

声源定位是音频信号处理领域的重要研究内容之一,在智能机器人、盲点探测和水下侦查等领域有广泛的应用[1-3]. 此外,由于基于麦克风阵列的声源定位属于宽带短时平稳信号的空间谱估计问题,其研究成果可被移动通信、声呐侦查和雷达探测等研究领域所借鉴. 传统声源定位方法主要分为3类:基于高分辨率谱估计的方法[4]、基于可控波束形成的方法[5]和基于时延(time delay of arrival,TDOA)估计的方法[6]. 这些方法可将声源与阵列结构的空间几何关系转换为空间谱、空间波束或到达时间差等信息,并通过对这些信息的估计完成声源定位. 传统几何定位方法需预知模型参数,属于参数化定位方法范畴. 其中,时延估计定位法因其计算复杂度低、实时性好且硬件成本低,被广泛应用于声源定位和跟踪中[7-8]. 然而,在多径信号和环境噪声的影响下,时延估计的精度一般较低,这是室内环境中基于时延估计的参数定位方法性能不佳的主要原因.
研究表明,位置指纹定位方法的定位精度受参考点(reference points,RPs)密度[11-12]影响较大. 因此,通常需要在离线采样阶段构建大规模的定位数据库来满足定位精度需求. 与此同时,在在线定位阶段,定位算法需要占用大量计算资源完成定位,使得位置指纹声源定位方法的定位效率降低,很难应用于移动机器人听觉定位、室内异常声源定位和发声者定位等对实时性要求较高的场景[13]. 为提高位置指纹定位方法的定位效率,Khalajmehrabadi等[14]采用了基于插值的稀疏数据库恢复方法来减少初始参考点数量,从而提高离线采样效率. 但是,由于插值生成的虚拟参考点仍需参与临近参考点匹配,该方法并未明显改善在线定位效率较低的情况.
有选择的进行目标点(target point,TP)和参考点的匹配可以减少在线匹配的计算量,因此可通过将搜索范围收缩到目标点周围参考点来减少非临近参考点的匹配量,提高匹配效率. 很多研究者考虑将数据库分块,然后选择最可能包含临近参考点的子库进行搜索来降低运算量[15]. 文献[16]介绍了多种基于坐标栅格划分的数据库分块方法,这些方法可有效提升位置指纹定位的效率和稳定性. Liu等[17]在坐标栅格划分方法的基础上提出了一种基于最小包围圈的方法来实现栅格大小的灵活定义. 但是,坐标划分方法受主观判断影响较大,存在数据库分区方式不统一和分区导致参考点失配后定位误差增大的问题. 聚类分析是一种以样本特征相似性为基础,对数据集进行自动划分的无监督学习算法. 聚类分析方法可将特征相似的参考点自动地划分到同一个子库. 相比坐标划分方法,特征聚类划分方法与临近参考点的选取规则更趋一致[18].
为提高位置指纹声源定位方法的定位效率,本文提出一种两级参考点匹配方法来提高临近参考点的搜索速率. 首先通过离线采样阶段的特征空间聚类分析将定位数据库划分为一定数目的子库,然后在在线定位阶段通过两级匹配过程对参考点匹配量进行缩减完成临近参考点快速搜索.
1. 基于位置指纹的声源定位
如图1中四麦克风(M0,M1,M2,M3)声源定位系统所示,基于位置指纹的声源定位过程包含用于数据库构建的离线采样阶段和用于位置估计的在线定位阶段两部分. 图中(
图 1
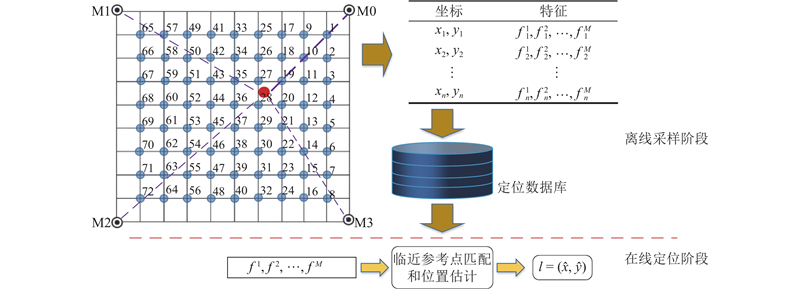
图 1 基于位置指纹的声源定位(SSL)技术示意图
Fig.1 Illustration of fingerprint-based sound source location (SSL) technique
1.1. 离线采样阶段
离线采样过程一般分为3步:1)根据定位区域环境和定位需求确定参考点的坐标;2)遍历每个参考点坐标并释放定位信号,同时通过声源定位系统完成信号采集和位置相关特征提取;3)将参考点二维坐标及其特征关联形成一组样本,也称作位置指纹:
式中:
1.2. 在线定位阶段
采用加权K-最近邻算法(weighted K-nearest neighbor,WKNN)进行位置估计. 首先,信号采集系统捕获待定位声源声音信号并提取特征向量
式中:k为临近参考点的个数:
其中,di和dj分别表示第i个和第j个临近参考点与目标点在特征空间的欧氏距离,
2. 两级参考点匹配法
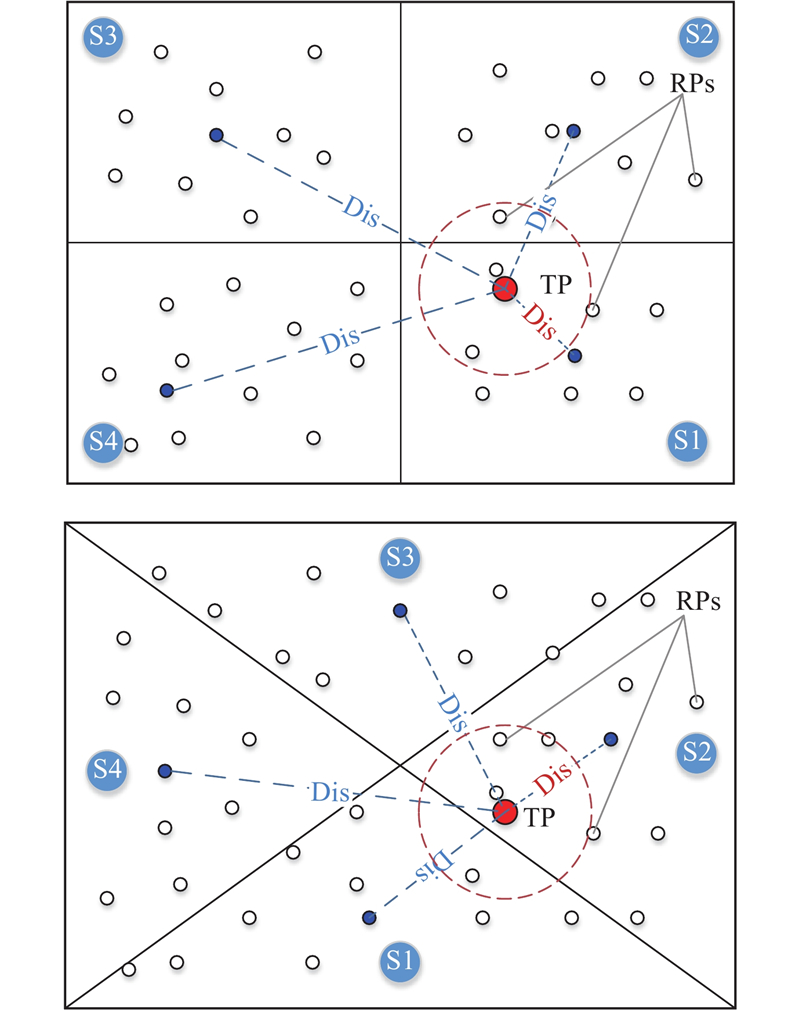
在传统的位置指纹定位方法中,待定位信号需要通过与数据库中的所有样本进行一一匹配完成临近参考点搜索. 位置指纹定位方法定位精度的提升通常依赖于增加定位区域的参考点密度. 然而,增加参考点数量将导致在线阶段参考点匹配运算复杂度的提高和定位效率的降低. 针对传统指纹定位中存在的这一矛盾,本文的改进如下:在离线采样阶段数据库建设完成后,将整个数据库划分为一定数量的子库. 在在线定位过程中,通过搜索临近子库来缩小匹配范围,从而用较小的匹配计算量完成临近参考点的搜索.
图 2
2.1. 数据库划分和离群点剔除
相对于坐标划分方法,特征聚类方法可以一定程度保证数据集划分结果的重复性,而且特征聚类划分方法与临近参考点的选取规则更趋一致,均为特征空间相似性. 目前聚类分析的主流方法有很多,其中K均值聚类算法以其简单、快速和高效处理大规模数据等诸多优点,成为应用最广泛的聚类方法之一[19]. 考虑到单个房间内声场特征较为均匀,而且麦克风在类正方形定位区域4个顶点处的布置使得子库中参考点之间特征区别明显,采用特征空间的K-means算法容易获得较好的分类效果,并且具有较高的效率.
采用K均值聚类对位置指纹数据库进行特征空间划分的一般过程为如下. 首先,从数据库D的所有样本中随机选择K个参考点作为初始聚类中心
输入:数据库
过程:
1:从D中随机选取K个样本作为初始聚类中心:
2:while flag>0do
3: 初始化聚类中心变化标记:flag=0;
4:
5: for j=
6: 计算
7: 根据距离最近的聚类中心确定
8: 将样本Sj划入相应的聚类:
9: end
10: for i=
11: 计算新的聚类中心:
12: if
13: 更新聚类中心
14: flag=flag+1;
15: else
16: 保持当前聚类中心
17: end
18: end
输出:
考虑到数据库中可能存在因噪声和测量误差导致的离群参考点,在聚类结束后,采用基于距离的离群点检测方法对离群点进行剔除[20]. 其基本过程如下:对于给定的数据集
2.2. 两级临近参考点匹配
如图3所示,两级临近参考点匹配方法步骤:首先,根据目标点特征F与各子库中心
图 3
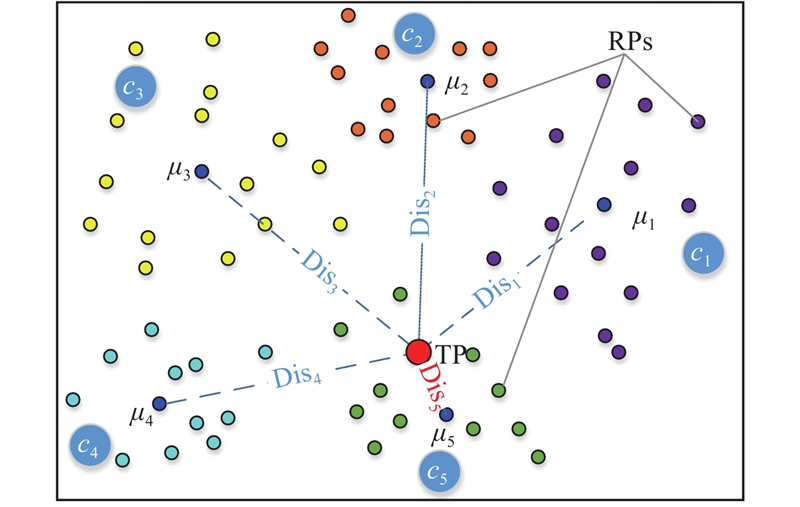
目标点临近子库
如图4所示,根据目标点特征F与临近聚类
图 4
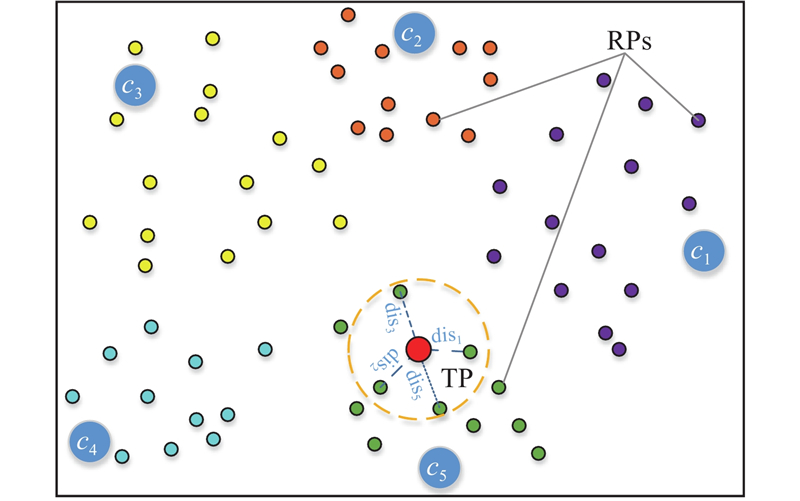
图 4 子库内临近参考点(RPs)搜索过程
Fig.4 Adjacent reference points(RPs)searching process in sub-database
式中:
由于参考点匹配过程的计算量远大于在线定位过程中的其他部分,同时在在线定位过程中除参考点匹配外的其他部分的计算量基本相当,本文仅考察传统全局线性匹配方法和两级匹配方法之间的复杂性差异. 线性匹配的复杂度为O(N),基于两级搜索方法的匹配过程的平均复杂度为O(N/K). 与全局线性匹配方法相比,两级参考点搜索方法可将参考点匹配过程的复杂度降低到前者的1/K.
3. 实验验证
验证实验在一个普通研究室中进行. 室内噪音约为40~60 dB,没有对定位环境作隔音和消噪等特殊处理. 如图5所示:定位区域是一个长约6 m、宽约5 m的矩形平面;麦克风安装在定位区域的4个顶点,距离房间地面的高度约为135 cm,四通道麦克风阵列由BSWA TECH公司的MPA201全向型麦克风组成;采集卡的型号为NI公司的NI9215A,采样频率设置为100 kHz,采样周期为1 s;声源为型号为sony SRS-X11的蓝牙音响,其形状近似为正方体,发声单元由布置在其3个侧面的同型号扬声器组成. 考虑到该音箱尺寸较小,且在水平方向具有直线对称性,本文算法不考虑其指向性.
图 5

如图5所示,定位参考点通过栅格地图形成,参考点之间的距离为0.593 m. 位置指纹数据库由72个参考点组成,另外13个测试点用于实验验证.
3.1. 聚类分区数目对定位精度的影响
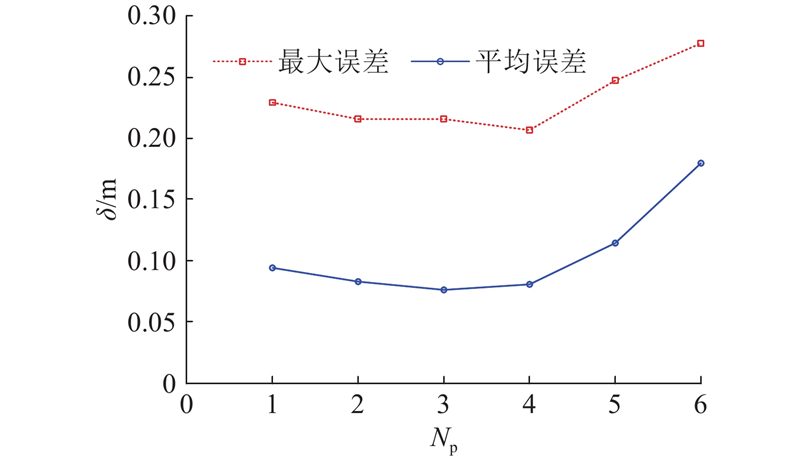
对指纹数据库分区数目为1~6的两级参考点匹配声源定位方法的定位结果进行比较,其中分区数目为1表示无分区定位,即全局线性匹配定位的情况.
如图6所示:当分区数目Np=2、3、4时,在定位效率逐步提高的前提下,定位精度相比全局线性匹配略有改善. 这主要是因为本文根据聚类结果,通过离群点检验的方法剔除定位数据库中测量误差较大的离群点,提高了数据库样本的准确性. 但是,当子库划分数量增加到5时,定位效果开始出现明显的恶化;当分区数目Np=6时,平均误差δ已经超过0.18 m,而最大误差达到了0.278 0 m. 此时,61.5%的测试点定位精度无法满足0.20 m的定位需求. 子库划分数量的增加可有效提高定位效率,但当子库数量达到一定数量时,子库之间的区分不再明显,聚类效果将随子库数量的增加逐步下降,使得测试点的临近参考点被划分到不同子库的概率增加,造成临近参考点匹配错误的情况. 由此可见,子库划分数目不可无限制增加,对数据库进行过多的分区将导致定位效果的恶化.
图 6
3.2. 和坐标分区方法对比
如表1所示,在子库数目为4时,对基于坐标划分和特征聚类划分2种数据库划分方式的定位结果进行对比. 表中NAM为平均匹配次数,TAM为平均匹配时间,δMA为平均绝对误差,σ2为平均误差方差. 在在线阶段,两者在参考点匹配过程中的平均匹配量和匹配用时基本相当,在线定位效率相比传统线性匹配方式均有大幅度改进. 其中,基于特征聚类划分方式将在线参考点匹配量降低了69.86%,坐标划分方式则为69.03%. 基于特征聚类的定位方法可达到0.0813 m的平均误差,而基于坐标划分的定位方法的平均定位误差为 0.1214 m. 由此可见,基于特征聚类划分的位置指纹定位方法在定位精度上的优势明显,同时该方法相比传统全局线性参考点匹配方法定位精度也略有提升. 相比传统线性匹配方式,坐标划分方式的平均误差方差增加了约42.0%,而特征聚类划分方法则将平均误差方差降低了约43.4%. 采用数据库特征聚类划分方式,系统在定位区域不同位置的定位能力更趋于一致. 需要指出的是:在离线阶段的子区域划分所需的运算量比较中,基于特征聚类的数据库划分方式较坐标划分方式复杂程度更高,但该部分处于对实时性要求不高的离线采样阶段,不对在线定位效率造成直接影响.
表 1 不同数据库划分方式对定位效果的影响对比
Tab.1
| 数据库划分方式 | NAM | TAM / s | δMA / m | σ2/m2 |
| 无分区 | 72.0 | 0.027 1 | 0.094 5 | 0.006 9 |
| 坐标划分 | 22.3 | 0.008 4 | 0.121 4 | 0.009 8 |
| 特征聚类划分 | 21.7 | 0.008 1 | 0.081 3 | 0.003 9 |
为进一步分析分区方式对不同参考点影响存在差异的原因,对2种数据库划分方法对各参考点的影响进行分析. 如图7所示:对于坐标划分方法,在4、9和10号测试点处出现了误差增加的情况,其他测试点和全局线性匹配定位方式的定位结果基本相当. 部分点定位效果恶化的原因是测试点处于不同子库的交界处,造成其在临近参考点的选择上出现了比较大的错误;特征聚类划分方法在5号测试点处的定位误差增加,其他点和全局分类的方法基本一致. 主要是因为该点位于3个聚类子库的交界处,其对应的临近参考点被划分到了不同的子库,因而造成了比较大的定位误差.
图 7
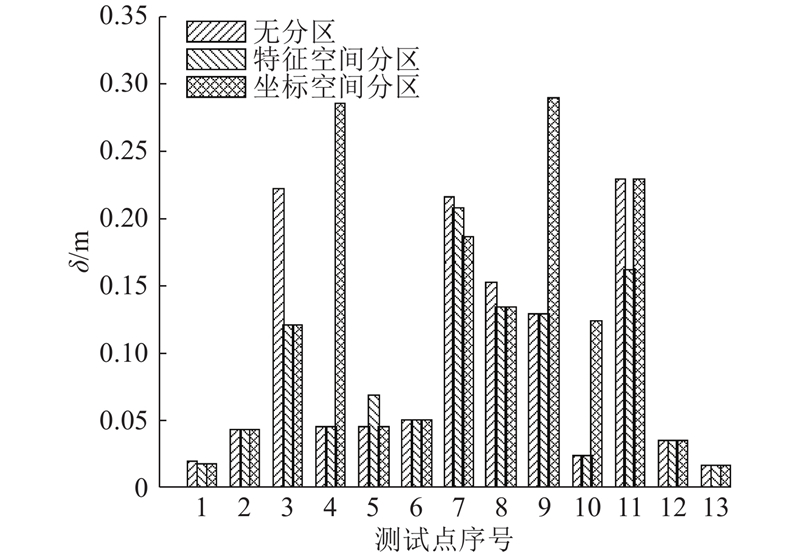
图 7 子库数目为4时不同划分方式对定位的影响
Fig.7 Effect of different partitioning methods on positioning with sub-database number of four
相较而言,基于特征聚类划分方法的两级定位算法提供了一种更稳定的参考点快速匹配策略. 此外,坐标划分方法受经验的影响较大,选择不同的划分方式将导致不同的定位结果,而采用特征空间聚类划分方法时,在确定子库数目后,数据库的划分结果基本相同.
两级参考点匹配方法可以在保证定位精度的前提下通过减少所需匹配的参考点数量来提高在线定位效率. 与此同时,这种方法对定位效果的提升是有限的,对数据库进行数量过多的划分将不可避免地带来临近参考点的失配从而导致定位精度的降低.
4. 结 语
本文提出了一种基于特征聚类的两级参考点匹配方法来提高位置指纹声源定位方法的效率. 在离线阶段,采用K-means聚类算法将定位数据库划分为一定数量的字库;在在线阶段,通过临近子库的搜索缩小临近参考点的搜索范围,提高了匹配效率. 与传统全局线性参考点匹配方法相比,该方法可以将临近参考点匹配过程的计算量减少69.86%,并进一步将室内声源定位的定位精度提升了13.97%. 但是,特征聚类划分方法对定位效果的提升不是无限度的,子库划分数量过多将导致声音位置指纹定位方法定位精度的恶化. 接下来进一步通过理论和仿真分析及不同环境下的实验针对特征聚类划分方法的有效参数及其设定方法展开研究.
参考文献
Localization of sound sources in robotics: a review
[J].
Indoor sound source localization with probabilistic neural network
[J].
Source localization in underwater waveguides using machine learning
[J].
Two-step spherical harmonics ESPRIT-type algorithms and performance analysis
[J].
Near-field acoustic source localization and beamforming in spherical harmonics domain
[J].DOI:10.1109/TSP.2016.2543201 [本文引用: 1]
A geometric approach to sound source localization from time-delay estimates
[J].
基于智能手机TDOA估计的被动声源定位方法与系统实现
[J].DOI:10.3969/j.issn.0254-3087.2016.04.030 [本文引用: 1]
Passive acoustic source target positioning method based on smart phone platform TDOA estimation and system implementation
[J].DOI:10.3969/j.issn.0254-3087.2016.04.030 [本文引用: 1]
机器人听觉声源定位研究综述
[J].DOI:10.3969/j.issn.1673-4785.201201003 [本文引用: 1]
A survey of sound source localization for robot audition
[J].DOI:10.3969/j.issn.1673-4785.201201003 [本文引用: 1]
A microphone position calibration method based on combination of acoustic energy decay model and TDOA for distributed microphone array
[J].DOI:10.1016/j.apacoust.2015.02.013 [本文引用: 1]
Chameleon: survey-free updating of a fingerprint database for indoor localization
[J].DOI:10.1109/MPRV.2016.69 [本文引用: 1]
An improved algorithm to generate a Wi-Fi fingerprint database for indoor positioning
[J].DOI:10.3390/s130811085 [本文引用: 1]
A comparison of deterministic and probabilistic methods for indoor localization
[J].
Structured group sparsity: a novel indoor WLAN localization, outlier detection, and radio map interpolation scheme
[J].DOI:10.1109/TVT.2016.2631980 [本文引用: 1]
Fast sound source localization using two-level search space clustering
[J].DOI:10.1109/TCYB.2015.2391252 [本文引用: 1]
A survey of grid based clustering algorithms
[J].
Coordinate-based clustering method for indoor fingerprinting localization in dense cluttered environments
[J].DOI:10.1109/JSEN.2016.2552300 [本文引用: 1]
Reduced-complexity fingerprinting in WLAN-based indoor positioning
[J].DOI:10.1007/s11235-016-0241-8 [本文引用: 1]
基于核模糊C均值指纹库管理的WIFI室内定位方法
[J].
WIFI fingerprinting localization based on kernel fuzzy C-means Ⅱ clustering
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}