

在深度学习研究初期,sigmoid与tanh函数被广泛用于卷积分类模型. 两者均为S型饱和函数,在训练过程中很容易出现梯度弥散的问题. Krizhevsky等[4]在2012年ImageNet ILSVRC比赛中首次使用了修正线性单元(rectified linear units,relu)[5]作为激活函数. Relu函数具备良好的稀疏性,收敛速度快,计算简单,有效解决了sigmoid与tanh所造成的梯度弥散问题. 由于relu在负值的梯度恒为零,神经元在训练过程中可能发生“坏死”[6]. 2013年至2015年期间,部分学者提出Leaky Relu[7]、ELU[8]、PRelu[9]等改进函数,缓解了神经元“坏死”的问题. ELU会发生梯度弥散,且导数计算复杂度为指数级;Leaky Relu和PRelu引入了额外的超参数α,需要根据分类场景对超参数α进行不同的调整,增加了模型训练难度.
1. 卷积神经网络中常用激活函数
在传统的神经网络中,每一层的输入都与上层输入成线性关系,从而导致最终的输出结果只能是初始输入的线性表达. 由于线性表达的局限性,初始输入的很多特征无法被保留下来. 需要在神经网络中引入一个非线性的函数,即激活函数,通过对输入图像的数据进行非线性的组合,表达出更多的图像特征,使得网络更加稳定高效. 对现有常用的激活函数进行讨论.
1.1. 早期的激活函数
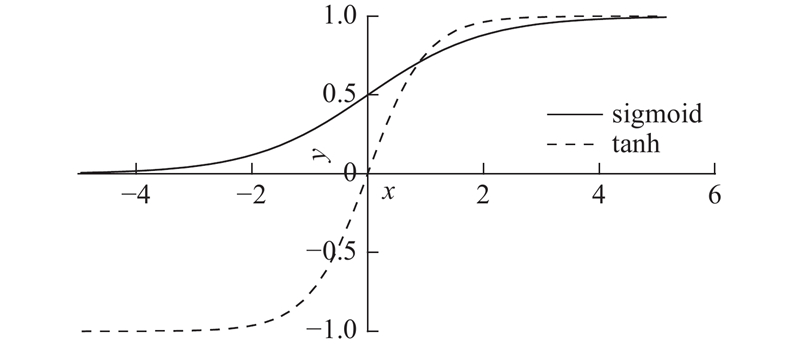
sigmoid函数和tanh函数是研究早期被广泛使用的2种激活函数. 两者都为S型饱和函数,函数曲线如图1所示. 当sigmoid函数输入的值趋于正无穷或负无穷时,梯度会趋近零,从而发生梯度弥散现象. sigmoid函数的输出恒为正值,不是以零为中心的,这会导致权值更新时只能朝一个方向更新,从而影响收敛速度. tanh激活函数是sigmoid函数的改进版,是以零为中心的对称函数,收敛速度快,不容易出现loss值晃动,但是无法解决梯度弥散的问题. 2个函数的计算量都是指数级的,计算相对复杂.
图 1
1.2. softsign激活函数
softsign函数是tanh函数的改进版,为S型饱和函数,以零为中心,值域为(−1,1). softsign函数的数学表达式为
由图2可知,与tanh函数相比,softsign函数的曲线更加平缓而且导数下降的速率更慢,这在一定程度上能够缓解收敛速度慢及梯度消失的问题.
图 2

1.3. relu激活函数
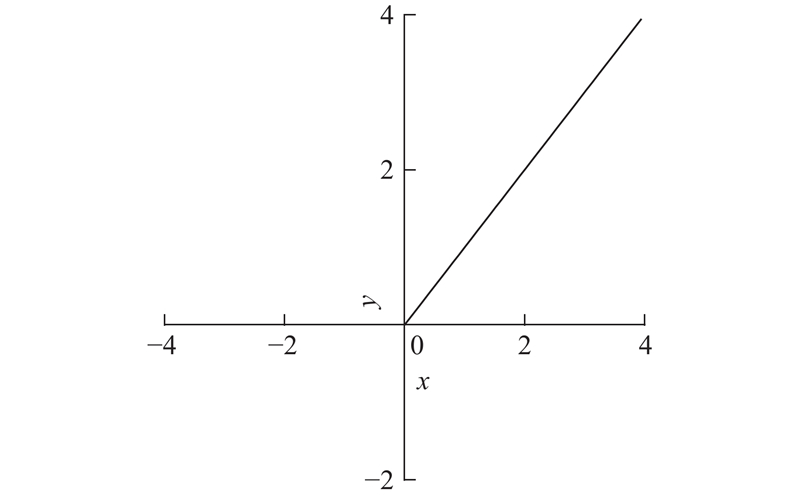
relu(修正线性单元)函数相对前面几种激活函数来说更简洁,公式为
当relu函数的输入为正数时,输出与输入成线性关系,导数恒为1,不会发生梯度弥散,在很大程度上解决了之前sigmoid、tanh等函数所存在的问题;由于是线性计算,与sigmoid函数和tanh函数的指数运算相比,运算速度有了很大的提升. 由于relu输入负值时的导数恒为零,当一个梯度较大的神经元经过relu后,很可能会发生神经元“坏死”的现象,导致该神经元不可用,影响最终的训练结果. 曲线图形如图3所示.
图 3
1.4. relu-softplus组合激活函数
针对relu函数可能造成神经元“坏死”的问题,可以通过用softplus函数替换其负半轴的方式来避免[10]. softplus的函数表达式如下:
虽然softplus函数的计算速度没有relu快,但可以保证负值时的导数不恒为零. 通过将2个激活函数组合,可以有效地结合两者的优点并互相弥补缺陷. softplus函数与sigmoid函数类似,输出恒大于零,这会对其收敛速度造成影响. 为了使softplus函数能够输出负值并与relu函数连接起来,对softplus函数作了减ln 2的操作. 最终的组合激活函数的数学公式为
对应的曲线图形如图4所示.
图 4
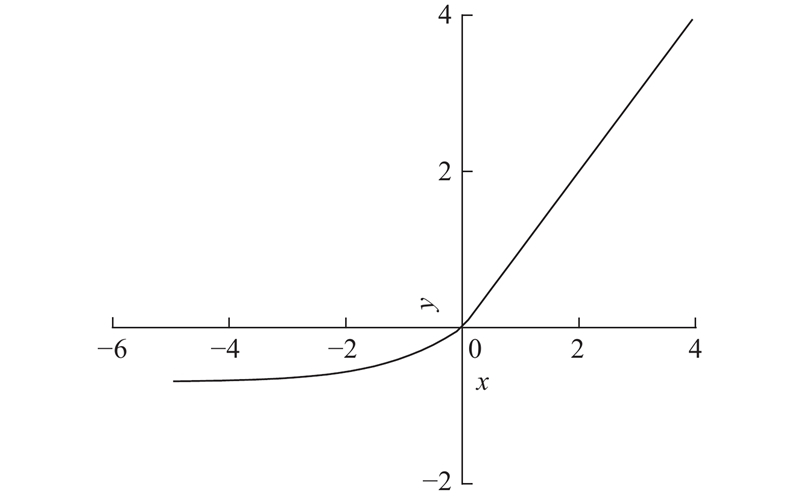
图 4 relu-softplus组合激活函数曲线图
Fig.4 Curve of relu-softplus combinatorial activation function
相对于relu函数,relu-softplus减少了神经元“坏死”的可能,可以获得更高的分类准确度,收敛速度更快. 由于softplus是指数型函数,在零点附近的导数变化极快,很容易下降到趋近零并再无变化,造成模型训练不收敛. 本文在使用relu-softplus激活函数进行实验的过程中,发现relu-softplus对学习率的要求很高. 当模型选用大于0.001的学习率进行训练时,会发生分类准确率度骤降的情况,训练集和测试集的分类准确率都降到1%左右并再无变化. 将学习率设为0.000 1,则模型能够成功收敛,但由于学习率过低,模型的收敛速度很慢.
在讨论现有常用激活函数的基础上,结合卷积神经网络的训练过程,分析激活函数的设计方法,提出新的改进的组合激活函数relu-softsign.
2. 激活函数设计方法分析
针对常见激活函数存在的梯度弥散、神经元“坏死”等问题,分析卷积神经网络训练过程中激活函数的作用,讨论激活函数的设计方法.
卷积神经网络的训练过程可以分为2个部分:前向传播和反向传播. 前向传播是指输入信号通过一个或多个网络层进行传递,最后在输出层得到实际输出的过程. 反向传播是根据实际输出和期望输出计算误差损失,然后通过每层的误差损失推导参数的学习规则,选择更优的参数,使实际输出更接近期望值的过程. 通过对前向传播和反向传播的过程进行分析,可以更好地理解激活函数在卷积神经网络训练过程中发挥的作用,明确在选择激活函数时需要考虑的激活函数特性.
由于激活函数在神经网络模型各层中发挥的作用类似,以最核心的卷积层为例,分析前向传播和反向传播中激活函数发挥的作用.
1)在前向传播过程中,上一层的输出经过卷积核卷积,如下所示:
然后通过激活函数运算:
可得该层的输出. 式中:
由式(5)、(6)可知,在前向传播过程中,激活函数在卷积层中的作用是对卷积求和操作的结果进行再次加工,使得卷积层的输入与输出不再成线性关系,增强特征的表达能力. 该过程要求激活函数不能为常数函数或其他线性函数. 由于每一层都有激活函数,为了保证模型的训练速度,激活函数的输出计算须尽量简便.
2)在反向传播过程中,卷积层需要进行调优的参数主要为卷积核参数k及偏置b. 通过计算损失,将损失对参数求偏导,最后乘上学习率,可得参数的更新Δk与Δb. 具体流程如下.
a)计算误差损失E,可以结合实际需求选用平方误差损失、互熵损失(cross entropy loss)、Hinge损失等多种方式.
式中:
c)用灵敏度对参数求偏导:
式中:
d)更新卷积层参数:
式中:η为学习率.
分析式(7)~(11),可以得到以下结论.
1)由式(7)~(11)的计算过程可知,最终的参数更新步长与激活函数的导数之间存在线性关系,所以激活函数的导数会直接影响卷积神经网络模型的收敛速度. 在模型训练前期,参数需要迅速更新到最优值附近,因此激活函数前半段的导数要足够大,才能加快模型收敛. 接下来参数更新放缓,逐步趋近最优值,因此激活函数后半段的导数须变小,最终趋近一个接近零的值,从而保证模型收敛. 另外,由式(10)、(11)可知,学习率与参数更新步长存在线性关系,理论上学习率越大,收敛速度越快,但学习率过大会导致不收敛,4.3节通过具体实验详细讨论了学习率与模型收敛性和收敛速度的关系.
2)计算参数更新时需要频繁计算和使用激活函数的导数,因此为了减少计算量,导数是否便于计算是激活函数选择时的一个重要衡量标准.
3)由式(9)、(10)可知,参数的更新方向与该层输入
综上所述,激活函数在前向传播和反向传播过程中都有着重要作用,所以在选择激活函数时需要综合考虑函数本身及其导数的特性,具体如下. 1)不能为常数或其他线性函数;2)输出便于计算;3)函数的值域中既包括正值,也包括负值;4)前半段导数要足够大,后半段导数逐渐减小到接近零值;5)导数要便于计算.
3. relu-softsign组合激活函数
由上述分析可知,激活函数前半段导数要足够大,使参数能够迅速更新到最优值附近;后半段导数逐渐减小到接近零值,以实现参数微调. 单一的激活函数无法同时满足这两点,需要采用对激活函数进行分段组合的方式来改善. 现有的组合激活函数relu-softplus虽然训练效果有所提升,但由于其负半轴的导数下降过快,无法适用较大的学习率,收敛速度受到限制. 为了缓解神经元“坏死”现象和改进激活函数的收敛性能,将relu函数与softsign函数组合,提出新的组合激活函数relu-softsign.
relu函数是线性的,收敛速度快,但由于x负半轴的导数恒为零的特性,容易发生神经元“坏死”;softsign函数在零值附近导数大,收敛快,在负值时导数能够一直保持变化,逐渐减小到接近零值. 结合这2种激活函数,可以优势互补,达到更高的分类准确度,加快收敛速度. 接下来具体分析选择relu和softsign函数进行组合的优势.
1)relu函数为线性函数,具备良好的稀疏性,计算简单,能够加快模型的训练速度. sigmoid函数只能输出正值,导致收敛缓慢. 函数两端导数为零,容易发生梯度消失. 与sigmoid函数相比,虽然tanh函数的收敛速度有所改善,但存在梯度消失问题. 使用relu函数的正半轴进行组合,可以使组合激活函数具备relu函数的部分特性,加快模型的收敛速度,大大减少发生梯度消失的可能.
2)softsign函数是以零为中心的对称曲线,曲线图形与tanh函数类似,softsign函数的值域既有正值也有负值,所以可以解决sigmoid函数由于只能输出正值、导致收敛缓慢的问题. 相对于tanh来说,softsign曲线更加平缓而且导数下降的速率更慢,更有利于解决由于函数两端导数为零造成的梯度消失问题. 相对于tanh和sigmoid函数及其导数的指数计算,softsign函数计算更加简便.
图 5

图 5 softplus函数和softsign函数的曲线图
Fig.5 Curve of softplus function and softsign function
4)对softsign和softplus的导数曲线图像进行分析,如图6所示. 由图6中导数的变化趋势可知,当输入数据在零附近波动时,softsign的导数变化更快,这表明softsign函数对数据更加敏感,收敛速度更快. 另外,在负半轴中,softplus的导数比softsign更容易趋向零,并保持一个接近零的数值,从而导致模型训练可能发生不收敛现象;softsign函数的导数在负半轴能够保持变化,缓慢减小. 当选用较大的学习率时,参数更新加快,softplus函数的导数很容易就降为零,造成神经元坏死;softsign函数的导数能够保持一个大于零的值,使模型持续收敛. 使用softsign函数替换softplus函数进行组合,可以使模型适用更高的学习率,提高模型的收敛速度. 在多个数据集上设置不同的学习率,开展详细的对比实验.
图 6

图 6 softplus和softsign的导数曲线对比图
Fig.6 Curve of softplus and softsign’s derivative
5)与Leaky Relu、PRelu等改进激活函数相比,softsign函数不需要设置额外的超参数,所以不会增加模型训练的难度. 另外,ELU的导数计算复杂度为指数级,softsign导数的计算复杂度为
将relu函数与softsign函数于x轴正、负半轴进行分段组合,得到relu-softsign组合激活函数,函数表达式如下:
组合函数的曲线图如图7所示.
图 7
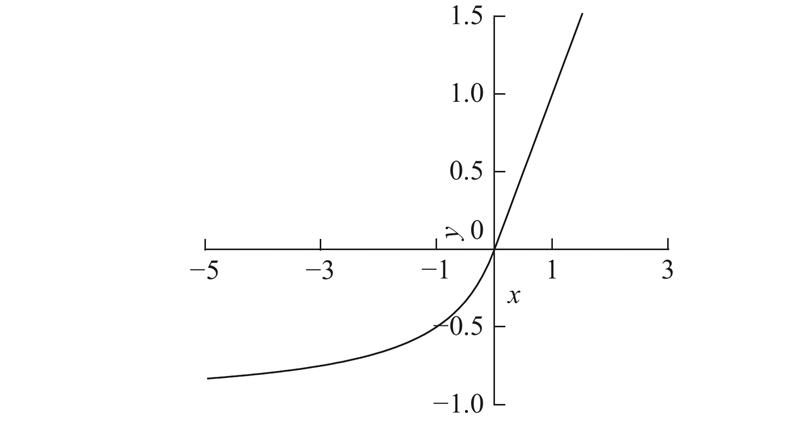
由式(12)和图7可知,当x>0时,relu-softsign函数的导数为常数1,此时模型能够快速收敛;当x≤0时,relu-softsign函数的导数缓慢减小,且能够为零附近的非正数提供非零导数,这样既增强了relu-softsign函数对非正值处理的鲁棒性,又加快了模型的收敛速度,从而获得比其他激活函数更好的分类效果.
4. 实验结果与分析
为了验证提出的relu-softsign组合激活函数在不同数据集中的有效性,分别在常用数据集MNIST、PI100、CIFAR-100和Caltech256中使用relu-softsign与其他几种激活函数进行对比实验. 针对每个数据集,分别建立对应的神经网络模型,其中由于Leaky Relu、PRelu等改进激活函数需要额外维护一个超参数,且对不同数据集的训练效果差异很大,训练成本过高,目前很少被采用,所以对比实验时使用relu、softsign、relu-softplus和本文提出的relu-softsign组合激活函数进行模型的训练. 该实验在基于Tensorflow后端的keras框架上实现. 最终的实验结果表明,在这4个数据集中,使用relu-softsign激活函数均能够达到比其他激活函数更高的分类准确度,收敛速度更快. 另外,对各个激活函数在不同学习率下的收敛情况进行实验对比,讨论relu-softsign函数对模型收敛性的影响. 实验结果表明,随着数据集复杂程度的增加,relu-softsign函数的收敛优势更明显.
4.1. 评估指标
4.1.1. 评价指标loss
本文要解决的是多分类问题,且使用了softmax层,所以loss计算采用与softmax相对应的损失函数categorial_cross_entropy,亦称多分类的对数损失. 由softmax层来计算每个类别的分类概率,再用cross_ entropy根据概率计算loss,具体公式如下:
式中:
4.1.2. 评价指标ACC
ACC是正确的样本数量与样本总数之比,计算公式为
式中:ACC为分类精度,
由于模型训练后期进入收敛阶段时,ACC和loss会在一个极小的范围内波动,取最后5轮训练的ACC和loss的均值作为最终的分类准确率和损失,如下所示:
式中:
本文所用的4个数据集都划分了训练集和测试集,所以在训练过程中对每一轮的训练集loss、训练集ACC、测试集loss和测试集ACC均须进行计算,分别记为losst、ACCt、lossv和ACCv.
4.2. 图像分类实验结果与分析
4.2.1. 在MNIST数据集上的实验结果与分析
MNIST是用于手写数字识别的数据集,有0~9这10个数字共70 000张图,其中60 000张为训练集,10 000张为测试集. 针对MNIST数据集设计的卷积神经网络模型结构共有2个卷积层、1个池化层和1个全连接层. 其中第1个卷积层卷积核的个数为32,第2个卷积层卷积核的个数为64,大小均为3×3. 最大池化层窗口大小为2×2,全连接层神经元个数为128. 由于MNIST数据集较简单,训练轮数epochs设置为12轮,批尺寸batch_size设置为128,学习率为0.000 1.
在MNIST的模型上不同激活函数的实验结果如表1所示. 由表1可知,提出的relu-softsign函数在训练集和测试集上的loss均最低,ACC最高. 其中,在训练集上,relu-softsign的最终分类精度相对于relu提高了0.05%,相对于softsign提高了0.28%,相对于relu-softplus提高了0.02%;在测试集上,相对于relu提高了0.01%,相对于softsign提高了0.24%,相对于relu-softplus提高了0.04%. 组合函数解决了单一函数存在的问题,训练时间略有增加. 在MNIST上的实验结果表明,相对于单一激活函数relu、softsign,平均每轮训练时间分别只增加了2、1 s,比组合激活函数relu-softplus少1 s.
表 1 MNIST上的实验结果
Tab.1
| 激活函数 | losst | ACCt | lossv | ACCv |
| relu | 0.041 6 | 0.987 7 | 0.039 3 | 0.989 0 |
| softsign | 0.047 9 | 0.985 4 | 0.041 0 | 0.986 7 |
| relu-softplus | 0.039 4 | 0.988 0 | 0.034 8 | 0.988 7 |
| relu-softsign | 0.037 1 | 0.988 2 | 0.034 8 | 0.989 1 |
图 8
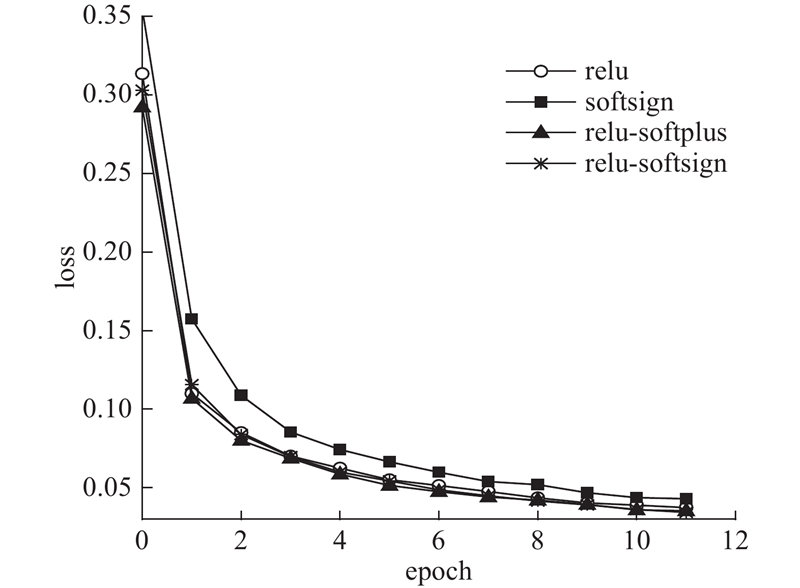
图 8 不同激活函数在MNIST上的losst
Fig.8 Training loss of different activation functions on MNIST
4.2.2. 在PI100数据集上的实验结果与分析
PI100数据集是微软研究院从MSN购物网站上收集的商品数据集,包含100类共10 000张图,分辨率为100像素×100像素[17]. 将PI100数据集随机划分为80%的训练集和20%的测试集进行训练,对训练集进行zca白化、随机缩放等预处理操作. 针对PI100数据集设计的卷积神经网络模型包含4个卷积层、4个池化层和1个全连接层. 4个卷积层的卷积核个数分别为64、64、128、256,大小均为3×3. 池化层窗口大小为2×2. 全连接层神经元个数为512,并接了一个BatchNormalization层. epoch设置为80轮,批尺寸batch_size设置为32,学习率设为0.000 1.
在PI100的模型上几个激活函数的实验结果如表2所示. 由表2可知,在训练集和测试集上,relu-softsign函数的loss最低,ACC最高. 在训练集上,relu-softsign的分类精度相对于relu提高了0.25%,相对于softsign提高了0.54%,相对于relu-softplus提高了0.15%;在测试集上,相对于relu提高了2.70%,相对于softsign提高了4.37%,相对于relu-softplus提高了0.47%. 在PI100上的实验结果表明,相对于单一激活函数relu、softsign,平均每轮训练时间分别只增加了10和4 s,比组合激活函数relu-softplus少2 s.
表 2 PI100上的实验结果
Tab.2
| 激活函数 | losst | ACCt | lossv | ACCv |
| relu | 0.047 8 | 0.987 9 | 0.486 8 | 0.879 8 |
| softsign | 0.052 3 | 0.985 0 | 0.626 2 | 0.863 1 |
| relu-softplus | 0.041 2 | 0.988 9 | 0.450 6 | 0.902 1 |
| relu-softsign | 0.037 4 | 0.990 4 | 0.432 6 | 0.906 8 |
如图9所示为不同激活函数在PI100上的losst变化曲线图. 可知,PI100数据集的图片较简单,模型结构较复杂,所以相对于MNIST数据集,几种激活函数的losst曲线更加接近. 在进行了80轮训练后,几个激活函数的losst均能够降到很低. 在训练前期,relu函数的收敛速度慢一些,其他3个激活函数的收敛速度相近;到了训练后期,几个函数的loss变化曲线十分接近,relu-softsign函数的收敛速度最快,loss最低.
图 9
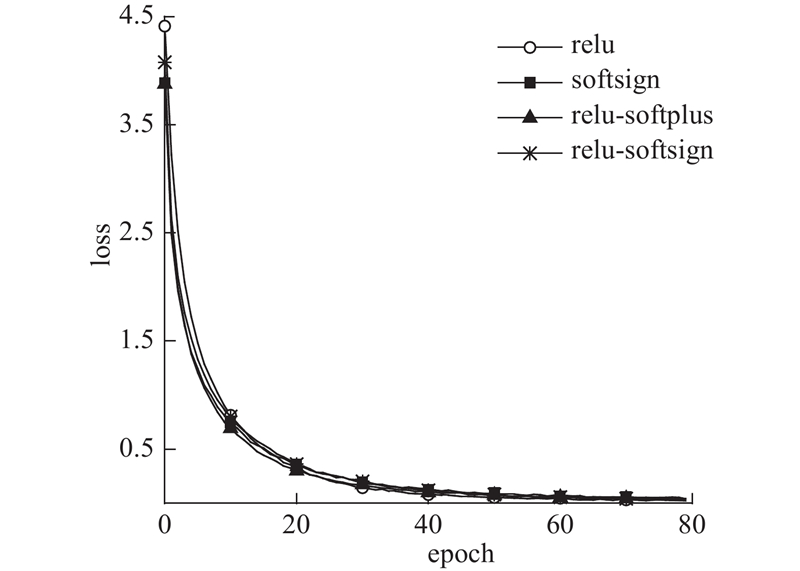
图 9 不同激活函数在PI100上的losst
Fig.9 Training loss of different activation functions on PI100
4.2.3. 在CIFAR-100数据集上的实验结果与分析
CIFAR-100数据集是图像分类领域的一个权威数据集,通过对CIFAR-10数据集的类别进行更加细致的划分而得到,共有100类60 000张彩色图像,其中50 000张用于训练,10 000张用于测试. 针对CIFAR-100数据集设计卷积神经网络,包含4个卷积层、2个池化层、1个全连接层. 4个卷积层中的卷积核大小均为3×3,前2个卷积层中卷积核的个数为64,后2个卷积层中卷积核的个数为128. 最大池化层的大小为2×2. 全连接层神经元个数为512. epoch设置为80轮,批尺寸batch_size设置为32,学习率为0.000 1.
在CIFAR-100的模型上不同激活函数的实验结果如表3所示. 可知,提出的组合激活函数relu-softsign在该训练集和测试集上的分类准确率均最高,loss最低. 其中,在训练集上,relu-softsign的最终分类精度相对于relu提高了0.8%,相对于softsign提高了7.92%,相对于relu-softplus提高了2.88%;在测试集上,相对于relu提高了1.91%,相对于softsign提高了2.93%,相对于relu-softplus提高了1.12%. 在CIFAR-100上的实验结果表明,相对于单一激活函数relu、softsign,平均每轮训练时间分别只增加了10和4 s,比组合激活函数relu-softplus少2 s.
表 3 CIFAR-100上的实验结果
Tab.3
| 激活函数 | losst | ACCt | lossv | ACCv |
| relu | 0.748 9 | 0.770 2 | 1.706 7 | 0.595 2 |
| softsign | 1.041 3 | 0.699 0 | 1.607 4 | 0.585 0 |
| relu-softplus | 0.853 8 | 0.749 4 | 1.596 2 | 0.603 1 |
| relu-softsign | 0.743 1 | 0.778 2 | 1.582 3 | 0.614 3 |
模型训练过程中的losst的变化曲线如图10所示. 可知,在模型训练的前期,relu收敛速度最快,但是在训练后期,relu-softsign收敛速度逐渐加快,最终的loss最低,分类性能最好.
图 10

图 10 不同激活函数在CIFAR-100上的losst
Fig.10 Training loss of different functions on CIFAR-100
4.2.4. 在Caltech256数据集上的实验结果与分析
Caltech256数据集是加州理工学院提供的图像分类数据库,共257类30 609张图,每类图片数量不等. 将Caltech256数据集随机划分为80%的训练集和20%的测试集进行训练,对训练集进行随机缩放、水平翻转等预处理操作. 针对Caltech256数据集设计的卷积神经网络模型包含4个卷积层、4个池化层和1个全连接层. 4个卷积层的卷积核个数分别为32、32、64、128,大小均为3×3. 池化层窗口大小为2×2. 全连接层神经元个数为512,并接了一个BatchNormalization层. epoch设置为100轮,批尺寸batch_size设置为32,学习率设为0.000 1.
在Caltech256的模型上几个激活函数的实验结果如表4所示. 可知,在训练集和测试集上,relu-softsign函数的loss最低,ACC最高. 其中,在训练集上,relu-softsign的分类精度相对于relu提高了2.94%,相对于softsign提高了3.96%,相对于relu-softplus提高了1.9%;在测试集上,相对于relu提高了0.5%,相对于softsign提高了2.29%,相对于relu-softplus提高了0.58%. 在Caltech256上的实验结果表明,相对于单一激活函数relu、softsign,平均每轮训练时间分别只增加了12和7 s,比组合激活函数relu-softplus少2 s.
表 4 Caltech256上的实验结果
Tab.4
| 激活函数 | losst | ACCt | lossv | ACCv |
| relu | 0.864 9 | 0.760 0 | 3.528 3 | 0.420 0 |
| softsign | 0.933 5 | 0.750 1 | 3.620 6 | 0.397 6 |
| relu-softplus | 0.840 5 | 0.770 4 | 3.453 4 | 0.414 7 |
| relu-softsign | 0.756 9 | 0.789 4 | 3.499 4 | 0.420 5 |
如图11所示为不同激活函数在Caltech256上的losst变化曲线图. 可知,在训练前期,几个函数的收敛速度相近,曲线基本重合,但到了训练后期, relu-softsign函数的收敛速度最快,loss最低.
图 11

图 11 不同激活函数在Caltech256上的losst
Fig.11 Training loss of different activation functions on Caltech256
综上所述,在MNIST、PI100、CIFAR-100和Caltech256数据集上,提出的relu-softsign函数均能够达到最高的ACC和最低的loss,分类性能最好,且训练时间相对于单一激活函数略有增加,比组合激活函数relu-softplus少. 在复杂数据集上,relu-softsign函数在ACC和loss上的提升更明显.
4.3. 不同学习率下的收敛性实验结果与分析
根据4.2节的实验结果可知,在低学习率情况下,对于MNIST、PI100、CIFAR-100和Caltech256数据集,提出的组合激活函数relu-softsign与relu-softplus函数的分类性能相近,相对单一激活函数在loss和ACC上都有明显提升. 在卷积神经网络中,适当增加学习率可以加快模型的收敛速度,但学习率过高会造成参数的更新幅度过大,模型难以收敛. 在这4个数据集上进行relu-softsign和relu-softplus函数的对比实验,通过设置不同的学习率,验证relu-softsign函数比relu-softplus函数可以使用更高的学习率,使得模型的收敛速度更快.
模型的训练过程本质上是参数更新的过程. 在反向传播时,根据期望输出和由前向传播得到的实际输出计算误差损失,然后依据损失的变化情况决定参数的变化方向,选择更优参数. 经过多轮训练,模型中各层的参数经过多次调整,逐渐趋近最优值,使实际输出逐渐接近期望输出,最终loss会在一个极小的范围内波动,说明模型成功收敛. 由2章对反向传播的分析可知,激活函数会影响参数更新的方向和参数更新的步长,同时学习率会影响参数更新的步长;因此,激活函数和学习率的选择会对模型的收敛性能产生很大的影响. 合适的激活函数和学习率会使参数在模型训练初期迅速更新到最优值附近,然后进行微调,逐渐趋近最优值,从而使得在模型训练过程中,loss逐渐变小,ACC逐渐增大,且最终趋于稳定,模型成功收敛. 若选择不合适的激活函数和学习率,则会导致参数更新步长过大、更新方向难以改变等问题,造成模型训练过程中loss难以下降或反复剧烈波动,模型无法收敛.
表 5 MNIST和PI100上不同学习率下的收敛情况对比
Tab.5
| 学习率 | MNIST收敛情况 | PI100收敛情况 | |||
| relu-softplus | relu-softsign | relu-softplus | relu-softsign | ||
| 0.000 1 | 成功收敛,分类准确率为98% | 成功收敛,分类准确率为98% | 成功收敛,分类准确率为99% | 成功收敛,分类准确率为99% | |
| 0.001 | 成功收敛,分类准确率为98% | 成功收敛,分类准确率为98% | 第10轮开始不收敛 | 成功收敛,分类准确率为99% | |
| 0.01 | 第2轮开始不收敛 | 第2轮开始不收敛 | 第4轮开始不收敛 | 成功收敛,分类准确率为85% | |
| 0.1 | 第1轮开始不收敛 | 第1轮开始不收敛 | 第2轮开始不收敛 | 第3轮开始不收敛 | |
表 6 CIFAR-100和Caltech256上不同学习率下的收敛情况对比
Tab.6
| 学习率 | CIFAR-100收敛情况 | Caltech256收敛情况 | |||
| relu-softplus | relu-softsign | relu-softplus | relu-softsign | ||
| 0.000 1 | 成功收敛,分类准确率为75% | 成功收敛,分类准确率为78% | 成功收敛,分类准确率为77% | 成功收敛,分类准确率为79% | |
| 0.001 | 第40轮开始不收敛 | 成功收敛,分类准确率为76% | 第10轮开始不收敛 | 成功收敛,分类准确率为79% | |
| 0.01 | 第4轮开始不收敛 | 成功收敛,分类准确率为72% | 第2轮开始不收敛 | 成功收敛,分类准确率为75% | |
| 0.1 | 第4轮开始不收敛 | 第3轮开始不收敛 | 第2轮开始不收敛 | 第20轮开始不收敛 | |
图 12

图 12 Caltech256上relu-softsign和relu-softplus的losst
Fig.12 Training loss of relu-softsign and relu-softplus on Caltech256
由表5、6可知,MNIST数据集上2个函数在不同学习率下的收敛情况近似,这是由于MNIST数据集相对其他数据集比较简单,在这个数据集上训练难以体现激活函数对收敛性的影响. 对于更复杂的数据集PI100、CIFAR-100和Caltech256,训练结果均出现明显差异. 在这3个数据集上,当学习率为0.000 1时,2个函数均能够成功收敛, relu-softsign函数的分类准确率略高于relu-softplus函数;当学习率为0.001时,relu-softsign函数在保证分类准确率的情况下能够正常收敛,即使学习率提高到0.01时relu-softsign仍能收敛,准确率明显下降,relu-softplus函数在学习率高于0.000 1时都无法收敛. 从MNIST、PI100到CIFAR-100、Caltech256,数据集的复杂程度是逐级增加的;由表5、6可知,随着数据集复杂程度的增加,relu-softsign函数在收敛性方面的优势更加明显.
接下来在复杂程度最大的数据集Caltech256上开展收敛速度的对比实验,在保证收敛和分类准确率的情况下,讨论 relu-softplus和relu-softsign函数的收敛速度,学习率分别取0.000 1和0.001.
通过图12可以看出,2条loss曲线在模型训练后期都趋于平缓,loss只在一个很小的范围内波动,这说明两者都已成功收敛. 使用relu-softsign函数进行训练,loss下降更快,且曲线在100轮左右已稳定,模型成功收敛;使用relu-softplus函数进行训练,由于学习率的限制,loss下降较缓慢,在130轮左右逐渐稳定,relu-softplus函数的收敛速度远远慢于提出的relu-softsign函数.
综上所述,relu-softsign函数能够在保证模型分类准确率的同时设置比relu-softplus更大的学习率,加快模型收敛.
5. 结 语
通过分析卷积神经网络中激活函数的作用,给出在激活函数选择时需要考虑的激活函数及其导数的特性,提出新的组合激活函数relu-softsign;将relu和softsign函数分别于x轴正、负半轴进行分段组合,使其x负半轴导数不再恒为零,简单、有效地缓解了神经元不可逆“坏死”现象. 在MNIST、PI100、CIFAR-100和Caltech256常用数据集上的实验结果表明,相比于单一激活函数和其他组合激活函数,使用relu-softsign组合激活函数的分类准确率最高,收敛效果最好. 通过设置不同学习率的对比实验可知,在保证模型分类性能的情况下,relu-softsign函数可以设置比relu-softplus函数更大的学习率,模型收敛速度更快.
本文提出的组合激活函数relu-softsign相对于relu-softplus加快了模型收敛速度,提高了模型的学习和泛化能力,但是存在可以进一步改进的地方. 目前深度学习领域正在向低精度数据发展,之后可以探讨该激活函数在低精度时如何防止精度损失;另外,可以研究该组合激活函数对不同优化器的适应能力,进一步提高收敛性能.
参考文献
图像物体分类与检测算法综述
[J].
A review on image object classification and detection
[J].
图像理解中的卷积神经网络
[J].
Convolution neural network in image understanding
[J].
Weight initialization possibilities for feedforward neural network with linear saturated activation functions
[J].DOI:10.1016/j.ifacol.2016.12.009 [本文引用: 1]
Fast and accurate deep network learning by exponential linear units (ELUs)
[J].
Gradient-based learning applied to document recognition
[J].DOI:10.1109/5.726791 [本文引用: 1]
From images to shape models for object detection
[J].DOI:10.1007/s11263-009-0270-9 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}