

以上安全现状表明,内部威胁已经是企业信息化环境下安全风险控制的新挑战. 卡耐基梅隆大学的计算机应急响应团队(CMU-CERT)根据其对内部威胁案例中内部攻击者行为特征和攻击模式等的研究,给出内部威胁人物的明确定义[3]如下:内部威胁人物是企业或组织员工(包括在职和离职)、承包商、商业伙伴以及第三方的服务提供方等,具有企业或组织的系统、网络、数据的访问权限,能够利用合法职权对企业或组织中信息或信息系统的机密性、完整性及可用性进行破坏或产生不利影响. 依据定义可知,内部威胁同外部威胁相比,具有高危性、隐蔽性、多元性的特点.
针对内部威胁人物的特点及其对企业或组织安全性的危害,目前的相关研究主要有基于主观要素的研究、基于客观要素的研究. 基于主观要素的研究包括心理学领域分析[4]和社会学领域分析[5]等;基于客观要素的研究包括基于用户命令检测[6]、基于行为日志检测[7]、基于I/O外设使用检测[8]等. 在实际研究中,心理特征及其他主观要素很难获取真实数据,同时基于心理学、社会学等的分析难以实现准确的判断和预测. 客观要素中基于用户命令的检测由于依靠的数据源单一以及模型简单导致检测率不高,基于I/O外设使用检测的模型实现较困难,所以现有研究主要基于员工行为日志进行分析. 本文基于员工行为日志信息,提出全特征信息均衡建模的内部威胁人物检测方法. 该方法通过对数据集所有特征进行交叉分组,更加充分地利用数据的特征信息,保证模型构建过程中对特征信息利用的均衡性,提高内部威胁人物的检测效果.
1. 相关工作
内部威胁人物检测本质上是基于异常的检测,即通过对日志数据中的异常或不一致的行为日志进行分析,从而检测出包含内部威胁行为的人物. 现有的内部威胁人物检测方法主要是从人物的行为日志中提取特征,利用机器学习的相关算法如K近邻(k-nearest neighbor,KNN)、支持向量机(support vector machine,SVM)、随机森林(random forest,RF)等进行模型训练和构建,最终对内部威胁人物进行检测和判定. 其中人物的行为日志主要包括系统登录/登出域、设备使用域、文件访问域、邮件使用域及网页访问域共5个域,可以基于单独的域信息对人物的行为开展针对性的单域行为模式分析,也可以结合多个域的信息进行综合性分析.
单域行为模式分析的方法通常依赖于某个用户属性来构建用户在某个检测域的域内行为模式,如李全刚等[9]分析电子邮件数据,引入基本行为模式单元挖掘用户的通信行为模式. 提取邮件通信网络的域内和域外结构特征和职能特征,通过对用户行为模式变化的分析来定位事件的发生,进一步指导内部威胁的相关工作. Camina等[10]基于文件访问域进行分析,通过文件访问间隔、文件搜索深度、文件访问频率及文件路径距离等特征,构建基于异常行为的内部威胁检测K均值近邻分类模型和支持向量机模型,依据构建的模型进行内部威胁分析. 随着内部攻击多元性的发展,内部威胁行为已经不仅仅局限于某单个域,因此在实际应用过程中,内部威胁多倾向于多域分析.
多域行为模式分析的方法选取文件访问特征、登录/登出特征、网页访问特征、设备使用特征、邮件使用特征等来进行人物的行为模式刻画,最终得到人物的行为刻画矩阵,使用算法分析人物的行为矩阵,进而检测内部威胁人物. 文雨等[11]收集了人物的5类行为日志,利用特征数据构成特征向量,应用高斯混合模型及贝叶斯信息准则,通过设定异常行为阈值或分析某一天特征向量的有无,进行内部威胁人物检测. Brdiczka等[12]使用随机森林算法检测社交网络图中潜在的威胁人物,利用图形分析技术、动态跟踪和机器学习来检测人物行为日志的异常. 目前,随着日志数据的不断累加,数据的维度信息不断扩大,导致多域行为的分析面临计算复杂度增加、维度信息利用不充分等问题.
综上所述,针对目前内部威胁人物检测方法中存在数据的多源特性、高维数据计算的复杂性、维度信息利用的不充分性等问题,本文提出全特征信息均衡建模的内部威胁人物检测方法. 该方法以多源数据为分析对象,运用异常“少而不同”的思想,即异常行为比正常行为更容易被孤立,采用数据被孤立的难易程度来衡量人物的威胁状态,简化计算复杂性;通过对数据集所有特征进行交叉分组,利用交叉分组后的特征进行孤立森林模型构建,充分利用数据的维度信息,提升内部威胁人物的检测效果.
2. 全特征信息均衡建模的内部威胁人物检测算法
2.1. 算法原理框架
全特征信息均衡建模的内部威胁人物检测方法首先从多源数据集中进行特征提取和构建,对所提特征进行交叉分组处理;利用交叉分组后的每个特征子集合构建一定数量的孤立树,最终将各个分组构建的孤立树集成起来,形成孤立森林模型. 模型构建完成后,首先令待测数据对模型进行遍历,通过数据遍历模型的平均路径长度计算数据的异常分数,依据数据的异常分数进行内部威胁人物检测,其原理框架如图1所示.
图 1

2.2. 内部威胁人物检测数据预处理
数据预处理的目的是保证数据的纯净性,提高数据的质量. 由于原始数据中往往存在噪声数据,且部分数据可能存在不完整、甚至不一致的问题,导致数据的准确性和完整性受到影响. 数据预处理阶段的工作是将空缺值、异常值进行甄别,对异常值进行剔除,对空缺值进行补全. 基于以上原则,采用如下预处理方法:1)对异常数据进行剔除,如时间记录超过24 h等不符合常规的数据;2)对空缺数据进行补全,补全的方法为均值法;3)将特征数值进行标准化处理,如将登录登出相关的时间特征转化为s.
2.3. 内部威胁人物多源数据特征提取
表 1 CERT-IT数据源详细信息
Tab.1
| 数据名称 | 内容说明 | 记录数 | 维度 |
| logon | 登录/登出日志 | 854 859 | 5 |
| device | 移动设备使用 | 405 380 | 5 |
| file | 文件操作日志 | 445 581 | 6 |
| 电子邮件日志 | 2 629 979 | 7 | |
| http | 人物上网日志 | 28 434 423 | 6 |
| psychometric | 人物心理调查 | 1 000 | 7 |
| LDAP | 2009.12-2011.05员工信息 | 1 000 | 9 |
多源数据特征提取是从多个数据源中提取人物特征,进行量化处理和特征构建. 其中,特征提取的最终目的是要进行判别,即通过所提特征能够有效地对数据进行区分,因此应以类别的可分性作为特征提取的原则,可分性越大,对判别越有利,可分性越小,对判别越不利. 在上述原则的基础上,考虑人物的行为特征,如登录时间、文件访问次数等,在保证提取的特征能够反映人物方方面面的同时,尽可能地提高判别的可分性,从而提高内部威胁人物检测的灵敏度.
CERT-IT(v4.2)内部威胁人物数据集中的原始数据为人物行为日志记录,各个子数据源中的数据不能直接作为数值化的人物特征,因此需要进行进一步的特征提取和构建.
Logon数据是人物登录登出设备产生的数据,其中包括id(事件标识)、date(时间标识)、user(人物标识)、pc(设备标识)、activity(状态标识,取值为Logon和Logoff). 在上述数据的基础上,对Logon和Logoff状态进行分时段特征提取,以6 h为一个时段间隔,将一天24 h,划分为0~6、6~12、12~18、18~24四个时段,统计每个时段内人物的最小登录/登出次数、最大登录/登出次数、登录/登出次数的众数、登录/登出的平均次数;此外,在全天的基础上统计人物最早登录/登出时间、最晚登录/登出时间、登录/登出时间的众数、登录/登出的平均时间,最终从Logon数据中提取出40维特征.
Device数据是人物连接断开可移动设备产生的数据,其中包括id(事件标识)、date(时间标识)、user(人物标识)、pc(设备标识)、activity(状态标识,取值为Connect和Disconnect). 对Device数据的特征提取方法同Logon数据提取方法相同,对Connect和Disconnect状态分别进行特征提取,得到每个时段内人物使用可移动设备的最小连接/断开次数、最大连接/断开次数、连接/断开次数的众数、连接/断开平均次数以及全天基础上的最早连接/断开时间、最晚连接/断开时间、连接/断开时间的众数、连接/断开的平均时间,最终从Device数据中提取出40维特征.
File数据是人物操作文件产生的数据,其中包括id(事件标识)、date(时间标识)、user(人物标识)、pc(设备标识)、filename(文件标识)、content(内容标识). 对File数据仅从整体进行分时频次特征提取和全时时间特征提取,得到每个时段内人物操作文件的最小次数、最大次数、操作次数的众数、平均操作次数以及全时段的最早操作时间、最晚操作时间、操作时间众数、操作平均时间,最终从File数据中提取20维特征.
Email数据是人物收发邮件产生的数据,其中包括id(事件标识)、date(时间标识)、user(人物标识)、pc(设备标识)、to(接收标识)、cc(抄送标识)、bcc(密送标识)、from(发送标识)、size(大小标识)、attachment(附件标识)、content(内容标识). 对Email数据的特征提取方法同File数据相同,得到每个时段内人物邮件活动的最小次数、最大次数、活动次数的众数、平均活动次数以及全时段的最早活动时间、最晚活动时间、活动时间众数、活动平均时间,最终从Email数据中提取20维特征.
Http数据是人物浏览网页产生的数据,其中包括id(事件标识)、date(时间标识)、user(人物标识)、pc(设备标识)、url(链接标识)、content(内容标识),对HTTP数据的处理方法同File和Email数据的方法相同,得到每个时段内人物上网活动的最小次数、最大次数、活动次数的众数、平均活动次数以及全时段的最早活动时间、最晚活动时间、活动时间众数、活动平均时间,最终从HTTP数据中提取20维特征.
Psychometric数据为人物的心理信息,具体含义如下:O(开放性评分)、C(责任感评分)、E(外向性评分)、A(宜人性评分)、N(神经质评分),评分数据具备数值化属性,因此可以直接融入特征集合. 最终从Psychometric数据中提取5维特征.
此外,利用数据集中的设备标识和人物标识统计与每个人物所关联的设备的数量,将结果融入最终特征集合作为1维特征. 以人物标识为依据,将从不同数据源中提取的数据特征整合到一起,形成最终的数据特征集.
综上所述,本文根据不同数据的特点,遵循特征提取的基本原则,对不同数据源进行特征提取,最终提取146维的人物特征用于内部威胁人物检测.
2.4. 全特征信息均衡建模的孤立森林模型构建
Liu等[14]提出的孤立森林算法利用异常“少而不同”的特点,依据数据的特征信息构建一系列的随机二叉树,即孤立树(
在孤立森林模型的构建过程中,由于每次切割数据空间划分子树时,都是在所有特征中随机选取一个特征,因此在构建完所有
1)输入特征数据集,对全特征信息均衡建模的孤立森林算法的参数进行初始化. 此处设定构建
2)采用子采样算法实现对数据集的子采样,对子采样后数据集的所有特征构成的集合依据交叉分组规则进行划分. 设数据集的全部特征集合为
3)利用上述的样本空间进行
孤立树构建算法—iTree(X′,Qj)
Input:X′-输入数据,Qj-特征选取的集合
Output:孤立树(iTree)
1:if X不可再分 then
2: return exNode{Size←|X|}
3:else
4: 从 Qj 中随机选择一个特征 q,即 q∈Qj
5: 从特征 q 在数据集的取值范围中随机选择一个值 p
6: Xl←filter(X′, q<p)
7: Xr←filter(X′, q≥p)
8: return inNode{Left←iTree(Xl),
9: Right←iTree(Xr),
10: SplitAtt←q,
11: SplitValue←p}
12:end if
在孤立树的基础上构建孤立森林. 为了保证不同树之间存在一定的差异性,采用随机采样一部分数据集的方法来构造每棵孤立树;在孤立森林构建的过程中,针对每个特征子集合分别构建一定数量的孤立树;最终将基于不同特征子集合而生成的多组孤立树集成到一起,共同组成孤立森林. 构建方法的伪代码如下.
孤立森林构建算法—iForest(X,t,φ,n,r)
Input:X-输入数据,t-孤立树的数量,φ-下采样大小,n-特征分组的组数,r-交叉因子
Output:孤立树的集合即孤立森林(iForest)
1:Initialize Forest
2:for i=1 to X. featureNum do
3: 把第i个特征放入到特征子集合Q(i−1)modn+1, ··· ,Q(i+rn−2)modn+1
4: end for
5: for j =1 to n do
6: for
7:
8:
9: end for
10: end for
11: return Forest
2.5. 全特征信息均衡建模的孤立森林模型检测
全特征信息均衡建模的孤立森林模型构建完成后,对数据集中的数据进行判定,最终的判定依据为数据的异常分数. 异常分数的定义如下:
式中:
孤立树平均路径长度计算—PathLength(x,T,hlim,e)
Input: x-测试数据,T-孤立树,hlim-树高限制,e-当前树的长度,需要初始化为0
Output:测试数据的路径长度
1:if T是外部节点or
2: return
3:end if
4:分裂属性
5:if
6: return
7:else {
8: return
9:end if
在检测阶段,
3. 实验分析
3.1. 实验数据与环境
为了验证该方法在内部威胁人物检测方面的效果,采用由CMU-CERT团队发布的CERT-IT(v4.2)内部威胁人物数据集进行实验. 该数据集包括人物的登录登出信息、邮件操作信息、文件操作信息、网络活动信息、设备使用信息、员工心理测试信息及LDAP信息,详细信息如表1所示. 基于上述原始信息进行特征提取,构建特征向量集,实验最终使用的人物特征向量是2.3节中提取的146维特征向量.
实验在Windows7操作系统的戴尔台式机和Ubuntu14.04操作系统的VMware虚拟机中进行,其中台式机配置为四核3.40 GHz的CPU以及4 GB内存,Ubuntu虚拟机配置为双核2.50 GHz的CPU以及32 GB内存.
3.2. 实验结果与分析
3.2.1. 评价指标
选择精确率(precision)、召回率(recall)、F1、AUC及算法运行时间作为评价全特征信息均衡建模的孤立森林算法性能优劣的指标.
假设混淆矩阵如表2所示.
表 2 用于内部威胁人物检测评价指标计算的混淆矩阵
Tab.2
| 样本类别 | 负类 | 正类 |
| 负类 | TN | FP |
| 正类 | FN | TP |
基于混淆矩阵模型,精确率表示在预测为正类的样本中,真正为正类的样本所占的比例,精确率越大,表示预测效果越好. 精确率的定义如下:
召回率表示预测为正类的样本数量,占总的正类样本数量的比值,召回率越大,表明更多正类样本预测正确,预测效果越好. 召回率的定义如下:
F1是结合精确率和召回率的综合指标,F1为0~1.0,且F1越大表示预测效果越好. F1定义为
ROC(receiver operating characteristic)曲线是根据一系列不同的二分类方式,FPR为假正率,TPR为真正率,曲线所覆盖的面积定义为AUC. ROC曲线和AUC都是用来评价分类模型优劣的常用指标,且AUC越大表明预测效果越好.
算法的运行时间是衡量算法性能优劣的重要指标之一. 算法的运行时间包括模型训练消耗时间和模型验证消耗时间.
3.2.2. 实验结果与分析
1)全特征信息均衡建模的孤立森林实验.
首先确定全特征信息均衡建模的孤立森林算法的交叉因子. 实验使用从CERT-IT(v4.2)数据集中提取的146维人物特征作为输入,设置算法的初始参数
图 2

在均衡建模交叉因子选择实验的基础上,比较孤立森林算法和全特征信息均衡建模的孤立森林算法在内部威协人物数据集上的运行效果. 在对数据集中的人物进行威胁判定时,由于原始数据集中每个人物都有着相应的威胁标签,可以通过程序迭代的方式确定异常判定阈值,依据程序迭代的结果将最终阈值设定为0.55;以该阈值对数据集中的每个人物作出威胁判定,将异常分数高于阈值的人物判定为内部威胁人物,最终将算法的判定结果同人物真实威胁标签进行对比. 依据对比结果统计 TN、FP、FN、TP 的数量,得到内部威胁人物检测混淆矩阵,计算算法的评价指标. 实验的最终输出为算法经过十折交叉验证后得到的精确率、召回率、F1和AUC的平均值.
图 3
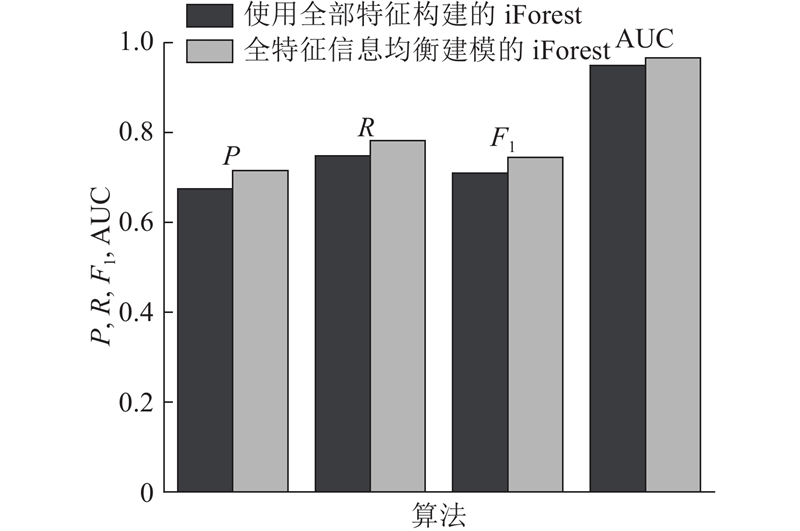
图 3 全特征信息均衡建模对比实验结果
Fig.3 Comparision of full-featured information equalization modeling
2)内部威胁人物检测算法对比分析实验.
将从CERT-IT(v4.2)内部威胁人物数据集中提取的146维的1 000条人物特征数据,按照80%和20%的比例分成训练集和测试集. 采用训练集中的数据进行相应算法的模型构建,测试集中的数据用于对各算法的检测效果进行评价. 其中全特征信息均衡建模的孤立森林算法的参数设定如下:iTree 为100棵,子采样大小为256,交叉分组的组数设定为10组,交叉因子设置为0.6,异常判定阈值设置为0.55;KNN算法中,K选取设定为12;SVM算法中,选用多项式内核函数进行模型训练;RF算法中,决策树的最大深度 max_depth 设置为10,单棵决策树使用的最大特征数 max_feature 设置为auto,决策树的数量 n_estimators 设置为10. 实验的输出为每个算法经过十折交叉验证后得到的精确率、召回率和F1的平均值.
图 4
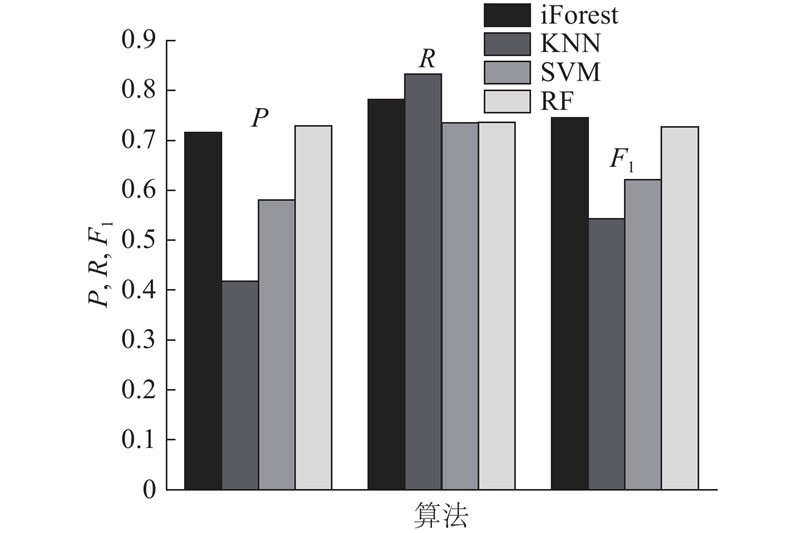
表 3 内部威胁人物检测算法运行时间对比实验结果
Tab.3
| 算法 | t/s | 算法 | t/s | |
| iForest | 0.126 | SVM | 17.353 | |
| KNN | 0.633 | RF | 127.160 |
如图4所示,全特征信息均衡建模的孤立森林算法在精确率方面优于KNN和SVM,与RF较相近;在召回率方面优于SVM和RF,与KNN结果相近;从F1方面可以看出,全特征信息均衡建模的孤立森林算法为0.745 2,高于所有对比算法. 由于F1是算法精确率和召回率的调和平均值,可以说明全特征信息均衡建模的孤立森林算法的综合表现优异. 在算法运行时间方面,由于全特征信息均衡建模的孤立森林训练过程简单,几乎不需要调整参数,算法效率比其他对比算法高. 实验结果表明,全特征信息均衡建模的孤立森林算法在检测效果和算法运行时间方面表现优异,在内部威胁人物检测方面具有较好的实用价值.
4. 讨 论
在全特征信息均衡建模的孤立森林实验中,不同交叉因子决定了构建孤立树的特征子集合中特征的数量,当交叉因子<0.4时,由于分组后的特征子集合中元素数量过少,导致构建的孤立树所包含的信息不足,对内部威胁人物的检测效果不佳;当交叉因子为0.5~0.9时,基于分组后的特征子集合构建的孤立树实现了对特征信息的均衡利用,检测效果得到提升,从折线图可以看出当交叉因子设置为0.6时,检测效果达到最佳;当交叉因子为1.0时,利用所有特征构建每棵孤立树. 实验结果表明,特征交叉分组可以提高孤立森林算法在内部威胁人物检测方面的精确率、召回率、F1及AUC,即全特征信息均衡建模的孤立森林算法能够充分地利用数据的特征信息,提高模型构建对特征利用的均衡性,具有更好的检测效果.
在对比分析实验中,全特征信息均衡建模的孤立森林算法的F1高于其他对比算法,表明该算法在内部威胁检测方面具有良好的检测效果. 在精确率和召回率方面,全特征信息均衡建模的孤立森林算法均未达到最高,这是由于孤立森林遵循正常样本点的一致性,但在真实场景中会出现正常人物在特殊的需求下进行特殊的操作;这种情况符合孤立森林对离群点的定义,而这部分正常人物没有对企业或组织进行内部威胁,因此产生了误判,但这说明全特征信息均衡建模的孤立森林算法对离群点十分敏感. 在运行时间方面,全特征信息均衡建模的孤立森林算法具有最短的运行时间,这表明该算法的计算复杂度低,运行速度快,算法效率高. 综上所述,全特征信息均衡建模的孤立森林算法能够很好地适用于内部威胁检测任务,具有较好的实用价值.
5. 结 语
本文提出全特征信息均衡建模的内部威胁人物检测方法,通过对特征集进行交叉分组并选择合适的交叉因子,实现全特征信息均衡建模;在保持较低复杂性和较高执行效率的同时,进一步提升内部威胁人物的检测效果. 实验结果表明,全特征信息均衡建模的孤立森林算法在CERT-IT(v4.2)内部威胁人物数据集上,能够充分利用数据集中的特征信息,解决因随机抽取而带来的特征信息利用不全的问题,保证孤立树构建过程中数据特征利用的均衡性,提升算法的检测效果,使得该算法能够更好地运用于内部威胁人物检测过程中. 本文的方法存在一些局限. 在对数据集的处理过程中,没有对数据集中的文本内容进行分析,如文件访问文本信息、电子邮件文本信息,上网网页文本信息等. 为了解决这些问题,下一步将研究文本分析技术,通过提取文本信息中的相关特征丰富内部威胁人物特征集,进而实现内部威胁人物的精确检测.
参考文献
Modeling and verification of insider threats using logical analysis
[J].DOI:10.1109/JSYST.2015.2453215 [本文引用: 1]
基于隐马尔可夫模型的内部威胁检测方法
[J].
Method of insider threat detection based on hidden Markov model
[J].
面向邮件网络事件检测的用户行为模式挖掘
[J].
Mining user behavior patterns for event detection in Email networks
[J].
The Windows-users and intruder simulations logs dataset (WUIL): an experimental framework for masquerade detection mechanisms
[J].DOI:10.1016/j.eswa.2013.08.022 [本文引用: 1]
面向内部威胁检测的用户跨域行为模式挖掘
[J].
Mining user cross-domain behavior patterns for insider threat detection
[J].
Isolation-based anomaly detection
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}