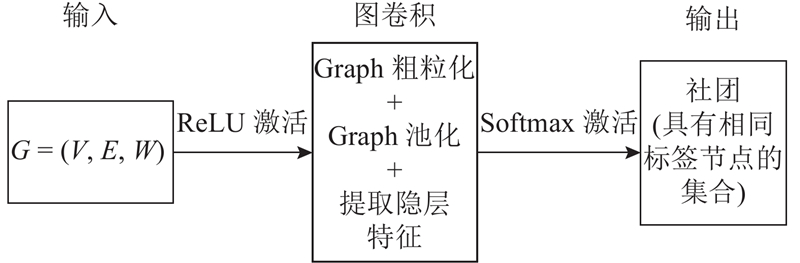
通常,复杂网络可以抽象为图 $G = (V,E,W)$ $V = \{ {v_i},i = 1,2,\cdots,n\} $ $E = \{ {e_i},i = 1,2,\cdots,m\} $ $({v_i},{v_j}) \in E$ ${ W} \in {{ R}^{N \times N}}$ A ${v_i}$ ${v_j}$ ${A_{ij}} = 1$ ${A_{ij}} = 0$ . 对图中的每个节点分配一个唯一标签,表示社团,则社团结构为一个标签向量 $s:V \to $ $ \{ 1,K\} $ .
[1]
SUN Y, WANG X, TANG X. Deeply learned face representations are sparse, selective, and robust [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 2892–2900.
[本文引用: 1]
[2]
XUE S, YAN Z. Improving latency-controlled BLSTM acoustic models for online speech recognition [C] // Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing . New Orleans: IEEE, 2017: 5340–5344.
[本文引用: 1]
[3]
奚雪峰, 周国栋 面向自然语言处理的深度学习研究
[J]. 自动化学报 , 2016 , 42 (10 ): 1445 - 1465
[本文引用: 1]
XI Xue-Feng, ZHOU Guo-Dong A survey on deep learning for natural language processing
[J]. Acta Automatica Sinica , 2016 , 42 (10 ): 1445 - 1465
[本文引用: 1]
[4]
FEDERICO M, DAVIDE B, JONATHAN M, et al. Geometric deep learning on graphs and manifolds using mixture model CNNs [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 5425–5434.
[本文引用: 1]
[5]
MICHAEL M. B, JOAN B, YANN L, et al. Geometric deep learning: going beyond euclidean data
[J]. IEEE Signal Processing Magazine , 2017 , 34 (4 ): 18 - 42
DOI:10.1109/MSP.2017.2693418
[本文引用: 1]
[6]
彭静, 廖乐健, 翟英, 等 谱聚类在社团发现中的应用
[J]. 北京理工大学学报 , 2016 , 36 (7 ): 701 - 705
[本文引用: 1]
PENG Jing, LIAO Le-jian, ZHAI Ying, et al Spectral clustering for community detection
[J]. Transactions of Beijing Institute of Technology , 2016 , 36 (7 ): 701 - 705
[本文引用: 1]
[7]
SHIGA M, TAKIGAWA I, MAMITSUKA H A spectral approach to clustering numerical vectors as nodes in a networks
[J]. Pattern Recognition , 2011 , 44 (2 ): 236 - 251
DOI:10.1016/j.patcog.2010.08.010
[本文引用: 1]
[8]
RAGHAVAN U N, ALBERT R, KUMARA S Near linear-time algorithm to detect community structures in large-scale networks
[J]. Physical Review E , 2007 , 76 (3 ): 036106
DOI:10.1103/PhysRevE.76.036106
[本文引用: 1]
[9]
WANG M, CAI X, ZENG Y, et al. A Community detection algorithm based on jaccard similarity label propagation [C] // Intelligent Data Engineering and Automated Learning . Guilin: IDEAL, 2017: 45–52.
[本文引用: 1]
[10]
刘大有, 金弟, 何东晓, 等 复杂网络社区挖掘综述
[J]. 计算机研究与发展 , 2013 , 50 (10 ): 2140 - 2154
DOI:10.7544/issn1000-1239.2013.20120357
[本文引用: 1]
LIU Da-you, JIN Di, HE Dong-xiao, et al Community ming in complex networks
[J]. Journal of Computer Research and Development , 2013 , 50 (10 ): 2140 - 2154
DOI:10.7544/issn1000-1239.2013.20120357
[本文引用: 1]
[12]
JOAN B, LI X. Community Detection with graph neural networks. [27 May 2017]. arXiv: 1705.08415v2 [stat.ML].
[本文引用: 1]
[13]
DUVENAUD D K, MACLAURIN D, IPARRAGUIRRE J , et al. Convolutional networks on graphs for learning molecular fingerprints [C] // Advances in Neural Information Processing Systems . Montreal: NIPS, 2015: 2224–2232.
[本文引用: 1]
[14]
YANG Z, WILLIAM C, RUSLAN S. Revisiting semi-supervised learning with graph embeddings [C] // Proceedings of the 33nd International Conference on Machine Learning . New York: ICML, 2016: 40–48.
[本文引用: 10]
[15]
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C] // 5th International Conference on Learning Representations . Toulon: ICLR, 2016. arXiv: 1609.02907.
[本文引用: 8]
[16]
LI R, WANG S, ZHU F, et al. Adaptive graph convolutional neural networks [C] // The Thirty-Second AAAI Conference on Artificial Intelligence . Louisiana: AAAI, 2018. arXiv: 1801.03226.
[本文引用: 1]
[17]
DHILLON I S, GUAN Y, KULIS B Weighted graph cuts without eigenvectors a multilevel approach
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2007 , 29 (11 ): 1944 - 57
DOI:10.1109/TPAMI.2007.1115
[本文引用: 1]
[18]
Mark Newman network data [DS]. [2017-12-05]. http://www-personal.umich.edu//~mejn/netdata.
[本文引用: 1]
[19]
HAMILTON W L, YING R, LESKOVEC J. Inductive Representation Learning on Large Graphs [C] // The Thirty-first Annual Conference on Neural Information Processing Systems . Long Beach: NIPS, 2017: 1025–1035.
[本文引用: 1]
[20]
KINGMA D P, BA J. Adam: a method for stochastic optimization [C] // In International Conference on Learning Representations . San Diego: ICLR, 2015.
[本文引用: 1]
[21]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE Computer Society, 2016: 770–778.
[本文引用: 1]
1
... 近年来,深度学习被广泛应用在图像识别[1 ] 、语音识别[2 ] 、自然语言处理[3 ] 等领域,而对于在复杂网络如社交网络、电信网络、蛋白质相互作用网络以及道路网络等方面的应用,还有很大的研究空间. 目前,研究者将深度学习的思想应用到图论[4 -5 ] 上,使采用深度学习的方法处理图结构数据并挖掘复杂网络社团结构成为可能. ...
1
... 近年来,深度学习被广泛应用在图像识别[1 ] 、语音识别[2 ] 、自然语言处理[3 ] 等领域,而对于在复杂网络如社交网络、电信网络、蛋白质相互作用网络以及道路网络等方面的应用,还有很大的研究空间. 目前,研究者将深度学习的思想应用到图论[4 -5 ] 上,使采用深度学习的方法处理图结构数据并挖掘复杂网络社团结构成为可能. ...
面向自然语言处理的深度学习研究
1
2016
... 近年来,深度学习被广泛应用在图像识别[1 ] 、语音识别[2 ] 、自然语言处理[3 ] 等领域,而对于在复杂网络如社交网络、电信网络、蛋白质相互作用网络以及道路网络等方面的应用,还有很大的研究空间. 目前,研究者将深度学习的思想应用到图论[4 -5 ] 上,使采用深度学习的方法处理图结构数据并挖掘复杂网络社团结构成为可能. ...
面向自然语言处理的深度学习研究
1
2016
... 近年来,深度学习被广泛应用在图像识别[1 ] 、语音识别[2 ] 、自然语言处理[3 ] 等领域,而对于在复杂网络如社交网络、电信网络、蛋白质相互作用网络以及道路网络等方面的应用,还有很大的研究空间. 目前,研究者将深度学习的思想应用到图论[4 -5 ] 上,使采用深度学习的方法处理图结构数据并挖掘复杂网络社团结构成为可能. ...
1
... 近年来,深度学习被广泛应用在图像识别[1 ] 、语音识别[2 ] 、自然语言处理[3 ] 等领域,而对于在复杂网络如社交网络、电信网络、蛋白质相互作用网络以及道路网络等方面的应用,还有很大的研究空间. 目前,研究者将深度学习的思想应用到图论[4 -5 ] 上,使采用深度学习的方法处理图结构数据并挖掘复杂网络社团结构成为可能. ...
Geometric deep learning: going beyond euclidean data
1
2017
... 近年来,深度学习被广泛应用在图像识别[1 ] 、语音识别[2 ] 、自然语言处理[3 ] 等领域,而对于在复杂网络如社交网络、电信网络、蛋白质相互作用网络以及道路网络等方面的应用,还有很大的研究空间. 目前,研究者将深度学习的思想应用到图论[4 -5 ] 上,使采用深度学习的方法处理图结构数据并挖掘复杂网络社团结构成为可能. ...
谱聚类在社团发现中的应用
1
2016
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
谱聚类在社团发现中的应用
1
2016
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
A spectral approach to clustering numerical vectors as nodes in a networks
1
2011
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
Near linear-time algorithm to detect community structures in large-scale networks
1
2007
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
1
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
复杂网络社区挖掘综述
1
2013
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
复杂网络社区挖掘综述
1
2013
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
Community detection in complex networks using extremal optimization
1
2005
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
1
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
1
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
10
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
... 为了验证本研究提出方法的有效性,采用社会网络数据集[18 ] :Zachary karate club美国大学空手道俱乐部、College Football美国大学生足球联赛网络,引文网络数据集[14 ] :Cora、Citeseer和Pubmed,大规模数据知识图谱NELL[14 ] 以及社交新闻网络Reddit [19 ] 进行验证. 社会网络数据集Zachary karate club节点表示俱乐部中的成员,边表示成员之间存在的友谊关系,College Football节点代表足球队,2个节点之间的边表示2支球队之间进行过1场比赛,参赛的115支大学生代表队被分为12个联盟. 引文网络数据集包含作者、引文等信息,每个节点表示文档,边表示文档之间的引用关系,特征表示描述文档的词汇数,社团表示文档的主题. Reddit是一个大型的在线论坛,用户可以在不同的主题社区发布和评论内容,节点表示论坛上的帖子,边表示同1个用户对2个帖子都发表过评论,社团表示帖子所在的社区,特征表示描述帖子的词汇. 数据的统计信息如表1 所示. ...
... [14 ]以及社交新闻网络Reddit [19 ] 进行验证. 社会网络数据集Zachary karate club节点表示俱乐部中的成员,边表示成员之间存在的友谊关系,College Football节点代表足球队,2个节点之间的边表示2支球队之间进行过1场比赛,参赛的115支大学生代表队被分为12个联盟. 引文网络数据集包含作者、引文等信息,每个节点表示文档,边表示文档之间的引用关系,特征表示描述文档的词汇数,社团表示文档的主题. Reddit是一个大型的在线论坛,用户可以在不同的主题社区发布和评论内容,节点表示论坛上的帖子,边表示同1个用户对2个帖子都发表过评论,社团表示帖子所在的社区,特征表示描述帖子的词汇. 数据的统计信息如表1 所示. ...
... 为了验证本研究提出方法的准确率,采用社会网络、引文网络、知识图谱以及社交新闻网络数据集进行实验,超参数设置主要有:随机丢弃率为0.5,L2正规化的权重衰减系数为 $5 \times {10^{ - 4}}$ $1 \times {10^{ - 6}}$ 14 ]和[15 ]对比如表3 所示. ...
... Accuracy comparison of different data sets under same network layer using different methods
Tab.3 % 数据集 文献[14 ] 文献[15 ] 本文方法 Karate − − 88.9 Footballs − − 93.3 Cora 75.7 81.5 81.7 Citeseer 64.7 70.3 73.1 Pubmed 77.2 79.0 82.3 NELL 61.9 66.0 73.6 Reddit − − 93.0
由表3 可知,在准确性方面,对于节点数较少的社会网络数据集Karate和Footballs,测试的准确率分别为88. 9%、93.3%. 与文献[14 ]相比,所提方法的准确性显著提高,引文网络数据集Cora的准确率提高了6.0%,Citeseer的准确率提高了8.4%,Pubmed的准确率提高了2.3%;知识图谱数据集NELL的准确率提高了6.4%. 与文献[15 ]相比,所提方法的引文网络数据集Cora、Citeseer、Pubmed的准确率分别提高了0.2%、2.8%、3.3%;知识图谱数据集NELL的准确率提高了7.6%. 并且所提方法可扩展到大规模数据集Reddit,准确性高达93%. ...
... 由表3 可知,在准确性方面,对于节点数较少的社会网络数据集Karate和Footballs,测试的准确率分别为88. 9%、93.3%. 与文献[14 ]相比,所提方法的准确性显著提高,引文网络数据集Cora的准确率提高了6.0%,Citeseer的准确率提高了8.4%,Pubmed的准确率提高了2.3%;知识图谱数据集NELL的准确率提高了6.4%. 与文献[15 ]相比,所提方法的引文网络数据集Cora、Citeseer、Pubmed的准确率分别提高了0.2%、2.8%、3.3%;知识图谱数据集NELL的准确率提高了7.6%. 并且所提方法可扩展到大规模数据集Reddit,准确性高达93%. ...
... Comparison of computational time-consuming of different data sets using different methods
Tab.5 数据集 文献[14 ] 文献[15 ] 本文方法 Karate − − 0.08 Footballs − − 0.06 Cora 13 4 3 Citeseer 26 7 5 Pubmed 25 38 40 NELL 185 48 32 Reddit − − 68
由表5 可知,在计算耗时方面,与文献[14 ]的方法对比,所提方法的计算耗时明显下降,特别是对于大数据集NELL,所提方法的计算效率明显提高;与文献[15 ]相比,除了Pubmed数据集之外,采用所提方法的计算耗时均有所下降,并且适用于更大规模的数据集. 由此可知,本文提出的方法在保证社团发现准确性较高的情况下,计算效率也显著提高,但是对于大数据的计算效率仍然有待提高. ...
... 由表5 可知,在计算耗时方面,与文献[14 ]的方法对比,所提方法的计算耗时明显下降,特别是对于大数据集NELL,所提方法的计算效率明显提高;与文献[15 ]相比,除了Pubmed数据集之外,采用所提方法的计算耗时均有所下降,并且适用于更大规模的数据集. 由此可知,本文提出的方法在保证社团发现准确性较高的情况下,计算效率也显著提高,但是对于大数据的计算效率仍然有待提高. ...
... 为了验证本文方法训练时的计算占用内存,使用数据集Cora、Pubmed以及Reddit进行实验. 实验结果如图4 所示. 可知,与文献[14 ]和[15 ]对比,所提方法采用了重要性抽样,因此在遍历样本时,直接采样的是图的节点而不是节点的邻域,从而减少了计算占用空间. 对于引文网络数据集,采用本文方法计算时内存空间减少了一半以上,并且适用于大规模数据集. ...
... 本研究提出了基于重要性抽样的图卷积社团发现方法,将复杂网络转化为易于处理的图结构数据,并且通过卷积层对图的粗粒化和池化操作,提高了社团发现的准确性. 在采用梯度下降法训练网络时,使用重要性抽样改变样本的分布来缩减方差,节省了梯度计算时间. 与文献[14 ]和[15 ]相比,提出的方法使用了不同数据集,在提高社团发现准确性的情况下,计算效率也有所提高,并且适用于大规模社交新闻网络数据集;同时,计算时占用的内存空间也明显减少. 随着网络中节点数目的增加,采用本研究方法可以得到更好的效果,未来进一步研究工作需要提升大规模数据的计算效率. ...
8
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
... 为了验证本研究提出方法的准确率,采用社会网络、引文网络、知识图谱以及社交新闻网络数据集进行实验,超参数设置主要有:随机丢弃率为0.5,L2正规化的权重衰减系数为 $5 \times {10^{ - 4}}$ $1 \times {10^{ - 6}}$ 14 ]和[15 ]对比如表3 所示. ...
... Accuracy comparison of different data sets under same network layer using different methods
Tab.3 % 数据集 文献[14 ] 文献[15 ] 本文方法 Karate − − 88.9 Footballs − − 93.3 Cora 75.7 81.5 81.7 Citeseer 64.7 70.3 73.1 Pubmed 77.2 79.0 82.3 NELL 61.9 66.0 73.6 Reddit − − 93.0
由表3 可知,在准确性方面,对于节点数较少的社会网络数据集Karate和Footballs,测试的准确率分别为88. 9%、93.3%. 与文献[14 ]相比,所提方法的准确性显著提高,引文网络数据集Cora的准确率提高了6.0%,Citeseer的准确率提高了8.4%,Pubmed的准确率提高了2.3%;知识图谱数据集NELL的准确率提高了6.4%. 与文献[15 ]相比,所提方法的引文网络数据集Cora、Citeseer、Pubmed的准确率分别提高了0.2%、2.8%、3.3%;知识图谱数据集NELL的准确率提高了7.6%. 并且所提方法可扩展到大规模数据集Reddit,准确性高达93%. ...
... 由表3 可知,在准确性方面,对于节点数较少的社会网络数据集Karate和Footballs,测试的准确率分别为88. 9%、93.3%. 与文献[14 ]相比,所提方法的准确性显著提高,引文网络数据集Cora的准确率提高了6.0%,Citeseer的准确率提高了8.4%,Pubmed的准确率提高了2.3%;知识图谱数据集NELL的准确率提高了6.4%. 与文献[15 ]相比,所提方法的引文网络数据集Cora、Citeseer、Pubmed的准确率分别提高了0.2%、2.8%、3.3%;知识图谱数据集NELL的准确率提高了7.6%. 并且所提方法可扩展到大规模数据集Reddit,准确性高达93%. ...
... Comparison of computational time-consuming of different data sets using different methods
Tab.5 数据集 文献[14 ] 文献[15 ] 本文方法 Karate − − 0.08 Footballs − − 0.06 Cora 13 4 3 Citeseer 26 7 5 Pubmed 25 38 40 NELL 185 48 32 Reddit − − 68
由表5 可知,在计算耗时方面,与文献[14 ]的方法对比,所提方法的计算耗时明显下降,特别是对于大数据集NELL,所提方法的计算效率明显提高;与文献[15 ]相比,除了Pubmed数据集之外,采用所提方法的计算耗时均有所下降,并且适用于更大规模的数据集. 由此可知,本文提出的方法在保证社团发现准确性较高的情况下,计算效率也显著提高,但是对于大数据的计算效率仍然有待提高. ...
... 由表5 可知,在计算耗时方面,与文献[14 ]的方法对比,所提方法的计算耗时明显下降,特别是对于大数据集NELL,所提方法的计算效率明显提高;与文献[15 ]相比,除了Pubmed数据集之外,采用所提方法的计算耗时均有所下降,并且适用于更大规模的数据集. 由此可知,本文提出的方法在保证社团发现准确性较高的情况下,计算效率也显著提高,但是对于大数据的计算效率仍然有待提高. ...
... 为了验证本文方法训练时的计算占用内存,使用数据集Cora、Pubmed以及Reddit进行实验. 实验结果如图4 所示. 可知,与文献[14 ]和[15 ]对比,所提方法采用了重要性抽样,因此在遍历样本时,直接采样的是图的节点而不是节点的邻域,从而减少了计算占用空间. 对于引文网络数据集,采用本文方法计算时内存空间减少了一半以上,并且适用于大规模数据集. ...
... 本研究提出了基于重要性抽样的图卷积社团发现方法,将复杂网络转化为易于处理的图结构数据,并且通过卷积层对图的粗粒化和池化操作,提高了社团发现的准确性. 在采用梯度下降法训练网络时,使用重要性抽样改变样本的分布来缩减方差,节省了梯度计算时间. 与文献[14 ]和[15 ]相比,提出的方法使用了不同数据集,在提高社团发现准确性的情况下,计算效率也有所提高,并且适用于大规模社交新闻网络数据集;同时,计算时占用的内存空间也明显减少. 随着网络中节点数目的增加,采用本研究方法可以得到更好的效果,未来进一步研究工作需要提升大规模数据的计算效率. ...
1
... 传统的复杂网络社团发现方法有谱聚类方法[6 -7 ] 、标签传播方法[8 -9 ] 、模块度优化方法[10 -11 ] 等,这些方法在基于大数据的复杂性科学研究上效果较差. 文献[12 ]结合随机块模型和图神经网络,提出了一种基于图神经网络的社团发现方法,为复杂网络社团发现的研究提供了新思路. 大多数图神经网络模型都有一个通用的架构,这些模型统称为图卷积网络. 之所以称之为卷积,是因为滤波器参数通常在图中所有位置共享[13 ] . 针对图结构数据,目前很多研究者提出了不同的图卷积神经网络. Yang等[14 ] 通过应用对称拉普拉斯模块作为图的有效嵌入机制提出了图卷积神经网络模型,然而该方法限制了其光谱近似的表达力,并且限制了在稀疏图中的应用. Kipf等[15 ] 根据频谱图卷积使用一阶近似简化计算的方法,直接操作于图结构数据的网络模型,提出了一种简单有效的层式传播方法,并验证了图结构神经网络模型可以处理图数据中节点半监督学习问题,但是在训练时由于跨层的递归邻域扩展,运算时间和内存消耗很多. 此外,Li等[16 ] 提出自适应图卷积神经网络,输入可以是多种图结构的原始数据,该网络不使用共享频谱核,而是给批量中的每个样本一个特定的图拉普拉斯矩阵,客观描述其独特拓扑结构. 根据其独特的图拓扑,定制化图拉普拉斯算子将带来定制化的频谱滤波器. 但是,该网络在训练时效率较低,并且无法扩展到大规模数据集上. ...
Weighted graph cuts without eigenvectors a multilevel approach
1
2007
... 池化操作需要为图上的节点选择适当的邻域,使相似的节点能够聚集在一起,相当于保留局部几何结构图的多尺度聚类. 然而图的聚类是一个难题,并且必须使用近似值. 虽然目前有许多聚类技术,如谱聚类方法,但是为了使每个层产生一个对应于不同的数据域的粗粒化图,需要采用多层次聚类算法. 此外,还需要通过图的大小控制图的粗粒化和池化. 本研究采用Graclus多层聚类算法的粗化阶段[17 ] 进行图的粗粒化,并采用归一化剪切对图进行归一化处理. ...
1
... 为了验证本研究提出方法的有效性,采用社会网络数据集[18 ] :Zachary karate club美国大学空手道俱乐部、College Football美国大学生足球联赛网络,引文网络数据集[14 ] :Cora、Citeseer和Pubmed,大规模数据知识图谱NELL[14 ] 以及社交新闻网络Reddit [19 ] 进行验证. 社会网络数据集Zachary karate club节点表示俱乐部中的成员,边表示成员之间存在的友谊关系,College Football节点代表足球队,2个节点之间的边表示2支球队之间进行过1场比赛,参赛的115支大学生代表队被分为12个联盟. 引文网络数据集包含作者、引文等信息,每个节点表示文档,边表示文档之间的引用关系,特征表示描述文档的词汇数,社团表示文档的主题. Reddit是一个大型的在线论坛,用户可以在不同的主题社区发布和评论内容,节点表示论坛上的帖子,边表示同1个用户对2个帖子都发表过评论,社团表示帖子所在的社区,特征表示描述帖子的词汇. 数据的统计信息如表1 所示. ...
1
... 为了验证本研究提出方法的有效性,采用社会网络数据集[18 ] :Zachary karate club美国大学空手道俱乐部、College Football美国大学生足球联赛网络,引文网络数据集[14 ] :Cora、Citeseer和Pubmed,大规模数据知识图谱NELL[14 ] 以及社交新闻网络Reddit [19 ] 进行验证. 社会网络数据集Zachary karate club节点表示俱乐部中的成员,边表示成员之间存在的友谊关系,College Football节点代表足球队,2个节点之间的边表示2支球队之间进行过1场比赛,参赛的115支大学生代表队被分为12个联盟. 引文网络数据集包含作者、引文等信息,每个节点表示文档,边表示文档之间的引用关系,特征表示描述文档的词汇数,社团表示文档的主题. Reddit是一个大型的在线论坛,用户可以在不同的主题社区发布和评论内容,节点表示论坛上的帖子,边表示同1个用户对2个帖子都发表过评论,社团表示帖子所在的社区,特征表示描述帖子的词汇. 数据的统计信息如表1 所示. ...
1
... 为了验证本文方法的网络深度对准确性的影响,在本实验中,采用引文网络数据集,通过设置不同的网络层数,探讨其对社团发现准确性的影响. 训练网络时设置的迭代次数为300,采用Adam优化学习算法[20 ] ,学习速率为0.01. 当交叉验证损失在连续10次迭代后不再下降时,停止训练. 其他超参数设置如下: 设置第一层和最后一层随机丢弃率(dropout rate)为0.5,第一层L2正则化的权重衰减系数为 $5 \times {10^{ - 4}}$ 图3 所示,同时对比了在隐藏层之间使用残差连接[21 ] 的效果. 图3 中,L 为网络层数;R acc 为社团检测的准确性,Res代表残差连接层. ...
1
... 为了验证本文方法的网络深度对准确性的影响,在本实验中,采用引文网络数据集,通过设置不同的网络层数,探讨其对社团发现准确性的影响. 训练网络时设置的迭代次数为300,采用Adam优化学习算法[20 ] ,学习速率为0.01. 当交叉验证损失在连续10次迭代后不再下降时,停止训练. 其他超参数设置如下: 设置第一层和最后一层随机丢弃率(dropout rate)为0.5,第一层L2正则化的权重衰减系数为 $5 \times {10^{ - 4}}$ 图3 所示,同时对比了在隐藏层之间使用残差连接[21 ] 的效果. 图3 中,L 为网络层数;R acc 为社团检测的准确性,Res代表残差连接层. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}