[2]
王素玉, 沈兰荪 智能视觉监控技术研究进展
[J]. 中国图象图形学报 , 2008 , 36 (5 ): 962 - 968
[本文引用: 1]
WANG Su-yu, SHEN Lan-sun intelligent visual surveillance technology: a survey
[J]. Journal of Image and Graphics , 2008 , 36 (5 ): 962 - 968
[本文引用: 1]
[3]
乔传标, 王素玉, 卓力, 等 智能视觉监控中的目标检测与跟踪技术
[J]. 测控技术 , 2008 , 27 (5 ): 22 - 24
DOI:10.3969/j.issn.1000-8829.2008.05.007
[本文引用: 1]
QIAO Chuan-biao, WANG Su-yu, ZHUO Li, et al Object detection and tracking for intelligent video surveillance
[J]. Measurement and Control Technology , 2008 , 27 (5 ): 22 - 24
DOI:10.3969/j.issn.1000-8829.2008.05.007
[本文引用: 1]
[4]
PAPAGEORGIOU C, POGGIO T A trainable system for object detection
[J]. International Journal of Computer Vision , 2000 , 38 (1 ): 15 - 33
DOI:10.1023/A:1008162616689
[本文引用: 1]
[6]
VIOLA P, JONES M J, SNOW D Detecting pedestrians using patterns of motion and appearance
[J]. International Journal of Computer Vision , 2005 , 63 (2 ): 153 - 161
DOI:10.1007/s11263-005-6644-8
[7]
VIOLA P, JONES M J, SNOW D. Detecting pedestrians using patterns of motion and appearance [C] // 9th IEEE International Conference on Computer Vision . Nice: IEEE, 2003: 734-741.
[8]
DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C] // Computer Vision and Pattern Recognition . San Diego: IEEE, 2005: 886-893.
[本文引用: 1]
[9]
WANG X Y, HAN T X, YAN S. An HOG-LBP human detector with partial occlusion handling [C] // 2009 IEEE 12th International Conference on Computer Vision . Kyoto: IEEE, 2009: 32-39.
[本文引用: 1]
[10]
FREUND Y, SCHAPIRE R E. Experiments with a new boosting algorithm [C] // International Conference on Machine Learning . Bari: ICML, 1996: 148-156.
[本文引用: 1]
[11]
GIRSHICK R B. Fast R-CNN [C] // IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440-1448.
[本文引用: 1]
[12]
GIRSHICK R B, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C] // IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 2]
[13]
UIJLINGS J R R, VANDESANDE K E A, GEVERS T, et al Selective search for object recognition
[J]. International Journal of Computer Vision , 2013 , 104 (2 ): 154 - 171
DOI:10.1007/s11263-013-0620-5
[本文引用: 1]
[14]
REN S Q, HE K M, GIRSHICK R B, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C] // Neural Information Processing Systems . Montreal: NIPS, 2015: 91-99.
[本文引用: 1]
[15]
LIU W, ANGUELOV D, ERHAN D. SSD: single shot multibox detector [C] // European Conference on Computer Vision . Amsterdam: ECCV, 2016: 21-37.
[本文引用: 1]
[16]
JOSEPH R, ALI F. YOLO9000: better, faster, stronger [C] // IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6517-6525.
[本文引用: 5]
[17]
SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions [C] // IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 1-9.
[本文引用: 1]
[18]
SZEGEDY C, IOFFE S, VANHOUCKE V. Inception-v4, Inception-ResNet and the impact of residual connections on learning [C] // Association for the Advancement of Artificial Intelligence . San Francisco: AAAI, 2017: 4278-4284
[19]
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE 2016: 2818-2826.
[本文引用: 1]
[20]
AHMED E, JONES M and MARKS T K. An improved deep learning architecture for person re-identification [C] // IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3908-3916.
[本文引用: 1]
[21]
KONG T, YAO A B, CHEN Y R, et al. HyperNet: towards accurate region proposal generation and joint object detection [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 845-853.
[本文引用: 1]
[22]
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C] // International Conference on Machine Learning . Lille: ICML, 2015: 448-456.
[本文引用: 1]
[23]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C] // IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431-3440.
[本文引用: 1]
[24]
ESS A, LEIBE B, VAN GOOL L. Depth and appearance for mobile scene analysis [C] // IEEE International Conference on Computer Vision . Rio de Janeiro: IEEE, 2007: 1-8.
[本文引用: 1]
[25]
NAM W, DOLLAR P, HAN J H. Local decorrelation for improved pedestrian detection [C] // Neural Information Processing Systems . Montreal: NIPS, 2014: 424-432.
[本文引用: 4]
[26]
LIM J, ZITNICK C, DOLLAR P. Sketch tokens: a learned mid-level representation for contour and object detection [C] // IEEE Conference on Computer Vision and Pattern Recognition . Portland: IEEE, 2013: 3158-3165.
[本文引用: 3]
[27]
BENENSON R, MATHIAS M, TUYTELAARS T. Seeking the strongest rigid detector [C] // IEEE Conference on Computer Vision and Pattern Recognition . Portland: IEEE, 2013: 3666-3673.
[本文引用: 3]
[28]
MARIN J, VAZQUEZ D, LOPEZ A, et al. Random forests of local experts for pedestrian detection [C] // IEEE International Conference on Computer Vision . Sydney: IEEE, 2013: 2592-2599.
[本文引用: 4]
[29]
LI J N, LIANG X D, SHEN S M, et al Scale-aware fast R-CNN for pedestrian detection
[J]. IEEE Transactions on Multimedia , 2018 , 20 (4 ): 985 - 996
[本文引用: 4]
行人检测系统研究新进展及关键技术展望
1
2008
... 行人检测是目标检测领域的一个重要分支,作为汽车安全[1 ] 、视频监控[2 -3 ] 等现实应用的关键部分,行人检测技术受到了大量关注. 当前行人检测主要存在两类算法:基于机器学习的传统行人检测算法,基于深度学习的行人检测算法. ...
行人检测系统研究新进展及关键技术展望
1
2008
... 行人检测是目标检测领域的一个重要分支,作为汽车安全[1 ] 、视频监控[2 -3 ] 等现实应用的关键部分,行人检测技术受到了大量关注. 当前行人检测主要存在两类算法:基于机器学习的传统行人检测算法,基于深度学习的行人检测算法. ...
智能视觉监控技术研究进展
1
2008
... 行人检测是目标检测领域的一个重要分支,作为汽车安全[1 ] 、视频监控[2 -3 ] 等现实应用的关键部分,行人检测技术受到了大量关注. 当前行人检测主要存在两类算法:基于机器学习的传统行人检测算法,基于深度学习的行人检测算法. ...
智能视觉监控技术研究进展
1
2008
... 行人检测是目标检测领域的一个重要分支,作为汽车安全[1 ] 、视频监控[2 -3 ] 等现实应用的关键部分,行人检测技术受到了大量关注. 当前行人检测主要存在两类算法:基于机器学习的传统行人检测算法,基于深度学习的行人检测算法. ...
智能视觉监控中的目标检测与跟踪技术
1
2008
... 行人检测是目标检测领域的一个重要分支,作为汽车安全[1 ] 、视频监控[2 -3 ] 等现实应用的关键部分,行人检测技术受到了大量关注. 当前行人检测主要存在两类算法:基于机器学习的传统行人检测算法,基于深度学习的行人检测算法. ...
智能视觉监控中的目标检测与跟踪技术
1
2008
... 行人检测是目标检测领域的一个重要分支,作为汽车安全[1 ] 、视频监控[2 -3 ] 等现实应用的关键部分,行人检测技术受到了大量关注. 当前行人检测主要存在两类算法:基于机器学习的传统行人检测算法,基于深度学习的行人检测算法. ...
A trainable system for object detection
1
2000
... 基于机器学习的传统行人检测算法[4 -9 ] 使用方向梯度直方图(histogram of oriented gradient,HOG)、局部二值模式(local binary pattern,LBP)、Haar-like等人工设计的特征训练SVM或者Adaboost算法[10 ] 的级联分类器实现. 这类算法在一些场景简单的行人检测任务中有较好的检测准确率,然而在商场、街道等复杂场景中,由于存在姿态变化、遮挡、背景复杂等因素,人工难以设计一种具有极高鲁棒性的特征,检测效果往往不理想. ...
Robust real-time face detection
2004
Detecting pedestrians using patterns of motion and appearance
2005
1
... INRIA行人检测数据集[8 ] :由法国国家信息与自动化研究所公开,该数据集训练样本包括614个正样本(包含2 416个行人)和1 218个负样本,测试样本包括288个正样本(包含1 126个行人)和453个负样本,如图4 所示.该数据集训练样本包括614个正样本(包含2 416个行人)和1 218个负样本,测试样本包括288个正样本(包含1 126个行人)和453个负样本. 图片中人体大部分为站立姿势且高度大于100个像素. ...
1
... 基于机器学习的传统行人检测算法[4 -9 ] 使用方向梯度直方图(histogram of oriented gradient,HOG)、局部二值模式(local binary pattern,LBP)、Haar-like等人工设计的特征训练SVM或者Adaboost算法[10 ] 的级联分类器实现. 这类算法在一些场景简单的行人检测任务中有较好的检测准确率,然而在商场、街道等复杂场景中,由于存在姿态变化、遮挡、背景复杂等因素,人工难以设计一种具有极高鲁棒性的特征,检测效果往往不理想. ...
1
... 基于机器学习的传统行人检测算法[4 -9 ] 使用方向梯度直方图(histogram of oriented gradient,HOG)、局部二值模式(local binary pattern,LBP)、Haar-like等人工设计的特征训练SVM或者Adaboost算法[10 ] 的级联分类器实现. 这类算法在一些场景简单的行人检测任务中有较好的检测准确率,然而在商场、街道等复杂场景中,由于存在姿态变化、遮挡、背景复杂等因素,人工难以设计一种具有极高鲁棒性的特征,检测效果往往不理想. ...
1
... 基于深度学习的行人检测算法的特征由计算机学习得到,这类特征同时具备轮廓、颜色、纹理等多种信息,具有极高的语义特征表达能力和鲁棒性. 近几年,许多基于深度学习的通用目标检测算法被提出. Girshick等[11 ] 在RCNN算法[12 ] 的基础上提出Fast R-CNN算法,实现了准确率和效率的大幅提升,该算法将每个用于特征提取的候选区域映射到卷积特征上而不是从原图直接获取,大幅减少了卷积运算,有效提升了候选区域特征的提取速度. 然而,Fast R-CNN仍没有解决Selective Search算法[13 ] 选取候选区域慢的问题. 针对这个问题,Ren等[14 ] 提出了Faster-RCNN算法,设计了区域生成网络(region proposal network,RPN)快速选取候选区域,实现了检测速度和精度的进一步提升,在Pascal VOC数据集的测试中准确率达到了76.4%,速度达到了2 帧/s.为了实现具备较高准确率和实时检测效率的通用目标检测,候选区域特征提取部分的计算量必须减少.Liu等[15 ] 提出了SSD算法,Joseph等[16 ] 提出了YOLOv2算法,实现了较高准确率下的实时目标检测.这2种算法的相同之处在于:都取消了区域生成网络,通过计算特征图滑动窗区域与真实区域的交并比寻找候选区域,并且候选区域直接作用于检测网络进行分类和定位.不同之处在于:SSD算法的滑动窗尺寸由人工确定,而YOLOv2算法的滑动窗尺寸由样本集边框标签进行K-means聚类得到;SSD算法使用不同层特征图生成候选区域,而YOLOv2算法只使用一层特征图生成候选区域.在Pascal VOC数据集测试中,SSD算法获得速度为46帧/s、平均准确率为74.3%的检测结果,YOLOv2算法获得速度为67帧/s、平均准确率为76.8%的检测结果. ...
2
... 基于深度学习的行人检测算法的特征由计算机学习得到,这类特征同时具备轮廓、颜色、纹理等多种信息,具有极高的语义特征表达能力和鲁棒性. 近几年,许多基于深度学习的通用目标检测算法被提出. Girshick等[11 ] 在RCNN算法[12 ] 的基础上提出Fast R-CNN算法,实现了准确率和效率的大幅提升,该算法将每个用于特征提取的候选区域映射到卷积特征上而不是从原图直接获取,大幅减少了卷积运算,有效提升了候选区域特征的提取速度. 然而,Fast R-CNN仍没有解决Selective Search算法[13 ] 选取候选区域慢的问题. 针对这个问题,Ren等[14 ] 提出了Faster-RCNN算法,设计了区域生成网络(region proposal network,RPN)快速选取候选区域,实现了检测速度和精度的进一步提升,在Pascal VOC数据集的测试中准确率达到了76.4%,速度达到了2 帧/s.为了实现具备较高准确率和实时检测效率的通用目标检测,候选区域特征提取部分的计算量必须减少.Liu等[15 ] 提出了SSD算法,Joseph等[16 ] 提出了YOLOv2算法,实现了较高准确率下的实时目标检测.这2种算法的相同之处在于:都取消了区域生成网络,通过计算特征图滑动窗区域与真实区域的交并比寻找候选区域,并且候选区域直接作用于检测网络进行分类和定位.不同之处在于:SSD算法的滑动窗尺寸由人工确定,而YOLOv2算法的滑动窗尺寸由样本集边框标签进行K-means聚类得到;SSD算法使用不同层特征图生成候选区域,而YOLOv2算法只使用一层特征图生成候选区域.在Pascal VOC数据集测试中,SSD算法获得速度为46帧/s、平均准确率为74.3%的检测结果,YOLOv2算法获得速度为67帧/s、平均准确率为76.8%的检测结果. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
Selective search for object recognition
1
2013
... 基于深度学习的行人检测算法的特征由计算机学习得到,这类特征同时具备轮廓、颜色、纹理等多种信息,具有极高的语义特征表达能力和鲁棒性. 近几年,许多基于深度学习的通用目标检测算法被提出. Girshick等[11 ] 在RCNN算法[12 ] 的基础上提出Fast R-CNN算法,实现了准确率和效率的大幅提升,该算法将每个用于特征提取的候选区域映射到卷积特征上而不是从原图直接获取,大幅减少了卷积运算,有效提升了候选区域特征的提取速度. 然而,Fast R-CNN仍没有解决Selective Search算法[13 ] 选取候选区域慢的问题. 针对这个问题,Ren等[14 ] 提出了Faster-RCNN算法,设计了区域生成网络(region proposal network,RPN)快速选取候选区域,实现了检测速度和精度的进一步提升,在Pascal VOC数据集的测试中准确率达到了76.4%,速度达到了2 帧/s.为了实现具备较高准确率和实时检测效率的通用目标检测,候选区域特征提取部分的计算量必须减少.Liu等[15 ] 提出了SSD算法,Joseph等[16 ] 提出了YOLOv2算法,实现了较高准确率下的实时目标检测.这2种算法的相同之处在于:都取消了区域生成网络,通过计算特征图滑动窗区域与真实区域的交并比寻找候选区域,并且候选区域直接作用于检测网络进行分类和定位.不同之处在于:SSD算法的滑动窗尺寸由人工确定,而YOLOv2算法的滑动窗尺寸由样本集边框标签进行K-means聚类得到;SSD算法使用不同层特征图生成候选区域,而YOLOv2算法只使用一层特征图生成候选区域.在Pascal VOC数据集测试中,SSD算法获得速度为46帧/s、平均准确率为74.3%的检测结果,YOLOv2算法获得速度为67帧/s、平均准确率为76.8%的检测结果. ...
1
... 基于深度学习的行人检测算法的特征由计算机学习得到,这类特征同时具备轮廓、颜色、纹理等多种信息,具有极高的语义特征表达能力和鲁棒性. 近几年,许多基于深度学习的通用目标检测算法被提出. Girshick等[11 ] 在RCNN算法[12 ] 的基础上提出Fast R-CNN算法,实现了准确率和效率的大幅提升,该算法将每个用于特征提取的候选区域映射到卷积特征上而不是从原图直接获取,大幅减少了卷积运算,有效提升了候选区域特征的提取速度. 然而,Fast R-CNN仍没有解决Selective Search算法[13 ] 选取候选区域慢的问题. 针对这个问题,Ren等[14 ] 提出了Faster-RCNN算法,设计了区域生成网络(region proposal network,RPN)快速选取候选区域,实现了检测速度和精度的进一步提升,在Pascal VOC数据集的测试中准确率达到了76.4%,速度达到了2 帧/s.为了实现具备较高准确率和实时检测效率的通用目标检测,候选区域特征提取部分的计算量必须减少.Liu等[15 ] 提出了SSD算法,Joseph等[16 ] 提出了YOLOv2算法,实现了较高准确率下的实时目标检测.这2种算法的相同之处在于:都取消了区域生成网络,通过计算特征图滑动窗区域与真实区域的交并比寻找候选区域,并且候选区域直接作用于检测网络进行分类和定位.不同之处在于:SSD算法的滑动窗尺寸由人工确定,而YOLOv2算法的滑动窗尺寸由样本集边框标签进行K-means聚类得到;SSD算法使用不同层特征图生成候选区域,而YOLOv2算法只使用一层特征图生成候选区域.在Pascal VOC数据集测试中,SSD算法获得速度为46帧/s、平均准确率为74.3%的检测结果,YOLOv2算法获得速度为67帧/s、平均准确率为76.8%的检测结果. ...
1
... 基于深度学习的行人检测算法的特征由计算机学习得到,这类特征同时具备轮廓、颜色、纹理等多种信息,具有极高的语义特征表达能力和鲁棒性. 近几年,许多基于深度学习的通用目标检测算法被提出. Girshick等[11 ] 在RCNN算法[12 ] 的基础上提出Fast R-CNN算法,实现了准确率和效率的大幅提升,该算法将每个用于特征提取的候选区域映射到卷积特征上而不是从原图直接获取,大幅减少了卷积运算,有效提升了候选区域特征的提取速度. 然而,Fast R-CNN仍没有解决Selective Search算法[13 ] 选取候选区域慢的问题. 针对这个问题,Ren等[14 ] 提出了Faster-RCNN算法,设计了区域生成网络(region proposal network,RPN)快速选取候选区域,实现了检测速度和精度的进一步提升,在Pascal VOC数据集的测试中准确率达到了76.4%,速度达到了2 帧/s.为了实现具备较高准确率和实时检测效率的通用目标检测,候选区域特征提取部分的计算量必须减少.Liu等[15 ] 提出了SSD算法,Joseph等[16 ] 提出了YOLOv2算法,实现了较高准确率下的实时目标检测.这2种算法的相同之处在于:都取消了区域生成网络,通过计算特征图滑动窗区域与真实区域的交并比寻找候选区域,并且候选区域直接作用于检测网络进行分类和定位.不同之处在于:SSD算法的滑动窗尺寸由人工确定,而YOLOv2算法的滑动窗尺寸由样本集边框标签进行K-means聚类得到;SSD算法使用不同层特征图生成候选区域,而YOLOv2算法只使用一层特征图生成候选区域.在Pascal VOC数据集测试中,SSD算法获得速度为46帧/s、平均准确率为74.3%的检测结果,YOLOv2算法获得速度为67帧/s、平均准确率为76.8%的检测结果. ...
5
... 基于深度学习的行人检测算法的特征由计算机学习得到,这类特征同时具备轮廓、颜色、纹理等多种信息,具有极高的语义特征表达能力和鲁棒性. 近几年,许多基于深度学习的通用目标检测算法被提出. Girshick等[11 ] 在RCNN算法[12 ] 的基础上提出Fast R-CNN算法,实现了准确率和效率的大幅提升,该算法将每个用于特征提取的候选区域映射到卷积特征上而不是从原图直接获取,大幅减少了卷积运算,有效提升了候选区域特征的提取速度. 然而,Fast R-CNN仍没有解决Selective Search算法[13 ] 选取候选区域慢的问题. 针对这个问题,Ren等[14 ] 提出了Faster-RCNN算法,设计了区域生成网络(region proposal network,RPN)快速选取候选区域,实现了检测速度和精度的进一步提升,在Pascal VOC数据集的测试中准确率达到了76.4%,速度达到了2 帧/s.为了实现具备较高准确率和实时检测效率的通用目标检测,候选区域特征提取部分的计算量必须减少.Liu等[15 ] 提出了SSD算法,Joseph等[16 ] 提出了YOLOv2算法,实现了较高准确率下的实时目标检测.这2种算法的相同之处在于:都取消了区域生成网络,通过计算特征图滑动窗区域与真实区域的交并比寻找候选区域,并且候选区域直接作用于检测网络进行分类和定位.不同之处在于:SSD算法的滑动窗尺寸由人工确定,而YOLOv2算法的滑动窗尺寸由样本集边框标签进行K-means聚类得到;SSD算法使用不同层特征图生成候选区域,而YOLOv2算法只使用一层特征图生成候选区域.在Pascal VOC数据集测试中,SSD算法获得速度为46帧/s、平均准确率为74.3%的检测结果,YOLOv2算法获得速度为67帧/s、平均准确率为76.8%的检测结果. ...
... 在关键指标Mr1值的评估上,本文算法检测准确率优于使用手工提取特征的算法[25 -28 ] ,并且优于取消区域生成网络的深度学习算法YOLOv2[16 ] 和SSD,与使用区域生成网络的SAF R-CNN[29 ] 相比存在一定差距.具体指标如表1 所示.这表明在行人检测应用中,本文对SSD算法的改进是有效的且行人检测准确性更好. ...
... Accuracy of detection in different methods on INRIA pedestrian datasets
Tab.1 算法 M r1 /% 算法 M r1 /% LDCF[25 ] 13.8 SAF R-CNN[29 ] 8.0 SketchTokens[26 ] 13.3 YOLOv2[16 ] 13.0 Roerei[27 ] 13.5 SSD 14.9 RandForest[28 ] 15.4 本文算法 12.1
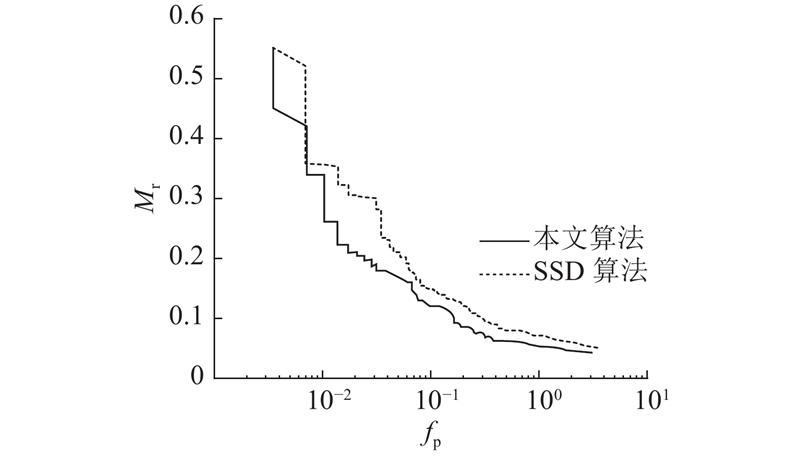
(2)关于ETH行人数据集实验分析,本文使用由INRIA行人数据集训练得到的检测模型,分别对ETH行人数据集的3个子数据集进行测试,实验结果如图7 所示. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
... Comparison of number of detected pictures per second in different methods
Tab.3 算法 N per-sec 算法 N per-sec LDCF[25 ] 1.7 SAF R-CNN[29 ] 1.7 SketchTokens[26 ] 1.0 YOLOv2[16 ] 67 Roerei[27 ] 1.0 SSD 35 RandForest[28 ] 4.6 本文算法 33
3. 结 语 本文提出了特征图聚集多尺度行人检测高效算法,通过将高、低层次的特征图进行聚集,使网络提取到的特征具有更好的空间分辨能力和语义能力;并根据行人数据集的特点,改进SSD算法的候选区域设计,将高宽比小于1的候选区域去除,增加高宽比大于1的候选区域,有效提升行人定位准确性. 与一些优秀的传统算法相比,本文算法具有更高的行人检测与定位准确率;相比YOLOv2算法具有更高的检测准确性,相比SAF R-CNN算法具有更高的检测效率;并可在一般设备上达到实时性应用的要求. 进一步研究可以结合模型压缩算法在保持准确性有限下降的情况下大幅度提高效率. ...
1
... 行人检测属于目标检测的一种特殊情况,本文对目标检测SSD算法进行改进,提出一种高效的特征图聚集多尺度行人检测算法,通过提高SSD算法中用于检测部分特征的空间分辨和语义能力,实现高效和准确的行人检测. 当前,已有许多优秀的特征图聚集算法,其中Inception module算法[17 -19 ] 对不同感受野特征图进行融合,构造出的特征具有较高的空间信息,但是未使用具有较好语义信息的高层特征;交叉输入邻域差异化算法[20 ] 通过单一较低层特征图互相减的运算可构造出具有差异化显著的类内与类间特征,但是所含语义信息较少. 本文进一步结合HpyerNet[21 ] 算法,提出一种将高层次特征与低层次特征图进行聚集的网络,构造出具有较好空间分辨和语义能力的特征图,以提高检测准确性. 同时,为获得更好的行人定位准确性,本文构造多尺度行人检测网络,对SSD算法的候选区域根据行人长宽比例进行重新设计,使预测区域更加逼近真实区域. ...
1
... 行人检测属于目标检测的一种特殊情况,本文对目标检测SSD算法进行改进,提出一种高效的特征图聚集多尺度行人检测算法,通过提高SSD算法中用于检测部分特征的空间分辨和语义能力,实现高效和准确的行人检测. 当前,已有许多优秀的特征图聚集算法,其中Inception module算法[17 -19 ] 对不同感受野特征图进行融合,构造出的特征具有较高的空间信息,但是未使用具有较好语义信息的高层特征;交叉输入邻域差异化算法[20 ] 通过单一较低层特征图互相减的运算可构造出具有差异化显著的类内与类间特征,但是所含语义信息较少. 本文进一步结合HpyerNet[21 ] 算法,提出一种将高层次特征与低层次特征图进行聚集的网络,构造出具有较好空间分辨和语义能力的特征图,以提高检测准确性. 同时,为获得更好的行人定位准确性,本文构造多尺度行人检测网络,对SSD算法的候选区域根据行人长宽比例进行重新设计,使预测区域更加逼近真实区域. ...
1
... 行人检测属于目标检测的一种特殊情况,本文对目标检测SSD算法进行改进,提出一种高效的特征图聚集多尺度行人检测算法,通过提高SSD算法中用于检测部分特征的空间分辨和语义能力,实现高效和准确的行人检测. 当前,已有许多优秀的特征图聚集算法,其中Inception module算法[17 -19 ] 对不同感受野特征图进行融合,构造出的特征具有较高的空间信息,但是未使用具有较好语义信息的高层特征;交叉输入邻域差异化算法[20 ] 通过单一较低层特征图互相减的运算可构造出具有差异化显著的类内与类间特征,但是所含语义信息较少. 本文进一步结合HpyerNet[21 ] 算法,提出一种将高层次特征与低层次特征图进行聚集的网络,构造出具有较好空间分辨和语义能力的特征图,以提高检测准确性. 同时,为获得更好的行人定位准确性,本文构造多尺度行人检测网络,对SSD算法的候选区域根据行人长宽比例进行重新设计,使预测区域更加逼近真实区域. ...
1
... 行人检测属于目标检测的一种特殊情况,本文对目标检测SSD算法进行改进,提出一种高效的特征图聚集多尺度行人检测算法,通过提高SSD算法中用于检测部分特征的空间分辨和语义能力,实现高效和准确的行人检测. 当前,已有许多优秀的特征图聚集算法,其中Inception module算法[17 -19 ] 对不同感受野特征图进行融合,构造出的特征具有较高的空间信息,但是未使用具有较好语义信息的高层特征;交叉输入邻域差异化算法[20 ] 通过单一较低层特征图互相减的运算可构造出具有差异化显著的类内与类间特征,但是所含语义信息较少. 本文进一步结合HpyerNet[21 ] 算法,提出一种将高层次特征与低层次特征图进行聚集的网络,构造出具有较好空间分辨和语义能力的特征图,以提高检测准确性. 同时,为获得更好的行人定位准确性,本文构造多尺度行人检测网络,对SSD算法的候选区域根据行人长宽比例进行重新设计,使预测区域更加逼近真实区域. ...
1
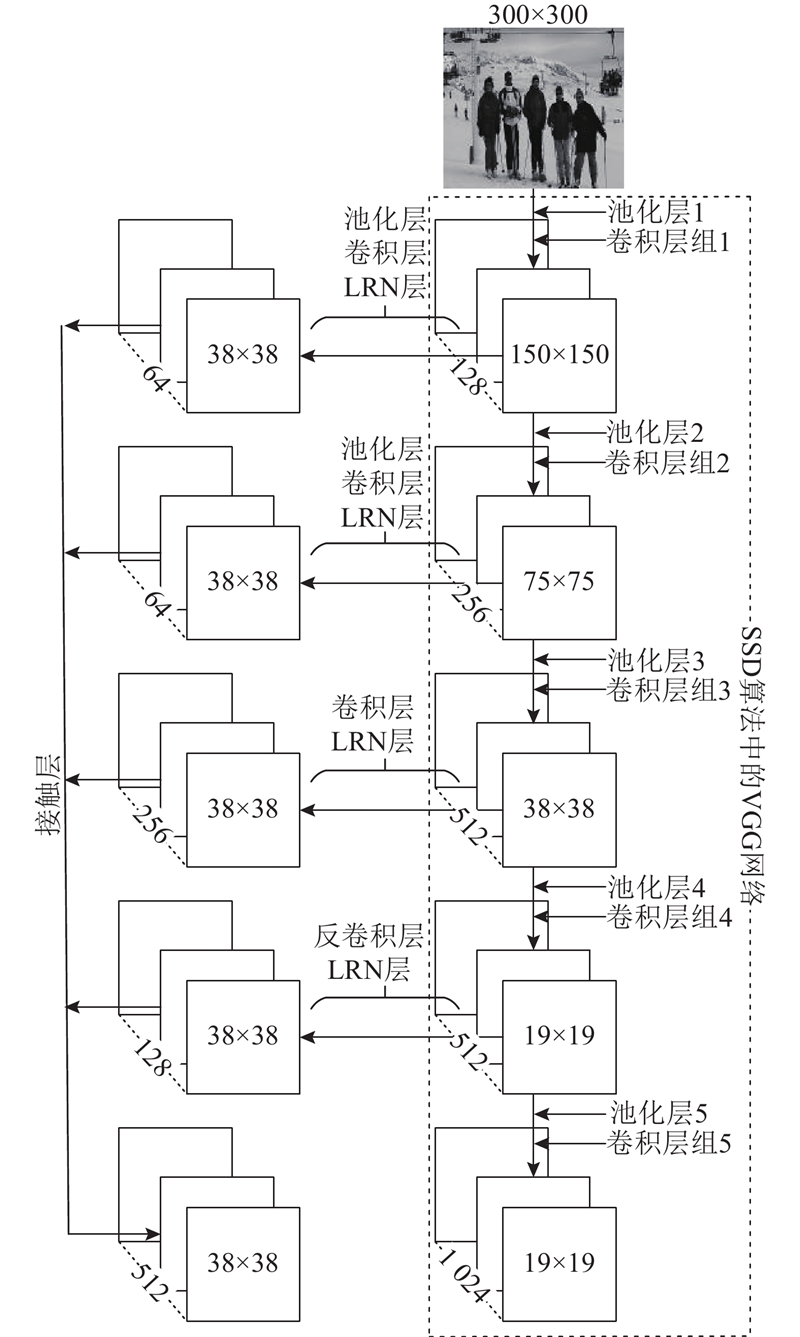
... 第一部分为特征提取网络,由特征图聚集网络和特征延伸网络组成. 特征图聚集网络是针对SSD算法中特征提取网络视觉几何组(visual geometry group,VGG)[22 ] 的一种改进,对其多个低层特征使用不同尺寸的池化层进行下采样,之后使用卷积核尺寸为3×3的卷积层处理加强语义能力,并对一个高层特征使用反卷积层[23 ] 进行上采样,以此将不同层输出的特征图尺寸统一到38×38. 为防止数据过拟合使用局部响应归一化层(local response normalization,LRN)对这些特征图进行处理,并使用拼接层Concat进行通道拼接,形成具有较好空间分辨能力和语义能力的聚集特征图. 特征延伸网络是对特征图聚集网络卷积层组5的扩展,以形成多尺度特征图,用于预测不同尺度的行人位置. ...
1
... 第一部分为特征提取网络,由特征图聚集网络和特征延伸网络组成. 特征图聚集网络是针对SSD算法中特征提取网络视觉几何组(visual geometry group,VGG)[22 ] 的一种改进,对其多个低层特征使用不同尺寸的池化层进行下采样,之后使用卷积核尺寸为3×3的卷积层处理加强语义能力,并对一个高层特征使用反卷积层[23 ] 进行上采样,以此将不同层输出的特征图尺寸统一到38×38. 为防止数据过拟合使用局部响应归一化层(local response normalization,LRN)对这些特征图进行处理,并使用拼接层Concat进行通道拼接,形成具有较好空间分辨能力和语义能力的聚集特征图. 特征延伸网络是对特征图聚集网络卷积层组5的扩展,以形成多尺度特征图,用于预测不同尺度的行人位置. ...
1
... ETH行人检测数据集[24 ] :由苏黎世联邦理工大学公开,该数据集的帧率和分辨率分别为13~14 帧/s 和640×480,由3种不同光线的街道场景组成,其中强光照场景包含354张图片,阴天场景包含999张图片,正常光照场景包含446张图片,如图5 所示. 该数据集由3个具有不同光线的街道场景的子数据集构成,帧率和分辨率分别为13~14帧/s和640×480,其中左侧为强光照场景包含354张图片,中间为阴天场景包含999张图片,右侧为正常光照场景包含446张图片. ...
4
... 在关键指标Mr1值的评估上,本文算法检测准确率优于使用手工提取特征的算法[25 -28 ] ,并且优于取消区域生成网络的深度学习算法YOLOv2[16 ] 和SSD,与使用区域生成网络的SAF R-CNN[29 ] 相比存在一定差距.具体指标如表1 所示.这表明在行人检测应用中,本文对SSD算法的改进是有效的且行人检测准确性更好. ...
... Accuracy of detection in different methods on INRIA pedestrian datasets
Tab.1 算法 M r1 /% 算法 M r1 /% LDCF[25 ] 13.8 SAF R-CNN[29 ] 8.0 SketchTokens[26 ] 13.3 YOLOv2[16 ] 13.0 Roerei[27 ] 13.5 SSD 14.9 RandForest[28 ] 15.4 本文算法 12.1
(2)关于ETH行人数据集实验分析,本文使用由INRIA行人数据集训练得到的检测模型,分别对ETH行人数据集的3个子数据集进行测试,实验结果如图7 所示. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
... Comparison of number of detected pictures per second in different methods
Tab.3 算法 N per-sec 算法 N per-sec LDCF[25 ] 1.7 SAF R-CNN[29 ] 1.7 SketchTokens[26 ] 1.0 YOLOv2[16 ] 67 Roerei[27 ] 1.0 SSD 35 RandForest[28 ] 4.6 本文算法 33
3. 结 语 本文提出了特征图聚集多尺度行人检测高效算法,通过将高、低层次的特征图进行聚集,使网络提取到的特征具有更好的空间分辨能力和语义能力;并根据行人数据集的特点,改进SSD算法的候选区域设计,将高宽比小于1的候选区域去除,增加高宽比大于1的候选区域,有效提升行人定位准确性. 与一些优秀的传统算法相比,本文算法具有更高的行人检测与定位准确率;相比YOLOv2算法具有更高的检测准确性,相比SAF R-CNN算法具有更高的检测效率;并可在一般设备上达到实时性应用的要求. 进一步研究可以结合模型压缩算法在保持准确性有限下降的情况下大幅度提高效率. ...
3
... Accuracy of detection in different methods on INRIA pedestrian datasets
Tab.1 算法 M r1 /% 算法 M r1 /% LDCF[25 ] 13.8 SAF R-CNN[29 ] 8.0 SketchTokens[26 ] 13.3 YOLOv2[16 ] 13.0 Roerei[27 ] 13.5 SSD 14.9 RandForest[28 ] 15.4 本文算法 12.1
(2)关于ETH行人数据集实验分析,本文使用由INRIA行人数据集训练得到的检测模型,分别对ETH行人数据集的3个子数据集进行测试,实验结果如图7 所示. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
... Comparison of number of detected pictures per second in different methods
Tab.3 算法 N per-sec 算法 N per-sec LDCF[25 ] 1.7 SAF R-CNN[29 ] 1.7 SketchTokens[26 ] 1.0 YOLOv2[16 ] 67 Roerei[27 ] 1.0 SSD 35 RandForest[28 ] 4.6 本文算法 33
3. 结 语 本文提出了特征图聚集多尺度行人检测高效算法,通过将高、低层次的特征图进行聚集,使网络提取到的特征具有更好的空间分辨能力和语义能力;并根据行人数据集的特点,改进SSD算法的候选区域设计,将高宽比小于1的候选区域去除,增加高宽比大于1的候选区域,有效提升行人定位准确性. 与一些优秀的传统算法相比,本文算法具有更高的行人检测与定位准确率;相比YOLOv2算法具有更高的检测准确性,相比SAF R-CNN算法具有更高的检测效率;并可在一般设备上达到实时性应用的要求. 进一步研究可以结合模型压缩算法在保持准确性有限下降的情况下大幅度提高效率. ...
3
... Accuracy of detection in different methods on INRIA pedestrian datasets
Tab.1 算法 M r1 /% 算法 M r1 /% LDCF[25 ] 13.8 SAF R-CNN[29 ] 8.0 SketchTokens[26 ] 13.3 YOLOv2[16 ] 13.0 Roerei[27 ] 13.5 SSD 14.9 RandForest[28 ] 15.4 本文算法 12.1
(2)关于ETH行人数据集实验分析,本文使用由INRIA行人数据集训练得到的检测模型,分别对ETH行人数据集的3个子数据集进行测试,实验结果如图7 所示. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
... Comparison of number of detected pictures per second in different methods
Tab.3 算法 N per-sec 算法 N per-sec LDCF[25 ] 1.7 SAF R-CNN[29 ] 1.7 SketchTokens[26 ] 1.0 YOLOv2[16 ] 67 Roerei[27 ] 1.0 SSD 35 RandForest[28 ] 4.6 本文算法 33
3. 结 语 本文提出了特征图聚集多尺度行人检测高效算法,通过将高、低层次的特征图进行聚集,使网络提取到的特征具有更好的空间分辨能力和语义能力;并根据行人数据集的特点,改进SSD算法的候选区域设计,将高宽比小于1的候选区域去除,增加高宽比大于1的候选区域,有效提升行人定位准确性. 与一些优秀的传统算法相比,本文算法具有更高的行人检测与定位准确率;相比YOLOv2算法具有更高的检测准确性,相比SAF R-CNN算法具有更高的检测效率;并可在一般设备上达到实时性应用的要求. 进一步研究可以结合模型压缩算法在保持准确性有限下降的情况下大幅度提高效率. ...
4
... 在关键指标Mr1值的评估上,本文算法检测准确率优于使用手工提取特征的算法[25 -28 ] ,并且优于取消区域生成网络的深度学习算法YOLOv2[16 ] 和SSD,与使用区域生成网络的SAF R-CNN[29 ] 相比存在一定差距.具体指标如表1 所示.这表明在行人检测应用中,本文对SSD算法的改进是有效的且行人检测准确性更好. ...
... Accuracy of detection in different methods on INRIA pedestrian datasets
Tab.1 算法 M r1 /% 算法 M r1 /% LDCF[25 ] 13.8 SAF R-CNN[29 ] 8.0 SketchTokens[26 ] 13.3 YOLOv2[16 ] 13.0 Roerei[27 ] 13.5 SSD 14.9 RandForest[28 ] 15.4 本文算法 12.1
(2)关于ETH行人数据集实验分析,本文使用由INRIA行人数据集训练得到的检测模型,分别对ETH行人数据集的3个子数据集进行测试,实验结果如图7 所示. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
... Comparison of number of detected pictures per second in different methods
Tab.3 算法 N per-sec 算法 N per-sec LDCF[25 ] 1.7 SAF R-CNN[29 ] 1.7 SketchTokens[26 ] 1.0 YOLOv2[16 ] 67 Roerei[27 ] 1.0 SSD 35 RandForest[28 ] 4.6 本文算法 33
3. 结 语 本文提出了特征图聚集多尺度行人检测高效算法,通过将高、低层次的特征图进行聚集,使网络提取到的特征具有更好的空间分辨能力和语义能力;并根据行人数据集的特点,改进SSD算法的候选区域设计,将高宽比小于1的候选区域去除,增加高宽比大于1的候选区域,有效提升行人定位准确性. 与一些优秀的传统算法相比,本文算法具有更高的行人检测与定位准确率;相比YOLOv2算法具有更高的检测准确性,相比SAF R-CNN算法具有更高的检测效率;并可在一般设备上达到实时性应用的要求. 进一步研究可以结合模型压缩算法在保持准确性有限下降的情况下大幅度提高效率. ...
Scale-aware fast R-CNN for pedestrian detection
4
2018
... 在关键指标Mr1值的评估上,本文算法检测准确率优于使用手工提取特征的算法[25 -28 ] ,并且优于取消区域生成网络的深度学习算法YOLOv2[16 ] 和SSD,与使用区域生成网络的SAF R-CNN[29 ] 相比存在一定差距.具体指标如表1 所示.这表明在行人检测应用中,本文对SSD算法的改进是有效的且行人检测准确性更好. ...
... Accuracy of detection in different methods on INRIA pedestrian datasets
Tab.1 算法 M r1 /% 算法 M r1 /% LDCF[25 ] 13.8 SAF R-CNN[29 ] 8.0 SketchTokens[26 ] 13.3 YOLOv2[16 ] 13.0 Roerei[27 ] 13.5 SSD 14.9 RandForest[28 ] 15.4 本文算法 12.1
(2)关于ETH行人数据集实验分析,本文使用由INRIA行人数据集训练得到的检测模型,分别对ETH行人数据集的3个子数据集进行测试,实验结果如图7 所示. ...
... 本文算法效率评估方式为每秒检测大小为640×480图片的数量. 由于有些算法使用CPU实现,有些使用GPU实现,因此,本实验不区分各个算法的硬件环境. 本文算法与当前一些优秀行人检测算法每秒可检测图片数量N per-sec 的比较,如表3 所示. 本文算法在检测单张图片的时间上相比基于手工提取特征的行人检测算法LDCF[25 ] 、SketchTokens[26 ] 、Roerei[27 ] 和RandForest[28 ] 大幅度减少,相比深度学习的SSD算法略有增加,与YOLOv2[16 ] 算法有一定的差距,与基于RCNN[12 ] 多尺度特征融合的SAF R-CNN[29 ] 算法大幅度减少. 这表明本文算法相比人工提取特征训练的行人检测算法效率明显提升,并且满足实时检测的要求. ...
... Comparison of number of detected pictures per second in different methods
Tab.3 算法 N per-sec 算法 N per-sec LDCF[25 ] 1.7 SAF R-CNN[29 ] 1.7 SketchTokens[26 ] 1.0 YOLOv2[16 ] 67 Roerei[27 ] 1.0 SSD 35 RandForest[28 ] 4.6 本文算法 33
3. 结 语 本文提出了特征图聚集多尺度行人检测高效算法,通过将高、低层次的特征图进行聚集,使网络提取到的特征具有更好的空间分辨能力和语义能力;并根据行人数据集的特点,改进SSD算法的候选区域设计,将高宽比小于1的候选区域去除,增加高宽比大于1的候选区域,有效提升行人定位准确性. 与一些优秀的传统算法相比,本文算法具有更高的行人检测与定位准确率;相比YOLOv2算法具有更高的检测准确性,相比SAF R-CNN算法具有更高的检测效率;并可在一般设备上达到实时性应用的要求. 进一步研究可以结合模型压缩算法在保持准确性有限下降的情况下大幅度提高效率. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}