| Computer Science and Artificial Intelligence |
|


|
|
|
| Near-data processing based on dynamic task offloading |
Xing-cheng HUA( ),Peng LIU*() ),Peng LIU*() |
| College of Information Science and Electronic Engineering, Zhejiang University, Hangzhou 310027, China |
|
|
|
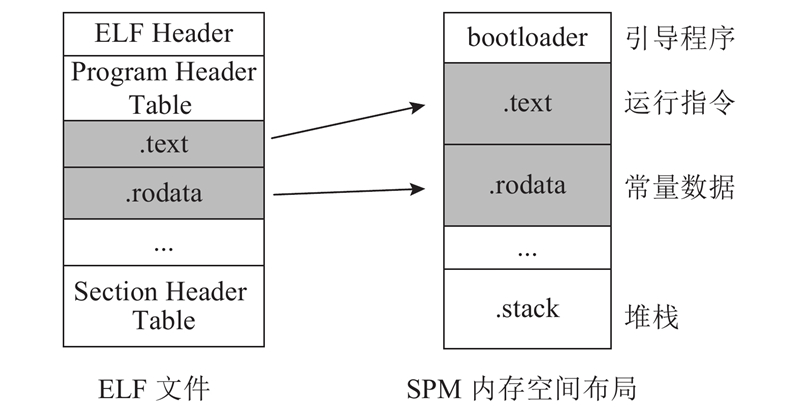
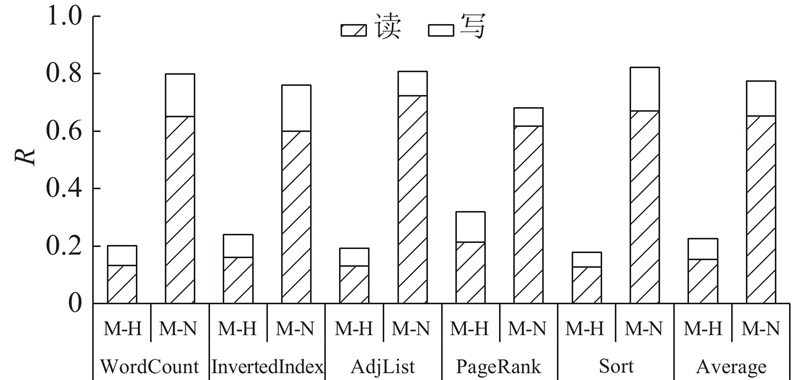
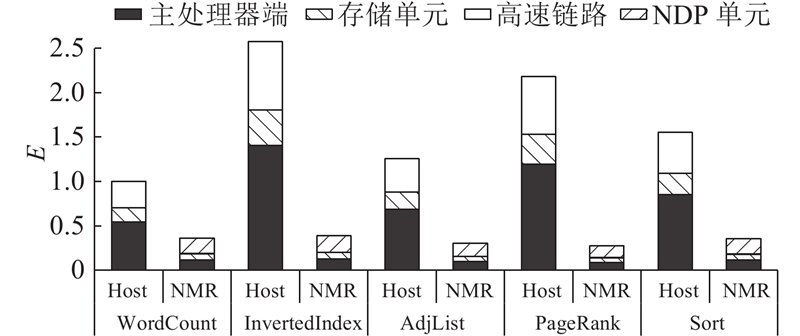
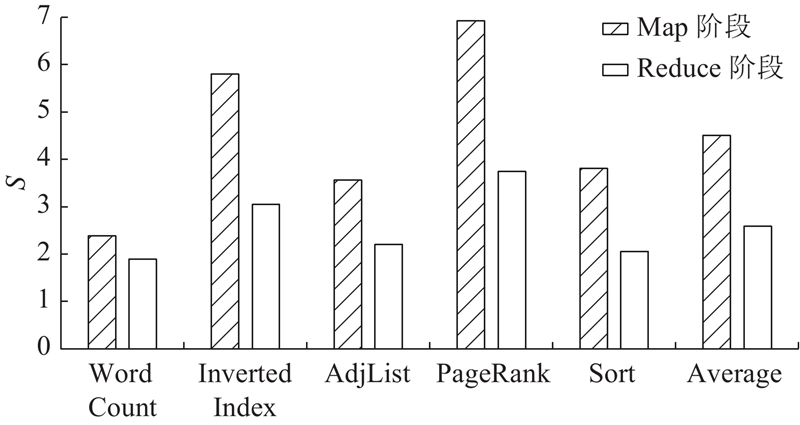
Abstract A near-data processing (NDP) approach based on dynamic task offloading was proposed to address the adverse effects on system performance and energy consumption incurred by data movements in big data applications. The approach leveraged the capability of 3D memory to integrate both memory and logic circuits and the data parallelization of the MapReduce model. The workflow of MapReduce workloads was decoupled to extract the key computation tasks, and the task offloading mechanism was provided to migrate the computation tasks to NDP units dynamically. Atomic operations were employed to optimize the memory accesses, thus reducing data movements dramatically. The experimental results demonstrate that for MapReduce workloads the proposed near-data processing approach restricts 75% of the data movements within the memory module, indicating that the data movements between the main memory and the host processors are significantly reduced. Compared with the state-of-the-art, the proposed approach improved system performance and energy efficiency by 70% and 44%, respectively.
|
|
Received: 24 October 2018
Published: 17 December 2019
|
|
|
|
Corresponding Authors:
Peng LIU
E-mail: hua2009x@zju.edu.cn;liupeng@zju.edu.cn
|
基于动态任务迁移的近数据处理方法
为了应对大数据应用中数据移动对系统性能和能耗造成的负面影响,基于3D存储器集成存储与逻辑电路的特点和MapReduce模型的并发特性,提出一种基于动态任务迁移的近数据处理(NDP)方法. 对MapReduce应用的工作流解耦以获取核心计算任务,提供迁移机制将计算任务动态迁移到NDP单元中;采用原子操作优化数据访问,从而大幅度减少数据移动. 实验结果表明,对于MapReduce应用,提出的近数据处理方法将75%的数据移动约束在存储单元内部,有效减少了主处理单元与存储单元之间的数据移动. 与目前最先进的工作相比,所提方法在系统性能和系统能效上分别有70%和44%的提升.
关键词:
近数据处理(NDP),
MapReduce,
3D存储器,
动态任务迁移
|
|
| [1] |
SIEGL P, BUCHTY R, BEREKOVIC M. Data-centric computing frontiers: A survey on processing-in-memory [C] // Proceedings of the Second International Symposium on Memory Systems. Alexandria: ACM, 2016: 295-308
|
|
|
| [2] |
DEAN J, GHEMAWAT S MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51 (1): 107- 113
doi: 10.1145/1327452.1327492
|
|
|
| [3] |
WANG L, ZHAN J, LUO C, et al. Bigdatabench: A big data benchmark suite from internet services [C] // IEEE International Symposium on High Performance Computer Architecture. Orlando: IEEE, 2014: 488-499
|
|
|
| [4] |
KECKLER S W, DALLY W J, KHAILANY B, et al GPUs and the future of parallel computing[J]. IEEE Micro, 2011, 31 (5): 7- 17
doi: 10.1109/MM.2011.89
|
|
|
| [5] |
BALASUBRAMONIAN R, CHANG J, MANNING T, et al Near-data processing: insights from a micro-46 workshop[J]. IEEE Micro, 2014, 34 (4): 36- 42
doi: 10.1109/MM.2014.55
|
|
|
| [6] |
LEE D U, KIM K W, KIM K W, et al. A 1.2 V 8Gb 8-channel 128 GB/s high-bandwidth memory (HBM) stacked DRAM with effective microbump I/O test methods using 29 nm process and TSV [C] // IEEE International Solid-State Circuits Conference Digest of Technical Papers. San Francisco : IEEE, 2014: 432−433
|
|
|
| [7] |
Hybrid memory cube specification 2.1[EB/OL]. [2018-01-19]. http://hybridmemorycube.org/.
|
|
|
| [8] |
GUTIERREZ A, CIESLAK M, GIRIDHAR B, et al. Integrated 3D-stacked server designs for increasing physical density of key-value stores [C] // ACM SIGPLAN Notices. Salt Lake City : ACM, 2014: 485−498.
|
|
|
| [9] |
AHN J, HONG S, YOO S, et al A scalable processing-in-memory accelerator for parallel graph processing[J]. ACM SIGARCH Computer Architecture News, 2016, 43 (3): 105- 117
|
|
|
| [10] |
AZARKHISH E, ROSSI D, LOI I, et al. Design and evaluation of a processing-in-memory architecture for the smart memory cube [C] // International Conference on Architecture of Computing Systems. Nuremberg: Springer, 2016: 19−31.
|
|
|
| [11] |
NAI L, HADIDI R, SIM J, et al. Graphpim: Enabling instruction-level pim offloading in graph computing frameworks [C] // IEEE International Symposium on High Performance Computer Architecture. Austin: IEEE, 2017: 457−468.
|
|
|
| [12] |
AZARKHISH E, ROSSI D, LOI I, et al Neurostream: Scalable and energy efficient deep learning with smart memory cubes[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29 (2): 420- 434
doi: 10.1109/TPDS.2017.2752706
|
|
|
| [13] |
PUGSLEY S H, JESTES J, ZHANG H, et al. NDC: Analyzing the impact of 3D-stacked memory+ logic devices on MapReduce workloads [C] // IEEE International Symposium on Performance Analysis of Systems and Software. Monterey: IEEE, 2014: 190−200.
|
|
|
| [14] |
Apache Hadoop [EB/OL]. [2018-01-19]. http://hadoop.apache.org/.
|
|
|
| [15] |
KOGGE P M. EXECUBE-A new architecture for scaleable MPPs [C] // International Conference on Parallel Processing. North Carolina: IEEE, 1994: 77−84.
|
|
|
| [16] |
PATTERSON D, ANDERSON T, CARDWELL N, et al A case for intelligent DRAM: IRAM[J]. IEEE Micro, 1997, 33- 44
|
|
|
| [17] |
OSKIN M, CHONG F T, SHERWOOD T. Active Pages: a computation model for intelligent memory [C] // Proceedings of the International Symposium on Computer Architecture. Barcelona: IEEE, 1998: 192−203.
|
|
|
| [18] |
CHU M, JAYASENA N, ZHANG D, et al. High-level programming model abstractions for processing in memory [C] // Workshop on Near-Data Processing. California: IEEE, 2013: 1−4.
|
|
|
| [19] |
GAO M, AYERS G, KOZYRAKIS C. Practical near-data processing for in-memory analytics frameworks [C] // International Conference on Parallel Architecture and Compilation. San Francisco: IEEE, 2015: 113−124.
|
|
|
| [20] |
BINKERT N, BECKMANN B, BLACK G, et al The gem5 simulator[J]. ACM SIGARCH Computer Architecture News, 2011, 39 (2): 1- 7
doi: 10.1145/2024716.2024718
|
|
|
| [21] |
TUDOR B M, TEO Y M. On understanding the energy consumption of arm-based multicore servers [C] // ACM SIGMETRICS Performance Evaluation Review. Pittsburgh: ACM, 2013: 267−278.
|
|
|
| [22] |
CACTI: An integrated cache and memory access time, cycle time, area, leakage, and dynamic power model [EB/OL]. [2018-01-19]. http://www.hpl.hp.com/research/cacti/.
|
|
|
| [23] |
CHANDRASEKAR K, AKESSON B, GOOSSENS K. Improved power modeling of DDR SDRAMs [C] // Euromicro Conference on Digital System Design. Oulu: IEEE, 2011: 99−108.
|
|
|
| [24] |
PAWLOWKI J T. Hybrid memory cube: breakthrough DRAM performance with a fundamentally re-architected DRAM subsystem[C] // Hot Chips. Stanford: IEEE, 2011: 1−24.
|
|
|
| [25] |
JEDDELOH J, KEETH B. Hybrid memory cube new DRAM architecture increases density and performance [C] // Symposium on VLSI Technology. Honolulu: IEEE, 2012: 87−88.
|
|
|
| [26] |
ROSENFELD P. Performance exploration of the hybrid memory cube[D]. Maryland: University of Maryland, 2014.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|