方式进行特征融合;链式残差池(chained residual pooling)模块是由多个池块连接成的链,每个池块都由1个最大池化层和1个卷积层组成,后一个池块将前一个池块的输出作为输入,因此可以重新利用来自先前池化操作的结果;输出模块包含1个RCU,通过该模块保持特征维度不变. ...
1
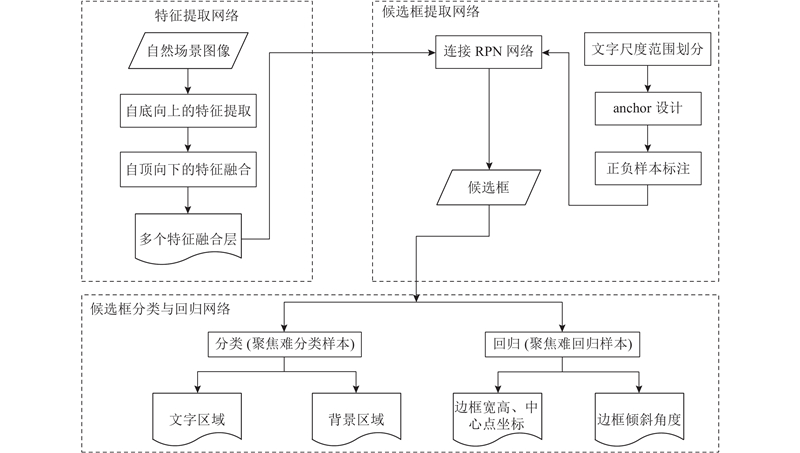
... 候选框提取网络RPN[22 ] 在CNN网络中采用共享卷积层和anchor① 机制快速生成候选框,解决了传统的方法如选择性搜索[23 ] (selective search,SS)和EdgeBoxes[24 ] 等在目标检测中单独进行候选框提取较耗时的问题. RPN通过在特征融合层进行3×3的窗口滑动和兴趣区域池化得到等长的特征,将特征输入全连接层,全连接层经过奇异值分解,得到分类层和回归层. 分类层采用softmax进行候选框的文本/非文本分类,回归层只对被判定为文字候选框的中心点坐标(x ,y )、宽度w 、高度h 、倾斜角度θ 5个几何参数的偏移量做回归. ...
Selective search for object recognition
1
2013
... 候选框提取网络RPN[22 ] 在CNN网络中采用共享卷积层和anchor① 机制快速生成候选框,解决了传统的方法如选择性搜索[23 ] (selective search,SS)和EdgeBoxes[24 ] 等在目标检测中单独进行候选框提取较耗时的问题. RPN通过在特征融合层进行3×3的窗口滑动和兴趣区域池化得到等长的特征,将特征输入全连接层,全连接层经过奇异值分解,得到分类层和回归层. 分类层采用softmax进行候选框的文本/非文本分类,回归层只对被判定为文字候选框的中心点坐标(x ,y )、宽度w 、高度h 、倾斜角度θ 5个几何参数的偏移量做回归. ...
1
... 候选框提取网络RPN[22 ] 在CNN网络中采用共享卷积层和anchor① 机制快速生成候选框,解决了传统的方法如选择性搜索[23 ] (selective search,SS)和EdgeBoxes[24 ] 等在目标检测中单独进行候选框提取较耗时的问题. RPN通过在特征融合层进行3×3的窗口滑动和兴趣区域池化得到等长的特征,将特征输入全连接层,全连接层经过奇异值分解,得到分类层和回归层. 分类层采用softmax进行候选框的文本/非文本分类,回归层只对被判定为文字候选框的中心点坐标(x ,y )、宽度w 、高度h 、倾斜角度θ 5个几何参数的偏移量做回归. ...
1
... COCO-Text[25 ] 为目前最大的文字检测和文字识别数据集,包含63 686张图片、145 859个文本实例,其中43 686张图片、118 309个文本实例用于训练,10 000张图片、27 550个文本实例用于验证,10 000张图片、27 730个文本实例用于测试. ICDAR2013[26 ] 在2013年国际鲁棒性阅读比赛挑战任务2中发布,包含462张图片,其中229张构成训练集,233张构成测试集,该数据集支持水平方向文字的检测. ICDAR2015[27 ] 在2015年国际鲁棒性阅读比赛挑战任务5中发布,包含1 500张图片,其中1 000张构成训练集,其余的500张用于测试,该数据集支持多方向文字的检测. ...
1
... COCO-Text[25 ] 为目前最大的文字检测和文字识别数据集,包含63 686张图片、145 859个文本实例,其中43 686张图片、118 309个文本实例用于训练,10 000张图片、27 550个文本实例用于验证,10 000张图片、27 730个文本实例用于测试. ICDAR2013[26 ] 在2013年国际鲁棒性阅读比赛挑战任务2中发布,包含462张图片,其中229张构成训练集,233张构成测试集,该数据集支持水平方向文字的检测. ICDAR2015[27 ] 在2015年国际鲁棒性阅读比赛挑战任务5中发布,包含1 500张图片,其中1 000张构成训练集,其余的500张用于测试,该数据集支持多方向文字的检测. ...
1
... COCO-Text[25 ] 为目前最大的文字检测和文字识别数据集,包含63 686张图片、145 859个文本实例,其中43 686张图片、118 309个文本实例用于训练,10 000张图片、27 550个文本实例用于验证,10 000张图片、27 730个文本实例用于测试. ICDAR2013[26 ] 在2013年国际鲁棒性阅读比赛挑战任务2中发布,包含462张图片,其中229张构成训练集,233张构成测试集,该数据集支持水平方向文字的检测. ICDAR2015[27 ] 在2015年国际鲁棒性阅读比赛挑战任务5中发布,包含1 500张图片,其中1 000张构成训练集,其余的500张用于测试,该数据集支持多方向文字的检测. ...
Object count/area graphs for the evaluation of object detection and segmentation algorithms
1
2006
... 评价检测方法性能的指标主要有准确率P 、召回率R 、综合值F . 计算P 、R 须统计真实正样本的数目,考虑到候选框与标注框之间可能存在一对多、多对一、一对一的关系,且每个候选框的得分为[0,1.0],而非0或1,采用Wolf标准[28 ] 计算P 、R 、F ,表达式分别为 ...
1
... 算法由Python语言实现,特征提取网络的初始权重使用预训练的ImageNet分类模型ResNet50的参数. 所选择的对比方法有基于特征金字塔网络的候选框提取方法FPN-RPN、基于单步多尺度包围盒检测器[29 ] (single shot multibox detector,SSD)的候选框提取方法SSD-RPN、基于更快速的候选区域提取与卷积神经网络的候选框提取方法FasterRCNN-RPN、基于深度轻量实时网络(performance vs accuracy network,PVANet)的候选框提取方法PVANet-RPN. 以上方法及本研究的方法中新增层的权重使用均值为0,方差为0.01的高斯分布进行随机初始化. 误差反向传播采用随机梯度下降算法(stochastic gradient descent,SGD),动量为 0.9,权值衰减率为0.000 5,最小批尺寸为4,训练历时为82 h. 训练迭代次数和学习率根据不同数据集的大小进行调整. COCO-Text 数据集最大,设置初始学习率为0.001,最大迭代次数为25万,学习率在第10、20万次迭代时分别除以10. ICDAR2013、ICDAR2015数据集均较小,设置最大迭代次数为4万,初始学习率为0.000 5,学习率在第2万次迭代时除以5. ...
3
... 2)与同类方法在标准数据集上的对比. 为了证明本研究所提方法的有效性和鲁棒性,分别在标准的水平多尺度文字数据集ICDAR2013和多方向多尺度文字数据集ICDAR2015上做进一步实验,并与同类优秀的两阶段文字检测方法进行对比,结果如表2 、3 所示. 可以看出,本研究所提方法在2个数据集上的召回率不逊色于目前最好的两阶段检测方法RRPN、RRD[30 ] . 本研究所提方法在2个数据集上的F 分别为0.89、0.83,较当前同类优秀方法有明显的提升,且在不同的数据集上均能达到较高的F ,证明本研究所提方法在多方向、多尺度的自然场景图像上的鲁棒性. ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2013
Tab.2 方法 R P F RTD[8 ] 0.66 0.88 0.76 RTLF[9 ] 0.72 0.82 0.77 FASText[10 ] 0.69 0.84 0.77 CTPN[7 ] 0.83 0.93 0.88 RRD[30 ] 0.86 0.92 0.89 RRPN[11 ] 0.88 0.95 0.91 RefineScale-RPN 0.88 0.90 0.89
表 3 不同文字检测方法在ICDAR2015上的常用评价指标对比 ...
... Comparison of common evaluation indexes for different text detection methods on dataset ICDAR2015
Tab.3 方法 R P F CTPN[7 ] 0.52 0.74 0.61 RTLF[9 ] 0.82 0.72 0.77 RRPN[11 ] 0.77 0.84 0.80 EAST[12 ] 0.78 0.83 0.81 RRD[30 ] 0.80 0.88 0.84 RefineScale-RPN 0.85 0.81 0.83
从ICDAR2013数据集的实验结果来看,本研究所提方法的召回率为0.88,准确率为0.90,相比于同类先进方法,召回率有明显提升,同时准确率也保持在较高水平;从ICDAR2015数据集的实验结果来看,本研究所提方法的召回率为0.85,准确率为0.81,召回率优于同类先进方法. 召回率明显提升的原因有以下2点:1)在精细化特征融合分层预测模型的基础上实施区分尺度的策略,提高了模型对多种尺度文字的召回率;2)增加难分类样本和难回归样本的学习,使得模型对关键难样本的特征学习更加充分,保证了模型学习的准确率. ...



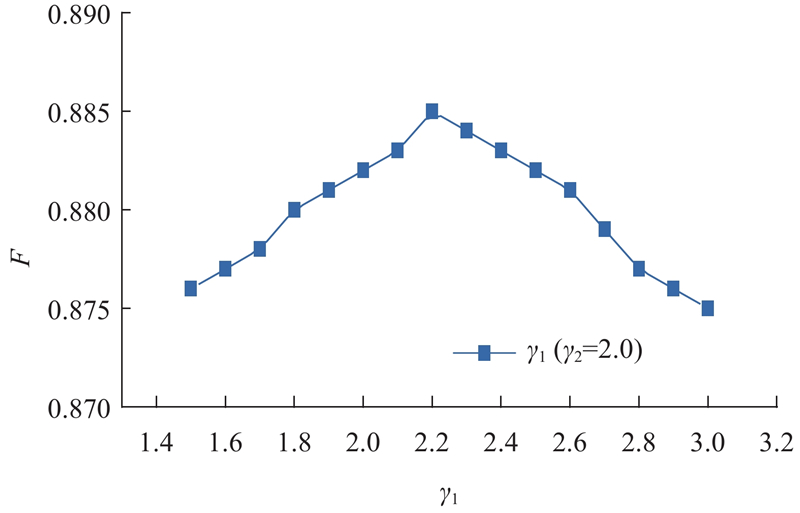


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}