0 引 言
自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] 。近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法。假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征。进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优。
多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] 。GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构。近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征。更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料。
在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高。图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] 。由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具。在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本。为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比。FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程。另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源。为求解更复杂、更大规模的问题,常用GPU进行并行计算。XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级。JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算。HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信。DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估。
多孔材料特征复杂,需用多尺度拓扑优化方法,对普遍采用的渐进均匀化方法并行研究尚存在空白。当用多尺度拓扑对3D微结构模型进行尺度优化、形状优化时,求解弹性张量矩阵C H n 3 ),n 为微结构模型的离散程度。针对此问题,本文提出求解C H C H
1 基于均匀化方法的多尺度拓扑优化
1.1 多尺度几何模型构建
在多尺度拓扑优化问题中,宏观尺度与微观尺度相差多个数量级,需采取不同描述方法建立几何模型。在宏观尺度下,模型表示为几何空间中的连续区域,用设计域Ω [13 ] ,用水平集描述微结构模型,线框拓扑信息分别存放于结点矩阵和线框矩阵。结点矩阵大小为3×N (N 为结点数),其列号代表线框结构中结点的编号,每列3行数据依次表示结点x 坐标、y 坐标和z 坐标。由于两点确定一条线框,线框矩阵大小为2×M (M 为线框数),每列依次存放线框的起、止结点编号。借助拓扑信息矩阵可自定义网格线框模型,表1 和表2 分别为结点矩阵和线框矩阵,线框模型可视化结果如图1 所示。
图1
图1
线框模型可视化
Fig.1
Visualization of wireframe model
一组节点以及节点间的连接关系表示微结构模型的基本结构特征,而其实体域范围由水平集初值描述,线框模型杆直径决定水平集函数值初始化。
1.2 多尺度分析模型构建
在多尺度结构拓扑优化问题中,基于微小应变与线弹性材料响应假设,在固定设计域Ω u
d i v σ + b = 0 , σ = C ϵ , ϵ = 1 2 ( ∇ u + ∇ u T ) , Ω 上 (1)
u = 0 Γ e 上 σ n = t , Γ n 上
其中,b ϵ σ ϵ C C ∂ Ω Γ e Γ n ∂ Ω n ∂ Ω t Γ n
在宏观尺度上求解平衡方程式(1),需基于渐进均匀化方法获得微观尺度的有效信息,即均匀化单元弹性张量C [33 -34 ] 。在渐进均匀化算法中,先建立相应的有限元方程并求解,得到单元位移与整体位移场,再计算均匀化单元弹性张量C E i l H
E i j k l H = 1 Ω ∫ Ω E p q r s ε p q 0 ( i j ) - ε p q ( i j ) ε r s 0 ( i j ) - ε r s ( i j ) d Ω , (2)
其中,E p q r s Ω ε p q 0 ( i j ) ε p q ( i j )
ε p q ( i j ) = ε p q X i j = 1 2 ( X p , q i j + X q , p i j ) (3)
∫ Ω E i j p q ε i j v ε p q X k l d Ω = ∫ Ω E i j p q ε i j v ε p q 0 ( k l ) d V , v ∈ Ω , (4)
其中,v 12 ]中提供的代码求解式(4)并计算二维多孔材料均匀化弹性张量。
1.3 多尺度拓扑优化方法
用六面体有限单元离散设计域,每个单元e ρ e [ 0,1 ] Ω ρ [ 0,1 ] C H C i H C e H
C e H = β e C i H + ( 1 - β e ) C i + 1 H , (5)
β e = ρ i + 1 - ρ e ρ i + 1 - ρ i (6)
密度梯度设置越小,基于线性插值计算的单元弹性张量越准确,但需求解更多方程(式(4)),这将消耗大量时间。为此提出GPU并行算法,以提高求解一系列多尺寸、多形状微结构单元矩阵C H
1.4 GPU并行架构
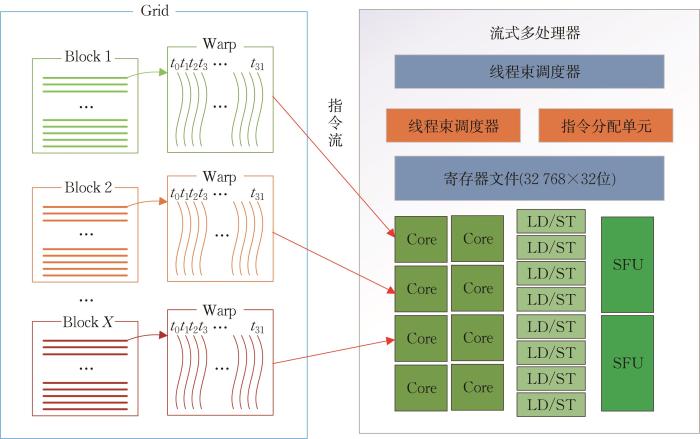
GPU具有并行计算大型数据的能力,自NVIDIA[35 ] 于2007年发布CUDA以来,GPU被广泛用于大规模科学计算。CUDA是一种异构计算平台,由CPU和GPU两种架构组成,其应用分为CPU主机端代码与GPU设备端代码,两者通过PCle总线进行信息交流[36 ] 。主机端代码主要负责设备的控制和数据传输,设备端代码定义功能函数并完成相应计算,此函数称为核函数。线程作为最小执行单元,在并行计算时,GPU将利用大量线程执行核函数[37 ] 。逻辑上将全部线程以一定数量各自归集到一起形成线程块,块中线程以线程束(32个线程)为单位在CUDA核心处理器上运行,如图2 所示。流式多处理器(SM)作为GPU并行架构的组成单元,支持大量线程并发执行,而线程束正是SM的并发执行单元。在SM中,以单指令、多线程(SIMT)方式管理执行线程,线程束中的执行线程在同一时刻运行同一条指令[38 ] 。
图2
图2
GPU并行架构
Fig.2
GPU parallel architecture
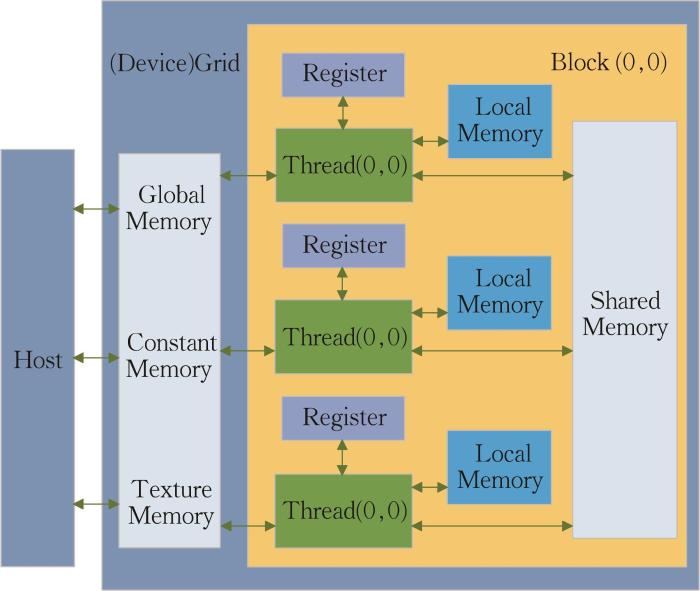
通过CUDA,运用合适的内存模型提升程序运行效率,其中寄存器内存访问速度最快,保证了常用变量的读写速度,每个线程拥有独立寄存器空间,线程间互不干扰。线程块中线程所使用的共享显存,其速度接近寄存器但存储空间更大,是提升程序效率的主要工具。全局显存存储空间大,但速度慢,主要存储设备端与主机端之间的传输数据,全局显存允许GPU所有线程对其进行读写。图3 展示了本文并行算法中CUDA线程及内存的层次逻辑结构。首先,程序在CPU端申请主机内存并将程序复制到GPU端全局显存,当GPU完成并行计算后,将设备显存中的结果数据复制到主机内存。共享显存具有带宽高、延迟低的特点,其可见范围仅为线程块,合理利用共享显存可显著提高程序性能。
图3
图3
CUDA线程及内存的层次逻辑结构
Fig.3
Logical structure of CUDA threads and memory hierarchy
2 构建微结构模型的并行策略
2.1 生成微结构模型
渐进均匀化分析初始步骤为生成微观尺度下的多孔结构模型,即微结构,宏观尺度下连续结构体将被离散为有限个微结构单元。为简化微结构模型获取过程并获得更高的模型精度,本文采用基于网格线框的水平集初始化算法,其中水平集初值由网格线框生成,将由水平集表示的几何模型作为均匀化模型的输入。微结构模型由水平集函数表示,定义为
φ x > 0 , x ∈ Ω , φ x = 0 , x ∈ Γ , φ x < 0 , x ∈ D ¯ / ( Ω ⋃ Γ ) , (7)
其中, Ω Γ D ¯
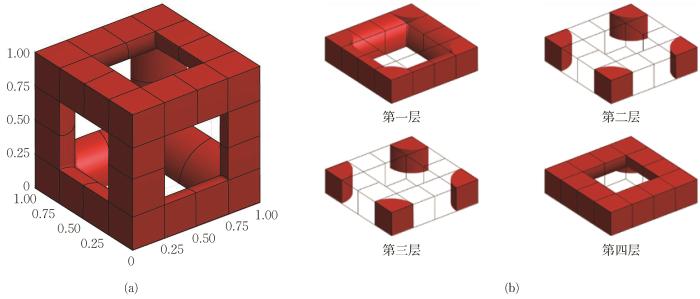
将水平集函数φ x 图4 (a)所示,轴向离散网格点数为5,从原点开始均匀排列于立方体设计域内。图4 (b)展示的为沿z 轴的各层水平集离散网格单元,红色代表含有材料的微结构模型实体,网格单元的材料用量以及分布形式由单元结点上的水平集值φ 插值决定。求水平集离散网格点与线框的最小距离,给定线框模型的支柱半径r ,计算水平集值φ =r -d ,得到水平集值3D逻辑矩阵:
图4
图4
水平集模型
Fig.4
Level set model
0.25 0.25 0.25 0.25 0.25 0.25 0 0 0 0.25 0.25 0 - 0.25 0 0.25 0.25 0 0 0 0.25 0.25 0.25 0.25 0.25 0.25
0.25 0 0 0 0.25 0 - 0.10 - 0.10 - 0.10 0 0 - 0.10 - 0.31 - 0.10 0 0 - 0.10 - 0.10 - 0.10 0 0.25 0 0 0 0.25
0.25 0 - 0.25 0 0.25 0 - 0.10 - 0.31 - 0.10 0 - 0.25 - 0.31 - 0.46 - 0.31 - 0.25 0 - 0.10 - 0.31 - 0.10 0 0.25 0 - 0.25 0 0.25
0.25 0 0 0 0.25 0 - 0.10 - 0.10 - 0.10 0 0 - 0.10 - 0.31 - 0.10 0 0 - 0.10 - 0.10 - 0.10 0 0.25 0 0 0 0.25
0.25 0.25 0.25 0.25 0.25 0.25 0 0 0 0.25 0.25 0 - 0.25 0 0.25 0.25 0 0 0 0.25 0.25 0.25 0.25 0.25 0.25
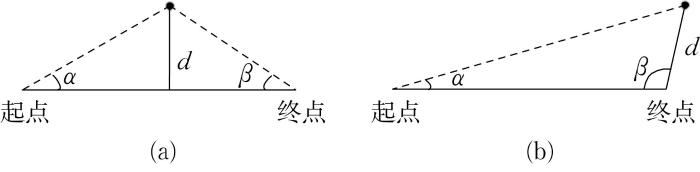
对设计域立方体进行网格离散,确定离散结点上的水平集值。由于水平集值φ =r-d ,故只要确定水平集离散网格点与线框各线段的最小距离d φ 。φ 为正,表示离散结点位于微结构模型内部,反之,位于微结构模型外部。在计算最小距离时,若离散结点与线框线段的起点夹角α β d 为结点到线段的垂直距离(图5 (a));若α β d 为结点到线段的起点或终点的直线距离(图5 (b))。
图5
图5
离散结点与线框的最小距离
Fig.5
Minimum distance between discrete nodes and wireframes
2.2 微结构模型初始化的并行策略
2.2.1 CUDA线程和内存的层次结构
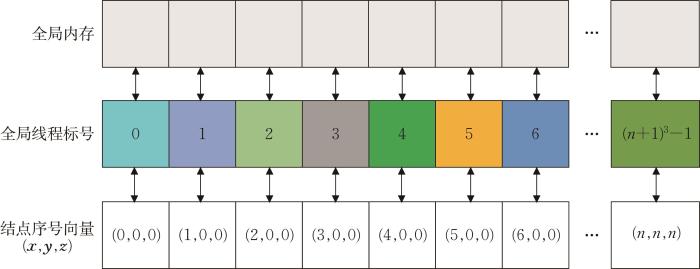
由分析水平集模型初始化过程,可知不同离散结点与线框的最小距离可并行计算,故用每条线程计算每个离散网格点上的水平集值。由于线程块以线程束为单位,因此CUDA处理器核心同一时刻执行相同指令,为避免线程块中多个线程占用一个核处理器,将线程数设置为32(线程束大小)的倍数。本文采用2D线程块模型,图6 展示的为线程全局标号与离散网格结点序号的映射关系。线程块中的单个线程全局标号对应GPU全局显存中的数据索引值。
图6
图6
线程全局标号与离散网格结点序号的映射关系
Fig.6
The mapping relationship between thread global labeling and discrete grid node numbering
2.2.2 水平集初始化并行策略
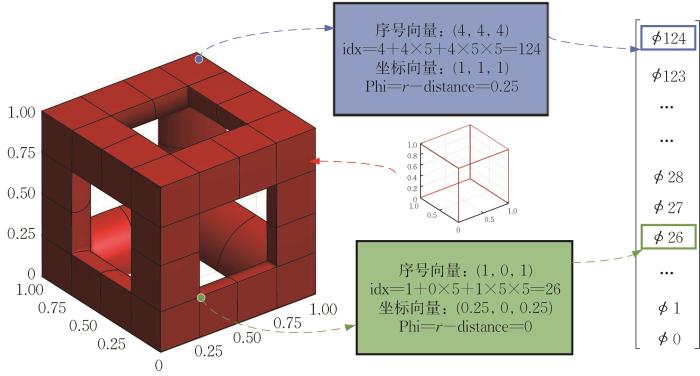
水平集初始化并行策略如表3 所示。←表示寄存器或本地内存中的变量赋值操作,⇒/⇐表示全局内存的读/写操作。函数GetCoordinate()可通过线程全局标号idx及离散网格尺寸size推导线程对应离散结点的位置向量 p p P P 图5 中的夹角α β r ,计算水平集值Phi=r -distance。将线程遍历得到的maxPhi赋值给全局水平集值数组Phi idx ,获取与全局标号idx对应的离散结点水平集值。并行计算水平集初值示例如图7 所示。
图7
图7
并行计算水平集初值示例
Fig.7
Example of initial values for parallel computing level sets
3 3D微结构弹性张量预计算并行算法
采用渐近均匀化方法计算多孔材料周期性微结构单元的弹性张量,通过大型稀疏矩阵的并行求解算法及均匀化本构矩阵的并行积分算法提升渐近均匀化方法的计算效率。
3.1 渐进均匀化过程整体方程的并行求解
在求解有限元整体平衡方程 K x = f x = K \ f [39 ] 。通常,用共轭梯度法(conjugate gradients,CG)求解大型稀疏矩阵方程,稀疏矩阵需满足对称及正定条件[40 ] ,而整体刚度矩阵K
Step 3 对迭代次数k = 0 , 1 , 2 , ⋯
有限元法的整体刚度矩阵为稀疏矩阵,本文CG方法采用行压缩(compressed sparse row,CSR)方式存储稀疏矩阵 A [41 ] ,如整体刚度矩阵。CSR格式将稀疏矩阵分为3个一维向量,分别为Val向量,记录非零元素值;Col_Val向量,记录非零元素对应的列号;Row_Val向量,记录矩阵每行中首个非零元素前的总非零元素个数。
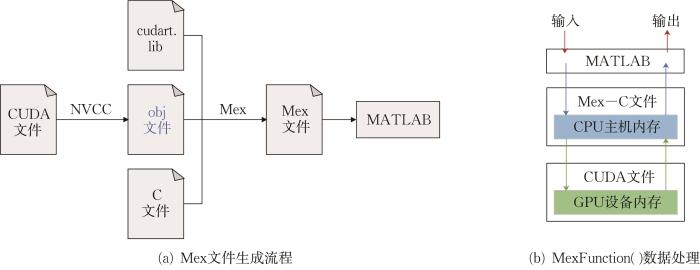
在渐进均匀化代码中,多处涉及大型稀疏矩阵方程的求解,为提升求解稀疏矩阵方程的效率,将预条件共轭梯度算法进行集成。本文联合Matlab, C与CUDA混合编程模式实现对稀疏矩阵方程的高效并行求解(图8 )。
图8
图8
Matlab,C和CUDA混合编程模型
Fig.8
Mixed programming model of Matlab, C and CUDA
并行共轭梯度算法如表4 所示。←表示寄存器或本地内存变量赋值操作,⇒/⇐表示全局内存读/写操作。其中,第1~6行为CG算法的准备工作,计算r 0 = b - A x 0 d_x ⇐alpha*d_p+d_x 语句完成近似解x r 小于 t o l * t o l r k T r k A p k x k + 1 = x k + α k p k
3.2 均匀化本构矩阵的并行计算
将六面体单元作为渐进均匀化对象,由单位应变求微结构单元结点位移,由式(8)求在均匀应变下微结构单元中的离散结点位移场,该两组位移矩阵是计算本构矩阵C C
C i j H = 1 Ω ∑ e ∫ Ω ( e ) ( x ( e ) 0 ( i ) - x ( e ) ( i ) ) T k e ( x ( e ) 0 ( j ) - x ( e ) ( j ) ) d Ω ( e ) (8)
其中,x ( e ) 0 ( i ) i x ( e ) ( i ) Ω 计算 C i j H C i j H
并行计算C H 表5 所示,其中,elem_N 为微结构单元数,当微结构单元用于变密度法拓扑优化时,可设置密度等梯度变化系列微结构单元,同时计算多个单元本构矩阵。将数据从全局显存取存到CUDA线程的寄存器单元,可避免对全局显存多次读取,提升存储读取效率。通过拉梅常数将单元刚度矩阵分解为两部分,C i j H d _Volumeele*blockN+idx *sum_L + Mu/ d_ Volumeele*blockN+idx *sum_M ,其中,Lambda与Mu分别为拉梅第一、第二常数。本构矩阵并行算法如表6 所示,每个CUDA线程负责组装一个完整单元本构矩阵 C
4 实验验证与分析
4.1 实验条件
实验所用机器硬件配置:CPU为Intel Core i9-10900x(十核心/二十线程),主频3.70 GHz,随机存储器RAM为Tigo DDR4 2 666 MHz,内存64 GB,GPU为GeForce RTX 2080,拥有2 944个CUDA内核,其中每个SM的最大激活线程数为1 024,线程块中最大激活线程数为1 024,线程块最大尺寸为1 024×1 024×64,网格最大尺寸为(231 -1)×65 535×65 535。操作系统为Windows 10.1 64位,CPU代码的编译器为Mathworks MATLAB 2018a和Microsoft Visual Studio 2019,GPU代码的编译器为NVIDIA CUDA 11.0,实验所用并行算法的全部CUDA内核程序均由作者编写调试。
4.2 实验设计与数据
以悬臂梁为例,展示多尺度拓扑优化渐进均匀化GPU并行算法的加速效率。三维悬臂梁设计域如图9 所示,梁的长、宽、高分别设为L ,0.2L ,L 。高度L 设为1,符合无量纲计算规则。在右端面下边缘向下施加竖向分布单位载荷F ,左端面受约束。
图9
图9
三维悬臂梁的设计域和边界条件
Fig.9
Design domain and boundary conditions of 3D cantilever beams
通过渐进均匀化过程计算微结构单元本构矩阵,其CPU串行算法基于Matlab编写实现。针对多尺度结构拓扑优化,主要计算环节为水平集初始化、大型稀疏刚度矩阵方程求解以及本构矩阵并行计算等。实验将微结构单元在轴向的水平集离散网格数作为自变量,称为分辨率。CPU串行算法与GPU并行算法分别在分辨率(自由度)为43 (192),83 (1 536),163 (12 288),323 (98 304),643 (786 432),1283 (6 291 456)下执行相应计算环节。
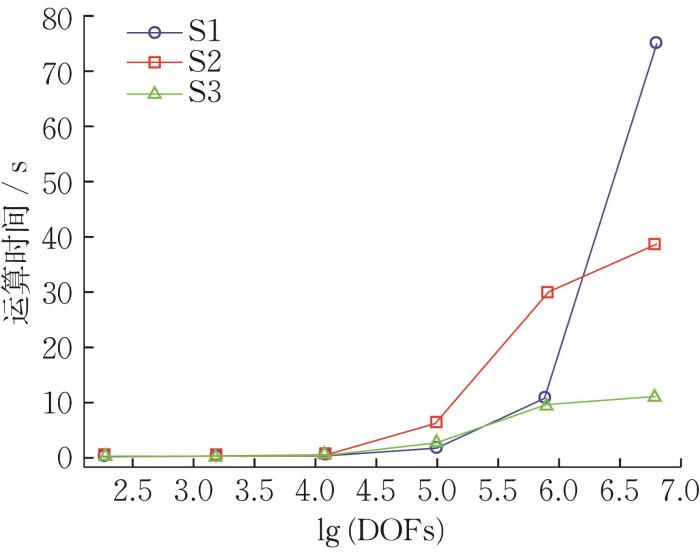
在不同分辨率下串行算法与并行算法完成各计算环节所需的平均时间如表7 所示,其中S1,S2,S3分别代表水平集初始化、大型稀疏刚度矩阵方程求解以及本构矩阵并行计算。
加速比为原CPU串行算法的执行时间除以GPU并行算法执行时间得到的比值,即表7 中的第5列数据除第6列数据得到第7列的GPU并行算法加速比。
由于微结构单元结构具有对称性,其在x ,y ,z 方向上的性质是相同的。可通过对本构矩阵求逆,得到柔度矩阵S H
S 11 H = 1 E x S 22 H = 1 E y S 33 H = 1 E z (9)
其中 , E x E y E z E x E y E z 表8 所示。CPU串行计算杨氏模量,数据均为double(双精度浮点)类型。GPU并行计算,为节省显存开销,同时降低主机向GPU传输数据的时间,使用了float(单精度浮点)类型,CPU与GPU计算结果并没有严格相等。经分析,GPU相较于CPU杨氏模量相对误差始终低于1×10-2 。随着分辨率的增加,微结构单元水平集模型更精细,杨氏模量逐渐收敛,趋于更精确的结果。当追求高准确度计算结果时,使用GPU并行算法更节省时间与资源。
4.3 实验结果分析
在渐进均匀化过程中,水平集初始化、总刚度方程求解及本构矩阵并行计算等的运算时间变化情况如图10 所示。当自由度较小时,即分辨率越小模型精度越低,GPU并行算法性能并不比CPU串行算法优越;当自由度逐渐增加时,GPU并行算法较CPU串行算法运算时间始终低一个水平,体现了GPU算法在面对大规模计算问题时的优越性。
图10
图10
计算环节执行时间
Fig.10
Execution time of calculation phase
由图11 可知,当自由度(分辨率)在192(43 )~98 304(323 )时,GPU并行算法的加速效率并不明显,当自由度大于98 304时,计算规模呈几何级增加,GPU并行算法的加速效率开始凸显,在大型稀疏刚度矩阵方程求解环节和本构矩阵并行计算环节,其加速比可达两个数量级。
图11
图11
GPU/CPU加速比
Fig.11
Acceleration ratio of GPU/CPU
综上分析可知,当模型自由度(分辨率)较低时,不足以体现GPU并行计算的能力,两种算法效率相近;随着自由度(分辨率)的增加,CPU串行算法无法适应大规模计算要求,此时凭借GPU强大的并行计算能力令加速比保持递增趋势。
图12 为悬臂梁多尺度拓扑优化结果,其中一系列密度梯度的单元具有相同的微结构和不同的体积。在多尺度拓扑优化中,每个梯度均需计算本构矩阵,基于渐进均匀化并行算法用GPU进行并行计算,可满足优化过程的算力要求。
图12
图12
悬臂梁多尺度拓扑优化结果
Fig.12
Multiscale topology optimization results of cantilever beams
5 总 结
基于渐进均匀化多尺度拓扑优化并行算法,研究了优化过程中水平集初始化、大型稀疏刚度矩阵方程求解以及本构矩阵并行计算等。实验结果表明,当计算规模较大时,GPU并行算法的加速比显著,尤其是大型稀疏刚度矩阵方程求解和本构矩阵并行计算环节,其加速比达几十倍。此外,两种算法得到的微结构单元杨氏模量值一致,验证了GPU并行算法的准确性。本文的并行算法可扩展至其他应用场景,但仍有待进一步完善,例如结合OpenMP, CUDA与MPI搭建多尺度结构拓扑优化CPU/GPU异构并行算法,以进一步提升结构优化设计效率。
http://dx.doi.org/10.3785/j.issn.1008-9497.2023.06.001
参考文献
View Option
[2]
LIU K JIANG L Bio-inspired design of multiscale structures for function integration
[J]. Nano Today , 2011 , 6 (2 ): 155 -175 . DOI:10.1016/j.nantod. 2011.02.002
[3]
YANG Y SONG X LI X J et al Recent progress in biomimetic additive manufacturing technology: From materials to functional structures
[J]. Advanced Materials , 2018 , 30 : 1706539 . DOI:10.1002/adma.201706539
[本文引用: 1]
[4]
YING J M LU L TIAN L H et al Anisotropic porous structure modeling for 3D printed objects
[J]. Computers & Graphics , 2018 , 70 : 157 -164 . DOI:10.1016/j.cag.2017.07.008
[本文引用: 1]
[5]
NAZIR A ABATE K M KUMAR A et al A state-of-the-art review on types, design, optimization, and additive manufacturing of cellular structures
[J]. The International Journal of Advanced Manufacturing Technology , 2019 , 104 : 3489 -3510 . DOI:10.1007/s00170-019-04085-3
[7]
SCHWERDTFEGER J WEIN F LEUGERING G et al Design of auxetic structures via mathematical optimization
[J]. Advanced Materials , 2011 , 23 : 2650 -2654 . DOI:10.1002/adma.201004090
[本文引用: 1]
[8]
OLSON R A MARTINS L C B Cellular ceramics in metal filtration
[J]. Advanced Engineering Materials , 2005 , 7 : 187 -192 . DOI:10.1002/adem.200500021
[本文引用: 1]
[9]
SANCHEZ-PALENCIA E Comportements local et macroscopique d'un type de milieux physiques heterogenes
[J]. International Journal of Engineering Science , 1974 , 12 : 331 -351 . DOI:10.1016/0020-7225(74)90062-7
[本文引用: 1]
[10]
OHNO N WU X MATSUDA T Homogenized properties of elastic-viscoplastic composites with periodic internal structures
[J]. International Journal of Mechanical Sciences , 2000 , 42 (8 ): 1519 -1536 . DOI:10.1016/S0020-7403(99)00088-0
[本文引用: 1]
[11]
GUEDES J M KIKUCHI N Preprocessing and postprocessing for materials based on the homogenization method with adaptive finite element methods
[J]. Computer Methods in Applied Mechanics and Engineering , 1990 , 83 (2 ): 143 -198 . DOI:10.1016/0045-7825(90)90148-f
[本文引用: 1]
[13]
DONG G Y TANG Y L ZHAO Y F A 149 line homogenization code for three-dimensional cellular materials written in Matlab
[J]. Journal of Engineering Materials and Technology , 2019 , 141 (1 ): 011005 -01100516 . DOI:10.1115/1.4040555
[本文引用: 1]
[14]
LIU P Q LIU A PENG H et al Mechanical property profiles of microstructures via asymptotic homogenization
[J]. Computers & Graphics , 2021 , 100 : 106 -115 . DOI:10.1016/j.cag.2021.07.021
[本文引用: 1]
[15]
WANG Y Q CHEN F F WANG M Y Concurrent design with connectable graded microstructures
[J]. Computer Methods in Applied Mechanics and Engineering , 2017 , 317 : 84 -101 . DOI:10.1016/j.cma.2016.12.007
[本文引用: 1]
[16]
YU W B TANG T A variational asymptotic micromechanics model for predicting thermoelastic properties of heterogeneous materials
[J]. International Journal of Solids and Structures ,2007 , 44 : 7510 -7525 . DOI:10.1016/j.ijsolstr.2007.04.026
[本文引用: 1]
[17]
TEMIZER İ WRIGGERS P Homogenization in finite thermoelasticity
[J]. Journal of the Mechanics and Physics of Solids , 2011 , 59 (2 ): 344 -372 . DOI:10.1016/j.jmps.2010.10.004
[18]
BACIGALUPO A MORINI L PICCOLROAZ A Multiscale asymptotic homogenization analysis of thermo-diffusive composite materials
[J]. International Journal of Solids and Structures , 2016 , 85-86 : 15 -33 . DOI:10.1016/j.ijsolstr.2016.01.016
[19]
PRÉVE D BACIGALUPO A PAGGI M Variational-asymptotic homogenization of thermoelastic periodic materials with thermal relaxation
[J]. International Journal of Mechanical Sciences , 2021 , 205 : 106566 . DOI:10.1016/j.ijmecsci.2021.106566
[本文引用: 1]
[20]
SALVADORI A BOSCO E GRAZIOLI D A computational homogenization approach for Li-ion battery cells: Part 1-formulation
[J]. Journal of the Mechanics and Physics of Solids , 2014 , 65 : 114 -137 . DOI:10.1016/j.jmps.2013.08.010
[本文引用: 1]
[21]
FANTONI F BACIGALUPO A PAGGI M Multi-field asymptotic homogenization of thermo-piezoelectric materials with periodic microstructure
[J]. International Journal of Solids and Structures , 2017 ,120 : 31 -56 . DOI:10.1016/j.ijsolstr.2017.04.009
[本文引用: 1]
[22]
SCHRÖDER J KEIP M A Two-scale homogenization of electromechanically coupled boundary value problems: Consistent linearization and applications
[J]. Computational Mechanics , 2012 , 50 : 229 -244 . DOI:10.1007/s00466-012-0715-9
[本文引用: 1]
[23]
FANTONI F BACIGALUPO A Wave propagation modeling in periodic elasto-thermo-diffusive materials via multifield asymptotic homogenization
[J]. International Journal of Solids and Structures ,2020 , 196-197 : 99 -128 . doi:10.1016/j.ijsolstr.2020.03.024
[本文引用: 1]
[24]
LI Y X ZHOU B J HU X L A two-grid method for level-set based topology optimization with GPU-acceleration
[J]. Journal of Computational and Applied Mathematics , 2021 , 389 : 113336 . DOI:10.1016/j.cam.2020.113336
[本文引用: 1]
[25]
MUNK D J KIPOUROS T VIO G A Multi-physics bi-directional evolutionary topology optimization on GPU-architecture
[J]. Engineering with Computers , 2019 , 35 (3 ): 10591079 . doi:10.1007/s00366-018-0651-1
[本文引用: 1]
[26]
QUINTELA B M FARAGE M C R LOBOSCO M Evaluation of effective properties of heterogeneous media through a GPGPU based algorithm
[J]. CILAMCE , 2010 , XXIX: 7085-7094 .
[本文引用: 1]
[27]
QUINTELA M B CALDAS D M FARAGE MCR et al Multiscale modeling of heterogeneous media applying AEH to 3D bodies
[C] // MURGANTE B, GERVASI O, MISRA S, et al. Computational Science and Its Applications-ICCSA 2012 . Berlin/Heidelberg : Springer , 2012 , 7333 : 675 -690 . doi:10.1007/978-3-642-31125-3_51
[本文引用: 1]
[28]
FRITZEN F HODAPP M LEUSCHNER M GPU accelerated computational homogenization based on a variational approach in a reduced basis framework
[J]. Computer Methods in Applied Mechanics and Engineering , 2014 , 278 : 186 -217 . DOI:10.1016/j.cma.2014.05.006
[本文引用: 1]
[29]
XIA Z H WANG Y J WANG Q F et al GPU parallel strategy for parameterized LSM-based topology optimization using isogeometric analysis
[J]. Structural and Multidisciplinary Optimization , 2017 , 56 : 413 -434 . DOI:10.1007/s00158-017-1672-x
[本文引用: 1]
[30]
MARTÍNEZ-FRUTOS J HERRERO-PÉREZ D GPU acceleration for evolutionary topology optimization of continuum structures using isosurfaces
[J]. Computers and Structures , 2017 , 182 :119 -136 . DOI:10.1016/j.compstruc.2016.10.018
[本文引用: 1]
[31]
HERRERO-PÉREZ D MARTÍNEZ CASTEJÓN J Multi-GPU acceleration of large-scale density-based topology optimization
[J]. Advances in Engineering Software , 2021 , 157 /158 : 103006 . DOI:10.1016/j.advengsoft.2021.103006
[本文引用: 1]
[32]
HE G WANG H LI E et al A multiple-GPU based parallel independent coefficient reanalysis method and applications for vehicle design
[J]. Advances in Engineering Software , 2015 , 85 : 108 -124 . DOI:10.1016/j.advengsoft.2015.03.006
[本文引用: 1]
[33]
GUEDES J M Nonlinear Computational Models for Composite Materials Using Homogenization
[D]. Ann Arbor : The University of Michigan ,1990 .
[本文引用: 1]
[34]
BENDSØE M P KIKUCHI N Generating optimal topologies in structural design using a homogenization method
[J]. Computer Methods in Applied Mechanics and Engineering , 1988 , 71 : 197 -224 . DOI:10.1016/0045-7825(88)90086-2
[本文引用: 1]
[35]
CHALLIS V J ROBERTS A P GROTOWSKI J F High resolution topology optimization using graphics processing units (GPUs)
[J]. Structural and Multidisciplinary Optimization , 2014 , 49 : 315 -325 . DOI:10.1007/s00158-013-0980-z
[本文引用: 1]
[36]
KUŹNIK K PASZYŃSKI M CALO V Graph grammar-Based multi-frontal parallel direct solver for two-dimensional isogeometric analysis
[J]. Procedia Computer Science ,2012 , 9 : 1454 -1463 . DOI:10.1016/j.procs.2012.04.160
[本文引用: 1]
[37]
HE L L BAI H T JIANG Y et al Revised simplex algorithm for linear programming on GPUs with CUDA
[J]. Multimedia Tools and Applications , 2018 , 77 (22 ): 30035 -30050 . DOI:10.1007/s11042-018-5947-z
[本文引用: 1]
[40]
YUAN G L LI T T HU W J A conjugate gradient algorithm for large-scale nonlinear equations and image restoration problems
[J]. Applied Numerical Mathematics , 2020 , 147 : 129 -141 . DOI:10.1016/j.apnum.2019.08.022
[本文引用: 1]
[41]
BORŠTNIK U VANDEVONDELE J WEBER V et al Sparse matrix multiplication: The distributed block-compressed sparse row library
[J]. Parallel Computing , 2014 , 40 : 47 -58 . DOI:10.1016/j.parco.2014.03.012
[本文引用: 1]
Architected cellular materials
1
2016
... 自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] .近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法.假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征.进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优. ...
Bio-inspired design of multiscale structures for function integration
0
2011
Recent progress in biomimetic additive manufacturing technology: From materials to functional structures
1
2018
... 自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] .近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法.假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征.进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优. ...
Anisotropic porous structure modeling for 3D printed objects
1
2018
... 自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] .近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法.假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征.进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优. ...
A state-of-the-art review on types, design, optimization, and additive manufacturing of cellular structures
0
2019
Nature teaching structures
1
2002
... 自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] .近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法.假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征.进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优. ...
Design of auxetic structures via mathematical optimization
1
2011
... 自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] .近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法.假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征.进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优. ...
Cellular ceramics in metal filtration
1
2005
... 自然界中的多孔材料如蛛丝、蜂巢、蚁穴等能以低密度实现高刚度和高强度[1 -3 ] ,其高性能结构为科学家和工程师提供了众多设计灵感[4 -6 ] .近年来,增材制造技术的快速发展进一步推动了先进结构材料的设计[7 -8 ] ,通过将拓扑优化方法和均匀化方法相结合,发展了多尺度拓扑优化方法.假设周期性多孔微结构单元均匀镶嵌在设计域中,当微结构单元的尺寸远小于宏观物体特征尺寸时,其多孔结构特性可通过均匀化方法表现为均质材料特征.进而利用拓扑优化方法对设计域每个微结构单元的几何结构进行优化,在满足约束的前提下使宏观物体性能达到最优. ...
Comportements local et macroscopique d'un type de milieux physiques heterogenes
1
1974
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Homogenized properties of elastic-viscoplastic composites with periodic internal structures
1
2000
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Preprocessing and postprocessing for materials based on the homogenization method with adaptive finite element methods
1
1990
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
How to determine composite material properties using numerical
2
2014
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
... 其中,v 12 ]中提供的代码求解式(4) 并计算二维多孔材料均匀化弹性张量. ...
A 149 line homogenization code for three-dimensional cellular materials written in Matlab
1
2019
... 在多尺度拓扑优化问题中,宏观尺度与微观尺度相差多个数量级,需采取不同描述方法建立几何模型.在宏观尺度下,模型表示为几何空间中的连续区域,用设计域Ω [13 ] ,用水平集描述微结构模型,线框拓扑信息分别存放于结点矩阵和线框矩阵.结点矩阵大小为3×N (N 为结点数),其列号代表线框结构中结点的编号,每列3行数据依次表示结点x 坐标、y 坐标和z 坐标.由于两点确定一条线框,线框矩阵大小为2×M (M 为线框数),每列依次存放线框的起、止结点编号.借助拓扑信息矩阵可自定义网格线框模型,表1 和表2 分别为结点矩阵和线框矩阵,线框模型可视化结果如图1 所示. ...
Mechanical property profiles of microstructures via asymptotic homogenization
1
2021
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Concurrent design with connectable graded microstructures
1
2017
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
A variational asymptotic micromechanics model for predicting thermoelastic properties of heterogeneous materials
1
2007
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Homogenization in finite thermoelasticity
0
2011
Multiscale asymptotic homogenization analysis of thermo-diffusive composite materials
0
2016
Variational-asymptotic homogenization of thermoelastic periodic materials with thermal relaxation
1
2021
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
A computational homogenization approach for Li-ion battery cells: Part 1-formulation
1
2014
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Multi-field asymptotic homogenization of thermo-piezoelectric materials with periodic microstructure
1
2017
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Two-scale homogenization of electromechanically coupled boundary value problems: Consistent linearization and applications
1
2012
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
Wave propagation modeling in periodic elasto-thermo-diffusive materials via multifield asymptotic homogenization
1
2020
... 多孔材料内部周期性结构特征复杂,为降低直接使用有限元分析模拟多孔材料的复杂度,研究了渐进均匀化方法[9 -10 ] .GUEDES等[11 ] 的工作表明,渐进均匀化方法是确定微观复合材料整体性能响应的有效工具,将非均质连续体替换为等效均匀化模型,得到基于单元的均匀化材料特性,并指定用具有该均匀化特性的固体材料替代周期性结构.近年来,均匀化方法已被广泛应用于研究复杂周期性材料的整体性能问题[12 -14 ] ,文献[15 ]将均匀化方法用于多尺度并行设计,文献[16 -19 ]采用均匀化方法分析了热弹性效应周期性材料的性能特征.更多关于多相材料渐进均匀化技术的前沿研究正在进行中[20 -21 ] ,如文献[22 -23 ]利用渐进均匀化技术研究了压电复合材料. ...
A two-grid method for level-set based topology optimization with GPU-acceleration
1
2021
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
Multi-physics bi-directional evolutionary topology optimization on GPU-architecture
1
2019
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
Evaluation of effective properties of heterogeneous media through a GPGPU based algorithm
1
2010
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
Multiscale modeling of heterogeneous media applying AEH to 3D bodies
1
2012
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
GPU accelerated computational homogenization based on a variational approach in a reduced basis framework
1
2014
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
GPU parallel strategy for parameterized LSM-based topology optimization using isogeometric analysis
1
2017
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
GPU acceleration for evolutionary topology optimization of continuum structures using isosurfaces
1
2017
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
Multi-GPU acceleration of large-scale density-based topology optimization
1
2021
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
A multiple-GPU based parallel independent coefficient reanalysis method and applications for vehicle design
1
2015
... 在多尺度拓扑优化过程中,渐进均匀化方法用等效模型表示多孔晶胞的力学性能,对结构复杂的周期性晶胞单元进行网格细化,当精度要求较高时计算成本也显著提高.图形处理单元(graphics processing unit,GPU)被广泛用于加速计算,尤其是用于超大规模数据计算[24 -25 ] .由于GPU具有支持并行计算所需大量线程的特殊体系架构,成为均匀化加速的强大工具.在均匀化研究领域,QUINTELA等[26 ] 用C实现了2D均匀化程序的串行版本,随后用OpenMP和CUDA实现了并行版本.为计算3D晶胞结构的弹性特性,QUINTELA等[27 ] 用OpenMP和统一计算设备架构(compute unified device architecture,CUDA)开发了并行版本均匀化程序,获得了较高的加速比.FRITZEN等[28 ] 在其提出的黏塑性材料混合计算均匀化方法基础上进行了扩展,为Nvidia GPU开发了高性能数值计算库,利用GPU提供的功能加速均匀化过程.另外,多尺度拓扑优化是一个迭代计算过程,在求解大规模问题时需消耗大量计算和内存资源.为求解更复杂、更大规模的问题,常用GPU进行并行计算.XIA等[29 ] 采用GPU和等几何分析(IGA)并行策略,提出基于水平集的拓扑优化方法,并比较了串行CPU、多线程并行CPU与GPU的效率,得到该并行策略的加速比达到了两个数量级.JESUS等[30 ] 将无矩阵迭代求解的细粒度GPU实例作为结构分析的求解工具,提出一种拓扑优化多粒度GPU的并行策略,并将其用于等值面提取和体积分数计算.HE等[31 ] 针对单个GPU分析大规模工程优化问题存在的效率低下和内存不足等问题,提出了一种基于多GPU平台的高效并行独立系数(IC)再分析方法,通过为每个GPU划分合理大小的矩阵和向量,实现良好的负载平衡和减少GPU之间的通信.DAVID等[32 ] 提出了一种基于分布式GPU计算的拓扑优化并行计算方法,用基于平滑聚合的代数多重网格(AMG)预处理的分布式共轭梯度求解器,利用多GPU平台计算求解,通过有限元分析(finite element analysis,FEA)获得线性方程组,并用结构化网格和非结构化网格对分布式GPU系统的性能与可扩展性进行了评估. ...
Nonlinear Computational Models for Composite Materials Using Homogenization
1
1990
... 在宏观尺度上求解平衡方程式(1) ,需基于渐进均匀化方法获得微观尺度的有效信息,即均匀化单元弹性张量C . 渐进均匀化,可用等效模型表示微结构单元的力学性能,已被广泛用于多尺度拓扑优化设计[33 -34 ] .在渐进均匀化算法中,先建立相应的有限元方程并求解,得到单元位移与整体位移场,再计算均匀化单元弹性张量C . 均匀化弹性张量E i l H
Generating optimal topologies in structural design using a homogenization method
1
1988
... 在宏观尺度上求解平衡方程式(1) ,需基于渐进均匀化方法获得微观尺度的有效信息,即均匀化单元弹性张量C . 渐进均匀化,可用等效模型表示微结构单元的力学性能,已被广泛用于多尺度拓扑优化设计[33 -34 ] .在渐进均匀化算法中,先建立相应的有限元方程并求解,得到单元位移与整体位移场,再计算均匀化单元弹性张量C . 均匀化弹性张量E i l H
High resolution topology optimization using graphics processing units (GPUs)
1
2014
... GPU具有并行计算大型数据的能力,自NVIDIA[35 ] 于2007年发布CUDA以来,GPU被广泛用于大规模科学计算.CUDA是一种异构计算平台,由CPU和GPU两种架构组成,其应用分为CPU主机端代码与GPU设备端代码,两者通过PCle总线进行信息交流[36 ] .主机端代码主要负责设备的控制和数据传输,设备端代码定义功能函数并完成相应计算,此函数称为核函数.线程作为最小执行单元,在并行计算时,GPU将利用大量线程执行核函数[37 ] .逻辑上将全部线程以一定数量各自归集到一起形成线程块,块中线程以线程束(32个线程)为单位在CUDA核心处理器上运行,如图2 所示.流式多处理器(SM)作为GPU并行架构的组成单元,支持大量线程并发执行,而线程束正是SM的并发执行单元.在SM中,以单指令、多线程(SIMT)方式管理执行线程,线程束中的执行线程在同一时刻运行同一条指令[38 ] . ...
Graph grammar-Based multi-frontal parallel direct solver for two-dimensional isogeometric analysis
1
2012
... GPU具有并行计算大型数据的能力,自NVIDIA[35 ] 于2007年发布CUDA以来,GPU被广泛用于大规模科学计算.CUDA是一种异构计算平台,由CPU和GPU两种架构组成,其应用分为CPU主机端代码与GPU设备端代码,两者通过PCle总线进行信息交流[36 ] .主机端代码主要负责设备的控制和数据传输,设备端代码定义功能函数并完成相应计算,此函数称为核函数.线程作为最小执行单元,在并行计算时,GPU将利用大量线程执行核函数[37 ] .逻辑上将全部线程以一定数量各自归集到一起形成线程块,块中线程以线程束(32个线程)为单位在CUDA核心处理器上运行,如图2 所示.流式多处理器(SM)作为GPU并行架构的组成单元,支持大量线程并发执行,而线程束正是SM的并发执行单元.在SM中,以单指令、多线程(SIMT)方式管理执行线程,线程束中的执行线程在同一时刻运行同一条指令[38 ] . ...
Revised simplex algorithm for linear programming on GPUs with CUDA
1
2018
... GPU具有并行计算大型数据的能力,自NVIDIA[35 ] 于2007年发布CUDA以来,GPU被广泛用于大规模科学计算.CUDA是一种异构计算平台,由CPU和GPU两种架构组成,其应用分为CPU主机端代码与GPU设备端代码,两者通过PCle总线进行信息交流[36 ] .主机端代码主要负责设备的控制和数据传输,设备端代码定义功能函数并完成相应计算,此函数称为核函数.线程作为最小执行单元,在并行计算时,GPU将利用大量线程执行核函数[37 ] .逻辑上将全部线程以一定数量各自归集到一起形成线程块,块中线程以线程束(32个线程)为单位在CUDA核心处理器上运行,如图2 所示.流式多处理器(SM)作为GPU并行架构的组成单元,支持大量线程并发执行,而线程束正是SM的并发执行单元.在SM中,以单指令、多线程(SIMT)方式管理执行线程,线程束中的执行线程在同一时刻运行同一条指令[38 ] . ...
GPU accelerated fast multipole methods for vortex particle simulation
1
2013
... GPU具有并行计算大型数据的能力,自NVIDIA[35 ] 于2007年发布CUDA以来,GPU被广泛用于大规模科学计算.CUDA是一种异构计算平台,由CPU和GPU两种架构组成,其应用分为CPU主机端代码与GPU设备端代码,两者通过PCle总线进行信息交流[36 ] .主机端代码主要负责设备的控制和数据传输,设备端代码定义功能函数并完成相应计算,此函数称为核函数.线程作为最小执行单元,在并行计算时,GPU将利用大量线程执行核函数[37 ] .逻辑上将全部线程以一定数量各自归集到一起形成线程块,块中线程以线程束(32个线程)为单位在CUDA核心处理器上运行,如图2 所示.流式多处理器(SM)作为GPU并行架构的组成单元,支持大量线程并发执行,而线程束正是SM的并发执行单元.在SM中,以单指令、多线程(SIMT)方式管理执行线程,线程束中的执行线程在同一时刻运行同一条指令[38 ] . ...
GPU加速不完全Cholesky分解预条件共轭梯度法
1
2015
... 在求解有限元整体平衡方程 K x = f x = K \ f [39 ] .通常,用共轭梯度法(conjugate gradients,CG)求解大型稀疏矩阵方程,稀疏矩阵需满足对称及正定条件[40 ] ,而整体刚度矩阵K
GPU加速不完全Cholesky分解预条件共轭梯度法
1
2015
... 在求解有限元整体平衡方程 K x = f x = K \ f [39 ] .通常,用共轭梯度法(conjugate gradients,CG)求解大型稀疏矩阵方程,稀疏矩阵需满足对称及正定条件[40 ] ,而整体刚度矩阵K
A conjugate gradient algorithm for large-scale nonlinear equations and image restoration problems
1
2020
... 在求解有限元整体平衡方程 K x = f x = K \ f [39 ] .通常,用共轭梯度法(conjugate gradients,CG)求解大型稀疏矩阵方程,稀疏矩阵需满足对称及正定条件[40 ] ,而整体刚度矩阵K
Sparse matrix multiplication: The distributed block-compressed sparse row library
1
2014
... 有限元法的整体刚度矩阵为稀疏矩阵,本文CG方法采用行压缩(compressed sparse row,CSR)方式存储稀疏矩阵 A [41 ] ,如整体刚度矩阵.CSR格式将稀疏矩阵分为3个一维向量,分别为Val向量,记录非零元素值;Col_Val向量,记录非零元素对应的列号;Row_Val向量,记录矩阵每行中首个非零元素前的总非零元素个数. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}