

作为人脸图像分析过程中的一个重要基础环节,精准的人脸特征点定位对众多人脸的相关研究和应用课题具有关键作用. 如何获取精准的人脸特征点定位一直都是图像处理、计算机视觉、模式识别以及人机交互等领域的研究热点问题[1].
姿态变化一直是人脸特征点定位所面临的经典难题. 在实际应用中,尤其是实时采集人脸图像同时受到姿态、光照、表情、遮挡等因素的共同作用,人脸特征点的定位精度很难令人满意,现有方法的精度距离实际应用的要求还有很大距离,需要进一步的研究和提升.
传统的多模型训练方法特征点定位的精度依赖于对测试人脸图像姿态估计的准确度. 由于三维人脸模型重建时间及模型精度问题,基于三维人脸模型重建的方法尚不足以应对实际应用中复杂多变的姿态多样性. 基于回归的方法是指直接学习从人脸表观到人脸形状模型的参数的映射函数,进而建立从表观到形状的对应关系. 此类方法由于不需要复杂的人脸形状和表观建模,简单高效.
1. 级联形状回归算法描述
特征点是人脸形状的主要描述形式,因此人脸特征点称为人脸形状. 首先对原始级联形状回归算法进行介绍.
级联形状回归是由一组级联的形状回归器
图 1

输入:2D人脸图像I,初始形状S0,形状回归器
For t = 1 to T
End
输出:最终的预测形状ST
2. 改进级联形状回归的多视角人脸特征点定位方法
原始级联形状回归器在较小姿态偏转人脸图像上取得了较好的定位效果,但是不具有对较大姿态变化的人脸特征点定位能力. 提出基于改进级联形状回归的多视角人脸特征点定位方法,通过引入特征点的可见/不可见属性,把任意姿态下的人脸特征点定位问题转化为可见特征点定位问题,从而实现在同一模型下任意姿态二维人脸图像特征点的自动定位,算法框架如图2所示.
图 2
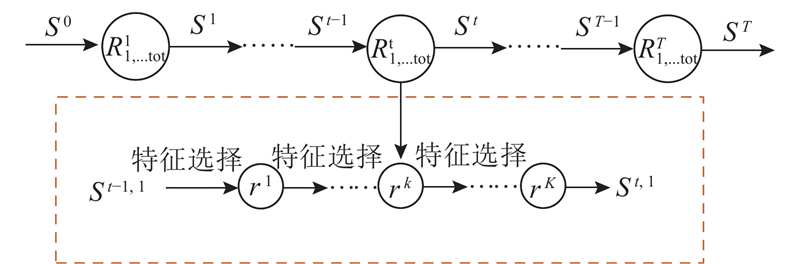
图 2 基于改进级联形状回归的多视角人脸图像特征点定位算法框架
Fig.2 Flow chart of proposed multi-view facial landmark location method based on improved cascade shape regression
为了提高算法对复杂姿态角度的应对能力,针对不同遮挡人脸区域分别训练级联形状回归器,具体采用两级级联形状回归(为了便于表述,假定外层级联回归为第一级级联回归,内层级联回归为第二级级联回归);第一级级联形状回归中的每个回归器
2.1. 对姿态、遮挡变化的鲁棒性
假设人脸形状由P个特征点组成,传统的级联形状回归方法中定义形状
通过为不同姿态人脸形状建立不同的点分布模型,可以提高模型应对姿态差异的能力. 提出根据较大姿态偏转下的自遮挡情况,将自动检测到的人脸区域按照特征点位置分为7部分(以本文标注21个特征点为例,区域①包含特征点1、2、3、4;区域②包含特征点5、10;区域③包含特征点6、7、8、9;区域④包含特征点12、16,区域⑤包含特征点11、13、15、17、18、19;区域⑥包含特征点14、20;区域⑦包含特征点21). 如图3(a)所示,区域1、3、4、6为易遮挡部分(水平方向姿态偏转大于±60°,垂直方向姿态大于±30°),区域2、5、7为不易遮挡部分(即使水平方向偏转达到±90°). 针对每一部分(所包含特征点)分别训练“视觉效果”不同的回归器,达到算法对不同程度遮挡下的人脸图像具有较强的适应性. 如图3(b)所示为定义特征点位置及相应顺序,当姿态偏转较大时,特征点由可见转为不可见,特征点的顺序保持不变.
图 3

图 3 人脸区域划分及特征点位置、顺序图
Fig.3 Face region division and position and sequence of landmark
2.2. 有效特征的提取
研究对任意姿态人脸图像鲁棒的人脸特征点定位方法. 原始级联回归算法使用的形状索引特征定义为特征点与最近邻特征点像素灰度之间的差值,主要处理正面姿态人脸特征点定位已经不能满足任意姿态伴随各种表情、光照、遮挡变化的人脸特征点定位. 对形状索引特征进行改进,称为改进的形状索引特征. 改进形状索引特征主要基于以下考虑.
任意姿态伴有表情、光照、遮挡等变化的人脸图像由于自遮挡问题,可能导致人脸大范围区域处于遮挡状态. 原始形状索引特征计算与最近邻特征点像素之间的差值可能会出现以下2种情况:1)最近邻特征点处于自遮挡区域,这些特征点的位置不可见,由此计算的形状索引特征不可靠;2)原始形状索引特征需要查找最近邻特征点位置,这不利于算法整体效率的提高.
为了提高形状索引特征对姿态、表情、光照、遮挡等变化二维人脸图像的鲁棒性,同时保持对位置的分辨能力,对原始形状索引特征进行以下改进:1)由计算两最近邻特征点之间的像素差值改进为计算任意两特征点位置像素之间的差值,避免了最近邻特征点的查找,提高了算法的整体效率;2)计算任意两特征点以及两特征点之间某随机位置之间的像素差值,与原始形状索引特征相比,该方式既丰富了原始特征信息,也使得改进后的形状索引特征对姿态、表情、光照、遮挡等变化更加鲁棒.
改进后的形状索引特征充分考虑了人脸形状随姿态、表情、光照、遮挡变化受到的影响. 核心思想是当人脸特征点由于姿态、表情、光照、遮挡变化导致人脸特征点不可见时,特征点本身没有像素值,并且其周围可以描述该特征点位置的信息相对较少. 基于以上考虑,改进之后的形状索引特征不仅包括任意两特征点位置的像素差值,还包括任意特征点与其他特征点之间某随机位置的像素差. 相对于原始形状索引特征[7],改进之后的形状索引特征一方面不需要查找最近邻特征点,提高了特征计算效率;另一方面,改进之后的形状索引特征包含了更丰富的特征信息,对姿态、表情、光照、遮挡等变化更加鲁棒.
2.3. 级联形状回归器训练
假设有T个随机蕨回归器进行级联,在每
3. 实验结果及分析
为了验证该方法对姿态、遮挡及非约束条件下特征点定位的鲁棒性,分别使用不同的数据集对该方法进行评估实验.
3.1. 数据库与参数设置
数据库:共选用4个比较流行的公开数据库,分别为Multi-PIE、AFLW、COFW和300-W数据库.
Multi-PIE人脸库[12]共采集了337人在19种不同光照条件、6种不同的表情和15种不同姿态(其中水平方向姿态偏转从-90°到+90°)下的750 000幅人脸图像. 本文选取对象编号为41~60的所有人脸图像用于训练,选取对象编号为61~70的10个人所有不同姿态人脸图像用于测试. 参数设置如下:
COFW数据库[8]包含LFPW人脸数据库训练集中的845幅人脸图像以及其他1 000幅存在不同程度遮挡的人脸图像,部分还伴有表情、光照等变化,每个人脸标记29个特征点. 本文选用数据库已配置好的1 345张人脸图像用于训练,其余507幅严重遮挡(同时包含姿态和表情的变化)的人脸图像用于测试. 参数设置如下:
300-W数据库[14]包含LFPW、HELEN、AFW、XM2VTS数据库以及iBUG数据库中135张极具姿态和表情挑战性的人脸图像并重新进行68点标定组成,数据库样本涵盖了不同程度遮挡、姿态、表情、光照、背景以及图像质量条件等情况,是目前最常用也最具挑战的人脸特征点检测数据库之一. 选择AFW、LFPW、HELEN数据库的3 148张人脸图像用作训练,余下689张人脸图像作为测试集. 参数设置如下:
评价指标如下. 为了量化分析提出的算法,定义人脸特征点定位平均误差:
式中:
3.2. Multi-PIE数据库上实验结果
为了评估该方法对大姿态偏转人脸特征点的定位效果,选择在包含较大姿态偏转的Multi-PIE人脸数据库上对该方法进行验证评估.
由于当前没有可用的报告大姿态偏转条件下人脸面部特征点的定位方法,选用原始级联形状回归方法(CPR)[8]作为基准方法.
表 1 提出方法(GCPR)与对比方法在Multi-PIE数据库上可见特征点的平均定位误差
Tab.1
| 方法 | e |
| CPR[8] | 6.89 |
| GCPR | 4.14 |
图 4
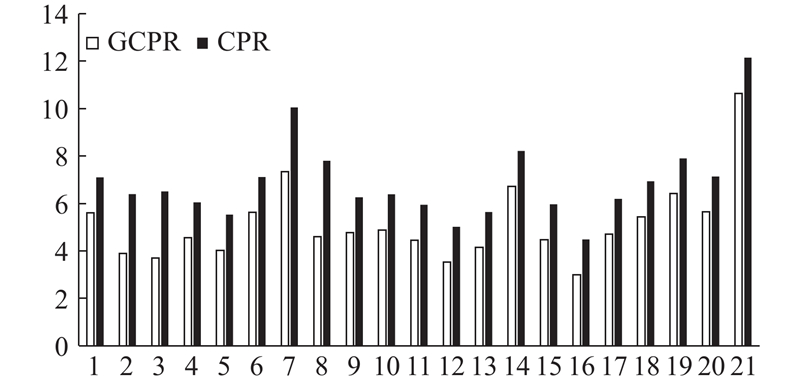
图 4 本文方法与基准方法在Multi-PIE数据库测试集上不同姿态下人脸特征点定位误差
Fig.4 Location errors of proposed and baseline methods under different posed on Multi-PIE database
图 5

图 5 本文算法在测试数据库上的部分实验结果
Fig.5 Some example results by proposed method on three different databases
3.3. AFLW数据库上实验结果
为了进一步验证该方法在复杂非约束条件下的有效性,选用在采集自复杂环境下的AFLW、COFW及300-W数据库对该方法进行测试评估.
表 2 提出方法(GCPR)与对比方法在AFLW数据库上可见特征点与不可见特征点的平均定位误差
Tab.2
图 6

图 6 提出方法与对比方法在AFLW数据库测试集上的各特征点定位误差
Fig.6 Location errors of proposed and baseline methods under different posed on AFLW database
3.4. COFW数据库上实验结果
人脸遮挡分为自遮挡和外遮挡2种,COFW是一个包含大量外物遮挡的人脸数据库,然而不管是自遮挡还是外遮挡都会导致人脸的部分特征点不可见,因此本组实验中所有的自遮挡和外物遮挡统一标注为不可见特征点.
表 3 提出方法(GCPR)与对比方法在COFW数据库上可见特征点与不可见特征点的平均定位误差
Tab.3
3.5. 300-W数据库上实验结果
测试集分为3部分,分别为来自Indoor的普通测试集、来自Outdoor的挑战测试集以及普通集(common subset)和挑战集(challenging subset)的合集(fullset). 其中普通集包括余下LFPW和HELEN数据库的554张人脸图像,挑战集为iBUG数据库的135张人脸图像,合集为普通集和挑战集的合集共689张人脸图像.
表 4 提出方法(GCPR)与对比方法在300-W数据库上特征点的平均定位误差
Tab.4
4. 结 语
针对大姿态偏转下的人脸图像的特征点定位问题,本文提出根据任意姿态下的人脸特征点自遮挡情况,将特征点划分为可见或不可见特征点,把人脸特征点的可见/不可见属性引入到级联形状回归方法的训练过程中. 将任意姿态下的人脸特征点定位问题转化为可见特征点定位问题,从而实现在同一模型下任意姿态人脸图像特征点的自动定位. 在Multi-PIE、AFLW、COFW和300-W 4个公开人脸数据库上的实验结果表明,提出方法不但对姿态、遮挡比较鲁棒,而且对于其他复杂非可控因素综合影响人脸图像的特征点检测取得很好的效果.
参考文献
Facial feature point detection: a comprehensive survey
[J].DOI:10.1016/j.neucom.2017.05.013 [本文引用: 1]
基于cpr和clm的多视角人脸特征点定位方法
[J].
A multi-view facial landmark localization method based on CPR and CLM
[J].
Fast keypoint recognition using random ferns
[J].DOI:10.1109/TPAMI.2009.23 [本文引用: 2]
Face alignment by explicit shape regression
[J].DOI:10.1007/s11263-013-0667-3 [本文引用: 3]
Robust facial landmark detection based on initializing multiple poses
[J].
A two-stage head pose estimation framework and evaluation
[J].DOI:10.1016/j.patcog.2007.07.017 [本文引用: 1]
Random cascaded-regression copse for robust facial landmark detection
[J].
Learning deep representation for face alignment with auxiliary attributes
[J].DOI:10.1109/TPAMI.2015.2469286 [本文引用: 3]
Combining data-driven and model-driven methods for robust facial landmark detection
[J].DOI:10.1109/TIFS.2018.2800901 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}