

近年来,机器学习逐渐成为学术界和工业界的热点研究问题,受到各界人士关注. 人们关心机器学习,希望了解机器学习的趋势和潮流;开发者关注机器学习,希望在传统软件中引入智能化的解决方案;专家关心机器学习,希望将研究成果在各行业转化,推动社会的发展和进步. 然而,机器学习领域内的相关主题众多,热点问题更新快,对机器学习相关主题进行全面研究,分析与机器学习相关的技术趋势很有必要.
在线问答类网站有丰富的数据集. Gyöngyi等[1]和Adamic等[2]分别分析Yahoo! Answers上的用户行为和问题内容. Yahoo! Answers是面向一般大众的社区驱动的问答网站. 相对于Yahoo! Answers,Stack Overflow①作为最受欢迎的软件信息站点之一,包含数以百万计的帖子,涵盖编程、移动、安全、算法等与软件开发和维护相关的主题. 开发人员可以在那里自由询问并回答有关问题. 目前已有一些基于Stack Overflow数据集的研究. Barua等[3]对Stack Overflow上开发者讨论的主题和趋势进行大规模分析;Rosen等[4]通过指定研究Stack Overflow上移动开发者的问题缩小问题规模;Linares-Vásquez等[5]探索分析与移动开发问题相关的讨论主题;Yang等[6]研究安全相关问题的主题; Beyer等[7]对550个Android相关帖子进行人工分析,发现其中问题类型和问题类别之间的依赖性; Nadi等[8]通过综合Stack Overflow上前100个Java密码学相关问题实证调查开发者在使用密码学API时面临的问题. 迄今为止,未有针对Stack Overflow上机器学习相关问题的研究.
本研究旨在针对Stack Overflow,采用潜在狄利克雷分布(latent Dirichlet allocation,LDA)主题模型,进行机器学习相关主题和趋势的大规模实证研究. LDA已经被应用于分析软件工程数据呈现的趋势. Hindle等[9]将LDA应用于版本系统内提交的日志消息,用于确定在指定时间段内开发者工作围绕的主题并研究开发趋势的变化; Neuhaus等[10]将LDA应用于著名的漏洞数据库,发现特定的安全漏洞随时间变化的趋势;Thomas等[11]将LDA应用于分析软件演化,并提出LDA的变体,以更好地检测源代码中主题的趋势. 本研究将LDA应用于开发者问答网站Stack Overflow,并进行了部分改进.
截至2018年9月,Stack Overflow的公开数据集包含4 178多万个帖子,每个帖子都有1个文本(Body),用一些元数据(CreateDate、ViewCount等)来描述1个问题或1个答案. 基于帖子标签使用2个启发式方法来提取与机器学习相关的问题;基于改进的主题模型——渐进搜索过程的LDA主题模型,对不同的机器学习相关问题进行分类;在获得主题后,再利用元数据进行各种分析. 通过调查机器学习平台的讨论量、机器学习相关主题的受欢迎程度、回答难度,总结了有趣且有价值的结论,从而为相关研究人员、教育工作者和从业者提出一些启示.
1. 相关知识
1.1. Stack Overflow问答网站
1.2. LDA主题模型
主题模型将文档视为主题的概率分布,而主题是单词的概率分布. 在本研究中,文档是指帖子中的文本(如正文和标题),主题是指与文本中单词的分布相对应的高级概念. 例如,当文本中包含“use”、“error”、“code”、“run”、“trying”等词时,可以归纳该主题为“代码运行”.
LDA主题模型是著名的主题模型,被用于软件工程研究的各种任务[16-18]. 从理论上讲,LDA主题模型是生成概率模型,假定数据(一组文档)是基于特定的统计过程生成的. 具体来说,LDA主题模型包含如下3个步骤:1) LDA主题模型分别基于2个狄利克雷分布[19]生成主题分布向量t和词汇分布向量p;2) 根据主题分布向量t,LDA主题模型给每个文档分配1个主题,生成1个主题分配向量z;3) LDA主题模型用词汇分布向量p和主题分配向量z生成文档中的每个词. 通过重复K次步骤1),生成K个主题;通过重复N次步骤2)和步骤3),生成1个含有N个词汇的文档;通过重复D次步骤1)到步骤3),生成1个包含D个文档的集合.
实际上,LDA主题模型采用文档词汇矩阵a(D×N)作为输入,输出2个矩阵b(D×N)、c(K×N),即文档主题矩阵和主题词汇矩阵. 文档词汇矩阵a可以被视为词汇频率矩阵,其中
2. 研究方法
2.1. 数据采集
为了进行全面的实验研究,使用在Stack Exchange Data Dump②上名为“posts.xml”的公开数据集. 该数据集包含从2008年7月到2018年9月的41 782 536个帖子. 其中,问题帖为16 389 567个(39.23%)、答案帖为25 297 926个(60.57%)、其他类型帖为95 043个(0.20%). 每个帖子均包括正文和多个元数据,详细信息如表1所示.
表 1 帖子包含的元数据信息
Tab.1
| 名称 | 描述 | 名称 | 描述 | |
| Id | 帖子的编号 | LastEditorUserId | 最近编辑帖子的用户ID(可选) | |
| PostTypeId | 帖子的类型,1表示问题帖,2表示答案帖,其他类型不予讨论 | LastEditorDisplayName | 最近编辑帖子的用户名(可选) | |
| AcceptedAnswerId | 问题帖对应的答案帖ID(可选,仅在PostTypeId=1时出现) | LastEditDate | 最近编辑帖子的时间(可选) | |
| ParentId | 答案帖对应的问题帖ID(可选,仅在PostTypeId=2时出现) | LastActivityDate | 帖子最近活动的时间 | |
| CreationDate | 帖子的创建时间 | Title | 帖子标题(可选) | |
| Score | 游客对帖子的平均分 | Tags | 帖子标签(可选) | |
| ViewCount | 帖子的总浏览数(可选,仅在PostTypeId=1时出现) | AnswerCount | 帖子的答案帖数量(可选,仅在PostTypeId=1时出现) | |
| Body | 帖子的正文,HTML格式 | CommentCount | 帖子的评论数量 | |
| OwnerUserId | 帖子所有者的ID(可选) | FavoriteCount | 喜欢帖子的人数(可选,仅在PostTypeId=1时出现) | |
| OwnerDisplayName | 帖子所有者的用户名(可选) | ClosedDate | 帖子关闭的时间(可选,仅在帖子关闭时出现) |
如图1所示为Stack Overflow上很受欢迎的机器学习问题之一. 帖子标题为Role of Bias in Neural Networks,标签为artificial-intelligence、machine-learning、neural-network. 在标题和标签之间是帖子的正文,详细描述了问题. 在帖子的右下角还有一些元数据,如帖子的评论数、编辑日期等.
图 1

图 1 Stack Overflow上机器学习相关帖子示例
Fig.1 An example of machine-learning-related post on Stack Overflow
并不是所有与机器学习相关的问题都包含machine-learning这个标签,因此,不能仅通过检查帖子的标签来确定其是否与机器学习相关. 为了解决该问题,设计了2个启发式方法,以提取与机器学习相关的标签,然后根据标签来提取与机器学习相关的帖子. 为了找到所有与机器学习相关的帖子,首先利用标签从数据集中提取与机器学习相关的问题帖,再根据问题帖中的信息提取答案帖. 主要包括以下3个步骤:
1) 遍历数据集找到标签中包含machine-learning的问题帖,共有25 961个. machine-learning是非常宽泛的概念,1个帖子的标签可能会有更细的粒度,因此还需要考虑那些与机器学习相关但并未包含 machine-learning标签的帖子.
2) 从步骤1)中提取的25 961个帖子中提取标签,作为候选标签. 对于每个候选标签t,分别计算:步骤1)中提取的所有帖子中包含标签t的问题帖的数量a,以及原始数据集的所有帖子中包含标签t的问题帖的数量b. 令
然而,仅仅使用上面的启发式方法提取标签,还会引起另一个问题. 假设某标签只出现在整个数据集的1个帖子中,而标签machine-learning恰好同时出现在这个帖子中. 尽管此时
表 2 根据不同阈值配置得到的“machine-learning”相关结果标签集
Tab.2
| (T1, T2) | 标签集 | 标签数 |
| (0.150,0.025) | classification,deep-learning,scikit-learn,neural-network,artificial-intelligence,machine-learning,keras,svm,conv-neural-network,weka | 10 |
| (0.150,0.030) | classification,deep-learning,scikit-learn,neural-network,artificial-intelligence,machine-learning,keras,svm | 8 |
| (0.250,0.025) | classification,deep-learning,scikit-learn,neural-network,machine-learning,svm,conv-neural-network,weka | 8 |
| (0.250,0.030) | classification,deep-learning,scikit-learn,neural-network,machine-learning,svm | 6 |
| (0.350,0.025)或(0.350,0.030) | classification,machine-learning,svm | 3 |
| (>0.400,>0.080) | machine-learning | 1 |
3) 再次遍历数据集,寻找至少包含1个默认标签集中标签的问题帖(共60 028个),主要使用这些问题帖和相应答案帖进行分析.
2.2. 数据分析
数据分析主要包含2个阶段:特征提取阶段和主题模型阶段. 提取帖子的词汇频率作为特征,并提出自适应的LDA主题模型,通过梯度渐进搜索最佳主题数,将不同的机器学习帖子分组到不同的主题中.
2.2.1. 数据预处理
一个问题帖包括标题、正文和几个元数据. 为了将帖子聚类,需要构建语料库,其中每一行都是1个帖子的文本(包括正文和标题). 数据预处理步骤如下:1) 删除文本中的所有代码片段(即<code>标签),因为代码片段对主题模型没有帮助[3];2) 删除HTML标签(如<p>标签)、停用词、数字、标点符号和其他非字母字符等对主题模型无效的信息;3) 使用Snowball①词干分析器将剩下的词汇转换成原形(例如,“reading”和“reads”被简化为“read”,即词干项),以减少特征维度,将相似的词统一成共同的表示.
在上述3个步骤之后,为了进一步减少干扰,根据它们的总频次对所有的词干项进行排序,并丢弃小于10次的项,剩下的7 757个不同的词干项为最终提取的特征,所有帖子共记3 645 754个词. 计算每个帖子中每个词汇出现的次数,得到词汇频次矩阵w. 其中,
2.2.2. 寻找最佳主题数
使用LDA主题模型将帖子分类到不同的主题中. 在LDA中,主题的数量K是待定但重要的参数,其过大或过小都可能会严重影响到方法的性能. 因此,采用分梯度渐进搜索的方式,搜索K的最优值.
算法1. 自适应LDA中的主题数渐进搜索过程
输入:主题数量的搜索范围[MinTopics, MaxTopics]、 渐进梯度数组g
输出:主题的数量
1)初始时趟数i=0,根据趟数从梯度数组g中选择 梯度
2)将主题数数组k中每个主题数
3)以
4)重复步骤1)到步骤3),直到梯度数组遍历完;
5)输出最佳主题数
算法1给出了自适应LDA中的主题数渐进搜索过程. 将搜索范围设为[2,50]的整数,因为至少有2个主题,而50足以满足最大的主题数量. 渐进梯度数组g是从大到小排序的整数数组,每个值不应超过搜索范围的1/4,且最后一个梯度为1. 本研究所选取的梯度数组g=[11,5,2,1]. 以11为梯度进行初步选择,所选的主题数数组k=[2,13,24,35,46]. 最终找到的最佳主题数为9,如图2所示. 图中,Ccoh为一致性系数,n为主题数. 需要注意的是,出于性能的考虑,所得最优主题数可能并非全局最优解.
图 2
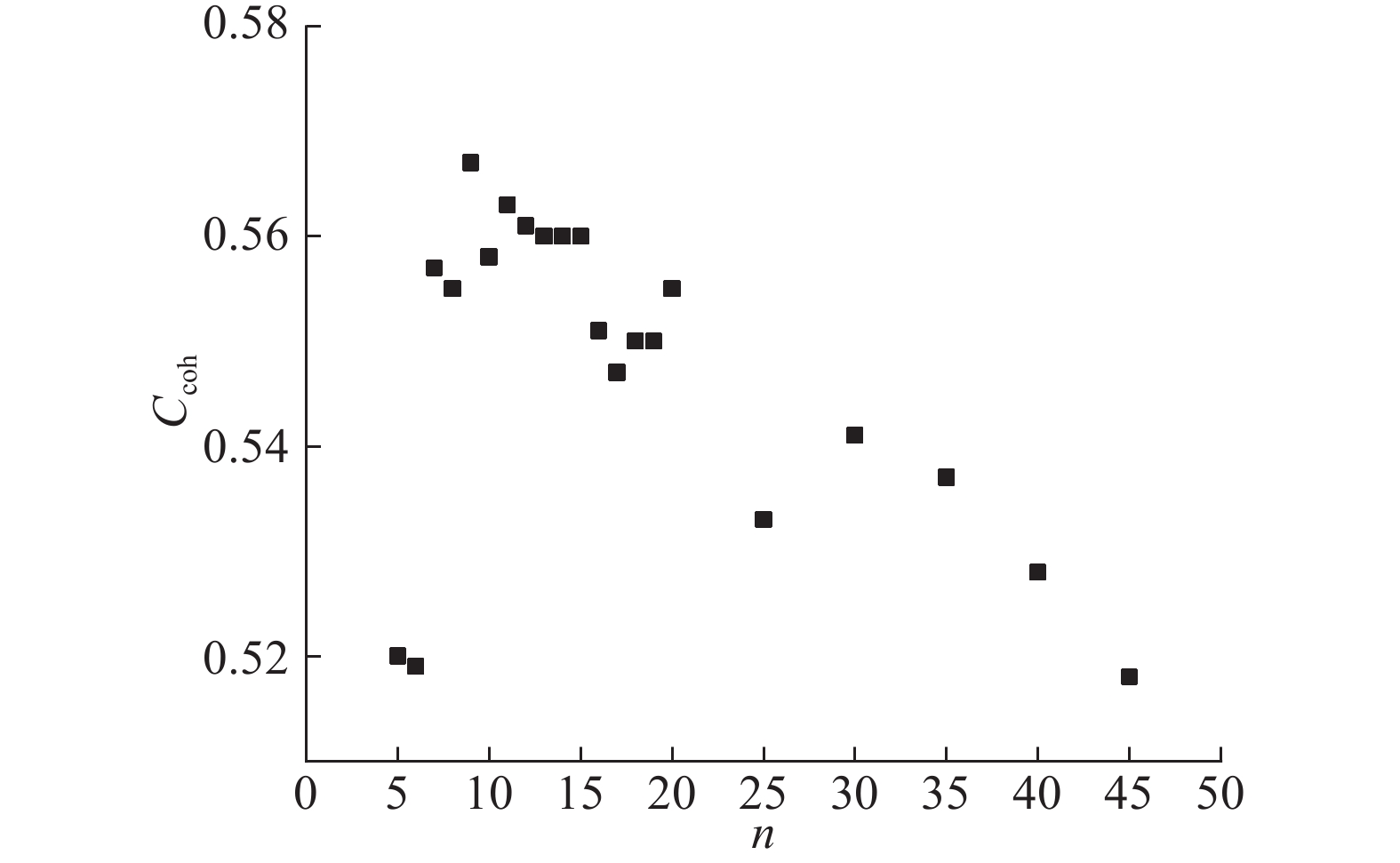
图 2 最佳主题数搜索算法过程中一致性系数的分布
Fig.2 Distribution of coherence coefficient in process of optimal topic number search algorithm
使用一致性系数评估LDA在不同主题数下的分类效果,一致性系数解决了主题模型对其输出结果可解释性低的问题. 一致性系数有
一致性系数为[−1.0,1.0]. 一致性系数越大表明聚类效果越好. 当主题数量获得较高的一致性系数时,意味着该主题数将使LDA获得较好的结果. 通过LDA的主题数渐进搜索,可以为所有机器学习问题帖找到适当数量的主题,并将每个帖子分配到相应的主题中.
3. 研究结果
对开发人员较感兴趣的4个问题进行实证研究和结果分析. 实验环境如下:处理器为Intel® CoreTM i7-6700HQ CPU @2.60GHz、RAM为16 GB、OS为Windows 10(64位).
3.1. 问题1 开发者在使用哪些机器学习平台?
利用提取的60 028个问题帖,通过分析正文、标题、标签,确定问题帖中讨论的机器学习平台,统计各机器学习平台的讨论量. 对于同一机器学习平台的同一概念,可能存在不同的表述. 因此,为各平台设置词汇表,其中包含平台名的一些泛化表述,比如H2o.ai平台,h2oai、h2o-3等词汇均属于某平台专有的词汇表. 如表3所示为前20个常用的机器学习平台或库.
表 3 不同机器学习平台的讨论帖的数量
Tab.3
| 序号 | 机器学习平台 | 讨论量 | 占比/% |
| 1 | Scikit-learn | 12 641 | 21.06 |
| 2 | TensorFlow | 11 524 | 19.20 |
| 3 | Keras | 10 842 | 18.06 |
| 4 | Caffe | 1 501 | 2.50 |
| 5 | Torch | 1 366 | 2.28 |
| 6 | Theano | 1 300 | 2.17 |
| 7 | Microsoft Cognitive Toolkit (CNTK) | 583 | 0.97 |
| 8 | AWS | 567 | 0.94 |
| 9 | XGBoost | 373 | 0.62 |
| 10 | Caret | 344 | 0.57 |
| 11 | Spark ML&MLlib | 339 | 0.56 |
| 12 | Watson | 286 | 0.48 |
| 13 | Tflearn | 224 | 0.37 |
| 14 | Mahout | 223 | 0.37 |
| 15 | H2o.ai | 209 | 0.35 |
| 16 | Blocks | 198 | 0.33 |
| 17 | MXNet | 155 | 0.26 |
| 18 | Deeplearning4j | 119 | 0.20 |
| 19 | SINGA | 98 | 0.16 |
| 20 | Accord.NET | 84 | 0.14 |
图 3

图 3 不同机器学习平台讨论帖数量占比
Fig.3 Proportion of number of discussion posts about different machine learning platforms
3.2. 问题2 Stack Overflow上提出的与机器学习相关的问题涉及哪些主题?
表 4 9个主题的归纳主题名和相关性前10的关键词
Tab.4
| 序号 | 主题名(类别) | 主题关键词(提取词干后) |
| 1 | 代码运行(代码相关) | use,error,code,run,tri,model,get,python,imag,train |
| 2 | 模型训练(模型相关) | model,imag,train,use,kera,layer,data,tensorflow,size,batch |
| 3 | 数据集分类(模型相关) | data,use,train,class,classifi,test,set,classif,model,dataset |
| 4 | 神经网络(模型相关) | network,neural,output,layer,loss,function,train,use,weight,input |
| 5 | 模型性能评估(模型相关) | use,predict,featur,model,word,data,time,text,score,valu |
| 6 | 实现细节(理论相关) | use,gradient,function,implement,learn,x,vector,calcul,algorithm,comput |
| 7 | 编程与库(代码相关) | file,line,py,packag,python,tensorflow,error,lib,c,site |
| 8 | 模型输入问题(模型相关) | input,error,shape,kera,lstm,array,model,use,sequenc,tri |
| 9 | 学习算法(理论相关) | algorithm,use,would,like,learn,tree,valu,one,data,problem |
表 5 随机抽样问题帖验证主题名
Tab.5
| 序号 | 标题 | 说明 | 主题概率 |
| 1 | Captcha Recognition using CNN not giving expected results | 题主尝试在Python中使用TensorFlow开发验证码识别程序,运行没有得到预期结果 | 代码运行:0.46 实现细节:0.31 |
| 2 | How to create Training data for Text classification on 4 categories | 题主询问如何为4个类别的文本分类创建训练数据 | 模型训练:0.42 学习算法:0.38 |
| 3 | How to use glmnet in R for classification problems | 题主想用R中的glmnet来做分类问题,并给出了样本数据和要求 | 数据集分类:0.92 |
| 4 | Properly declaring input_shape for neural network in Keras? | 题主描述在Keras中遇到的声明神经网络参数input_shape的问题 | 神经网络:0.73 代码运行:0.18 |
| 5 | R and PCA Explanation for machine learning | 题主希望解释机器学习过程中发生了什么,以阿尔茨海默病数据为例,构建2个预测模型,评估其准确度 | 模型性能评估:0.39 模型训练:0.37 |
| 6 | Keras ImageDataGenerator for Cloud ML Engine | 题主试图调用Keras的flow_from_directory方法来处理云存储中的图像,但读取数据一直失败 | 实现细节:0.77 编程与库:0.22 |
| 7 | ModuleNotFoundError: No module named 'keras' in AI DevCloud Intel | 题主在装完Keras和TensorFlow环境后,在调用ImageDataGenerator包时仍提示Keras库未安装 | 编程与库:0.90 |
| 8 | How to make this neural network traning function faster | 题主输入锯齿状阵列的变量,每个处理阶段至少需要 5 min,询问训练更快的方法 | 模型输入问题:0.49 代码运行:0.26 |
| 9 | How to classify documents using Naive Bayes and Principal Component Analysis (C#,Accord.NET) | 题主想要学习如何使用朴素贝叶斯和主成分分析对文档进行分类 | 学习算法:0.45 模型训练:0.21 |
图 4

3.3. 问题3 哪些主题在机器学习相关问题中最受欢迎?
回答此研究问题可以帮助开发人员了解机器学习相关问题的一般趋势. 为了衡量某个主题的受欢迎程度,收集与该主题相关的所有问题,根据这些问题的元数据使用4个评估指标进行评估,即平均浏览次数V、平均评论数量C、平均喜欢人数F以及问题的平均得分S. 在Stack Overflow的Data Dump中,可以直接从问题帖的ViewCount属性获得问题的浏览量,从CommentCount属性获得问题的评论数,从FavouriteCount属性获得喜欢帖子的人数,从Score属性获得帖子的得分.
实验结果如表6所示,表中列出了不同主题在这4个评估指标方面的受欢迎程度. 可以看出,学习算法、数据集分类、实现细节、代码运行是四大最受欢迎的主题. 其中,学习算法是Stack Overflow上每个初学者最普遍的问题,数据集分类是机器学习中经典和普遍的问题;模型输入问题、模型训练和模型性能评估是在用机器学习建立模型过程中,开发人员可能遇到的常见问题;学习算法、实现细节和代码运行主题的问题平均评论数和喜欢数排名较靠前,进一步表明这3个主题基于这些评估指标是较受欢迎的;相反,模型训练、编程与库似乎较少受到关注,尽管关于编程与库这一主题的问题具有较高的平均评论数. 经计算,这些机器学习相关主题的问题的平均浏览量为1 088.27,表明开发人员确实较关注机器学习领域.
表 6 基于4项评估指标的主题流行度
Tab.6
| 主题名(所属类别) | V | C | F | S |
| 学习算法(理论相关) | 1 509.89 | 1.92 | 4.38 | 2.64 |
| 数据集分类(模型相关) | 1 281.56 | 1.61 | 2.38 | 1.46 |
| 实现细节(理论相关) | 1 230.19 | 1.42 | 2.74 | 1.92 |
| 代码运行(代码相关) | 1 150.17 | 1.72 | 2.11 | 1.38 |
| 神经网络(模型相关) | 971.61 | 1.55 | 2.46 | 1.67 |
| 编程与库(代码相关) | 968.26 | 1.71 | 1.38 | 0.93 |
| 模型性能评估(模型相关) | 912.53 | 1.46 | 2.56 | 1.42 |
| 模型输入问题(模型相关) | 888.61 | 1.41 | 2.06 | 1.39 |
| 模型训练(模型相关) | 836.63 | 1.25 | 2.30 | 1.51 |
| 平均值 | 1 088.27 | 1.56 | 2.49 | 1.59 |
图 5

图 5 各主题的问题帖数逐年变化趋势
Fig.5 Trends in number of question posts on each topic yearly
3.4. 问题4 哪些与机器学习相关的主题最难回答?
该研究问题的答案可以帮助开发人员重视难题,以便他们分配更多的时间来解决这些问题. 特别是,如果某主题既流行又困难,该主题应该得到更多的关注. 参考Yang等[6]的工作,为了衡量某主题的难度,使用2个评估指标:问题从提出到得到答案的平均时间跨
Stack Overflow作为良性发展的问答社区,很大程度上得益于其问答机制,包括投票(vote)机制、声望(reputation)机制和排行榜(ranking system);提供优质回答的用户会根据投票数量获得声望值,声望和衍生系统的操作权限与排名密切相关,而各类别的排行榜对参与贡献的用户具有激励作用;Stack Overflow提供异常检测机制,保证声望的客观公正. 声望体现了用户在Stack Overflow社区的影响力,许多IT公司将其作为招聘面试中的参考指标. 因此,当某一问题有大量的浏览量,但回答很少,通常意味着只有少数人才能解决这个问题. 最极端的情况为,在很长的时间跨度中,某问题被大量用户浏览却没有被接受的回答,可以认为该问题是难题.
分别从主题中每个问题的AnswerCount和ViewCount属性中获得答案数和浏览量,计算平均值(A、V),从而计算主题的PD以衡量该主题的难度:
PD越小,表示该主题中的问题越难.
实验结果如表7所示,展示了9个主题的平均时间跨度、平均答案数和PD得分,发现不同主题在接受答案所需的平均时间跨度上有较大差异. 关于实现细节、代码运行和学习算法的问题是最难解决的3类问题,平均需要十多天才能提交和接受答案(分别为14.40、14.23、10.75 d). 而关于模型输入问题和模型训练的问题则相对容易回答,平均为4~5 d. 另外,实现细节和代码运行的PD得分较小,仅为0.08、0.10,这与第1个度量指标指征的结果一致. 此外,神经网络的时间跨度超过10 d,PD=0.09,表明它也较难回答.
表 7 基于2个指标(问题回答的平均时间跨度、答案量与浏览量的比例)的主题难度
Tab.7
| 主题名(所属类别) | Δt/d | PD/% |
| 实现细节(理论相关) | 14.40 | 0. 08 |
| 代码运行(代码相关) | 14.23 | 0.10 |
| 学习算法(理论相关) | 10.75 | 0.12 |
| 神经网络(模型相关) | 10.41 | 0.09 |
| 模型性能评估(模型相关) | 9.85 | 0.14 |
| 编程与库(代码相关) | 9.27 | 0.11 |
| 数据集分类(模型相关) | 8.75 | 0.09 |
| 模型训练(模型相关) | 5.54 | 0.10 |
| 模型输入问题(模型相关) | 4.21 | 0.11 |
第1个指标平均时间跨度和第2个指标PD不具相关性,时间跨度主要用于考察问题是否已经充分曝光,与PD的分母平均浏览量所指征信息相似. 因此,以PD指标为主,同时参考平均时间跨度. 选出PD不超过0.10且时间跨度超过10 d的主题作为难题,总共找到3个主题,即实现细节、代码运行和神经网络.
4. 结 论
基于Stack Overflow大规模的技术问题,对机器学习相关问题的主题和趋势进行分析,实验性地发现了流行的机器学习平台、受欢迎的机器学习主题和困难的机器学习主题. 本研究的处理方法和流程具有通用性,可用于分析其他技术问题的主题和趋势.
研究结果的启示如下:
(1)对研究人员的启示. 通过大规模实验研究分析了开发人员关心的机器学习相关主题,并重点探究了最受欢迎和最困难的主题. 基于已有的大量回答材料,研究人员可以研究诸如特定领域的自动问答等技术来帮助开发人员回答这些问题.
(2)对教育者的启示. 模型相关是问题最多的类别,其问题数量占Stack Overflow上所有机器学习相关问题的一半以上,表明开发人员对模型相关问题普遍困惑. 因此,教育工作者应该更加关注模型层面,尤其是模型输入和训练性能. 此外,还可以在编写的书籍或讲义中使用更多的章节去详细阐述机器学习领域的热门模型等知识,使学习者对模型有更深入的了解.
(3)对从业人员的启示. 项目经理可能希望将不同难度级别的任务分配给不同的开发人员. 与机器学习相关的三大难题分别为实现细节、代码运行和神经网络,据此,他们可以向高级开发人员分配关于实现细节的任务,向初级开发人员分配关于模型输入问题、模型训练的任务. 正确的分配可以大大缩短项目开发进度. 另外,Scikit-learn、TensorFlow、Keras是三大主流机器学习平台,建议从业者选择这些主流的机器学习平台,在遇到问题时,可以从这些社区中得到更好的支持.
有效性威胁分析如下:
(1)内部有效性. 内部有效性的挑战与本实验中的错误有关. 本研究基于标签来进行问题的提取,所以难免会遗漏一些与机器学习相关的问题. 另外,在对同一单词不同词性的统一处理上仍有不足,没有对词频过高但语意泛化的单词进行有效过滤,机器学习平台的专有词汇表也有待扩充.
(2)外部有效性. 外部有效性的挑战与本研究结果的普遍性有关. 研究仅对Stack Overflow上的60 028个机器学习的相关问题进行实验研究,实验数据集的规模还需要进一步扩展. 未来计划结合问题帖相应的答案帖进行分析,并通过调查更多的问答网站进一步扩展研究,确保得到更具普遍性的结论.
参考文献
What are developers talking about? an analysis of topics and trends in stack overflow
[J].DOI:10.1007/s10664-012-9231-y [本文引用: 4]
What are mobile developers asking about? a large scale study using stack overflow
[J].DOI:10.1007/s10664-015-9379-3 [本文引用: 2]
What security questions do developers ask? a large-scale study of stack overflow posts
[J].DOI:10.1007/s11390-016-1672-0 [本文引用: 4]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}