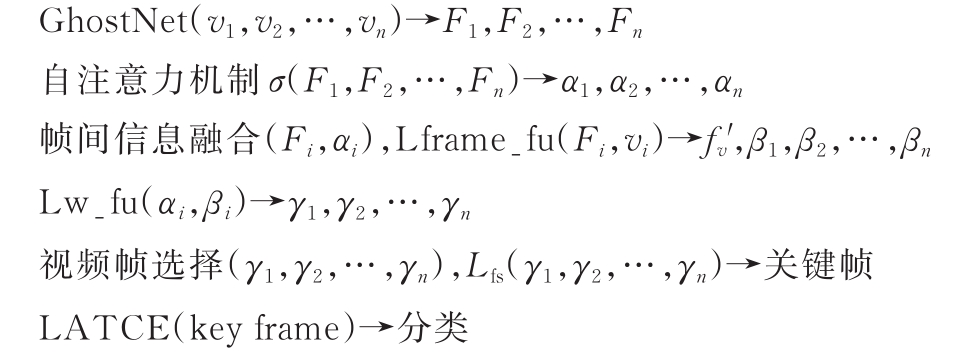| Intelligent Recognition and Visualization |
|


|
|
|
| FSAGN:An expression recognition method based on independent selection of video key frames |
Jintai ZHU1,2( ),Jihua YE1(),Feng GUO1,Lu JIANG1,Aiwen JIANG1 ),Jihua YE1(),Feng GUO1,Lu JIANG1,Aiwen JIANG1 |
1.School of Computer Information Engineering,Jiangxi Normal University,Nanchang 330022,China
2.Department of Information Engineering,Zibo Technician College,Zibo 255030,Shandong Province,China |
|
|
|
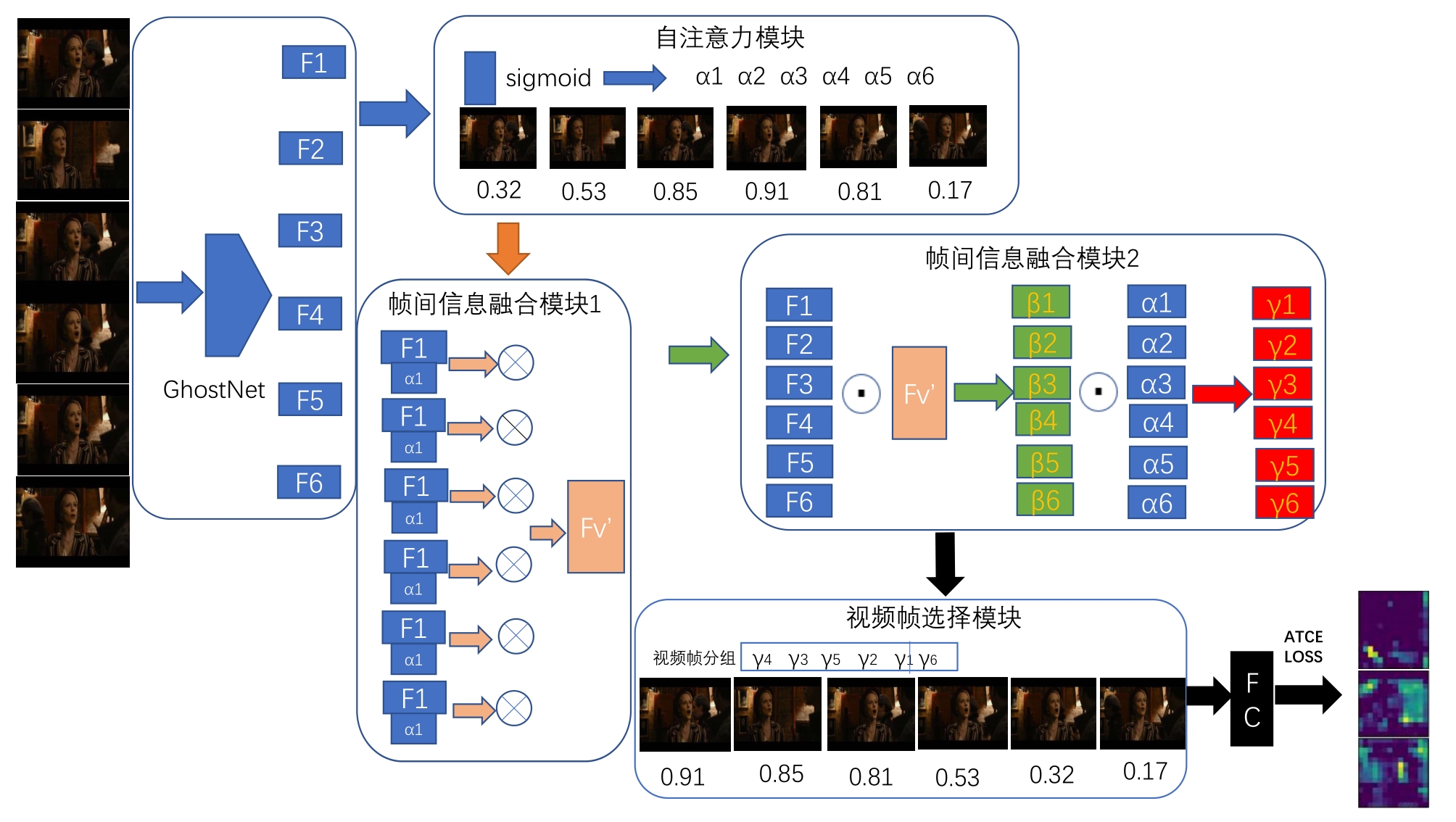
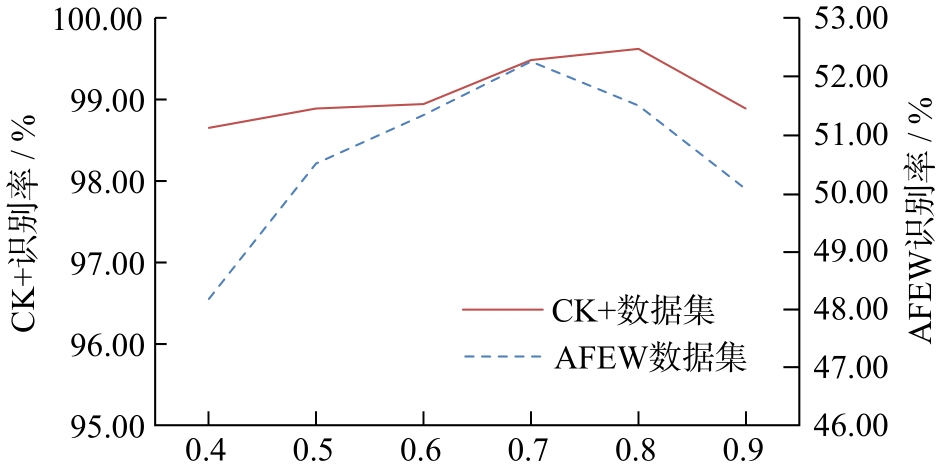
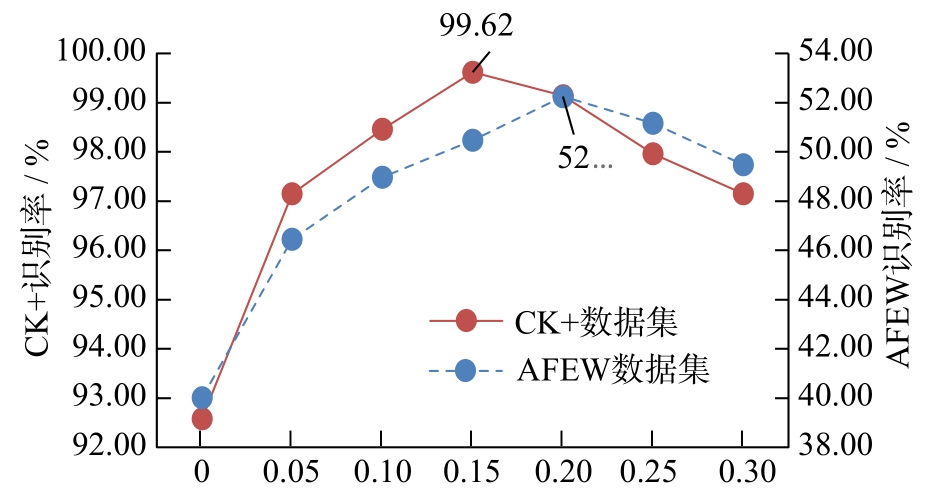
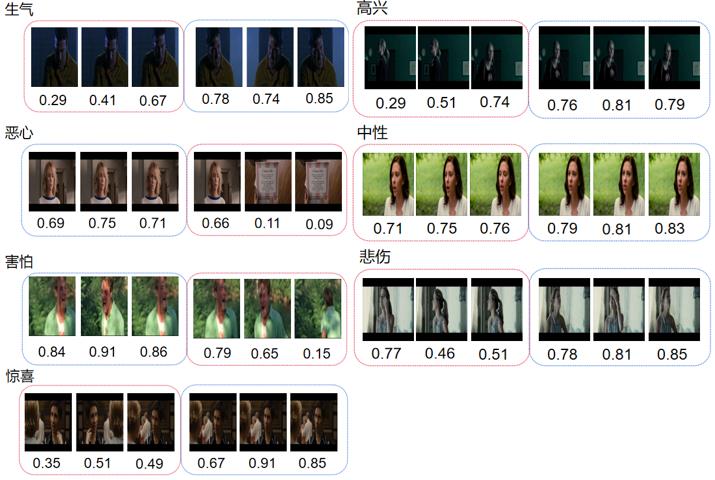
Abstract As there exist a large number of video frames unrelated to facial expressions in the video data set containing facial expressions, a large amount of information unrelated to facial expressions is learned in the training process of the model, which results in a significant decline of the performance. So how to make the model capable of choosing the relevant video key frame autonomously becomes the key problem. At present, most of the existing video expression recognition methods do not yet consider the different effects of key frame and non-key frame on the training effect of the model. In the paper, a face expression recognition model based on attention mechanism and GhostNet(FSAGN) is proposed. The model calculates the weights of different frames by self-attention mechanism and frame selection loss, then selects the key frames of the video sequence autonomously according to the weights. In addition, in order to reduce model parameters and training costs, our approach replaces the traditional feature extraction network with the GhostNet network with fewer training parameters, and combines it with the attention model. Experiments were carried out on the designed network in CK+ and AFEW data sets, and the highest recognition rates were 99.64% and 52.31%, respectively, which reached a competitive classification accuracy. It was suitable for facial expression recognition tasks with long video sequences and uneven distribution of facial expression features in video sequences.
|
|
Received: 21 June 2021
Published: 22 March 2022
|
|
|
|
Corresponding Authors:
Jihua YE
E-mail: 2545000505@qq.com;yjhwcl@163.com
|
|
Cite this article:
Jintai ZHU, Jihua YE, Feng GUO, Lu JIANG, Aiwen JIANG. FSAGN:An expression recognition method based on independent selection of video key frames. Journal of Zhejiang University (Science Edition), 2022, 49(2): 141-150.
URL:
https://www.zjujournals.com/sci/EN/Y2022/V49/I2/141
|
FSAGN: 一种自主选择关键帧的表情识别方法
由于在包含表情的视频数据集中存在大量与表情特征无关的视频帧,使得模型在训练中学习到大量无关信息,导致识别率大幅下降,因此如何令模型自主地选择视频关键帧成为研究的关键。在已有的视频表情识别方法中,大多没有考虑关键帧和非关键帧对模型训练效果的影响,为此提出了一种基于注意力机制与GhostNet的人脸表情识别(FSAGN)模型。通过自注意力机制与帧选择损失计算不同帧的权重,根据权重自主选择视频序列的关键帧。此外,为减少模型参数、降低模型的训练成本,将传统的特征提取网络替换为训练参数较少的GhostNet网络,并与注意力机制结合,分别在CK+和AFEW数据集中进行了实验,得到的最高识别率分别为99.64%和52.31%,分类正确率具有竞争力,适用于对视频序列较长且在视频序列中表情特征分布不均匀的面部表情识别。
关键词:
面部表情识别,
注意力机制,
关键帧自主选择,
GhostNet
|
|
| [1] |
HE K M, ZHANG X Y, REN S Q,et al. Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016: 770-778. doi:10.1109/cvpr.2016.90
doi: 10.1109/cvpr.2016.90
|
|
|
| [2] |
YAO A B, CAI D Q, HU P,et al. HoloNet: Towards robust emotion recognition in the wild[C]//Proceedings of the 18th ACM International Conference on Multimodal Interaction. New York: Association for Computing Machinery,2016: 472-478. DOI:10.1145/2993148.2997639
doi: 10.1145/2993148.2997639
|
|
|
| [3] |
LIU C H, TANG T H,LYU K,et al. Multi-feature based emotion recognition for video clips[C]//ACM International Conference on Multimodal Interaction. New York: Association for Computing Machinery,2018: 630-634. doi:10.1145/3242969.3264989
doi: 10.1145/3242969.3264989
|
|
|
| [4] |
MENG D B, PENG X J, WANG K,et al. Frame attention networks for facial expression recognition in videos[C]//2019 IEEE International Conference on Image Processing. Piscataway: IEEE,2019: 3866-3870. doi:10.1109/icip.2019.8803603
doi: 10.1109/icip.2019.8803603
|
|
|
| [5] |
GAO Q Q, ZENG H X, LI G,et al. Graph reasoning-based emotion recognition network[J]. IEEE Access,2020,9: 6488-6497. DOI:10.1109/ACCESS.2020. 3048693
doi: 10.1109/ACCESS.2020. 3048693
|
|
|
| [6] |
XIE W C, CHEN W T, SHEN L L,et al. Surrogate network-based sparseness hyper-parameter optimization for deep expression recognition[J]. Pattern Recognition,2020,111: 107701. DOI:10. 1016/j.patcog.2020.107701
doi: 10. 1016/j.patcog.2020.107701
|
|
|
| [7] |
LUCEY P, COHN J F, KANADE T,et al. The extended cohn-kanade dataset (CK+): A complete dataset for action unit and emotion-specified expression[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops. Piscataway: IEEE,2010: 94-101. DOI:10.1109/CVPRW.2010.5543262
doi: 10.1109/CVPRW.2010.5543262
|
|
|
| [8] |
DHALL A, GOECKE R, JOSHI J,et al. Emotion recognition in the wild challenge 2014: Baseline,data and protocol[C]//Proceedings of the 16th International Conference on Multimodal Interaction. Piscataway: IEEE,2014: 461-466. DOI:10.1145/2663204. 2666275
doi: 10.1145/2663204. 2666275
|
|
|
| [9] |
OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(7): 971-987. DOI:10.1109/TPAMI.2002.1017623
doi: 10.1109/TPAMI.2002.1017623
|
|
|
| [10] |
黄凯奇,任伟强,谭铁牛. 图像物体分类与检测算法综述[J].计算机学报,2014,37(6): 1225-1240. DOI:10.3724/SP.J.1016.2014.01225
HUANG K Q, REN W Q, TAN T N,et al. A review on image object classification and detection[J]. Chinese Journal of Computers,2014,37(6): 1225-1240. DOI:10.3724/SP.J.1016.2014.01225
doi: 10.3724/SP.J.1016.2014.01225
|
|
|
| [11] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation,1997,9(8): 1735-1780. DOI:10.1162/neco.1997.9.8.1735
doi: 10.1162/neco.1997.9.8.1735
|
|
|
| [12] |
BARGAL S A, BARSOUM E, FERRER C C,et al. Emotion recognition in the wild from videos using images[C]// Proceedings of the 18th ACM International Conference on Multimodal Interaction. New York: Association for Computing Machinery,2016: 433-436. doi:10.1145/2993148.2997627
doi: 10.1145/2993148.2997627
|
|
|
| [13] |
ZHAO X Y, LIANG X D, LIU L Q,et al. Peak-piloted deep network for facial expression recognition[C]// European Conference on Computer Vision. Cham: Springer,2016: 425-442. DOI:10.1007/978-3-319-46475-6_27
doi: 10.1007/978-3-319-46475-6_27
|
|
|
| [14] |
HAN K, WANG Y H, TIAN Q,et al. GhostNet: More features from cheap operations[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2020:1577-1586. doi:10.1109/cvpr42600.2020.00165
doi: 10.1109/cvpr42600.2020.00165
|
|
|
| [15] |
WEI H, HUANG Y Y, ZHANG F,et al. Noise-tolerant paradigm for training face recognition CNNs[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2019:11887-11896. doi:10.1109/cvpr.2019.01216
doi: 10.1109/cvpr.2019.01216
|
|
|
| [16] |
LIN T Y, GOYAL P, GIRSHICK R,et al. Focal loss for dense object detection[C]// 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE,2017:2999-3007. doi:10.1109/iccv.2017.324
doi: 10.1109/iccv.2017.324
|
|
|
| [17] |
JUNG H, LEE S,YIM J,et al. Joint fine-tuning in deep neural networks for facial expression recognition[C]//IEEE International Conference on Computer Vision. Piscataway: IEEE,2015: 2983-2991. DOI:10.1109/ICCV.2015.341
doi: 10.1109/ICCV.2015.341
|
|
|
| [18] |
SIKKA K, SHARMA G, BARTLETT M. LoMo: Latent ordinal model for facial analysis in videos[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016:5580-5589. doi:10.1109/cvpr.2016.602
doi: 10.1109/cvpr.2016.602
|
|
|
| [19] |
ZHANG H P, HUANG B, TIAN G H. Facial expression recognition based on deep convolution long short-term memory networks of double-channel weighted mixture[J]. Pattern Recognition Letters,2020,131: 128-134. DOI:10.1016/j.patrec.2019. 12.013
doi: 10.1016/j.patrec.2019. 12.013
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|