

图像目标检测是指识别图像中的目标并在图像中确定这些目标的位置及尺寸. 近几年,基于深度学习的图像目标检测,特别是基于深度卷积神经网络的图像目标检测技术发展迅速. 从2013年Sermanet 等[1]提出的基于深度卷积网络和滑动窗口的目标检测方法在检测精度上有大幅度提升,到后来的基于区域建议(region proposal,RP)在速度上的大幅度提升,目标检测方法一直是研究热点.
本文基于区域建议网络(region proposal network,RPN)[2]提出一种新的目标检测网络结构. 该网络结构采用一种基于特征金字塔的多尺度全卷积结构,能够实现对多尺度目标的精准检测;通过对检测到的目标进行后处理消除冗余目标窗口,并精修目标窗口的位置;最后在PASCAL VOC 2007、PASCAL VOC 2012以及古代绘画数据集上进行实验及分析.
1. 相关工作
目标检测技术的研究工作,经历了基于图像的全局特征阶段、基于图像局部特征阶段,发展到现在的基于深度学习特征的阶段.
Krizhevsky等[8]采用卷积神经网络大幅提升了图像分类的精度,推动了卷积神经网络在目标检测研究工作中的应用. Sermanet等[1]采用卷积神经网络和滑动窗口实现了多尺度目标检测,但其中的滑动窗口技术导致检测结果时间效率低计算代价高. 针对在不降低精度的情况下提升目标检测速度,出现了一些基于RP的目标检测方法. Girshick等[9]提出了RCNN(regions with CNN features)目标检测网络,采用RP的方式大幅减少图像中的候选窗口从而减少了计算量并提升了检测速度,在PASCAL VOC数据集上取得了54%的期望平均精度(mean average precision,MAP),高出基于HOG特征的变形部件模型(deformable part model,DPM)检测方法[10-11]约20%. 后续Girshick等提出的Fast RCNN和Ren等[2]提出的Faster RCNN[2],以及SPP[13]、PYN[14]、Mask-RCNN[15]都是基于RP的目标检测方法,克服了滑动窗口暴力计算的缺陷.
除了上述基于RP的目标检测工作以外,许多方法使用卷积神经网络中不同的层来提高检测和分割的性能. Redmon等[16]通过分别累加不同尺度不同类别的特征实现语义分割. Simonyan等[17]则先联合多个层的特征,再对变换的特征求和. Liu等[18]在没有组合特征或分数的条件下,在多个特征层次上预测对象. Russakovsky等[19]通过联合低级别语义特征提高图像分割的性能. Ghiasi等[20]提出了一种拉普拉斯金字塔全卷积网络(fully convolutional networks,FCNs)逐步细化分割. 这些方法采用具有金字塔形状的体系结构,与特征化的图像金字塔主要的区别在于各个层次的预测是独立的,仍然需要跨尺度识别检测目标. Liu等[16,18]提出的方法是近年出现的回归方法,相比RP方法,目标检测的速度更快,可在视频中进行实时目标检测.
2. 基于特征金字塔的多尺度全卷积目标检测
2.1. 多尺度全卷积图像目标检测网络
目标检测任务常基于RP方法结合分类器和回归器完成目标检测. Faster-RCNN的RPN方法在最后一层卷积特征图上滑动3×3的全卷积核,每个像素生成一个256维(或512维)的特征向量,再结合anchor机制得到区域建议. 本研究在RPN的基础上提出一种基于特征金字塔的网络结构,结合多尺度的全卷积操作完成多尺度、不分类别的目标检测任务. 将该目标检测网络命名为“多尺度全卷积目标检测网络”,简称“多尺度全卷积网络”. 多尺度全卷积网络的结构如图1所示,基于VGG16网络模型[17]的特征提取方法,卷积特征图按尺寸分为5级. 将各级的最后一个卷积特征图作为该级的特征表示,如图1所示,立方体的边框为该级特征表示,其中W×H为特征图的分辨率. Zeiler等[21]提出,不同卷积级别的图像卷积特征分别描述了不同级别的语义,卷积层越深则图像特征的语义级别越高,图1的5级特征图对应5级图像语义.
图 1

图 1 多尺度全卷积目标检测网络结构图
Fig.1 Structure chart of multi-scale and full convolution target detection network
将最后3级特征图通过侧连接构造成新特征金字塔,如图1中虚线部分所示. 在特征金字塔的3层特征图上进行3个不同尺度的卷积核的卷积操作. 这3个卷积核的尺度分别为9×9、 6×6、 3×3. 在对应的特征图上滑动这3个卷积核,则每像素生成一个512维的特征向量,取K个anchor(以该像素点为中心的矩形框)检测像素点周围的目标. 令K=15,组合自5类尺寸{512,256,128,64,32}和3类高宽比{1∶1,1∶2,2∶1}. 因此每个特征图有W×H×K个anchor.
卷积层完成操作之后,连接多任务学习模块,该模块内并行运行分类器和边框回归器,全连接输入为前述步骤生成的512维特征向量. 分类器共输出2K个结点,表示K个anchor检测到目标的概率. 边框回归器的输出共4K个结点,表示K个anchor平移变换及缩放变换.
2.1.1. 侧连接
针对上述问题,基于侧连接方法构造新特征金字塔,步骤如下:
1)输入图像进入卷积网络,逐步池化,生成5个级别的卷积特征,每级最后一层的特征图代表该级别的特征.
2)按从后到前的顺序上对最后3级特征图实施采样操作,使得前、后两级特征图具有同样尺寸.
3)对前一级特征图进行卷积运算,卷积核大小为1×1,将卷积核数设为本级通道数.
4)将步骤2)、3)生成的特征图按像素求和,生成新特征图.
5)对每一级特征图,按从后到前的顺序,重复迭代步骤2)、3)、4),直到生成3张新特征图,组成新特征金字塔.
6)上采样操作会产生反走样误差,故对新特征金字塔每层特征图再卷积运算,卷积核为3×3,以减弱误差影响.
侧连接是指对步骤1)和4)中的上采样操作按像素进行求和操作.
2.1.2. 多尺度全卷积
无论新特征金字塔各层特征表达能力是否足够强,因各层特征图尺度有别,若使用固定尺寸的小型卷积网络进行全卷积滑动操作,则会导致滑动窗口对应的特征信息不均匀. 为了使每层具有均匀的特征信息,采用可变尺寸小型卷积网络策略. 如图1所示,小型全卷积网络卷积核尺寸分别为9×9、6×6、3×3. 全卷积操作后,各像素均得到512维的特征向量,用于输出到多任务学习模块. 全卷积滑动还生成一个训练样本anchor集合.
2.2. 网络训练策略与代价函数
网络训练需要对训练样本anchor中每个anchor打标签,根据anchor面积与真值窗口面积的交并比(intersection-over-union,IoU),可将anchor分为正样本和负样本. 本文采用小样本训练策略,令批大小(即每次用于样本训练的anchor数量)
式中:Nres_1、Nres_2、Nres_3分别表示3个特征图包含的像素总数. j=1,2,3表示从下向上特征金字塔的层级;i=1,2,
其中,x、y、w、h分别为预测窗口的中心位置坐标以及宽、高;
式(1)中的
其中,
式(1)中的
其中,
如式(1)所示的代价的前半部分
2.3. 检测后处理
2.3.1. 非极大值抑制
上述目标检测过程将产生不分类目标,其中包含相互重叠的目标,若直接进行特征提取进一步检测,冗余计算较多. 本研究采用一种非极大值抑制算法过滤重叠目标. 由于只对不分类别的目标进行检测,忽略了目标的类别归属,采用高IoU阈值(0.9)过滤目标包围盒,最后只有极少的预测包围盒在目标附近保留,流程图如图2所示. 该非极大值抑制算法筛除了大量冗余目标窗口,保留了最接近真值的窗口,目标基本被覆盖,但误差仍然存在,需进行位置精修.
图 2
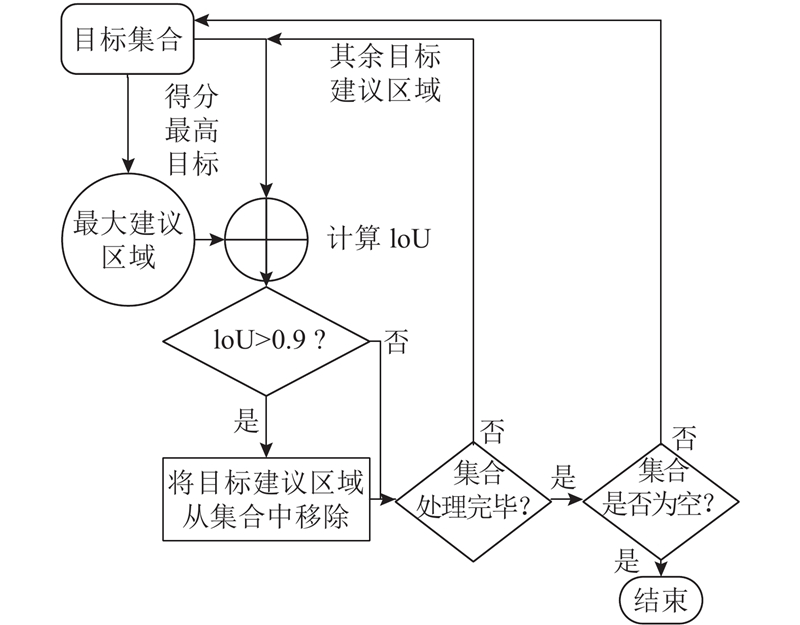
2.3.2. 位置精修
输入为目标包围盒映射到特征图上的特征,感兴趣区域(region of interest,ROI)池化层将不同尺度特征归一化为7×7×512维度,再连接卷积层,之后连接2个分别基于x和y轴池化的最大池化层,其后各连接1个全连接层产生条件概率,如图3所示.
图 3
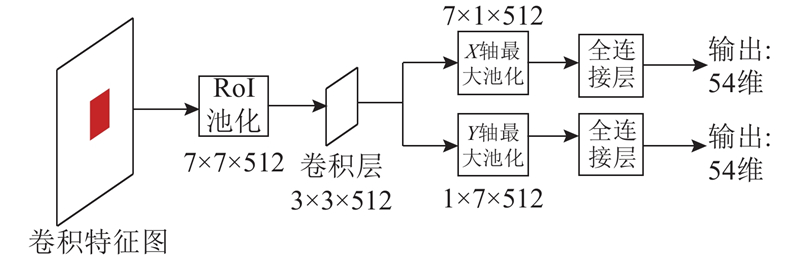
精修步骤如下:
1)将目标窗口缩放得到区域R,缩放因子
2)将R映射到特征金子塔上的对应区域.
3)将各层区域中的特征进行RoI池化操作,得到归一化的7×7×512维特征向量.
4)将归一化的特征向量作一层卷积,分别在x、y轴作最大池化,得到7×1×512和1×7×512的特征向量.
5)x轴向量后接一个全连接层得到M×3个输出值,每3个输出值为一组,表示
6)
式中:
该算法基于条件概率对窗口边界进行量化和调整,比边框回归预测方法更精确.
3. 实验结果与分析
采用基于特征金字塔的多尺度全卷积目标检测方法,在PASCAL VOC 2007、PASCAL VOC 2012标准数据集以及古代绘画图像数据集进行相关实验. 将在这3种数据集上的实验结果与采用Faster RCNN方法及Mask-RCNN方法得到的结果进行分析比较.
3.1. 实验环境
实验硬件配置:CPU为Intel(R)Core(TM)i5-4590 CPU @ 3.30GHz,GPU为NVIDIA GTX 1080Ti 显存11G,内存为16GB. 软件环境:操作系统为Linux系统,深度学习的框架为Tensorflow1.2.0,编程语言为Python 3.5,第三方库为OpenCV3.3-python以及CUDA8.0.
3.1.1. 实验数据集
实验所用的数据集共有3个:公开数据集PASCAL VOC 2007 和 PASCAL VOC 2012,其中PASCAL VOC 2007包含9 963幅图像和 24 640个标注信息,PASCAL VOC 2012包含11 530幅图像和27 450个标注信息;私有数据集古代绘画集,为作者实验室制作的图像集,包含2 890副图像和6 040个标注信息.
3.2. 网络参数
本文检测网络模型采用VGG16,卷积层用ImageNet预训练的参数初始化. 全卷积层、全连接层以及包围盒精修中的卷积层初始化为高斯分布,期望为0,方差为0.01. PASCASL VOC训练集网络训练的初始学习率为0.000 5,每进行3万次迭代\学习率下降10倍. 网络训练的动量因子为0.9,权值衰减系数为0.000 5,网络训练共进行10万次迭代. 在古代绘画数据集上,初始学习率不变,每1万次迭代学习率下降10倍,共进行4万次迭代.
3.3. 评价指标
本研究采用的评价指标是平均检测精度Pave、召回率R和交并比IoU,是目标检测领域常见的重要评价指标.
1)召回率是指检测出的正确目标占图像中总的正确目标的比率,该指标用于衡量目标检测算法查全的能力.
2)精度是指检测出的目标中正确目标所占的比率,平均精度Pave是指在不同召回率条件下,目标检测精度的平均值,该指标用于衡量目标检测算法在查准率和查全率上的平衡.
3)交并比是指检测到的包围盒与目标真值包围盒之间的交集与并集的比值,该指标用于衡量检测到的目标位置的精确度.
3.4. 标准数据集以及实验结果
在标准数据集及其并集上的实验Pave值统计结果如表1所示. 可见,所提方法比Fater-RCNN方法精度高约2%,原因如下:1)多尺度全卷积网络采用了侧连接的特征金字塔结构使得每层都融合更多语义信息,增强了识别能力;2)在金字塔不同层上采用了不同尺度的全卷积操作,各层特征信息利用更均匀.
表 1 不同网络模型在标准数据集上的平均精度值比较
Tab.1
| 网络模型 | 数据集 | Pave / % |
| 多尺度全卷积网络 | 71.2 | |
| Faster-RCNN | PASCAL VOC 2007 | 68.8 |
| Mask-RCNN | 69.36 | |
| 多尺度全卷积网络 | 67.1 | |
| Faster-RCNN | PASCAL VOC 2012 | 66.5 |
| Mask-RCNN | 66.9 | |
| 多尺度全卷积网络 | 74.8 | |
| Faster-RCNN | PASCAL VOC 2007 + 2012 | 72.5 |
| Mask-RCNN | 73.26 |
图 4
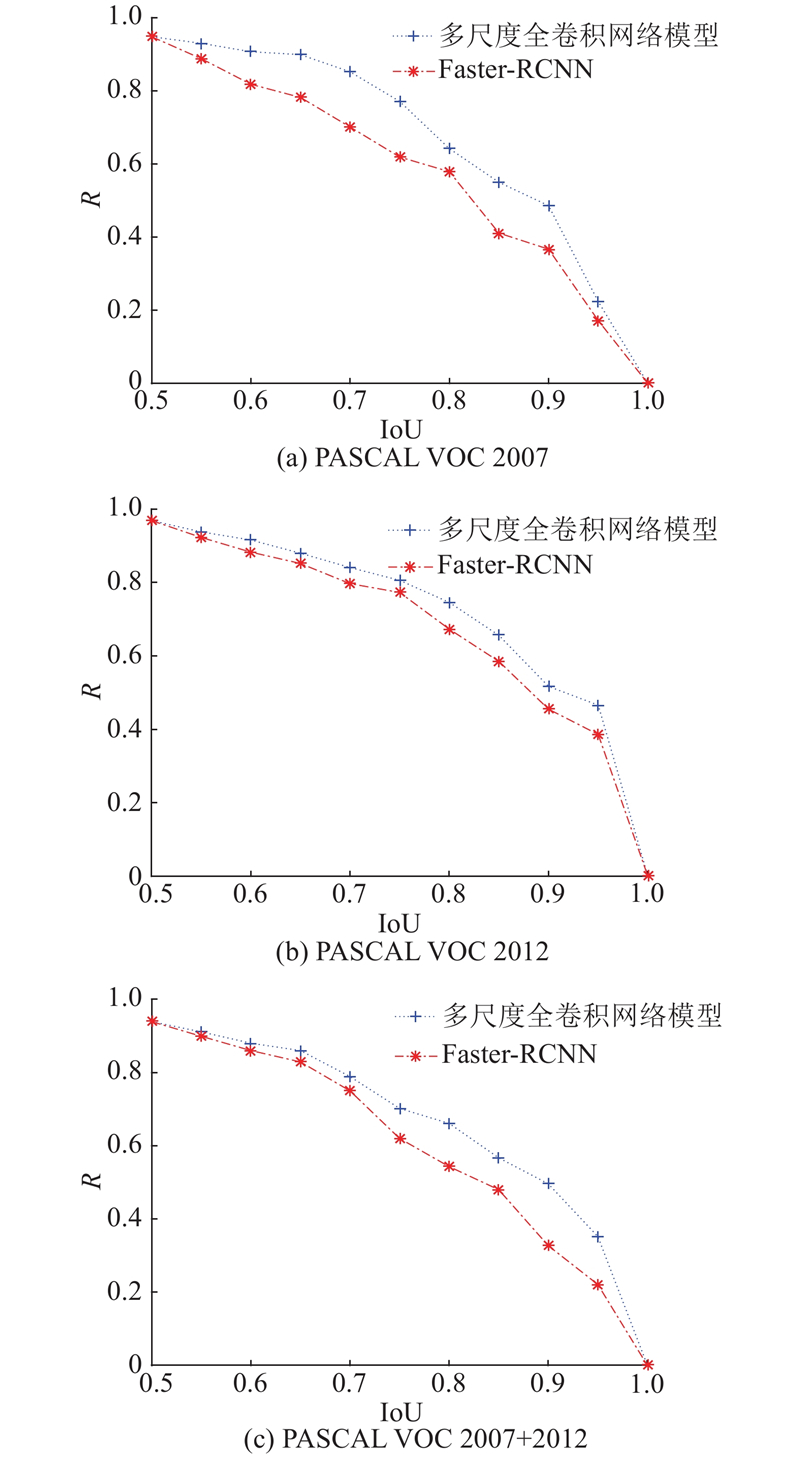
图 4 多尺度全卷积网络与Faster-RCNN在标准数据集上的召回率随交并比(IoU)变化折线图
Fig.4 Recall rate variation line of Faster-RCNN and multi-scale full convolution network on standard dataset with intersection-over-union (IoU)
对微小目标检测的实验及对比如图5所示,结果表明:所提方法比Faster-RCNN方法检测效果更好。原因是多尺度全卷积网络在不同尺度的金字塔层级上进行不同尺度的全卷积操作,使得不同尺度目标的特征信息能够得到适当程度的挖掘和利用,对于信息的缺失和冗余控制更精确.
图 5

图 5 多尺度全卷积网络模型与Faster-RCNN方法的微小目标检测效果对比
Fig.5 Results comparison between multi-scale full convolution network model and Faster-RCNN method in micro-target detection
分析多金字塔特征提取以及目标包围盒位置精修对目标检测结果的影响,结果表明:多金字塔的特征提取与分析可使目标检测结果提升3%,而目标包围盒位置精修可使精度提高2%,表明多金字塔特征提取对目标检测具有较大的影响.
在私有古代绘画图像数据集上的实验结果显示,所提方法得到的Pave值为60.32,而Faster-RCNN方法的Pave值为55.78,Mask-RCNN方法的Pave值为56.32. 在该数据集上,所提方法和Faster-RCNN方法的Pave均明显下降,原因如下:1)数据样本量较小,模型的泛化能力变弱;2)古代绘画图像与自然图像存在较大的差异,古代绘画受创作者的风格和手法的影响,相同类型的目标在不同风格的绘画中差别较大,对检测精度有较大影响. 实验结果表明,所提检测方法比Faster-RCNN方法检测精度高约5%,在古代绘画图像上具有更强的扩展性. 统计2种目标检测方法在该数据集上的召回率,如图6所示,得到召回率的变化规律与在PASCAL VOC标准数据集上的实验结果基本一致.
图 6

图 6 古代绘画图像数据集上的召回率随IoU的变化
Fig.6 Variation of recall rate with IoU on ancient painting image dataset
在私有古代绘画图像数据集上对比所提方法与Faster-RCNN方法的微小目标检测能力,如图7所示,结果显示所提方法比Faster-RCNN方法检测效果更好。
图 7

图 7 多尺度全卷积网络模型与Fast-RCNN方法在古代绘画图像数据集上的目标检测效果对比
Fig.7 Results comparison between multi-scale full convolution network model and Fast-RCNN method in target detection on ancient painting image data sets
4. 结 语
本文主要介绍了一种特征金字塔多尺度全卷积目标检测算法. 该算法首先在RPN网络的基础上构建了一种特征金字塔多尺度网络结构. 该网络结构结合多尺度的全卷积操作能够完成多种尺度的不分类别的目标的检测任务,并采用侧连接技术构造了一种3层特征金字塔结构. 采用一种非极大值抑制算法过滤重叠目标,消除冗余目标窗口,对目标窗口进行位置精修,提高了不分种类目标检测的鲁棒性. 在PASCAL VOC 2007、PASCAL VOC 2012以及古代绘画数据集上进行了系列实验,并对实验结果进行了分析. 实验结果表明:提出的算法在微小目标检测、多尺度目标检测、不分种类的目标检测方面具有较好的平均检测精度、召回率和交并比.
参考文献
Faster R-CNN: towards real-time object detection with region proposal networks
[J].
A trainable system for object detection
[J].DOI:10.1023/A:1008162616689 [本文引用: 1]
Distinctive image features from scale-invariant keypoints
[J].DOI:10.1023/B:VISI.0000029664.99615.94 [本文引用: 1]
Object detection with discriminatively trained part-based models
[J].DOI:10.1109/TPAMI.2009.167 [本文引用: 1]
Spatial pyramid pooling in deep convolutional networks for visual recognition
[J].
ImageNet large scale visual recognition challenge
[J].DOI:10.1007/s11263-015-0816-y [本文引用: 1]
Visualizing and understanding convolutional networks
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}