Front. Inform. Technol. Electron. Eng.
2016, 17 (
):
15-31.
(1278KB)
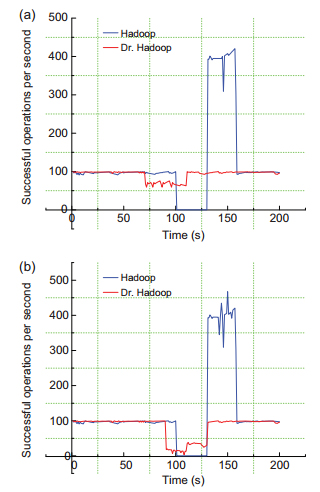
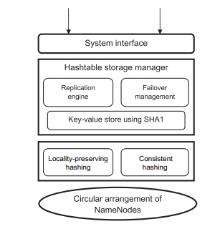
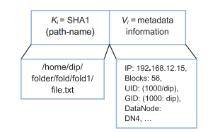
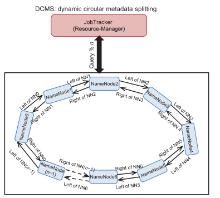
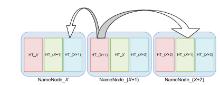
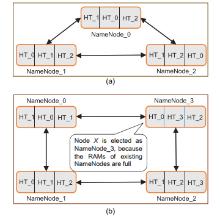
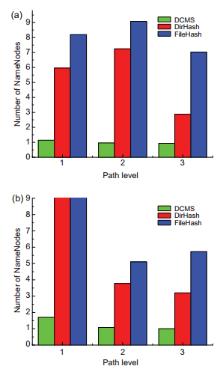
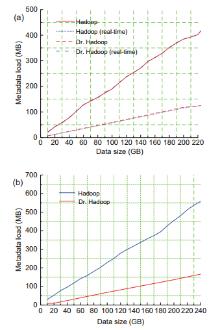
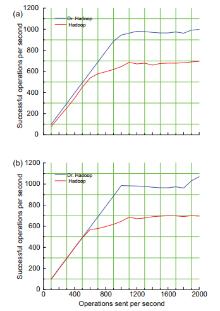
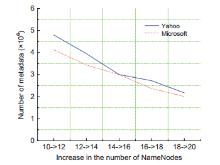
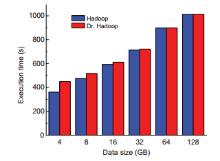
In this Exa byte scale era, data increases at an exponential rate. This is in turn generating a massive amount of metadata in the file system. Hadoop is the most widely used framework to deal with big data. Due to this growth of huge amount of metadata, however, the efficiency of Hadoop is questioned numerous times by many researchers. Therefore, it is essential to create an efficient and scalable metadata management for Hadoop. Hash-based mapping and subtree partitioning are suitable in distributed metadata management schemes. Subtree partitioning does not uniformly distribute workload among the metadata servers, and metadata needs to be migrated to keep the load roughly balanced. Hash-based mapping suffers from a constraint on the locality of metadata, though it uniformly distributes the load among NameNodes, which are the metadata servers of Hadoop. In this paper, we present a circular metadata management mechanism named dynamic circular metadata splitting (DCMS). DCMS preserves metadata locality using consistent hashing and locality-preserving hashing, keeps replicated metadata for excellent reliability, and dynamically distributes metadata among the NameNodes to keep load balancing. NameNode is a centralized heart of the Hadoop. Keeping the directory tree of all files, failure of which causes the single point of failure (SPOF). DCMS removes Hadoop’s SPOF and provides an efficient and scalable metadata management. The new framework is named ‘Dr. Hadoop’ after the name of the authors.




{kind=link}