The existing target detection methods were only suitable for large size and few specific types of traffic signs, and showed poor performance on complex traffic scene images. The ResNet101 with strong anti-degradation performance was used as basic network, and then a residual single shot multibox detector (SSD) model added with a number of convolution layers was proposed, in order to conduct multi-scale block detection on high resolution traffic images. A strategy Coarse-to-Fine was adopted to omit the prediction of pure background image blocks, in order to speed up. The target range was narrowed by the initial detection results of the medium scale image block. The other blocks within the target range were detected. All the block results were mapped back to the original image and non-maximum suppression was used to realize accurate recognition. Experiment results showed that the proposed method achieved 94% overall accuracy and 95% overall recall on the public traffic sign dataset Tsinghua-Tencent 100K. The detection ability on traffic sign with different sizes and shapes in multi-resolution images was strong and the proposed model was robust.
Keywords:traffic sign
;
residual single shot multibox detector (SSD) model
;
multi-scale block
;
detection
;
Coarse-to-Fine
RUTA A, LI Y M, LIU X H. Detection, tracking and recognition of traffic signs from video input [C]// Proceedings of the 11th International IEEE Conference on Intelligent Transportation Systems. Beijing: IEEE, 2008: 55–60.
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Advances in Neural Information Processing Systems 25. Nevada: NIPS, 2012: 1097–1105.
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Ohio: IEEE, 2014: 580–587.
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C]// Advances in Neural Information Processing Systems 28. Montreal: NIPS, 2015: 91–99.
DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks [C]// Advances in Neural Information Processing Systems 29. Barcelona: NIPS, 2016: 379–387.
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision And Pattern. Nevada: IEEE, 2016: 779–788.
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 2016 European Conference on Computer Vision. Amsterdam: ECCV, 2016: 21–37.
STALLKAMP J, SCHLIPSING M, SALMEN J, et al. The German traffic sign detection benchmark[EB/OL]. [2013-11-05]. http://benchmark.ini.rub.de/?section=gtsdb&subsection=news.
STALLKAMP J, SCHLIPSING M, SALMEN J, et al. The German traffic sign recognition benchmark[EB/OL]. [2012-03-16]. http://benchmark.ini.rub.de/?section=gtsrb&subsection=news.
ZHU Z, LIANG D, ZHANG S H, et al. Traffic-sign detection and classification in the wild [C]// Proceedings of the 2016 IEEE Conference on Computer Vision And Pattern Recognition. Nevada: IEEE, 2016: 2110–2118.
MENG Z B, FAN X C, CHEN X, et al. Detecting small signs from large images [C]// Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration. California: IEEE, 2017: 217–224.
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C] // Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Nevada: IEEE, 2016: 770–778.
SIMON-YAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// International Conference on Learning Representations. San Diego: ICLR, 2015: 1-14.
HARIHARAN B, ARBELAEZ P, GIRSHICK R, et al. Hypercolumns for object segmentation and fine-grained localization [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Massachusetts: IEEE, 2015: 447–456.
LIU W, RABINOVICH A, BERG A C. ParseNet: looking wider to see better [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Massachusetts: IEEE, 2015: 1–11.
JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding [C]// ACM International Conference on Multimedia. Florida: ACM, 2014: 675–678.
LIN T, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision. Zurich: ECCV, 2014: 740–755.
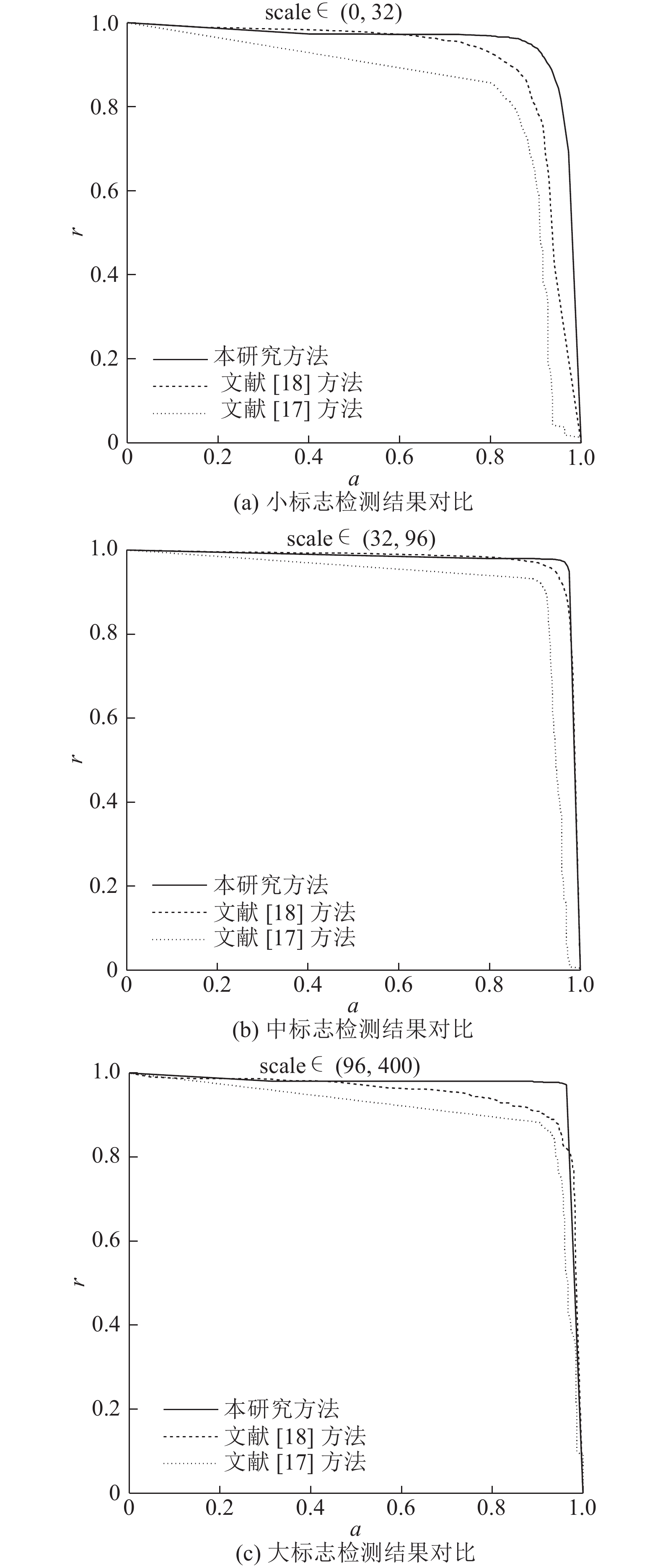
... 由表2可以看出,残差SSD网络结构以及多尺度图像分块方法对检测性能的提升均有直接作用. 与基础SSD网络相比,残差SSD网络的应用使得总体精确度和召回率提升约6%. 相对单尺度分块,多尺度分块使得总体精确度和召回率提升近10%. 由粗到精的策略,将每张图像块的检测时间缩短75%,采用残差SSD网络的检测速度约为采用基础SSD网络的一半. 事实上,He等[19]指出ResNet110参数量为1.7 M(ResNet101更少),远小于VGG16的参数量(约为138.0 M)[20];而ResNet101[19]和VGG16[20]在ImageNet数据集上的每秒浮点操作(floating point operations per second,FLOP)分别为7.6、153.0亿,表明ResNet101模型的时间复杂度远低于VGG16. 实验结果和相关研究依据都充分说明了所提出方法的有效性. 本实验中残差SSD网络对512×512图像块的检测速度约为0.038秒/帧,多尺度分块和非极大值抑制的时间可忽略不计,但由于多尺度图像块数量庞大,总体检测速度达到13.600秒/帧. 可见所提出方法在减少多尺度图像块的数量,缩短检测时间上仍有较大的提升空间. ...
... [19]和VGG16[20]在ImageNet数据集上的每秒浮点操作(floating point operations per second,FLOP)分别为7.6、153.0亿,表明ResNet101模型的时间复杂度远低于VGG16. 实验结果和相关研究依据都充分说明了所提出方法的有效性. 本实验中残差SSD网络对512×512图像块的检测速度约为0.038秒/帧,多尺度分块和非极大值抑制的时间可忽略不计,但由于多尺度图像块数量庞大,总体检测速度达到13.600秒/帧. 可见所提出方法在减少多尺度图像块的数量,缩短检测时间上仍有较大的提升空间. ...
... 由表2可以看出,残差SSD网络结构以及多尺度图像分块方法对检测性能的提升均有直接作用. 与基础SSD网络相比,残差SSD网络的应用使得总体精确度和召回率提升约6%. 相对单尺度分块,多尺度分块使得总体精确度和召回率提升近10%. 由粗到精的策略,将每张图像块的检测时间缩短75%,采用残差SSD网络的检测速度约为采用基础SSD网络的一半. 事实上,He等[19]指出ResNet110参数量为1.7 M(ResNet101更少),远小于VGG16的参数量(约为138.0 M)[20];而ResNet101[19]和VGG16[20]在ImageNet数据集上的每秒浮点操作(floating point operations per second,FLOP)分别为7.6、153.0亿,表明ResNet101模型的时间复杂度远低于VGG16. 实验结果和相关研究依据都充分说明了所提出方法的有效性. 本实验中残差SSD网络对512×512图像块的检测速度约为0.038秒/帧,多尺度分块和非极大值抑制的时间可忽略不计,但由于多尺度图像块数量庞大,总体检测速度达到13.600秒/帧. 可见所提出方法在减少多尺度图像块的数量,缩短检测时间上仍有较大的提升空间. ...
... [20]在ImageNet数据集上的每秒浮点操作(floating point operations per second,FLOP)分别为7.6、153.0亿,表明ResNet101模型的时间复杂度远低于VGG16. 实验结果和相关研究依据都充分说明了所提出方法的有效性. 本实验中残差SSD网络对512×512图像块的检测速度约为0.038秒/帧,多尺度分块和非极大值抑制的时间可忽略不计,但由于多尺度图像块数量庞大,总体检测速度达到13.600秒/帧. 可见所提出方法在减少多尺度图像块的数量,缩短检测时间上仍有较大的提升空间. ...
Fully convolutional networks for semantic segmentation









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}