[1]
YUE L W, SHEN H F, LI J, et al Image super-resolution: the techniques, applications, and future
[J]. Signal Processing , 2016 , 128 (11 ): 389 - 408
[本文引用: 1]
[2]
陆志芳, 钟宝江 基于预测梯度的图像插值算法
[J]. 自动化学报 , 2018 , 44 (06 ): 1072 - 1085
[本文引用: 1]
LU Zhi-fang, ZHONG Bao-jiang Image interpolation with predicted gradients
[J]. Acta Automatica Sinica , 2018 , 44 (06 ): 1072 - 1085
[本文引用: 1]
[3]
孙京, 袁强强, 李冀玮, 等 亮度--梯度联合约束的车牌图像超分辨率重建
[J]. 中国图象图形学报 , 2018 , 23 (06 ): 802 - 813
[本文引用: 1]
SUN Jing, YUAN Qiang-qiang, LI Ji-wei, et al License plate image super-resolution based on intensity-gradient prior combination
[J]. Journal of Image and Graphics , 2018 , 23 (06 ): 802 - 813
[本文引用: 1]
[4]
YANG J, WRIGHT J, HUANG T, et al. Image super-resolution as sparse representation of raw image patches [C] // IEEE Conference on Computer Vision and Pattern Recognition . Anchorage: IEEE, 2008: 1–8.
[本文引用: 1]
[5]
孙旭, 李晓光, 李嘉锋, 等 基于深度学习的图像超分辨率复原研究进展
[J]. 自动化学报 , 2017 , 43 (5 ): 697 - 709
[本文引用: 1]
SUN Xu, LI Xiao-guang, LI Jia-feng, et al Review on deep learning based image super-resolution restoration algorithms
[J]. Acta Automatica Sinica , 2017 , 43 (5 ): 697 - 709
[本文引用: 1]
[6]
DONG C, CHEN C L, HE K, et al Image super-resolution using deep convolutional networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 38 (2 ): 295 - 307
DOI:10.1109/TPAMI.2015.2439281
[本文引用: 4]
[7]
YANG S, SUN Y, CHEN Y, et al Structural similarity regularized and sparse coding based super-resolution for medical images
[J]. Biomedical Signal Processing and Control , 2012 , 7 (6 ): 579 - 590
DOI:10.1016/j.bspc.2012.08.001
[本文引用: 1]
[8]
DONG C, CHEN C L, TANG X. Accelerating the super-resolution convolutional neural network [C] // European Conference on Computer Vision . Amsterdam: Springer, 2016: 391–407.
[本文引用: 5]
[9]
KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1646–1654.
[本文引用: 2]
[10]
谢珍珠, 吴从中, 詹曙 边缘增强深层网络的图像超分辨率重建
[J]. 中国图象图形学报 , 2018 , 23 (1 ): 114 - 122
[本文引用: 6]
XIE Zhen-zhu, WU Cong-zhong, ZHAN Shu Image super-resolution reconstruction via deep network based on edge-enhancement
[J]. Journal of Image and Graphics , 2018 , 23 (1 ): 114 - 122
[本文引用: 6]
[11]
李云飞, 符冉迪, 金炜, 等 多通道卷积的图像超分辨率方法
[J]. 中国图象图形学报 , 2017 , 22 (12 ): 1690 - 1700
LI Yun-fei, FU Ran-di, JIN Wei, et al Image super-resolution using multi-channel convolution
[J]. Journal of Image and Graphics , 2017 , 22 (12 ): 1690 - 1700
[12]
陈书贞, 解小会, 杨郁池, 等 利用多尺度卷积神经网络的图像超分辨率算法
[J]. 信号处理 , 2018 , 34 (09 ): 1033 - 1044
[本文引用: 1]
CHEN Shu-zhen, XIE Xiao-hui, YANG Yu-chi, et al Image super-resolution algorithm based on multi-scale convolution neural network
[J]. Journal of Signal Processing , 2018 , 34 (09 ): 1033 - 1044
[本文引用: 1]
[13]
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2414–2423.
[本文引用: 2]
[14]
JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution [C] // European Conference on Computer Vision . Amsterdam: Springer, 2016: 694–711.
[本文引用: 13]
[15]
LEDIG C, WANG Z, SHI W, et al. Photo-realistic single image super-resolution using a generative adversarial network [C] // IEEE Conference on Computer Vision and Pattern Recognition . Hawaii: IEEE, 2017: 105–114.
[本文引用: 10]
[16]
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C] // International Conference on Neural Information Processing Systems . Montreal: ACM, 2014: 2672–2680.
[本文引用: 2]
[17]
DENG X Enhancing image quality via style transfer for single image super-resolution
[J]. IEEE Signal Processing Letters , 2018 , 25 (4 ): 571 - 575
DOI:10.1109/LSP.2018.2805809
[本文引用: 8]
[18]
SHI W, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1874–1883.
[本文引用: 1]
[19]
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C] // International Conference on International Conference on Machine Learning . New York City: ACM, 2016: 1060–1069.
[本文引用: 1]
[20]
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C] // IEEE Conference on Computer Vision and Pattern Recognition . Hawaii, USA: IEEE, 2017: 5967–5976.
[本文引用: 4]
[21]
SAJJADI M S, SCHOLKOPF B, HIRSCH M, et al. EnhanceNet: single image super-resolution through automated texture synthesis [C] // IEEE International Conference on Computer Vision . Zurich: IEEE, 2017: 4501–4510.
[本文引用: 1]
[22]
LI C, WAND M. Precomputed real-time texture synthesis with Markovian generative adversarial networks [C] // European Conference on Computer Vision . Amsterdam: Springer, 2016: 702–716.
[本文引用: 1]
[23]
YANG J, WRIGHT J, HUANG T S, et al Image super-resolution via sparse representation
[J]. IEEE Transactions on Image Processing , 2010 , 19 (11 ): 2861 - 2873
DOI:10.1109/TIP.2010.2050625
[本文引用: 1]
[24]
TIMOFTE R, LEE K M, WANG X, et al. NTIRE 2017 challenge on single image super-resolution: methods and results [C] // IEEE Conference on Computer Vision and Pattern Recognition Workshops . Hawaii, USA: IEEE, 2017: 1110–1121.
[本文引用: 1]
[25]
HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on imageNet classification [C] // IEEE International Conference on Computer Vision . Santiago: IEEE, 2015:1026–1034.
[本文引用: 1]
[26]
TIMOFTE R, SMET V D, GOOL L V. A+: adjusted anchored neighborhood regression for fast super-resolution [C] // Asian Conference on Computer Vision . Singapore: Springer, 2014: 111–126.
[本文引用: 3]
Image super-resolution: the techniques, applications, and future
1
2016
... 图像超分辨率(SR)旨在通过软件技术,从单帧或多帧低分辨率(LR)图像中重建高分辨率(HR)图像或序列. 近年来,图像超分辨率重建方法在视频监控、遥感图像观测、天文图像处理及医学成像等领域都有较广泛的应用[1 ] . 图像超分辨率重建的方法可以大致分为基于插值[2 ] 、基于重建[3 ] 和基于学习[4 ] 3类. ...
基于预测梯度的图像插值算法
1
2018
... 图像超分辨率(SR)旨在通过软件技术,从单帧或多帧低分辨率(LR)图像中重建高分辨率(HR)图像或序列. 近年来,图像超分辨率重建方法在视频监控、遥感图像观测、天文图像处理及医学成像等领域都有较广泛的应用[1 ] . 图像超分辨率重建的方法可以大致分为基于插值[2 ] 、基于重建[3 ] 和基于学习[4 ] 3类. ...
基于预测梯度的图像插值算法
1
2018
... 图像超分辨率(SR)旨在通过软件技术,从单帧或多帧低分辨率(LR)图像中重建高分辨率(HR)图像或序列. 近年来,图像超分辨率重建方法在视频监控、遥感图像观测、天文图像处理及医学成像等领域都有较广泛的应用[1 ] . 图像超分辨率重建的方法可以大致分为基于插值[2 ] 、基于重建[3 ] 和基于学习[4 ] 3类. ...
亮度--梯度联合约束的车牌图像超分辨率重建
1
2018
... 图像超分辨率(SR)旨在通过软件技术,从单帧或多帧低分辨率(LR)图像中重建高分辨率(HR)图像或序列. 近年来,图像超分辨率重建方法在视频监控、遥感图像观测、天文图像处理及医学成像等领域都有较广泛的应用[1 ] . 图像超分辨率重建的方法可以大致分为基于插值[2 ] 、基于重建[3 ] 和基于学习[4 ] 3类. ...
亮度--梯度联合约束的车牌图像超分辨率重建
1
2018
... 图像超分辨率(SR)旨在通过软件技术,从单帧或多帧低分辨率(LR)图像中重建高分辨率(HR)图像或序列. 近年来,图像超分辨率重建方法在视频监控、遥感图像观测、天文图像处理及医学成像等领域都有较广泛的应用[1 ] . 图像超分辨率重建的方法可以大致分为基于插值[2 ] 、基于重建[3 ] 和基于学习[4 ] 3类. ...
1
... 图像超分辨率(SR)旨在通过软件技术,从单帧或多帧低分辨率(LR)图像中重建高分辨率(HR)图像或序列. 近年来,图像超分辨率重建方法在视频监控、遥感图像观测、天文图像处理及医学成像等领域都有较广泛的应用[1 ] . 图像超分辨率重建的方法可以大致分为基于插值[2 ] 、基于重建[3 ] 和基于学习[4 ] 3类. ...
基于深度学习的图像超分辨率复原研究进展
1
2017
... 近年来,深度学习技术为SR的研究带来新的进展[5 ] . Dong等[6 ] 提出的SRCNN利用3层卷积神经网络(CNN),实现了LR图像和HR图像之间端到端的映射,表现出了比以往方法[7 ] 更优的性能. 该方法存在以下不足:1)SRCNN网络较浅,因此网络对应的感受野较小,限制了网络从海量的数据以及丰富的信息中对图像特征的学习和使用;2)SRCNN使用均方误差(MSE)损失训练CNN,虽然能够提高重建图像的PSNR评分,但是当超分辨率因子较大时,重建图像具有较明显的过度模糊现象. ...
基于深度学习的图像超分辨率复原研究进展
1
2017
... 近年来,深度学习技术为SR的研究带来新的进展[5 ] . Dong等[6 ] 提出的SRCNN利用3层卷积神经网络(CNN),实现了LR图像和HR图像之间端到端的映射,表现出了比以往方法[7 ] 更优的性能. 该方法存在以下不足:1)SRCNN网络较浅,因此网络对应的感受野较小,限制了网络从海量的数据以及丰富的信息中对图像特征的学习和使用;2)SRCNN使用均方误差(MSE)损失训练CNN,虽然能够提高重建图像的PSNR评分,但是当超分辨率因子较大时,重建图像具有较明显的过度模糊现象. ...
Image super-resolution using deep convolutional networks
4
2016
... 近年来,深度学习技术为SR的研究带来新的进展[5 ] . Dong等[6 ] 提出的SRCNN利用3层卷积神经网络(CNN),实现了LR图像和HR图像之间端到端的映射,表现出了比以往方法[7 ] 更优的性能. 该方法存在以下不足:1)SRCNN网络较浅,因此网络对应的感受野较小,限制了网络从海量的数据以及丰富的信息中对图像特征的学习和使用;2)SRCNN使用均方误差(MSE)损失训练CNN,虽然能够提高重建图像的PSNR评分,但是当超分辨率因子较大时,重建图像具有较明显的过度模糊现象. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 训练基于MSE损失的多尺度特征映射网络模型,用于分析网络结构的性能. 如表1 所示为本文方法与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 和文献[10 ]方法的PSNR和SSIM对比结果. 本文方法在常用测试集Set5、Set14和BSD100上的平均PSNR与其他5种方法相比,分别提高了2.10、0.66、0.53、0.40、0.05 dB,平均SSIM分别提高了0.069、0.023、0.022、0.02、0.005. ...
... Average PSNRs and SSIMs compared with other SR methods on Set5,Set14 and BSD100 (4×)
Tab.1 SR方法 PSNR/dB, SSIM Set5 Set14 BSD100 平均值 双三次插值 28.43, 0.810 25.77, 0.703 25.98, 0.671 26.73, 0.728 A+[26 ] 30.30, 0.859 27.38, 0.752 26.82, 0.710 28.17, 0.774 SRCNN[6 ] 30.49, 0.863 27.50, 0.751 26.91, 0.712 28.30, 0.775 FSRCNN[8 ] 30.71, 0.865 27.60, 0.753 26.97, 0.713 28.43, 0.777 文献[10 ]方法 30.80, 0.873 28.60, 0.792 26.96, 0.711 28.78, 0.792 本文方法(MSE) 31.32, 0.881 27.78, 0.773 27.40, 0.736 28.83, 0.797
如图4 所示为利用本文方法和其他方法,分别对Set5、Set14和BSD100中经4倍双三次下采样的LR图像进行超分辨率重建的结果. 利用提出的多尺度特征映射网络能够增大感受野的尺寸,提取更复杂的特征,增强局部特征间的相关性,增强网络对特征的利用率,因而重建图像表现出了更加清晰的轮廓和边缘,具有很好的视觉效果. ...
Structural similarity regularized and sparse coding based super-resolution for medical images
1
2012
... 近年来,深度学习技术为SR的研究带来新的进展[5 ] . Dong等[6 ] 提出的SRCNN利用3层卷积神经网络(CNN),实现了LR图像和HR图像之间端到端的映射,表现出了比以往方法[7 ] 更优的性能. 该方法存在以下不足:1)SRCNN网络较浅,因此网络对应的感受野较小,限制了网络从海量的数据以及丰富的信息中对图像特征的学习和使用;2)SRCNN使用均方误差(MSE)损失训练CNN,虽然能够提高重建图像的PSNR评分,但是当超分辨率因子较大时,重建图像具有较明显的过度模糊现象. ...
5
... 近几年提出的许多超分辨率方法[8 -12 ] 通过优化网络结构来提高重建图像的质量. Dong等[8 ] 在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
... [8 ]在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 训练基于MSE损失的多尺度特征映射网络模型,用于分析网络结构的性能. 如表1 所示为本文方法与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 和文献[10 ]方法的PSNR和SSIM对比结果. 本文方法在常用测试集Set5、Set14和BSD100上的平均PSNR与其他5种方法相比,分别提高了2.10、0.66、0.53、0.40、0.05 dB,平均SSIM分别提高了0.069、0.023、0.022、0.02、0.005. ...
... Average PSNRs and SSIMs compared with other SR methods on Set5,Set14 and BSD100 (4×)
Tab.1 SR方法 PSNR/dB, SSIM Set5 Set14 BSD100 平均值 双三次插值 28.43, 0.810 25.77, 0.703 25.98, 0.671 26.73, 0.728 A+[26 ] 30.30, 0.859 27.38, 0.752 26.82, 0.710 28.17, 0.774 SRCNN[6 ] 30.49, 0.863 27.50, 0.751 26.91, 0.712 28.30, 0.775 FSRCNN[8 ] 30.71, 0.865 27.60, 0.753 26.97, 0.713 28.43, 0.777 文献[10 ]方法 30.80, 0.873 28.60, 0.792 26.96, 0.711 28.78, 0.792 本文方法(MSE) 31.32, 0.881 27.78, 0.773 27.40, 0.736 28.83, 0.797
如图4 所示为利用本文方法和其他方法,分别对Set5、Set14和BSD100中经4倍双三次下采样的LR图像进行超分辨率重建的结果. 利用提出的多尺度特征映射网络能够增大感受野的尺寸,提取更复杂的特征,增强局部特征间的相关性,增强网络对特征的利用率,因而重建图像表现出了更加清晰的轮廓和边缘,具有很好的视觉效果. ...
2
... 近几年提出的许多超分辨率方法[8 -12 ] 通过优化网络结构来提高重建图像的质量. Dong等[8 ] 在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
... 相关研究人员通过使用更复杂的损失函数来更好地重建图像的高频信息. 受文献[13 ]的启发,Johnson等[14 ] 使用感知损失训练网络,重建图像具有更加清晰的边缘. Ledig等[15 ] 基于生成对抗网络(GAN)[16 ] 提出的SRGAN算法,结合对抗损失与感知损失,令重建图像具有更加逼真的视觉效果,但重建图像的PSNR比其他方法[9 ] 低. 为了提高SRGAN的重建图像在PSNR评分上的不足,Deng[17 ] 在SRGAN的基础上,结合风格迁移的方法,通过取阈值灵活调整重建图像的客观评分和感知质量. ...
边缘增强深层网络的图像超分辨率重建
6
2018
... 近几年提出的许多超分辨率方法[8 -12 ] 通过优化网络结构来提高重建图像的质量. Dong等[8 ] 在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 训练基于MSE损失的多尺度特征映射网络模型,用于分析网络结构的性能. 如表1 所示为本文方法与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 和文献[10 ]方法的PSNR和SSIM对比结果. 本文方法在常用测试集Set5、Set14和BSD100上的平均PSNR与其他5种方法相比,分别提高了2.10、0.66、0.53、0.40、0.05 dB,平均SSIM分别提高了0.069、0.023、0.022、0.02、0.005. ...
... Average PSNRs and SSIMs compared with other SR methods on Set5,Set14 and BSD100 (4×)
Tab.1 SR方法 PSNR/dB, SSIM Set5 Set14 BSD100 平均值 双三次插值 28.43, 0.810 25.77, 0.703 25.98, 0.671 26.73, 0.728 A+[26 ] 30.30, 0.859 27.38, 0.752 26.82, 0.710 28.17, 0.774 SRCNN[6 ] 30.49, 0.863 27.50, 0.751 26.91, 0.712 28.30, 0.775 FSRCNN[8 ] 30.71, 0.865 27.60, 0.753 26.97, 0.713 28.43, 0.777 文献[10 ]方法 30.80, 0.873 28.60, 0.792 26.96, 0.711 28.78, 0.792 本文方法(MSE) 31.32, 0.881 27.78, 0.773 27.40, 0.736 28.83, 0.797
如图4 所示为利用本文方法和其他方法,分别对Set5、Set14和BSD100中经4倍双三次下采样的LR图像进行超分辨率重建的结果. 利用提出的多尺度特征映射网络能够增大感受野的尺寸,提取更复杂的特征,增强局部特征间的相关性,增强网络对特征的利用率,因而重建图像表现出了更加清晰的轮廓和边缘,具有很好的视觉效果. ...
... 在4倍放大因子下与双三次插值、A+、SRCNN、FSRCNN和文献[10 ]方法的重建结果对比图 ...
... Reconstruction results compared with bicubic interpolation,A+,SRCNN,FSRCNN and reference [10 ] (4×) ...
边缘增强深层网络的图像超分辨率重建
6
2018
... 近几年提出的许多超分辨率方法[8 -12 ] 通过优化网络结构来提高重建图像的质量. Dong等[8 ] 在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 训练基于MSE损失的多尺度特征映射网络模型,用于分析网络结构的性能. 如表1 所示为本文方法与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 和文献[10 ]方法的PSNR和SSIM对比结果. 本文方法在常用测试集Set5、Set14和BSD100上的平均PSNR与其他5种方法相比,分别提高了2.10、0.66、0.53、0.40、0.05 dB,平均SSIM分别提高了0.069、0.023、0.022、0.02、0.005. ...
... Average PSNRs and SSIMs compared with other SR methods on Set5,Set14 and BSD100 (4×)
Tab.1 SR方法 PSNR/dB, SSIM Set5 Set14 BSD100 平均值 双三次插值 28.43, 0.810 25.77, 0.703 25.98, 0.671 26.73, 0.728 A+[26 ] 30.30, 0.859 27.38, 0.752 26.82, 0.710 28.17, 0.774 SRCNN[6 ] 30.49, 0.863 27.50, 0.751 26.91, 0.712 28.30, 0.775 FSRCNN[8 ] 30.71, 0.865 27.60, 0.753 26.97, 0.713 28.43, 0.777 文献[10 ]方法 30.80, 0.873 28.60, 0.792 26.96, 0.711 28.78, 0.792 本文方法(MSE) 31.32, 0.881 27.78, 0.773 27.40, 0.736 28.83, 0.797
如图4 所示为利用本文方法和其他方法,分别对Set5、Set14和BSD100中经4倍双三次下采样的LR图像进行超分辨率重建的结果. 利用提出的多尺度特征映射网络能够增大感受野的尺寸,提取更复杂的特征,增强局部特征间的相关性,增强网络对特征的利用率,因而重建图像表现出了更加清晰的轮廓和边缘,具有很好的视觉效果. ...
... 在4倍放大因子下与双三次插值、A+、SRCNN、FSRCNN和文献[10 ]方法的重建结果对比图 ...
... Reconstruction results compared with bicubic interpolation,A+,SRCNN,FSRCNN and reference [10 ] (4×) ...
利用多尺度卷积神经网络的图像超分辨率算法
1
2018
... 近几年提出的许多超分辨率方法[8 -12 ] 通过优化网络结构来提高重建图像的质量. Dong等[8 ] 在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
利用多尺度卷积神经网络的图像超分辨率算法
1
2018
... 近几年提出的许多超分辨率方法[8 -12 ] 通过优化网络结构来提高重建图像的质量. Dong等[8 ] 在SRCNN的基础上,提出基于沙漏型CNN结构的FSRCNN模型,通过缩放特征维度减少了网络参数,提高了运行速度. Kim等[9 ] 设计基于深层残差网络的VDSR模型,利用深层残差网络提高算法性能. 谢珍珠等[10 ] 提出基于边缘增强的深层CNN网络结构,改善了易于出现边缘信息丢失和易于产生伪影等问题. ...
2
... 相关研究人员通过使用更复杂的损失函数来更好地重建图像的高频信息. 受文献[13 ]的启发,Johnson等[14 ] 使用感知损失训练网络,重建图像具有更加清晰的边缘. Ledig等[15 ] 基于生成对抗网络(GAN)[16 ] 提出的SRGAN算法,结合对抗损失与感知损失,令重建图像具有更加逼真的视觉效果,但重建图像的PSNR比其他方法[9 ] 低. 为了提高SRGAN的重建图像在PSNR评分上的不足,Deng[17 ] 在SRGAN的基础上,结合风格迁移的方法,通过取阈值灵活调整重建图像的客观评分和感知质量. ...
... Ledig等[15 ] 提出的SRGAN结合对抗损失与感知损失,虽然生成了具有高频纹理细节的逼真图像,但重建图像的平滑区域会受到锐化纹理的影响. Sajjadi等[21 ] 对这一问题进行分析,提出加入纹理损失[13 ] 改善生成图像质量的方法. 本文采用的判别器由大小为70×70的图像块进行训练,学习得到的是图像的局部纹理分布,因此由式(5)定义的对抗损失可以看作是纹理损失的一种[22 ] . 此外,本文加入的MSE损失因其对异常数值的敏感,能够有效地降低平滑区域产生的高频噪声. ...
13
... 相关研究人员通过使用更复杂的损失函数来更好地重建图像的高频信息. 受文献[13 ]的启发,Johnson等[14 ] 使用感知损失训练网络,重建图像具有更加清晰的边缘. Ledig等[15 ] 基于生成对抗网络(GAN)[16 ] 提出的SRGAN算法,结合对抗损失与感知损失,令重建图像具有更加逼真的视觉效果,但重建图像的PSNR比其他方法[9 ] 低. 为了提高SRGAN的重建图像在PSNR评分上的不足,Deng[17 ] 在SRGAN的基础上,结合风格迁移的方法,通过取阈值灵活调整重建图像的客观评分和感知质量. ...
... Johnson等[14 ] 使用16层VGG网络的第4个卷积层的激活值构建感知损失,生成的图像虽然具有更加锐化的边缘,但对一些局部纹理的恢复不够自然真实. 可能有以下2个主要原因:1)VGG网络是图像分类网络,通过VGG网络提取的图像特征更多地保留了物体轮廓和空间结构等有助于图像分类的语义信息,这些特征引导网络生成边缘更加锐利的图像,但会丢失一些对于图像分类来说不重要的纹理和细节;2)式(4)中计算欧氏距离会在一定程度上造成图像的平滑. SRGAN中的相关实验表明:当使用对抗损失训练网络模型时,基于高层特征的感知损失比使用低层特征生成的重建图像更加真实和清晰. 本文使用VGG网络第13卷积层的激活值构建感知损失. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
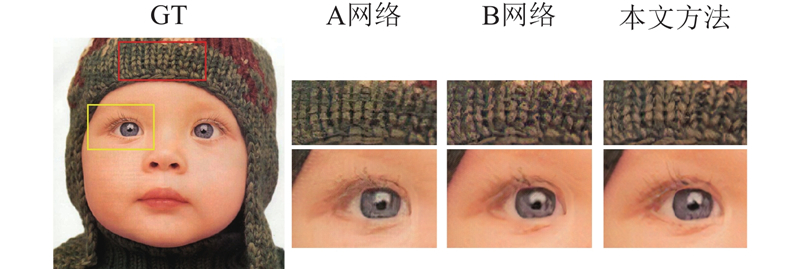
... 为了分析MSE损失、感知损失与对抗损失对重建图像质量的影响,设计结合感知损失与对抗损失的高频损失函数(PA)和结合MSE损失、感知损失以及对抗损失的综合损失函数(EPA),分别对网络进行优化,并将综合损失的实验结果与文献[14 ]方法、SRGAN[15 ] 、文献[17 ]方法进行比较. 如图5 所示为设计的网络基于不同损失函数,对4倍下采样图像的超分辨率重建结果. 可以看出,使用相同的图像生成网络,基于MSE损失的重建模型生成的图像缺少清晰的边缘和纹理,整体表现模糊;基于高频损失(PA)的网络模型虽然生成了含有丰富细节和纹理的图像,但一些平滑区域被尖锐的噪声所影响,如图5 中人脸的平滑区域存在黑色的斑点状噪声;使用综合损失(EPA)对网络进行优化,生成的图像具有清晰的轮廓和丰富的纹理,能够有效减少高频损失结果中出现的噪声. ...
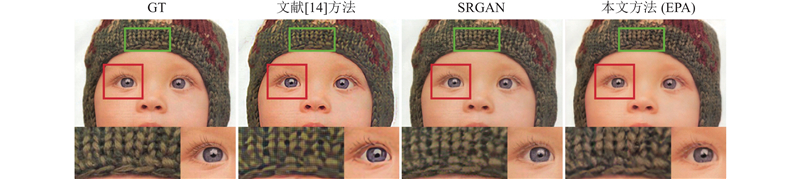
... 本文通过与文献[14 ]方法、SRGAN[15 ] 在4倍放大因子上的重建结果进行对比,分析和验证了本文提出的算法在超分辨率重建任务中的优越性能. 各方法的重建结果如图6 ~8 所示. 可以看出,提出的方法对图像中边缘、形状和纹理的恢复都有较好的效果:首先,与文献[14 ]结果进行比较可以发现,本文方法通过使用对抗损失能够更好地重建局部纹理,例如在图8 中,通过本文方法重建的baby图像,能够生成比Johnson等[14 ] 的结果更加真实和自然的毛线纹理;其次,本文采用基于patchGAN[20 ] 的对抗损失和基于像素的MSE损失,可以有效减少生成图像中平滑区域的高频噪声,与SRGAN的结果相比,能够更好地保留图像中小物体的形状和轮廓,例如图6 所示的图像右上角的金属花瓣,从SRGAN的重建图像中可以看到高频噪声极大地破坏了花瓣的形状,本文的重建图像虽然丢失了一些细小的边,但较完好地保留了花瓣的外形特征. 基于像素的MSE损失虽然抵消了感知损失与对抗损失在平滑区域产生的噪声,但对重建图像高频信息的恢复效果会造成影响,如图7 的放大区域,与SRGAN[15 ] 和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
... 所示. 可以看出,提出的方法对图像中边缘、形状和纹理的恢复都有较好的效果:首先,与文献[14 ]结果进行比较可以发现,本文方法通过使用对抗损失能够更好地重建局部纹理,例如在图8 中,通过本文方法重建的baby图像,能够生成比Johnson等[14 ] 的结果更加真实和自然的毛线纹理;其次,本文采用基于patchGAN[20 ] 的对抗损失和基于像素的MSE损失,可以有效减少生成图像中平滑区域的高频噪声,与SRGAN的结果相比,能够更好地保留图像中小物体的形状和轮廓,例如图6 所示的图像右上角的金属花瓣,从SRGAN的重建图像中可以看到高频噪声极大地破坏了花瓣的形状,本文的重建图像虽然丢失了一些细小的边,但较完好地保留了花瓣的外形特征. 基于像素的MSE损失虽然抵消了感知损失与对抗损失在平滑区域产生的噪声,但对重建图像高频信息的恢复效果会造成影响,如图7 的放大区域,与SRGAN[15 ] 和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
... [14 ]的结果更加真实和自然的毛线纹理;其次,本文采用基于patchGAN[20 ] 的对抗损失和基于像素的MSE损失,可以有效减少生成图像中平滑区域的高频噪声,与SRGAN的结果相比,能够更好地保留图像中小物体的形状和轮廓,例如图6 所示的图像右上角的金属花瓣,从SRGAN的重建图像中可以看到高频噪声极大地破坏了花瓣的形状,本文的重建图像虽然丢失了一些细小的边,但较完好地保留了花瓣的外形特征. 基于像素的MSE损失虽然抵消了感知损失与对抗损失在平滑区域产生的噪声,但对重建图像高频信息的恢复效果会造成影响,如图7 的放大区域,与SRGAN[15 ] 和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
... 和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
... 如表2 所示为SRGAN[15 ] 、文献[14 ]方法及文献[17 ]方法在Set5、Set14和BSD100测试集上的平均PSNR和平均SSIM评分. 由于使用MSE损失作为目标函数的一部分,本文方法与SRGAN和文献[14 ]方法相比,具有更高的PSNR和SSIM评分. 本文方法通过使用联合损失函数,更好地平衡了重建图像的客观评价和感知质量. 本文方法的PSNR评分虽然低于文献[17 ],但重建图像的结构相似度(SSIM)更高. 综上所述,本文提出的基于生成对抗的多尺度特征映射网络无论在PSNR和SSIM等客观量化标准还是主观视觉效果上,都有优于其他方法的评价和表现. ...
... ]方法在Set5、Set14和BSD100测试集上的平均PSNR和平均SSIM评分. 由于使用MSE损失作为目标函数的一部分,本文方法与SRGAN和文献[14 ]方法相比,具有更高的PSNR和SSIM评分. 本文方法通过使用联合损失函数,更好地平衡了重建图像的客观评价和感知质量. 本文方法的PSNR评分虽然低于文献[17 ],但重建图像的结构相似度(SSIM)更高. 综上所述,本文提出的基于生成对抗的多尺度特征映射网络无论在PSNR和SSIM等客观量化标准还是主观视觉效果上,都有优于其他方法的评价和表现. ...
... 在4倍放大因子下与文献[14 ]方法、SRGAN以及文献[17 ]方法的平均PSNR和平均SSIM对比 ...
... Average PSNRs and SSIMs compared with reference [14 ],SRGAN and reference [17 ] method (4×) ...
... 文献[
14 ]方法
27.09, 0.768 24.99, 0.673 24.95, 0.631 25.68, 0.691 SRGAN[15 ] 29.36, 0.833 25.96, 0.696 25.20, 0.642 26.84, 0.724 文献[17 ]方法 31.30, 0.877 27.72, 0.755 26.65, 0.703 28.56, 0.778 本文方法(EPA) 29.67, 0.887 26.63, 0.801 26.16, 0.774 27.49, 0.821 3. 结 语 本文结合生成对抗网络这一当前深度学习领域的研究热点和图像风格迁移问题中的感知损失,用于解决图像超分辨率重建问题. 针对SRCNN在网络结构和损失函数方面的不足,提出基于多尺度特征映射网络的图像超分辨率重建方法. 该网络使用MSE损失、感知损失和对抗损失的加权和作为目标函数进行优化,对重建图像的客观量化评价和主观视觉评价具有明显的提升. 本文提出的多尺度特征映射网络与SRCNN相比具有更深的网络结构,能够学习感受野更大的深层特征,提高特征利用率. 为了解决基于像素的MSE损失难以恢复图像高频信息的问题,分析MSE损失、感知损失及对抗损失这3种常用于图像超分辨率重建任务中的损失函数,联合MSE损失、感知损失和对抗损失训练图像生成网络,重建出更高质量的HR图像. 本文通过实验,进一步验证了本文方法在恢复重建图像的感知质量方面的良好性能. ...
10
... 相关研究人员通过使用更复杂的损失函数来更好地重建图像的高频信息. 受文献[13 ]的启发,Johnson等[14 ] 使用感知损失训练网络,重建图像具有更加清晰的边缘. Ledig等[15 ] 基于生成对抗网络(GAN)[16 ] 提出的SRGAN算法,结合对抗损失与感知损失,令重建图像具有更加逼真的视觉效果,但重建图像的PSNR比其他方法[9 ] 低. 为了提高SRGAN的重建图像在PSNR评分上的不足,Deng[17 ] 在SRGAN的基础上,结合风格迁移的方法,通过取阈值灵活调整重建图像的客观评分和感知质量. ...
... 本文受上述一些方法[15 ] 的启发,分别从网络结构和损失函数两方面对SRCNN提出以下改进:1)构建一个23层的编码器-解码器网络,相较于SRCNN,该网络具有更大的感受野,能够获取更加复杂的图像特征,学习更加丰富的图像信息;2)采用多尺度特征映射模块学习不同尺度的LR图像特征与HR图像特征之间的映射关系,进一步增大了网络的感受野,有效提高了重建过程中特征的利用率;3)本文联合优化逐像素损失、感知损失和对抗损失函数,重建图像在低频内容保留、高频边缘锐化以及局部纹理恢复等方面均具有较均衡的良好性能和表现. ...
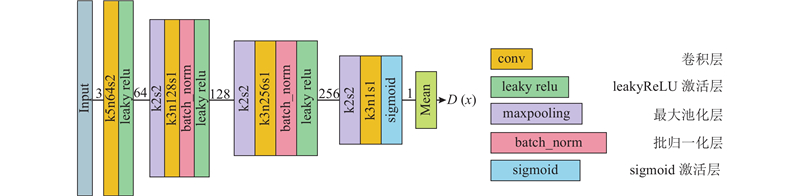
... 本文的判别器网络与Ledig等[15 ] 的判别器网络不同,后者是一个标准的二元分类网络,其网络结构包含多个卷积层构成的特征提取网络和由全连接层构成的分类器网络,网络参数量由输入图像的尺寸决定,大尺寸的输入有更多的参数和更大的运算量. 一旦输入图像的尺寸改变,全连接层的参数设置也要进行相应的改变,这大大降低了网络的灵活性. 本文参考Isola等[20 ] 提出的基于图像块的判别器(patchGAN),设计6层(卷积层+批归一化层)的小规模全卷积网络作为判别器网络. 网络对小尺寸的图像块进行运算,与SRGAN的判别器相比,大大减少了参数数量和运算量. 如图2 所示,该判别器网络由卷积层、批归一化层、激活层和最大池化层交替构成,卷积层和最大池化层的步幅均设置为2,以增大输出特征的感受野,批归一化层的使用可以提高判别器网络的泛化能力. Isola等[20 ] 利用实验验证,当图像块的尺寸大于70时,生成图像的效果已经十分接近对完整图像进行判定的结果,本文判别器网络的设计遵循这一设定. ...
... Ledig等[15 ] 提出的SRGAN结合对抗损失与感知损失,虽然生成了具有高频纹理细节的逼真图像,但重建图像的平滑区域会受到锐化纹理的影响. Sajjadi等[21 ] 对这一问题进行分析,提出加入纹理损失[13 ] 改善生成图像质量的方法. 本文采用的判别器由大小为70×70的图像块进行训练,学习得到的是图像的局部纹理分布,因此由式(5)定义的对抗损失可以看作是纹理损失的一种[22 ] . 此外,本文加入的MSE损失因其对异常数值的敏感,能够有效地降低平滑区域产生的高频噪声. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 为了分析MSE损失、感知损失与对抗损失对重建图像质量的影响,设计结合感知损失与对抗损失的高频损失函数(PA)和结合MSE损失、感知损失以及对抗损失的综合损失函数(EPA),分别对网络进行优化,并将综合损失的实验结果与文献[14 ]方法、SRGAN[15 ] 、文献[17 ]方法进行比较. 如图5 所示为设计的网络基于不同损失函数,对4倍下采样图像的超分辨率重建结果. 可以看出,使用相同的图像生成网络,基于MSE损失的重建模型生成的图像缺少清晰的边缘和纹理,整体表现模糊;基于高频损失(PA)的网络模型虽然生成了含有丰富细节和纹理的图像,但一些平滑区域被尖锐的噪声所影响,如图5 中人脸的平滑区域存在黑色的斑点状噪声;使用综合损失(EPA)对网络进行优化,生成的图像具有清晰的轮廓和丰富的纹理,能够有效减少高频损失结果中出现的噪声. ...
... 本文通过与文献[14 ]方法、SRGAN[15 ] 在4倍放大因子上的重建结果进行对比,分析和验证了本文提出的算法在超分辨率重建任务中的优越性能. 各方法的重建结果如图6 ~8 所示. 可以看出,提出的方法对图像中边缘、形状和纹理的恢复都有较好的效果:首先,与文献[14 ]结果进行比较可以发现,本文方法通过使用对抗损失能够更好地重建局部纹理,例如在图8 中,通过本文方法重建的baby图像,能够生成比Johnson等[14 ] 的结果更加真实和自然的毛线纹理;其次,本文采用基于patchGAN[20 ] 的对抗损失和基于像素的MSE损失,可以有效减少生成图像中平滑区域的高频噪声,与SRGAN的结果相比,能够更好地保留图像中小物体的形状和轮廓,例如图6 所示的图像右上角的金属花瓣,从SRGAN的重建图像中可以看到高频噪声极大地破坏了花瓣的形状,本文的重建图像虽然丢失了一些细小的边,但较完好地保留了花瓣的外形特征. 基于像素的MSE损失虽然抵消了感知损失与对抗损失在平滑区域产生的噪声,但对重建图像高频信息的恢复效果会造成影响,如图7 的放大区域,与SRGAN[15 ] 和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
... [15 ]和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
... 如表2 所示为SRGAN[15 ] 、文献[14 ]方法及文献[17 ]方法在Set5、Set14和BSD100测试集上的平均PSNR和平均SSIM评分. 由于使用MSE损失作为目标函数的一部分,本文方法与SRGAN和文献[14 ]方法相比,具有更高的PSNR和SSIM评分. 本文方法通过使用联合损失函数,更好地平衡了重建图像的客观评价和感知质量. 本文方法的PSNR评分虽然低于文献[17 ],但重建图像的结构相似度(SSIM)更高. 综上所述,本文提出的基于生成对抗的多尺度特征映射网络无论在PSNR和SSIM等客观量化标准还是主观视觉效果上,都有优于其他方法的评价和表现. ...
... Average PSNRs and SSIMs compared with reference [
14 ],SRGAN and reference [
17 ] method (4×)
Tab.2 SR方法 PSNR/dB, SSIM Set5 Set14 BSD100 平均值 文献[14 ]方法 27.09, 0.768 24.99, 0.673 24.95, 0.631 25.68, 0.691 SRGAN[15 ] 29.36, 0.833 25.96, 0.696 25.20, 0.642 26.84, 0.724 文献[17 ]方法 31.30, 0.877 27.72, 0.755 26.65, 0.703 28.56, 0.778 本文方法(EPA) 29.67, 0.887 26.63, 0.801 26.16, 0.774 27.49, 0.821
3. 结 语 本文结合生成对抗网络这一当前深度学习领域的研究热点和图像风格迁移问题中的感知损失,用于解决图像超分辨率重建问题. 针对SRCNN在网络结构和损失函数方面的不足,提出基于多尺度特征映射网络的图像超分辨率重建方法. 该网络使用MSE损失、感知损失和对抗损失的加权和作为目标函数进行优化,对重建图像的客观量化评价和主观视觉评价具有明显的提升. 本文提出的多尺度特征映射网络与SRCNN相比具有更深的网络结构,能够学习感受野更大的深层特征,提高特征利用率. 为了解决基于像素的MSE损失难以恢复图像高频信息的问题,分析MSE损失、感知损失及对抗损失这3种常用于图像超分辨率重建任务中的损失函数,联合MSE损失、感知损失和对抗损失训练图像生成网络,重建出更高质量的HR图像. 本文通过实验,进一步验证了本文方法在恢复重建图像的感知质量方面的良好性能. ...
2
... 相关研究人员通过使用更复杂的损失函数来更好地重建图像的高频信息. 受文献[13 ]的启发,Johnson等[14 ] 使用感知损失训练网络,重建图像具有更加清晰的边缘. Ledig等[15 ] 基于生成对抗网络(GAN)[16 ] 提出的SRGAN算法,结合对抗损失与感知损失,令重建图像具有更加逼真的视觉效果,但重建图像的PSNR比其他方法[9 ] 低. 为了提高SRGAN的重建图像在PSNR评分上的不足,Deng[17 ] 在SRGAN的基础上,结合风格迁移的方法,通过取阈值灵活调整重建图像的客观评分和感知质量. ...
... 式中:D (G (I LR ,θ ))为判别器判定生成图像为真实图像的概率,为了方便梯度的计算,使用−log D (G (I LR ,θ ))代替log [1−D (G (I LR ,θ ))][16 ] . ...
Enhancing image quality via style transfer for single image super-resolution
8
2018
... 相关研究人员通过使用更复杂的损失函数来更好地重建图像的高频信息. 受文献[13 ]的启发,Johnson等[14 ] 使用感知损失训练网络,重建图像具有更加清晰的边缘. Ledig等[15 ] 基于生成对抗网络(GAN)[16 ] 提出的SRGAN算法,结合对抗损失与感知损失,令重建图像具有更加逼真的视觉效果,但重建图像的PSNR比其他方法[9 ] 低. 为了提高SRGAN的重建图像在PSNR评分上的不足,Deng[17 ] 在SRGAN的基础上,结合风格迁移的方法,通过取阈值灵活调整重建图像的客观评分和感知质量. ...
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 为了分析MSE损失、感知损失与对抗损失对重建图像质量的影响,设计结合感知损失与对抗损失的高频损失函数(PA)和结合MSE损失、感知损失以及对抗损失的综合损失函数(EPA),分别对网络进行优化,并将综合损失的实验结果与文献[14 ]方法、SRGAN[15 ] 、文献[17 ]方法进行比较. 如图5 所示为设计的网络基于不同损失函数,对4倍下采样图像的超分辨率重建结果. 可以看出,使用相同的图像生成网络,基于MSE损失的重建模型生成的图像缺少清晰的边缘和纹理,整体表现模糊;基于高频损失(PA)的网络模型虽然生成了含有丰富细节和纹理的图像,但一些平滑区域被尖锐的噪声所影响,如图5 中人脸的平滑区域存在黑色的斑点状噪声;使用综合损失(EPA)对网络进行优化,生成的图像具有清晰的轮廓和丰富的纹理,能够有效减少高频损失结果中出现的噪声. ...
... 如表2 所示为SRGAN[15 ] 、文献[14 ]方法及文献[17 ]方法在Set5、Set14和BSD100测试集上的平均PSNR和平均SSIM评分. 由于使用MSE损失作为目标函数的一部分,本文方法与SRGAN和文献[14 ]方法相比,具有更高的PSNR和SSIM评分. 本文方法通过使用联合损失函数,更好地平衡了重建图像的客观评价和感知质量. 本文方法的PSNR评分虽然低于文献[17 ],但重建图像的结构相似度(SSIM)更高. 综上所述,本文提出的基于生成对抗的多尺度特征映射网络无论在PSNR和SSIM等客观量化标准还是主观视觉效果上,都有优于其他方法的评价和表现. ...
... ]方法相比,具有更高的PSNR和SSIM评分. 本文方法通过使用联合损失函数,更好地平衡了重建图像的客观评价和感知质量. 本文方法的PSNR评分虽然低于文献[17 ],但重建图像的结构相似度(SSIM)更高. 综上所述,本文提出的基于生成对抗的多尺度特征映射网络无论在PSNR和SSIM等客观量化标准还是主观视觉效果上,都有优于其他方法的评价和表现. ...
... 在4倍放大因子下与文献[14 ]方法、SRGAN以及文献[17 ]方法的平均PSNR和平均SSIM对比 ...
... Average PSNRs and SSIMs compared with reference [14 ],SRGAN and reference [17 ] method (4×) ...
... 文献[
17 ]方法
31.30, 0.877 27.72, 0.755 26.65, 0.703 28.56, 0.778 本文方法(EPA) 29.67, 0.887 26.63, 0.801 26.16, 0.774 27.49, 0.821 3. 结 语 本文结合生成对抗网络这一当前深度学习领域的研究热点和图像风格迁移问题中的感知损失,用于解决图像超分辨率重建问题. 针对SRCNN在网络结构和损失函数方面的不足,提出基于多尺度特征映射网络的图像超分辨率重建方法. 该网络使用MSE损失、感知损失和对抗损失的加权和作为目标函数进行优化,对重建图像的客观量化评价和主观视觉评价具有明显的提升. 本文提出的多尺度特征映射网络与SRCNN相比具有更深的网络结构,能够学习感受野更大的深层特征,提高特征利用率. 为了解决基于像素的MSE损失难以恢复图像高频信息的问题,分析MSE损失、感知损失及对抗损失这3种常用于图像超分辨率重建任务中的损失函数,联合MSE损失、感知损失和对抗损失训练图像生成网络,重建出更高质量的HR图像. 本文通过实验,进一步验证了本文方法在恢复重建图像的感知质量方面的良好性能. ...
1
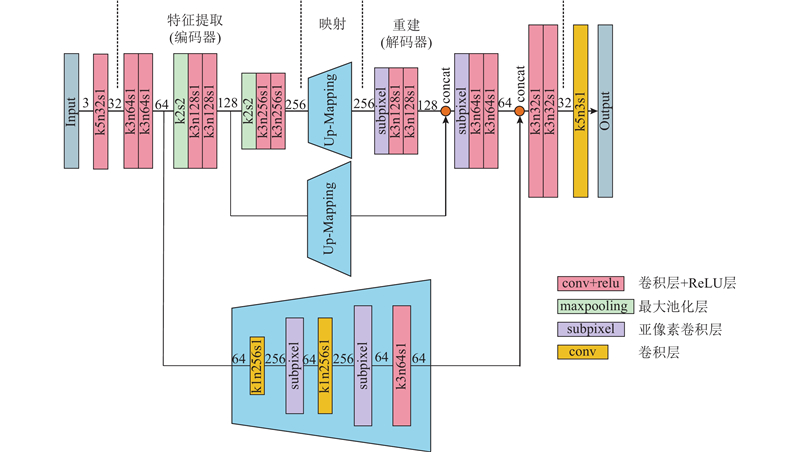
... 多尺度特征映射模块由3个结构相似的子模块组成,分别提取编码器第2、4和6个卷积层的输出作为输入,每个子模块由卷积层和亚像素卷积层[18 ] 构成. 亚像素卷积层代替SRCNN中的双三次插值放大,相较于具有固定公式的双三次插值,亚像素卷积层直接将低分辨率(LR)特征映射为高分辨率(HR)特征,可以更灵活地学习上采样算法,并与卷积层共同工作,将上采样处理与特征映射结合. 3个独立子模块分别处理3个尺度上的LR特征,这些特征对应不同大小的感受野,包含的图像信息可以更加多样化. ...
1
... Reed等[19 -20 ] 的方法表明,基于生成对抗的网络框架有利于生成更加逼真的图像. 本文将设计的多尺度特征映射网络作为生成器,构建基于生成对抗的算法框架. 整体框架由生成器G 和判别器D 组成,其中生成器通过学习LR图像I LR 与HR图像I HR 之间的映射关系G ∶I LR →I HR ,实现LR图像与HR图像端到端的转换,判别器用于对输入图像是否为真实图像进行判定. 在训练过程中,使用大量的LR与HR图像对作为训练样本来训练G ,使其生成十分近似真实HR图像的重建图像;使用预先标注的真实HR图像和G 生成的重建图像训练D ,以学习真实图像与生成图像的差距,从而进行区分. 整体框架的优化目标可以表示为 ...
4
... Reed等[19 -20 ] 的方法表明,基于生成对抗的网络框架有利于生成更加逼真的图像. 本文将设计的多尺度特征映射网络作为生成器,构建基于生成对抗的算法框架. 整体框架由生成器G 和判别器D 组成,其中生成器通过学习LR图像I LR 与HR图像I HR 之间的映射关系G ∶I LR →I HR ,实现LR图像与HR图像端到端的转换,判别器用于对输入图像是否为真实图像进行判定. 在训练过程中,使用大量的LR与HR图像对作为训练样本来训练G ,使其生成十分近似真实HR图像的重建图像;使用预先标注的真实HR图像和G 生成的重建图像训练D ,以学习真实图像与生成图像的差距,从而进行区分. 整体框架的优化目标可以表示为 ...
... 本文的判别器网络与Ledig等[15 ] 的判别器网络不同,后者是一个标准的二元分类网络,其网络结构包含多个卷积层构成的特征提取网络和由全连接层构成的分类器网络,网络参数量由输入图像的尺寸决定,大尺寸的输入有更多的参数和更大的运算量. 一旦输入图像的尺寸改变,全连接层的参数设置也要进行相应的改变,这大大降低了网络的灵活性. 本文参考Isola等[20 ] 提出的基于图像块的判别器(patchGAN),设计6层(卷积层+批归一化层)的小规模全卷积网络作为判别器网络. 网络对小尺寸的图像块进行运算,与SRGAN的判别器相比,大大减少了参数数量和运算量. 如图2 所示,该判别器网络由卷积层、批归一化层、激活层和最大池化层交替构成,卷积层和最大池化层的步幅均设置为2,以增大输出特征的感受野,批归一化层的使用可以提高判别器网络的泛化能力. Isola等[20 ] 利用实验验证,当图像块的尺寸大于70时,生成图像的效果已经十分接近对完整图像进行判定的结果,本文判别器网络的设计遵循这一设定. ...
... [20 ]利用实验验证,当图像块的尺寸大于70时,生成图像的效果已经十分接近对完整图像进行判定的结果,本文判别器网络的设计遵循这一设定. ...
... 本文通过与文献[14 ]方法、SRGAN[15 ] 在4倍放大因子上的重建结果进行对比,分析和验证了本文提出的算法在超分辨率重建任务中的优越性能. 各方法的重建结果如图6 ~8 所示. 可以看出,提出的方法对图像中边缘、形状和纹理的恢复都有较好的效果:首先,与文献[14 ]结果进行比较可以发现,本文方法通过使用对抗损失能够更好地重建局部纹理,例如在图8 中,通过本文方法重建的baby图像,能够生成比Johnson等[14 ] 的结果更加真实和自然的毛线纹理;其次,本文采用基于patchGAN[20 ] 的对抗损失和基于像素的MSE损失,可以有效减少生成图像中平滑区域的高频噪声,与SRGAN的结果相比,能够更好地保留图像中小物体的形状和轮廓,例如图6 所示的图像右上角的金属花瓣,从SRGAN的重建图像中可以看到高频噪声极大地破坏了花瓣的形状,本文的重建图像虽然丢失了一些细小的边,但较完好地保留了花瓣的外形特征. 基于像素的MSE损失虽然抵消了感知损失与对抗损失在平滑区域产生的噪声,但对重建图像高频信息的恢复效果会造成影响,如图7 的放大区域,与SRGAN[15 ] 和文献[14 ]方法相比,本文方法对帽檐的边缘恢复较平滑. 这是由于MSE损失是针对图像全局内容的运算,在减轻SRGAN中尖锐噪声的同时,会对高频纹理和边缘的恢复产生一定影响. 本文方法的重建图像与SRCNN等仅使用MSE损失的方法相比,表现出更清晰的边缘和纹理. ...
1
... Ledig等[15 ] 提出的SRGAN结合对抗损失与感知损失,虽然生成了具有高频纹理细节的逼真图像,但重建图像的平滑区域会受到锐化纹理的影响. Sajjadi等[21 ] 对这一问题进行分析,提出加入纹理损失[13 ] 改善生成图像质量的方法. 本文采用的判别器由大小为70×70的图像块进行训练,学习得到的是图像的局部纹理分布,因此由式(5)定义的对抗损失可以看作是纹理损失的一种[22 ] . 此外,本文加入的MSE损失因其对异常数值的敏感,能够有效地降低平滑区域产生的高频噪声. ...
1
... Ledig等[15 ] 提出的SRGAN结合对抗损失与感知损失,虽然生成了具有高频纹理细节的逼真图像,但重建图像的平滑区域会受到锐化纹理的影响. Sajjadi等[21 ] 对这一问题进行分析,提出加入纹理损失[13 ] 改善生成图像质量的方法. 本文采用的判别器由大小为70×70的图像块进行训练,学习得到的是图像的局部纹理分布,因此由式(5)定义的对抗损失可以看作是纹理损失的一种[22 ] . 此外,本文加入的MSE损失因其对异常数值的敏感,能够有效地降低平滑区域产生的高频噪声. ...
Image super-resolution via sparse representation
1
2010
... 训练集的选取对于实验结果具有很大的影响. 基于学习的超分辨率重建方法常常选择Image91[23 ] 作为训练集,但对于深层网络模型而言,这一训练集数据过少,训练过程中可能出现过拟合问题;提出的生成器网络内部需要对输入图像进行4倍下采样操作,若输入图像尺寸太小会影响生成器以及计算感知损失时的特征提取,影响网络的性能,所以需要一个数量足够多、尺寸足够大的图像集合作为训练集. 采用NTIRE2017[24 ] 中提供的DIV2K训练集,该训练集由1 000幅RGB图像组成,其中训练集包含800幅图像,验证集和测试集各100幅图像,所有图像至少在一个轴(水平或垂直)上包含2 040个像素. 先将DIV2K中的800幅训练图像顺时针分别旋转0°、90°、180°和270°,并进行镜像操作,获取6 400幅图像. 按照尺寸为400×400、步长为200×200,对这6 400幅图像进行裁剪,最终得到329 184个子图像. ...
1
... 训练集的选取对于实验结果具有很大的影响. 基于学习的超分辨率重建方法常常选择Image91[23 ] 作为训练集,但对于深层网络模型而言,这一训练集数据过少,训练过程中可能出现过拟合问题;提出的生成器网络内部需要对输入图像进行4倍下采样操作,若输入图像尺寸太小会影响生成器以及计算感知损失时的特征提取,影响网络的性能,所以需要一个数量足够多、尺寸足够大的图像集合作为训练集. 采用NTIRE2017[24 ] 中提供的DIV2K训练集,该训练集由1 000幅RGB图像组成,其中训练集包含800幅图像,验证集和测试集各100幅图像,所有图像至少在一个轴(水平或垂直)上包含2 040个像素. 先将DIV2K中的800幅训练图像顺时针分别旋转0°、90°、180°和270°,并进行镜像操作,获取6 400幅图像. 按照尺寸为400×400、步长为200×200,对这6 400幅图像进行裁剪,最终得到329 184个子图像. ...
1
... 对网络进行训练时,网络批量处理8幅子图像,且通过随机裁剪的方式从每一幅400×400的子图像中获取16个128×128的子块,因此网络每批次处理128个子块. 网络使用Adam算法进行优化,总迭代次数为100 000次. 初始学习率设置为10−4 ,网络每迭代20 000次,则学习率衰减为原来的0.8倍. 网络采用微软亚洲研究院提出的MSRA算法[25 ] 进行参数初始化,损失函数的参数α 和β 经交叉验证分别设为0.1和0.001. 本文方法基于PyTorch框架进行实验,实验的硬件参数如下:Intel Core i7-4790K 4.00 GHz,NVIDIA GTX Titan X GPU. ...
3
... 主要研究图像超分辨率在4倍放大因子上的重建效果,在Set5、Set14及BSD100测试集上进行实验,从主观视觉评价和客观量化指标两方面,与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 、文献[10 ]方法、文献[14 ]方法、SRGAN[15 ] 及文献[17 ]方法进行对比. 采用峰值信噪比(PSNR)和结构相似度(SSIM),作为图像质量的客观量化标准. ...
... 训练基于MSE损失的多尺度特征映射网络模型,用于分析网络结构的性能. 如表1 所示为本文方法与双三次插值、A+[26 ] 、SRCNN[6 ] 、FSRCNN[8 ] 和文献[10 ]方法的PSNR和SSIM对比结果. 本文方法在常用测试集Set5、Set14和BSD100上的平均PSNR与其他5种方法相比,分别提高了2.10、0.66、0.53、0.40、0.05 dB,平均SSIM分别提高了0.069、0.023、0.022、0.02、0.005. ...
... Average PSNRs and SSIMs compared with other SR methods on Set5,Set14 and BSD100 (4×)
Tab.1 SR方法 PSNR/dB, SSIM Set5 Set14 BSD100 平均值 双三次插值 28.43, 0.810 25.77, 0.703 25.98, 0.671 26.73, 0.728 A+[26 ] 30.30, 0.859 27.38, 0.752 26.82, 0.710 28.17, 0.774 SRCNN[6 ] 30.49, 0.863 27.50, 0.751 26.91, 0.712 28.30, 0.775 FSRCNN[8 ] 30.71, 0.865 27.60, 0.753 26.97, 0.713 28.43, 0.777 文献[10 ]方法 30.80, 0.873 28.60, 0.792 26.96, 0.711 28.78, 0.792 本文方法(MSE) 31.32, 0.881 27.78, 0.773 27.40, 0.736 28.83, 0.797
如图4 所示为利用本文方法和其他方法,分别对Set5、Set14和BSD100中经4倍双三次下采样的LR图像进行超分辨率重建的结果. 利用提出的多尺度特征映射网络能够增大感受野的尺寸,提取更复杂的特征,增强局部特征间的相关性,增强网络对特征的利用率,因而重建图像表现出了更加清晰的轮廓和边缘,具有很好的视觉效果. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}